 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Jacobian Computation for Cumulative B-splines on SE(3) and Application to Continuous-Time Object Tracking
Jan 25, 2022
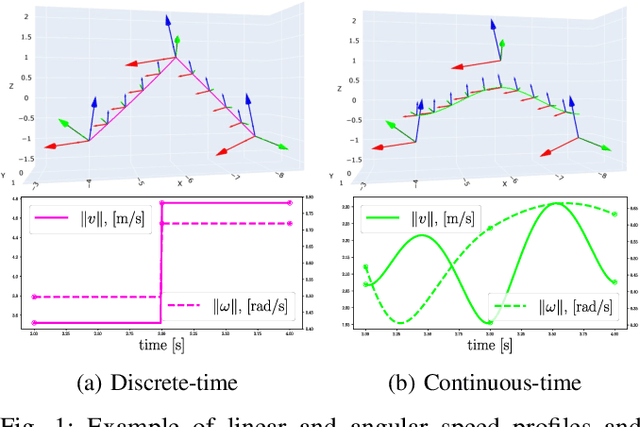
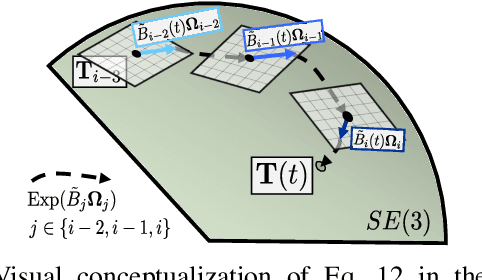
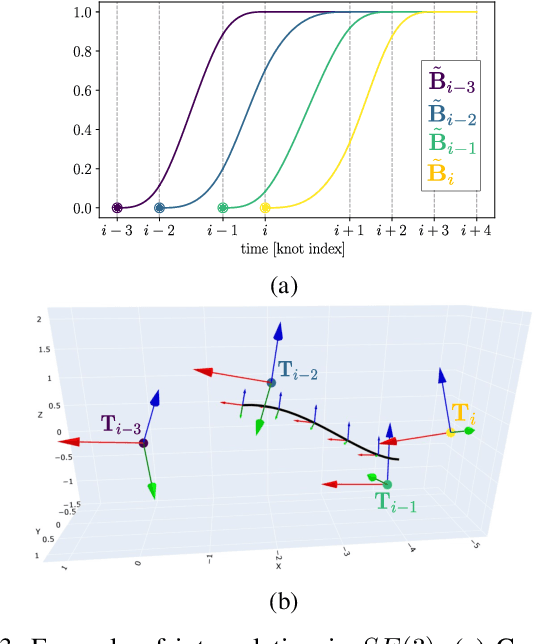

In this paper we propose a method that estimates the $SE(3)$ continuous trajectories (orientation and translation) of the dynamic rigid objects present in a scene, from multiple RGB-D views. Specifically, we fit the object trajectories to cumulative B-Splines curves, which allow us to interpolate, at any intermediate time stamp, not only their poses but also their linear and angular velocities and accelerations. Additionally, we derive in this work the analytical $SE(3)$ Jacobians needed by the optimization, being applicable to any other approach that uses this type of curves. To the best of our knowledge this is the first work that proposes 6-DoF continuous-time object tracking, which we endorse with significant computational cost reduction thanks to our analytical derivations. We evaluate our proposal in synthetic data and in a public benchmark, showing competitive results in localization and significant improvements in velocity estimation in comparison to discrete-time approaches.
