 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Transformer Meets Boundary Value Inverse Problems
Sep 29, 2022
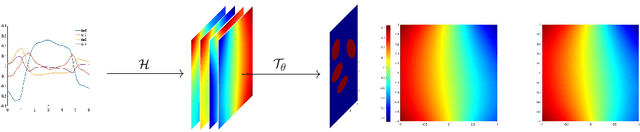


A Transformer-based deep direct sampling method is proposed for solving a class of boundary value inverse problem. A real-time reconstruction is achieved by evaluating the learned inverse operator between carefully designed data and the reconstructed images. An effort is made to give a case study for a fundamental and critical question: whether and how one can benefit from the theoretical structure of a mathematical problem to develop task-oriented and structure-conforming deep neural network? Inspired by direct sampling methods for inverse problems, the 1D boundary data are preprocessed by a partial differential equation-based feature map to yield 2D harmonic extensions in different frequency input channels. Then, by introducing learnable non-local kernel, the approximation of direct sampling is recast to a modified attention mechanism. The proposed method is then applied to electrical impedance tomography, a well-known severely ill-posed nonlinear inverse problem. The new method achieves superior accuracy over its predecessors and contemporary operator learners, as well as shows robustness with respect to noise. This research shall strengthen the insights that the attention mechanism, despite being invented for natural language processing tasks, offers great flexibility to be modified in conformity with the a priori mathematical knowledge, which ultimately leads to the design of more physics-compatible neural architectures.
Domain Shift-oriented Machine Anomalous Sound Detection Model Based on Self-Supervised Learning
Aug 31, 2022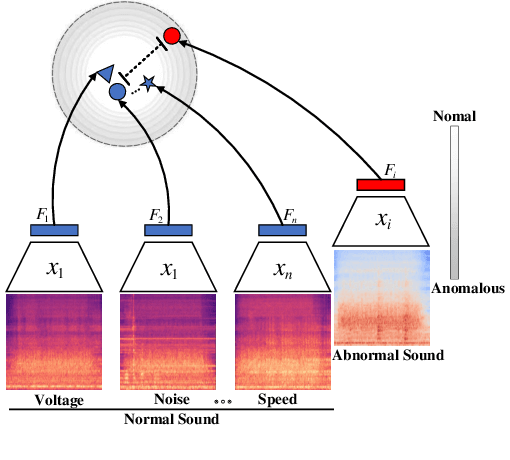
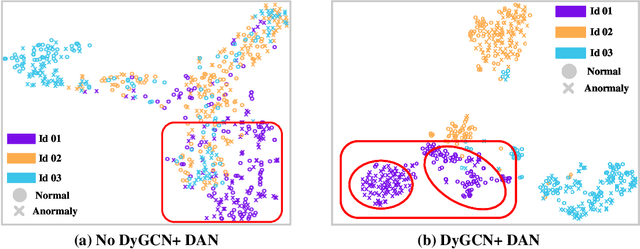
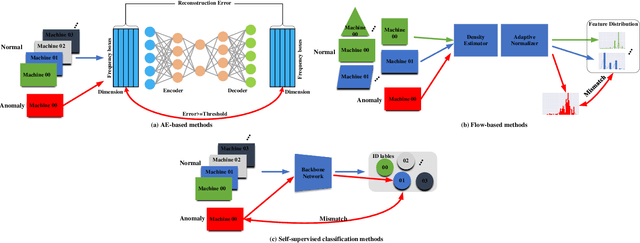
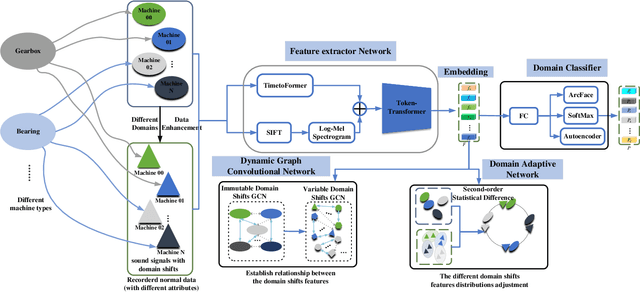
Thanks to the development of deep learning, research on machine anomalous sound detection based on self-supervised learning has made remarkable achievements. However, there are differences in the acoustic characteristics of the test set and the training set under different operating conditions of the same machine (domain shifts). It is challenging for the existing detection methods to learn the domain shifts features stably with low computation overhead. To address these problems, we propose a domain shift-oriented machine anomalous sound detection model based on self-supervised learning (TranSelf-DyGCN) in this paper. Firstly, we design a time-frequency domain feature modeling network to capture global and local spatial and time-domain features, thus improving the stability of machine anomalous sound detection stability under domain shifts. Then, we adopt a Dynamic Graph Convolutional Network (DyGCN) to model the inter-dependence relationship between domain shifts features, enabling the model to perceive domain shifts features efficiently. Finally, we use a Domain Adaptive Network (DAN) to compensate for the performance decrease caused by domain shifts, making the model adapt to anomalous sound better in the self-supervised environment. The performance of the suggested model is validated on DCASE 2020 task 2 and DCASE 2022 task 2.
