 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimal Robot Formations: Balancing Range-Based Observability and User-Defined Configurations
Mar 01, 2024
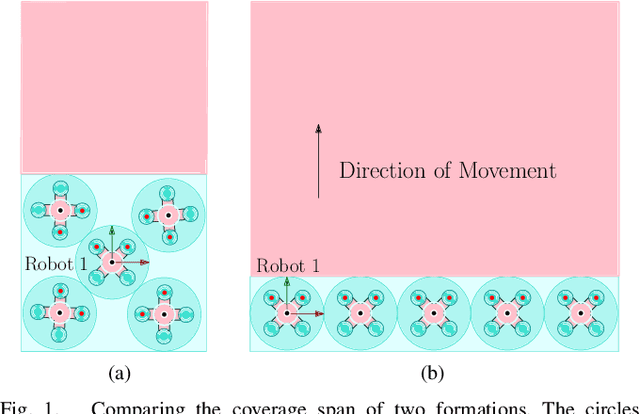
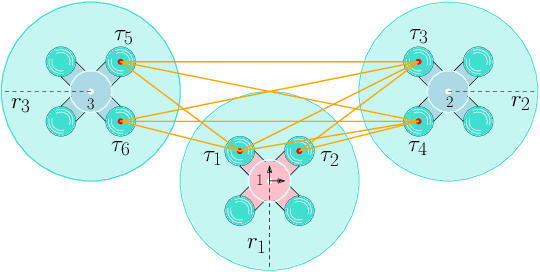
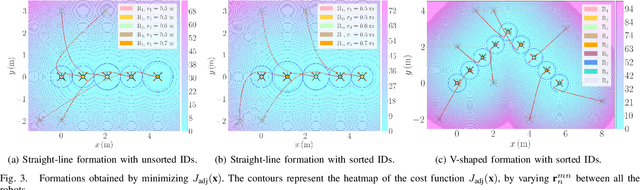
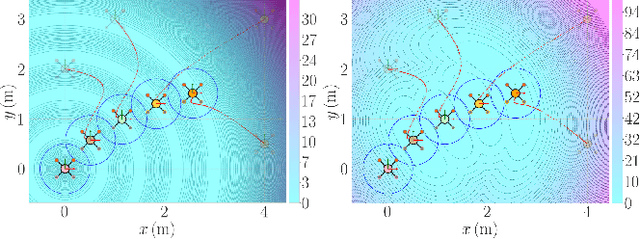
This paper introduces a set of customizable and novel cost functions that enable the user to easily specify desirable robot formations, such as a ``high-coverage'' infrastructure-inspection formation, while maintaining high relative pose estimation accuracy. The overall cost function balances the need for the robots to be close together for good ranging-based relative localization accuracy and the need for the robots to achieve specific tasks, such as minimizing the time taken to inspect a given area. The formations found by minimizing the aggregated cost function are evaluated in a coverage path planning task in simulation and experiment, where the robots localize themselves and unknown landmarks using a simultaneous localization and mapping algorithm based on the extended Kalman filter. Compared to an optimal formation that maximizes ranging-based relative localization accuracy, these formations significantly reduce the time to cover a given area with minimal impact on relative pose estimation accuracy.
