 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Is your noise correction noisy? PLS: Robustness to label noise with two stage detection
Oct 10, 2022
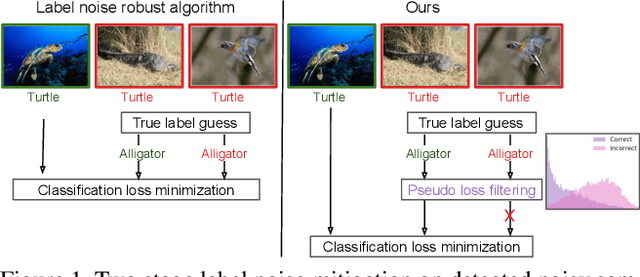

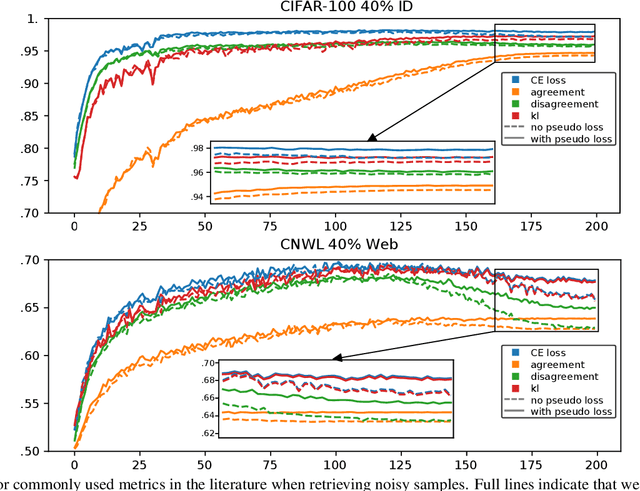
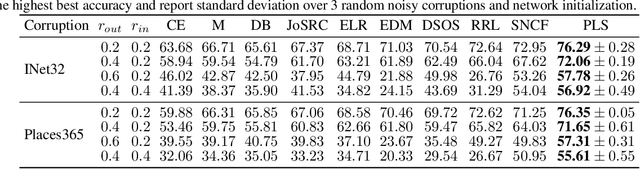
Designing robust algorithms capable of training accurate neural networks on uncurated datasets from the web has been the subject of much research as it reduces the need for time consuming human labor. The focus of many previous research contributions has been on the detection of different types of label noise; however, this paper proposes to improve the correction accuracy of noisy samples once they have been detected. In many state-of-the-art contributions, a two phase approach is adopted where the noisy samples are detected before guessing a corrected pseudo-label in a semi-supervised fashion. The guessed pseudo-labels are then used in the supervised objective without ensuring that the label guess is likely to be correct. This can lead to confirmation bias, which reduces the noise robustness. Here we propose the pseudo-loss, a simple metric that we find to be strongly correlated with pseudo-label correctness on noisy samples. Using the pseudo-loss, we dynamically down weight under-confident pseudo-labels throughout training to avoid confirmation bias and improve the network accuracy. We additionally propose to use a confidence guided contrastive objective that learns robust representation on an interpolated objective between class bound (supervised) for confidently corrected samples and unsupervised representation for under-confident label corrections. Experiments demonstrate the state-of-the-art performance of our Pseudo-Loss Selection (PLS) algorithm on a variety of benchmark datasets including curated data synthetically corrupted with in-distribution and out-of-distribution noise, and two real world web noise datasets. Our experiments are fully reproducible [github coming soon]
