 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Labeling of fMRI Brain Networks Using Cloud Based Processing
Sep 20, 2022
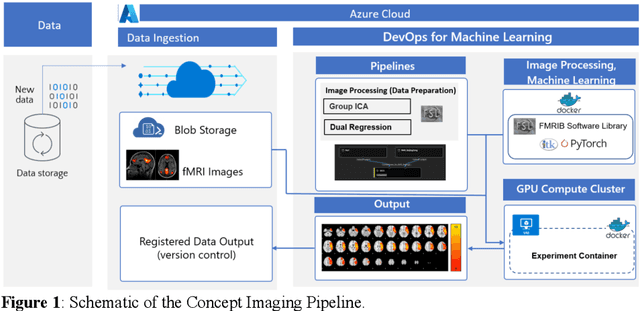
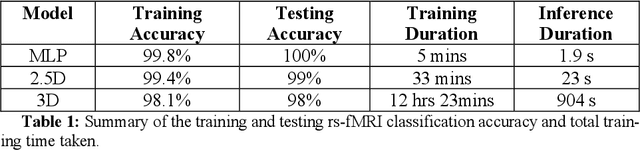

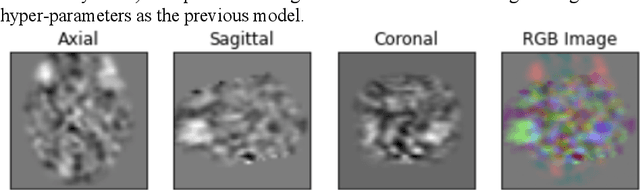
Resting state fMRI is an imaging modality which reveals brain activity localization through signal changes, in what is known as Resting State Networks (RSNs). This technique is gaining popularity in neurosurgical pre-planning to visualize the functional regions and assess regional activity. Labeling of rs-fMRI networks require subject-matter expertise and is time consuming, creating a need for an automated classification algorithm. While the impact of AI in medical diagnosis has shown great progress; deploying and maintaining these in a clinical setting is an unmet need. We propose an end-to-end reproducible pipeline which incorporates image processing of rs-fMRI in a cloud-based workflow while using deep learning to automate the classification of RSNs. We have architected a reproducible Azure Machine Learning cloud-based medical imaging concept pipeline for fMRI analysis integrating the popular FMRIB Software Library (FSL) toolkit. To demonstrate a clinical application using a large dataset, we compare three neural network architectures for classification of deeper RSNs derived from processed rs-fMRI. The three algorithms are: an MLP, a 2D projection-based CNN, and a fully 3D CNN classification networks. Each of the net-works was trained on the rs-fMRI back-projected independent components giving >98% accuracy for each classification method.
Improving GANs with A Dynamic Discriminator
Sep 20, 2022
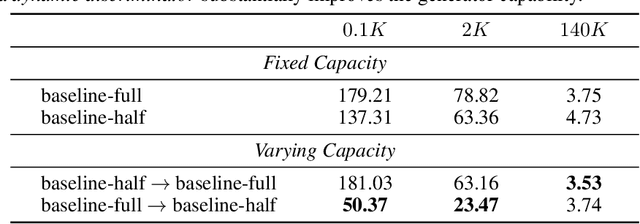

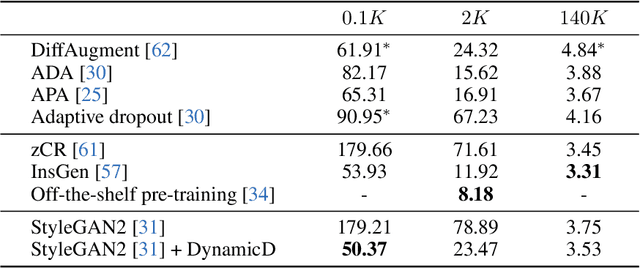
Discriminator plays a vital role in training generative adversarial networks (GANs) via distinguishing real and synthesized samples. While the real data distribution remains the same, the synthesis distribution keeps varying because of the evolving generator, and thus effects a corresponding change to the bi-classification task for the discriminator. We argue that a discriminator with an on-the-fly adjustment on its capacity can better accommodate such a time-varying task. A comprehensive empirical study confirms that the proposed training strategy, termed as DynamicD, improves the synthesis performance without incurring any additional computation cost or training objectives. Two capacity adjusting schemes are developed for training GANs under different data regimes: i) given a sufficient amount of training data, the discriminator benefits from a progressively increased learning capacity, and ii) when the training data is limited, gradually decreasing the layer width mitigates the over-fitting issue of the discriminator. Experiments on both 2D and 3D-aware image synthesis tasks conducted on a range of datasets substantiate the generalizability of our DynamicD as well as its substantial improvement over the baselines. Furthermore, DynamicD is synergistic to other discriminator-improving approaches (including data augmentation, regularizers, and pre-training), and brings continuous performance gain when combined for learning GANs.
