 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Biological neurons act as generalization filters in reservoir computing
Oct 06, 2022
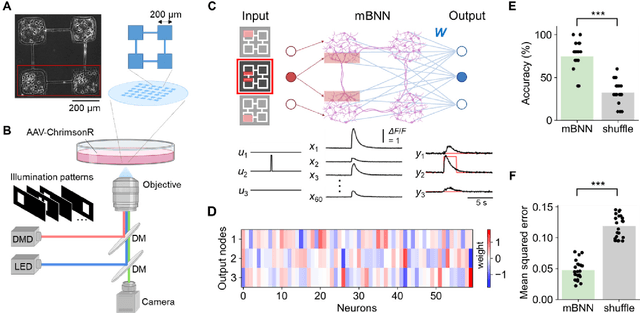
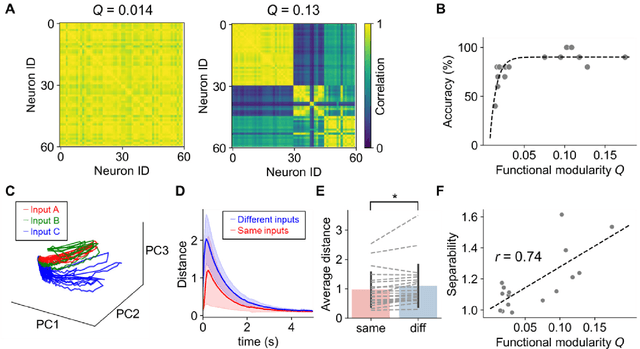
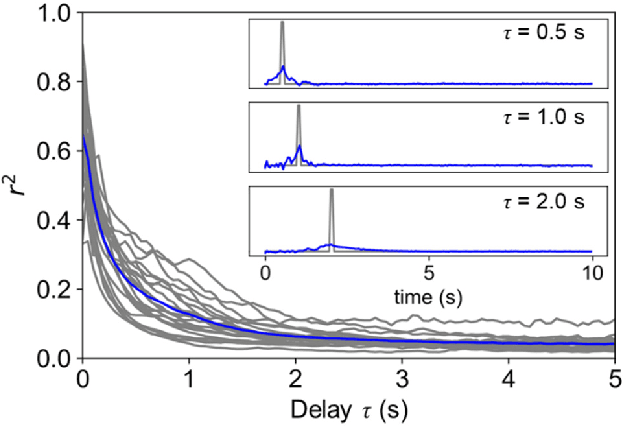
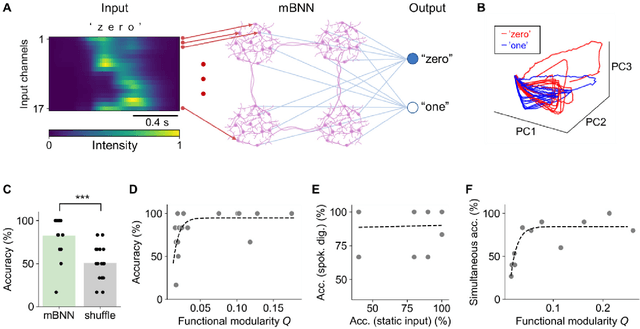
Reservoir computing is a machine learning paradigm that transforms the transient dynamics of high-dimensional nonlinear systems for processing time-series data. Although reservoir computing was initially proposed to model information processing in the mammalian cortex, it remains unclear how the non-random network architecture, such as the modular architecture, in the cortex integrates with the biophysics of living neurons to characterize the function of biological neuronal networks (BNNs). Here, we used optogenetics and fluorescent calcium imaging to record the multicellular responses of cultured BNNs and employed the reservoir computing framework to decode their computational capabilities. Micropatterned substrates were used to embed the modular architecture in the BNNs. We first show that modular BNNs can be used to classify static input patterns with a linear decoder and that the modularity of the BNNs positively correlates with the classification accuracy. We then used a timer task to verify that BNNs possess a short-term memory of ~1 s and finally show that this property can be exploited for spoken digit classification. Interestingly, BNN-based reservoirs allow transfer learning, wherein a network trained on one dataset can be used to classify separate datasets of the same category. Such classification was not possible when the input patterns were directly decoded by a linear decoder, suggesting that BNNs act as a generalization filter to improve reservoir computing performance. Our findings pave the way toward a mechanistic understanding of information processing within BNNs and, simultaneously, build future expectations toward the realization of physical reservoir computing systems based on BNNs.
