 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Planar Pose Estimation via UWB Measurements
Sep 15, 2022
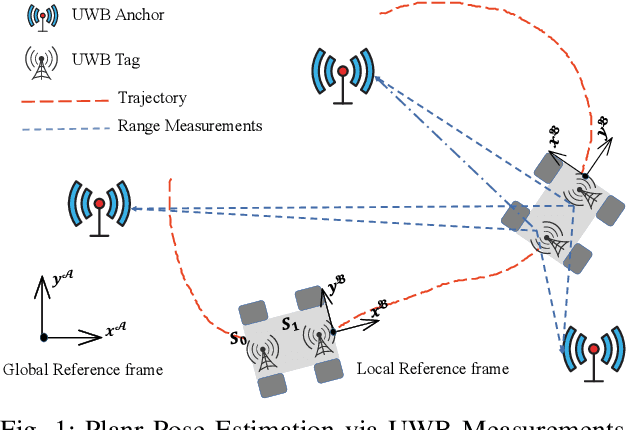
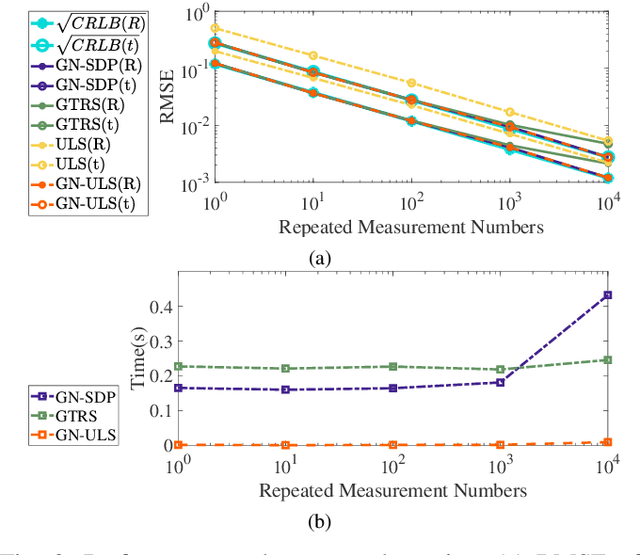
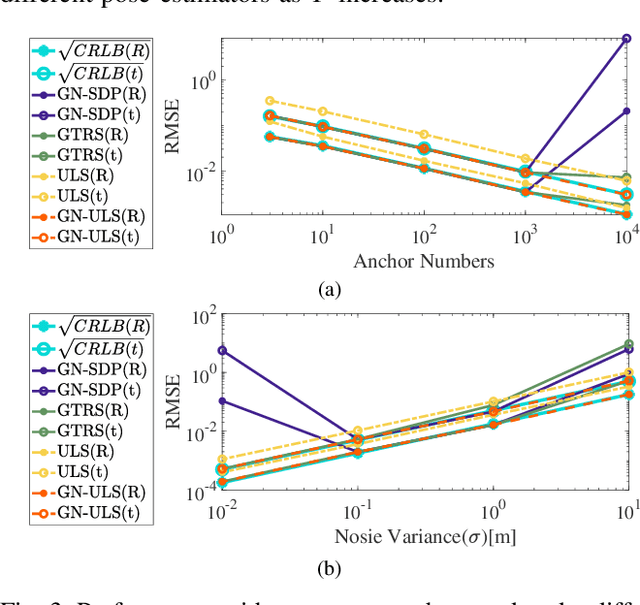

State estimation is an essential part of autonomous systems. Integrating the Ultra-Wideband(UWB) technique has been shown to correct the long-term estimation drift and bypass the complexity of loop closure detection. However, few works on robotics adopt UWB as a stand-alone state estimation solution. The primary purpose of this work is to investigate planar pose estimation using only UWB range measurements and study the estimator's statistical efficiency. We prove the excellent property of a two-step scheme, which says that we can refine a consistent estimator to be asymptotically efficient by one step of Gauss-Newton iteration. Grounded on this result, we design the GN-ULS estimator and evaluate it through simulations and collected datasets. GN-ULS attains millimeter and sub-degree level accuracy on our static datasets and attains centimeter and degree level accuracy on our dynamic datasets, presenting the possibility of using only UWB for real-time state estimation.
TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data
Jan 18, 2022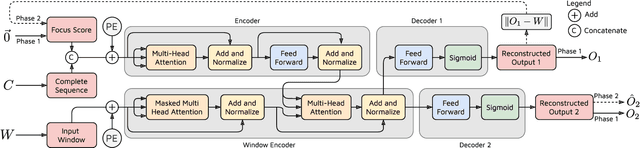
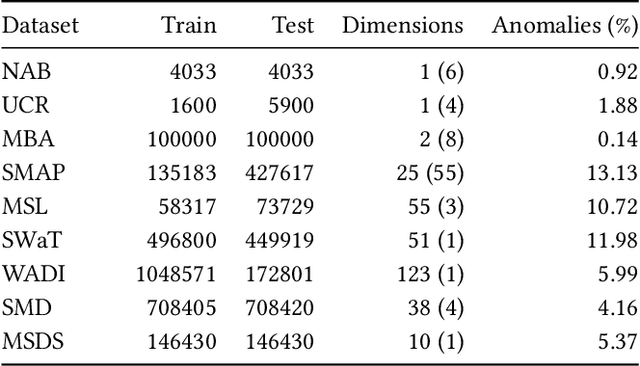
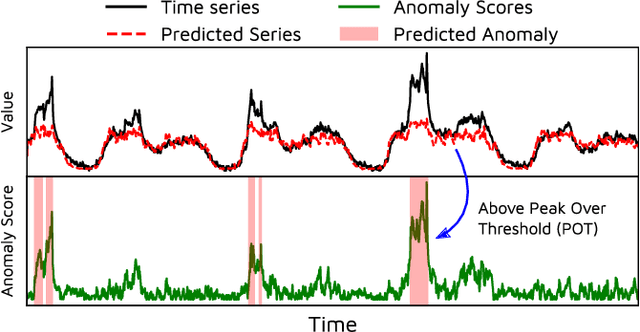
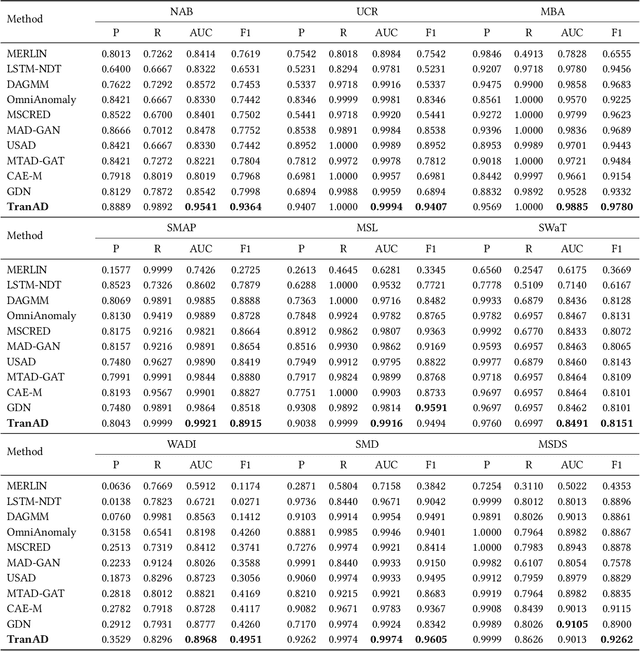
Efficient anomaly detection and diagnosis in multivariate time-series data is of great importance for modern industrial applications. However, building a system that is able to quickly and accurately pinpoint anomalous observations is a challenging problem. This is due to the lack of anomaly labels, high data volatility and the demands of ultra-low inference times in modern applications. Despite the recent developments of deep learning approaches for anomaly detection, only a few of them can address all of these challenges. In this paper, we propose TranAD, a deep transformer network based anomaly detection and diagnosis model which uses attention-based sequence encoders to swiftly perform inference with the knowledge of the broader temporal trends in the data. TranAD uses focus score-based self-conditioning to enable robust multi-modal feature extraction and adversarial training to gain stability. Additionally, model-agnostic meta learning (MAML) allows us to train the model using limited data. Extensive empirical studies on six publicly available datasets demonstrate that TranAD can outperform state-of-the-art baseline methods in detection and diagnosis performance with data and time-efficient training. Specifically, TranAD increases F1 scores by up to 17%, reducing training times by up to 99% compared to the baselines.
