 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Impact of dataset size and long-term ECoG-based BCI usage on deep learning decoders performance
Sep 08, 2022


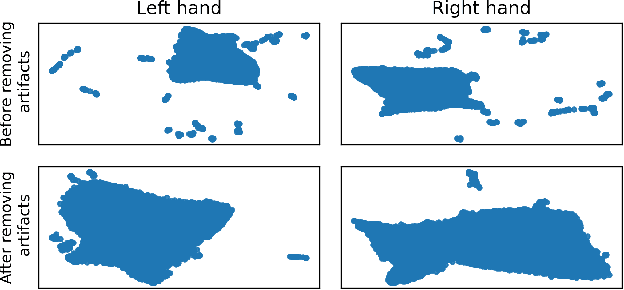
In brain-computer interfaces (BCI) research, recording data is time-consuming and expensive, which limits access to big datasets. This may influence the BCI system performance as machine learning methods depend strongly on the training dataset size. Important questions arise: taking into account neuronal signal characteristics (e.g., non-stationarity), can we achieve higher decoding performance with more data to train decoders? What is the perspective for further improvement with time in the case of long-term BCI studies? In this study, we investigated the impact of long-term recordings on motor imagery decoding from two main perspectives: model requirements regarding dataset size and potential for patient adaptation. We evaluated the multilinear model and two deep learning (DL) models on a long-term BCI and Tetraplegia NCT02550522 clinical trial dataset containing 43 sessions of ECoG recordings performed with a tetraplegic patient. In the experiment, a participant executed 3D virtual hand translation using motor imagery patterns. We designed multiple computational experiments in which training datasets were increased or translated to investigate the relationship between models' performance and different factors influencing recordings. Our analysis showed that adding more data to the training dataset may not instantly increase performance for datasets already containing 40 minutes of the signal. DL decoders showed similar requirements regarding the dataset size compared to the multilinear model while demonstrating higher decoding performance. Moreover, high decoding performance was obtained with relatively small datasets recorded later in the experiment, suggesting motor imagery patterns improvement and patient adaptation. Finally, we proposed UMAP embeddings and local intrinsic dimensionality as a way to visualize the data and potentially evaluate data quality.
GATraj: A Graph- and Attention-based Multi-Agent Trajectory Prediction Model
Sep 16, 2022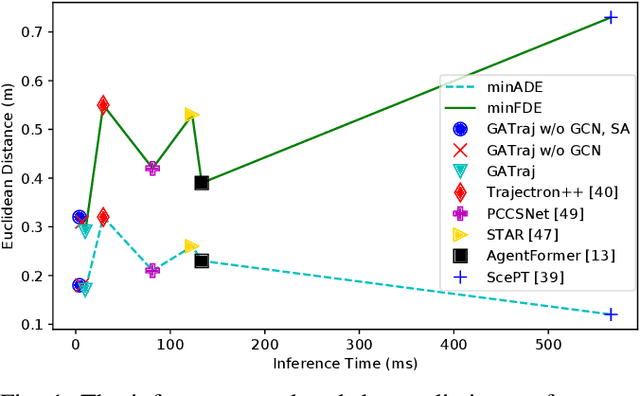

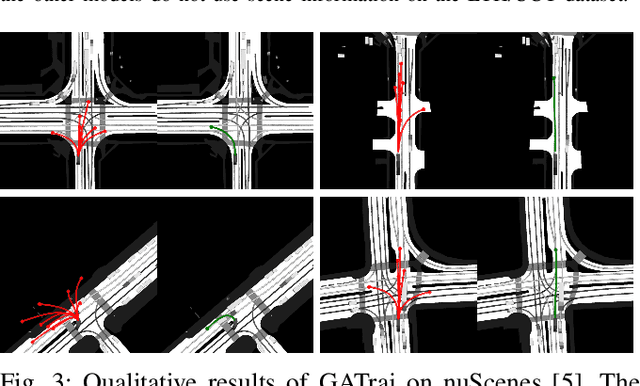
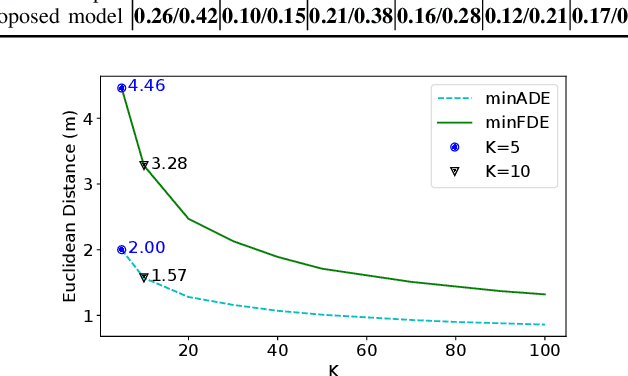
Trajectory prediction has been a long-standing problem in intelligent systems such as autonomous driving and robot navigation. Recent state-of-the-art models trained on large-scale benchmarks have been pushing the limit of performance rapidly, mainly focusing on improving prediction accuracy. However, those models put less emphasis on efficiency, which is critical for real-time applications. This paper proposes an attention-based graph model named GATraj with a much higher prediction speed. Spatial-temporal dynamics of agents, e.g., pedestrians or vehicles, are modeled by attention mechanisms. Interactions among agents are modeled by a graph convolutional network. We also implement a Laplacian mixture decoder to mitigate mode collapse and generate diverse multimodal predictions for each agent. Our model achieves performance on par with the state-of-the-art models at a much higher prediction speed tested on multiple open datasets.