Combining Hybrid Architecture and Pseudo-label for Semi-supervised Abdominal Organ Segmentation
Jul 23, 2022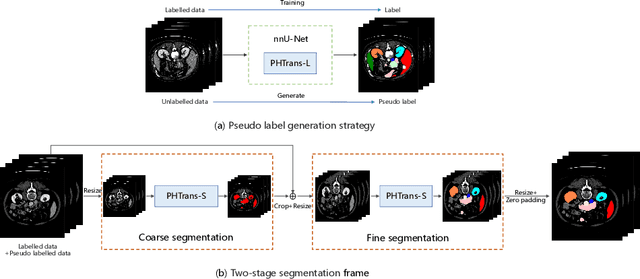

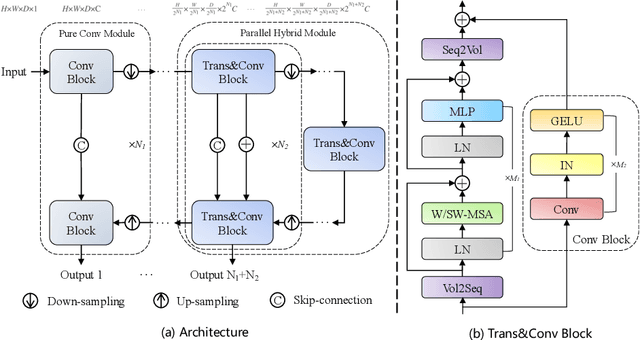
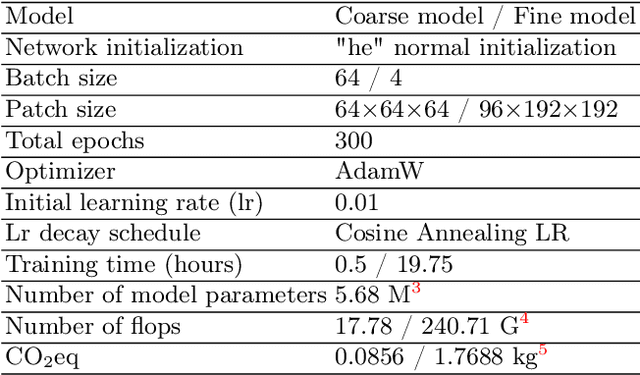
Abdominal organ segmentation has many important clinical applications, such as organ quantification, surgical planning, and disease diagnosis. However, manually annotating organs from CT scans is time-consuming and labor-intensive. Semi-supervised learning has shown the potential to alleviate this challenge by learning from a large set of unlabeled images and limited labeled samples. In this work, we follow the self-training strategy and employ a hybrid architecture (PHTrans) with CNN and Transformer for both teacher and student models to generate precise pseudo-labels. Afterward, we introduce them with label data together into a two-stage segmentation framework with lightweight PHTrans for training to improve the performance and generalization ability of the model while remaining efficient. Experiments on the validation set of FLARE2022 demonstrate that our method achieves excellent segmentation performance as well as fast and low-resource model inference. The average DSC and HSD are 0.8956 and 0.9316, respectively. Under our development environments, the average inference time is 18.62 s, the average maximum GPU memory is 1995.04 MB, and the area under the GPU memory-time curve and the average area under the CPU utilization-time curve are 23196.84 and 319.67.
