 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Mini-Batch Learning Strategies for modeling long term temporal dependencies: A study in environmental applications
Oct 15, 2022

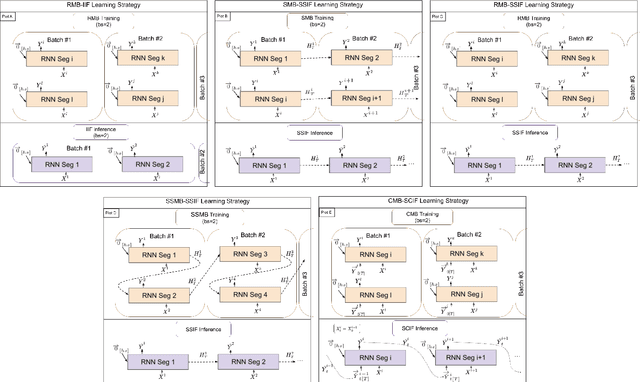
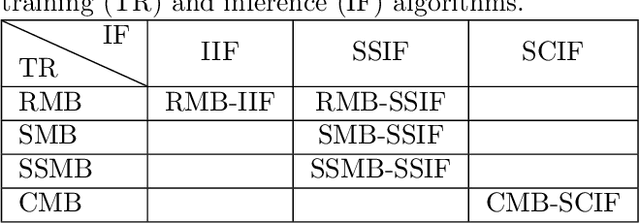
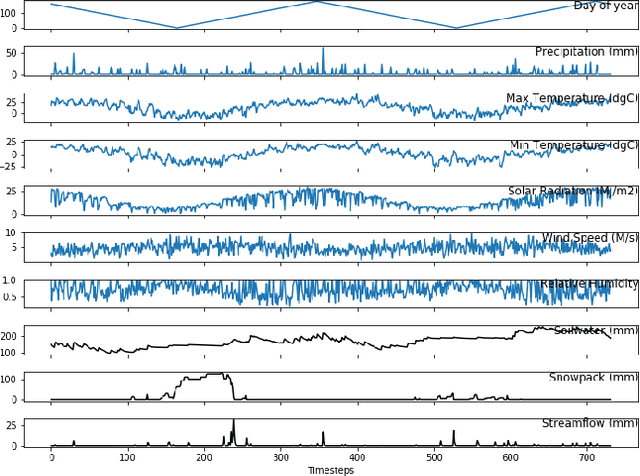
In many environmental applications, recurrent neural networks (RNNs) are often used to model physical variables with long temporal dependencies. However, due to mini-batch training, temporal relationships between training segments within the batch (intra-batch) as well as between batches (inter-batch) are not considered, which can lead to limited performance. Stateful RNNs aim to address this issue by passing hidden states between batches. Since Stateful RNNs ignore intra-batch temporal dependency, there exists a trade-off between training stability and capturing temporal dependency. In this paper, we provide a quantitative comparison of different Stateful RNN modeling strategies, and propose two strategies to enforce both intra- and inter-batch temporal dependency. First, we extend Stateful RNNs by defining a batch as a temporally ordered set of training segments, which enables intra-batch sharing of temporal information. While this approach significantly improves the performance, it leads to much larger training times due to highly sequential training. To address this issue, we further propose a new strategy which augments a training segment with an initial value of the target variable from the timestep right before the starting of the training segment. In other words, we provide an initial value of the target variable as additional input so that the network can focus on learning changes relative to that initial value. By using this strategy, samples can be passed in any order (mini-batch training) which significantly reduces the training time while maintaining the performance. In demonstrating our approach in hydrological modeling, we observe that the most significant gains in predictive accuracy occur when these methods are applied to state variables whose values change more slowly, such as soil water and snowpack, rather than continuously moving flux variables such as streamflow.
