 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Algorithms for Intelligent Agents and Mechanisms
Oct 06, 2022
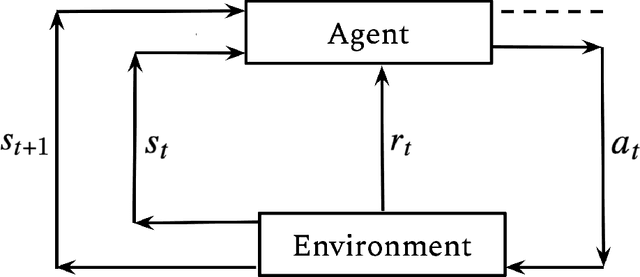

In this thesis, we research learning algorithms for optimal decision making in two different contexts, Reinforcement Learning in Part I and Auction Design in Part II. Reinforcement learning (RL) is an area of machine learning that is concerned with how an agent should act in an environment in order to maximize its cumulative reward over time. In Chapter 2, inspired by statistical physics, we develop a novel approach to Reinforcement Learning (RL) that not only learns optimal policies with enhanced desirable properties but also sheds new light on maximum entropy RL. In Chapter 3, we tackle the generalization problem in RL using a Bayesian perspective. We show that imperfect knowledge of the environments dynamics effectively turn a fully-observed Markov Decision Process (MDP) into a Partially Observed MDP (POMDP) that we call the Epistemic POMDP. Informed by this observation, we develop a new policy learning algorithm LEEP which has improved generalization properties. Designing an incentive compatible, individually rational auction that maximizes revenue is a challenging and intractable problem. Recently, deep learning based approaches have been proposed to learn optimal auctions from data. While successful, this approach suffers from a few limitations, including sample inefficiency, lack of generalization to new auctions, and training difficulties. In Chapter 4, we construct a symmetry preserving neural network architecture, EquivariantNet, suitable for anonymous auctions. EquivariantNet is not only more sample efficient but is also able to learn auction rules that generalize well to other settings. In Chapter 5, we propose a novel formulation of the auction learning problem as a two player game. The resulting learning algorithm, ALGNet, is easier to train, more reliable and better suited for non stationary settings.
Deep Learning Mixture-of-Experts Approach for Cytotoxic Edema Assessment in Infants and Children
Oct 06, 2022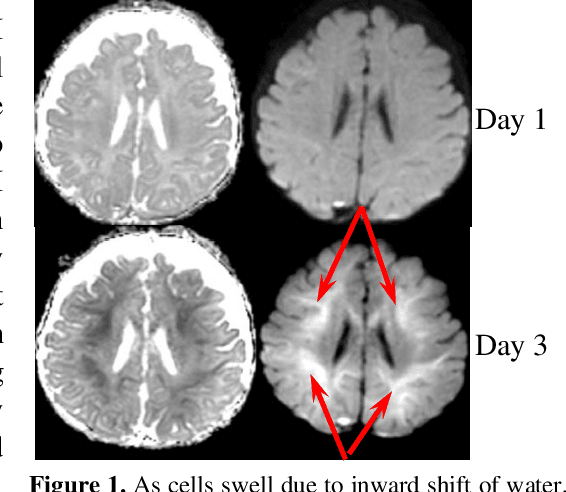
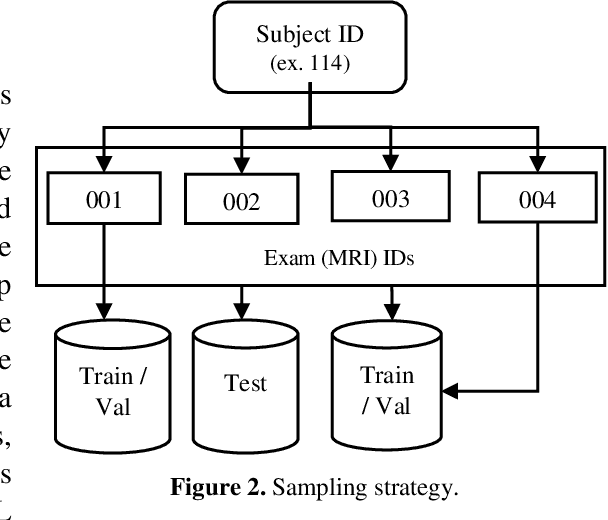
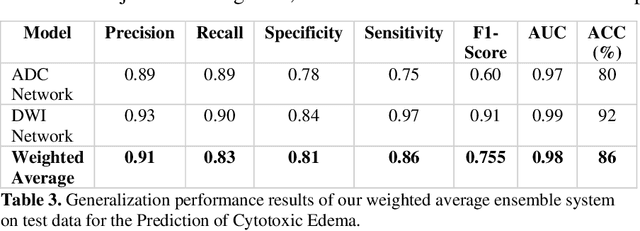