Extremely Simple Activation Shaping for Out-of-Distribution Detection
Sep 20, 2022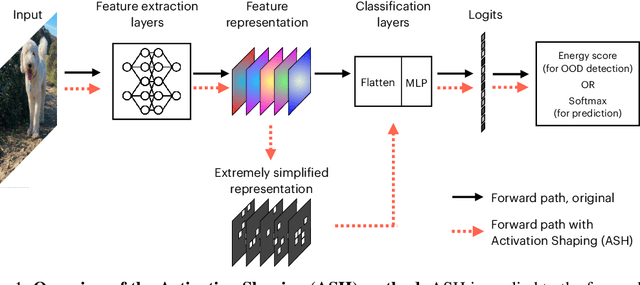


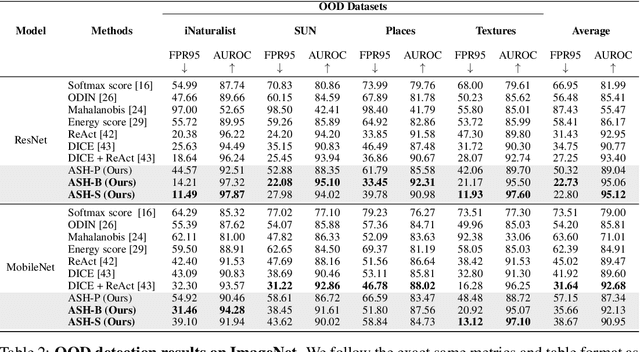
The separation between training and deployment of machine learning models implies that not all scenarios encountered in deployment can be anticipated during training, and therefore relying solely on advancements in training has its limits. Out-of-distribution (OOD) detection is an important area that stress-tests a model's ability to handle unseen situations: Do models know when they don't know? Existing OOD detection methods either incur extra training steps, additional data or make nontrivial modifications to the trained network. In contrast, in this work, we propose an extremely simple, post-hoc, on-the-fly activation shaping method, ASH, where a large portion (e.g. 90%) of a sample's activation at a late layer is removed, and the rest (e.g. 10%) simplified or lightly adjusted. The shaping is applied at inference time, and does not require any statistics calculated from training data. Experiments show that such a simple treatment enhances in-distribution and out-of-distribution sample distinction so as to allow state-of-the-art OOD detection on ImageNet, and does not noticeably deteriorate the in-distribution accuracy. We release alongside the paper two calls for explanation and validation, believing the collective power to further validate and understand the discovery. Calls, video and code can be found at: https://andrijazz.github.io/ash
Pyramidal Denoising Diffusion Probabilistic Models
Aug 03, 2022
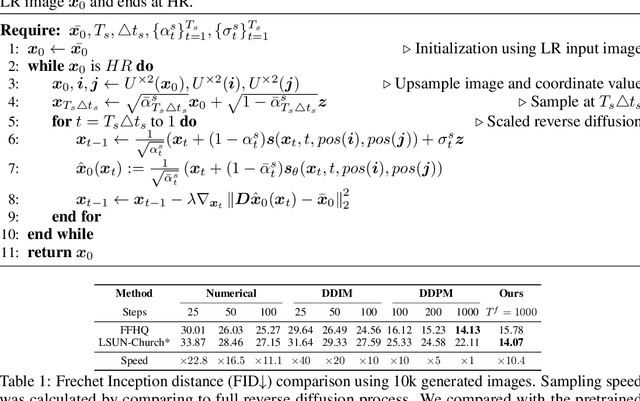
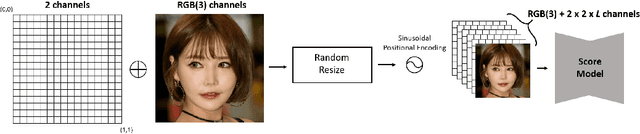
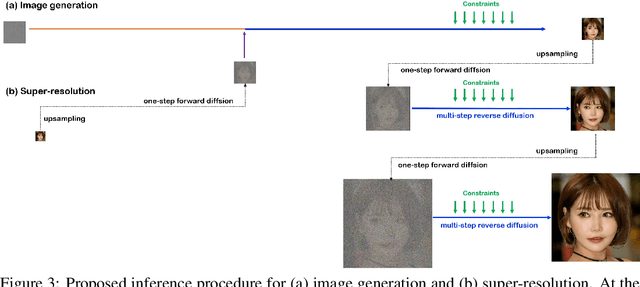
Diffusion models have demonstrated impressive image generation performance, and have been used in various computer vision tasks. Unfortunately, image generation using diffusion models is very time-consuming since it requires thousands of sampling steps. To address this problem, here we present a novel pyramidal diffusion model to generate high resolution images starting from much coarser resolution images using a single score function trained with a positional embedding. This enables a time-efficient sampling for image generation, and also solves the low batch size problem when training with limited resources. Furthermore, we show that the proposed approach can be efficiently used for multi-scale super-resolution problem using a single score function.