Degradation-Invariant Music Indexing
Mar 01, 2024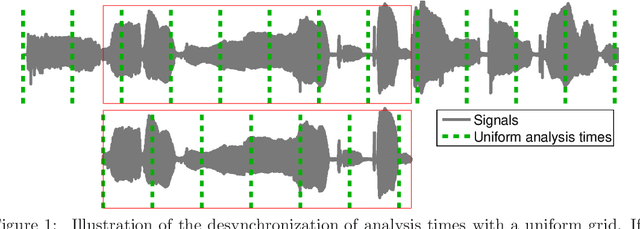
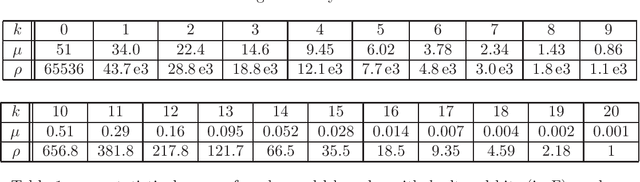
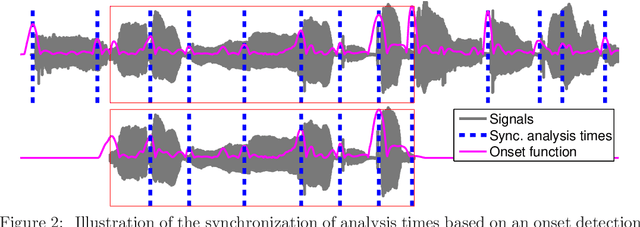
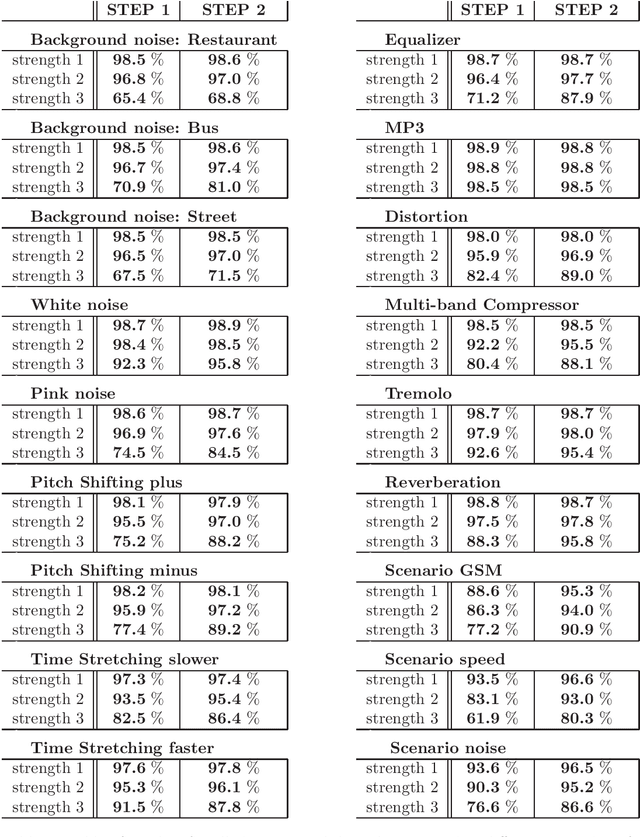
For music indexing robust to sound degradations and scalable for big music catalogs, this scientific report presents an approach based on audio descriptors relevant to the music content and invariant to sound transformations (noise addition, distortion, lossy coding, pitch/time transformations, or filtering e.g.). To achieve this task, one of the key point of the proposed method is the definition of high-dimensional audio prints, which are intrinsically (by design) robust to some sound degradations. The high dimensionality of this first representation is then used to learn a linear projection to a sub-space significantly smaller, which reduces again the sensibility to sound degradations using a series of discriminant analyses. Finally, anchoring the analysis times on local maxima of a selected onset function, an approximative hashing is done to provide a better tolerance to bit corruptions, and in the same time to make easier the scaling of the method.