Modeling Polyp Activity of Paragorgia arborea Using Supervised Learning
Sep 26, 2022
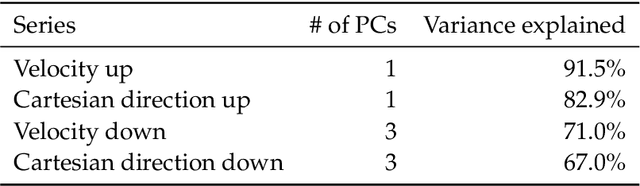
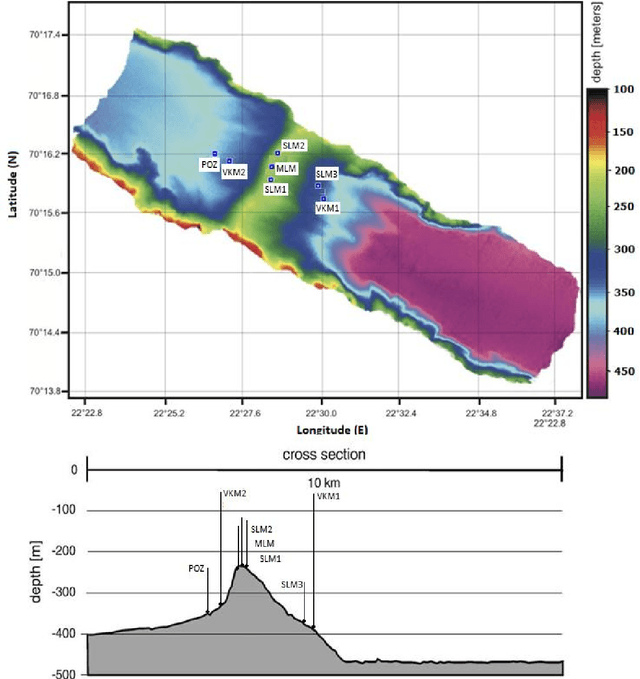
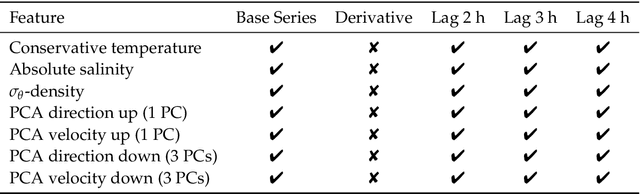
While the distribution patterns of cold-water corals, such as Paragorgia arborea, have received increasing attention in recent studies, little is known about their in situ activity patterns. In this paper, we examine polyp activity in P. arborea using machine learning techniques to analyze high-resolution time series data and photographs obtained from an autonomous lander cluster deployed in the Stjernsund, Norway. An interactive illustration of the models derived in this paper is provided online as supplementary material. We find that the best predictor of the degree of extension of the coral polyps is current direction with a lag of three hours. Other variables that are not directly associated with water currents, such as temperature and salinity, offer much less information concerning polyp activity. Interestingly, the degree of polyp extension can be predicted more reliably by sampling the laminar flows in the water column above the measurement site than by sampling the more turbulent flows in the direct vicinity of the corals. Our results show that the activity patterns of the P. arborea polyps are governed by the strong tidal current regime of the Stjernsund. It appears that P. arborea does not react to shorter changes in the ambient current regime but instead adjusts its behavior in accordance with the large-scale pattern of the tidal cycle itself in order to optimize nutrient uptake.
