 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Lifelong Learning for Neural powered Mixed Integer Programming
Aug 24, 2022
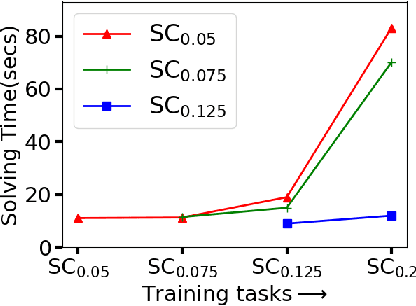
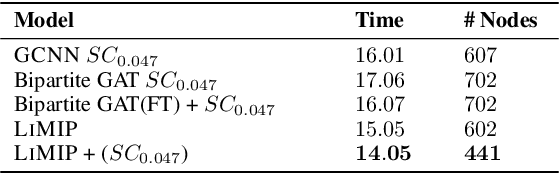
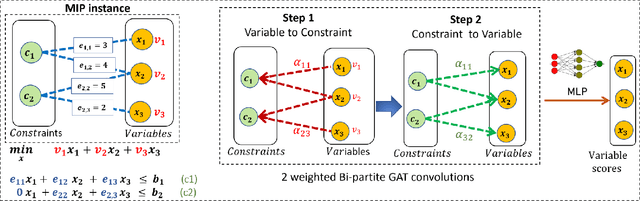

Mixed Integer programs (MIPs) are typically solved by the Branch-and-Bound algorithm. Recently, Learning to imitate fast approximations of the expert strong branching heuristic has gained attention due to its success in reducing the running time for solving MIPs. However, existing learning-to-branch methods assume that the entire training data is available in a single session of training. This assumption is often not true, and if the training data is supplied in continual fashion over time, existing techniques suffer from catastrophic forgetting. In this work, we study the hitherto unexplored paradigm of Lifelong Learning to Branch on Mixed Integer Programs. To mitigate catastrophic forgetting, we propose LIMIP, which is powered by the idea of modeling an MIP instance in the form of a bipartite graph, which we map to an embedding space using a bipartite Graph Attention Network. This rich embedding space avoids catastrophic forgetting through the application of knowledge distillation and elastic weight consolidation, wherein we learn the parameters key towards retaining efficacy and are therefore protected from significant drift. We evaluate LIMIP on a series of NP-hard problems and establish that in comparison to existing baselines, LIMIP is up to 50% better when confronted with lifelong learning.
What Are You Anxious About? Examining Subjects of Anxiety during the COVID-19 Pandemic
Sep 27, 2022
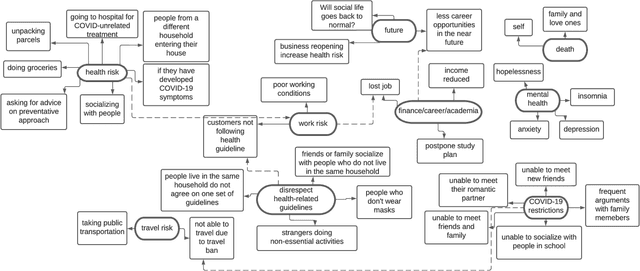
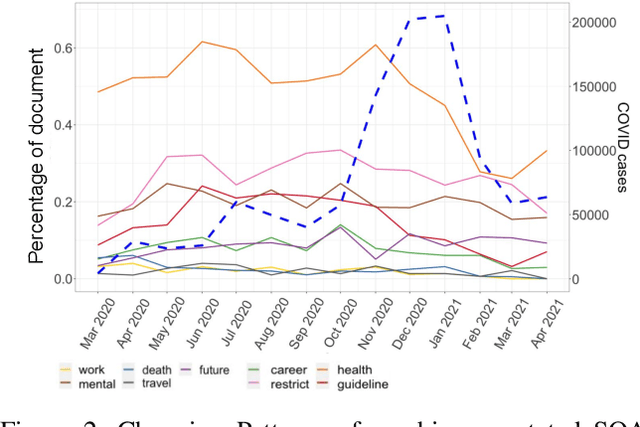

COVID-19 poses disproportionate mental health consequences to the public during different phases of the pandemic. We use a computational approach to capture the specific aspects that trigger an online community's anxiety about the pandemic and investigate how these aspects change over time. First, we identified nine subjects of anxiety (SOAs) in a sample of Reddit posts ($N$=86) from r/COVID19\_support using thematic analysis. Then, we quantified Reddit users' anxiety by training algorithms on a manually annotated sample ($N$=793) to automatically label the SOAs in a larger chronological sample ($N$=6,535). The nine SOAs align with items in various recently developed pandemic anxiety measurement scales. We observed that Reddit users' concerns about health risks remained high in the first eight months of the pandemic. These concerns diminished dramatically despite the surge of cases occurring later. In general, users' language disclosing the SOAs became less intense as the pandemic progressed. However, worries about mental health and the future increased steadily throughout the period covered in this study. People also tended to use more intense language to describe mental health concerns than health risks or death concerns. Our results suggest that this online group's mental health condition does not necessarily improve despite COVID-19 gradually weakening as a health threat due to appropriate countermeasures. Our system lays the groundwork for population health and epidemiology scholars to examine aspects that provoke pandemic anxiety in a timely fashion.
