 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Lead-lag detection and network clustering for multivariate time series with an application to the US equity market
Jan 20, 2022
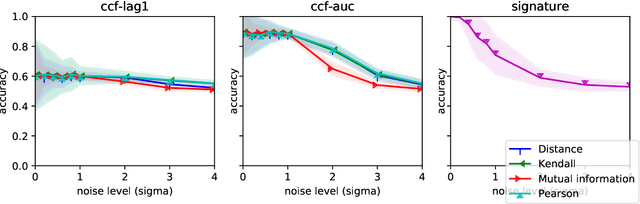
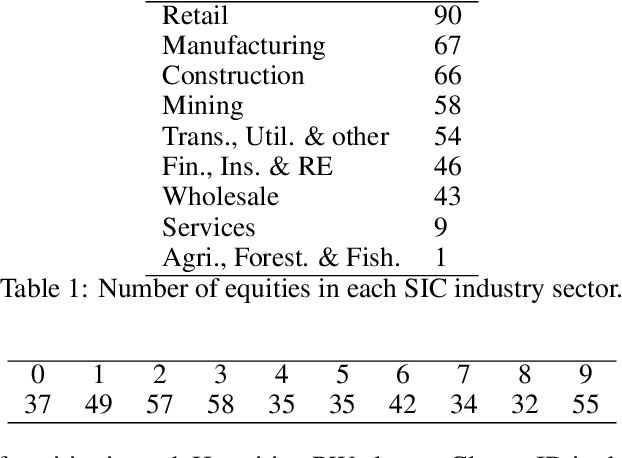
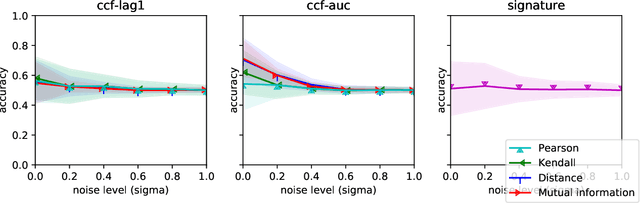
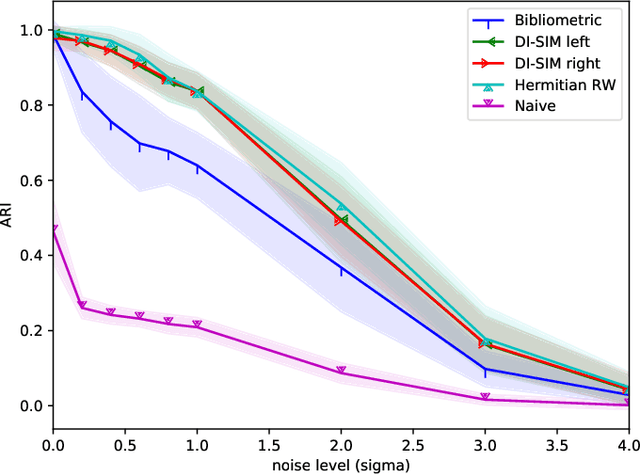
In multivariate time series systems, it has been observed that certain groups of variables partially lead the evolution of the system, while other variables follow this evolution with a time delay; the result is a lead-lag structure amongst the time series variables. In this paper, we propose a method for the detection of lead-lag clusters of time series in multivariate systems. We demonstrate that the web of pairwise lead-lag relationships between time series can be helpfully construed as a directed network, for which there exist suitable algorithms for the detection of pairs of lead-lag clusters with high pairwise imbalance. Within our framework, we consider a number of choices for the pairwise lead-lag metric and directed network clustering components. Our framework is validated on both a synthetic generative model for multivariate lead-lag time series systems and daily real-world US equity prices data. We showcase that our method is able to detect statistically significant lead-lag clusters in the US equity market. We study the nature of these clusters in the context of the empirical finance literature on lead-lag relations and demonstrate how these can be used for the construction of predictive financial signals.