Spillover of Antisocial Behavior from Fringe Platforms: The Unintended Consequences of Community Banning
Sep 20, 2022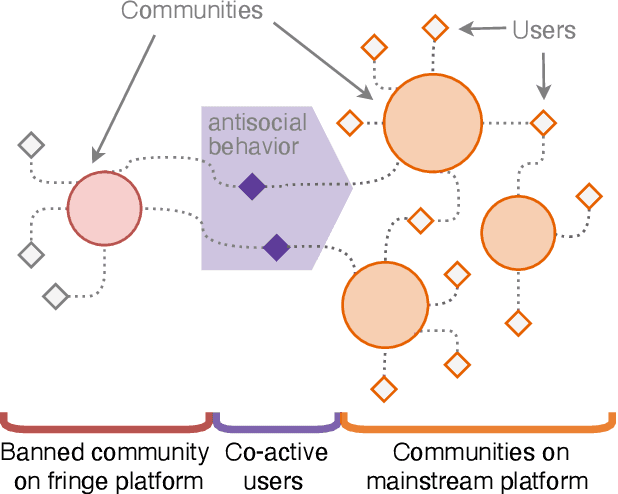
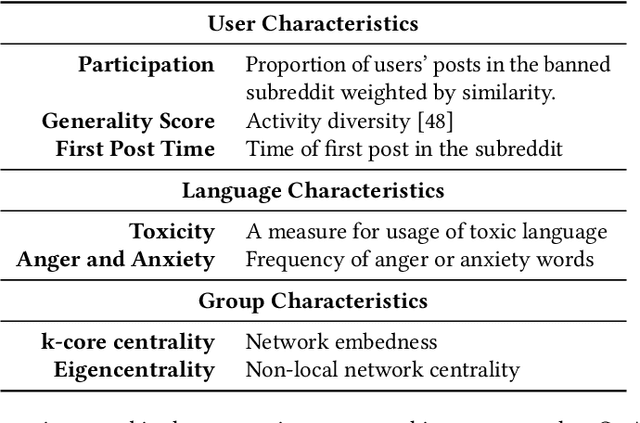
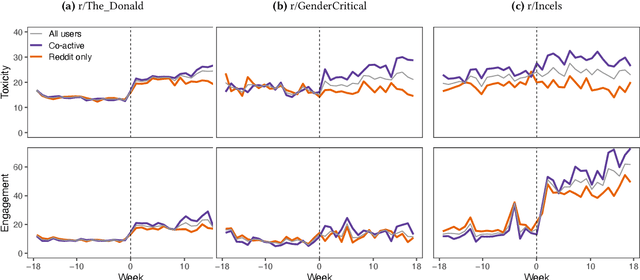
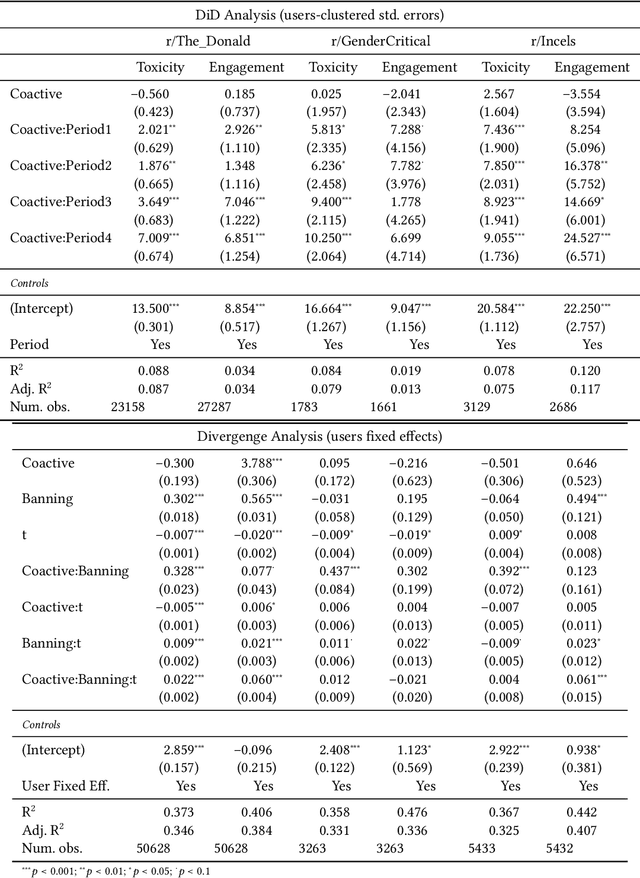
Online platforms face pressure to keep their communities civil and respectful. Thus, the bannings of problematic online communities from mainstream platforms like Reddit and Facebook are often met with enthusiastic public reactions. However, this policy can lead users to migrate to alternative fringe platforms with lower moderation standards and where antisocial behaviors like trolling and harassment are widely accepted. As users of these communities often remain \ca across mainstream and fringe platforms, antisocial behaviors may spill over onto the mainstream platform. We study this possible spillover by analyzing around $70,000$ users from three banned communities that migrated to fringe platforms: r/The\_Donald, r/GenderCritical, and r/Incels. Using a difference-in-differences design, we contrast \ca users with matched counterparts to estimate the causal effect of fringe platform participation on users' antisocial behavior on Reddit. Our results show that participating in the fringe communities increases users' toxicity on Reddit (as measured by Perspective API) and involvement with subreddits similar to the banned community -- which often also breach platform norms. The effect intensifies with time and exposure to the fringe platform. In short, we find evidence for a spillover of antisocial behavior from fringe platforms onto Reddit via co-participation.