An Effective Technique for Increasing Capacity and Improving Bandwidth in 5G NB-IoT
Aug 29, 2022
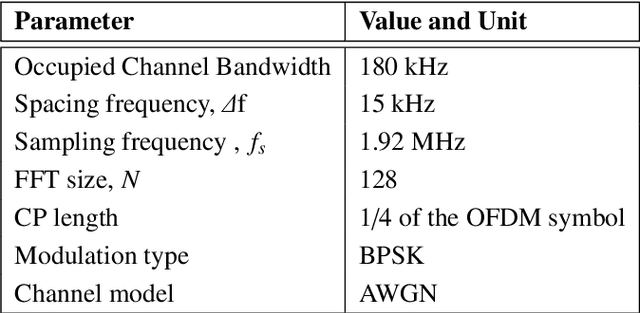
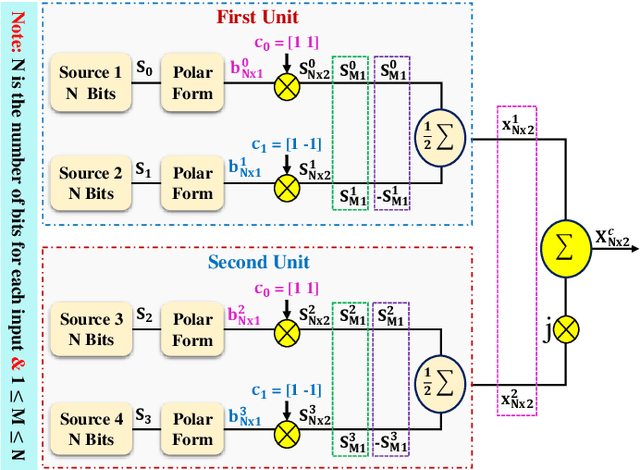

With hundreds of billions of the IoT connected devices, it is important for researchers to create effective resource management approach to satisfy the quality of service (QoS) requirements of 5th generation (5G) and beyond. Furthermore, wireless spectrum is increasingly scarce as demand for wireless services develops, demanding imaginative approaches to increase capacity within a limited spectral resource in order to meet service demands. In this article, the modified symbol time compression (M-STC) technique is suggested to paves the way for 5G networks and beyond to enhance the capacity and throughput. The M-STC method is a compressed signal waveform technique that increases the capacity by compressing the occupied bandwidth without increasing the complexity, losing data throughput or bit error rate (BER) performance. A comparative analysis is provided between the traditional orthogonal frequency division multiplexing (OFDM) system, OFDM using conventional symbol time compression (C-STC-OFDM) and OFDM using the proposed technique (M-STC-OFDM). The simulation results using Matlab-2021a show that the suggested method, M-STC-OFDM, drastically lowers the time needed for each OFDM signal by 75%. As a consequence, the M-STC-OFDM system decreases bandwidth (BW) by 75% when compared to a standard OFDM system (BW_OFDM = 180 kHz and BW_M-STC-OFDM = 45 kHz), while the C-STC-OFDM system reduces BW by 50% (BW_C-STC-OFDM = 90 kHz). Furthermore, using the M-STC-OFDM system reduces peak to average-power-ratio (PAPR) by 2.09 dB when compared to the standard OFDM system and 1.18 dB when compared to C-STC-OFDM with no BER deterioration. Moreover, as compared to the 16QAM-OFDM system, the proposed M-STC-OFDM system reduces the signal-to-noise-ratio (SNR) by 3.8 dB to transmit the same amount of data.
