 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Common human diseases prediction using machine learning based on survey data
Sep 22, 2022




In this era, the moment has arrived to move away from disease as the primary emphasis of medical treatment. Although impressive, the multiple techniques that have been developed to detect the diseases. In this time, there are some types of diseases COVID-19, normal flue, migraine, lung disease, heart disease, kidney disease, diabetics, stomach disease, gastric, bone disease, autism are the very common diseases. In this analysis, we analyze disease symptoms and have done disease predictions based on their symptoms. We studied a range of symptoms and took a survey from people in order to complete the task. Several classification algorithms have been employed to train the model. Furthermore, performance evaluation matrices are used to measure the model's performance. Finally, we discovered that the part classifier surpasses the others.
Learning Decoupled Retrieval Representation for Nearest Neighbour Neural Machine Translation
Sep 20, 2022



K-Nearest Neighbor Neural Machine Translation (kNN-MT) successfully incorporates external corpus by retrieving word-level representations at test time. Generally, kNN-MT borrows the off-the-shelf context representation in the translation task, e.g., the output of the last decoder layer, as the query vector of the retrieval task. In this work, we highlight that coupling the representations of these two tasks is sub-optimal for fine-grained retrieval. To alleviate it, we leverage supervised contrastive learning to learn the distinctive retrieval representation derived from the original context representation. We also propose a fast and effective approach to constructing hard negative samples. Experimental results on five domains show that our approach improves the retrieval accuracy and BLEU score compared to vanilla kNN-MT.
Blinder: End-to-end Privacy Protection in Sensing Systems via Personalized Federated Learning
Sep 27, 2022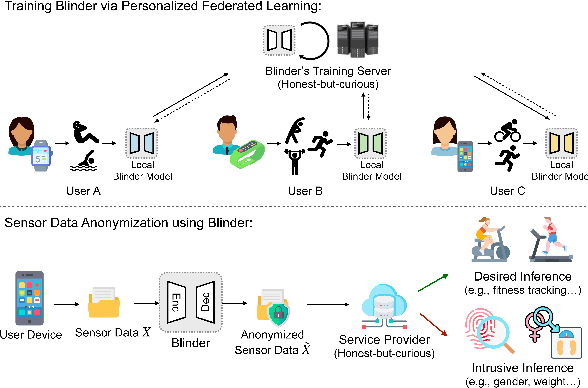

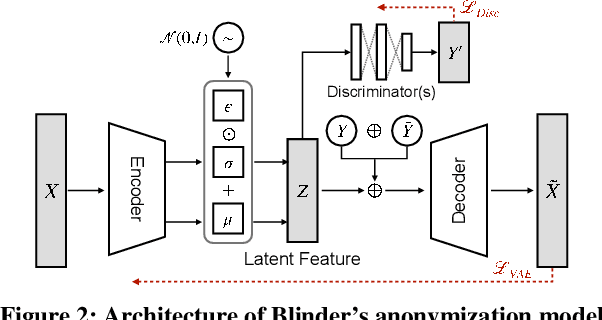
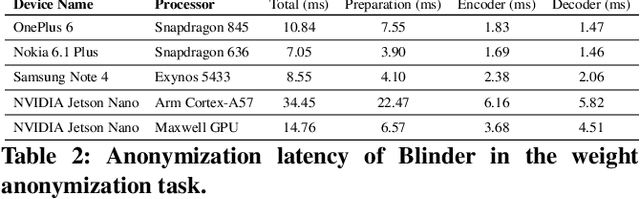
This paper proposes a sensor data anonymization model that is trained on decentralized data and strikes a desirable trade-off between data utility and privacy, even in heterogeneous settings where the collected sensor data have different underlying distributions. Our anonymization model, dubbed Blinder, is based on a variational autoencoder and discriminator networks trained in an adversarial fashion. We use the model-agnostic meta-learning framework to adapt the anonymization model trained via federated learning to each user's data distribution. We evaluate Blinder under different settings and show that it provides end-to-end privacy protection at the cost of increasing privacy loss by up to 4.00% and decreasing data utility by up to 4.24%, compared to the state-of-the-art anonymization model trained on centralized data. Our experiments confirm that Blinder can obscure multiple private attributes at once, and has sufficiently low power consumption and computational overhead for it to be deployed on edge devices and smartphones to perform real-time anonymization of sensor data.
Graph2Vid: Flow graph to Video Grounding forWeakly-supervised Multi-Step Localization
Oct 10, 2022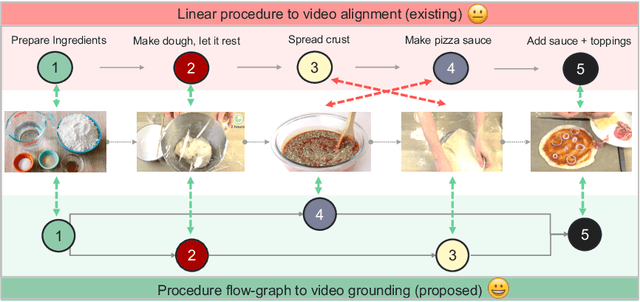
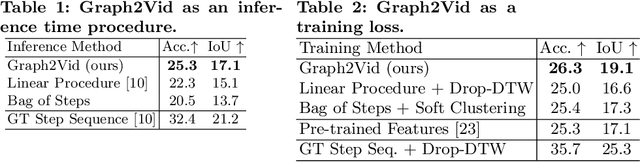