A Multi Camera Unsupervised Domain Adaptation Pipeline for Object Detection in Cultural Sites through Adversarial Learning and Self-Training
Oct 03, 2022
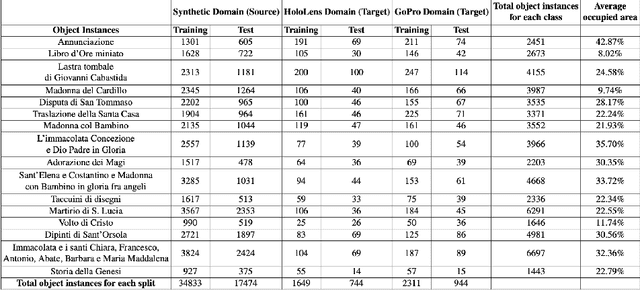

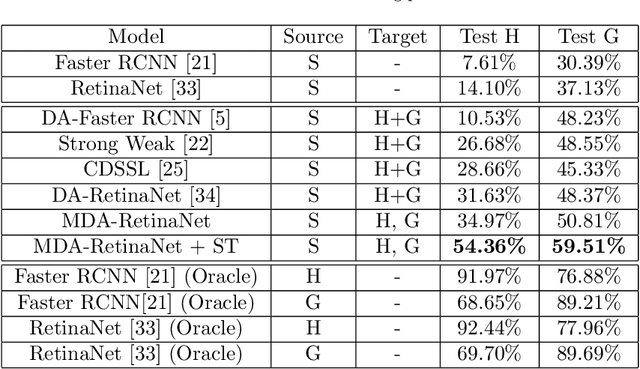
Object detection algorithms allow to enable many interesting applications which can be implemented in different devices, such as smartphones and wearable devices. In the context of a cultural site, implementing these algorithms in a wearable device, such as a pair of smart glasses, allow to enable the use of augmented reality (AR) to show extra information about the artworks and enrich the visitors' experience during their tour. However, object detection algorithms require to be trained on many well annotated examples to achieve reasonable results. This brings a major limitation since the annotation process requires human supervision which makes it expensive in terms of time and costs. A possible solution to reduce these costs consist in exploiting tools to automatically generate synthetic labeled images from a 3D model of the site. However, models trained with synthetic data do not generalize on real images acquired in the target scenario in which they are supposed to be used. Furthermore, object detectors should be able to work with different wearable devices or different mobile devices, which makes generalization even harder. In this paper, we present a new dataset collected in a cultural site to study the problem of domain adaptation for object detection in the presence of multiple unlabeled target domains corresponding to different cameras and a labeled source domain obtained considering synthetic images for training purposes. We present a new domain adaptation method which outperforms current state-of-the-art approaches combining the benefits of aligning the domains at the feature and pixel level with a self-training process. We release the dataset at the following link https://iplab.dmi.unict.it/OBJ-MDA/ and the code of the proposed architecture at https://github.com/fpv-iplab/STMDA-RetinaNet.
