 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Quantum Advantage on Noisy Quantum Computers
Sep 27, 2022
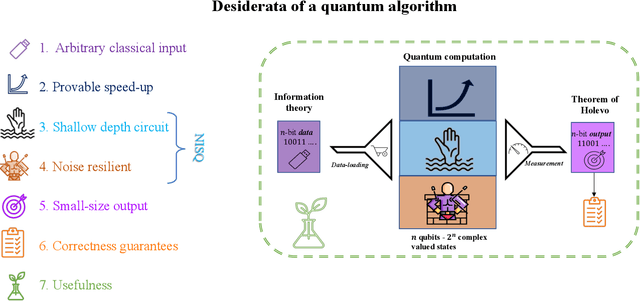

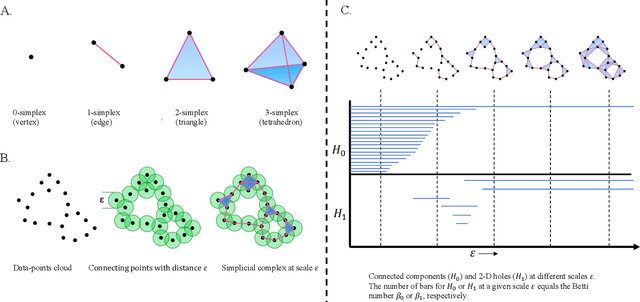
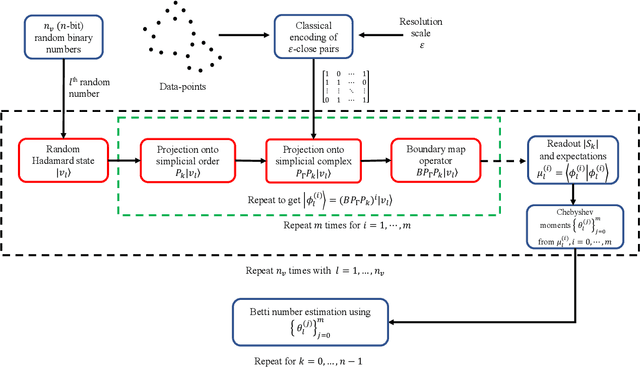
Topological data analysis (TDA) is a powerful technique for extracting complex and valuable shape-related summaries of high-dimensional data. However, the computational demands of classical TDA algorithms are exorbitant, and quickly become impractical for high-order characteristics. Quantum computing promises exponential speedup for certain problems. Yet, many existing quantum algorithms with notable asymptotic speedups require a degree of fault tolerance that is currently unavailable. In this paper, we present NISQ-TDA, the first fully implemented end-to-end quantum machine learning algorithm needing only a linear circuit-depth, that is applicable to non-handcrafted high-dimensional classical data, with potential speedup under stringent conditions. The algorithm neither suffers from the data-loading problem nor does it need to store the input data on the quantum computer explicitly. Our approach includes three key innovations: (a) an efficient realization of the full boundary operator as a sum of Pauli operators; (b) a quantum rejection sampling and projection approach to restrict a uniform superposition to the simplices of the desired order in the complex; and (c) a stochastic rank estimation method to estimate the topological features in the form of approximate Betti numbers. We present theoretical results that establish additive error guarantees for NISQ-TDA, and the circuit and computational time and depth complexities for exponentially scaled output estimates, up to the error tolerance. The algorithm was successfully executed on quantum computing devices, as well as on noisy quantum simulators, applied to small datasets. Preliminary empirical results suggest that the algorithm is robust to noise.