This paper presents a deep learning framework for image classification aimed at increasing predictive performance for Cytotoxic Edema (CE) diagnosis in infants and children. The proposed framework includes two 3D network architectures optimized to learn from two types of clinical MRI data , a trace Diffusion Weighted Image (DWI) and the calculated Apparent Diffusion Coefficient map (ADC). This work proposes a robust and novel solution based on volumetric analysis of 3D images (using pixels from time slices) and 3D convolutional neural network (CNN) models. While simple in architecture, the proposed framework shows significant quantitative results on the domain problem. We use a dataset curated from a Childrens Hospital Colorado (CHCO) patient registry to report a predictive performance F1 score of 0.91 at distinguishing CE patients from children with severe neurologic injury without CE. In addition, we perform analysis of our systems output to determine the association of CE with Abusive Head Trauma (AHT) , a type of traumatic brain injury (TBI) associated with abuse , and overall functional outcome and in hospital mortality of infants and young children. We used two clinical variables, AHT diagnosis and Functional Status Scale (FSS) score, to arrive at the conclusion that CE is highly correlated with overall outcome and that further study is needed to determine whether CE is a biomarker of AHT. With that, this paper introduces a simple yet powerful deep learning based solution for automated CE classification. This solution also enables an indepth analysis of progression of CE and its correlation to AHT and overall neurologic outcome, which in turn has the potential to empower experts to diagnose and mitigate AHT during early stages of a childs life.
Learning Minimally-Violating Continuous Control for Infeasible Linear Temporal Logic Specifications
Oct 06, 2022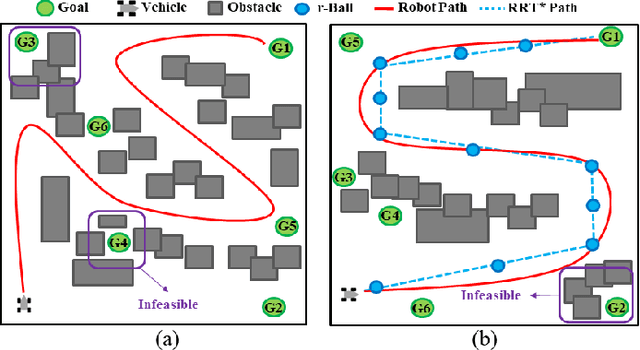
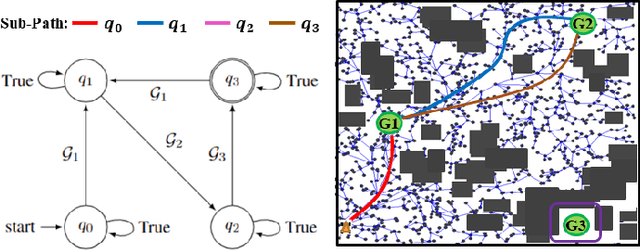
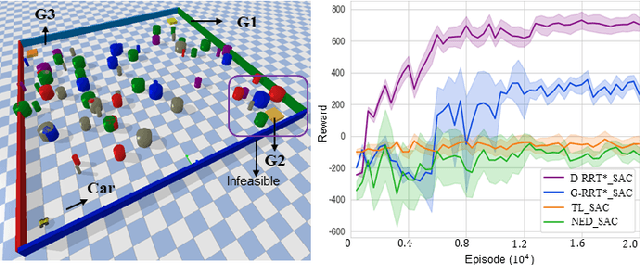
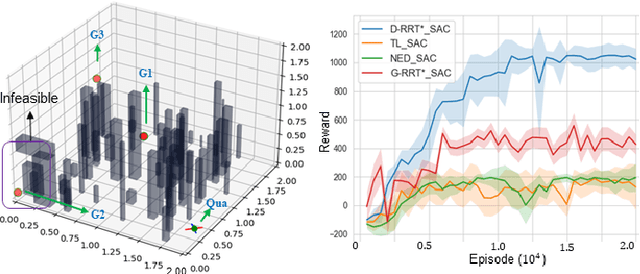
This paper explores continuous-time control synthesis for target-driven navigation to satisfy complex high-level tasks expressed as linear temporal logic (LTL). We propose a model-free framework using deep reinforcement learning (DRL) where the underlying dynamic system is unknown (an opaque box). Unlike prior work, this paper considers scenarios where the given LTL specification might be infeasible and therefore cannot be accomplished globally. Instead of modifying the given LTL formula, we provide a general DRL-based approach to satisfy it with minimal violation. %\mminline{Need to decide if we're comfortable calling these "guarantees" due to the stochastic policy. I'm not repeating this comment everywhere that says "guarantees" but there are multiple places.