On the Complexity of Finding Small Subgradients in Nonsmooth Optimization
Sep 21, 2022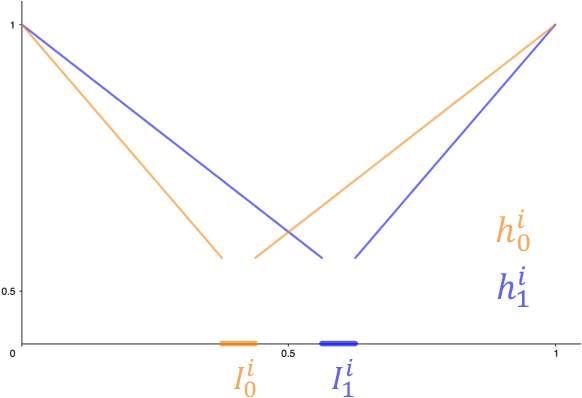
We study the oracle complexity of producing $(\delta,\epsilon)$-stationary points of Lipschitz functions, in the sense proposed by Zhang et al. [2020]. While there exist dimension-free randomized algorithms for producing such points within $\widetilde{O}(1/\delta\epsilon^3)$ first-order oracle calls, we show that no dimension-free rate can be achieved by a deterministic algorithm. On the other hand, we point out that this rate can be derandomized for smooth functions with merely a logarithmic dependence on the smoothness parameter. Moreover, we establish several lower bounds for this task which hold for any randomized algorithm, with or without convexity. Finally, we show how the convergence rate of finding $(\delta,\epsilon)$-stationary points can be improved in case the function is convex, a setting which we motivate by proving that in general no finite time algorithm can produce points with small subgradients even for convex functions.
Spikformer: When Spiking Neural Network Meets Transformer
Sep 29, 2022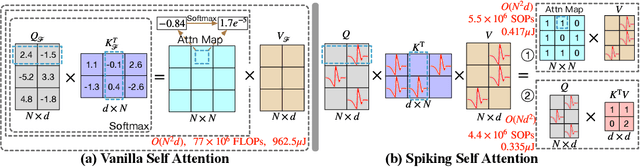
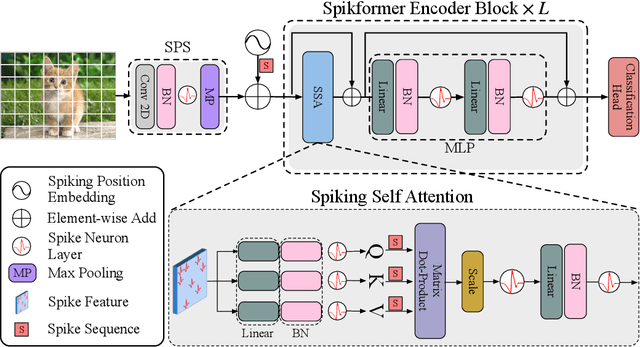
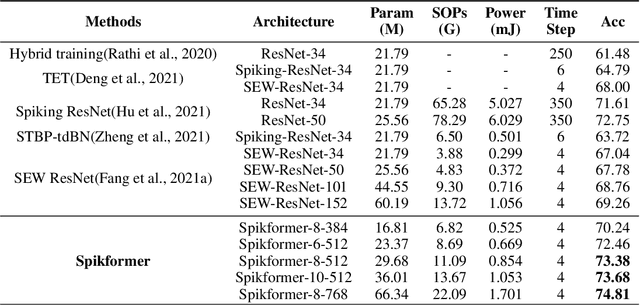
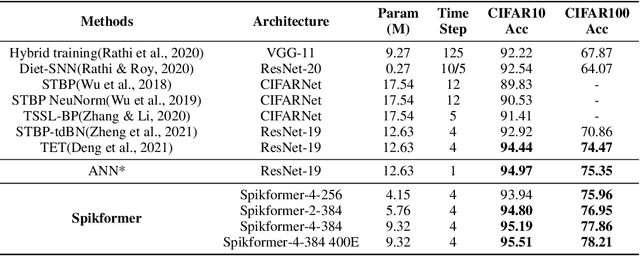
We consider two biologically plausible structures, the Spiking Neural Network (SNN) and the self-attention mechanism. The former offers an energy-efficient and event-driven paradigm for deep learning, while the latter has the ability to capture feature dependencies, enabling Transformer to achieve good performance. It is intuitively promising to explore the marriage between them. In this paper, we consider leveraging both self-attention capability and biological properties of SNNs, and propose a novel Spiking Self Attention (SSA) as well as a powerful framework, named Spiking Transformer (Spikformer). The SSA mechanism in Spikformer models the sparse visual feature by using spike-form Query, Key, and Value without softmax. Since its computation is sparse and avoids multiplication, SSA is efficient and has low computational energy consumption. It is shown that Spikformer with SSA can outperform the state-of-the-art SNNs-like frameworks in image classification on both neuromorphic and static datasets. Spikformer (66.3M parameters) with comparable size to SEW-ResNet-152 (60.2M,69.26%) can achieve 74.81% top1 accuracy on ImageNet using 4 time steps, which is the state-of-the-art in directly trained SNNs models.