Efficient Calibration of Multi-Agent Market Simulators from Time Series with Bayesian Optimization
Dec 03, 2021
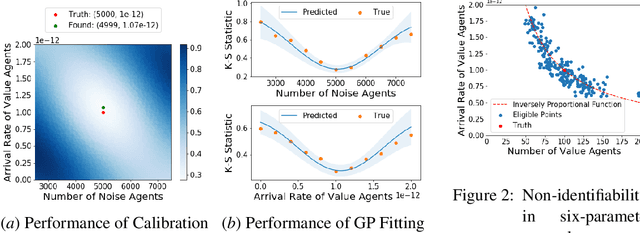

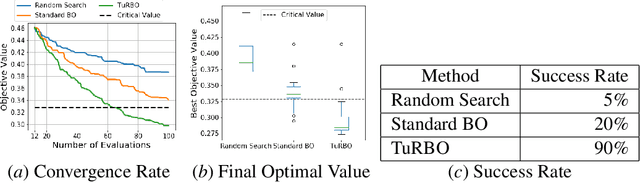
Multi-agent market simulation is commonly used to create an environment for downstream machine learning or reinforcement learning tasks, such as training or testing trading strategies before deploying them to real-time trading. In electronic trading markets only the price or volume time series, that result from interaction of multiple market participants, are typically directly observable. Therefore, multi-agent market environments need to be calibrated so that the time series that result from interaction of simulated agents resemble historical -- which amounts to solving a highly complex large-scale optimization problem. In this paper, we propose a simple and efficient framework for calibrating multi-agent market simulator parameters from historical time series observations. First, we consider a novel concept of eligibility set to bypass the potential non-identifiability issue. Second, we generalize the two-sample Kolmogorov-Smirnov (K-S) test with Bonferroni correction to test the similarity between two high-dimensional time series distributions, which gives a simple yet effective distance metric between the time series sample sets. Third, we suggest using Bayesian optimization (BO) and trust-region BO (TuRBO) to minimize the aforementioned distance metric. Finally, we demonstrate the efficiency of our framework using numerical experiments.
Using Full-Text Content to Characterize and Identify Best Seller Books
Oct 05, 2022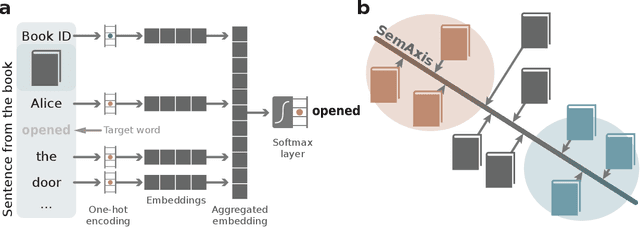
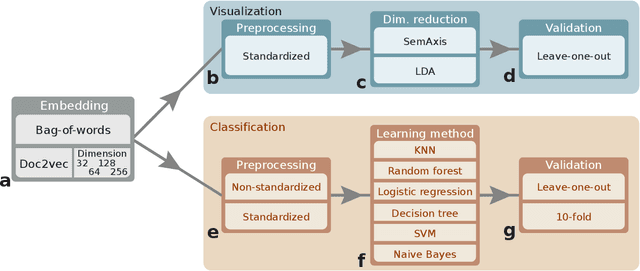
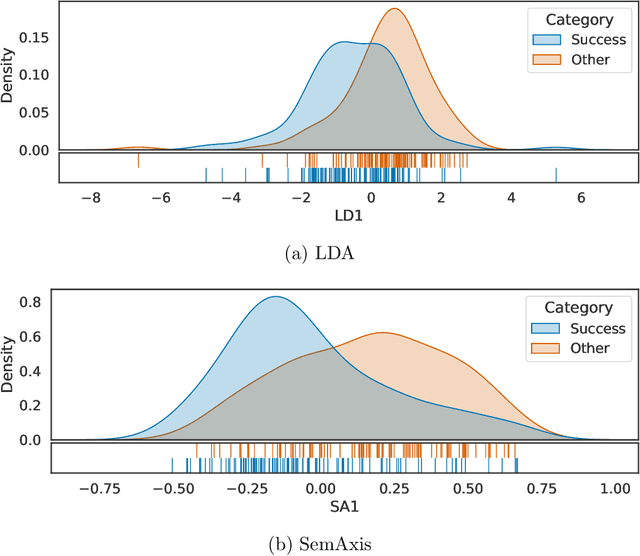
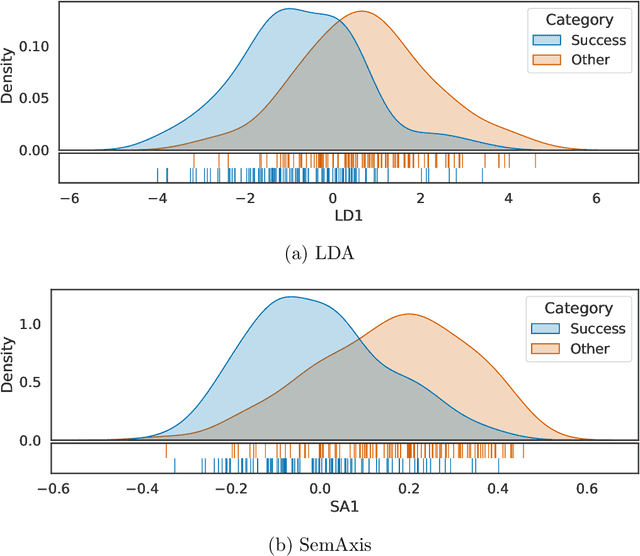
Artistic pieces can be studied from several perspectives, one example being their reception among readers over time. In the present work, we approach this interesting topic from the standpoint of literary works, particularly assessing the task of predicting whether a book will become a best seller. Dissimilarly from previous approaches, we focused on the full content of books and considered visualization and classification tasks. We employed visualization for the preliminary exploration of the data structure and properties, involving SemAxis and linear discriminant analyses. Then, to obtain quantitative and more objective results, we employed various classifiers. Such approaches were used