Decentralized Deadlock-free Trajectory Planning for Quadrotor Swarm in Obstacle-rich Environments -- Extended version
Sep 20, 2022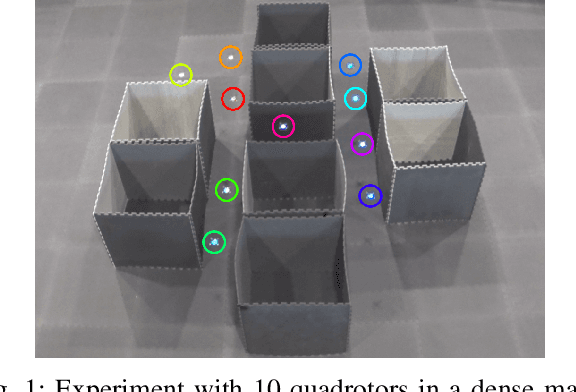
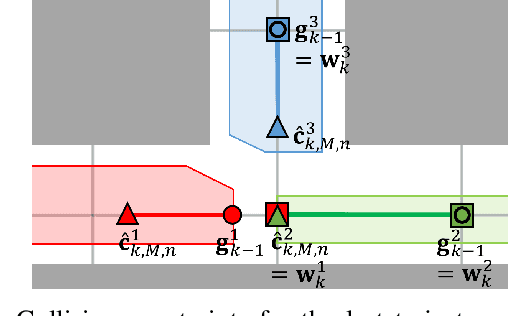
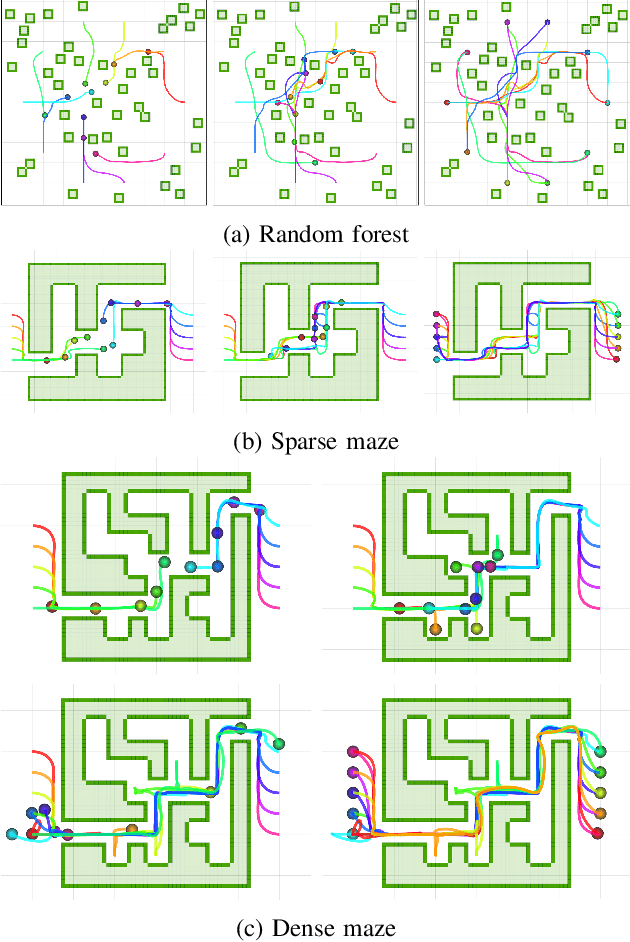
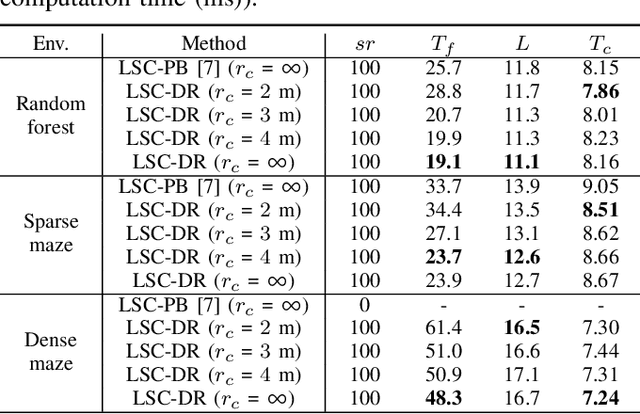
This paper presents a decentralized multi-agent trajectory planning (MATP) algorithm that guarantees to generate a safe, deadlock-free trajectory in an obstacle-rich environment under a limited communication range. The proposed algorithm utilizes a grid-based multi-agent path planning (MAPP) algorithm for deadlock resolution, and we introduce the subgoal optimization method to make the agent converge to the waypoint generated from the MAPP without deadlock. In addition, the proposed algorithm ensures the feasibility of the optimization problem and collision avoidance by adopting a linear safe corridor (LSC). We verify that the proposed algorithm does not cause a deadlock in both random forests and dense mazes regardless of communication range, and it outperforms our previous work in flight time and distance. We validate the proposed algorithm through a hardware demonstration with ten quadrotors.