Deep Cooperation in ISAC System: Resource, Node and Infrastructure Perspectives
Mar 05, 2024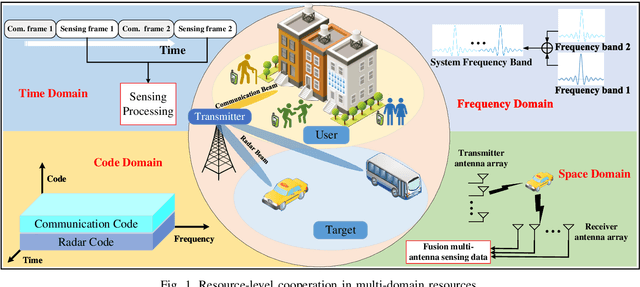
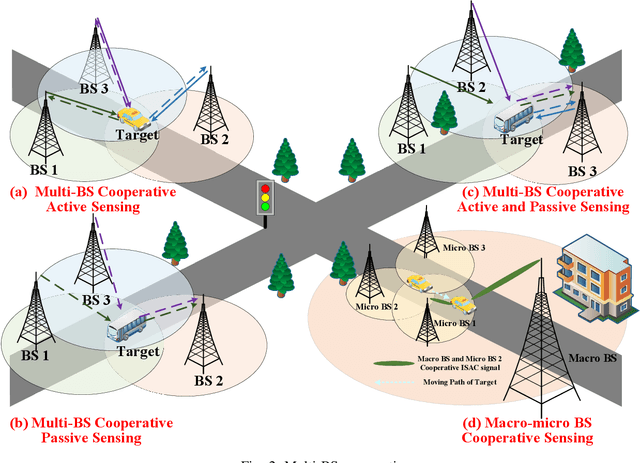
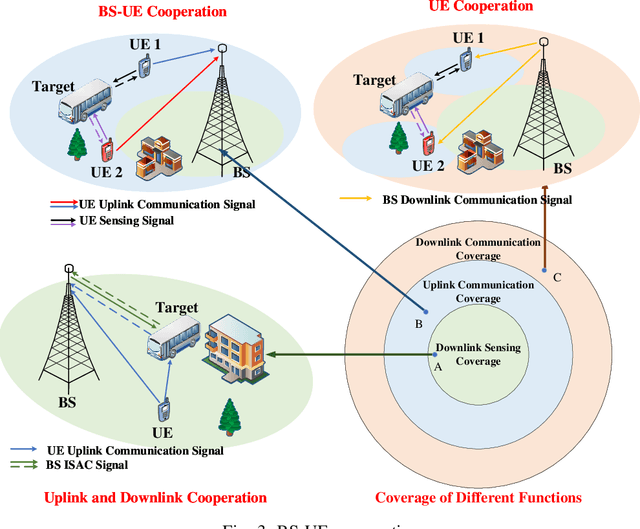
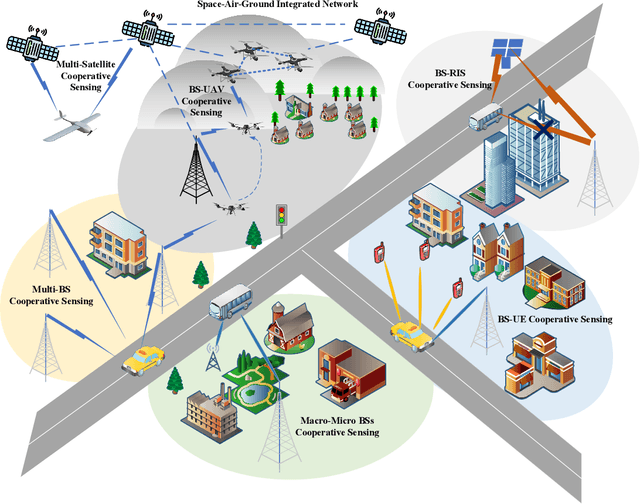
With the mobile communication system evolving into 6th-generation (6G), the Internet of Everything (IoE) is becoming reality, which connects human, big data and intelligent machines to support the intelligent decision making, reconfiguring the traditional industries and human life. The applications of IoE require not only pure communication capability, but also high-accuracy and large-scale sensing capability. With the emerging integrated sensing and communication (ISAC) technique, exploiting the mobile communication system with multi-domain resources, multiple network elements, and large-scale infrastructures to realize cooperative sensing is a crucial approach to satisfy the requirements of high-accuracy and large-scale sensing in IoE. In this article, the deep cooperation in ISAC system including three perspectives is investigated. In the microscopic perspective, namely, within a single node, the cooperation at the resource-level is performed to improve sensing accuracy by fusing the sensing information carried in the time-frequency-space-code multi-domain resources. In the mesoscopic perspective, the sensing accuracy could be improved through the cooperation of multiple nodes including Base Station (BS), User Equipment (UE), and Reconfigurable Intelligence Surface (RIS), etc. In the macroscopic perspective, the massive number of infrastructures from the same operator or different operators could perform cooperative sensing to extend the sensing coverage and improve the sensing continuity. This article may provide a deep and comprehensive view on the cooperative sensing in ISAC system to enhance the performance of sensing, supporting the applications of IoE.