D-ITAGS: A Dynamic Interleaved Approach to Resilient Task Allocation, Scheduling, and Motion Planning
Sep 27, 2022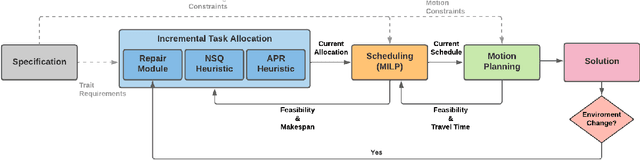
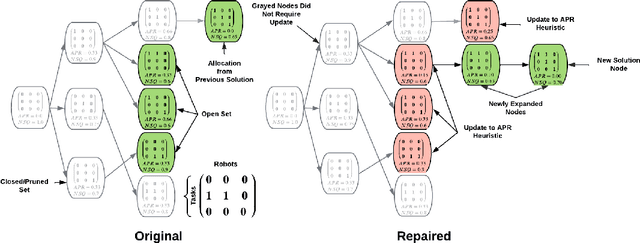

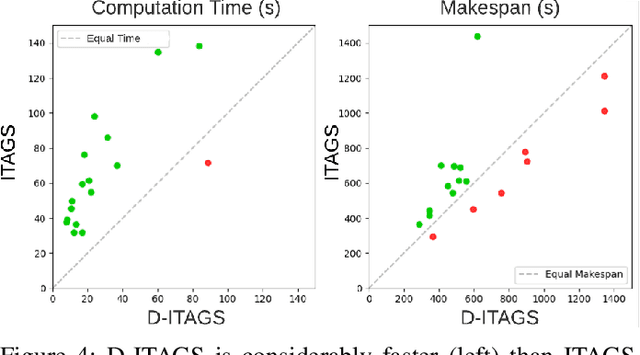
Complex, multi-objective missions require the coordination of heterogeneous robots at multiple inter-connected levels, such as coalition formation, scheduling, and motion planning. This challenge is exacerbated by dynamic changes, such as sensor and actuator failures, communication loss, and unexpected delays. We introduce Dynamic Iterative Task Allocation Graph Search (D-ITAGS) to \textit{simultaneously} address coalition formation, scheduling, and motion planning in dynamic settings involving heterogeneous teams. D-ITAGS achieves resilience via two key characteristics: i) interleaved execution, and ii) targeted repair. \textit{Interleaved execution} enables an effective search for solutions at each layer while avoiding incompatibility with other layers. \textit{Targeted repair} identifies and repairs parts of the existing solution impacted by a given disruption, while conserving the rest. In addition to algorithmic contributions, we provide theoretical insights into the inherent trade-off between time and resource optimality in these settings and derive meaningful bounds on schedule suboptimality. Our experiments reveal that i) D-ITAGS is significantly faster than recomputation from scratch in dynamic settings, with little to no loss in solution quality, and ii) the theoretical suboptimality bounds consistently hold in practice.
