 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Chronos and CRS: Design of a miniature car-like robot and a software framework for single and multi-agent robotics and control
Sep 24, 2022

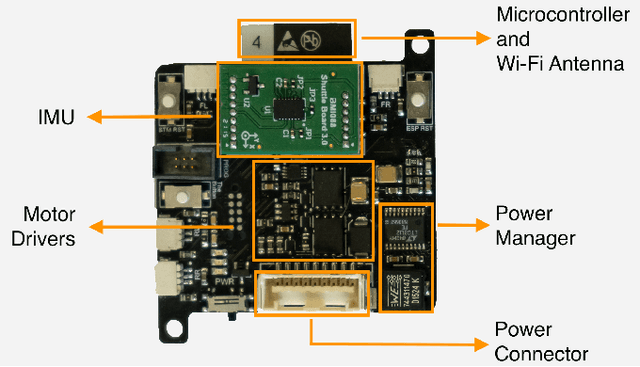
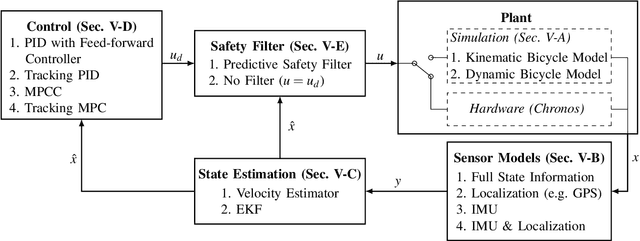
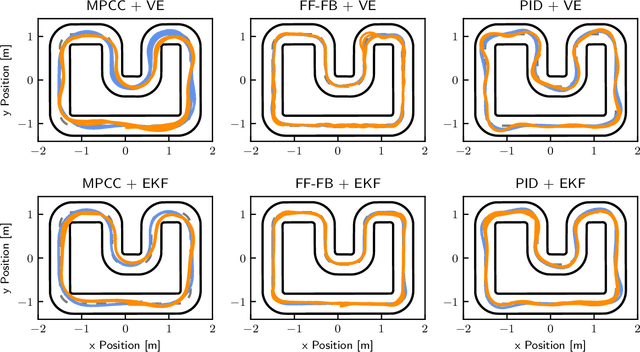
From both an educational and research point of view, experiments on hardware are a key aspect of robotics and control. In the last decade, many open-source hardware and software frameworks for wheeled robots have been presented, mainly in the form of unicycles and car-like robots, with the goal of making robotics accessible to a wider audience and to support control systems development. Unicycles are usually small and inexpensive, and therefore facilitate experiments in a larger fleet, but they are not suited for high-speed motion. Car-like robots are more agile, but they are usually larger and more expensive, thus requiring more resources in terms of space and money. In order to bridge this gap, we present Chronos, a new car-like 1/28th scale robot with customized open-source electronics, and CRS, an open-source software framework for control and robotics. The CRS software framework includes the implementation of various state-of-the-art algorithms for control, estimation, and multi-agent coordination. With this work, we aim to provide easier access to hardware and reduce the engineering time needed to start new educational and research projects.