Optimizing Mobile-Friendly Viewport Prediction for Live 360-Degree Video Streaming
Mar 05, 2024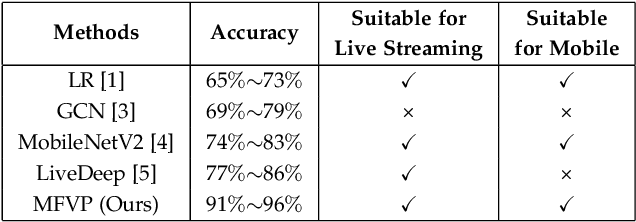
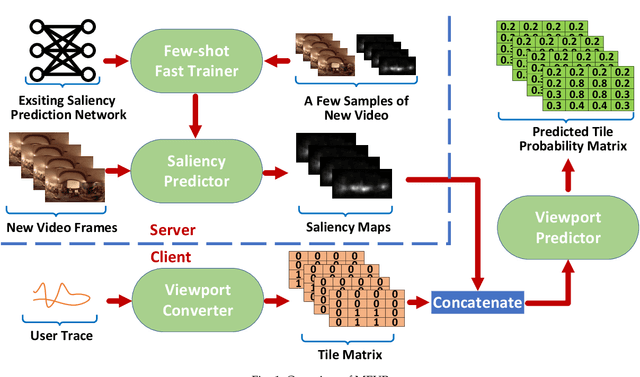
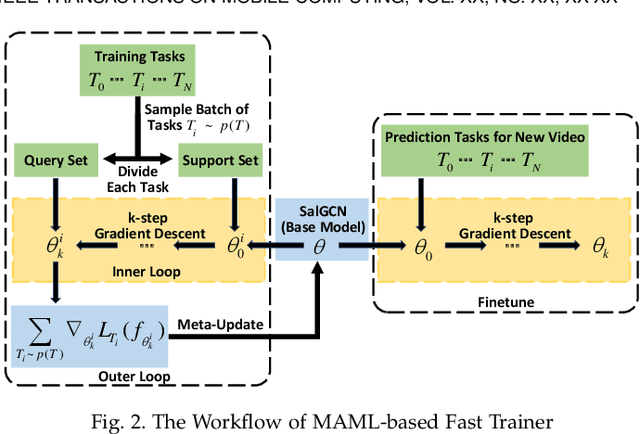
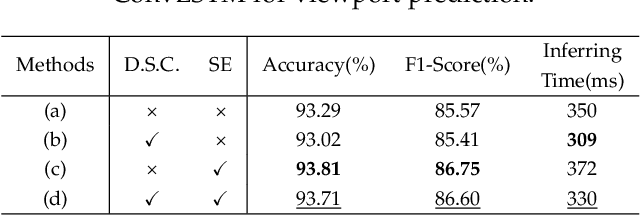
Viewport prediction is the crucial task for adaptive 360-degree video streaming, as the bitrate control algorithms usually require the knowledge of the user's viewing portions of the frames. Various methods are studied and adopted for viewport prediction from less accurate statistic tools to highly calibrated deep neural networks. Conventionally, it is difficult to implement sophisticated deep learning methods on mobile devices, which have limited computation capability. In this work, we propose an advanced learning-based viewport prediction approach and carefully design it to introduce minimal transmission and computation overhead for mobile terminals. We also propose a model-agnostic meta-learning (MAML) based saliency prediction network trainer, which provides a few-sample fast training solution to obtain the prediction model by utilizing the information from the past models. We further discuss how to integrate this mobile-friendly viewport prediction (MFVP) approach into a typical 360-degree video live streaming system by formulating and solving the bitrate adaptation problem. Extensive experiment results show that our prediction approach can work in real-time for live video streaming and can achieve higher accuracies compared to other existing prediction methods on mobile end, which, together with our bitrate adaptation algorithm, significantly improves the streaming QoE from various aspects. We observe the accuracy of MFVP is 8.1$\%$ to 28.7$\%$ higher than other algorithms and achieves 3.73$\%$ to 14.96$\%$ higher average quality level and 49.6$\%$ to 74.97$\%$ less quality level change than other algorithms.