Comparative Study of Q-Learning and NeuroEvolution of Augmenting Topologies for Self Driving Agents
Sep 19, 2022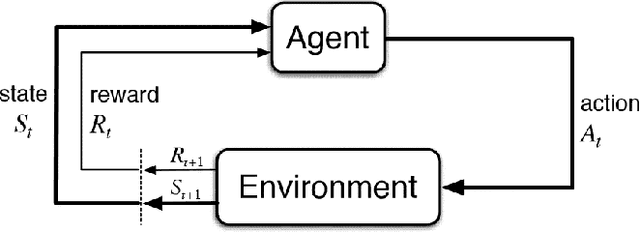
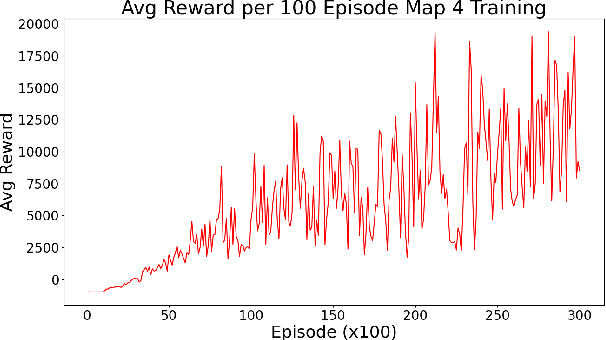
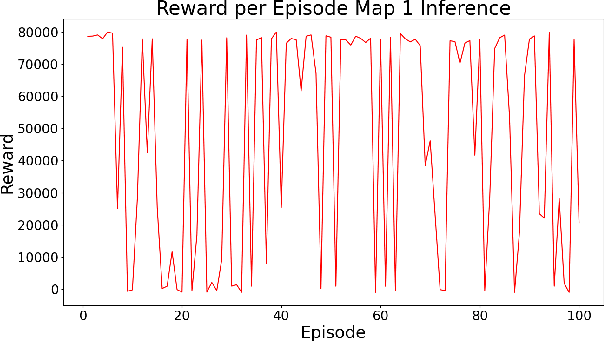
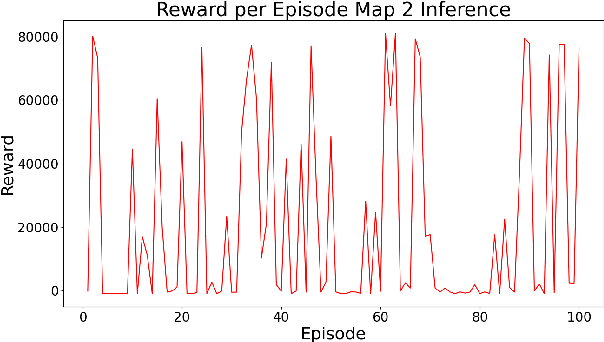
Autonomous driving vehicles have been of keen interest ever since automation of various tasks started. Humans are prone to exhaustion and have a slow response time on the road, and on top of that driving is already quite a dangerous task with around 1.35 million road traffic incident deaths each year. It is expected that autonomous driving can reduce the number of driving accidents around the world which is why this problem has been of keen interest for researchers. Currently, self-driving vehicles use different algorithms for various sub-problems in making the vehicle autonomous. We will focus reinforcement learning algorithms, more specifically Q-learning algorithms and NeuroEvolution of Augment Topologies (NEAT), a combination of evolutionary algorithms and artificial neural networks, to train a model agent to learn how to drive on a given path. This paper will focus on drawing a comparison between the two aforementioned algorithms.
EEG-based Image Feature Extraction for Visual Classification using Deep Learning
Sep 27, 2022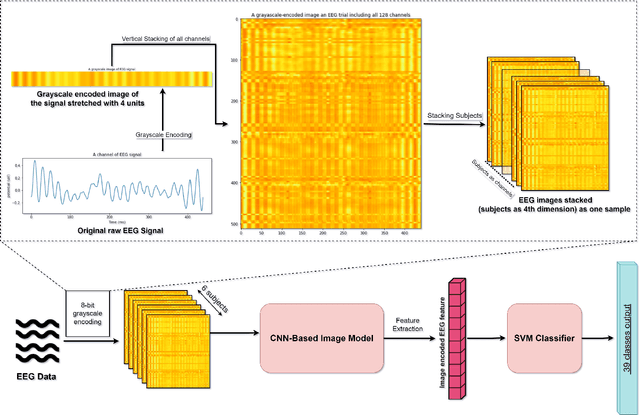