Anomaly localization for copy detection patterns through print estimations
Sep 29, 2022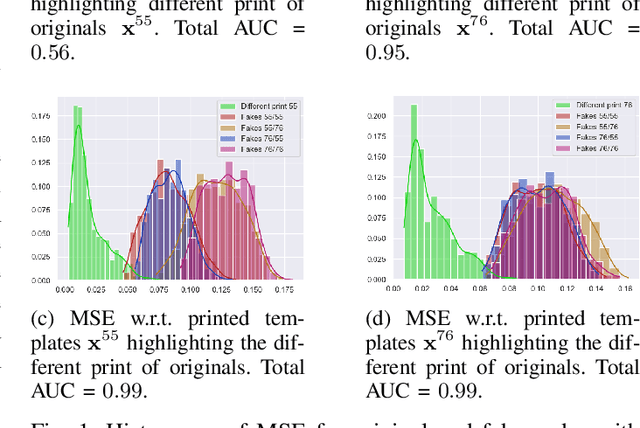
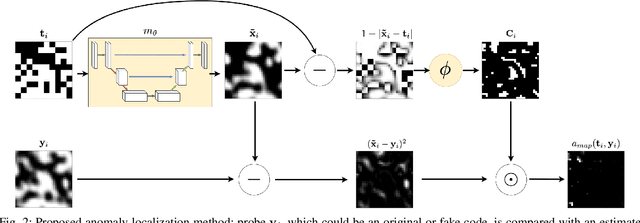
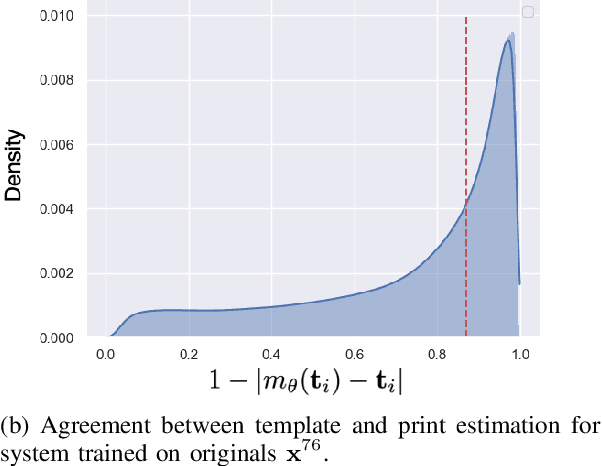
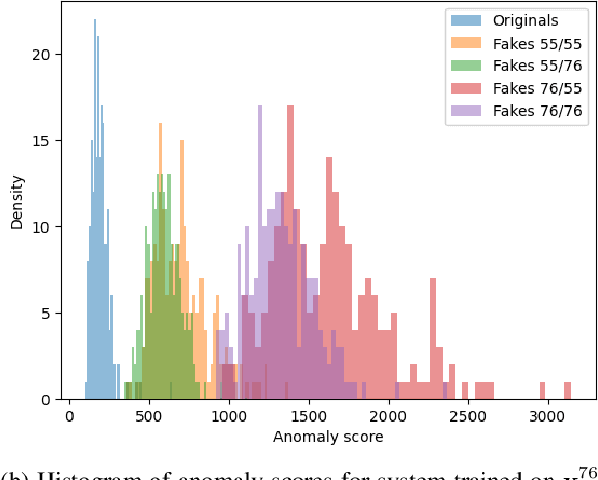
Copy detection patterns (CDP) are recent technologies for protecting products from counterfeiting. However, in contrast to traditional copy fakes, deep learning-based fakes have shown to be hardly distinguishable from originals by traditional authentication systems. Systems based on classical supervised learning and digital templates assume knowledge of fake CDP at training time and cannot generalize to unseen types of fakes. Authentication based on printed copies of originals is an alternative that yields better results even for unseen fakes and simple authentication metrics but comes at the impractical cost of acquisition and storage of printed copies. In this work, to overcome these shortcomings, we design a machine learning (ML) based authentication system that only requires digital templates and printed original CDP for training, whereas authentication is based solely on digital templates, which are used to estimate original printed codes. The obtained results show that the proposed system can efficiently authenticate original and detect fake CDP by accurately locating the anomalies in the fake CDP. The empirical evaluation of the authentication system under investigation is performed on the original and ML-based fakes CDP printed on two industrial printers.