Denoising MCMC for Accelerating Diffusion-Based Generative Models
Sep 29, 2022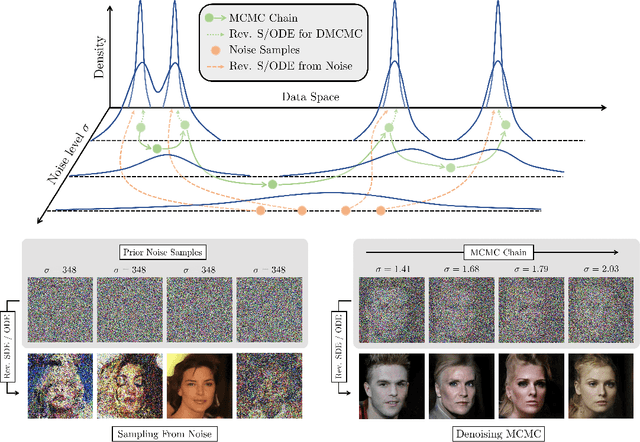
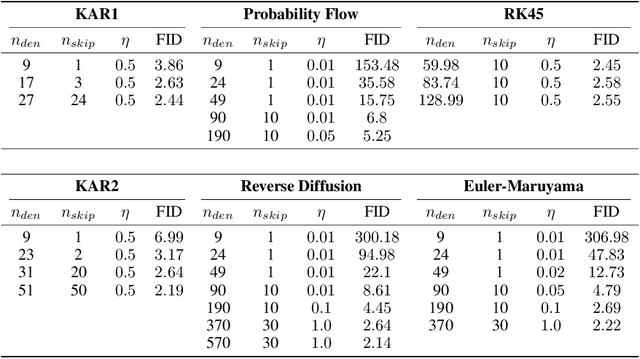
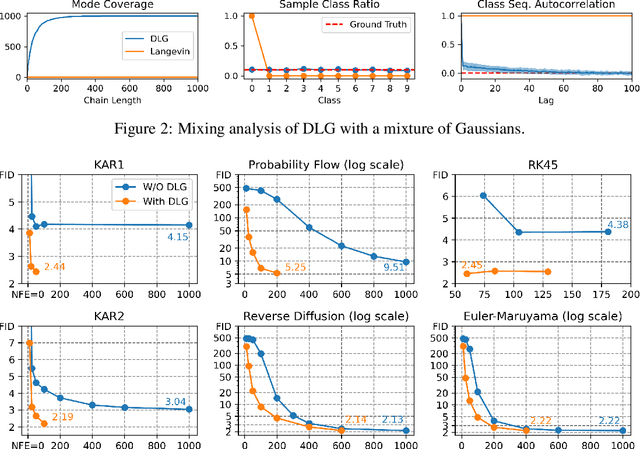
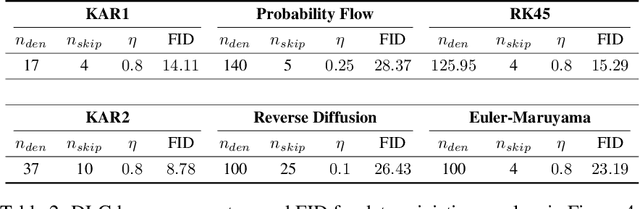
Diffusion models are powerful generative models that simulate the reverse of diffusion processes using score functions to synthesize data from noise. The sampling process of diffusion models can be interpreted as solving the reverse stochastic differential equation (SDE) or the ordinary differential equation (ODE) of the diffusion process, which often requires up to thousands of discretization steps to generate a single image. This has sparked a great interest in developing efficient integration techniques for reverse-S/ODEs. Here, we propose an orthogonal approach to accelerating score-based sampling: Denoising MCMC (DMCMC). DMCMC first uses MCMC to produce samples in the product space of data and variance (or diffusion time). Then, a reverse-S/ODE integrator is used to denoise the MCMC samples. Since MCMC traverses close to the data manifold, the computation cost of producing a clean sample for DMCMC is much less than that of producing a clean sample from noise. To verify the proposed concept, we show that Denoising Langevin Gibbs (DLG), an instance of DMCMC, successfully accelerates all six reverse-S/ODE integrators