along with a dataset containing (i) books published from 1895 to 1924 and consecrated as best sellers by the \emph{Publishers Weekly Bestseller Lists} and (ii) literary works published in the same period but not being mentioned in that list. Our comparison of methods revealed that the best-achieved result - combining a bag-of-words representation with a logistic regression classifier - led to an average accuracy of 0.75 both for the leave-one-out and 10-fold cross-validations. Such an outcome suggests that it is unfeasible to predict the success of books with high accuracy using only the full content of the texts. Nevertheless, our findings provide insights into the factors leading to the relative success of a literary work.
Revisiting Graph Contrastive Learning from the Perspective of Graph Spectrum
Oct 05, 2022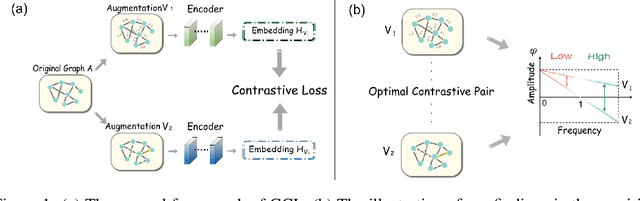

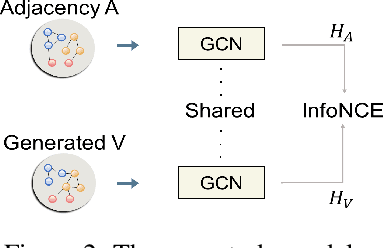
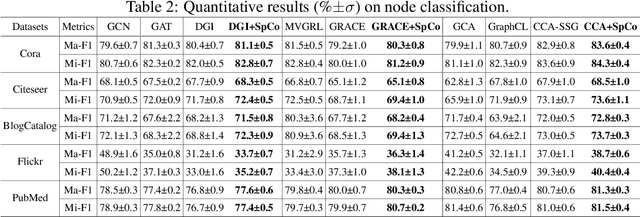
Graph Contrastive Learning (GCL), learning the node representations by augmenting graphs, has attracted considerable attentions. Despite the proliferation of various graph augmentation strategies, some fundamental questions still remain unclear: what information is essentially encoded into the learned representations by GCL? Are there some general graph augmentation rules behind different augmentations? If so, what are they and what insights can they bring? In this paper, we answer these questions by establishing the connection between GCL and graph spectrum. By an experimental investigation in spectral domain, we firstly find the General grAph augMEntation (GAME) rule for GCL, i.e., the difference of the high-frequency parts between two augmented graphs should be larger than that of low-frequency parts. This rule reveals the fundamental principle to revisit the current graph augmentations and design new effective graph augmentations. Then we theoretically prove that GCL is able to learn the invariance information by contrastive invariance theorem, together with our GAME rule, for the first time, we uncover that the learned representations by GCL essentially encode the low-frequency information, which explains why GCL works. Guided by this rule, we propose a spectral graph contrastive learning module (SpCo), which is a general and GCL-friendly plug-in. We combine it with different existing GCL models, and extensive experiments well demonstrate that it can further improve the performances of a wide variety of different GCL methods.