FINDE: Neural Differential Equations for Finding and Preserving Invariant Quantities
Oct 01, 2022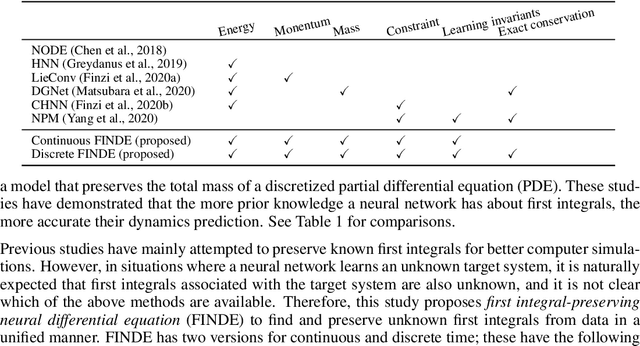

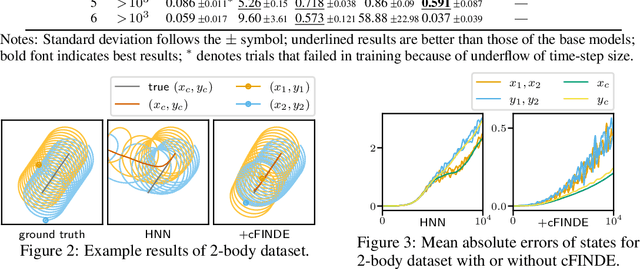
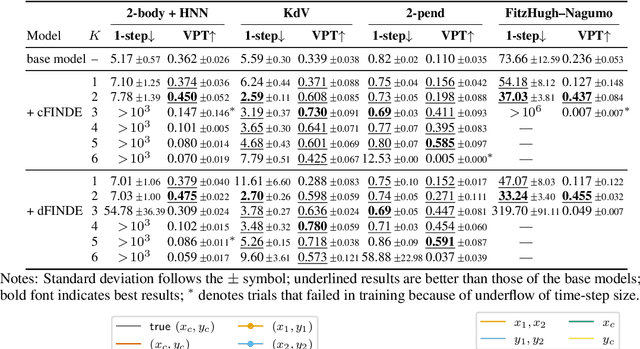
Many real-world dynamical systems are associated with first integrals (a.k.a. invariant quantities), which are quantities that remain unchanged over time. The discovery and understanding of first integrals are fundamental and important topics both in the natural sciences and in industrial applications. First integrals arise from the conservation laws of system energy, momentum, and mass, and from constraints on states; these are typically related to specific geometric structures of the governing equations. Existing neural networks designed to ensure such first integrals have shown excellent accuracy in modeling from data. However, these models incorporate the underlying structures, and in most situations where neural networks learn unknown systems, these structures are also unknown. This limitation needs to be overcome for scientific discovery and modeling of unknown systems. To this end, we propose first integral-preserving neural differential equation (FINDE). By leveraging the projection method and the discrete gradient method, FINDE finds and preserves first integrals from data, even in the absence of prior knowledge about underlying structures. Experimental results demonstrate that FINDE can predict future states of target systems much longer and find various quantities consistent with well-known first integrals in a unified manner.