Precise Extraction of Deep Learning Models via Side-Channel Attacks on Edge/Endpoint Devices
Mar 05, 2024With growing popularity, deep learning (DL) models are becoming larger-scale, and only the companies with vast training datasets and immense computing power can manage their business serving such large models. Most of those DL models are proprietary to the companies who thus strive to keep their private models safe from the model extraction attack (MEA), whose aim is to steal the model by training surrogate models. Nowadays, companies are inclined to offload the models from central servers to edge/endpoint devices. As revealed in the latest studies, adversaries exploit this opportunity as new attack vectors to launch side-channel attack (SCA) on the device running victim model and obtain various pieces of the model information, such as the model architecture (MA) and image dimension (ID). Our work provides a comprehensive understanding of such a relationship for the first time and would benefit future MEA studies in both offensive and defensive sides in that they may learn which pieces of information exposed by SCA are more important than the others. Our analysis additionally reveals that by grasping the victim model information from SCA, MEA can get highly effective and successful even without any prior knowledge of the model. Finally, to evince the practicality of our analysis results, we empirically apply SCA, and subsequently, carry out MEA under realistic threat assumptions. The results show up to 5.8 times better performance than when the adversary has no model information about the victim model.
MOMENT: A Family of Open Time-series Foundation Models
Feb 06, 2024We introduce MOMENT, a family of open-source foundation models for general-purpose time-series analysis. Pre-training large models on time-series data is challenging due to (1) the absence of a large and cohesive public time-series repository, and (2) diverse time-series characteristics which make multi-dataset training onerous. Additionally, (3) experimental benchmarks to evaluate these models, especially in scenarios with limited resources, time, and supervision, are still in their nascent stages. To address these challenges, we compile a large and diverse collection of public time-series, called the Time-series Pile, and systematically tackle time-series-specific challenges to unlock large-scale multi-dataset pre-training. Finally, we build on recent work to design a benchmark to evaluate time-series foundation models on diverse tasks and datasets in limited supervision settings. Experiments on this benchmark demonstrate the effectiveness of our pre-trained models with minimal data and task-specific fine-tuning. Finally, we present several interesting empirical observations about large pre-trained time-series models. Our code is available anonymously at anonymous.4open.science/r/BETT-773F/.
