 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Suture Thread Spline Reconstruction from Endoscopic Images for Robotic Surgery with Reliability-driven Keypoint Detection
Sep 27, 2022
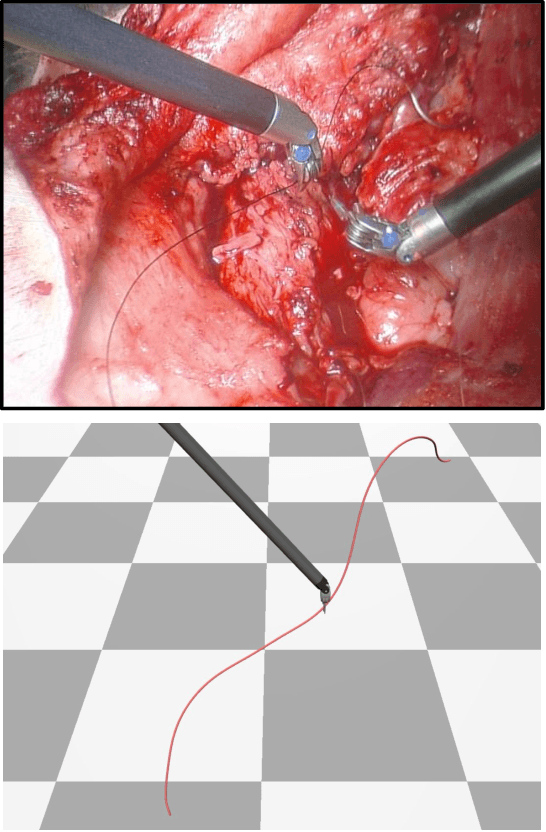
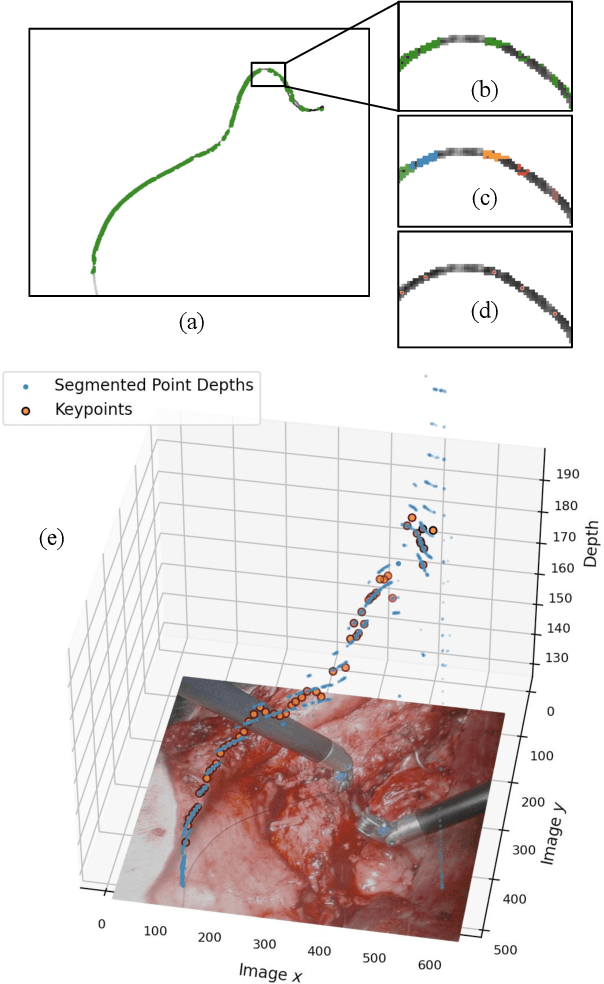
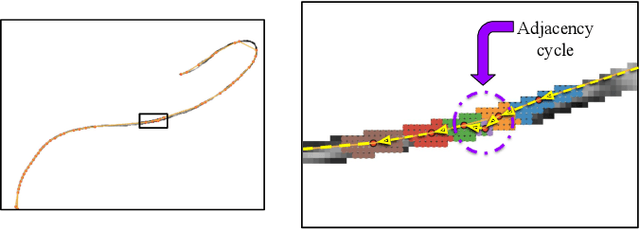
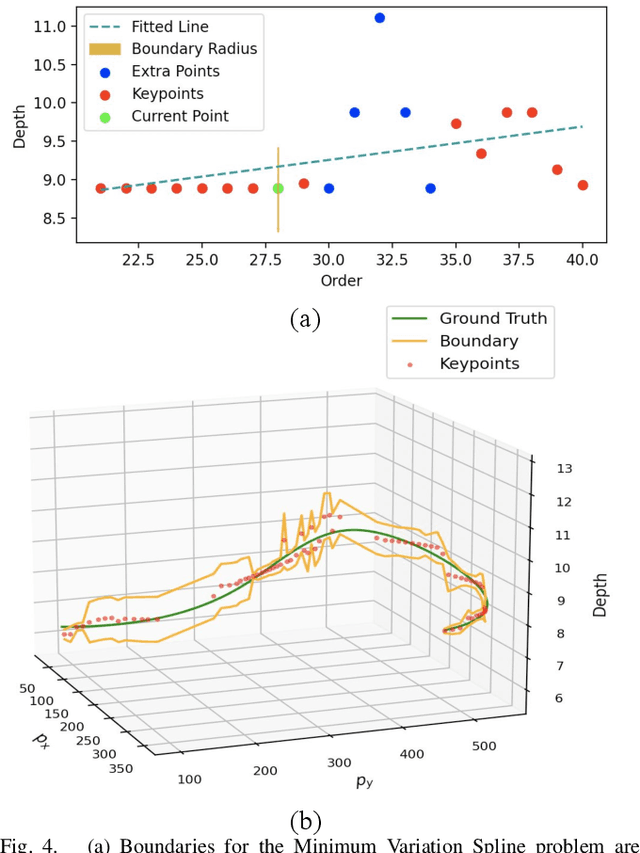
Automating the process of manipulating and delivering sutures during robotic surgery is a prominent problem at the frontier of surgical robotics, as automating this task can significantly reduce surgeons' fatigue during tele-operated surgery and allow them to spend more time addressing higher-level clinical decision making. Accomplishing autonomous suturing and suture manipulation in the real world requires accurate suture thread localization and reconstruction, the process of creating a 3D shape representation of suture thread from 2D stereo camera surgical image pairs. This is a very challenging problem due to how limited pixel information is available for the threads, as well as their sensitivity to lighting and specular reflection. We present a suture thread reconstruction work that uses reliable keypoints and a Minimum Variation Spline (MVS) smoothing optimization to construct a 3D centerline from a segmented surgical image pair. This method is comparable to previous suture thread reconstruction works, with the possible benefit of increased accuracy of grasping point estimation. Our code and datasets will be available at: https://github.com/ucsdarclab/thread-reconstruction.
Change Detection for Local Explainability in Evolving Data Streams
Sep 06, 2022
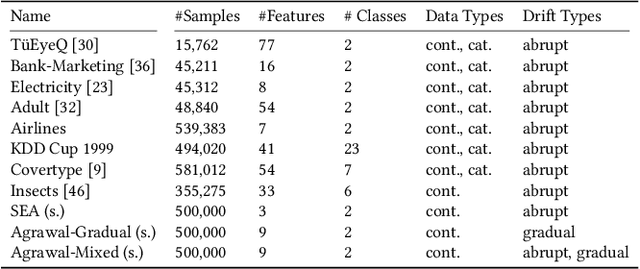
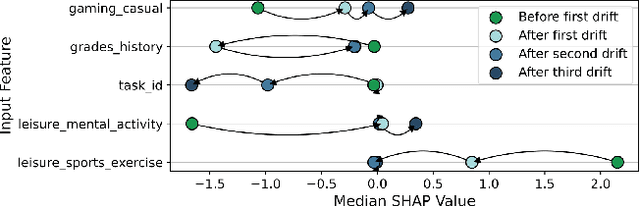
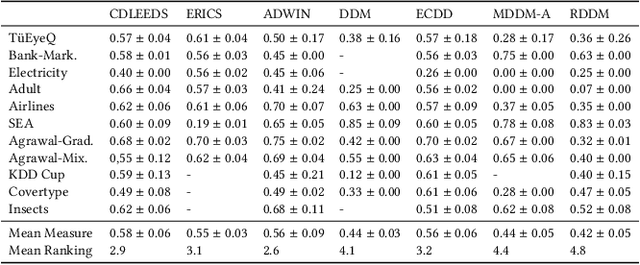