IGNiteR: News Recommendation in Microblogging Applications (Extended Version)
Oct 04, 2022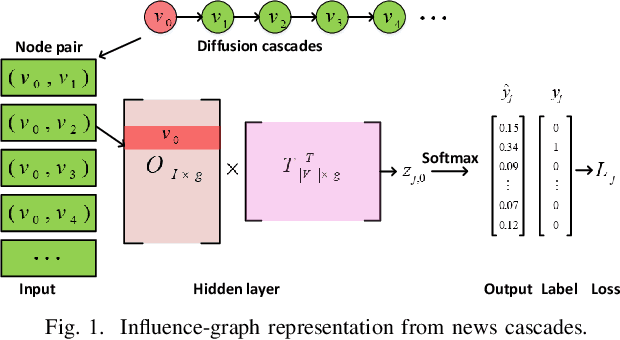
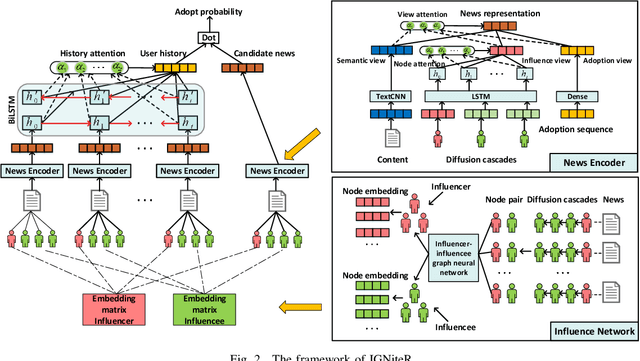
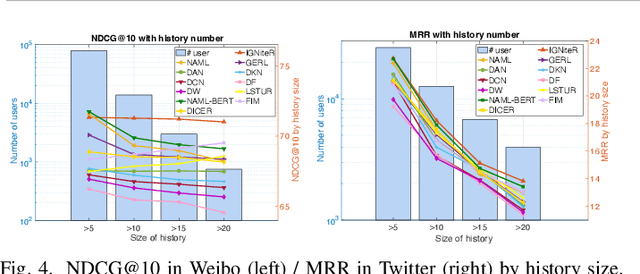
News recommendation is one of the most challenging tasks in recommender systems, mainly due to the ephemeral relevance of news to users. As social media, and particularly microblogging applications like Twitter or Weibo, gains popularity as platforms for news dissemination, personalized news recommendation in this context becomes a significant challenge. We revisit news recommendation in the microblogging scenario, by taking into consideration social interactions and observations tracing how the information that is up for recommendation spreads in an underlying network. We propose a deep-learning based approach that is diffusion and influence-aware, called Influence-Graph News Recommender (IGNiteR). It is a content-based deep recommendation model that jointly exploits all the data facets that may impact adoption decisions, namely semantics, diffusion-related features pertaining to local and global influence among users, temporal attractiveness, and timeliness, as well as dynamic user preferences. To represent the news, a multi-level attention-based encoder is used to reveal the different interests of users. This news encoder relies on a CNN for the news content and on an attentive LSTM for the diffusion traces. For the latter, by exploiting previously observed news diffusions (cascades) in the microblogging medium, users are mapped to a latent space that captures potential influence on others or susceptibility of being influenced for news adoptions. Similarly, a time-sensitive user encoder enables us to capture the dynamic preferences of users with an attention-based bidirectional LSTM. We perform extensive experiments on two real-world datasets, showing that IGNiteR outperforms the state-of-the-art deep-learning based news recommendation methods.