Inf2Guard: An Information-Theoretic Framework for Learning Privacy-Preserving Representations against Inference Attacks
Mar 04, 2024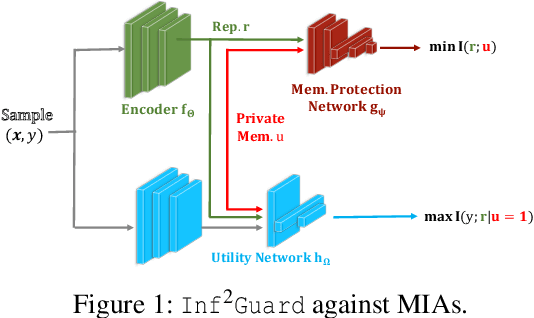
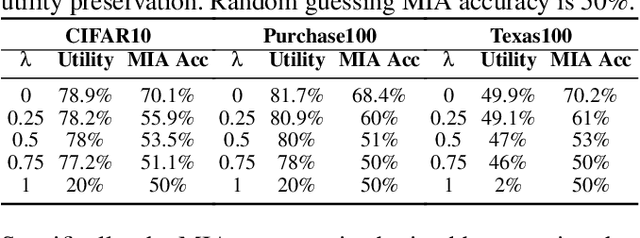
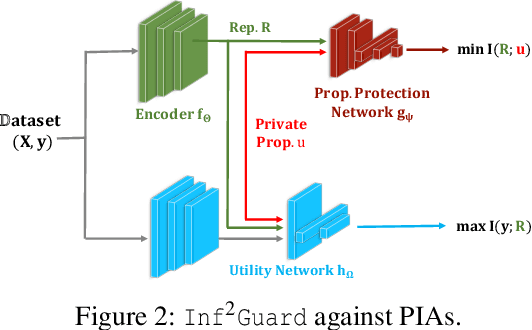
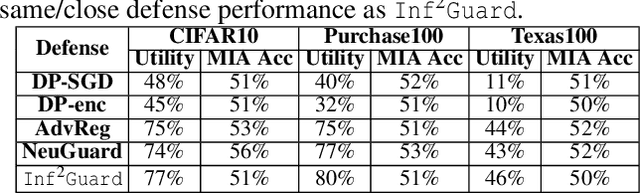
Machine learning (ML) is vulnerable to inference (e.g., membership inference, property inference, and data reconstruction) attacks that aim to infer the private information of training data or dataset. Existing defenses are only designed for one specific type of attack and sacrifice significant utility or are soon broken by adaptive attacks. We address these limitations by proposing an information-theoretic defense framework, called Inf2Guard, against the three major types of inference attacks. Our framework, inspired by the success of representation learning, posits that learning shared representations not only saves time/costs but also benefits numerous downstream tasks. Generally, Inf2Guard involves two mutual information objectives, for privacy protection and utility preservation, respectively. Inf2Guard exhibits many merits: it facilitates the design of customized objectives against the specific inference attack; it provides a general defense framework which can treat certain existing defenses as special cases; and importantly, it aids in deriving theoretical results, e.g., inherent utility-privacy tradeoff and guaranteed privacy leakage. Extensive evaluations validate the effectiveness of Inf2Guard for learning privacy-preserving representations against inference attacks and demonstrate the superiority over the baselines.
Leveraging Weakly Annotated Data for Hate Speech Detection in Code-Mixed Hinglish: A Feasibility-Driven Transfer Learning Approach with Large Language Models
Mar 04, 2024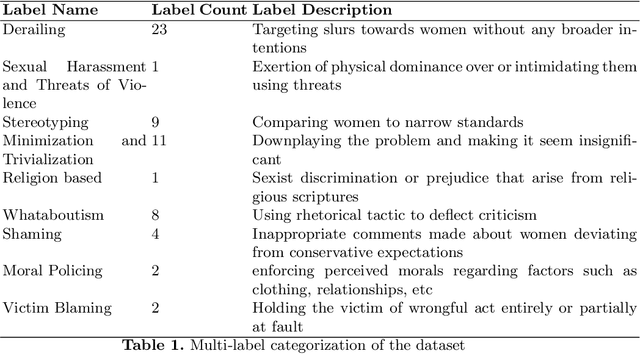
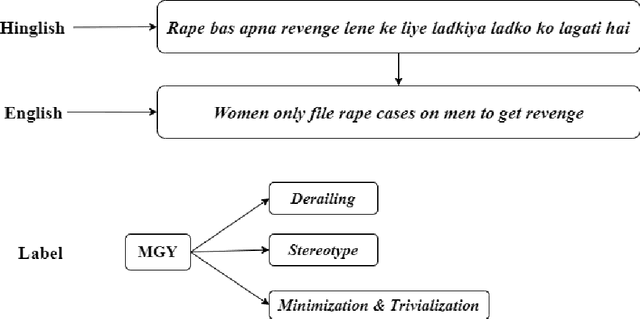
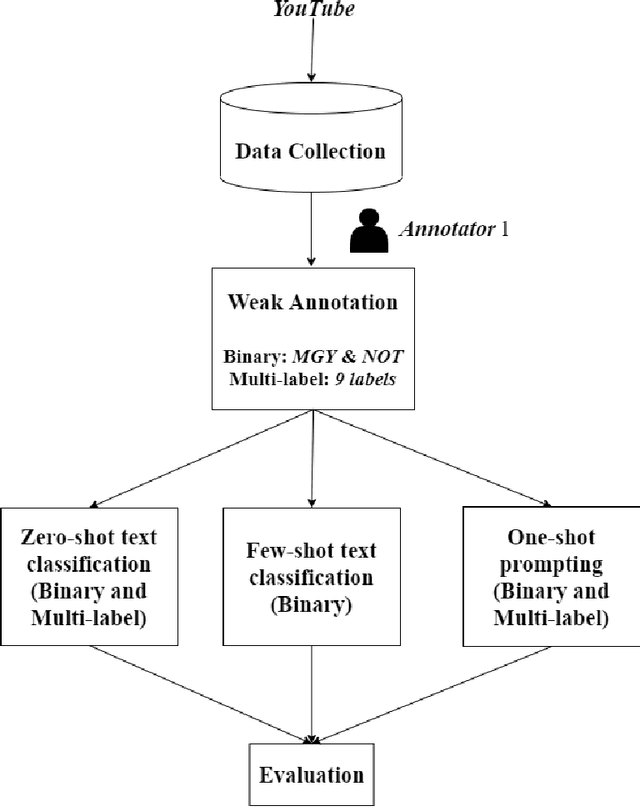
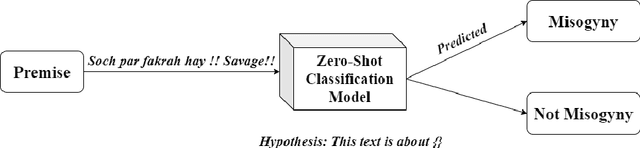