As complex machine learning models are increasingly used in sensitive applications like banking, trading or credit scoring, there is a growing demand for reliable explanation mechanisms. Local feature attribution methods have become a popular technique for post-hoc and model-agnostic explanations. However, attribution methods typically assume a stationary environment in which the predictive model has been trained and remains stable. As a result, it is often unclear how local attributions behave in realistic, constantly evolving settings such as streaming and online applications. In this paper, we discuss the impact of temporal change on local feature attributions. In particular, we show that local attributions can become obsolete each time the predictive model is updated or concept drift alters the data generating distribution. Consequently, local feature attributions in data streams provide high explanatory power only when combined with a mechanism that allows us to detect and respond to local changes over time. To this end, we present CDLEEDS, a flexible and model-agnostic framework for detecting local change and concept drift. CDLEEDS serves as an intuitive extension of attribution-based explanation techniques to identify outdated local attributions and enable more targeted recalculations. In experiments, we also show that the proposed framework can reliably detect both local and global concept drift. Accordingly, our work contributes to a more meaningful and robust explainability in online machine learning.
Stochastic Identification-based Active Sensing Acousto-Ultrasound SHM Using Stationary Time Series Models
Jan 26, 2022In this work, a probabilistic damage detection and identification scheme using stochastic time series models in the context of acousto-ultrasound guided wave-based SHM is proposed, and its performance is assessed experimentally. In order to simplify the damage detection and identification process, model parameters are modified based on the singular value decomposition (SVD) as well as the principal component analysis (PCA)-based truncation approach. The modified model parameters are then used to estimate a statistical characteristic quantity that follows a chi-squared distribution. A probabilistic threshold is used instead of a user-defined margin to facilitate automatic damage detection. The method's effectiveness is assessed via multiple experiments using both metallic and composite coupons and under various damage scenarios using damage intersecting and damage non-intersecting paths. The results of the study confirm the high potential and effectiveness of the stochastic time series methods for guided wave-based damage detection and identification in a potentially automated way.
MLT-LE: predicting drug-target binding affinity with multi-task residual neural networks
Sep 13, 2022

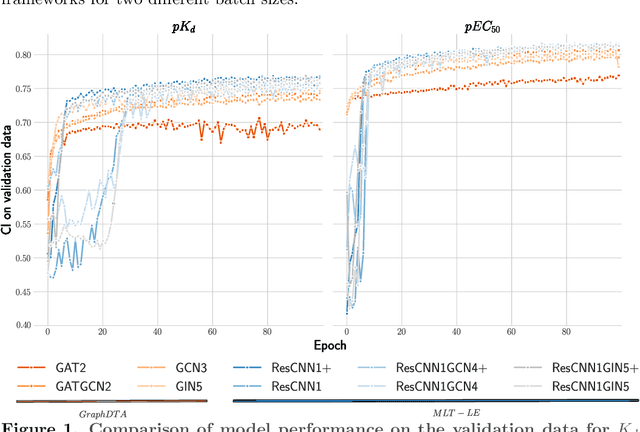
Assessing drug-target affinity is a critical step in the drug discovery and development process, but to obtain such data experimentally is both time consuming and expensive. For this reason, computational methods for predicting binding strength are being widely developed. However, these methods typically use a single-task approach for prediction, thus ignoring the additional information that can be extracted from the data and used to drive the learning process. Thereafter in this work, we present a multi-task approach for binding strength prediction. Our results suggest that these prediction can indeed benefit from a multi-task learning approach, by utilizing added information from related tasks and multi-task induced regularization.