Independent Natural Policy Gradient Methods for Potential Games: Finite-time Global Convergence with Entropy Regularization
Apr 12, 2022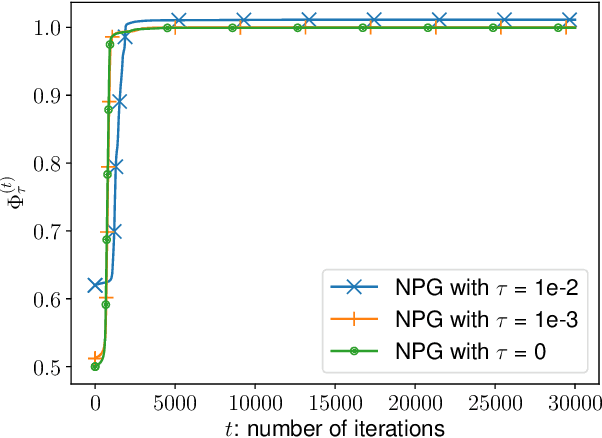
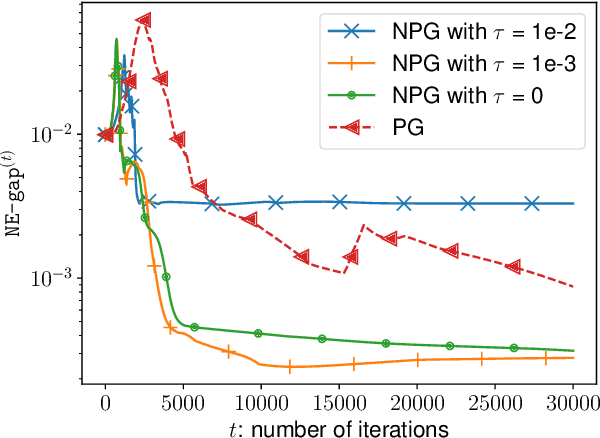
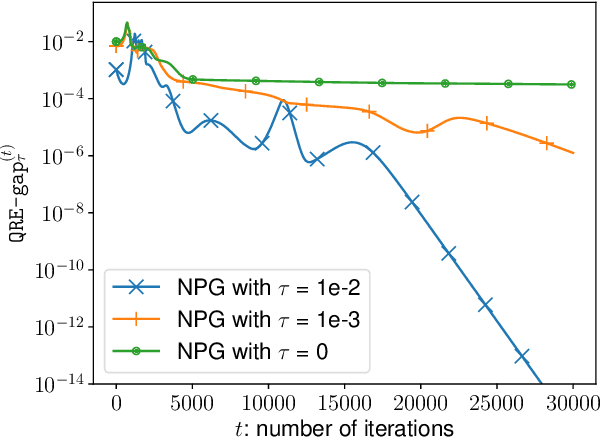
A major challenge in multi-agent systems is that the system complexity grows dramatically with the number of agents as well as the size of their action spaces, which is typical in real world scenarios such as autonomous vehicles, robotic teams, network routing, etc. It is hence in imminent need to design decentralized or independent algorithms where the update of each agent is only based on their local observations without the need of introducing complex communication/coordination mechanisms. In this work, we study the finite-time convergence of independent entropy-regularized natural policy gradient (NPG) methods for potential games, where the difference in an agent's utility function due to unilateral deviation matches exactly that of a common potential function. The proposed entropy-regularized NPG method enables each agent to deploy symmetric, decentralized, and multiplicative updates according to its own payoff. We show that the proposed method converges to the quantal response equilibrium (QRE) -- the equilibrium to the entropy-regularized game -- at a sublinear rate, which is independent of the size of the action space and grows at most sublinearly with the number of agents. Appealingly, the convergence rate further becomes independent with the number of agents for the important special case of identical-interest games, leading to the first method that converges at a dimension-free rate. Our approach can be used as a smoothing technique to find an approximate Nash equilibrium (NE) of the unregularized problem without assuming that stationary policies are isolated.