Model-Free Sequential Testing for Conditional Independence via Testing by Betting
Oct 01, 2022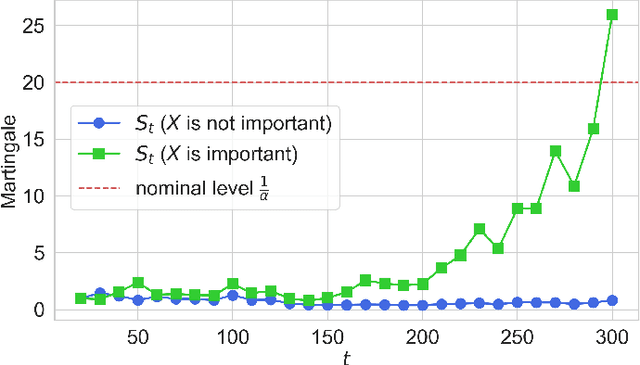
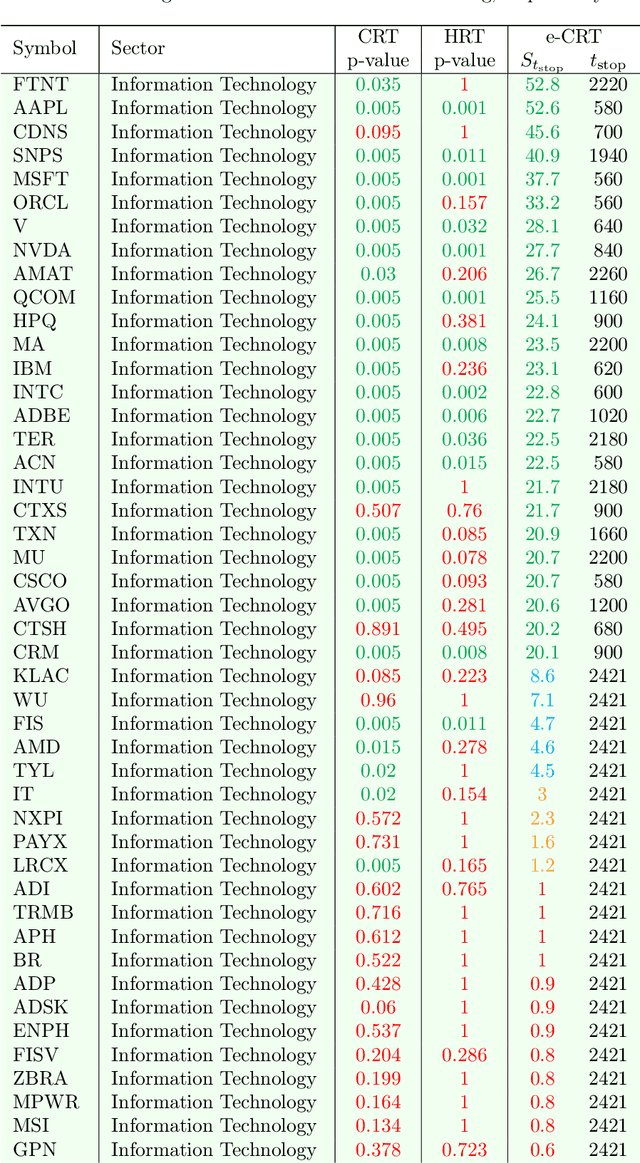
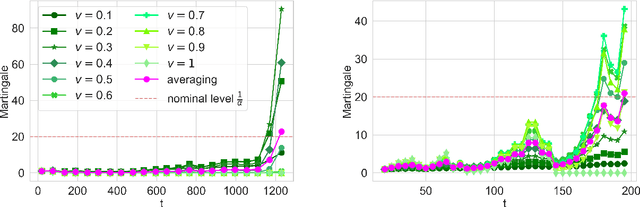
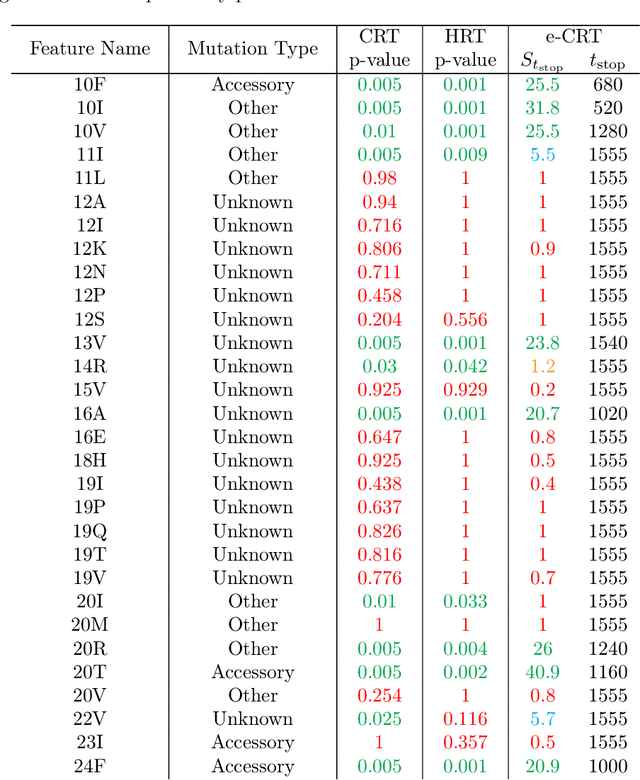
This paper develops a model-free sequential test for conditional independence. The proposed test allows researchers to analyze an incoming i.i.d. data stream with any arbitrary dependency structure, and safely conclude whether a feature is conditionally associated with the response under study. We allow the processing of data points online as soon as they arrive and stop data acquisition once significant results are detected while rigorously controlling the type-I error rate. Our test can work with any sophisticated machine learning algorithm to enhance data efficiency to the extent possible. The developed method is inspired by two statistical frameworks. The first is the model-X conditional randomization test, a test for conditional independence that is valid in offline settings where the sample size is fixed in advance. The second is testing by betting, a "game-theoretic" approach for sequential hypothesis testing. We conduct synthetic experiments to demonstrate the advantage of our test over out-of-the-box sequential tests that account for the multiplicity of tests in the time horizon, and demonstrate the practicality of our proposal by applying it to real-world tasks.