Biblio-Analysis of Cohort Intelligence (CI) Algorithm and its allied applications from Scopus and Web of Science Perspective
Sep 07, 2022
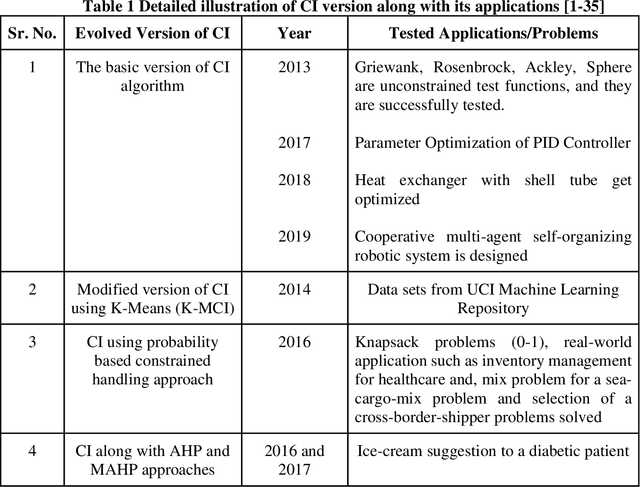
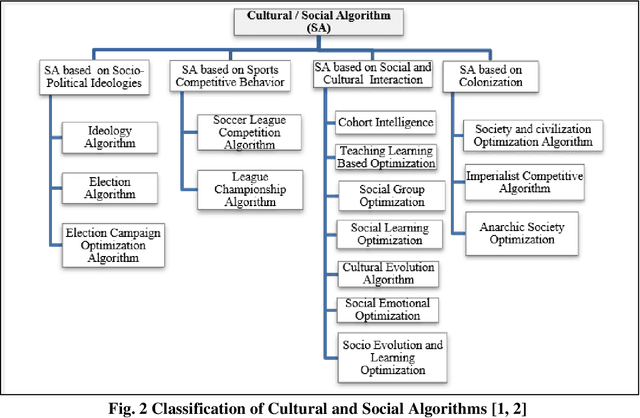
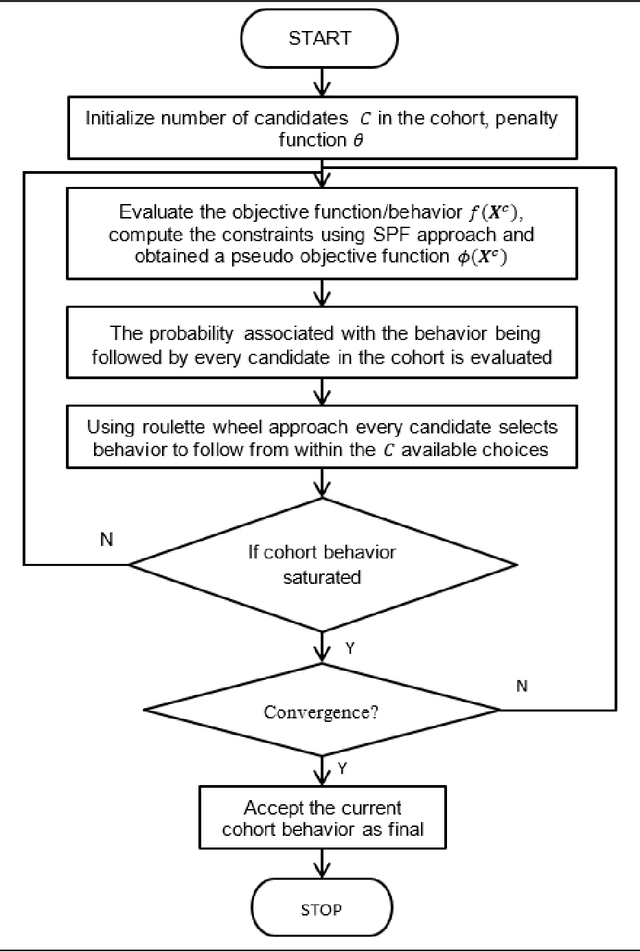
Cohort Intelligence or CI is one of its kind of novel optimization algorithm. Since its inception, in a very short span it is applied successfully in various domains and its results are observed to be effectual in contrast to algorithm of its kind. Till date, there is no such type of bibliometric analysis carried out on CI and its related applications. So, this research paper in a way will be an ice breaker for those who want to take up CI to a new level. In this research papers, CI publications available in Scopus are analyzed through graphs, networked diagrams about authors, source titles, keywords over the years, journals over the time. In a way this bibliometric paper showcase CI, its applications and detail outs systematic review in terms its bibliometric details.