Deterministic Sequencing of Exploration and Exploitation for Reinforcement Learning
Sep 12, 2022We propose Deterministic Sequencing of Exploration and Exploitation (DSEE) algorithm with interleaving exploration and exploitation epochs for model-based RL problems that aim to simultaneously learn the system model, i.e., a Markov decision process (MDP), and the associated optimal policy. During exploration, DSEE explores the environment and updates the estimates for expected reward and transition probabilities. During exploitation, the latest estimates of the system dynamics are used to obtain a robust policy with high probability. We design the lengths of the exploration and exploitation epochs such that the cumulative regret grows as a sub-linear function of time. We also discuss a method for efficient exploration using multi-hop MDP and Metropolis-Hastings algorithm to uniformly sample each state-action pair with high probability.
Celeritas: Fast Optimizer for Large Dataflow Graphs
Jul 30, 2022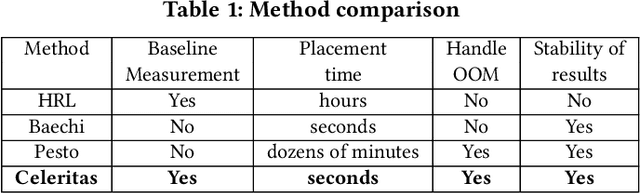
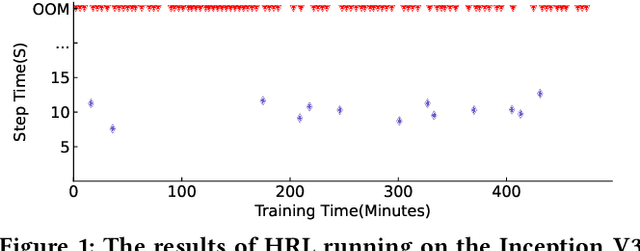
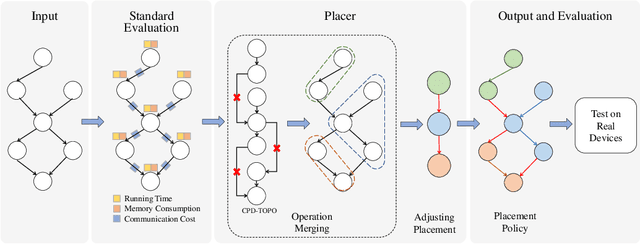
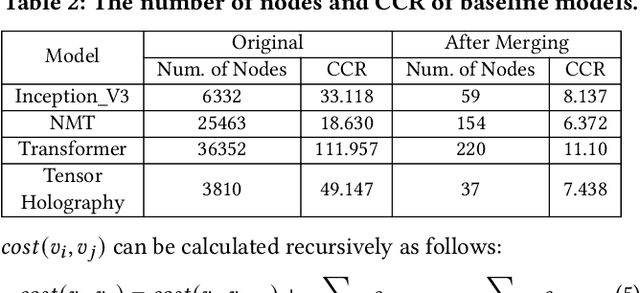
The rapidly enlarging neural network models are becoming increasingly challenging to run on a single device. Hence model parallelism over multiple devices is critical to guarantee the efficiency of training large models. Recent proposals fall short either in long processing time or poor performance. Therefore, we propose Celeritas, a fast framework for optimizing device placement for large models. Celeritas employs a simple but efficient model parallelization strategy in the Standard Evaluation, and generates placement policies through a series of scheduling algorithms. We conduct experiments to deploy and evaluate Celeritas on numerous large models. The results show that Celeritas not only reduces the placement policy generation time by 26.4\% but also improves the model running time by 34.2\% compared to most advanced methods.