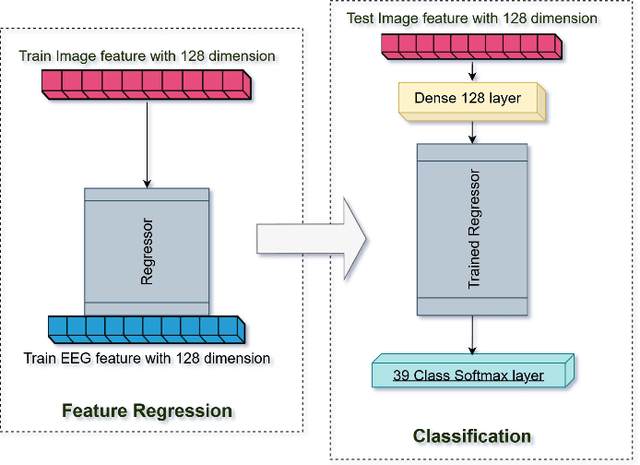
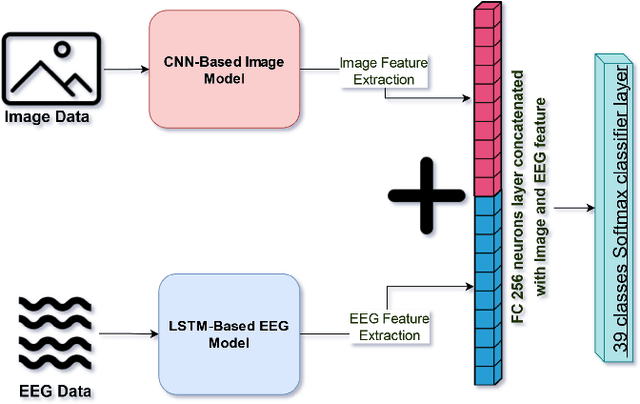
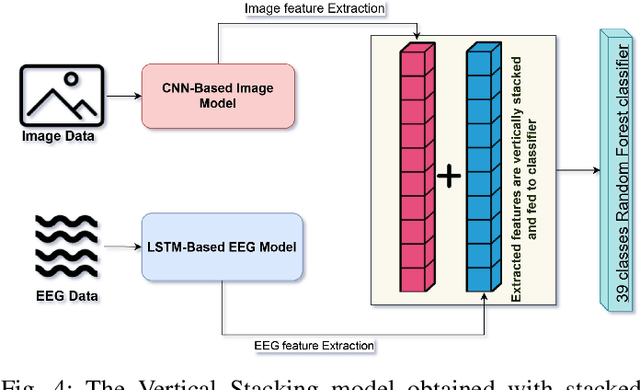
While capable of segregating visual data, humans take time to examine a single piece, let alone thousands or millions of samples. The deep learning models efficiently process sizeable information with the help of modern-day computing. However, their questionable decision-making process has raised considerable concerns. Recent studies have identified a new approach to extract image features from EEG signals and combine them with standard image features. These approaches make deep learning models more interpretable and also enables faster converging of models with fewer samples. Inspired by recent studies, we developed an efficient way of encoding EEG signals as images to facilitate a more subtle understanding of brain signals with deep learning models. Using two variations in such encoding methods, we classified the encoded EEG signals corresponding to 39 image classes with a benchmark accuracy of 70% on the layered dataset of six subjects, which is significantly higher than the existing work. Our image classification approach with combined EEG features achieved an accuracy of 82% compared to the slightly better accuracy of a pure deep learning approach; nevertheless, it demonstrates the viability of the theory.