Accelerating Laboratory Automation Through Robot Skill Learning For Sample Scraping
Sep 29, 2022
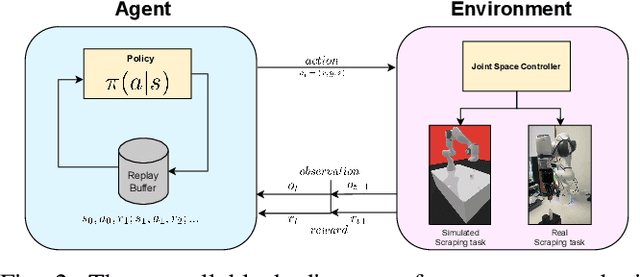
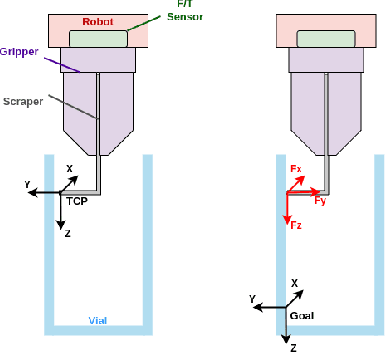
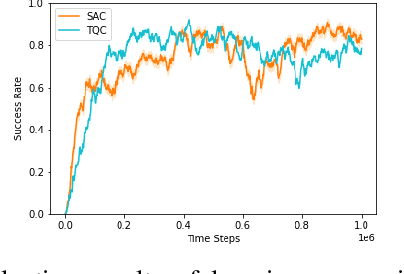
The potential use of robotics for laboratory experiments offers an attractive route to alleviate scientists from tedious tasks while accelerating the process of obtaining new materials, where topical issues such as climate change and disease risks worldwide would greatly benefit. While some experimental workflows can already benefit from automation, it is common that sample preparation is still carried out manually due to the high level of motor function required when dealing with heterogeneous systems, e.g., different tools, chemicals, and glassware. A fundamental workflow in chemical fields is crystallisation, where one application is polymorph screening, i.e., obtaining a three dimensional molecular structure from a crystal. For this process, it is of utmost importance to recover as much of the sample as possible since synthesising molecules is both costly in time and money. To this aim, chemists have to scrape vials to retrieve sample contents prior to imaging plate transfer. Automating this process is challenging as it goes beyond robotic insertion tasks due to a fundamental requirement of having to execute fine-granular movements within a constrained environment that is the sample vial. Motivated by how human chemists carry out this process of scraping powder from vials, our work proposes a model-free reinforcement learning method for learning a scraping policy, leading to a fully autonomous sample scraping procedure. To realise that, we first create a simulation environment with a Panda Franka Emika robot using a laboratory scraper which is inserted into a simulated vial, to demonstrate how a scraping policy can be learned successfully. We then evaluate our method on a real robotic manipulator in laboratory settings, and show that our method can autonomously scrape powder across various setups.