An Efficient and Reliable Asynchronous Federated Learning Scheme for Smart Public Transportation
Aug 15, 2022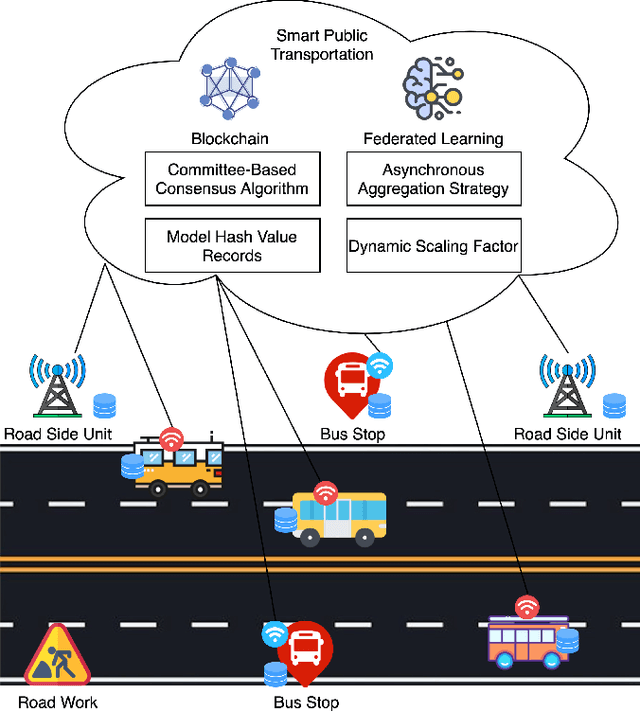
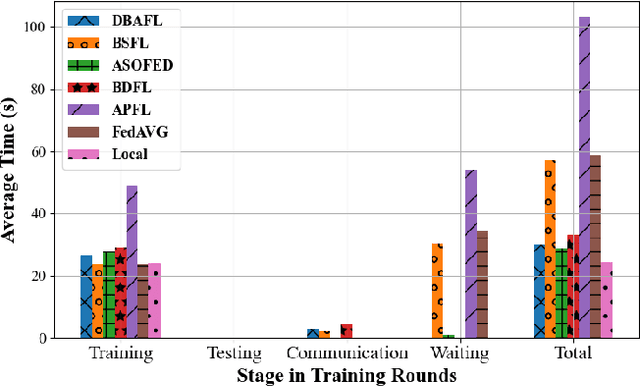
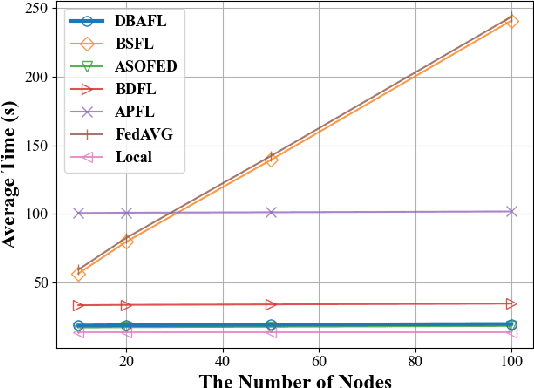
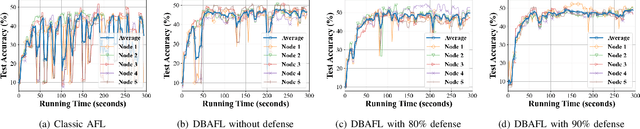
Machine Learning (ML) is a distributed approach for training predictive models on the Internet of Vehicles (IoV) to enable smart public transportation. Since the traffic conditions change over time, the ML model that predicts traffic flows and the time passengers wait at stops must be updated continuously and efficiently. Federated learning (FL) is a distributed machine learning scheme that allows vehicles to receive continuous model updates without having to upload raw data to the cloud and wait for models to be trained. However, FL in smart public transportation is vulnerable to poisoning or DDoS attacks since vehicles travel in public. Besides, due to device heterogeneity and imbalanced data distributions, the synchronized aggregation strategy that collects local models from specific vehicles before aggregation is inefficient. Although Asynchronous Federated Learning (AFL) schemes are developed to improve efficiency by aggregating local models as soon as they are received, the stale local models remain unreasonably weighted, resulting in poor learning performance. To enable smarter public transportation, this paper offers a blockchain-based asynchronous federated learning scheme with a dynamic scaling factor (DBAFL). Specifically, the novel committee-based consensus algorithm for blockchain improves reliability at the lowest possible cost of time. Meanwhile, the devised dynamic scaling factor allows AFL to assign reasonable weight to stale local models. Extensive experiments conducted on heterogeneous devices validate outperformed learning performance, efficiency, and reliability of DBAFL.