Learning-Based Dimensionality Reduction for Computing Compact and Effective Local Feature Descriptors
Sep 27, 2022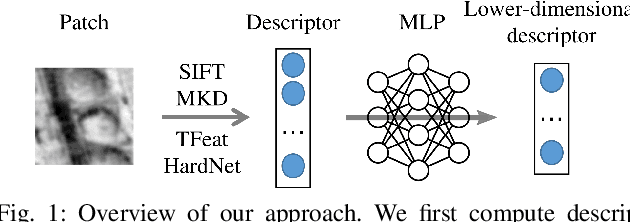
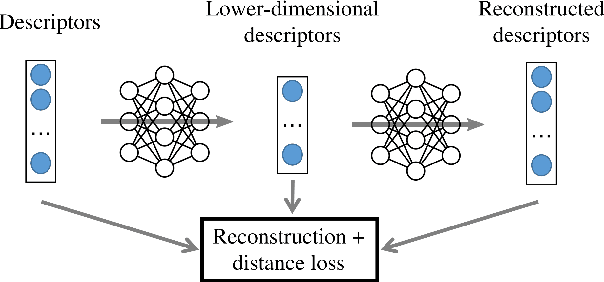
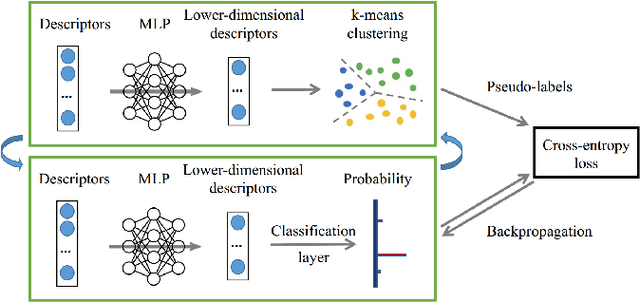
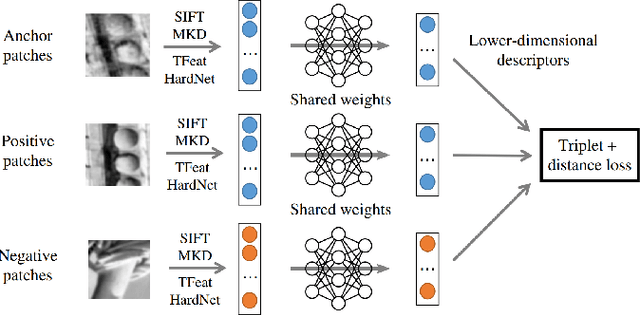
A distinctive representation of image patches in form of features is a key component of many computer vision and robotics tasks, such as image matching, image retrieval, and visual localization. State-of-the-art descriptors, from hand-crafted descriptors such as SIFT to learned ones such as HardNet, are usually high dimensional; 128 dimensions or even more. The higher the dimensionality, the larger the memory consumption and computational time for approaches using such descriptors. In this paper, we investigate multi-layer perceptrons (MLPs) to extract low-dimensional but high-quality descriptors. We thoroughly analyze our method in unsupervised, self-supervised, and supervised settings, and evaluate the dimensionality reduction results on four representative descriptors. We consider different applications, including visual localization, patch verification, image matching and retrieval. The experiments show that our lightweight MLPs achieve better dimensionality reduction than PCA. The lower-dimensional descriptors generated by our approach outperform the original higher-dimensional descriptors in downstream tasks, especially for the hand-crafted ones. The code will be available at https://github.com/PRBonn/descriptor-dr.