Information Theoretic Measures of Causal Influences during Transient Neural Events
Sep 15, 2022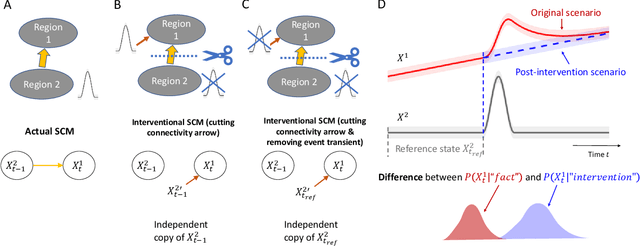
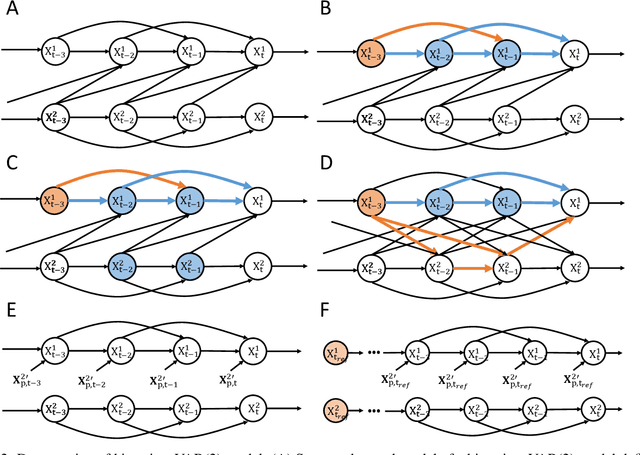
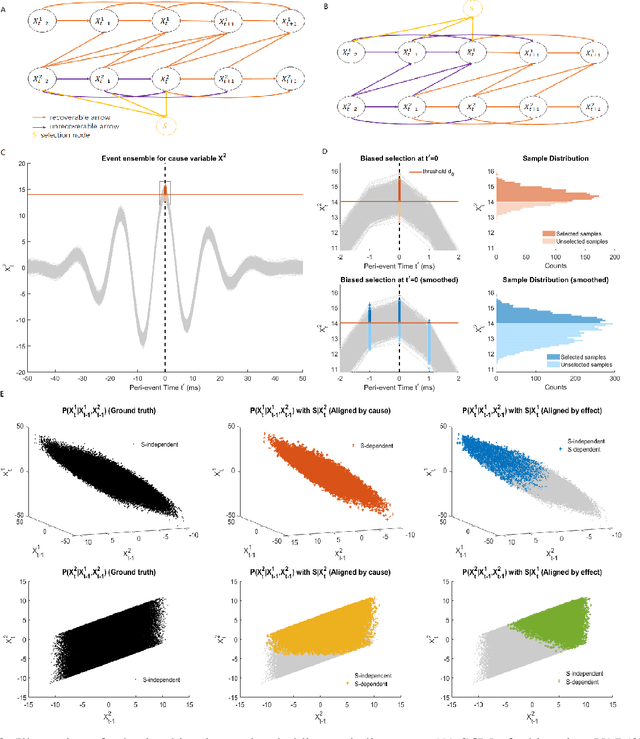
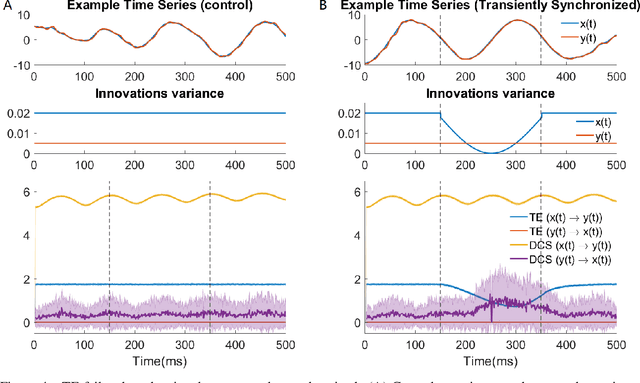
Transient phenomena play a key role in coordinating brain activity at multiple scales, however,their underlying mechanisms remain largely unknown. A key challenge for neural data science is thus to characterize the network interactions at play during these events. Using the formalism of Structural Causal Models and their graphical representation, we investigate the theoretical and empirical properties of Information Theory based causal strength measures in the context of recurring spontaneous transient events. After showing the limitations of Transfer Entropy and Dynamic Causal Strength in such a setting, we introduce a novel measure, relative Dynamic Causal Strength, and provide theoretical and empirical support for its benefits. These methods are applied to simulated and experimentally recorded neural time series, and provide results in agreement with our current understanding of the underlying brain circuits.