How do tuna schools associate to dFADs? A study using echo-sounder buoys to identify global patterns
Jul 14, 2022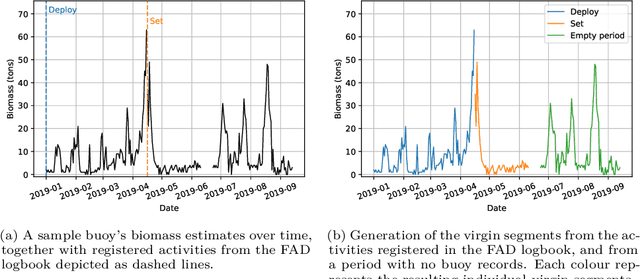
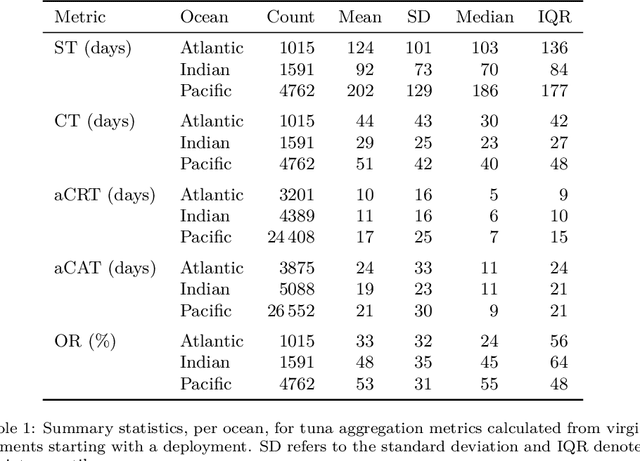

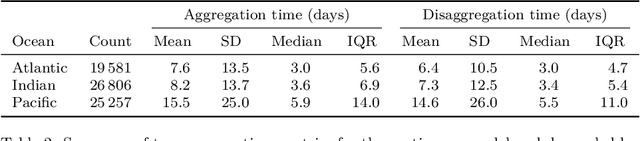
Based on the data gathered by echo-sounder buoys attached to drifting Fish Aggregating Devices (dFADs) across tropical oceans, the current study applies a Machine Learning protocol to examine the temporal trends of tuna schools' association to drifting objects. Using a binary output, metrics typically used in the literature were adapted to account for the fact that the entire tuna aggregation under the dFAD was considered. The median time it took tuna to colonize the dFADs for the first time varied between 25 and 43 days, depending on the ocean, and the longest soak and colonization times were registered in the Pacific Ocean. The tuna schools' Continuous Residence Times were generally shorter than Continuous Absence Times (median values between 5 and 7 days, and 9 and 11 days, respectively), in line with the results found by previous studies. Using a regression output, two novel metrics, namely aggregation time and disaggregation time, were estimated to obtain further insight into the symmetry of the aggregation process. Across all oceans, the time it took for the tuna aggregation to depart from the dFADs was not significantly longer than the time it took for the aggregation to form. The value of these results in the context of the "ecological trap" hypothesis is discussed, and further analyses to enrich and make use of this data source are proposed.
Towards an AI-based Early Warning System for Bridge Scour
Aug 22, 2022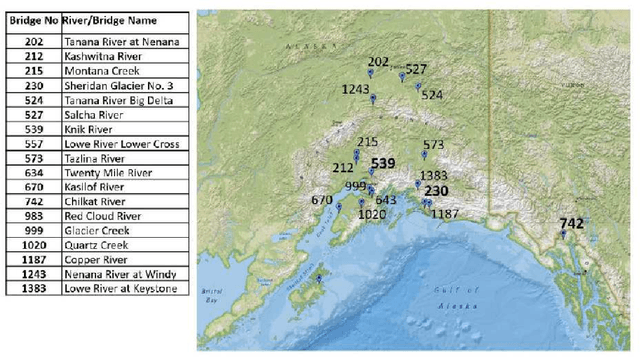
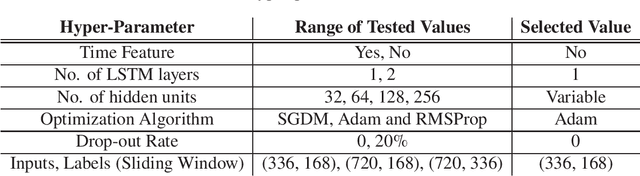