Correlation Based Feature Subset Selection for Multivariate Time-Series Data
Nov 26, 2021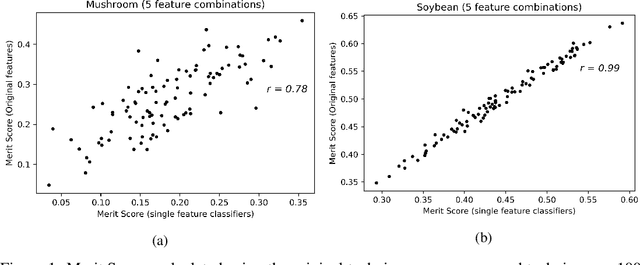
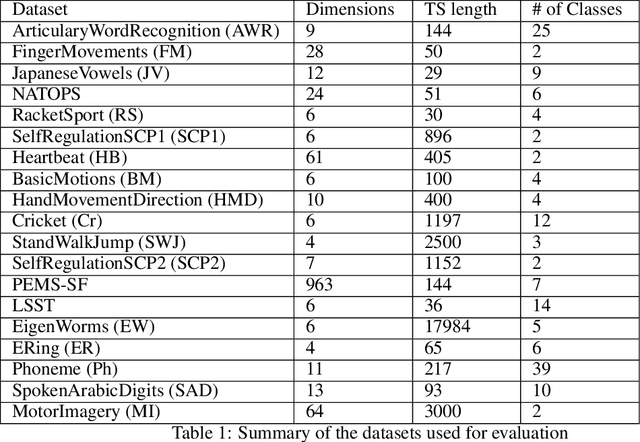
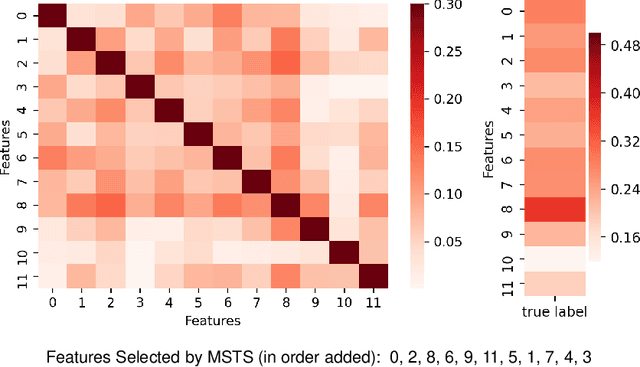
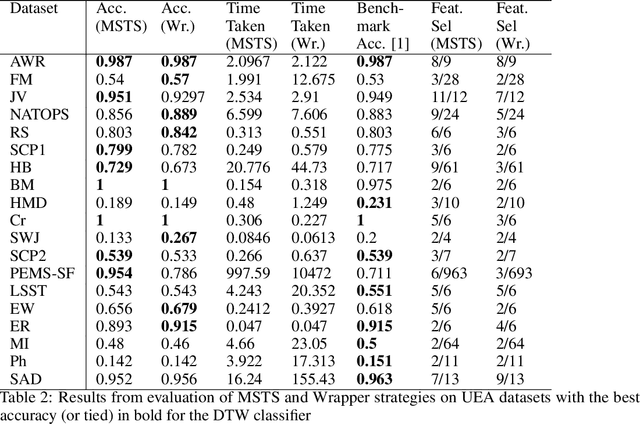
Correlations in streams of multivariate time series data means that typically, only a small subset of the features are required for a given data mining task. In this paper, we propose a technique which we call Merit Score for Time-Series data (MSTS) that does feature subset selection based on the correlation patterns of single feature classifier outputs. We assign a Merit Score to the feature subsets which is used as the basis for selecting 'good' feature subsets. The proposed technique is evaluated on datasets from the UEA multivariate time series archive and is compared against a Wrapper approach for feature subset selection. MSTS is shown to be effective for feature subset selection and is in particular effective as a data reduction technique. MSTS is shown here to be computationally more efficient than the Wrapper strategy in selecting a suitable feature subset, being more than 100 times faster for some larger datasets while also maintaining a good classification accuracy.