AirTrack: Onboard Deep Learning Framework for Long-Range Aircraft Detection and Tracking
Sep 26, 2022
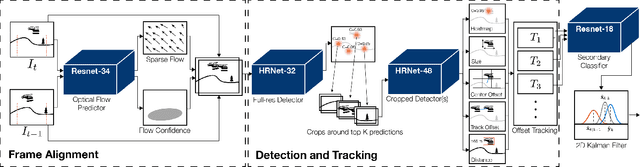

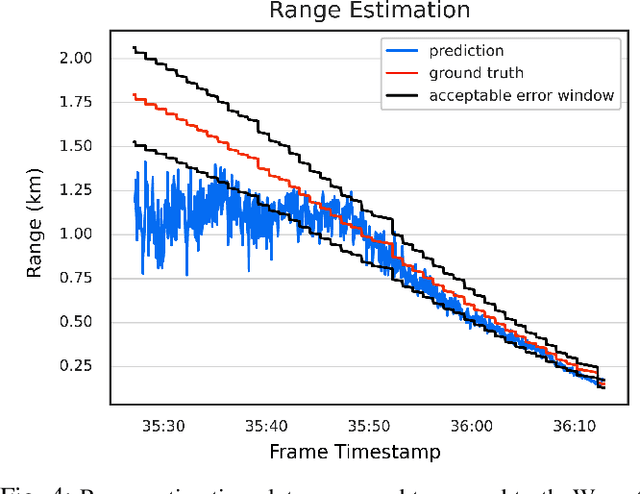
Detect-and-Avoid (DAA) capabilities are critical for safe operations of unmanned aircraft systems (UAS). This paper introduces, AirTrack, a real-time vision-only detect and tracking framework that respects the size, weight, and power (SWaP) constraints of sUAS systems. Given the low Signal-to-Noise ratios (SNR) of far away aircraft, we propose using full resolution images in a deep learning framework that aligns successive images to remove ego-motion. The aligned images are then used downstream in cascaded primary and secondary classifiers to improve detection and tracking performance on multiple metrics. We show that AirTrack outperforms state-of-the art baselines on the Amazon Airborne Object Tracking (AOT) Dataset. Multiple real world flight tests with a Cessna 172 interacting with general aviation traffic and additional near-collision flight tests with a Bell helicopter flying towards a UAS in a controlled setting showcase that the proposed approach satisfies the newly introduced ASTM F3442/F3442M standard for DAA. Empirical evaluations show that our system has a probability of track of more than 95% up to a range of 700m. Video available at https://youtu.be/H3lL_Wjxjpw .
Transformer Networks for Predictive Group Elevator Control
Aug 15, 2022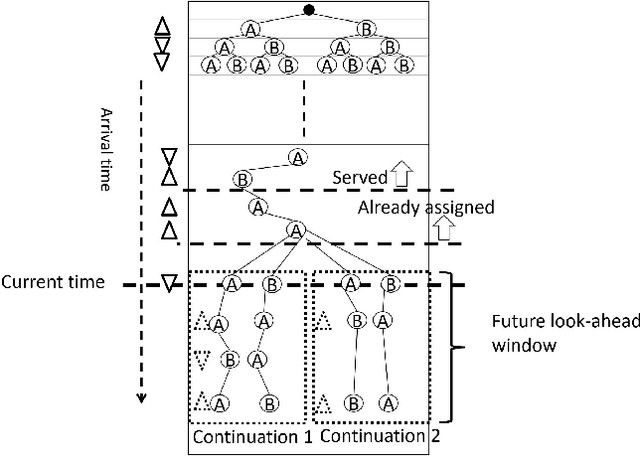
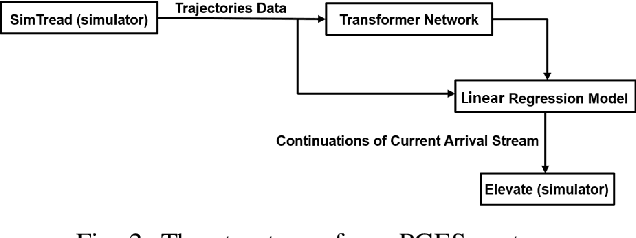
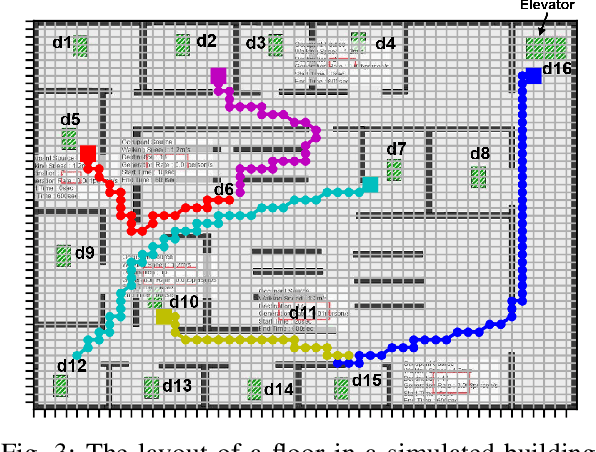
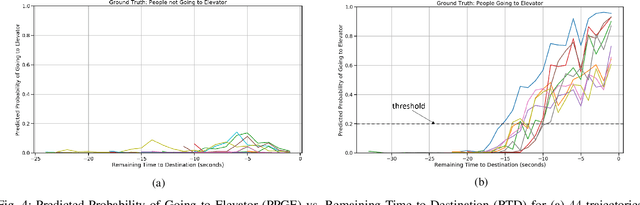
We propose a Predictive Group Elevator Scheduler by using predictive information of passengers arrivals from a Transformer based destination predictor and a linear regression model that predicts remaining time to destinations. Through extensive empirical evaluation, we find that the savings of Average Waiting Time (AWT) could be as high as above 50% for light arrival streams and around 15% for medium arrival streams in afternoon down-peak traffic regimes. Such results can be obtained after carefully setting the Predicted Probability of Going to Elevator (PPGE) threshold, thus avoiding a majority of false predictions for people heading to the elevator, while achieving as high as 80% of true predictive elevator landings as early as after having seen only 60% of the whole trajectory of a passenger.
Doubly Fair Dynamic Pricing