A Taxonomy of Recurrent Learning Rules
Jul 23, 2022
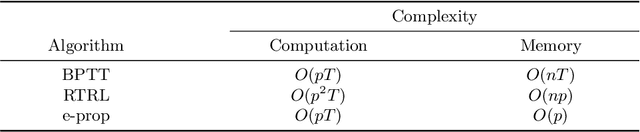
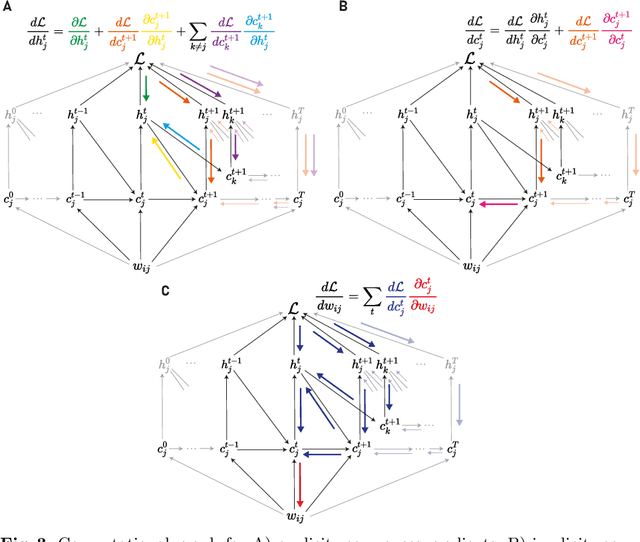
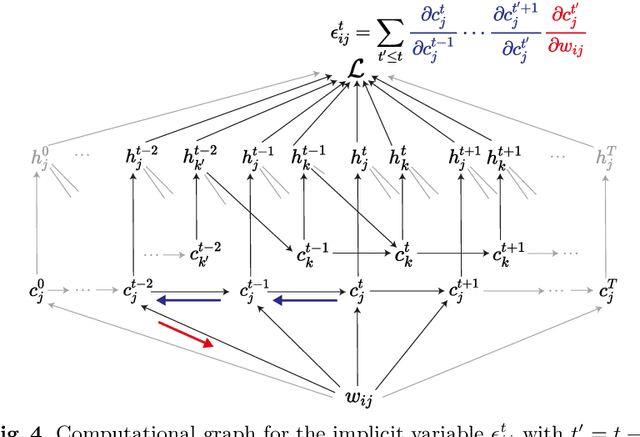
Backpropagation through time (BPTT) is the de facto standard for training recurrent neural networks (RNNs), but it is non-causal and non-local. Real-time recurrent learning is a causal alternative, but it is highly inefficient. Recently, e-prop was proposed as a causal, local, and efficient practical alternative to these algorithms, providing an approximation of the exact gradient by radically pruning the recurrent dependencies carried over time. Here, we derive RTRL from BPTT using a detailed notation bringing intuition and clarification to how they are connected. Furthermore, we frame e-prop within in the picture, formalising what it approximates. Finally, we derive a family of algorithms of which e-prop is a special case.
A Comparative Study of Detecting Anomalies in Time Series Data Using LSTM and TCN Models
Dec 17, 2021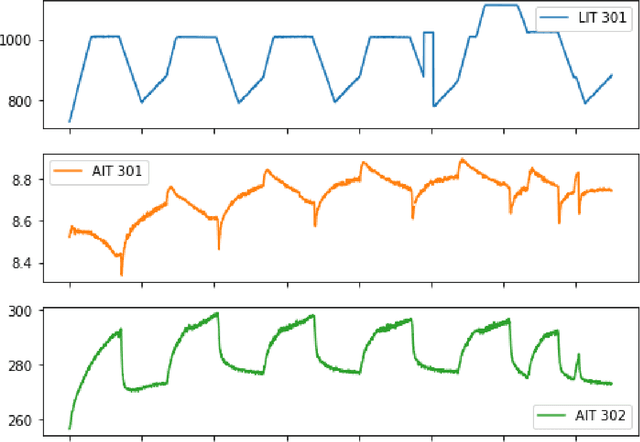
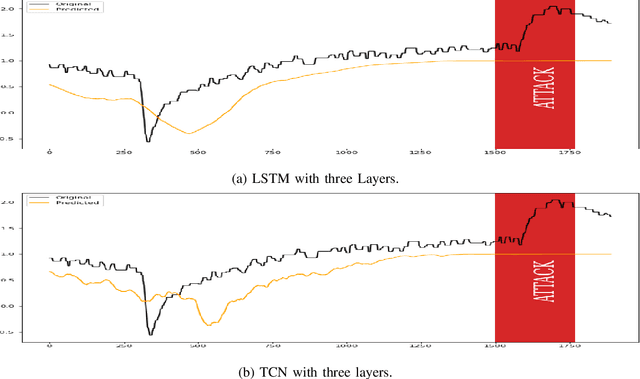
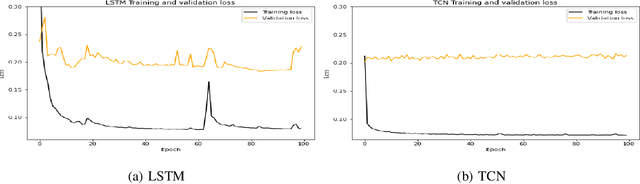
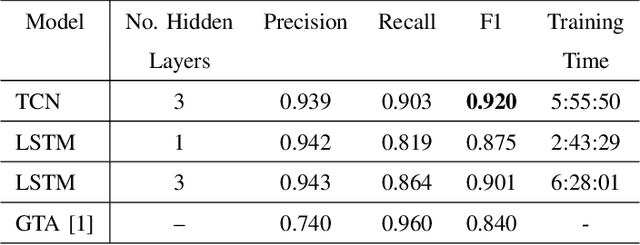
There exist several data-driven approaches that enable us model time series data including traditional regression-based modeling approaches (i.e., ARIMA). Recently, deep learning techniques have been introduced and explored in the context of time series analysis and prediction. A major research question to