} To do this, we transform a previously multi-objective DRL problem, which requires simultaneous automata satisfaction and minimum violation cost, into a single objective. By guiding the DRL agent with a sampling-based path planning algorithm for the potentially infeasible LTL task, the proposed approach mitigates the myopic tendencies of DRL, which are often an issue when learning general LTL tasks that can have long or infinite horizons. This is achieved by decomposing an infeasible LTL formula into several reach-avoid sub-tasks with shorter horizons, which can be trained in a modular DRL architecture. Furthermore, we overcome the challenge of the exploration process for DRL in complex and cluttered environments by using path planners to design rewards that are dense in the configuration space. The benefits of the presented approach are demonstrated through testing on various complex nonlinear systems and compared with state-of-the-art baselines. The Video demonstration can be found on YouTube Channel:\url{https://youtu.be/jBhx6Nv224E}.
Time Series Analysis of Blockchain-Based Cryptocurrency Price Changes
Feb 19, 2022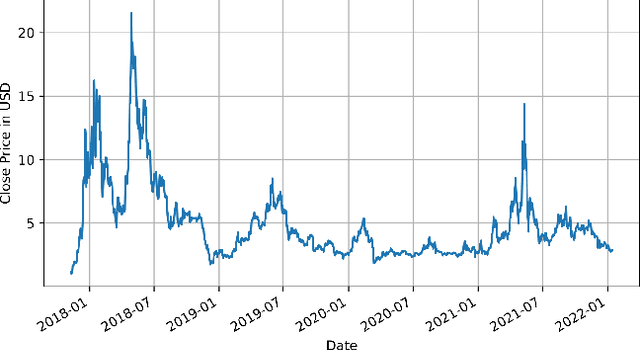
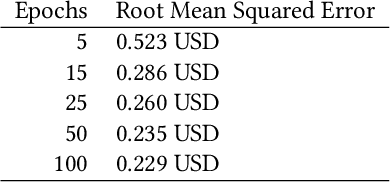
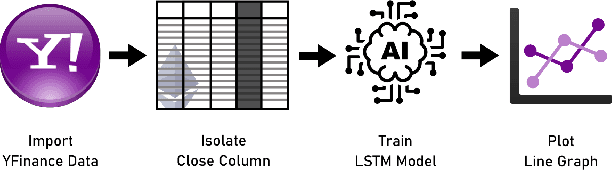

In this paper we apply neural networks and Artificial Intelligence (AI) to historical records of high-risk cryptocurrency coins to train a prediction model that guesses their price. This paper's code contains Jupyter notebooks, one of which outputs a timeseries graph of any cryptocurrency price once a CSV file of the historical data is inputted into the program. Another Jupyter notebook trains an LSTM, or a long short-term memory model, to predict a cryptocurrency's closing price. The LSTM is fed the close price, which is the price that the currency has at the end of the day, so it can learn from those values. The notebook creates two sets: a training set and a test set to assess the accuracy of the results. The data is then normalized using manual min-max scaling so that the model does not experience any bias; this also enhances the performance of the model. Then, the model is trained using three layers -- an LSTM, dropout, and dense layer-minimizing the loss through 50 epochs of training; from this training, a recurrent neural network (RNN) is produced and fitted to the training set. Additionally, a graph of the loss over each epoch is produced, with the loss minimizing over time. Finally, the notebook plots a line graph of the actual currency price in red and the predicted price in blue. The process is then repeated for several more cryptocurrencies to compare prediction models. The parameters for the LSTM, such as number of epochs and batch size, are tweaked to try and minimize the root mean square error.