Learning an Efficient Terrain Representation for Haptic Localization of a Legged Robot
Sep 29, 2022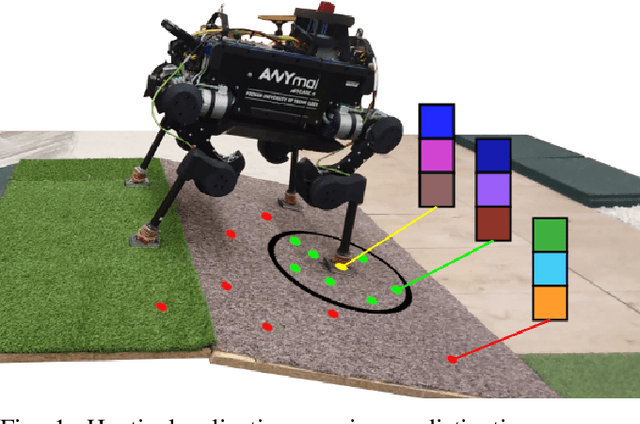
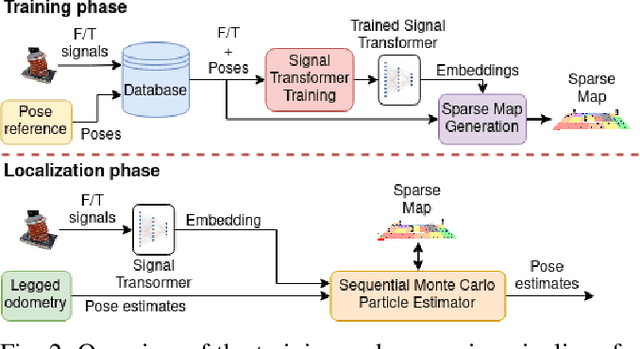
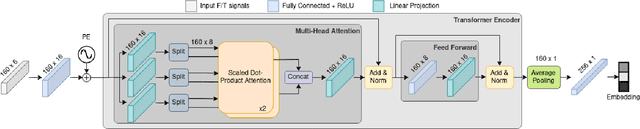
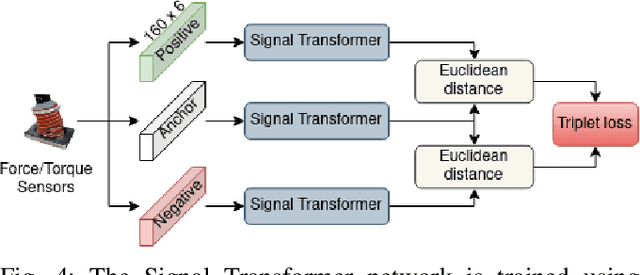
Although haptic sensing has recently been used for legged robot localization in extreme environments where a camera or LiDAR might fail, the problem of efficiently representing the haptic signatures in a learned prior map is still open. This paper introduces an approach to terrain representation for haptic localization inspired by recent trends in machine learning. It combines this approach with the proven Monte Carlo algorithm to obtain an accurate, computation-efficient, and practical method for localizing legged robots under adversarial environmental conditions. We apply the triplet loss concept to learn highly descriptive embeddings in a transformer-based neural network. As the training haptic data are not labeled, the positive and negative examples are discriminated by their geometric locations discovered while training. We demonstrate experimentally that the proposed approach outperforms by a large margin the previous solutions to haptic localization of legged robots concerning the accuracy, inference time, and the amount of data stored in the map. As far as we know, this is the first approach that completely removes the need to use a dense terrain map for accurate haptic localization, thus paving the way to practical applications.