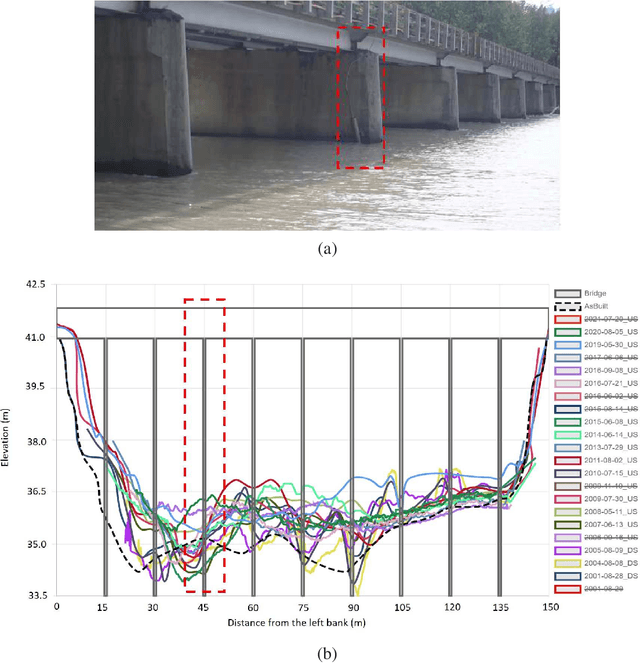

Scour is the number one cause of bridge failure in many parts of the world. Considering the lack of reliability in existing empirical equations for scour depth estimation and the complexity and uncertainty of scour as a physical phenomenon, it is essential to develop more reliable solutions for scour risk assessment. This study introduces a novel AI approach for early forecast of scour based on real-time monitoring data obtained from sonar and stage sensors installed at bridge piers. Long-short Term Memory networks (LSTMs), a prominent Deep Learning algorithm successfully used for time-series forecasting in other fields, were developed and trained using river stage and bed elevation readings for more than 11 years obtained from Alaska scour monitoring program. The capability of the AI models in scour prediction is shown for three case-study bridges. Results show that LSTMs can capture the temporal and seasonal patterns of both flow and river bed variations around bridge piers, through cycles of scour and filling and can provide reasonable predictions of upcoming scour depth as early as seven days in advance. It is expected that the proposed solution can be implemented by transportation authorities for development of emerging AI-based early warning systems, enabling superior bridge scour management.
An Empirical Evaluation of Time-Series Feature Sets
Oct 21, 2021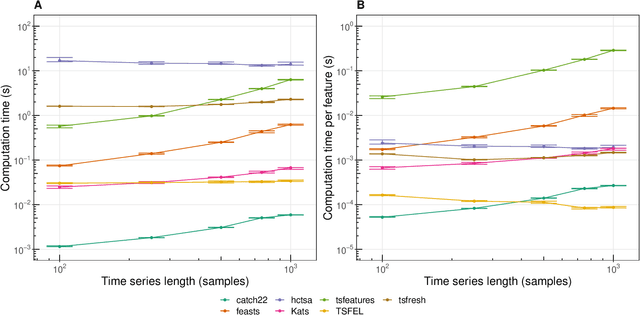
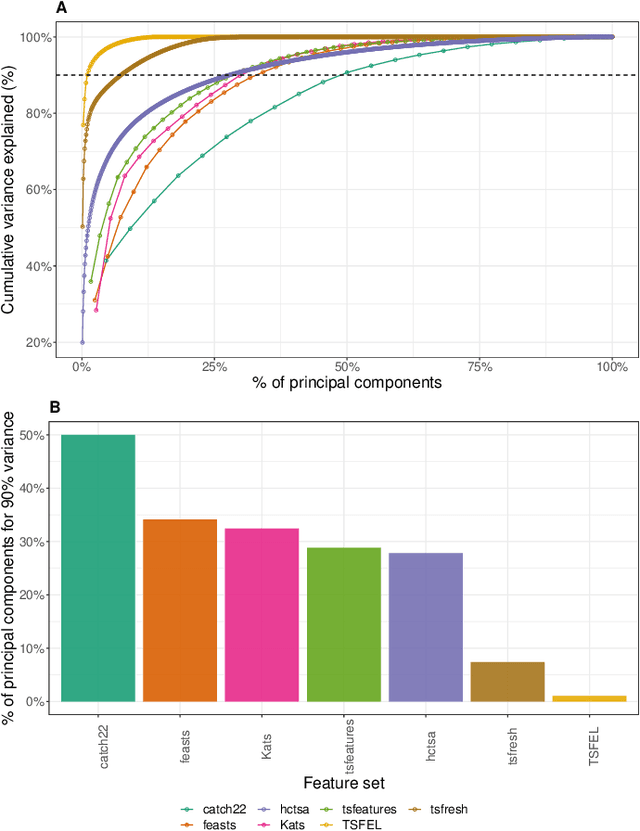
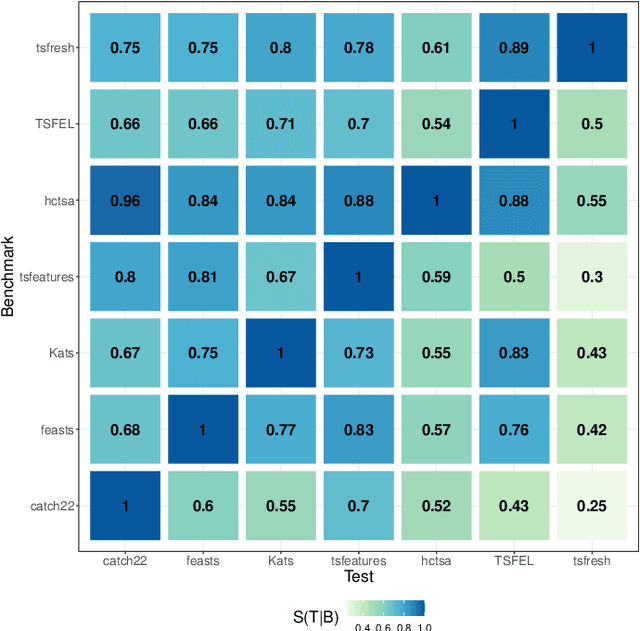