Multi-Field De-interlacing using Deformable Convolution Residual Blocks and Self-Attention
Sep 21, 2022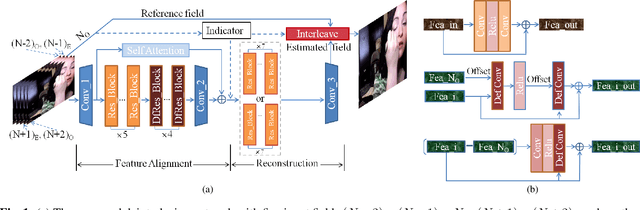
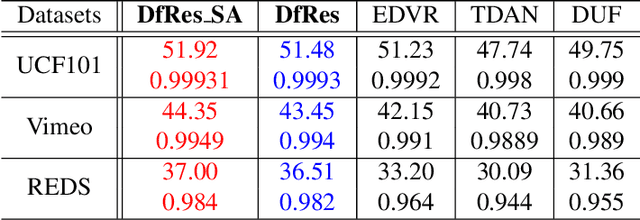
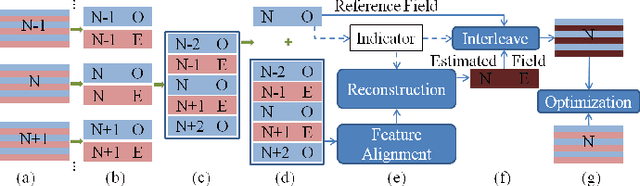

Although deep learning has made significant impact on image/video restoration and super-resolution, learned deinterlacing has so far received less attention in academia or industry. This is despite deinterlacing is well-suited for supervised learning from synthetic data since the degradation model is known and fixed. In this paper, we propose a novel multi-field full frame-rate deinterlacing network, which adapts the state-of-the-art superresolution approaches to the deinterlacing task. Our model aligns features from adjacent fields to a reference field (to be deinterlaced) using both deformable convolution residual blocks and self attention. Our extensive experimental results demonstrate that the proposed method provides state-of-the-art deinterlacing results in terms of both numerical and perceptual performance. At the time of writing, our model ranks first in the Full FrameRate LeaderBoard at https://videoprocessing.ai/benchmarks/deinterlacer.html
Decentralized Coordination in Partially Observable Queueing Networks
Aug 29, 2022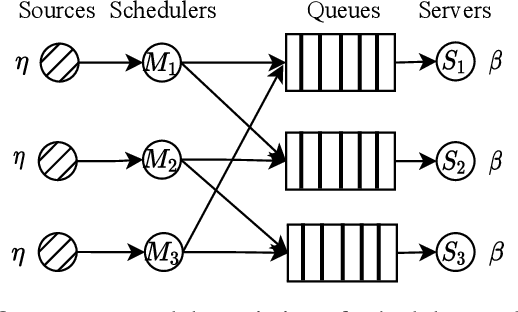
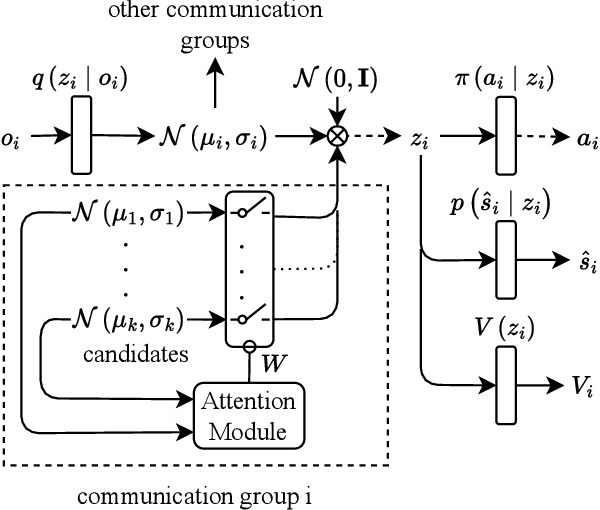
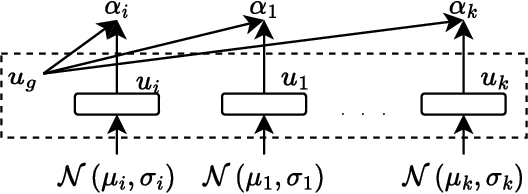
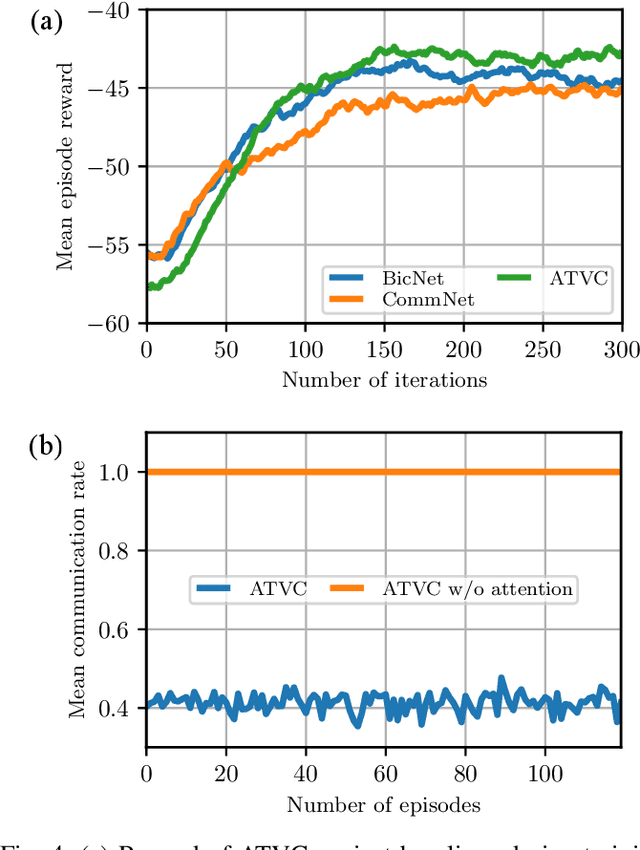
We consider communication in a fully cooperative multi-agent system, where the agents have partial observation of the environment and must act jointly to maximize the overall reward. We have a discrete-time queueing network where agents route packets to queues based only on the partial information of the current queue lengths. The queues have limited buffer capacity, so packet drops happen when they are sent to a full queue. In this work, we implemented a communication channel for the agents to share their information in order to reduce the