Multiple View Performers for Shape Completion
Sep 13, 2022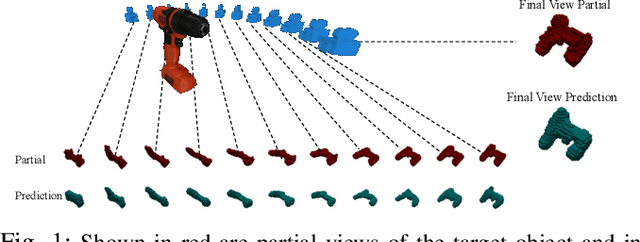
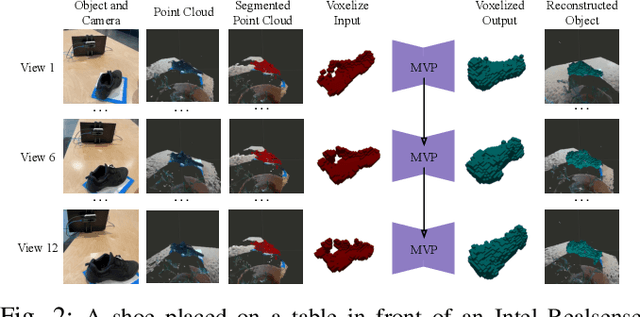
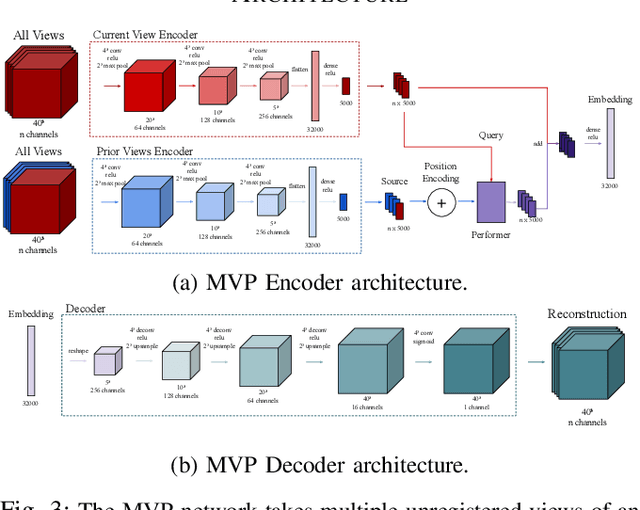
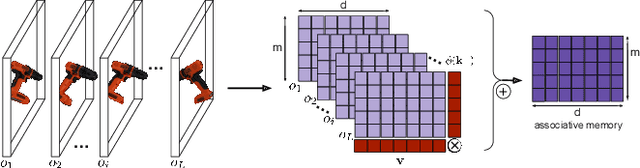
We propose the Multiple View Performer (MVP) - a new architecture for 3D shape completion from a series of temporally sequential views. MVP accomplishes this task by using linear-attention Transformers called Performers. Our model allows the current observation of the scene to attend to the previous ones for more accurate infilling. The history of past observations is compressed via the compact associative memory approximating modern continuous Hopfield memory, but crucially of size independent from the history length. We compare our model with several baselines for shape completion over time, demonstrating the generalization gains that MVP provides. To the best of our knowledge, MVP is the first multiple view voxel reconstruction method that does not require registration of multiple depth views and the first causal Transformer based model for 3D shape completion.
A Fourier Approach to Mixture Learning
Oct 05, 2022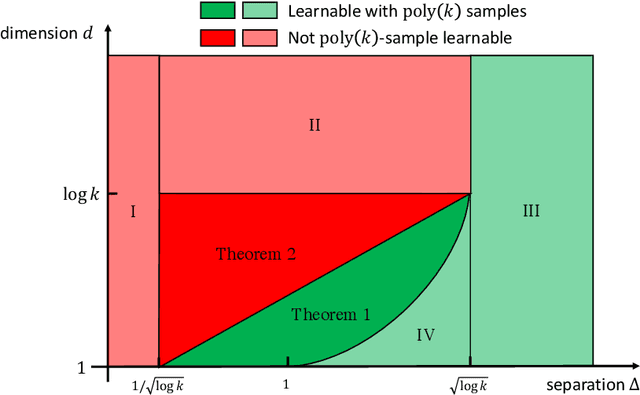

We revisit the problem of learning mixtures of spherical Gaussians. Given samples from mixture $\frac{1}{k}\sum_{j=1}^{k}\mathcal{N}(\mu_j, I_d)$, the goal is to estimate the means $\mu_1, \mu_2, \ldots, \mu_k \in \mathbb{R}^d$ up to a small error. The hardness of this learning problem can be measured by the separation $\Delta$ defined as the minimum distance between all pairs of means. Regev and Vijayaraghavan (2017) showed that with $\Delta = \Omega(\sqrt{\log k})$ separation, the means can be learned using $\mathrm{poly}(k, d)$ samples, whereas super-polynomially many samples are required if $\Delta = o(\sqrt{\log k})$ and $d = \Omega(\log k)$. This leaves open the low-dimensional regime where $d = o(\log k)$. In this work, we give an algorithm that efficiently learns the means in $d = O(\log k/\log\log k)$ dimensions under separation $d/\sqrt{\log k}$ (modulo doubly logarithmic factors). This separation is strictly smaller than $\sqrt{\log k}$, and is also shown to be necessary. Along with the results of Regev and Vijayaraghavan (2017), our work almost pins down the critical separation threshold at which efficient parameter learning becomes possible for spherical Gaussian mixtures. More generally, our algorithm runs in time $\mathrm{poly}(k)\cdot f(d, \Delta, \epsilon)$, and is thus fixed-parameter tractable in parameters $d$, $\Delta$ and $\epsilon$. Our approach is based on estimating the Fourier transform of the mixture at carefully chosen frequencies, and both the algorithm and its analysis are simple and elementary. Our positive results can be easily extended to learning mixtures of non-Gaussian distributions, under a mild condition on the Fourier spectrum of the distribution.
Celeritas: Fast Optimizer for Large Dataflow Graphs
Jul 30, 2022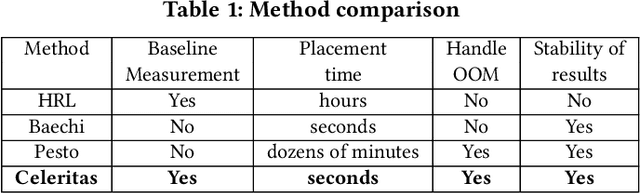
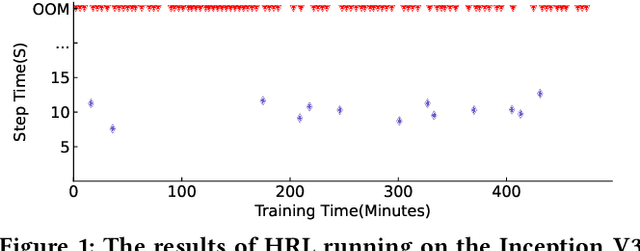
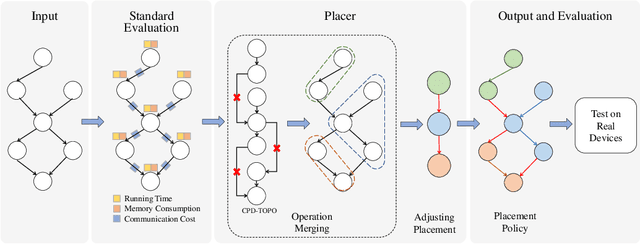
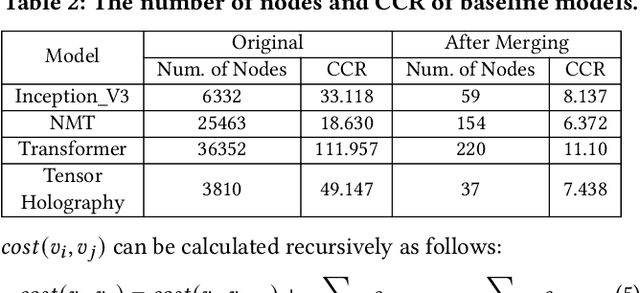
The rapidly enlarging neural network models are becoming increasingly challenging to run on a single device. Hence model parallelism over multiple devices is critical to guarantee the efficiency of training large models. Recent proposals fall short either in long processing time or poor performance. Therefore, we propose Celeritas, a fast framework for optimizing device placement for large models. Celeritas employs a simple but efficient model parallelization strategy in the Standard Evaluation, and generates placement policies through a series of scheduling algorithms. We conduct experiments to deploy and evaluate Celeritas on numerous large models. The results show that Celeritas not only reduces the placement policy generation time by 26.4\% but also improves the model running time by 34.2\% compared to most advanced methods.