The advent of Large Language Models (LLMs) has advanced the benchmark in various Natural Language Processing (NLP) tasks. However, large amounts of labelled training data are required to train LLMs. Furthermore, data annotation and training are computationally expensive and time-consuming. Zero and few-shot learning have recently emerged as viable options for labelling data using large pre-trained models. Hate speech detection in mix-code low-resource languages is an active problem area where the use of LLMs has proven beneficial. In this study, we have compiled a dataset of 100 YouTube comments, and weakly labelled them for coarse and fine-grained misogyny classification in mix-code Hinglish. Weak annotation was applied due to the labor-intensive annotation process. Zero-shot learning, one-shot learning, and few-shot learning and prompting approaches have then been applied to assign labels to the comments and compare them to human-assigned labels. Out of all the approaches, zero-shot classification using the Bidirectional Auto-Regressive Transformers (BART) large model and few-shot prompting using Generative Pre-trained Transformer- 3 (ChatGPT-3) achieve the best results
Fast Benchmarking of Asynchronous Multi-Fidelity Optimization on Zero-Cost Benchmarks
Mar 04, 2024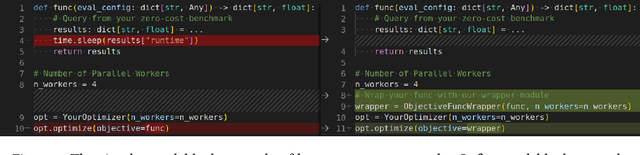

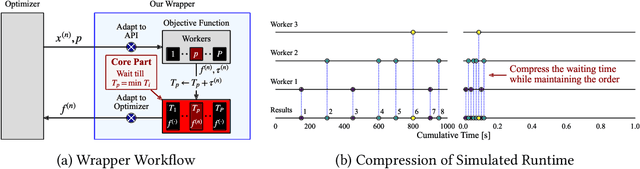

While deep learning has celebrated many successes, its results often hinge on the meticulous selection of hyperparameters (HPs). However, the time-consuming nature of deep learning training makes HP optimization (HPO) a costly endeavor, slowing down the development of efficient HPO tools. While zero-cost benchmarks, which provide performance and runtime without actual training, offer a solution for non-parallel setups, they fall short in parallel setups as each worker must communicate its queried runtime to return its evaluation in the exact order. This work addresses this challenge by introducing a user-friendly Python package that facilitates efficient parallel HPO with zero-cost benchmarks. Our approach calculates the exact return order based on the information stored in file system, eliminating the need for long waiting times and enabling much faster HPO evaluations. We first verify the correctness of our approach through extensive testing and the experiments with 6 popular HPO libraries show its applicability to diverse libraries and its ability to achieve over 1000x speedup compared to a traditional approach. Our package can be installed via pip install mfhpo-simulator.