Argus++: Robust Real-time Activity Detection for Unconstrained Video Streams with Overlapping Cube Proposals
Jan 14, 2022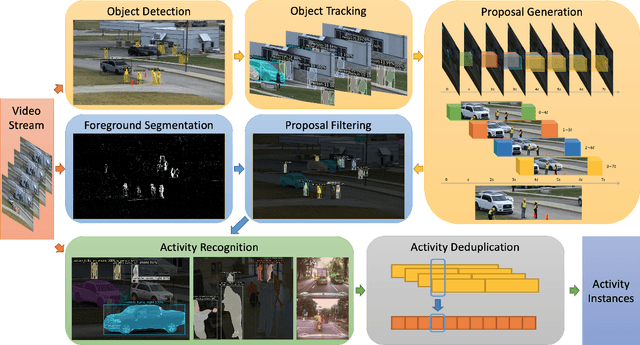
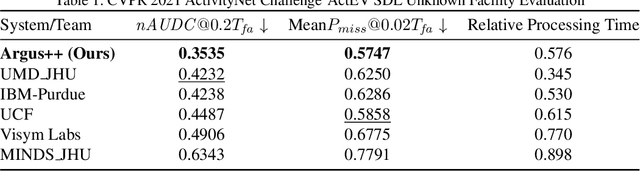

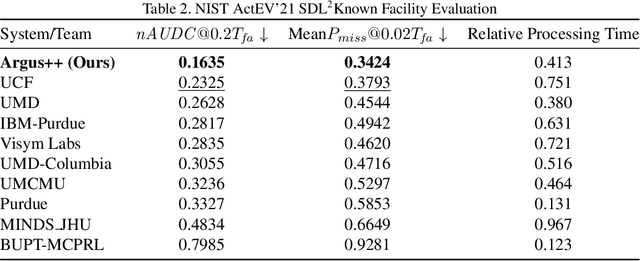
Activity detection is one of the attractive computer vision tasks to exploit the video streams captured by widely installed cameras. Although achieving impressive performance, conventional activity detection algorithms are usually designed under certain constraints, such as using trimmed and/or object-centered video clips as inputs. Therefore, they failed to deal with the multi-scale multi-instance cases in real-world unconstrained video streams, which are untrimmed and have large field-of-views. Real-time requirements for streaming analysis also mark brute force expansion of them unfeasible. To overcome these issues, we propose Argus++, a robust real-time activity detection system for analyzing unconstrained video streams. The design of Argus++ introduces overlapping spatio-temporal cubes as an intermediate concept of activity proposals to ensure coverage and completeness of activity detection through over-sampling. The overall system is optimized for real-time processing on standalone consumer-level hardware. Extensive experiments on different surveillance and driving scenarios demonstrated its superior performance in a series of activity detection benchmarks, including CVPR ActivityNet ActEV 2021, NIST ActEV SDL UF/KF, TRECVID ActEV 2020/2021, and ICCV ROAD 2021.
Uncertainty estimations methods for a deep learning model to aid in clinical decision-making -- a clinician's perspective
Oct 02, 2022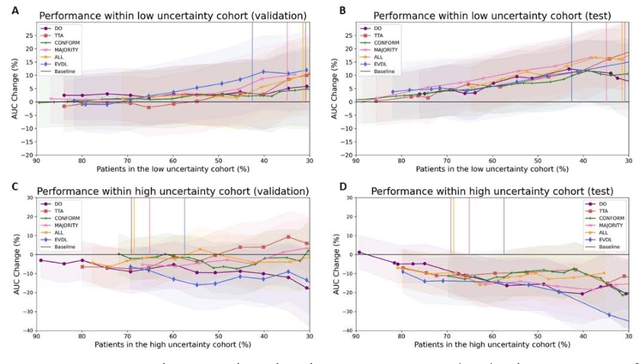
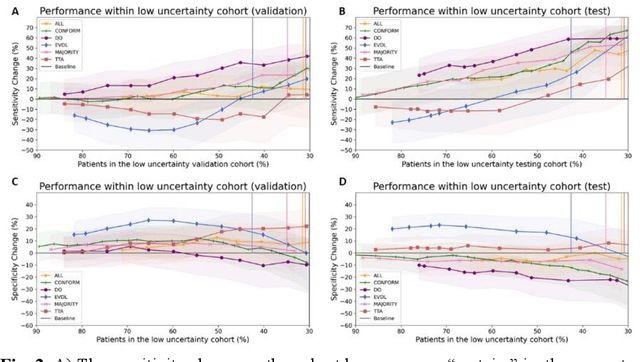
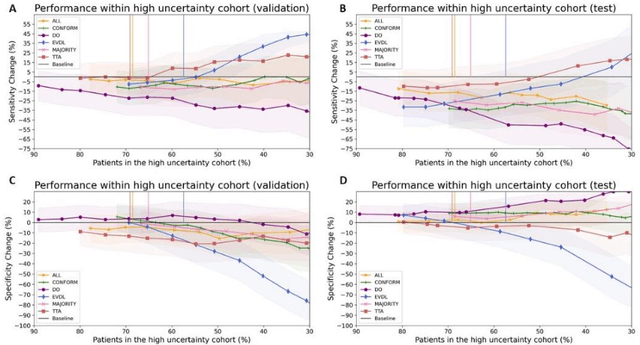
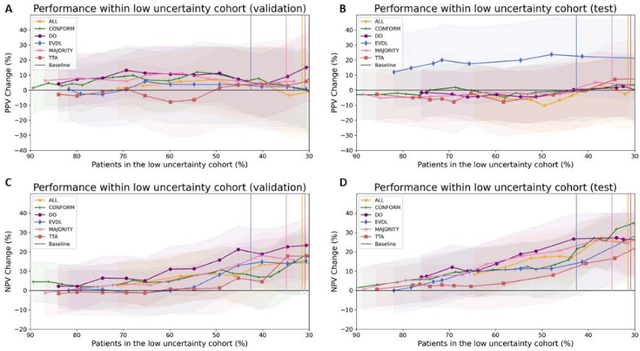
Prediction uncertainty estimation has clinical significance as it can potentially quantify prediction reliability. Clinicians may trust 'blackbox' models more if robust reliability information is available, which may lead to more models being adopted into clinical practice. There are several deep learning-inspired uncertainty estimation techniques, but few are implemented on medical datasets -- fewer on single institutional datasets/models. We sought to compare dropout variational inference (DO), test-time augmentation (TTA), conformal predictions, and single deterministic methods for estimating uncertainty using our model trained to predict feeding tube placement for 271 head and neck cancer patients treated with radiation. We compared the area under the curve (AUC), sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV) trends for each method at various cutoffs that sought to stratify patients into 'certain' and 'uncertain' cohorts. These cutoffs were obtained by calculating the percentile "uncertainty" within the validation cohort and applied to the testing cohort. Broadly, the AUC, sensitivity, and NPV increased as the predictions were more 'certain' -- i.e., lower uncertainty estimates. However, when a majority vote (implementing 2/3 criteria: DO, TTA, conformal predictions) or a stricter approach (3/3 criteria) were used, AUC, sensitivity, and NPV improved without a notable loss in specificity or PPV. Especially for smaller, single institutional datasets, it may be important to evaluate multiple estimations techniques before incorporating a model into clinical practice.
Outage Probability Analysis of HARQ-Aided Terahertz Communications
Sep 24, 2022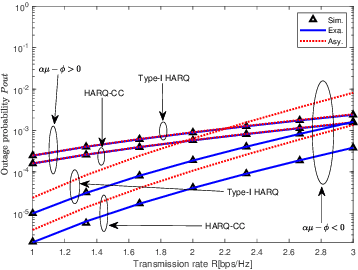
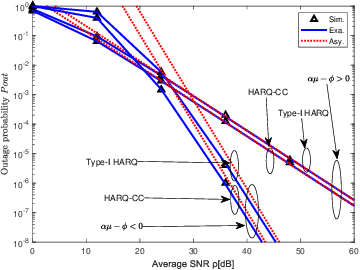
Although terahertz (THz) communications can provide mobile broadband services, it usually has a large path loss and is vulnerable to antenna misalignment. This significantly degrades the reception reliability. To address this issue, the hybrid automatic repeat request (HARQ) is proposed to further enhance the reliability of THz communications. This paper provides an in-depth investigation on the outage performance of two different types of HARQ-aided THz communications, including Type-I HARQ and HARQ with chase combining (HARQ-CC). Moreover, the effects of both fading and stochastic antenna misalignment are considered in this paper. The exact outage probabilities of HARQ-aided THz communications are derived in closed-form, with which the asymptotic outage analysis is enabled to explore helpful insights. In particular, it is revealed that full time diversity can be achieved by using HARQ assisted schemes. Besides, the HARQ-CC-aided scheme performs better than the Type-I HARQ-aided one due to its high diversity combining gain. The analytical results are eventually validated via Monte-Carlo simulations.