A Sublinear Adversarial Training Algorithm
Aug 10, 2022Adversarial training is a widely used strategy for making neural networks resistant to adversarial perturbations. For a neural network of width $m$, $n$ input training data in $d$ dimension, it takes $\Omega(mnd)$ time cost per training iteration for the forward and backward computation. In this paper we analyze the convergence guarantee of adversarial training procedure on a two-layer neural network with shifted ReLU activation, and shows that only $o(m)$ neurons will be activated for each input data per iteration. Furthermore, we develop an algorithm for adversarial training with time cost $o(m n d)$ per iteration by applying half-space reporting data structure.
How to Define the Propagation Environment Semantics and Its Application in Scatterer-Based Beam Prediction
Sep 17, 2022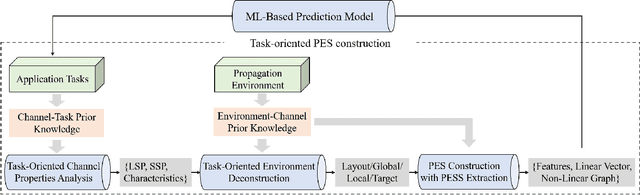
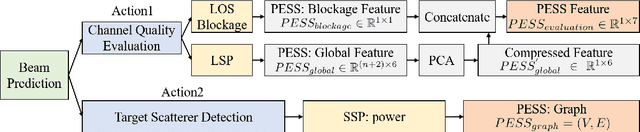
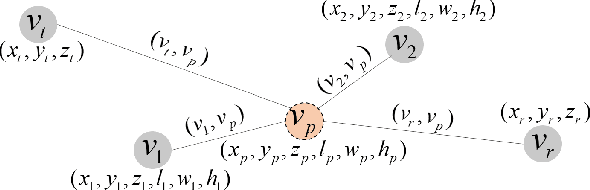
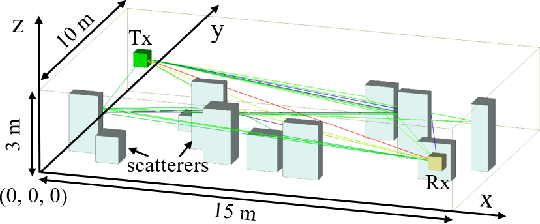
In view of the propagation environment directly determining the channel fading, the application tasks can also be solved with the aid of the environment information. Inspired by task-oriented semantic communication and machine learning (ML) powered environment-channel mapping methods, this work aims to provide a new view of the environment from the semantic level, which defines the propagation environment semantics (PES) as a limited set of propagation environment semantic symbols (PESS) for diverse application tasks. The PESS is extracted oriented to the tasks with channel properties as a foundation. For method validation, the PES-aided beam prediction (PESaBP) is presented in non-line-of-sight (NLOS). The PESS of environment features and graphs are given for the semantic actions of channel quality evaluation and target scatterer detection of maximum power, which can obtain 0.92 and 0.9 precision, respectively, and save over 87% of time cost.