The Dynamic of Consensus in Deep Networks and the Identification of Noisy Labels
Oct 02, 2022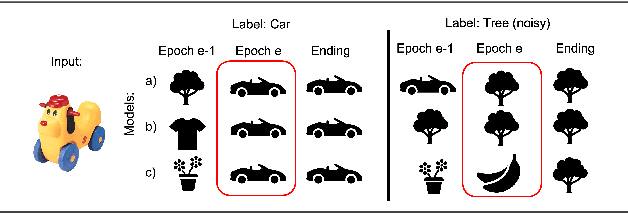
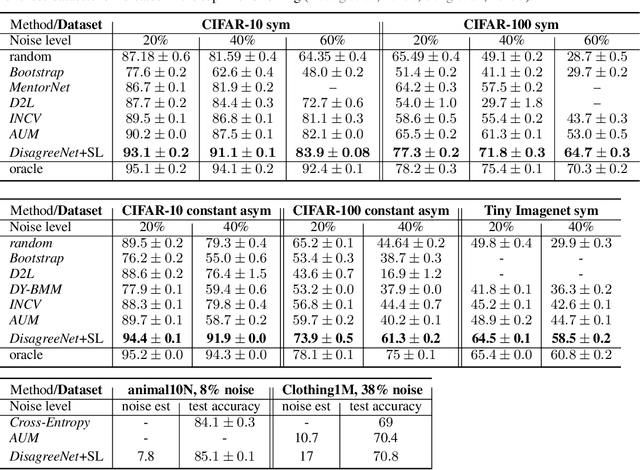
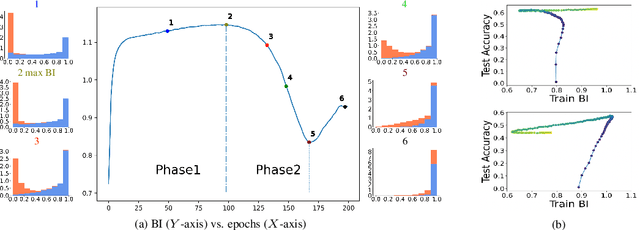
Deep neural networks have incredible capacity and expressibility, and can seemingly memorize any training set. This introduces a problem when training in the presence of noisy labels, as the noisy examples cannot be distinguished from clean examples by the end of training. Recent research has dealt with this challenge by utilizing the fact that deep networks seem to memorize clean examples much earlier than noisy examples. Here we report a new empirical result: for each example, when looking at the time it has been memorized by each model in an ensemble of networks, the diversity seen in noisy examples is much larger than the clean examples. We use this observation to develop a new method for noisy labels filtration. The method is based on a statistics of the data, which captures the differences in ensemble learning dynamics between clean and noisy data. We test our method on three tasks: (i) noise amount estimation; (ii) noise filtration; (iii) supervised classification. We show that our method improves over existing baselines in all three tasks using a variety of datasets, noise models, and noise levels. Aside from its improved performance, our method has two other advantages. (i) Simplicity, which implies that no additional hyperparameters are introduced. (ii) Our method is modular: it does not work in an end-to-end fashion, and can therefore be used to clean a dataset for any other future usage.