Spatio-temporal Keyframe Control of Traffic Simulation using Coarse-to-Fine Optimization
Sep 26, 2022
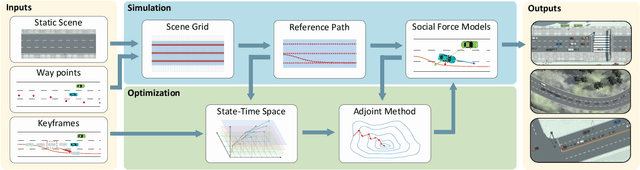

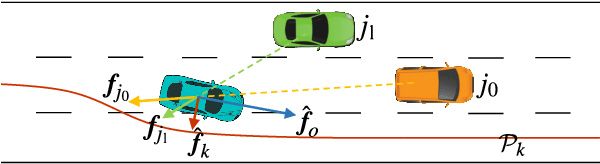
We present a novel traffic trajectory editing method which uses spatio-temporal keyframes to control vehicles during the simulation to generate desired traffic trajectories. By taking self-motivation, path following and collision avoidance into account, the proposed force-based traffic simulation framework updates vehicle's motions in both the Frenet coordinates and the Cartesian coordinates. With the way-points from users, lane-level navigation can be generated by reference path planning. With a given keyframe, the coarse-to-fine optimization is proposed to efficiently generate the plausible trajectory which can satisfy the spatio-temporal constraints. At first, a directed state-time graph constructed along the reference path is used to search for a coarse-grained trajectory by mapping the keyframe as the goal. Then, using the information extracted from the coarse trajectory as initialization, adjoint-based optimization is applied to generate a finer trajectory with smooth motions based on our force-based simulation. We validate our method with extensive experiments.
ros2_tracing: Multipurpose Low-Overhead Framework for Real-Time Tracing of ROS 2
Jan 02, 2022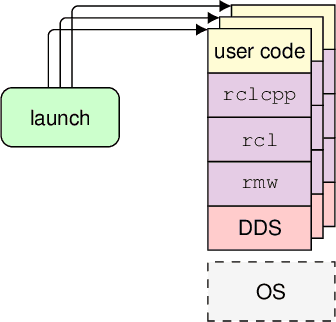
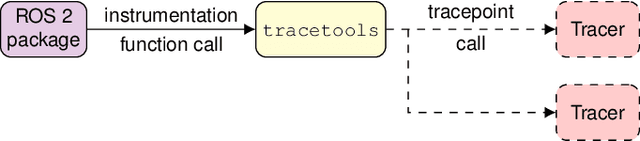
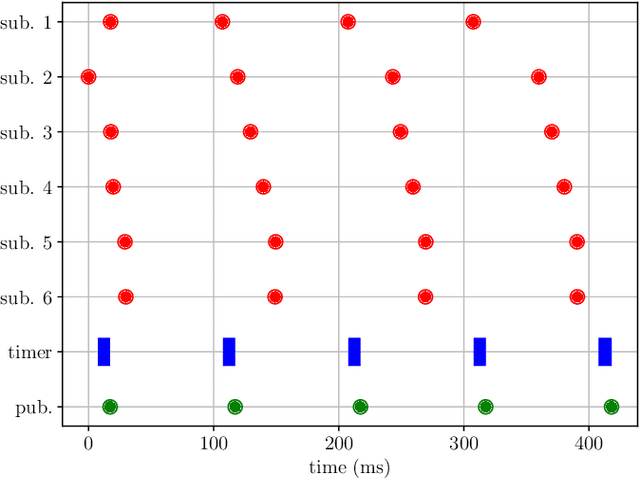
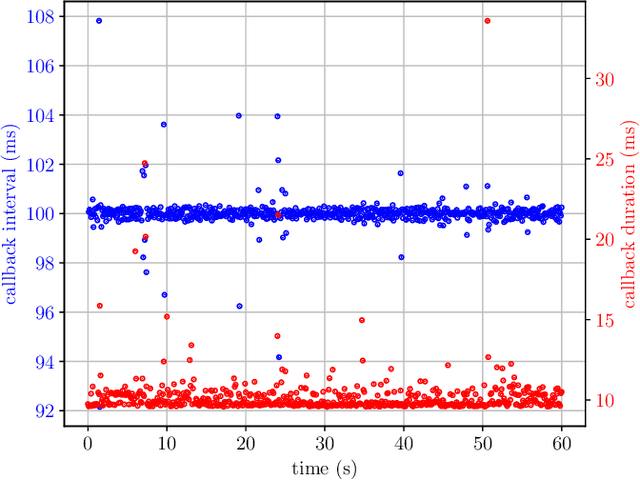
Testing and debugging have become major obstacles for robot software development, because of high system complexity and dynamic environments. Standard, middleware-based data recording does not provide sufficient information on internal computation and performance bottlenecks. Other existing methods also target very specific problems and thus cannot be used for multipurpose analysis. Moreover, they are not suitable for real-time applications. In this paper, we present ros2_tracing, a collection of flexible