DeepGraphONet: A Deep Graph Operator Network to Learn and Zero-shot Transfer the Dynamic Response of Networked Systems
Sep 21, 2022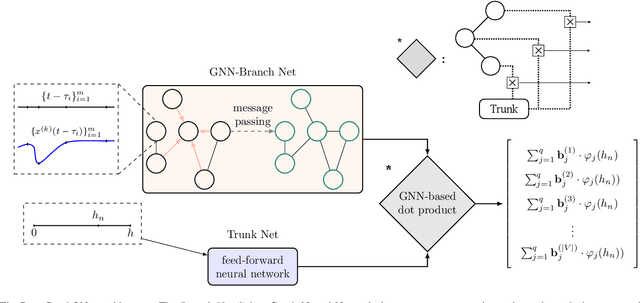
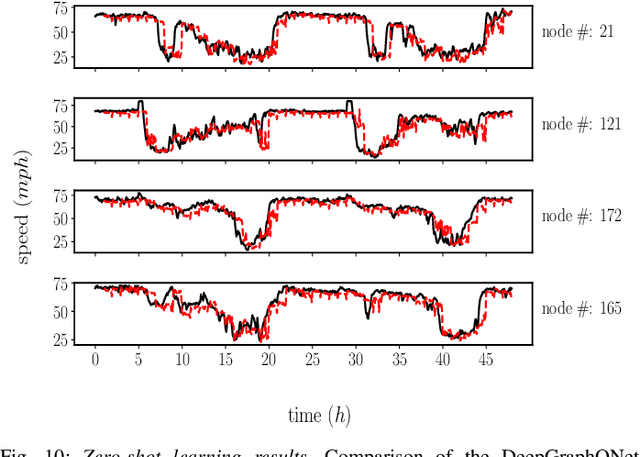
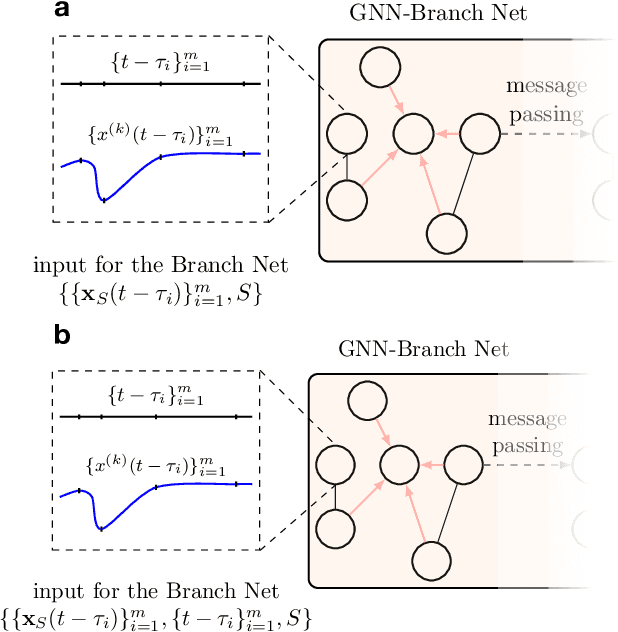
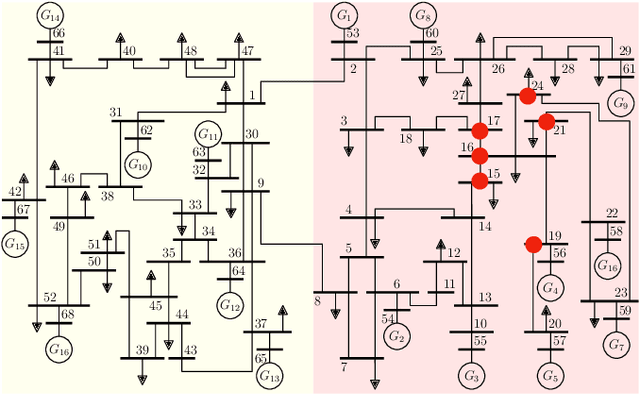
This paper develops a Deep Graph Operator Network (DeepGraphONet) framework that learns to approximate the dynamics of a complex system (e.g. the power grid or traffic) with an underlying sub-graph structure. We build our DeepGraphONet by fusing the ability of (i) Graph Neural Networks (GNN) to exploit spatially correlated graph information and (ii) Deep Operator Networks~(DeepONet) to approximate the solution operator of dynamical systems. The resulting DeepGraphONet can then predict the dynamics within a given short/medium-term time horizon by observing a finite history of the graph state information. Furthermore, we design our DeepGraphONet to be resolution-independent. That is, we do not require the finite history to be collected at the exact/same resolution. In addition, to disseminate the results from a trained DeepGraphONet, we design a zero-shot learning strategy that enables using it on a different sub-graph. Finally, empirical results on the (i) transient stability prediction problem of power grids and (ii) traffic flow forecasting problem of a vehicular system illustrate the effectiveness of the proposed DeepGraphONet.