Supervised Parameter Estimation of Neuron Populations from Multiple Firing Events
Oct 02, 2022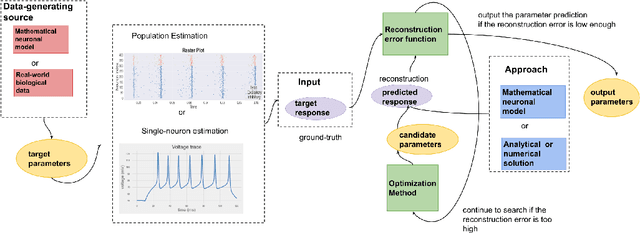
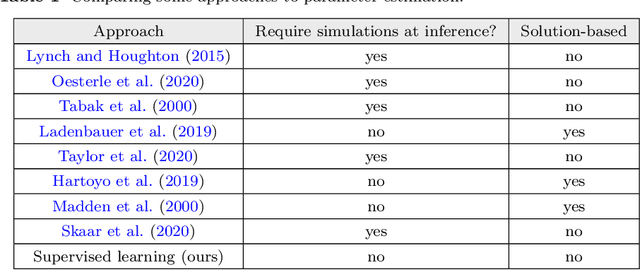
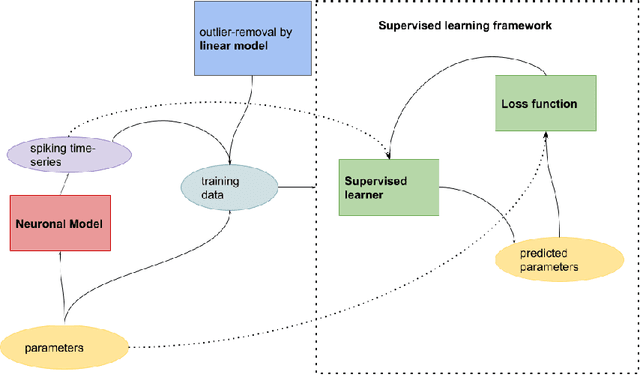
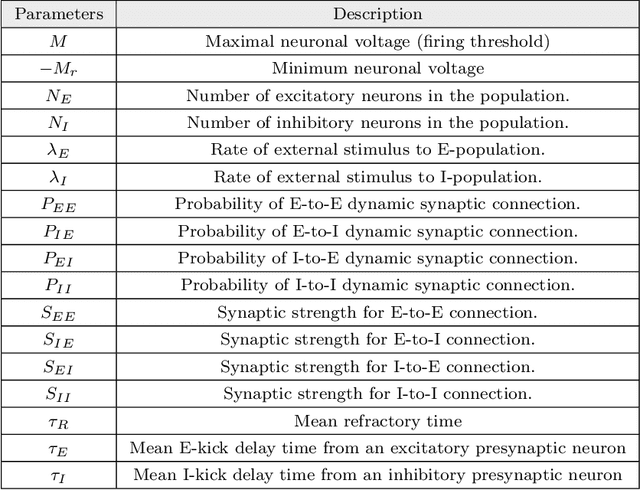
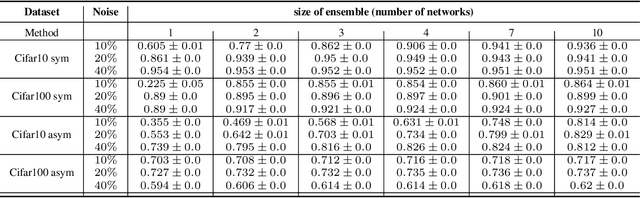
The firing dynamics of biological neurons in mathematical models is often determined by the model's parameters, representing the neurons' underlying properties. The parameter estimation problem seeks to recover those parameters of a single neuron or a neuron population from their responses to external stimuli and interactions between themselves. Most common methods for tackling this problem in the literature use some mechanistic models in conjunction with either a simulation-based or solution-based optimization scheme. In this paper, we study an automatic approach of learning the parameters of neuron populations from a training set consisting of pairs of spiking series and parameter labels via supervised learning. Unlike previous work, this automatic learning does not require additional simulations at inference time nor expert knowledge in deriving an analytical solution or in constructing some approximate models. We simulate many neuronal populations with different parameter settings using a stochastic neuron model. Using that data, we train a variety of supervised machine learning models, including convolutional and deep neural networks, random forest, and support vector regression. We then compare their performance against classical approaches including a genetic search, Bayesian sequential estimation, and a random walk approximate model. The supervised models almost always outperform the classical methods in parameter estimation and spike reconstruction errors, and computation expense. Convolutional neural network, in particular, is the best among all models across all metrics. The supervised models can also generalize to out-of-distribution data to a certain extent.