tracing tools and multipurpose instrumentation for ROS 2. It allows collecting runtime execution information on real-time distributed systems, using the low-overhead LTTng tracer. Tools also integrate tracing into the invaluable ROS 2 orchestration system and other usability tools. A message latency experiment shows that the end-to-end message latency overhead, when enabling all ROS 2 instrumentation, is below 0.0055 ms, which we believe is suitable for production real-time systems. ROS 2 execution information obtained using ros2_tracing can be combined with trace data from the operating system, enabling a wider range of precise analyses, that help understand an application execution, to find the cause of performance bottlenecks and other issues. The source code is available at: https://gitlab.com/ros-tracing/ros2_tracing.
Adversarially Robust Prototypical Few-shot Segmentation with Neural-ODEs
Oct 07, 2022Few-shot Learning (FSL) methods are being adopted in settings where data is not abundantly available. This is especially seen in medical domains where the annotations are expensive to obtain. Deep Neural Networks have been shown to be vulnerable to adversarial attacks. This is even more severe in the case of FSL due to the lack of a large number of training examples. In this paper, we provide a framework to make few-shot segmentation models adversarially robust in the medical domain where such attacks can severely impact the decisions made by clinicians who use them. We propose a novel robust few-shot segmentation framework, Prototypical Neural Ordinary Differential Equation (PNODE), that provides defense against gradient-based adversarial attacks. We show that our framework is more robust compared to traditional adversarial defense mechanisms such as adversarial training. Adversarial training involves increased training time and shows robustness to limited types of attacks depending on the type of adversarial examples seen during training. Our proposed framework generalises well to common adversarial attacks