Sep 23, 2022We study the problem of online dynamic pricing with two types of fairness constraints: a "procedural fairness" which requires the proposed prices to be equal in expectation among different groups, and a "substantive fairness" which requires the accepted prices to be equal in expectation among different groups. A policy that is simultaneously procedural and substantive fair is referred to as "doubly fair". We show that a doubly fair policy must be random to have higher revenue than the best trivial policy that assigns the same price to different groups. In a two-group setting, we propose an online learning algorithm for the 2-group pricing problems that achieves $\tilde{O}(\sqrt{T})$ regret, zero procedural unfairness and $\tilde{O}(\sqrt{T})$ substantive unfairness over $T$ rounds of learning. We also prove two lower bounds showing that these results on regret and unfairness are both information-theoretically optimal up to iterated logarithmic factors. To the best of our knowledge, this is the first dynamic pricing algorithm that learns to price while satisfying two fairness constraints at the same time.
Superpixel Generation and Clustering for Weakly Supervised Brain Tumor Segmentation in MR Images
Sep 20, 2022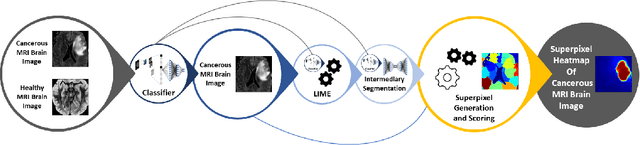
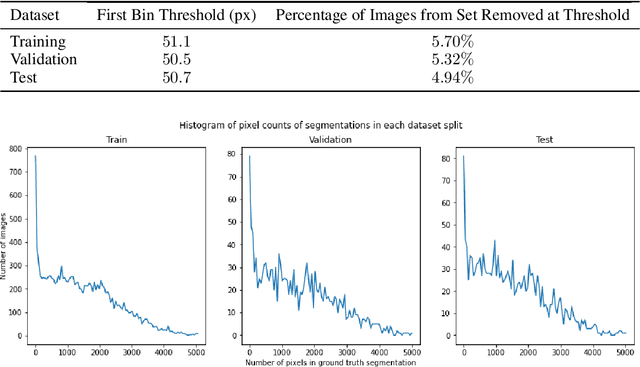


Training Machine Learning (ML) models to segment tumors and other anomalies in medical images is an increasingly popular area of research but generally requires manually annotated ground truth segmentations which necessitates significant time and resources to create. This work proposes a pipeline of ML models that utilize binary classification labels, which can be easily acquired, to segment ROIs without requiring ground truth annotations. We used 2D slices of Magnetic Resonance Imaging (MRI) brain scans from the Multimodal Brain Tumor Segmentation Challenge (BraTS) 2020 dataset and labels indicating the presence of high-grade glioma (HGG) tumors to train the pipeline. Our pipeline also introduces a novel variation of deep learning-based superpixel generation, which enables training guided by clustered superpixels and simultaneously trains a superpixel clustering model. On our test set, our pipeline's segmentations achieved a Dice coefficient of 61.7%, which is a substantial improvement over the 42.8% Dice coefficient acquired when the popular Local Interpretable Model-Agnostic Explanations (LIME) method was used.