considered in this work on the tasks of CIFAR10 and CelebA-HQ-256 image generation. Notably, combined with integrators of Karras et al. (2022) and pre-trained score models of Song et al. (2021b), DLG achieves SOTA results. In the limited number of score function evaluation (NFE) settings on CIFAR10, we have $3.86$ FID with $\approx 10$ NFE and $2.63$ FID with $\approx 20$ NFE. On CelebA-HQ-256, we have $6.99$ FID with $\approx 160$ NFE, which beats the current best record of Kim et al. (2022) among score-based models, $7.16$ FID with $4000$ NFE. Code: https://github.com/1202kbs/DMCMC
OnlineSTL: Scaling Time Series Decomposition by 100x
Jul 19, 2021
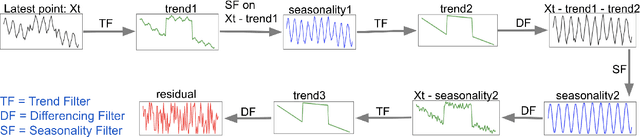
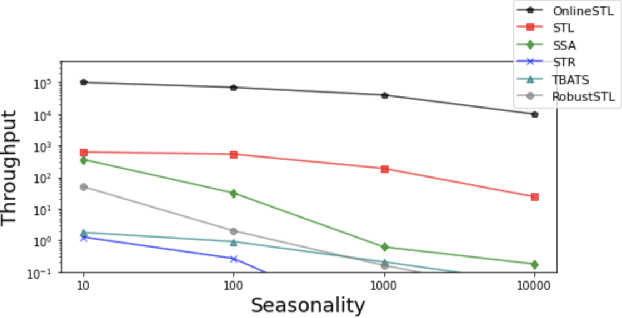

Decomposing a complex time series into trend, seasonality, and remainder components is an important primitive that facilitates time series anomaly detection, change point detection and forecasting. Although numerous batch algorithms are known for time series decomposition, none operate well in an online scalable setting where high throughput and real-time response are paramount. In this paper, we propose OnlineSTL, a novel online algorithm for time series decomposition which solves the scalability problem and is deployed for real-time metrics monitoring on high resolution, high ingest rate data. Experiments on different synthetic and real world time series datasets demonstrate that OnlineSTL achieves orders of magnitude speedups while maintaining quality of decomposition.