like FGSM, PGD and SMIA while having the model parameters comparable to the existing few-shot segmentation models. We show the effectiveness of our proposed approach on three publicly available multi-organ segmentation datasets in both in-domain and cross-domain settings by attacking the support and query sets without the need for ad-hoc adversarial training.
Elastic Step DQN: A novel multi-step algorithm to alleviate overestimation in Deep QNetworks
Oct 07, 2022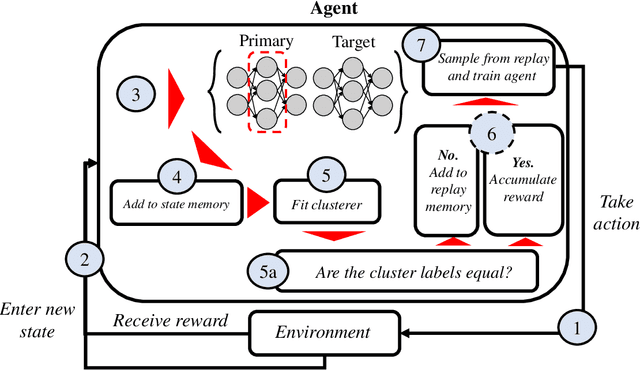
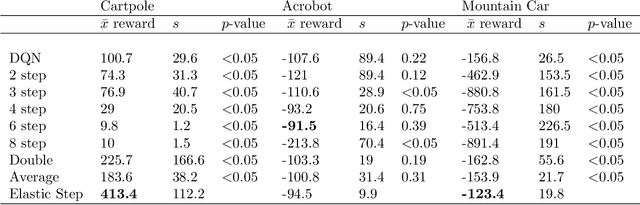
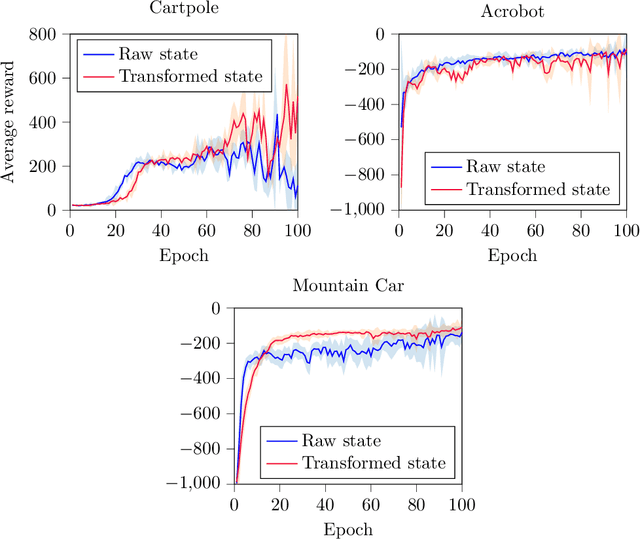
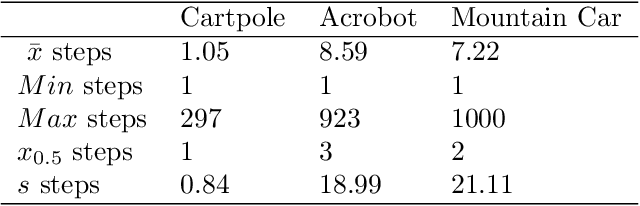
Deep Q-Networks algorithm (DQN) was the first reinforcement learning algorithm using deep neural network to successfully surpass human level performance in a number of Atari learning environments. However, divergent and unstable behaviour have been long standing issues in DQNs. The unstable behaviour is often characterised by overestimation in the $Q$-values, commonly referred to as the overestimation bias. To address the overestimation bias and the divergent behaviour, a number of heuristic extensions have been proposed. Notably, multi-step updates have been shown to drastically reduce unstable behaviour while improving agent's training performance. However, agents are often highly sensitive to the selection of the multi-step update horizon ($n$), and our empirical experiments show that a poorly chosen static value for $n$ can in many cases lead to worse performance than single-step DQN. Inspired by the success of $n$-step DQN and the effects that multi-step updates have on overestimation bias, this paper proposes a new algorithm that we call `Elastic Step DQN' (ES-DQN). It dynamically varies the step size horizon in multi-step updates based on the similarity of states visited. Our empirical evaluation shows that ES-DQN out-performs $n$-step with fixed $n$ updates, Double DQN and Average DQN in several OpenAI Gym environments while at the same time alleviating the overestimation bias.