Approximating the full-field temperature evolution in 3D electronic systems from randomized "Minecraft" systems
Sep 21, 2022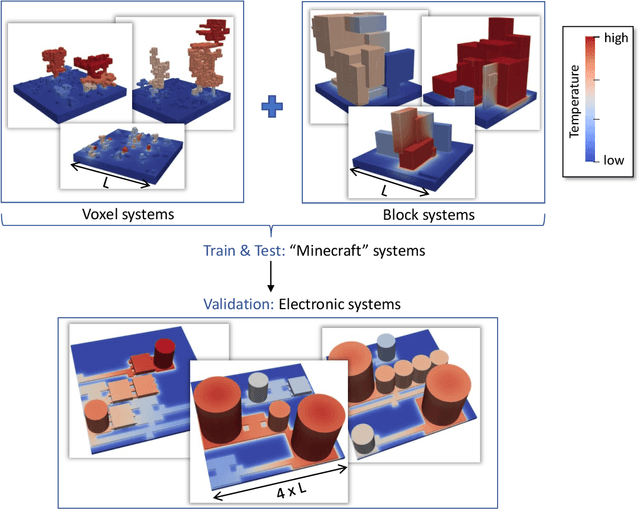
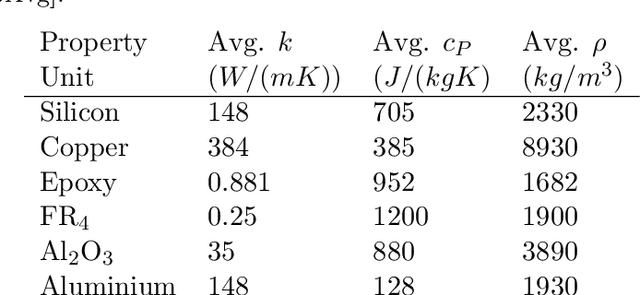
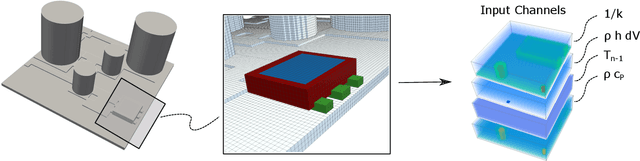
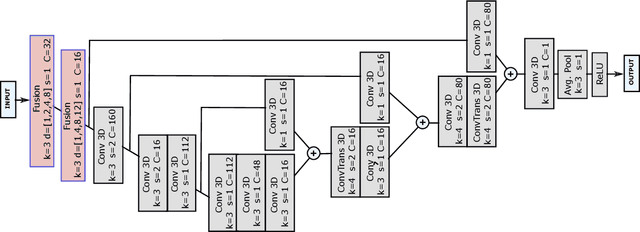
Neural Networks as fast physics simulators have a large potential for many engineering design tasks. Prerequisites for a wide-spread application are an easy-to-use workflow for generating training datasets in a reasonable time, and the capability of the network to generalize to unseen systems. In contrast to most previous works where training systems are similar to the evaluation dataset, we propose to adapt the type of training system to the network architecture. Specifically, we apply a fully convolutional network and, thus, design 3D systems of randomly located voxels with randomly assigned physical properties. The idea is tested for the transient heat diffusion in electronic systems. Training only on random "Minecraft" systems, we obtain good generalization to electronic systems four times as large as the training systems (one-step prediction error of 0.07% vs 0.8%).