DeepVol: Volatility Forecasting from High-Frequency Data with Dilated Causal Convolutions
Sep 23, 2022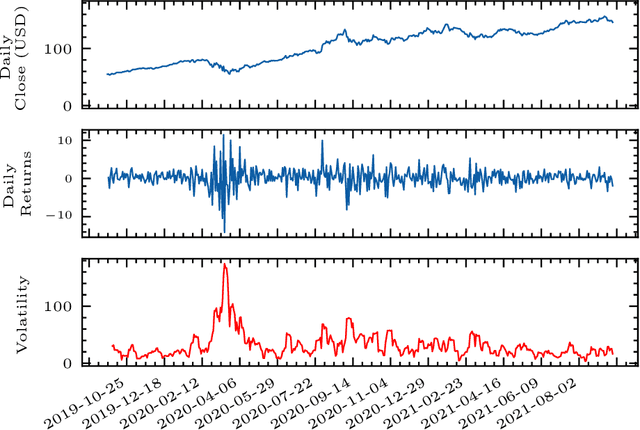
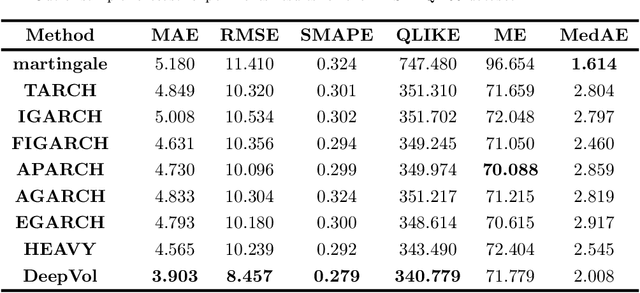
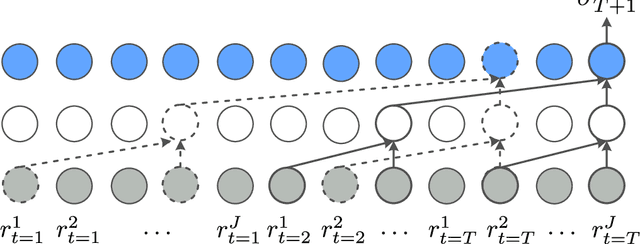
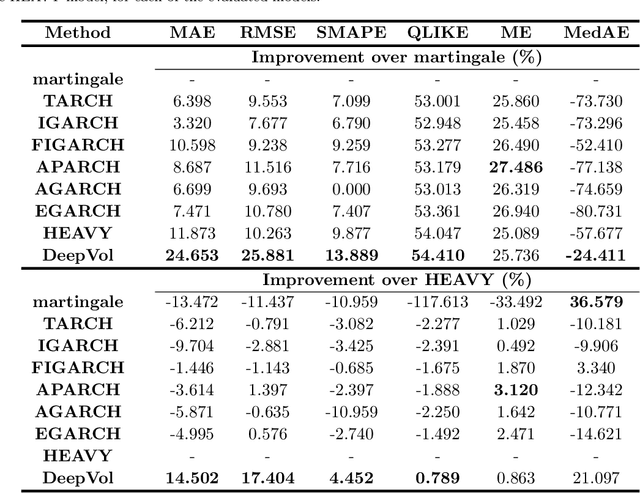
Volatility forecasts play a central role among equity risk measures. Besides traditional statistical models, modern forecasting techniques, based on machine learning, can readily be employed when treating volatility as a univariate, daily time-series. However, econometric studies have shown that increasing the number of daily observations with high-frequency intraday data helps to improve predictions. In this work, we propose DeepVol, a model based on Dilated Causal Convolutions to forecast day-ahead volatility by using high-frequency data. We show that the dilated convolutional filters are ideally suited to extract relevant information from intraday financial data, thereby naturally mimicking (via a data-driven approach) the econometric models which incorporate realised measures of volatility into the forecast. This allows us to take advantage of the abundance of intraday observations, helping us to avoid the limitations of models that use daily data, such as model misspecification or manually designed handcrafted features, whose devise involves optimising the trade-off between accuracy and computational efficiency and makes models prone to lack of adaptation into changing circumstances. In our analysis, we use two years of intraday data from NASDAQ-100 to evaluate DeepVol's performance. The reported empirical results suggest that the proposed deep learning-based approach learns global features from high-frequency data, achieving more accurate predictions than traditional methodologies, yielding to more appropriate risk measures.