ask is the performance of these many variations of deep learning techniques in predicting time series data. This paper compares two prominent deep learning modeling techniques. The Recurrent Neural Network (RNN)-based Long Short-Term Memory (LSTM) and the convolutional Neural Network (CNN)-based Temporal Convolutional Networks (TCN) are compared and their performance and training time are reported. According to our experimental results, both modeling techniques perform comparably having TCN-based models outperform LSTM slightly. Moreover, the CNN-based TCN model builds a stable model faster than the RNN-based LSTM models.
Symbolic Knowledge Extraction from Opaque Predictors Applied to Cosmic-Ray Data Gathered with LISA Pathfinder
Sep 10, 2022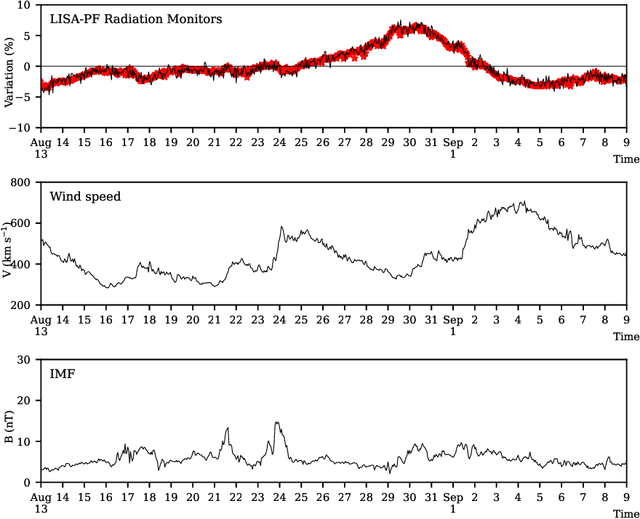
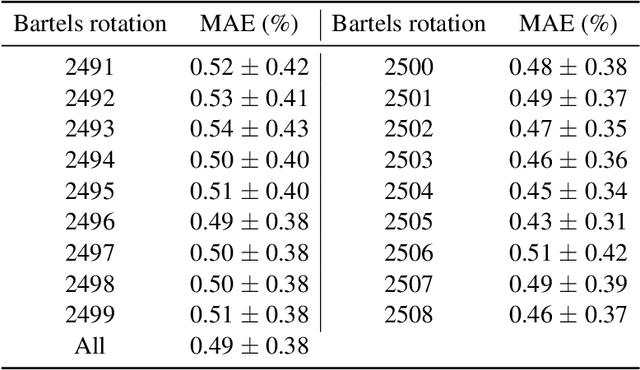
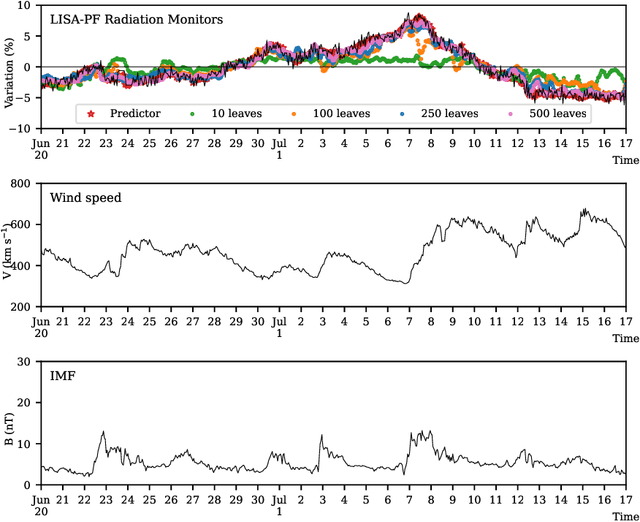
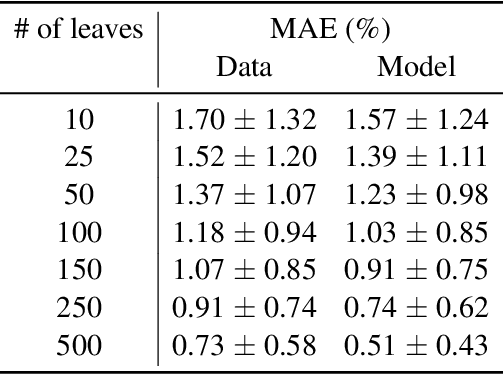
Machine learning models are nowadays ubiquitous in space missions, performing a wide variety of tasks ranging from the prediction of multivariate time series through the detection of specific patterns in the input data. Adopted models are usually deep neural networks or other complex machine learning algorithms providing predictions that are opaque, i.e., human users are not allowed to understand the rationale behind the provided predictions. Several techniques exist in the literature to combine the impressive predictive performance of opaque machine learning