Celeritas: Fast Optimizer for Large Dataflow Graphs
Jul 30, 2022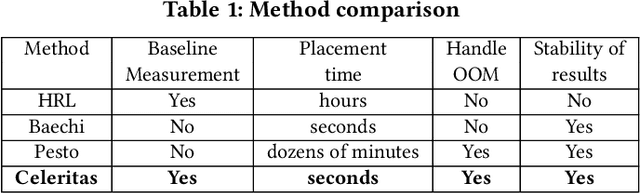
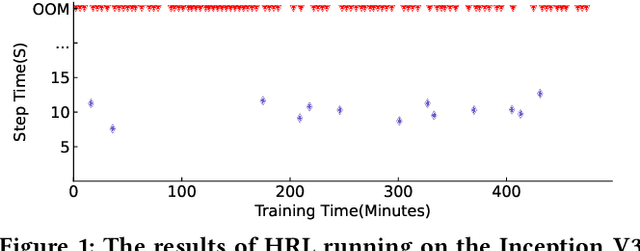
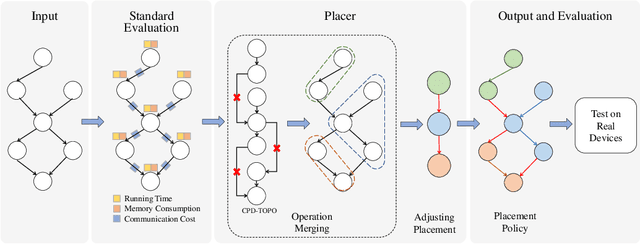
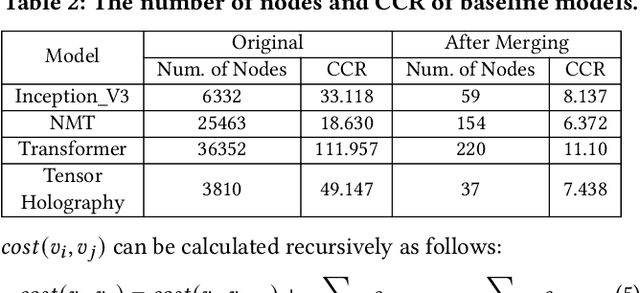
The rapidly enlarging neural network models are becoming increasingly challenging to run on a single device. Hence model parallelism over multiple devices is critical to guarantee the efficiency of training large models. Recent proposals fall short either in long processing time or poor performance. Therefore, we propose Celeritas, a fast framework for optimizing device placement for large models. Celeritas employs a simple but efficient model parallelization strategy in the Standard Evaluation, and generates placement policies through a series of scheduling algorithms. We conduct experiments to deploy and evaluate Celeritas on numerous large models. The results show that Celeritas not only reduces the placement policy generation time by 26.4\% but also improves the model running time by 34.2\% compared to most advanced methods.
Active Bucketized Learning for ACOPF Optimization Proxies
Aug 16, 2022
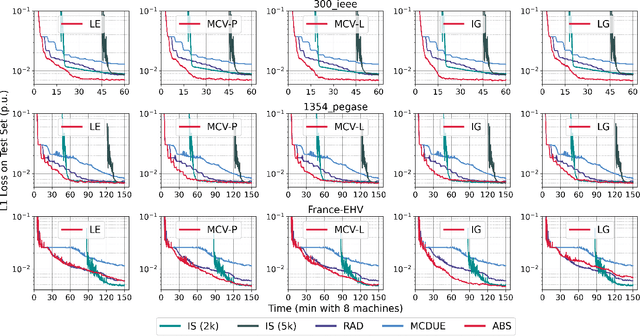
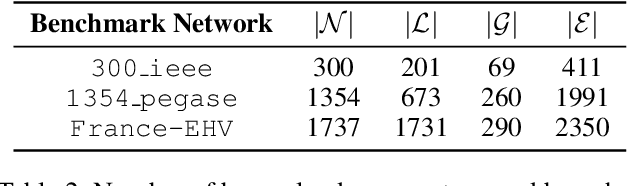
This paper considers optimization proxies for Optimal Power Flow (OPF), i.e., machine-learning models that approximate the input/output relationship of OPF. Recent work has focused on showing that such proxies can be of high fidelity. However, their training requires significant data, each instance necessitating the (offline) solving of an OPF for a sample of the input distribution. To meet the requirements of market-clearing applications, this paper proposes Active Bucketized Sampling (ABS), a novel active learning framework that aims at training the best possible OPF proxy within a time limit. ABS partitions the input distribution into buckets and uses an acquisition function to determine where to sample next. It relies on an adaptive learning rate that increases and decreases over time. Experimental results demonstrate the benefits of ABS.