Time Series Analysis of Blockchain-Based Cryptocurrency Price Changes
Feb 19, 2022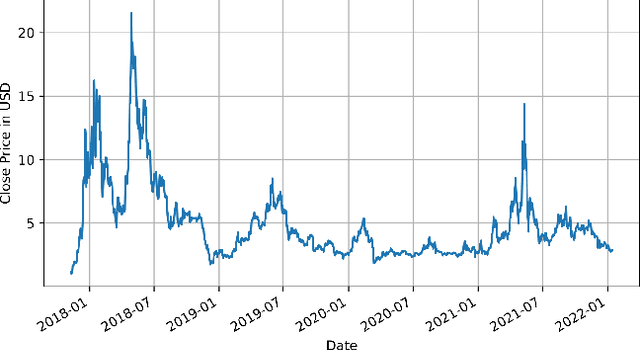
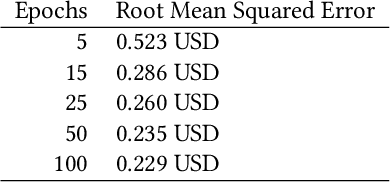
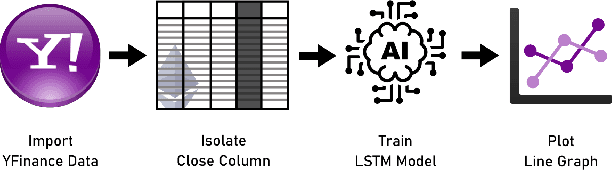

In this paper we apply neural networks and Artificial Intelligence (AI) to historical records of high-risk cryptocurrency coins to train a prediction model that guesses their price. This paper's code contains Jupyter notebooks, one of which outputs a timeseries graph of any cryptocurrency price once a CSV file of the historical data is inputted into the program. Another Jupyter notebook trains an LSTM, or a long short-term memory model, to predict a cryptocurrency's closing price. The LSTM is fed the close price, which is the price that the currency has at the end of the day, so it can learn from those values. The notebook creates two sets: a training set and a test set to assess the accuracy of the results. The data is then normalized using manual min-max scaling so that the model does not experience any bias; this also enhances the performance of the model. Then, the model is trained using three layers -- an LSTM, dropout, and dense layer-minimizing the loss through 50 epochs of training; from this training, a recurrent neural network (RNN) is produced and fitted to the training set. Additionally, a graph of the loss over each epoch is produced, with the loss minimizing over time. Finally, the notebook plots a line graph of the actual currency price in red and the predicted price in blue. The process is then repeated for several more cryptocurrencies to compare prediction models. The parameters for the LSTM, such as number of epochs and batch size, are tweaked to try and minimize the root mean square error.
Untargeted Backdoor Watermark: Towards Harmless and Stealthy Dataset Copyright Protection
Sep 27, 2022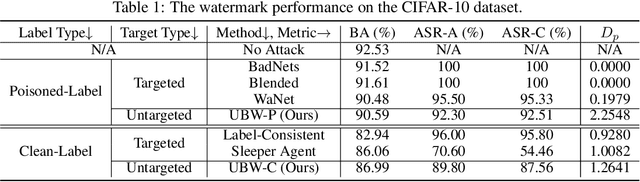


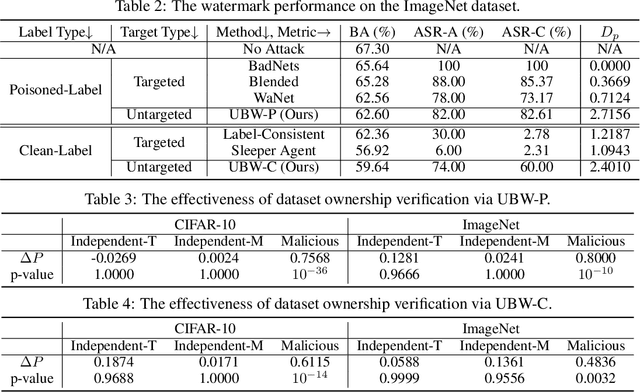
Deep neural networks (DNNs) have demonstrated their superiority in practice. Arguably, the rapid development of DNNs is largely benefited from high-quality (open-sourced) datasets, based on which researchers and developers can easily evaluate and improve their learning methods. Since the data collection is usually time-consuming or even expensive, how to protect their copyrights is of great significance and worth further exploration. In this paper, we revisit dataset ownership verification. We find that existing verification methods introduced new security risks in DNNs trained on the protected dataset, due to the targeted nature of poison-only backdoor watermarks. To alleviate this problem, in this work, we explore the untargeted backdoor watermarking scheme, where the abnormal model behaviors are not deterministic. Specifically, we introduce two dispersibilities and prove their correlation, based on which we design the untargeted backdoor watermark under both poisoned-label and clean-label settings. We also discuss how to use the proposed untargeted backdoor watermark for dataset ownership verification. Experiments on benchmark datasets verify the effectiveness of our methods and their resistance to existing backdoor defenses. Our codes are available at \url{https://github.com/THUYimingLi/Untargeted_Backdoor_Watermark}.