* 25 pages
Applying Regression Conformal Prediction with Nearest Neighbors to time series data
Oct 25, 2021
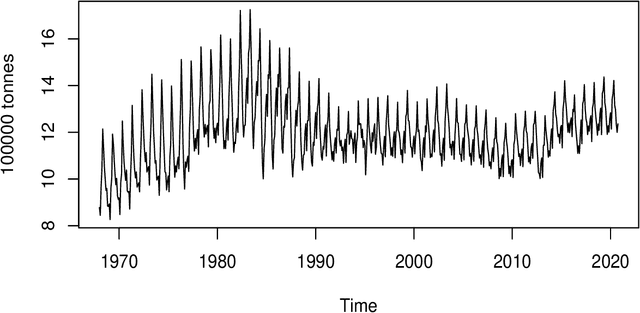

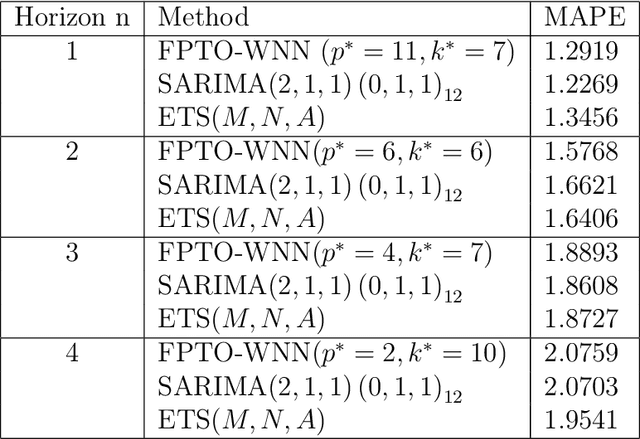
In this paper, we apply conformal prediction to time series data. Conformal prediction isa method that produces predictive regions given a confidence level. The regions outputs arealways valid under the exchangeability assumption. However, this assumption does not holdfor the time series data because there is a link among past, current, and future observations.Consequently, the challenge of applying conformal predictors to the problem of time seriesdata lies in the fact that observations of a time series are dependent and therefore do notmeet the exchangeability assumption. This paper aims to present a way of constructingreliable prediction intervals by using conformal predictors in the context of time series. Weuse the nearest neighbors method based on the fast parameters tuning technique in theweighted nearest neighbors (FPTO-WNN) approach as the underlying algorithm. Dataanalysis demonstrates the effectiveness of the proposed approach.
Adversarially Robust Learning: A Generic Minimax Optimal Learner and Characterization
Sep 15, 2022We present a minimax optimal learner for the problem of learning predictors robust to adversarial examples at test-time. Interestingly, we find that this requires new algorithmic ideas and approaches to adversarially robust learning. In particular, we show, in a strong negative sense, the suboptimality of the robust learner proposed by Montasser, Hanneke, and Srebro (2019) and a broader family of learners we identify as local learners. Our results are enabled by adopting a global perspective, specifically, through a key technical contribution: the global one-inclusion graph, which may be of independent interest, that generalizes the classical one-inclusion graph due to Haussler, Littlestone, and Warmuth (1994). Finally, as a byproduct, we identify a dimension characterizing qualitatively and quantitatively what classes of predictors $\mathcal{H}$ are robustly learnable. This resolves an open problem due to Montasser et al. (2019), and closes a (potentially) infinite gap between the established upper and lower bounds on the sample complexity of adversarially robust learning.
Siamese Network-based Lightweight Framework for Tomato Leaf Disease Recognition
Sep 18, 2022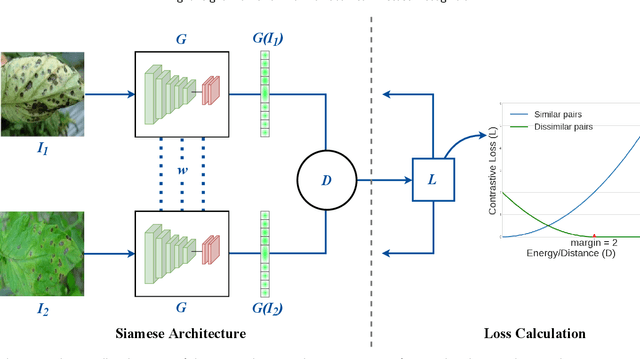