IC-GVINS: A Robust, Real-time, INS-Centric GNSS-Visual-Inertial Navigation System for Wheeled Robot
Apr 11, 2022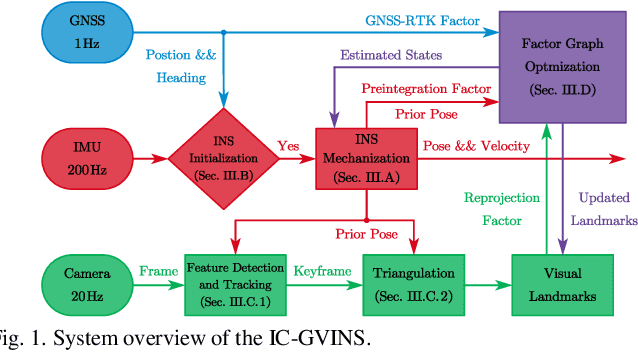
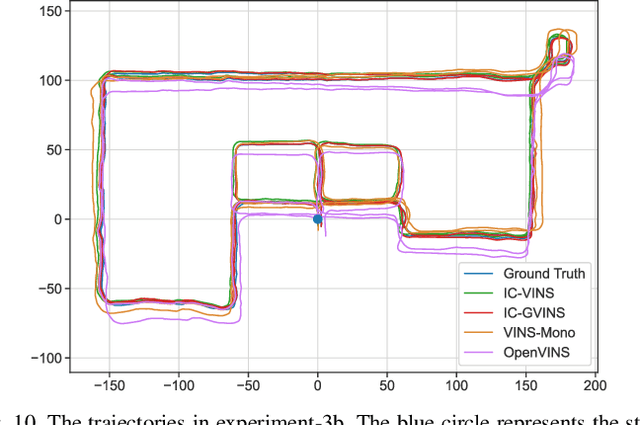
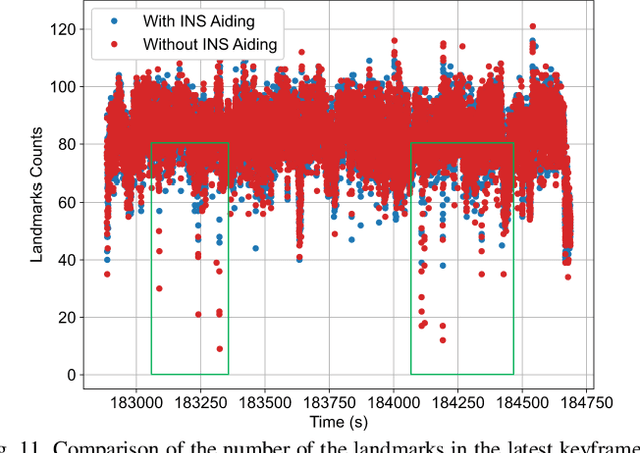
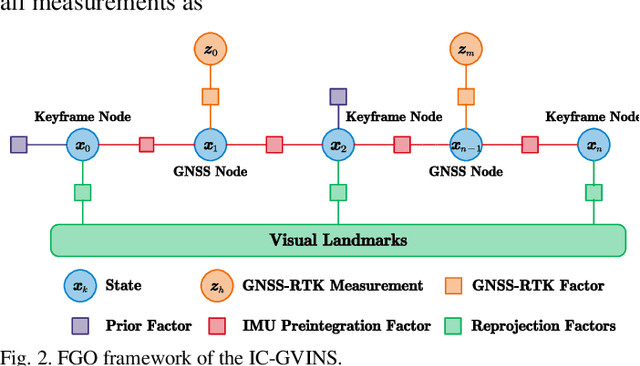
In this letter, we present a robust, real-time, inertial navigation system (INS)-Centric GNSS-Visual-Inertial navigation system (IC-GVINS) for wheeled robot, in which the precise INS is fully utilized in both the state estimation and visual process. To improve the system robustness, the INS information is employed during the whole keyframe-based visual process, with strict outlier-culling strategy. GNSS is adopted to perform an accurate and convenient initialization of the IC-GVINS, and is further employed to achieve absolute positioning in large-scale environments. The IMU, visual, and GNSS measurements are tightly fused within the framework of factor graph optimization. Dedicated experiments were conducted to evaluate the robustness and accuracy of the IC-GVINS on a wheeled robot. The IC-GVINS demonstrates superior robustness in various visual-degenerated scenes with moving objects. Compared to the state-of-the-art visual-inertial navigation systems, the proposed method yields improved robustness and accuracy in various environments. We open source our codes combined with the dataset on GitHub
One-Shot Learning of Stochastic Differential Equations with Computational Graph Completion
Sep 24, 2022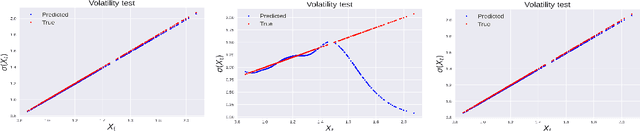

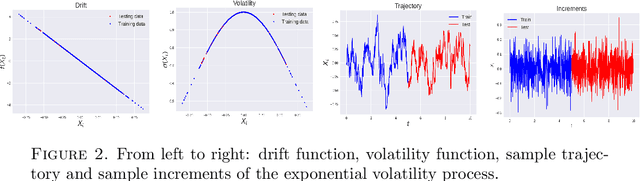

We consider the problem of learning Stochastic Differential Equations of the form $dX_t = f(X_t)dt+\sigma(X_t)dW_t $ from one sample trajectory. This problem is more challenging than learning deterministic dynamical systems because one sample trajectory only provides indirect information on the unknown functions $f$, $\sigma$, and stochastic process $dW_t$ representing the drift, the diffusion, and the stochastic forcing terms, respectively. We propose a simple kernel-based solution to this problem that can be decomposed as follows: (1) Represent the time-increment map $X_t \rightarrow X_{t+dt}$ as a Computational Graph in which $f$, $\sigma$ and $dW_t$ appear as unknown functions and random variables. (2) Complete the graph (approximate unknown functions and random variables) via Maximum a Posteriori Estimation (given the data) with Gaussian Process (GP) priors on the unknown functions. (3) Learn the covariance functions (kernels) of the GP priors from data with randomized cross-validation. Numerical experiments illustrate the efficacy, robustness, and scope of our method.
LEADER: Learning Attention over Driving Behaviors for Planning under Uncertainty
Sep 23, 2022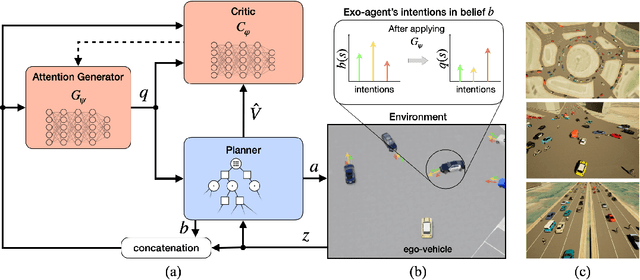

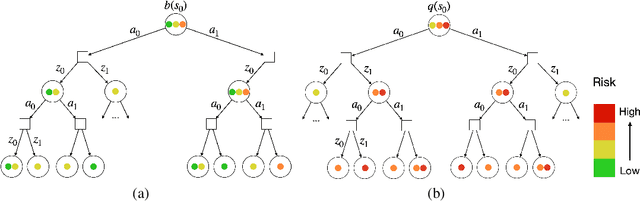
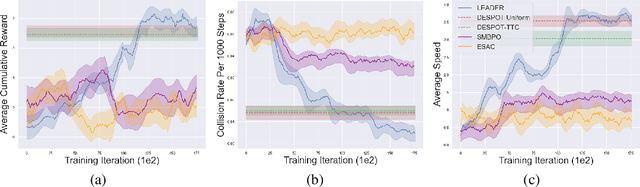
Uncertainty on human behaviors poses a significant challenge to autonomous driving in crowded urban environments. The partially observable Markov decision processes (POMDPs) offer a principled framework for planning under uncertainty, often leveraging Monte Carlo sampling to achieve online performance for complex tasks. However, sampling also raises safety concerns by potentially missing critical events. To address this, we propose a new algorithm, LEarning Attention over Driving bEhavioRs (LEADER), that learns to attend to critical human behaviors during planning. LEADER learns a neural network generator to provide attention over human behaviors in real-time situations. It integrates the attention into a belief-space planner, using importance sampling to bias reasoning towards critical events. To train the algorithm, we let the attention generator and the planner form a min-max game. By solving the min-max game, LEADER learns to perform risk-aware planning without human labeling.