Distribution Calibration for Out-of-Domain Detection with Bayesian Approximation
Sep 14, 2022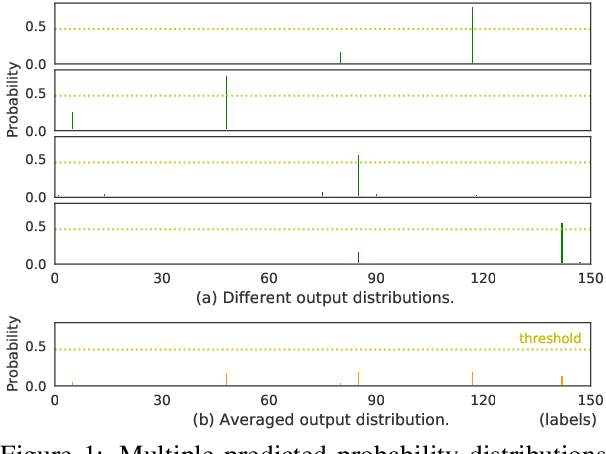
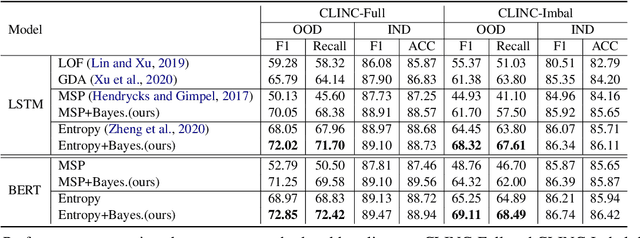
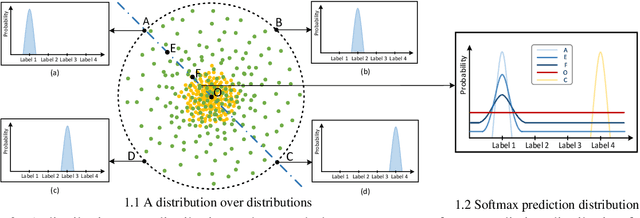
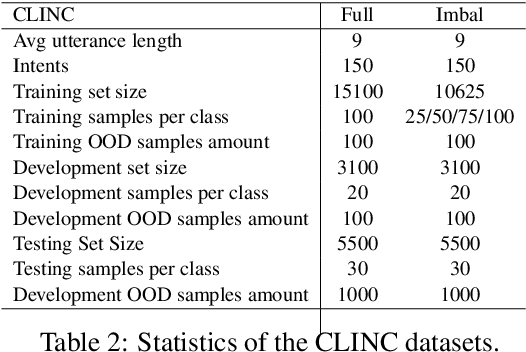
Out-of-Domain (OOD) detection is a key component in a task-oriented dialog system, which aims to identify whether a query falls outside the predefined supported intent set. Previous softmax-based detection algorithms are proved to be overconfident for OOD samples. In this paper, we analyze overconfident OOD comes from distribution uncertainty due to the mismatch between the training and test distributions, which makes the model can't confidently make predictions thus probably causing abnormal softmax scores. We propose a Bayesian OOD detection framework to calibrate distribution uncertainty using Monte-Carlo Dropout. Our method is flexible and easily pluggable into existing softmax-based baselines and gains 33.33\% OOD F1 improvements with increasing only 0.41\% inference time compared to MSP. Further analyses show the effectiveness of Bayesian learning for OOD detection.
Analysis of Reinforcement Learning for determining task replication in workflows
Sep 14, 2022

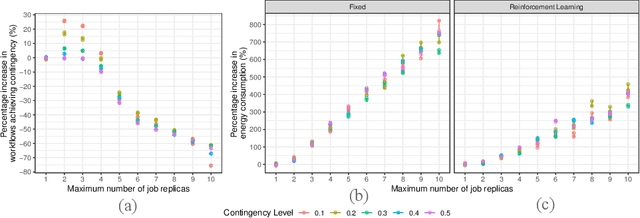
Executing workflows on volunteer computing resources where individual tasks may be forced to relinquish their resource for the resource's primary use leads to unpredictability and often significantly increases execution time. Task replication is one approach that can ameliorate this challenge. This comes at the expense of a potentially significant increase in system load and energy consumption. We propose the use of Reinforcement Learning (RL) such that a system may `learn' the `best' number of replicas to run to increase the number of workflows which complete promptly whilst minimising the additional workload on the system when replicas are not beneficial. We show, through simulation, that we can save 34% of the energy consumption using RL compared to a fixed number of replicas with only a 4% decrease in workflows achieving a pre-defined overhead bound.