Quantifying and Predicting Residential Building Flexibility Using Machine Learning Methods
Mar 04, 2024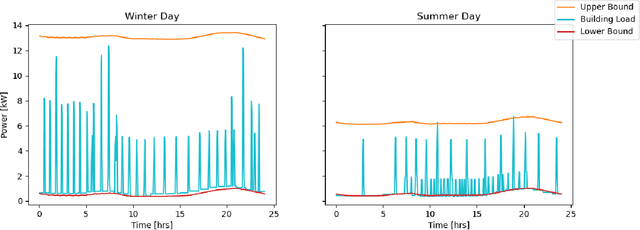
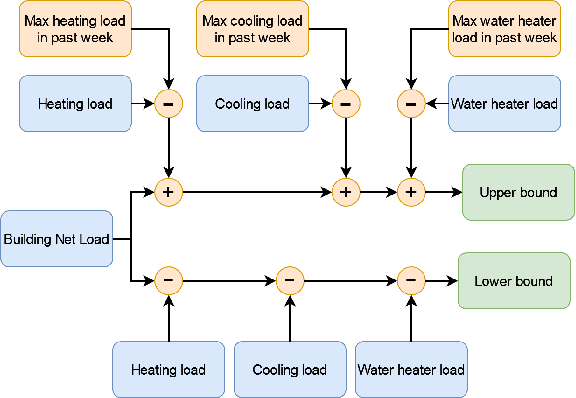
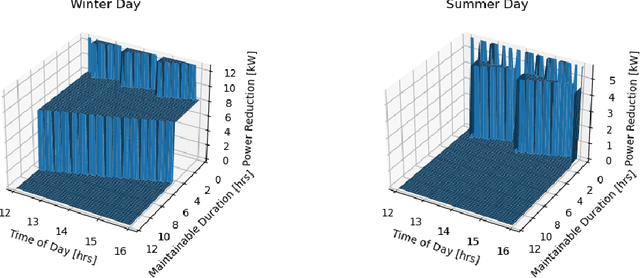
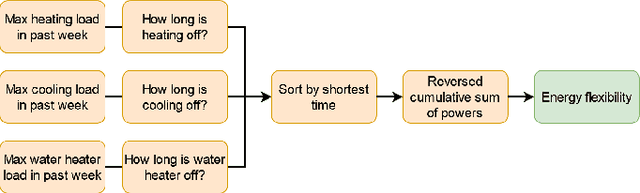
Residential buildings account for a significant portion (35\%) of the total electricity consumption in the U.S. as of 2022. As more distributed energy resources are installed in buildings, their potential to provide flexibility to the grid increases. To tap into that flexibility provided by buildings, aggregators or system operators need to quantify and forecast flexibility. Previous works in this area primarily focused on commercial buildings, with little work on residential buildings. To address the gap, this paper first proposes two complementary flexibility metrics (i.e., power and energy flexibility) and then investigates several mainstream machine learning-based models for predicting the time-variant and sporadic flexibility of residential buildings at four-hour and 24-hour forecast horizons. The long-short-term-memory (LSTM) model achieves the best performance and can predict power flexibility for up to 24 hours ahead with the average error around 0.7 kW. However, for energy flexibility, the LSTM model is only successful for loads with consistent operational patterns throughout the year and faces challenges when predicting energy flexibility associated with HVAC systems.