Locally temporal-spatial pattern learning with graph attention mechanism for EEG-based emotion recognition
Aug 19, 2022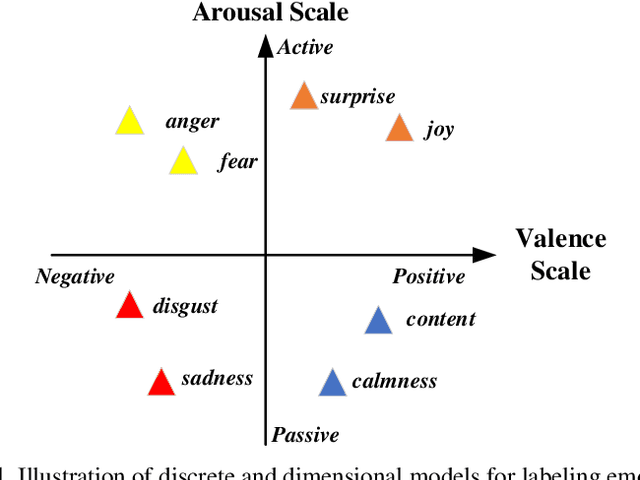

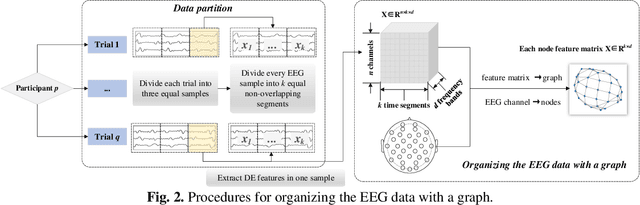
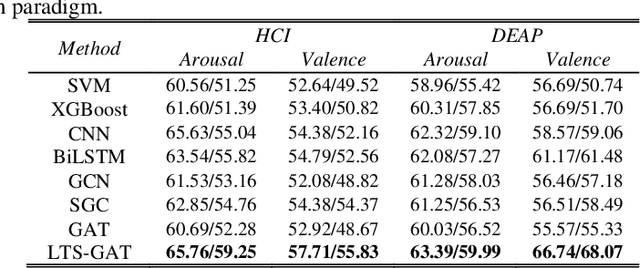
Technique of emotion recognition enables computers to classify human affective states into discrete categories. However, the emotion may fluctuate instead of maintaining a stable state even within a short time interval. There is also a difficulty to take the full use of the EEG spatial distribution due to its 3-D topology structure. To tackle the above issues, we proposed a locally temporal-spatial pattern learning graph attention network (LTS-GAT) in the present study. In the LTS-GAT, a divide-and-conquer scheme was used to examine local information on temporal and spatial dimensions of EEG patterns based on the graph attention mechanism. A dynamical domain discriminator was added to improve the robustness against inter-individual variations of the EEG statistics to learn robust EEG feature representations across different participants. We evaluated the LTS-GAT on two public datasets for affective computing studies under individual-dependent and independent paradigms. The effectiveness of LTS-GAT model was demonstrated when compared to other existing mainstream methods. Moreover, visualization methods were used to illustrate the relations of different brain regions and emotion recognition. Meanwhile, the weights of different time segments were also visualized to investigate emotion sparsity problems.