In-situ animal behavior classification using knowledge distillation and fixed-point quantization
Sep 09, 2022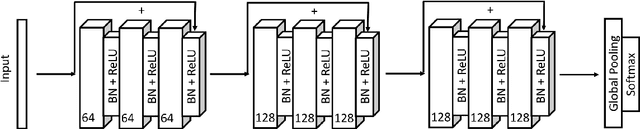
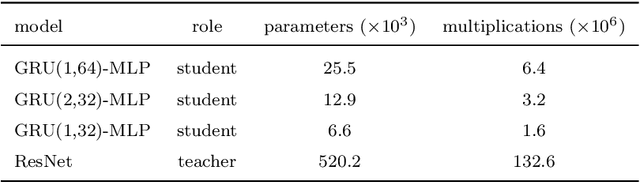
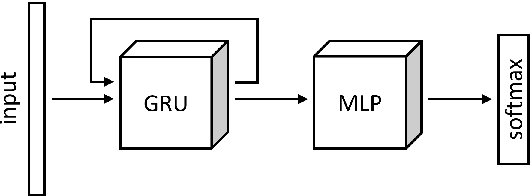
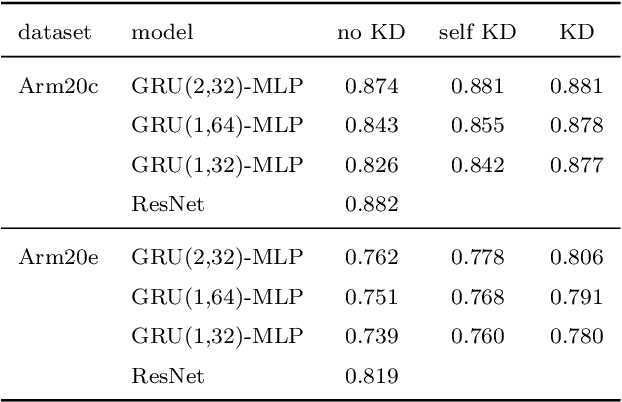
We explore the use of knowledge distillation (KD) for learning compact and accurate models that enable classification of animal behavior from accelerometry data on wearable devices. To this end, we take a deep and complex convolutional neural network, known as residual neural network (ResNet), as the teacher model. ResNet is specifically designed for multivariate time-series classification. We use ResNet to distil the knowledge of animal behavior classification datasets into soft labels, which consist of the predicted pseudo-probabilities of every class for each datapoint. We then use the soft labels to train our significantly less complex student models, which are based on the gated recurrent unit (GRU) and multilayer perceptron (MLP). The evaluation results using two real-world animal behavior classification datasets show that the classification accuracy of the student GRU-MLP models improves appreciably through KD, approaching that of the teacher ResNet model. To further reduce the computational and memory requirements of performing inference using the student models trained via KD, we utilize dynamic fixed-point quantization through an appropriate modification of the computational graphs of the models. We implement both unquantized and quantized versions of the developed KD-based models on the embedded systems of our purpose-built collar and ear tag devices to classify animal behavior in situ and in real time. The results corroborate the effectiveness of KD and quantization in improving the inference performance in terms of both classification accuracy and computational and memory efficiency.