Argus++: Robust Real-time Activity Detection for Unconstrained Video Streams with Overlapping Cube Proposals
Jan 14, 2022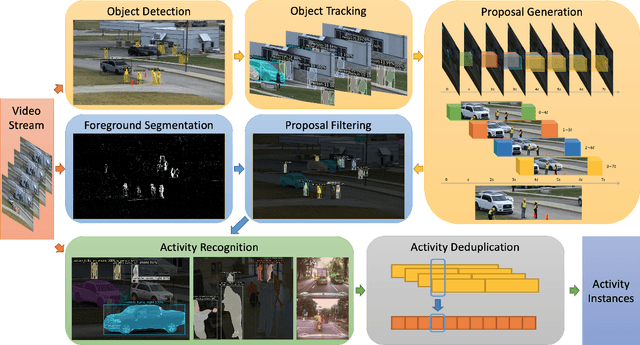
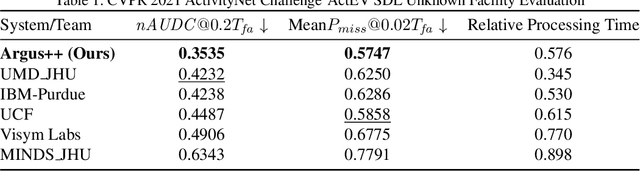

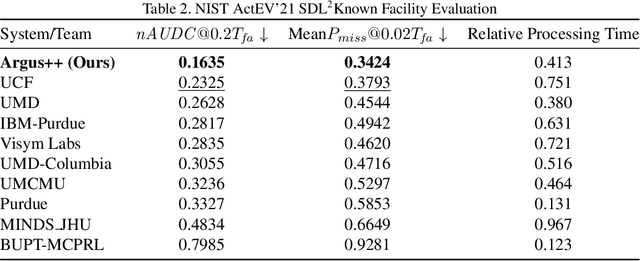
Activity detection is one of the attractive computer vision tasks to exploit the video streams captured by widely installed cameras. Although achieving impressive performance, conventional activity detection algorithms are usually designed under certain constraints, such as using trimmed and/or object-centered video clips as inputs. Therefore, they failed to deal with the multi-scale multi-instance cases in real-world unconstrained video streams, which are untrimmed and have large field-of-views. Real-time requirements for streaming analysis also mark brute force expansion of them unfeasible. To overcome these issues, we propose Argus++, a robust real-time activity detection system for analyzing unconstrained video streams. The design of Argus++ introduces overlapping spatio-temporal cubes as an intermediate concept of activity proposals to ensure coverage and completeness of activity detection through over-sampling. The overall system is optimized for real-time processing on standalone consumer-level hardware. Extensive experiments on different surveillance and driving scenarios demonstrated its superior performance in a series of activity detection benchmarks, including CVPR ActivityNet ActEV 2021, NIST ActEV SDL UF/KF, TRECVID ActEV 2020/2021, and ICCV ROAD 2021.