models with human-intelligible prediction explanations, as for instance the application of symbolic knowledge extraction procedures. In this paper are reported the results of different knowledge extractors applied to an ensemble predictor capable of reproducing cosmic-ray data gathered on board the LISA Pathfinder space mission. A discussion about the readability/fidelity trade-off of the extracted knowledge is also presented.
The Role of Voice Persona in Expressive Communication:An Argument for Relevance in Speech Synthesis Design
Sep 06, 2022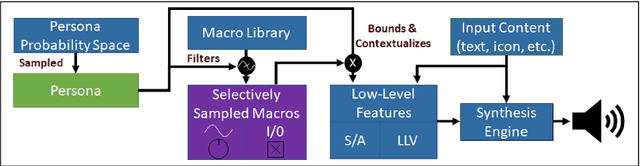
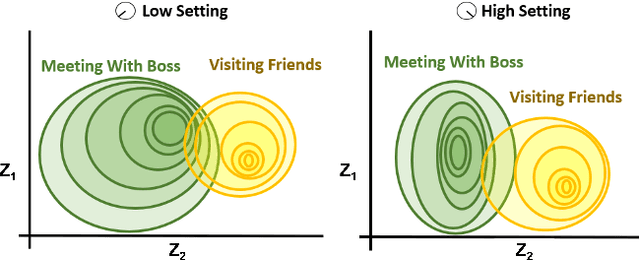
We present an approach to imbuing expressivity in a synthesized voice by acquiring a thematic analysis of 10 interviews with vocal studies and performance experts to inform the design framework for a real-time, interactive vocal persona that would generate compelling and appropriate contextually-dependent expression. The resultant tone of voice is defined as a point existing within a continuous, contextually-dependent probability space. The inclusion of voice persona in synthesized voice can be significant in a broad range of applications. Of particular interest is the potential impact in augmentative and assistive communication (AAC) community. Finally, we conclude with an introduction to our ongoing research investigating the themes of vocal persona and how they may continue to inform proposed expressive speech synthesis design frameworks.