KAST: Knowledge Aware Adaptive Session Multi-Topic Network for Click-Through Rate Prediction
Oct 07, 2022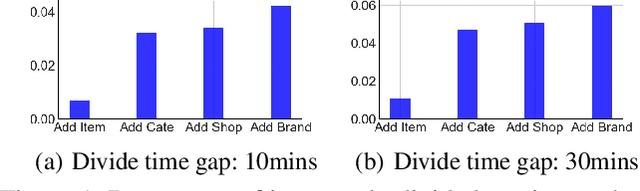
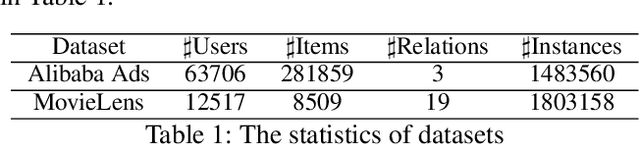
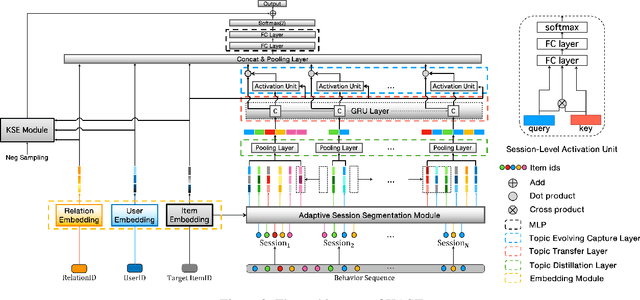
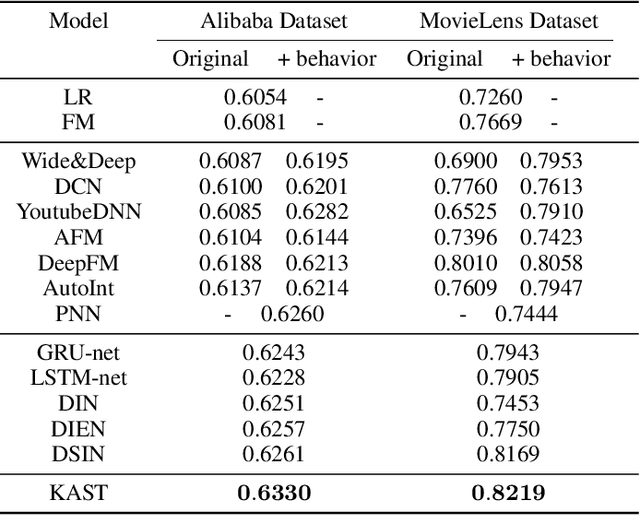
Capturing the evolving trends of user interest is important for both recommendation systems and advertising systems, and user behavior sequences have been successfully used in Click-Through-Rate(CTR) prediction problems. However, if the user interest is learned on the basis of item-level behaviors, the performance may be affected by the following two issues. Firstly, some casual outliers might be included in the behavior sequences as user behaviors are likely to be diverse. Secondly, the span of time intervals between user behaviors is random and irregular, for which a RNN-based module employed from NLP is not perfectly adaptive. To handle these two issues, we propose the Knowledge aware Adaptive Session multi-Topic network(KAST). It can adaptively segment user sessions from the whole user behavior sequence, and maintain similar intents in the same session. Furthermore, in order to improve the quality of session segmentation and representation, a knowledge-aware module is introduced so that the structural information from the user-item interaction can be extracted in an end-to-end manner, and a marginal based loss with these information is merged into the major loss. Through extensive experiments on public benchmarks, we demonstrate that KAST can achieve superior performance than state-of-the-art methods for CTR prediction, and key modules and hyper-parameters are also evaluated.
Images as Weight Matrices: Sequential Image Generation Through Synaptic Learning Rules
Oct 07, 2022
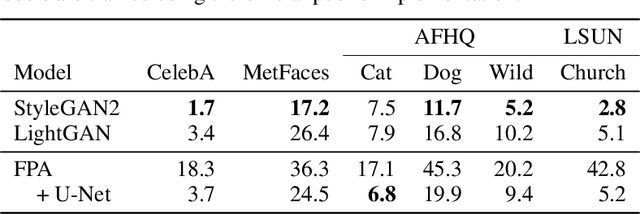
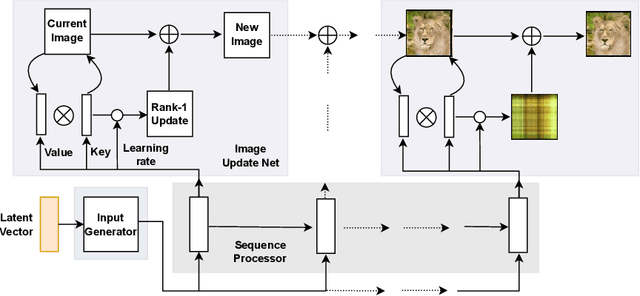
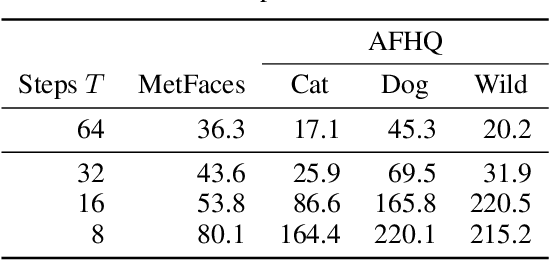
Work on fast weight programmers has demonstrated the effectiveness of key/value outer product-based learning rules for sequentially generating a weight matrix (WM) of a neural net (NN) by another NN or itself. However, the weight generation steps are typically not visually interpretable by humans, because the contents stored in the WM of an NN are not. Here we apply the same principle to generate natural images. The resulting fast weight painters (FPAs) learn to execute sequences of delta learning rules to sequentially generate images as sums of outer products of self-invented keys and values, one