Diabetic foot ulcers monitoring by employing super resolution and noise reduction deep learning techniques
Sep 20, 2022
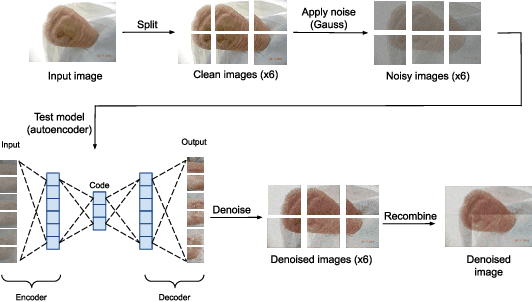

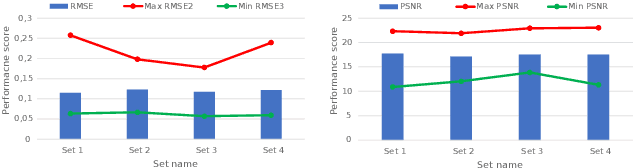
Diabetic foot ulcers (DFUs) constitute a serious complication for people with diabetes. The care of DFU patients can be substantially improved through self-management, in order to achieve early-diagnosis, ulcer prevention, and complications management in existing ulcers. In this paper, we investigate two categories of image-to-image translation techniques (ItITT), which will support decision making and monitoring of diabetic foot ulcers: noise reduction and super-resolution. In the former case, we investigated the capabilities on noise removal, for convolutional neural network stacked-autoencoders (CNN-SAE). CNN-SAE was tested on RGB images, induced with Gaussian noise. The latter scenario involves the deployment of four deep learning super-resolution models. The performance of all models, for both scenarios, was evaluated in terms of execution time and perceived quality. Results indicate that applied techniques consist a viable and easy to implement alternative that should be used by any system designed for DFU monitoring.
Modelling Patient Trajectories Using Multimodal Information
Sep 09, 2022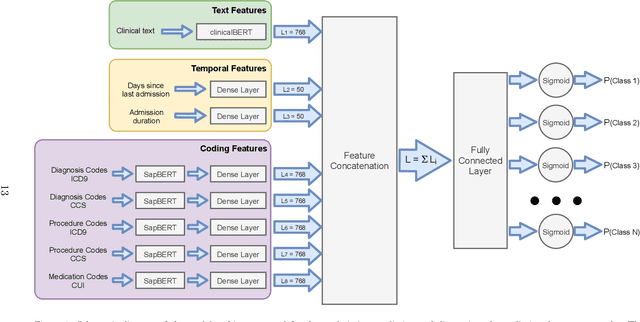
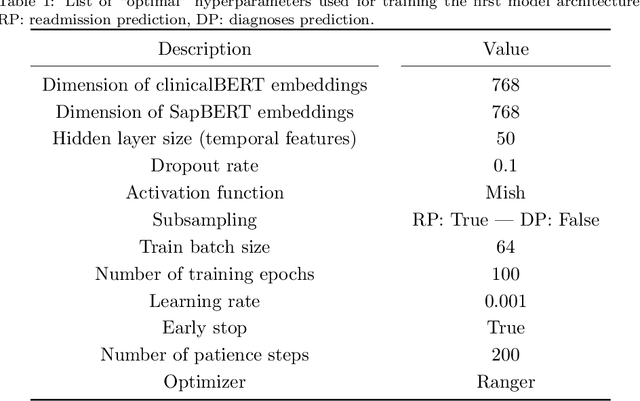
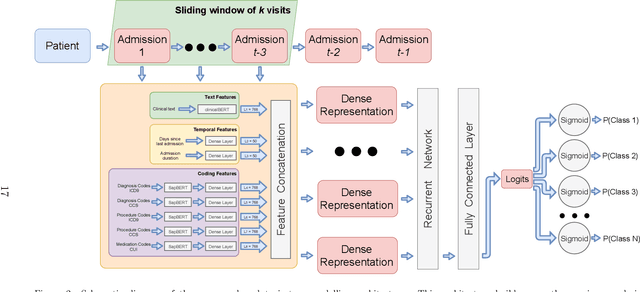

Electronic Health Records (EHRs) aggregate diverse information at the patient level, holding a trajectory representative of the evolution of the patient health status throughout time. Although this information provides context and can be leveraged by physicians to monitor patient health and make more accurate prognoses/diagnoses, patient records can contain information from very long time spans, which combined with the rapid generation rate of medical data makes clinical decision making more complex. Patient trajectory modelling can assist by exploring existing information in a scalable manner, and can contribute in augmenting health care quality by fostering preventive medicine practices. We propose a solution to model patient trajectories that combines different types of information and considers the temporal aspect of clinical data. This solution leverages two different architectures: one supporting flexible sets of input features, to convert patient admissions into dense representations; and a second exploring extracted admission representations in a recurrent-based architecture, where patient trajectories are processed in sub-sequences using a sliding window mechanism. The developed solution was evaluated on two different clinical