Alexa, Predict My Flight Delay
Aug 21, 2022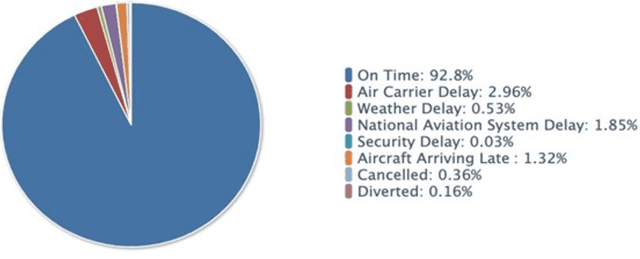
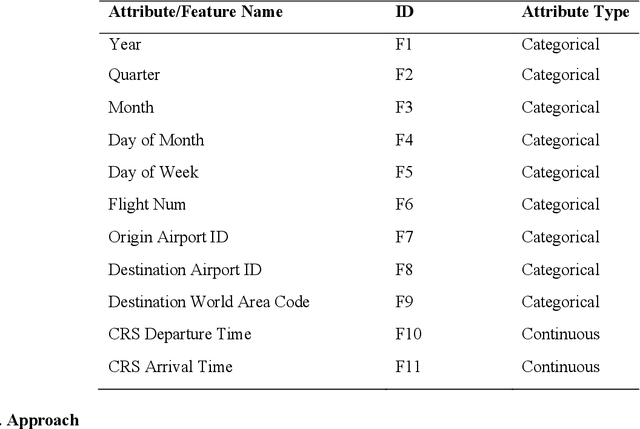
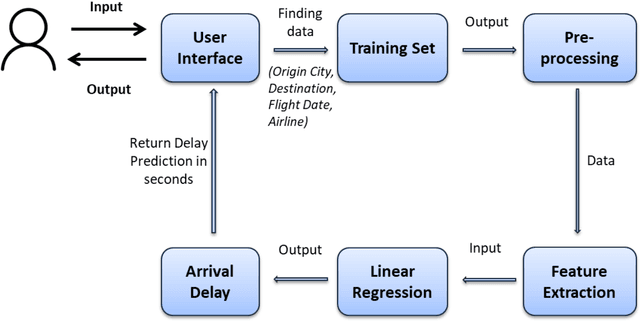
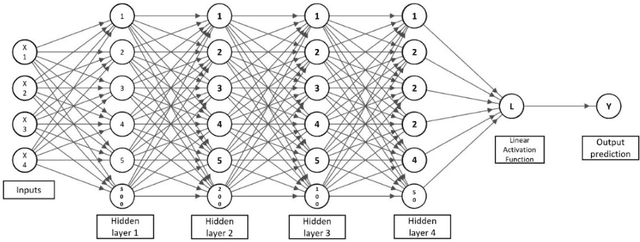
Airlines are critical today for carrying people and commodities on time. Any delay in the schedule of these planes can potentially disrupt the business and trade of thousands of employees at any given time. Therefore, precise flight delay prediction is beneficial for the aviation industry and passenger travel. Recent research has focused on using artificial intelligence algorithms to predict the possibility of flight delays. Earlier prediction algorithms were designed for a specific air route or airfield. Many present flight delay prediction algorithms rely on tiny samples and are challenging to understand, allowing almost no room for machine learning implementation. This research study develops a flight delay prediction system by analyzing data from domestic flights inside the United States of America. The proposed models learn about the factors that cause flight delays and cancellations and the link between departure and arrival delays.
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Sep 07, 2022
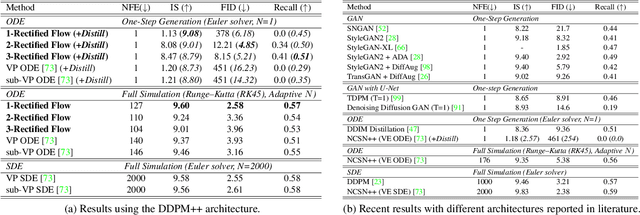


We present rectified flow, a surprisingly simple approach to learning (neural) ordinary differential equation (ODE) models to transport between two empirically observed distributions \pi_0 and \pi_1, hence providing a unified solution to generative modeling and domain transfer, among various other tasks involving distribution transport. The idea of rectified flow is to learn the ODE to follow the straight paths connecting the points drawn from \pi_0 and \pi_1 as much as possible. This is achieved by solving a straightforward nonlinear least squares optimization problem, which can be easily scaled to large models without introducing extra parameters beyond standard supervised learning. The straight paths are special and preferred because they are the shortest paths between two points, and can be simulated exactly without time discretization and hence yield computationally efficient models. We show that the procedure of learning a rectified flow from data, called rectification, turns an arbitrary coupling of \pi_0 and \pi_1 to a new deterministic coupling with provably non-increasing convex transport costs. In addition, recursively applying rectification allows us to obtain a sequence of flows with increasingly straight paths, which can be simulated accurately with coarse time discretization in the inference phase. In empirical studies, we show that rectified flow performs superbly on image generation, image-to-image translation, and domain adaptation. In particular, on image generation and translation, our method yields nearly straight flows that give high quality results even with a single Euler discretization step.