rank at a time, as if each image was a WM of an NN. We train our FPAs in the generative adversarial networks framework, and evaluate on various image datasets. We show how these generic learning rules can generate images with respectable visual quality without any explicit inductive bias for images. While the performance largely lags behind the one of specialised state-of-the-art image generators, our approach allows for visualising how synaptic learning rules iteratively produce complex connection patterns, yielding human-interpretable meaningful images. Finally, we also show that an additional convolutional U-Net (now popular in diffusion models) at the output of an FPA can learn one-step "denoising" of FPA-generated images to enhance their quality. Our code is public.
Modeling Inter-Class and Intra-Class Constraints in Novel Class Discovery
Oct 07, 2022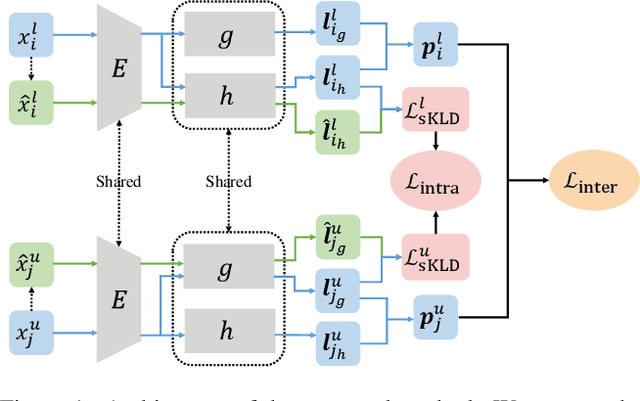
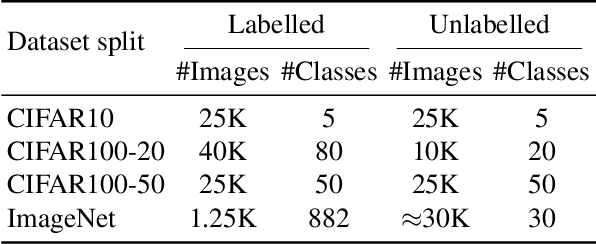
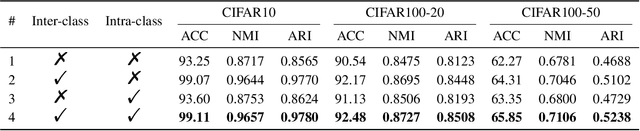
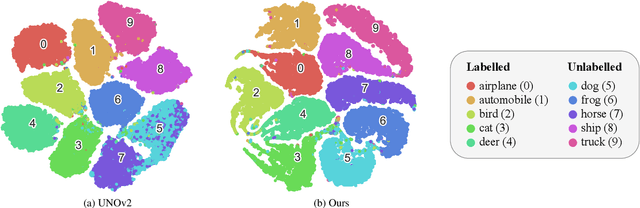
Novel class discovery (NCD) aims at learning a model that transfers the common knowledge from a class-disjoint labelled dataset to another unlabelled dataset and discovers new classes (clusters) within it. Many methods have been proposed as well as elaborate training pipelines and appropriate objectives and considerably boosted the performance on NCD tasks. Despite all this, we find that the existing methods do not sufficiently take advantage of the essence of the NCD setting. To this end, in this paper, we propose to model both inter-class and intra-class constraints in NCD based on the symmetric Kullback-Leibler divergence (sKLD). Specifically, we propose an inter-class sKLD constraint to effectively exploit the disjoint relationship between labelled and unlabelled classes, enforcing the separability for different classes in the embedding space. In addition, we present an intra-class sKLD constraint to explicitly constrain the intra-relationship between samples and their augmentations and ensure the stability of the training process at the same time. We conduct extensive experiments on the popular CIFAR10, CIFAR100 and ImageNet benchmarks and successfully demonstrate that our method can establish a new state of the art and can achieve significantly performance improvements, e.g., $3.6\%$/$7.9\%$ clustering accuracy improvements on CIFAR100-50 under the task-aware/-agnostic evaluation protocol, over previous state-of-the-art methods.