outcomes, unexpected patient readmission and disease progression, using the publicly available MIMIC-III clinical database. The results obtained demonstrate the potential of the first architecture to model readmission and diagnoses prediction using single patient admissions. While information from clinical text did not show the discriminative power observed in other existing works, this may be explained by the need to fine-tune the clinicalBERT model. Finally, we demonstrate the potential of the sequence-based architecture using a sliding window mechanism to represent the input data, attaining comparable performances to other existing solutions.
Active Privacy-Utility Trade-off Against Inference in Time-Series Data Sharing
Feb 11, 2022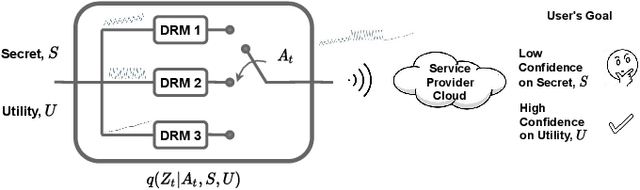
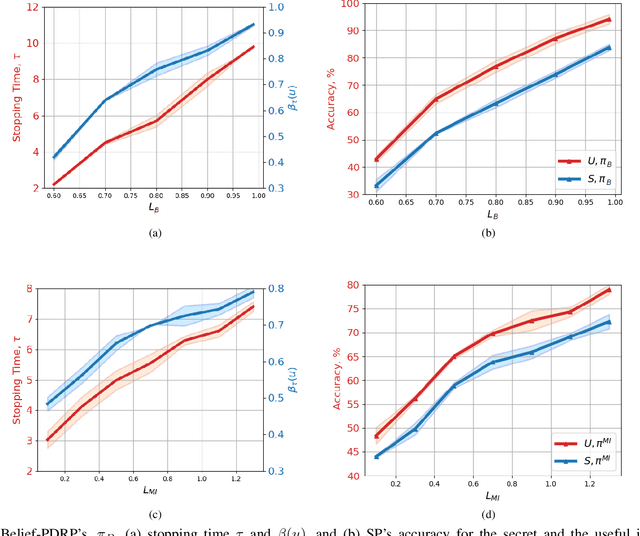
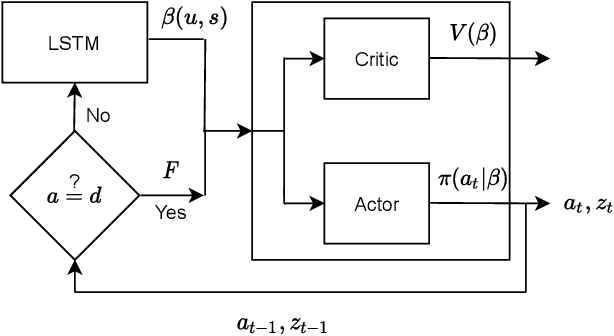
Internet of things (IoT) devices, such as smart meters, smart speakers and activity monitors, have become highly popular thanks to the services they offer. However, in addition to their many benefits, they raise privacy concerns since they share fine-grained time-series user data with untrusted third parties. In this work, we consider a user releasing her data containing personal information in return of a service from an honest-but-curious service provider (SP). We model user's personal information as two correlated random variables (r.v.'s), one of them, called the secret variable, is to be kept private, while the other, called the useful variable, is to be disclosed for utility. We consider active sequential data release, where at each time step the user chooses from among a finite set of release mechanisms, each revealing some information about the user's personal information, i.e., the true values of the r.v.'s, albeit with different statistics. The user manages data release in an online fashion such that the maximum amount of information is revealed about the latent useful variable as quickly as possible, while the confidence for the sensitive variable is kept below a predefined level. For privacy measure, we consider both the probability of correctly detecting the true value of the secret and the mutual information (MI) between the secret and the released data. We formulate both problems as partially observable Markov decision processes (POMDPs), and numerically solve them by advantage actor-critic (A2C) deep reinforcement learning (DRL). We evaluate the privacy-utility trade-off (PUT) of the proposed policies on both the synthetic data and smoking activity dataset, and show their validity by testing the activity detection accuracy of the SP modeled by a long short-term memory (LSTM) neural network.