Billion-user Customer Lifetime Value Prediction: An Industrial-scale Solution from Kuaishou
Aug 29, 2022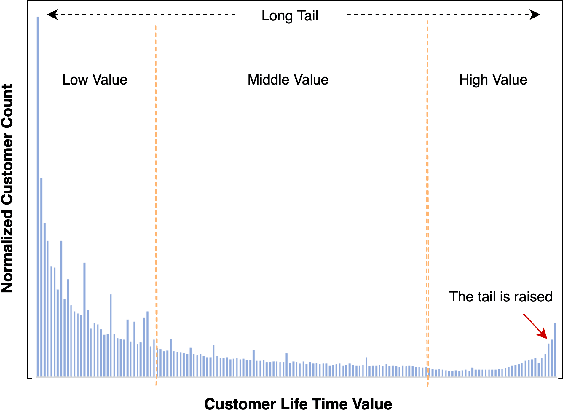
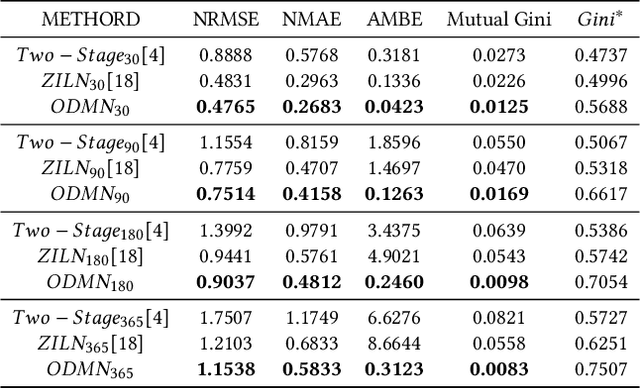
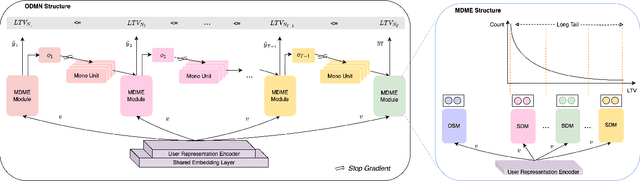
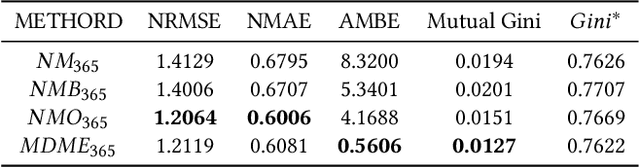
Customer Life Time Value (LTV) is the expected total revenue that a single user can bring to a business. It is widely used in a variety of business scenarios to make operational decisions when acquiring new customers. Modeling LTV is a challenging problem, due to its complex and mutable data distribution. Existing approaches either directly learn from posterior feature distributions or leverage statistical models that make strong assumption on prior distributions, both of which fail to capture those mutable distributions. In this paper, we propose a complete set of industrial-level LTV modeling solutions. Specifically, we introduce an Order Dependency Monotonic Network (ODMN) that models the ordered dependencies between LTVs of different time spans, which greatly improves model performance. We further introduce a Multi Distribution Multi Experts (MDME) module based on the Divide-and-Conquer idea, which transforms the severely imbalanced distribution modeling problem into a series of relatively balanced sub-distribution modeling problems hence greatly reduces the modeling complexity. In addition, a novel evaluation metric Mutual Gini is introduced to better measure the distribution difference between the estimated value and the ground-truth label based on the Lorenz Curve. The ODMN framework