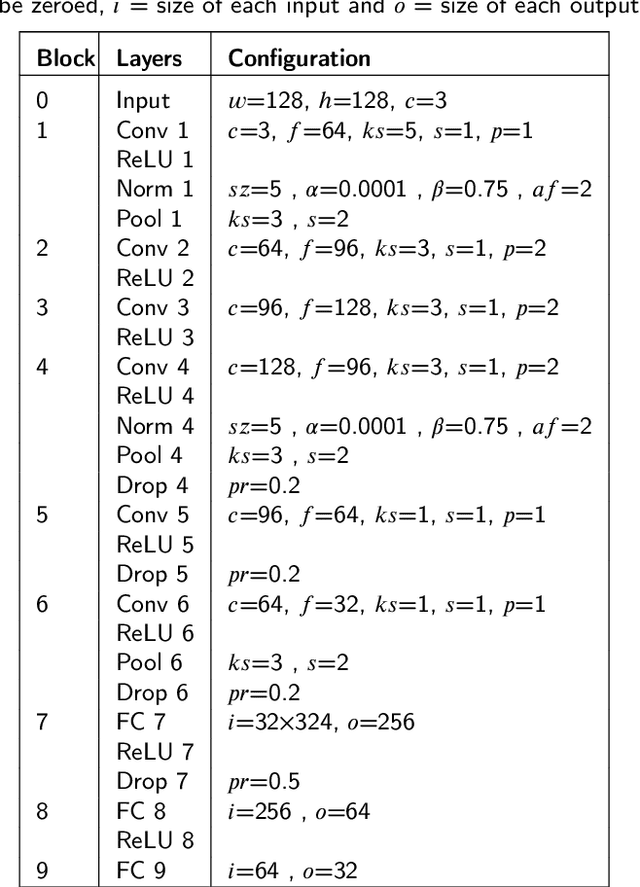

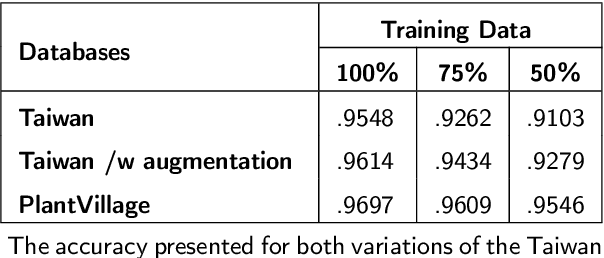
Automatic tomato disease recognition from leaf images is vital to avoid crop losses by applying control measures on time. Even though recent deep learning-based tomato disease recognition methods with classical training procedures showed promising recognition results, they demand large labelled data and involve expensive training. The traditional deep learning models proposed for tomato disease recognition also consume high memory and storage because of a high number of parameters. While lightweight networks overcome some of these issues to a certain extent, they continue to show low performance and struggle to handle imbalanced data. In this paper, a novel Siamese network-based lightweight framework is proposed for automatic tomato leaf disease recognition. This framework achieves the highest accuracy of 96.97% on the tomato subset obtained from the PlantVillage dataset and 95.48% on the Taiwan tomato leaf disease dataset. Experimental results further confirm that the proposed framework is effective with imbalanced and small data. The backbone deep network integrated with this framework is lightweight with approximately 2.9629 million trainable parameters, which is way lower than existing lightweight deep networks.
Merlion: A Machine Learning Library for Time Series
Sep 20, 2021
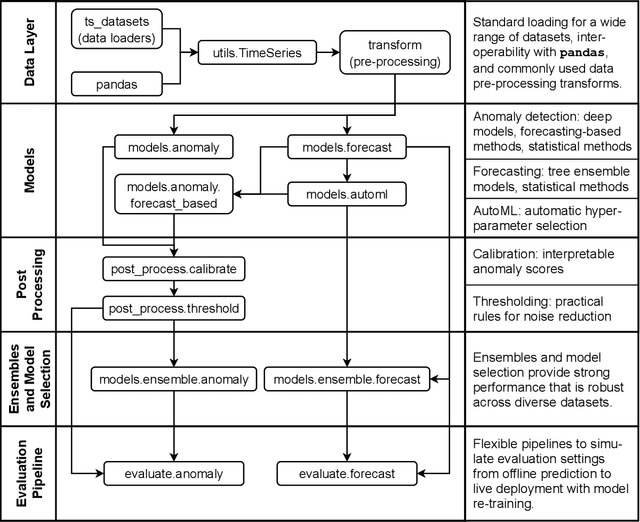
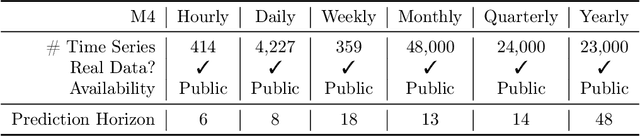

We introduce Merlion, an open-source machine learning library for time series. It features a unified interface for many commonly used models and datasets for anomaly detection and forecasting on both univariate and multivariate time series, along with standard pre/post-processing layers. It has several modules to improve ease-of-use, including visualization, anomaly score calibration to improve interpetability, AutoML for hyperparameter tuning and model selection, and model ensembling. Merlion also provides a unique evaluation framework that simulates the live deployment and re-training of a model in production. This library aims to provide engineers and researchers a one-stop solution to rapidly develop models for their specific time series needs and benchmark them across multiple time series datasets. In this technical report, we highlight Merlion's architecture and major functionalities, and we report benchmark numbers across different baseline models and ensembles.