packet drop rate. For efficient information sharing we use an attention-based communication model, called ATVC, to select informative messages from other agents. The agents then infer the state of queues using a combination of the variational auto-encoder, VAE, and product-of-experts, PoE, model. Ultimately, the agents learn what they need to communicate and with whom, instead of communicating all the time with everyone. We also show empirically that ATVC is able to infer the true state of the queues and leads to a policy which outperforms existing baselines.
Combined Dynamic Virtual Spatiotemporal Graph Mapping for Traffic Prediction
Oct 03, 2022
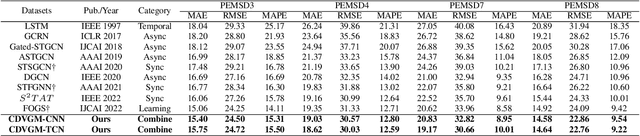
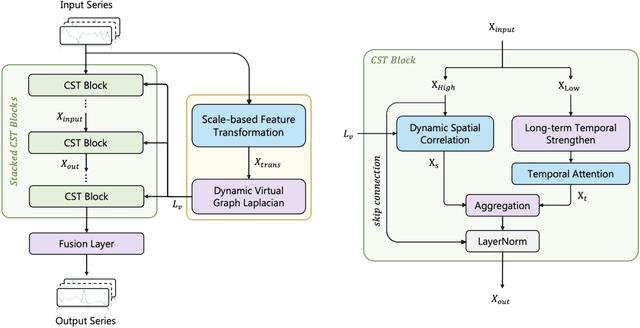
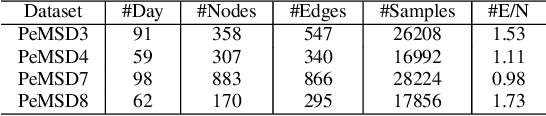
The continuous expansion of the urban construction scale has recently contributed to the demand for the dynamics of traffic intersections that are managed, making adaptive modellings become a hot topic. Existing deep learning methods are powerful to fit complex heterogeneous graphs. However, they still have drawbacks, which can be roughly classified into two categories, 1) spatiotemporal async-modelling approaches separately consider temporal and spatial dependencies, resulting in weak generalization and large instability while aggregating; 2) spatiotemporal sync-modelling is hard to capture long-term temporal dependencies because of the local receptive field. In order to overcome above challenges, a \textbf{C}ombined \textbf{D}ynamic \textbf{V}irtual spatiotemporal \textbf{G}raph \textbf{M}apping \textbf{(CDVGM)} is proposed in this work. The contributions are the following: 1) a dynamic virtual graph Laplacian ($DVGL$) is designed, which considers both the spatial signal passing and the temporal features simultaneously; 2) the Long-term Temporal Strengthen model ($LT^2S$) for improving the stability of time series forecasting; Extensive experiments demonstrate that CDVGM has excellent performances of fast convergence speed and low resource consumption and achieves the current SOTA effect in terms of both accuracy and generalization. The code is available at \hyperlink{https://github.com/Dandelionym/CDVGM.}{https://github.com/Dandelionym/CDVGM.}