Solving time-series problems with features has been rising in popularity due to the availability of software for feature extraction. Feature-based time-series analysis can now be performed using many different feature sets, including hctsa (7730 features: Matlab), feasts (42 features: R), tsfeatures (63 features: R), Kats (40 features: Python), tsfresh (up to 1558 features: Python), TSFEL (390 features: Python), and the C-coded catch22 (22 features: Matlab, R, Python, and Julia). There is substantial overlap in the types of methods included in these sets (e.g., properties of the autocorrelation function and Fourier power spectrum), but they are yet to be systematically compared. Here we compare these seven sets on computational speed, assess the redundancy of features contained in each, and evaluate the overlap and redundancy between them. We take an empirical approach to feature similarity based on outputs across a diverse set of real-world and simulated time series. We find that feature sets vary across three orders of magnitude in their computation time per feature on a laptop for a 1000-sample series, from the fastest sets catch22 and TSFEL (~0.1ms per feature) to tsfeatures (~3s per feature). Using PCA to evaluate feature redundancy within each set, we find the highest within-set redundancy for TSFEL and tsfresh. For example, in TSFEL, 90% of the variance across 390 features can be captured with just four PCs. Finally, we introduce a metric for quantifying overlap between pairs of feature sets, which indicates substantial overlap. We found that the largest feature set, hctsa, is the most comprehensive, and that tsfresh is the most distinctive, due to its incorporation of many low-level Fourier coefficients. Our results provide empirical understanding of the differences between existing feature sets, information that can be used to better tailor feature sets to their applications.