Two-Stage Deep Anomaly Detection with Heterogeneous Time Series Data
Feb 10, 2022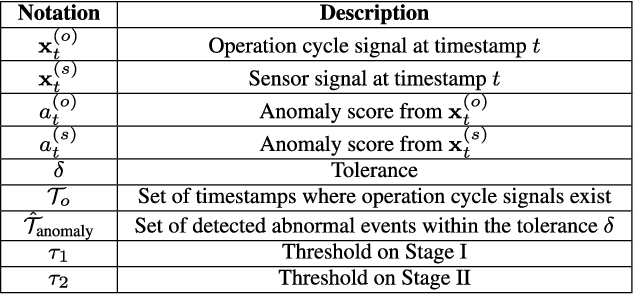
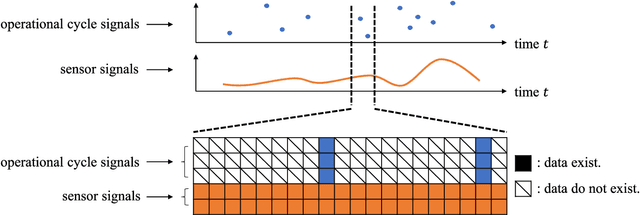
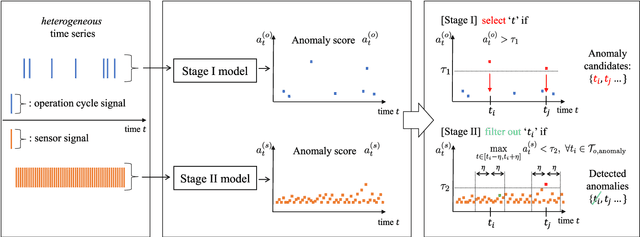

We introduce a data-driven anomaly detection framework using a manufacturing dataset collected from a factory assembly line. Given heterogeneous time series data consisting of operation cycle signals and sensor signals, we aim at discovering abnormal events. Motivated by our empirical findings that conventional single-stage benchmark approaches may not exhibit satisfactory performance under our challenging circumstances, we propose a two-stage deep anomaly detection (TDAD) framework in which two different unsupervised learning models are adopted depending on types of signals. In Stage I, we select anomaly candidates by using a model trained by operation cycle signals; in Stage II, we finally detect abnormal events out of the candidates by using another model, which is suitable for taking advantage of temporal continuity, trained by sensor signals. A distinguishable feature of our framework is that operation cycle signals are exploited first to find likely anomalous points, whereas sensor signals are leveraged to filter out unlikely anomalous points afterward. Our experiments comprehensively demonstrate the superiority over single-stage benchmark approaches, the model-agnostic property, and the robustness to difficult situations.
KDCTime: Knowledge Distillation with Calibration on InceptionTime for Time-series Classification
Dec 04, 2021


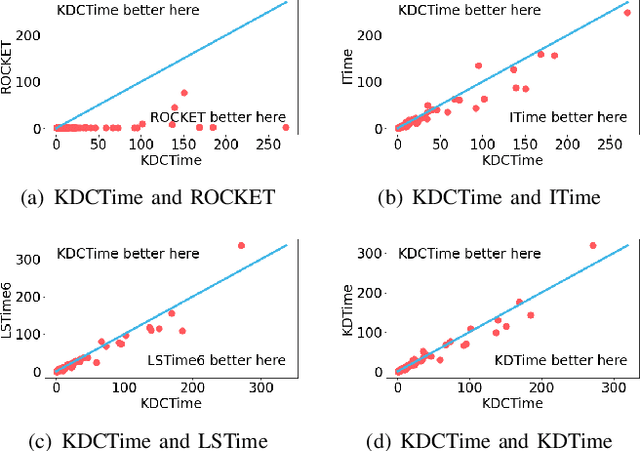
Time-series classification approaches based on deep neural networks are easy to be overfitting on UCR datasets, which is caused by the few-shot problem of those datasets. Therefore, in order to alleviate the overfitting phenomenon for further improving the accuracy, we first propose Label Smoothing for InceptionTime (LSTime), which adopts the information of soft labels compared to just hard labels. Next, instead of manually adjusting soft labels by LSTime, Knowledge Distillation for InceptionTime (KDTime) is proposed in order to automatically generate soft labels by the teacher model. At last, in order to rectify the incorrect predicted soft labels from the teacher model, Knowledge Distillation with Calibration for InceptionTime (KDCTime) is proposed, where it contains two optional calibrating strategies, i.e. KDC by Translating (KDCT) and KDC by Reordering (KDCR). The experimental results show that the accuracy of KDCTime is promising, while its inference time is two orders of magnitude faster than ROCKET with an acceptable training time overhead.