Nonstationary data stream classification with online active learning and siamese neural networks
Oct 03, 2022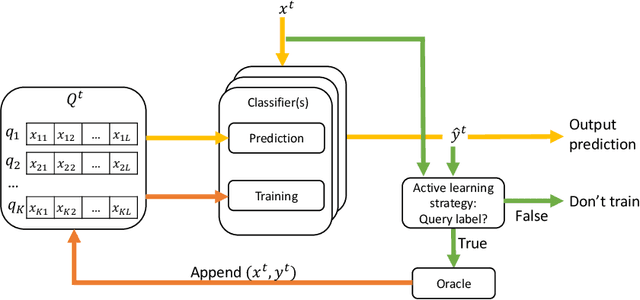
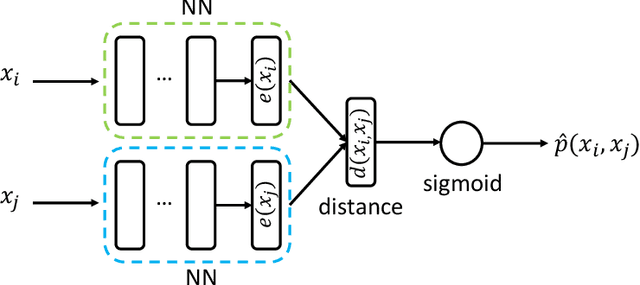
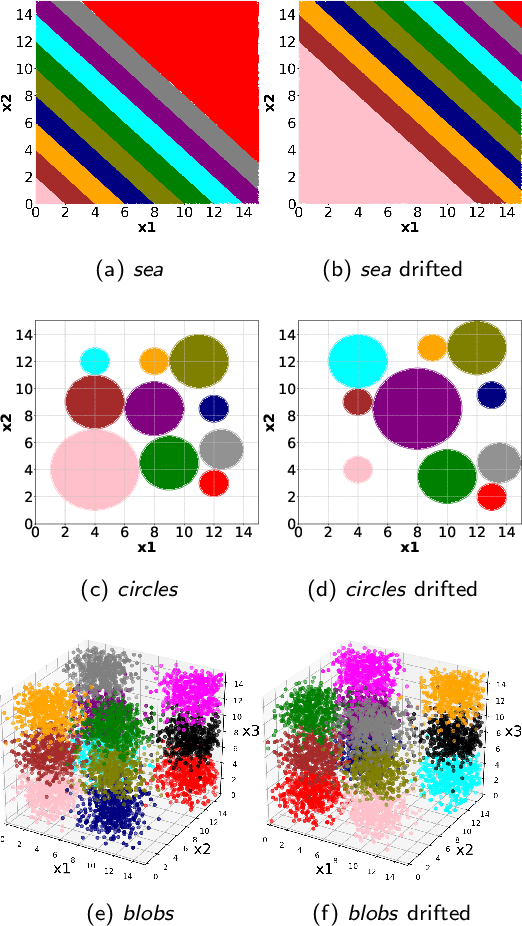
We have witnessed in recent years an ever-growing volume of information becoming available in a streaming manner in various application areas. As a result, there is an emerging need for online learning methods that train predictive models on-the-fly. A series of open challenges, however, hinder their deployment in practice. These are, learning as data arrive in real-time one-by-one, learning from data with limited ground truth information, learning from nonstationary data, and learning from severely imbalanced data, while occupying a limited amount of memory for data storage. We propose the ActiSiamese algorithm, which addresses these challenges by combining online active learning, siamese networks, and a multi-queue memory. It develops a new density-based active learning strategy which considers similarity in the latent (rather than the input) space. We conduct an extensive study that compares the role of different active learning budgets and strategies, the performance with/without memory, the performance with/without ensembling, in both synthetic and real-world datasets, under different data nonstationarity characteristics and class imbalance levels. ActiSiamese outperforms baseline and state-of-the-art algorithms, and is effective under severe imbalance, even only when a fraction of the arriving instances' labels is available. We publicly release our code to the community.
* Keywords: Incremental learning, Active learning, Data streams, Concept drift, Class imbalance