De-Sequentialized Monte Carlo: a parallel-in-time particle smoother
Feb 04, 2022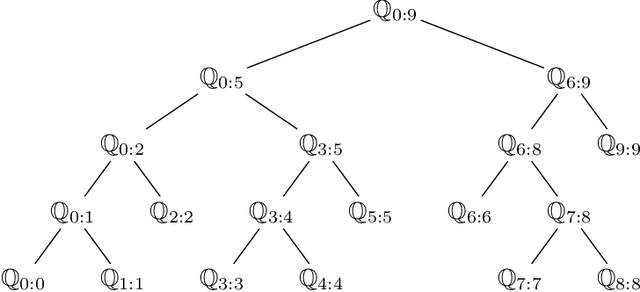
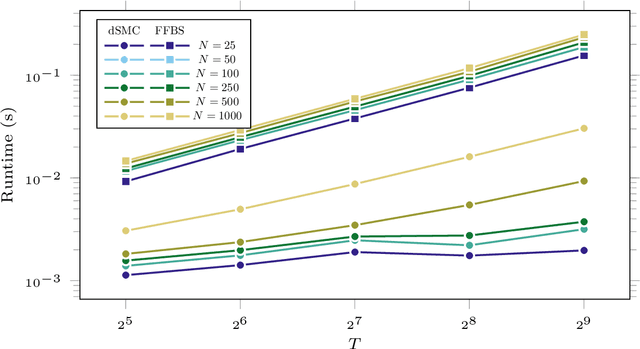
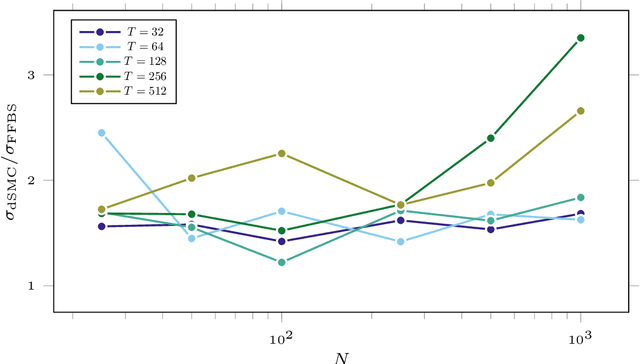
Particle smoothers are SMC (Sequential Monte Carlo) algorithms designed to approximate the joint distribution of the states given observations from a state-space model. We propose dSMC (de-Sequentialized Monte Carlo), a new particle smoother that is able to process $T$ observations in $\mathcal{O}(\log T)$ time on parallel architecture. This compares favourably with standard particle smoothers, the complexity of which is linear in $T$. We derive $\mathcal{L}_p$ convergence results for dSMC, with an explicit upper bound, polynomial in $T$. We then discuss how to reduce the variance of the smoothing estimates computed by dSMC by (i) designing good proposal distributions for sampling the particles at the initialization of the algorithm, as well as by (ii) using lazy resampling to increase the number of particles used in dSMC. Finally, we design a particle Gibbs sampler based on dSMC, which is able to perform parameter inference in a state-space model at a $\mathcal{O}(\log(T))$ cost on parallel hardware.