Deep Speech Synthesis from Articulatory Representations
Sep 13, 2022

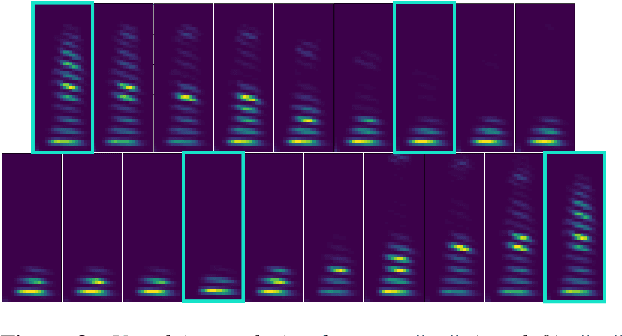
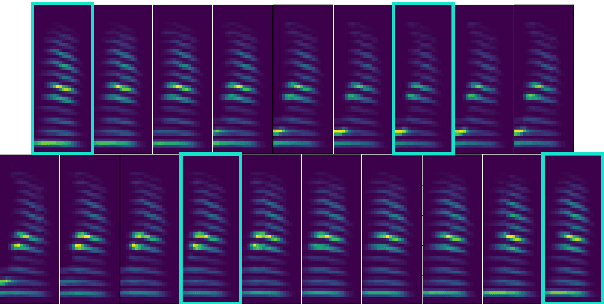
In the articulatory synthesis task, speech is synthesized from input features containing information about the physical behavior of the human vocal tract. This task provides a promising direction for speech synthesis research, as the articulatory space is compact, smooth, and interpretable. Current works have highlighted the potential for deep learning models to perform articulatory synthesis. However, it remains unclear whether these models can achieve the efficiency and fidelity of the human speech production system. To help bridge this gap, we propose a time-domain articulatory synthesis methodology and demonstrate its efficacy with both electromagnetic articulography (EMA) and synthetic articulatory feature inputs. Our model is computationally efficient and achieves a transcription word error rate (WER) of 18.5% for the EMA-to-speech task, yielding an improvement of 11.6% compared to prior work. Through interpolation experiments, we also highlight the generalizability and interpretability of our approach.
Estimation of Consistent Time Delays in Subsample via Auxiliary-Function-Based Iterative Updates
Mar 23, 2022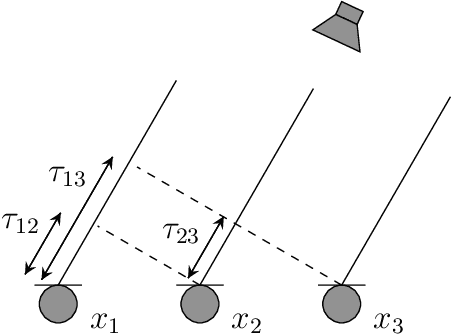
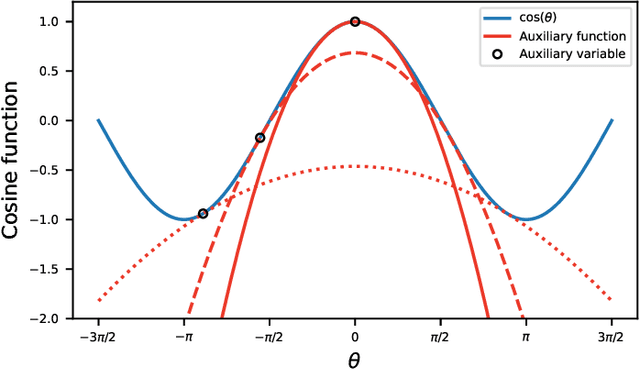
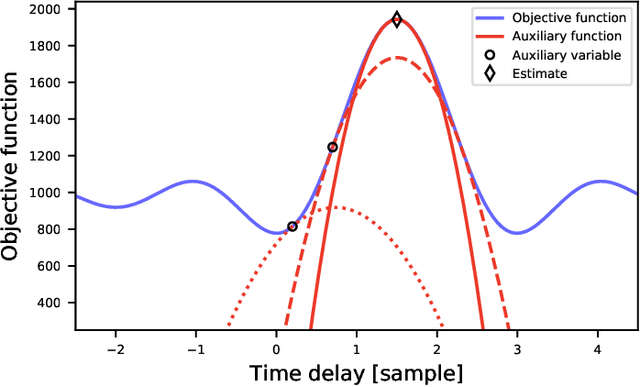
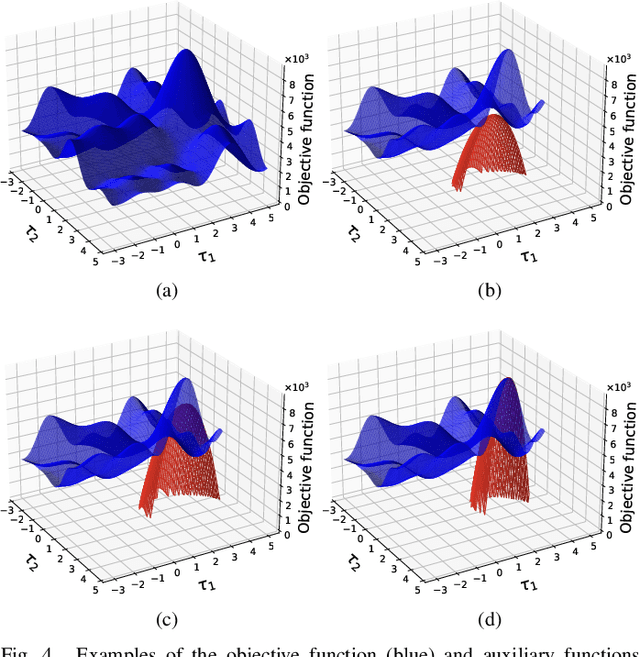
In this paper, we propose a new algorithm for the estimation of multiple time delays (TDs). Since a TD is a fundamental spatial cue for sensor array signal processing techniques, many methods for estimating it have been studied. Most of them, including generalized cross correlation (CC)-based methods, focus on how to estimate a TD between two sensors. These methods can then be easily adapted for multiple TDs by applying them to every pair of a reference sensor and another one. However, these pairwise methods can use only the partial information obtained by the