has been successfully deployed in many business scenarios of Kuaishou, and achieved great performance. Extensive experiments on real-world industrial data demonstrate the superiority of the proposed methods compared to state-of-the-art baselines including ZILN and Two-Stage XGBoost models.
Automatic Rule Generation for Time Expression Normalization
Aug 31, 2021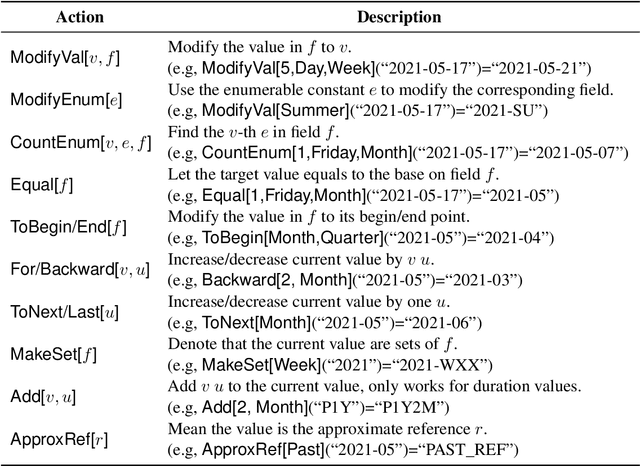
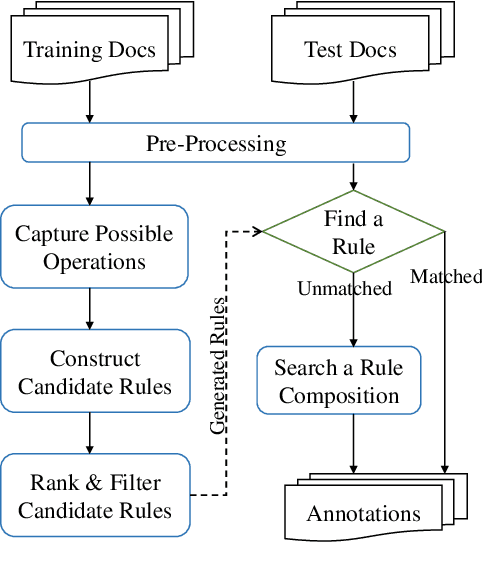

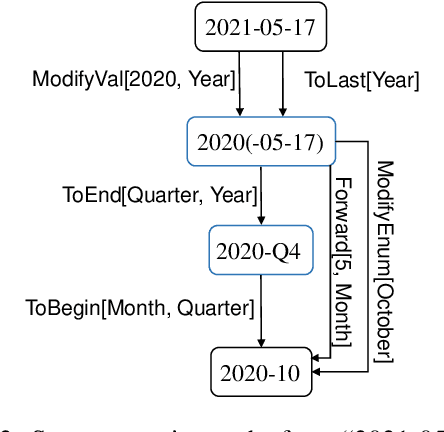
The understanding of time expressions includes two sub-tasks: recognition and normalization. In recent years, significant progress has been made in the recognition of time expressions while research on normalization has lagged behind. Existing SOTA normalization methods highly rely on rules or grammars designed by experts, which limits their performance on emerging corpora, such as social media texts. In this paper, we model time expression normalization as a sequence of operations to construct the normalized temporal value, and we present a novel method called ARTime, which can automatically generate normalization rules from training data without expert interventions. Specifically, ARTime automatically captures possible operation sequences from annotated data and generates normalization rules on time expressions with common surface forms. The experimental results show that ARTime can significantly surpass SOTA methods on the Tweets benchmark, and achieves competitive results with existing expert-engineered rule methods on the TempEval-3 benchmark.