Motion-inductive Self-supervised Object Discovery in Videos
Oct 01, 2022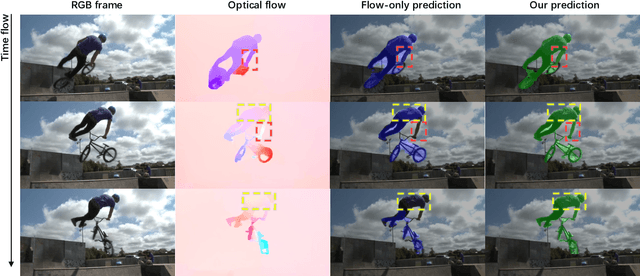
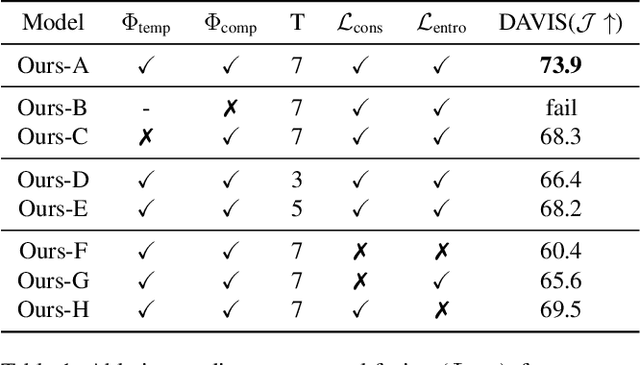
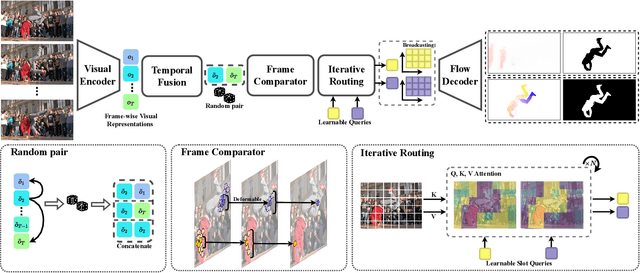
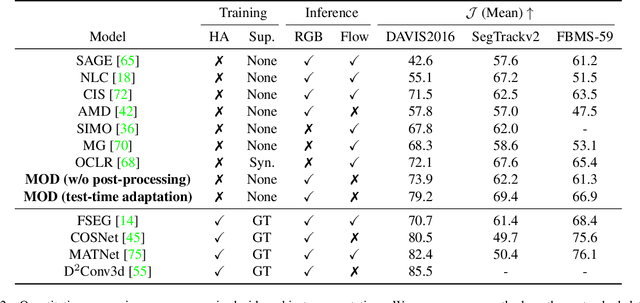
In this paper, we consider the task of unsupervised object discovery in videos. Previous works have shown promising results via processing optical flows to segment objects. However, taking flow as input brings about two drawbacks. First, flow cannot capture sufficient cues when objects remain static or partially occluded. Second, it is challenging to establish temporal coherency from flow-only input, due to the missing texture information. To tackle these limitations, we propose a model for directly processing consecutive RGB frames, and infer the optical flow between any pair of frames using a layered representation, with the opacity channels being treated as the segmentation. Additionally, to enforce object permanence, we apply temporal consistency loss on the inferred masks from randomly-paired frames, which refer to the motions at different paces, and encourage the model to segment the objects even if they may not move at the current time point. Experimentally, we demonstrate superior performance over previous state-of-the-art methods on three public video segmentation datasets (DAVIS2016, SegTrackv2, and FBMS-59), while being computationally efficient by avoiding the overhead of computing optical flow as input.
Convolutional Neural Networks on Manifolds: From Graphs and Back
Oct 01, 2022
Geometric deep learning has gained much attention in recent years due to more available data acquired from non-Euclidean domains. Some examples include point clouds for 3D models and wireless sensor networks in communications. Graphs are common models to connect these discrete data points and capture the underlying geometric structure. With the large amount of these geometric data, graphs with arbitrarily large size tend to converge to a limit model -- the manifold. Deep neural network architectures have been proved as a powerful technique to solve problems based on these data residing on the manifold. In this paper, we propose a manifold neural network (MNN) composed of a bank of manifold convolutional filters and point-wise nonlinearities. We define a manifold convolution operation which is consistent with the discrete graph convolution by discretizing in both space and time domains. To sum up, we focus on the manifold model as the limit of large graphs and construct MNNs, while we can still bring back graph neural networks by the discretization of MNNs. We carry out experiments based on point-cloud dataset to showcase the performance of our proposed MNNs.
A Combinatorial Perspective on the Optimization of Shallow ReLU Networks
Oct 01, 2022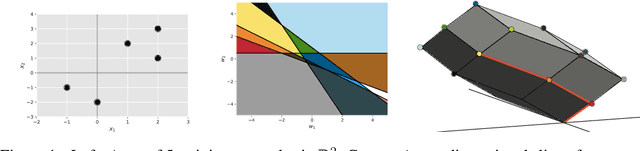

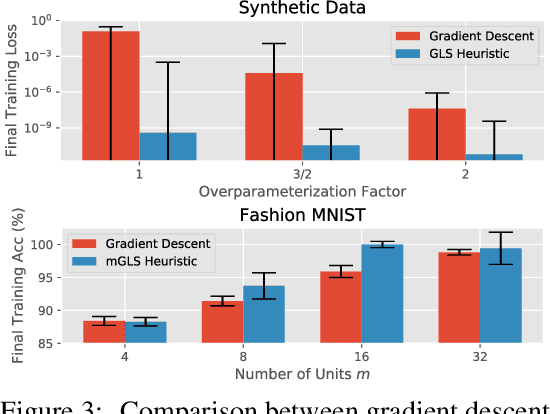
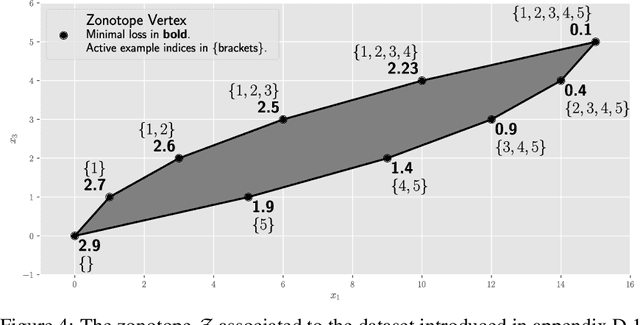
The NP-hard problem of optimizing a shallow ReLU network can be characterized as a combinatorial search over each training example's activation pattern followed by a constrained convex problem given a fixed set of activation patterns. We explore the implications of this combinatorial aspect of ReLU optimization in this work. We show that it can be naturally modeled via a geometric and combinatoric object known as a zonotope with its vertex set isomorphic to the set of feasible activation patterns. This assists in analysis and provides a foundation for further research. We demonstrate its usefulness when we explore the sensitivity of the optimal loss to perturbations of the training data. Later we discuss methods of zonotope vertex selection and its relevance to optimization. Overparameterization assists in training by making a randomly chosen vertex more likely to contain a good solution. We then introduce a novel polynomial-time vertex selection procedure that provably picks a vertex containing the global optimum using only double the minimum number of parameters required to fit the data. We further introduce a local greedy search heuristic over zonotope vertices and demonstrate that it outperforms gradient descent on underparameterized problems.