selected sensors, resulting in inconsistent TD estimates and limited estimation accuracy. In contrast, we propose joint optimization of entire TD parameters, where spatial information obtained from all sensors is taken into account. We also introduce a consistent constraint regarding TD parameters to the observation model. We then consider a multidimensional CC (MCC) as the objective function, which is derived on the basis of maximum likelihood estimation. To maximize the MCC, which is a nonconvex function, we derive the auxiliary function for the MCC and design efficient update rules. We additionally estimate the amplitudes of the transfer functions for supporting the TD estimation, where we maximize the Rayleigh quotient under the non-negative constraint. We experimentally analyze essential features of the proposed method and evaluate its effectiveness in TD estimation. Code will be available at https://github.com/onolab-tmu/AuxTDE.
A Near-Optimal Algorithm for Univariate Zeroth-Order Budget Convex Optimization
Aug 13, 2022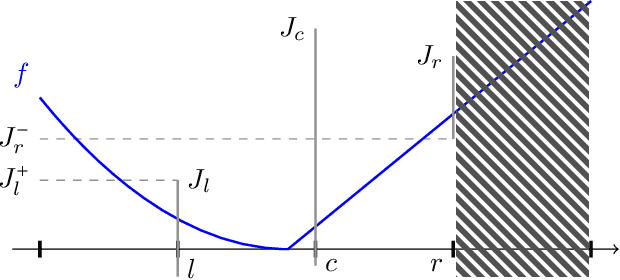
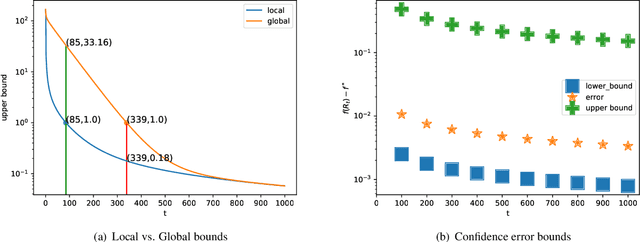
This paper studies a natural generalization of the problem of minimizing a univariate convex function $f$ by querying its values sequentially. At each time-step $t$, the optimizer can invest a budget $b_t$ in a query point $X_t$ of their choice to obtain a fuzzy evaluation of $f$ at $X_t$ whose accuracy depends on the amount of budget invested in $X_t$ across times. This setting is motivated by the minimization of objectives whose values can only be determined approximately through lengthy or expensive computations. We design an any-time parameter-free algorithm called Dyadic Search, for which we prove near-optimal optimization error guarantees. As a byproduct of our analysis, we show that the classical dependence on the global Lipschitz constant in the error bounds is an artifact of the granularity of the budget. Finally, we illustrate our theoretical findings with numerical simulations.