Set2Box: Similarity Preserving Representation Learning of Sets
Oct 07, 2022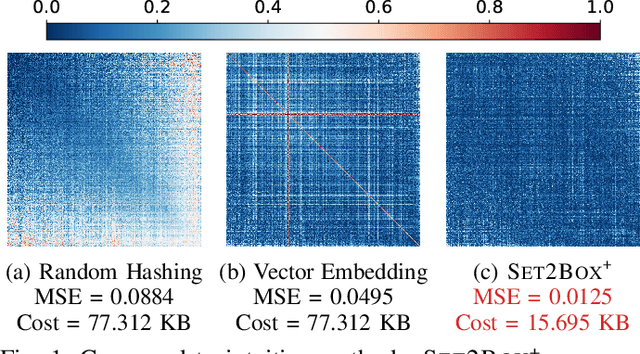

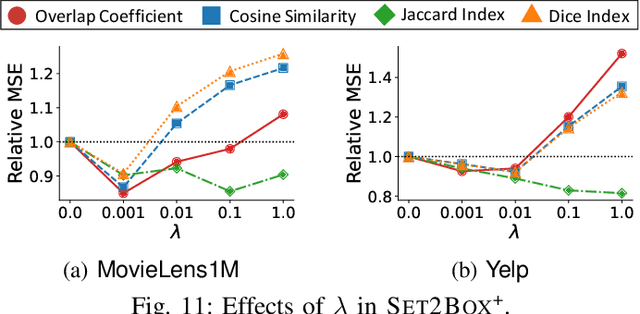
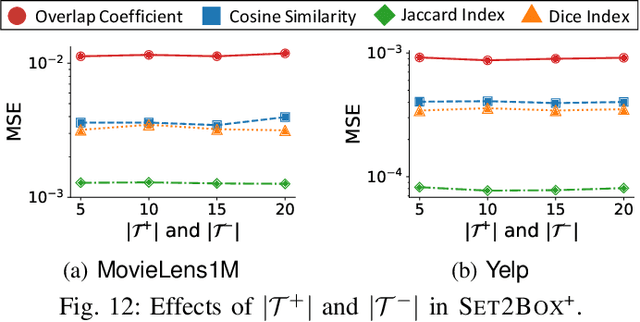
Sets have been used for modeling various types of objects (e.g., a document as the set of keywords in it and a customer as the set of the items that she has purchased). Measuring similarity (e.g., Jaccard Index) between sets has been a key building block of a wide range of applications, including, plagiarism detection, recommendation, and graph compression. However, as sets have grown in numbers and sizes, the computational cost and storage required for set similarity computation have become substantial, and this has led to the development of hashing and sketching based solutions. In this work, we propose Set2Box, a learning-based approach for compressed representations of sets from which various similarity measures can be estimated accurately in constant time. The key idea is to represent sets as boxes to precisely capture overlaps of sets. Additionally, based on the proposed box quantization scheme, we design Set2Box+, which yields more concise but more accurate box representations of sets. Through extensive experiments on 8 real-world datasets, we show that, compared to baseline approaches, Set2Box+ is (a) Accurate: achieving up to 40.8X smaller estimation error while requiring 60% fewer bits to encode sets, (b) Concise: yielding up to 96.8X more concise representations with similar estimation error, and (c) Versatile: enabling the estimation of four set-similarity measures from a single representation of each set.