Multi-Modal Temporal Attention Models for Crop Mapping from Satellite Time Series
Dec 14, 2021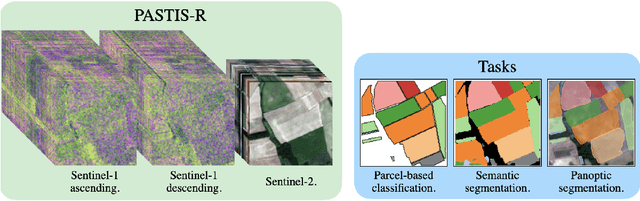
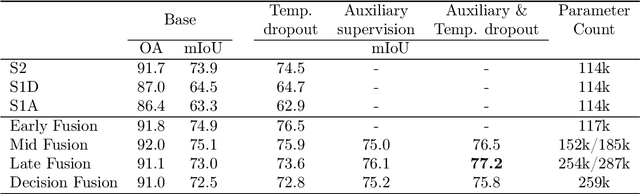
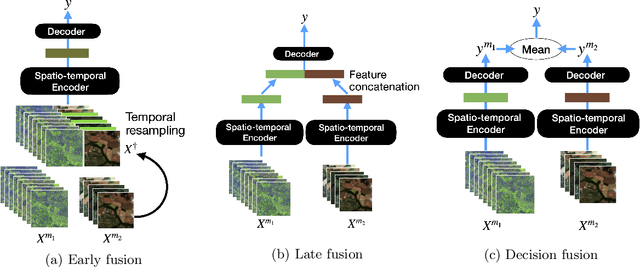
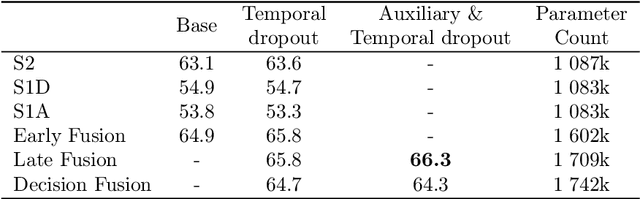
Optical and radar satellite time series are synergetic: optical images contain rich spectral information, while C-band radar captures useful geometrical information and is immune to cloud cover. Motivated by the recent success of temporal attention-based methods across multiple crop mapping tasks, we propose to investigate how these models can be adapted to operate on several modalities. We implement and evaluate multiple fusion schemes, including a novel approach and simple adjustments to the training procedure, significantly improving performance and efficiency with little added complexity. We show that most fusion schemes have advantages and drawbacks, making them relevant for specific settings. We then evaluate the benefit of multimodality across several tasks: parcel classification, pixel-based segmentation, and panoptic parcel segmentation. We show that by leveraging both optical and radar time series, multimodal temporal attention-based models can outmatch single-modality models in terms of performance and resilience to cloud cover. To conduct these experiments, we augment the PASTIS dataset with spatially aligned radar image time series. The resulting dataset, PASTIS-R, constitutes the first large-scale, multimodal, and open-access satellite time series dataset with semantic and instance annotations.