FoVolNet: Fast Volume Rendering using Foveated Deep Neural Networks
Sep 20, 2022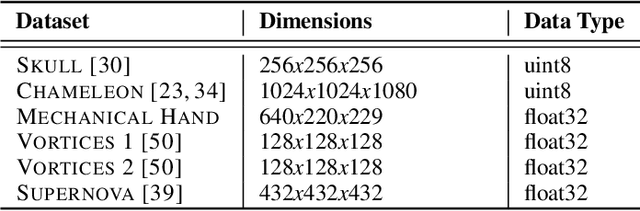



Volume data is found in many important scientific and engineering applications. Rendering this data for visualization at high quality and interactive rates for demanding applications such as virtual reality is still not easily achievable even using professional-grade hardware. We introduce FoVolNet -- a method to significantly increase the performance of volume data visualization. We develop a cost-effective foveated rendering pipeline that sparsely samples a volume around a focal point and reconstructs the full-frame using a deep neural network. Foveated rendering is a technique that prioritizes rendering computations around the user's focal point. This approach leverages properties of the human visual system, thereby saving computational resources when rendering data in the periphery of the user's field of vision. Our reconstruction network combines direct and kernel prediction methods to produce fast, stable, and perceptually convincing output. With a slim design and the use of quantization, our method outperforms state-of-the-art neural reconstruction techniques in both end-to-end frame times and visual quality. We conduct extensive evaluations of the system's rendering performance, inference speed, and perceptual properties, and we provide comparisons to competing neural image reconstruction techniques. Our test results show that FoVolNet consistently achieves significant time saving over conventional rendering while preserving perceptual quality.
Outlier Suppression: Pushing the Limit of Low-bit Transformer Language Models
Sep 27, 2022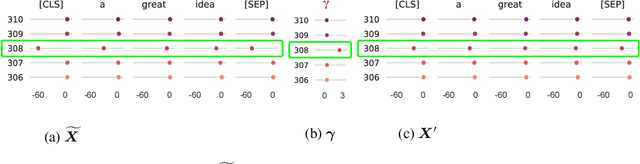

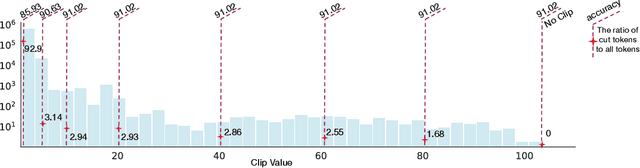

Transformer architecture has become the fundamental element of the widespread natural language processing~(NLP) models. With the trends of large NLP models, the increasing memory and computation costs hinder their efficient deployment on resource-limited devices. Therefore, transformer quantization attracts wide research interest. Recent work recognizes that structured outliers are the critical bottleneck for quantization performance. However, their proposed methods increase the computation overhead and still leave the outliers there. To fundamentally address this problem, this paper delves into the inherent inducement and importance of the outliers. We discover that $\boldsymbol \gamma$ in LayerNorm (LN) acts as a sinful amplifier for the outliers, and the importance of outliers varies greatly where some outliers provided by a few tokens cover a large area but can be clipped sharply without negative impacts. Motivated by these findings, we propose an outlier suppression framework including two components: Gamma Migration and Token-Wise Clipping. The Gamma Migration migrates the outlier amplifier to subsequent modules in an equivalent transformation, contributing to a more quantization-friendly model without any extra burden. The Token-Wise Clipping takes advantage of the large variance of token range and designs a token-wise coarse-to-fine pipeline, obtaining a clipping range with minimal final quantization loss in an efficient way. This framework effectively suppresses the outliers and can be used in a plug-and-play mode. Extensive experiments prove that our framework surpasses the existing works and, for the first time, pushes the 6-bit post-training BERT quantization to the full-precision (FP) level. Our code is available at https://github.com/wimh966/outlier_suppression.