Learning robotic cutting from demonstration: Non-holonomic DMPs using the Udwadia-Kalaba method
Sep 24, 2022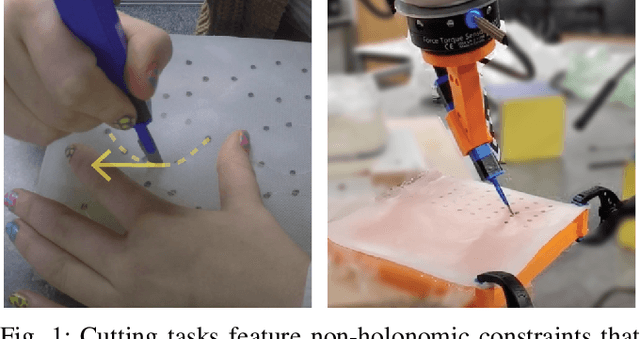

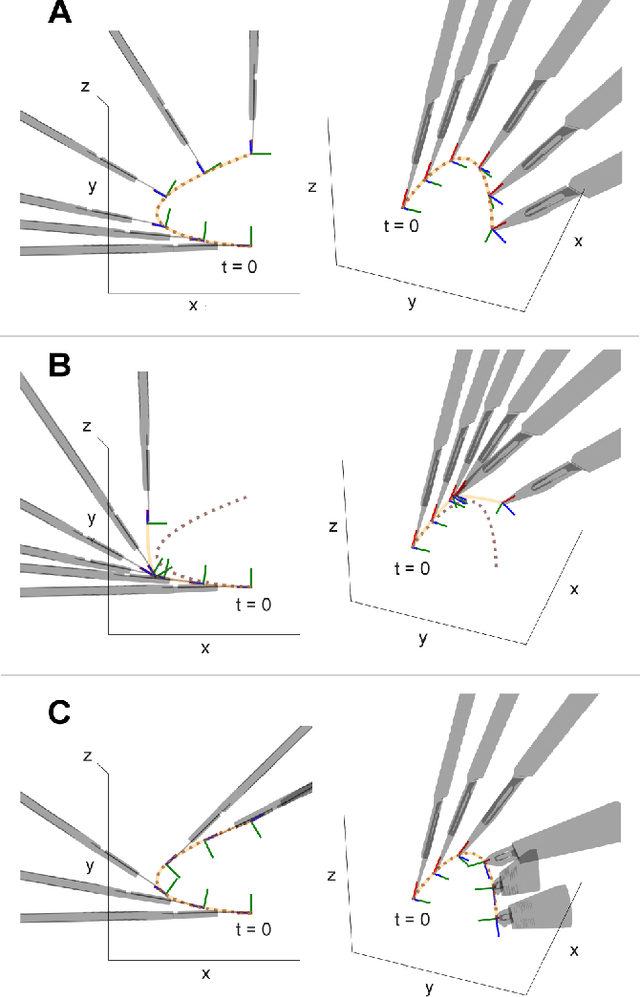

Dynamic Movement Primitives (DMPs) offer great versatility for encoding, generating and adapting complex end-effector trajectories. DMPs are also very well suited to learning manipulation skills from human demonstration. However, the reactive nature of DMPs restricts their applicability for tool use and object manipulation tasks involving non-holonomic constraints, such as scalpel cutting or catheter steering. In this work, we extend the Cartesian space DMP formulation by adding a coupling term that enforces a pre-defined set of non-holonomic constraints. We obtain the closed-form expression for the constraint forcing term using the Udwadia-Kalaba method. This approach offers a clean and practical solution for guaranteed constraint satisfaction at run-time. Further, the proposed analytical form of the constraint forcing term enables efficient trajectory optimization subject to constraints. We demonstrate the usefulness of this approach by showing how we can learn robotic cutting skills from human demonstration.