A Probabilistic Model of Activity Recognition with Loose Clothing
Sep 23, 2022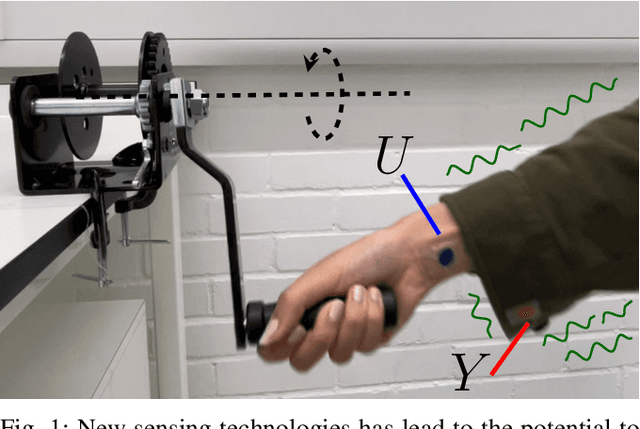
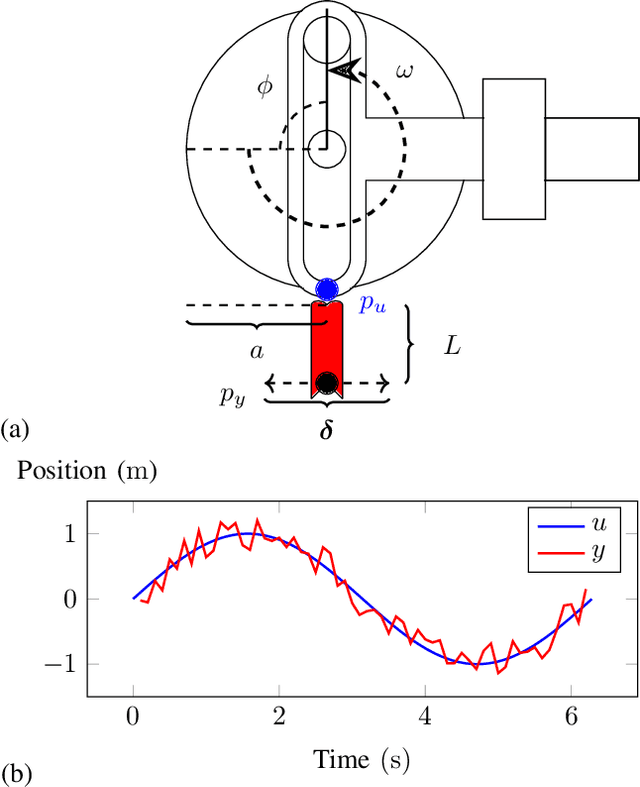
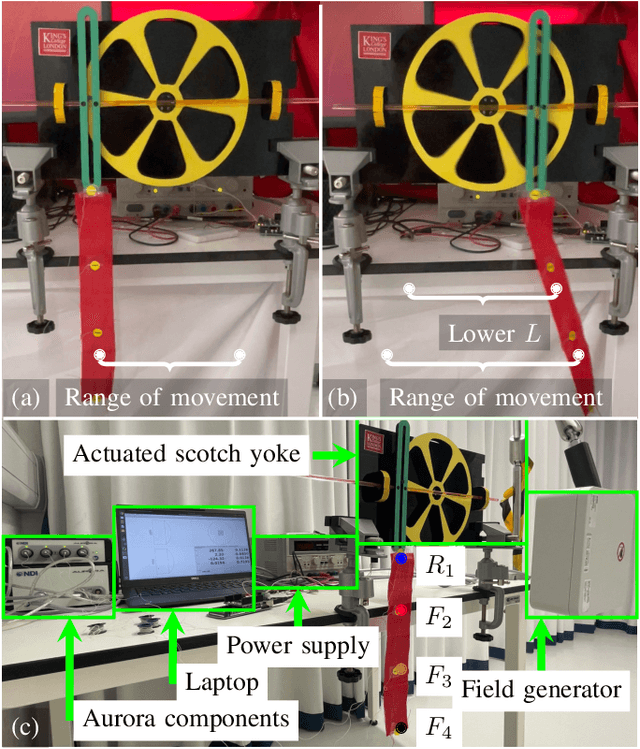
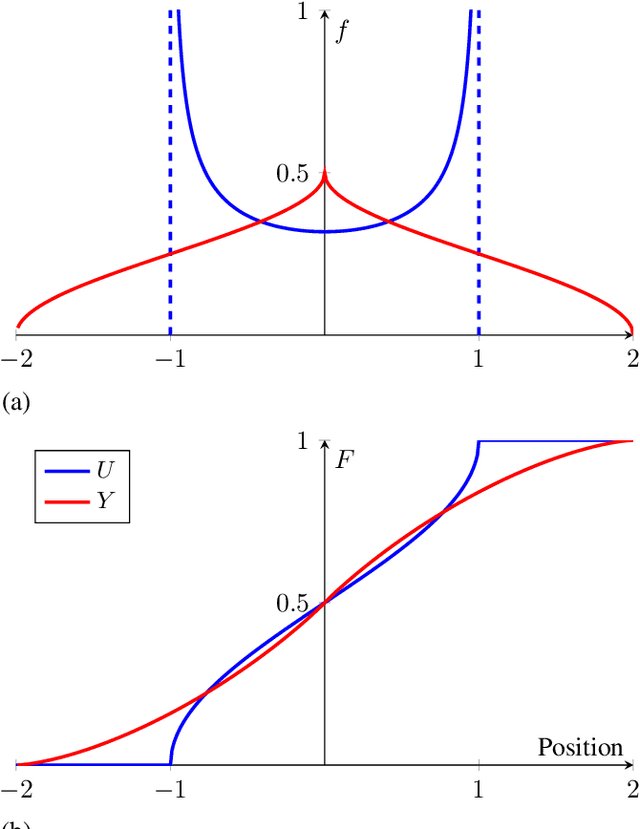
Human activity recognition has become an attractive research area with the development of on-body wearable sensing technology. With comfortable electronic-textiles, sensors can be embedded into clothing so that it is possible to record human movement outside the laboratory for long periods. However, a long-standing issue is how to deal with motion artefacts introduced by movement of clothing with respect to the body. Surprisingly, recent empirical findings suggest that cloth-attached sensor can actually achieve higher accuracy of activity recognition than rigid-attached sensor, particularly when predicting from short time-windows. In this work, a probabilistic model is introduced in which this improved accuracy and resposiveness is explained by the increased statistical distance between movements recorded via fabric sensing. The predictions of the model are verified in simulated and real human motion capture experiments, where it is evident that this counterintuitive effect is closely captured.