Lightweight Transformers for Human Activity Recognition on Mobile Devices
Sep 22, 2022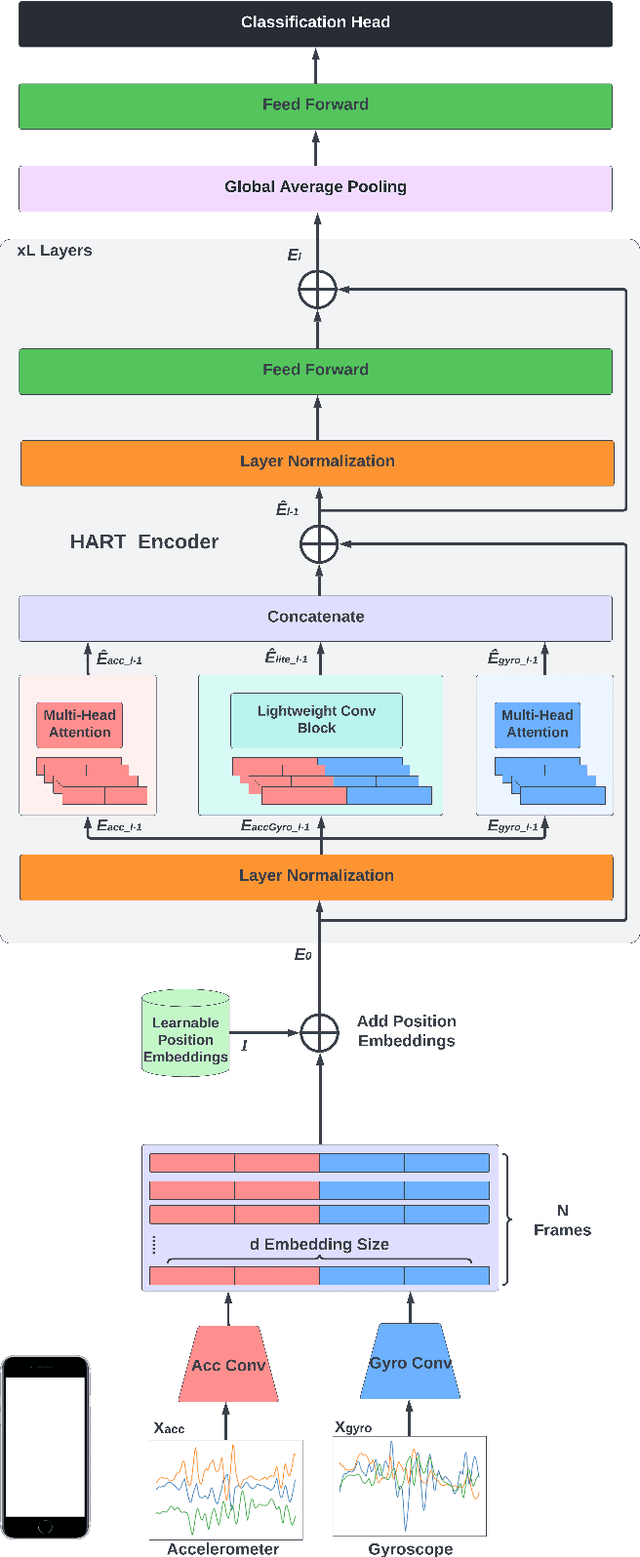
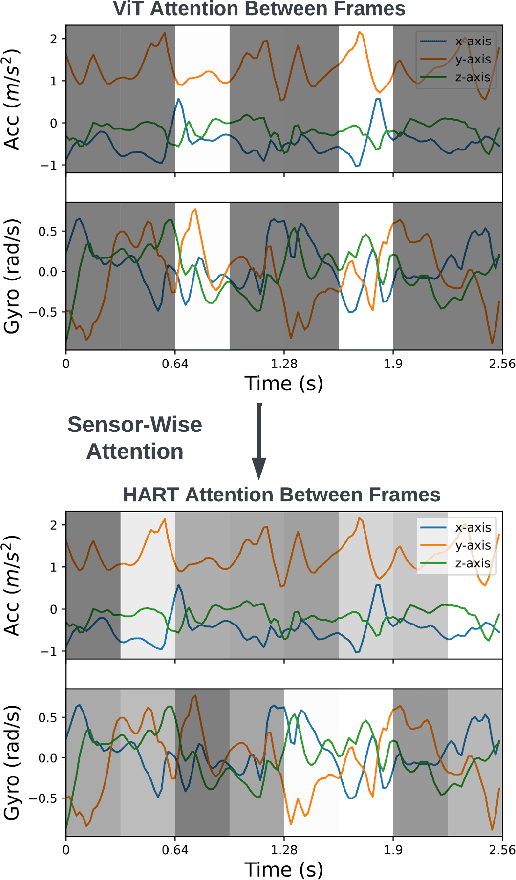
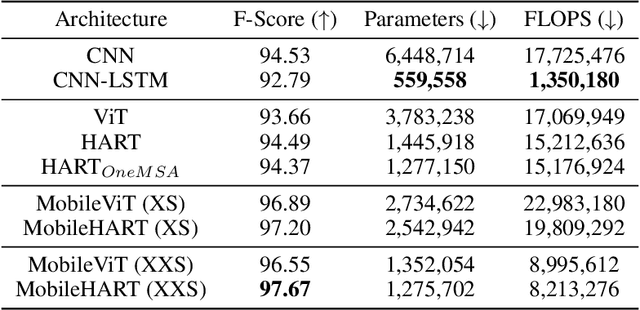
Human Activity Recognition (HAR) on mobile devices has shown to be achievable with lightweight neural models learned from data generated by the user's inertial measurement units (IMUs). Most approaches for instanced-based HAR have used Convolutional Neural Networks (CNNs), Long Short-Term Memory (LSTMs), or a combination of the two to achieve state-of-the-art results with real-time performances. Recently, the Transformers architecture in the language processing domain and then in the vision domain has pushed further the state-of-the-art over classical architectures. However, such Transformers architecture is heavyweight in computing resources, which is not well suited for embedded applications of HAR that can be found in the pervasive computing domain. In this study, we present Human Activity Recognition Transformer (HART), a lightweight, sensor-wise transformer architecture that has been specifically adapted to the domain of the IMUs embedded on mobile devices. Our experiments on HAR tasks with several publicly available datasets show that HART uses fewer FLoating-point Operations Per Second (FLOPS) and parameters while outperforming current state-of-the-art results. Furthermore, we present evaluations across various architectures on their performances in heterogeneous environments and show that our models can better generalize on different sensing devices or on-body positions.