Data Leakage in Tabular Federated Learning
Oct 04, 2022

While federated learning (FL) promises to preserve privacy in distributed training of deep learning models, recent work in the image and NLP domains showed that training updates leak private data of participating clients. At the same time, most high-stakes applications of FL (e.g., legal and financial) use tabular data. Compared to the NLP and image domains, reconstruction of tabular data poses several unique challenges: (i) categorical features introduce a significantly more difficult mixed discrete-continuous optimization problem, (ii) the mix of categorical and continuous features causes high variance in the final reconstructions, and (iii) structured data makes it difficult for the adversary to judge reconstruction quality. In this work, we tackle these challenges and propose the first comprehensive reconstruction attack on tabular data, called TabLeak. TabLeak is based on three key ingredients: (i) a softmax structural prior, implicitly converting the mixed discrete-continuous optimization problem into an easier fully continuous one, (ii) a way to reduce the variance of our reconstructions through a pooled ensembling scheme exploiting the structure of tabular data, and (iii) an entropy measure which can successfully assess reconstruction quality. Our experimental evaluation demonstrates the effectiveness of TabLeak, reaching a state-of-the-art on four popular tabular datasets. For instance, on the Adult dataset, we improve attack accuracy by 10% compared to the baseline on the practically relevant batch size of 32 and further obtain non-trivial reconstructions for batch sizes as large as 128. Our findings are important as they show that performing FL on tabular data, which often poses high privacy risks, is highly vulnerable.
On Background Bias in Deep Metric Learning
Oct 04, 2022

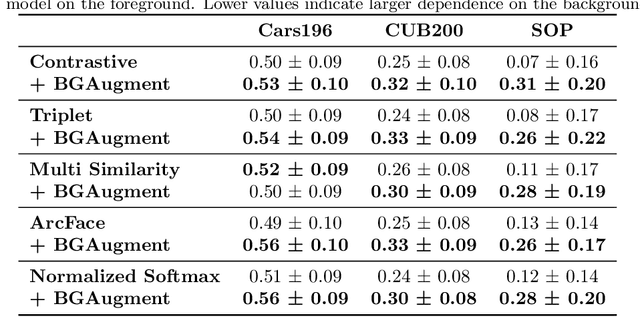
Deep Metric Learning trains a neural network to map input images to a lower-dimensional embedding space such that similar images are closer together than dissimilar images. When used for item retrieval, a query image is embedded using the trained model and the closest items from a database storing their respective embeddings are returned as the most similar items for the query. Especially in product retrieval, where a user searches for a certain product by taking a photo of it, the image background is usually not important and thus should not influence the embedding process. Ideally, the retrieval process always returns fitting items for the photographed object, regardless of the environment the photo was taken in. In this paper, we analyze the influence of the image background on Deep Metric Learning models by utilizing five common loss functions and three common datasets. We find that Deep Metric Learning networks are prone to so-called background bias, which can lead to a severe decrease in retrieval performance when changing the image background during inference. We also show that replacing the background of images during training with random background images alleviates this issue. Since we use an automatic background removal method to do this background replacement, no additional manual labeling work and model changes are required while inference time stays the same. Qualitative and quantitative analyses, for which we introduce a new evaluation metric, confirm that models trained with replaced backgrounds attend more to the main object in the image, benefitting item retrieval systems.