Deep Labeling of fMRI Brain Networks Using Cloud Based Processing
Sep 20, 2022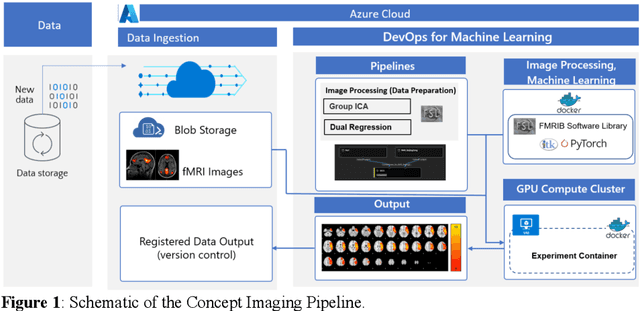
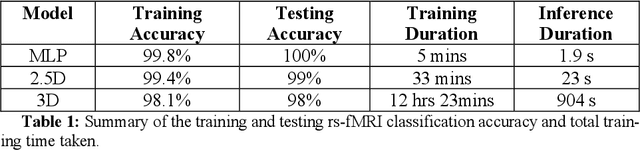

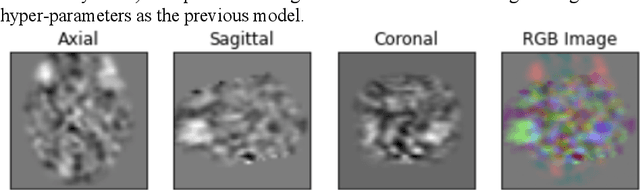
Resting state fMRI is an imaging modality which reveals brain activity localization through signal changes, in what is known as Resting State Networks (RSNs). This technique is gaining popularity in neurosurgical pre-planning to visualize the functional regions and assess regional activity. Labeling of rs-fMRI networks require subject-matter expertise and is time consuming, creating a need for an automated classification algorithm. While the impact of AI in medical diagnosis has shown great progress; deploying and maintaining these in a clinical setting is an unmet need. We propose an end-to-end reproducible pipeline which incorporates image processing of rs-fMRI in a cloud-based workflow while using deep learning to automate the classification of RSNs. We have architected a reproducible Azure Machine Learning cloud-based medical imaging concept pipeline for fMRI analysis integrating the popular FMRIB Software Library (FSL) toolkit. To demonstrate a clinical application using a large dataset, we compare three neural network architectures for classification of deeper RSNs derived from processed rs-fMRI. The three algorithms are: an MLP, a 2D projection-based CNN, and a fully 3D CNN classification networks. Each of the net-works was trained on the rs-fMRI back-projected independent components giving >98% accuracy for each classification method.
Improving GANs with A Dynamic Discriminator
Sep 20, 2022
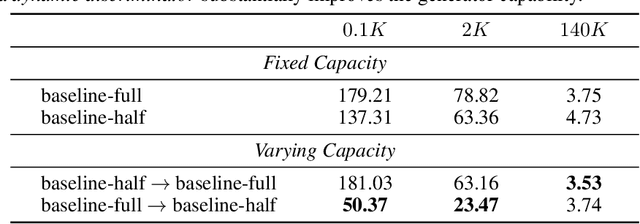

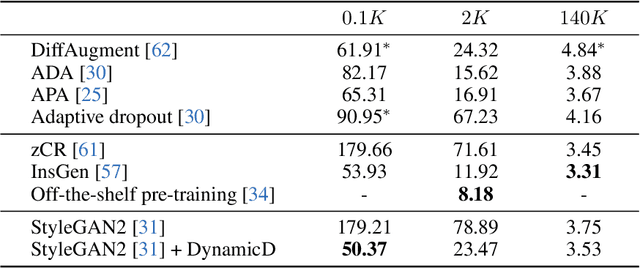
Discriminator plays a vital role in training generative adversarial networks (GANs) via distinguishing real and synthesized samples. While the real data distribution remains the same, the synthesis distribution keeps varying because of the evolving generator, and thus effects a corresponding change to the bi-classification task for the discriminator. We argue that a discriminator with an on-the-fly adjustment on its capacity can better accommodate such a time-varying task. A comprehensive empirical study confirms that the proposed training strategy, termed as DynamicD, improves the synthesis performance without incurring any additional computation cost or training objectives. Two capacity adjusting schemes are developed for training GANs under different data regimes: i) given a sufficient amount of training data, the discriminator benefits from a progressively increased learning capacity, and ii) when the training data is limited, gradually decreasing the layer width mitigates the over-fitting issue of the discriminator. Experiments on both 2D and 3D-aware image synthesis tasks conducted on a range of datasets substantiate the generalizability of our DynamicD as well as its substantial improvement over the baselines. Furthermore, DynamicD is synergistic to other discriminator-improving approaches (including data augmentation, regularizers, and pre-training), and brings continuous performance gain when combined for learning GANs.