Optimal Latent Space Forecasting for Large Collections of Short Time Series Using Temporal Matrix Factorization
Dec 15, 2021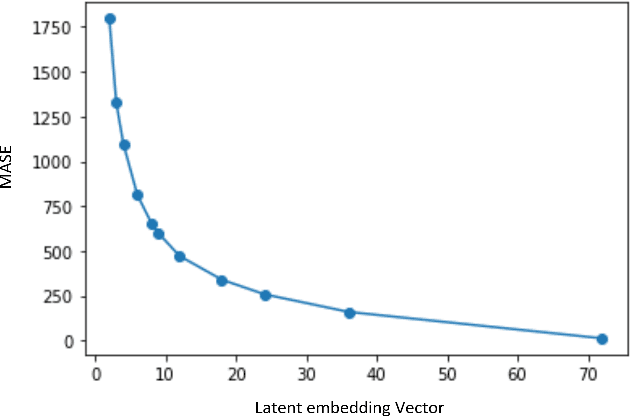
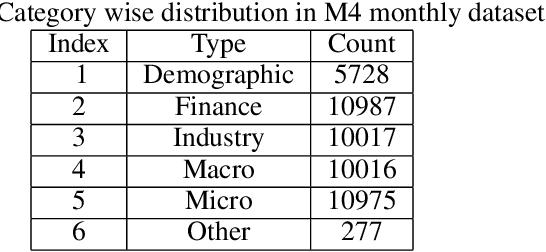
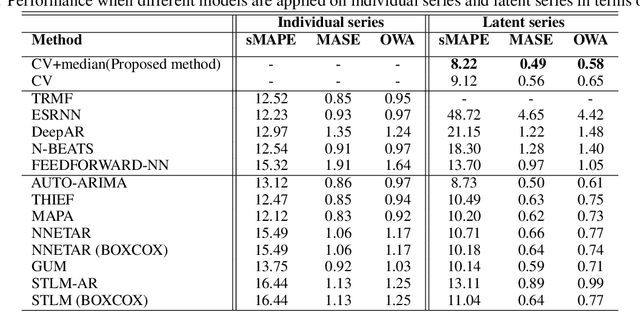
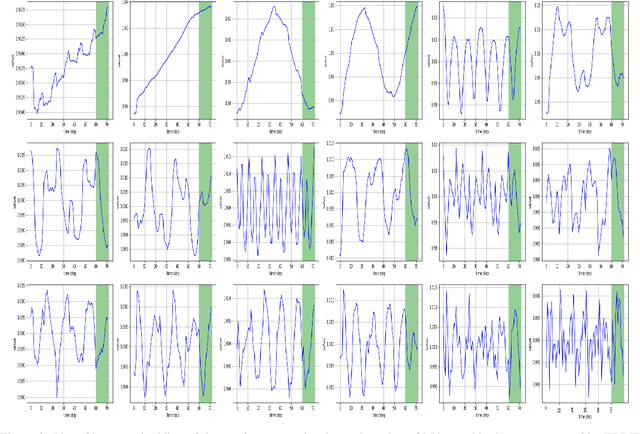
In the context of time series forecasting, it is a common practice to evaluate multiple methods and choose one of these methods or an ensemble for producing the best forecasts. However, choosing among different ensembles over multiple methods remains a challenging task that undergoes a combinatorial explosion as the number of methods increases. In the context of demand forecasting or revenue forecasting, this challenge is further exacerbated by a large number of time series as well as limited historical data points available due to changing business context. Although deep learning forecasting methods aim to simultaneously forecast large collections of time series, they become challenging to apply in such scenarios due to the limited history available and might not yield desirable results. We propose a framework for forecasting short high-dimensional time series data by combining low-rank temporal matrix factorization and optimal model selection on latent time series using cross-validation. We demonstrate that forecasting the latent factors leads to significant performance gains as compared to directly applying different uni-variate models on time series. Performance has been validated on a truncated version of the M4 monthly dataset which contains time series data from multiple domains showing the general applicability of the method. Moreover, it is amenable to incorporating the analyst view of the future owing to the low number of latent factors which is usually impractical when applying forecasting methods directly to high dimensional datasets.