Online Multi Camera-IMU Calibration
Sep 28, 2022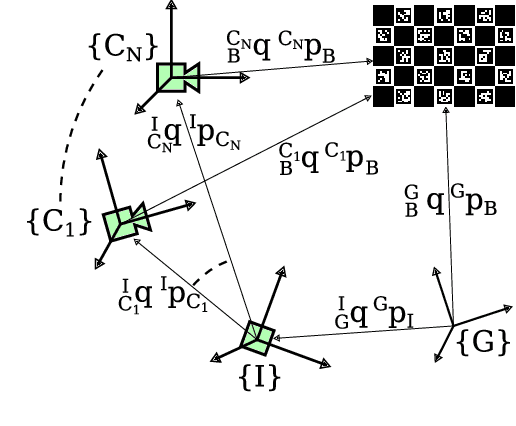
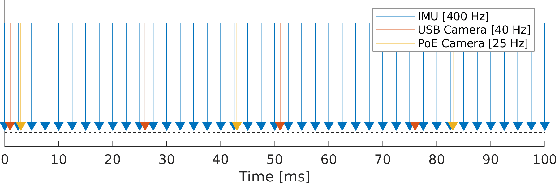
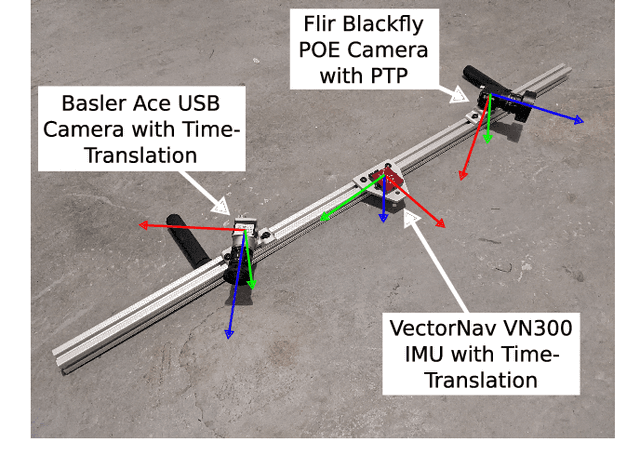
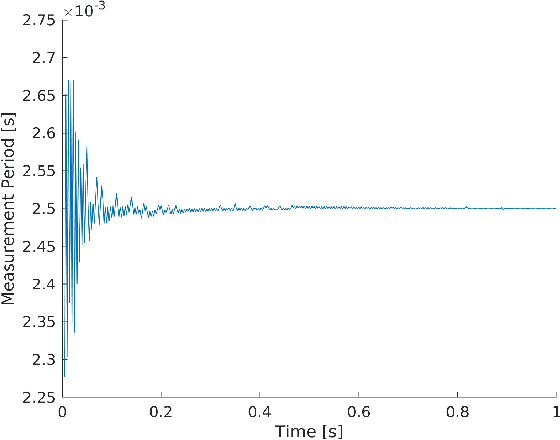
Visual-inertial navigation systems are powerful in their ability to accurately estimate localization of mobile systems within complex environments that preclude the use of global navigation satellite systems. However, these navigation systems are reliant on accurate and up-to-date temporospatial calibrations of the sensors being used. As such, online estimators for these parameters are useful in resilient systems. This paper presents an extension to existing Kalman Filter based frameworks for estimating and calibrating the extrinsic parameters of multi-camera IMU systems. In addition to extending the filter framework to include multiple camera sensors, the measurement model was reformulated to make use of measurement data that is typically made available in fiducial detection software. A secondary filter layer was used to estimate time translation parameters without closed-loop feedback of sensor data. Experimental calibration results, including the use of cameras with non-overlapping fields of view, were used to validate the stability and accuracy of the filter formulation when compared to offline methods. Finally the generalized filter code has been open-sourced and is available online.