NasHD: Efficient ViT Architecture Performance Ranking using Hyperdimensional Computing
Sep 23, 2022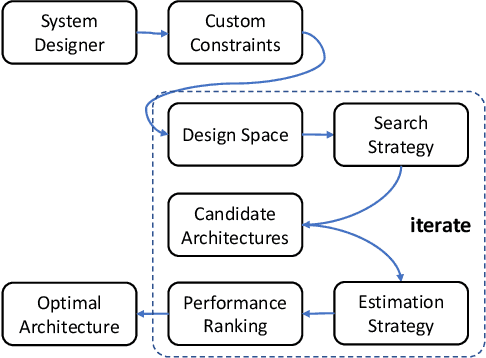
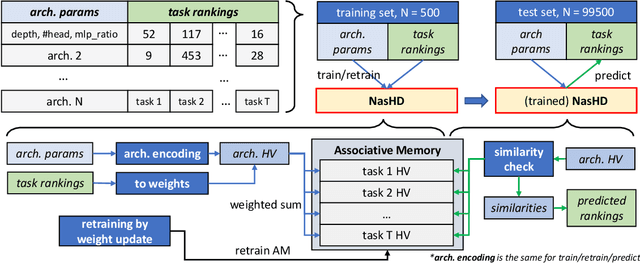
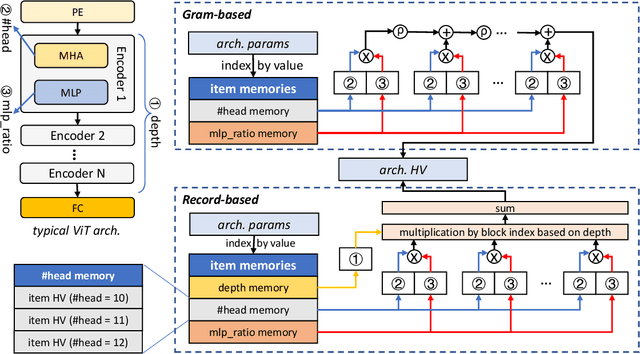
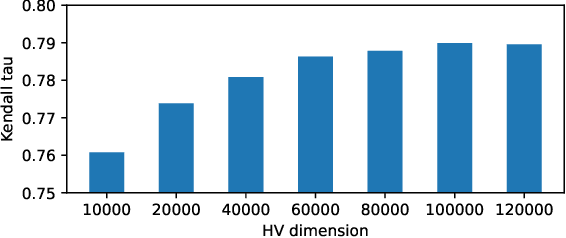
Neural Architecture Search (NAS) is an automated architecture engineering method for deep learning design automation, which serves as an alternative to the manual and error-prone process of model development, selection, evaluation and performance estimation. However, one major obstacle of NAS is the extremely demanding computation resource requirements and time-consuming iterations particularly when the dataset scales. In this paper, targeting at the emerging vision transformer (ViT), we present NasHD, a hyperdimensional computing based supervised learning model to rank the performance given the architectures and configurations. Different from other learning based methods, NasHD is faster thanks to the high parallel processing of HDC architecture. We also evaluated two HDC encoding schemes: Gram-based and Record-based of NasHD on their performance and efficiency. On the VIMER-UFO benchmark dataset of 8 applications from a diverse range of domains, NasHD Record can rank the performance of nearly 100K vision transformer models with about 1 minute while still achieving comparable results with sophisticated models.
Self-move and Other-move: Quantum Categorical Foundations of Japanese
Oct 10, 2022

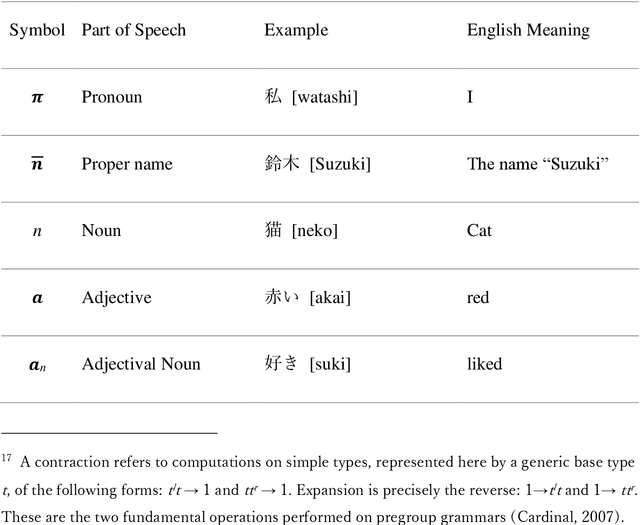

The purpose of this work is to contribute toward the larger goal of creating a Quantum Natural Language Processing (QNLP) translator program. This work contributes original diagrammatic representations of the Japanese language based on prior work that accomplished on the English language based on category theory. The germane differences between the English and Japanese languages are emphasized to help address English language bias in the current body of research. Additionally, topological principles of these diagrams and many potential avenues for further research are proposed. Why is this endeavor important? Hundreds of languages have developed over the course of millennia coinciding with the evolution of human interaction across time and geographic location. These languages are foundational to human survival, experience, flourishing, and living the good life. They are also, however, the strongest barrier between people groups. Over the last several decades, advancements in Natural Language Processing (NLP) have made it easier to bridge the gap between individuals who do not share a common language or culture. Tools like Google Translate and DeepL make it easier than ever before to share our experiences with people globally. Nevertheless, these tools are still inadequate as they fail to convey our ideas across the language barrier fluently, leaving people feeling anxious and embarrassed. This is particularly true of languages born out of substantially different cultures, such as English and Japanese. Quantum computers offer the best chance to achieve translation fluency in that they are better suited to simulating the natural world and natural phenomenon such as natural speech. Keywords: category theory, DisCoCat, DisCoCirc, Japanese grammar, English grammar, translation, topology, Quantum Natural Language Processing, Natural Language Processing
Data-Driven Machine Learning Models for a Multi-Objective Flapping Fin Unmanned Underwater Vehicle Control System
Sep 14, 2022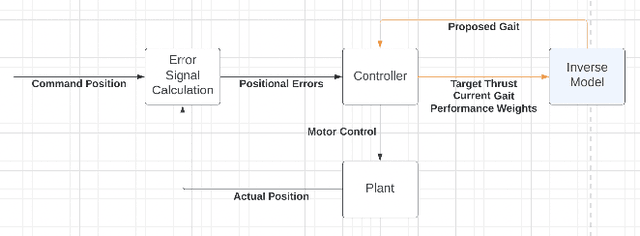

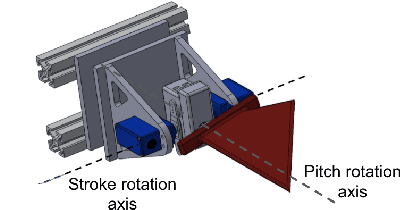
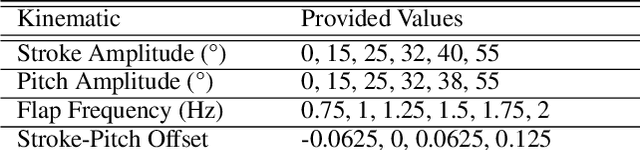
Flapping-fin unmanned underwater vehicle (UUV) propulsion systems provide high maneuverability for naval tasks such as surveillance and terrain exploration. Recent work has explored the use of time-series neural network surrogate models to predict thrust from vehicle design and fin kinematics. We develop a search-based inverse model that leverages a kinematics-to-thrust neural network model for control system design. Our inverse model finds a set of fin kinematics with the multi-objective goal of reaching a target thrust and creating a smooth kinematic transition between flapping cycles. We demonstrate how a control system integrating this inverse model can make online, cycle-to-cycle adjustments to prioritize different system objectives.