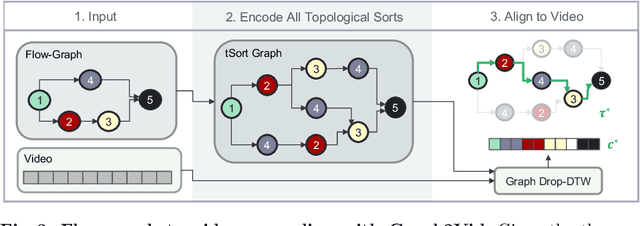
In this work, we consider the problem of weakly-supervised multi-step localization in instructional videos. An established approach to this problem is to rely on a given list of steps. However, in reality, there is often more than one way to execute a procedure successfully, by following the set of steps in slightly varying orders. Thus, for successful localization in a given video, recent works require the actual order of procedure steps in the video, to be provided by human annotators at both training and test times. Instead, here, we only rely on generic procedural text that is not tied to a specific video. We represent the various ways to complete the procedure by transforming the list of instructions into a procedure flow graph which captures the partial order of steps. Using the flow graphs reduces both training and test time annotation requirements. To this end, we introduce the new problem of flow graph to video grounding. In this setup, we seek the optimal step ordering consistent with the procedure flow graph and a given video. To solve this problem, we propose a new algorithm - Graph2Vid - that infers the actual ordering of steps in the video and simultaneously localizes them. To show the advantage of our proposed formulation, we extend the CrossTask dataset with procedure flow graph information. Our experiments show that Graph2Vid is both more efficient than the baselines and yields strong step localization results, without the need for step order annotation.
* ECCV'22, oral
Multi-dataset Training of Transformers for Robust Action Recognition
Sep 27, 2022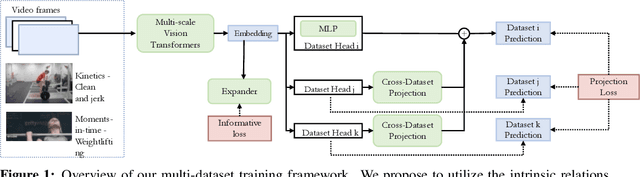
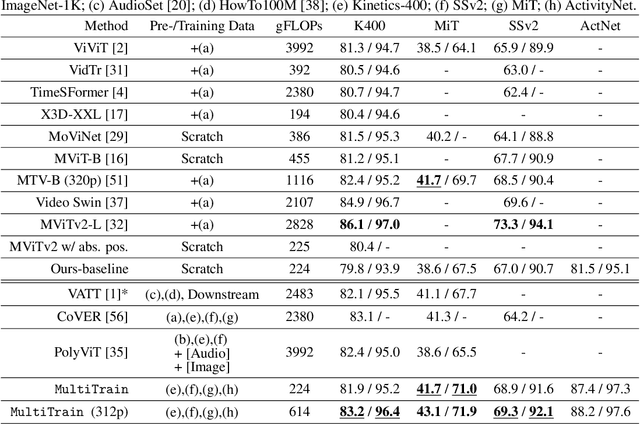
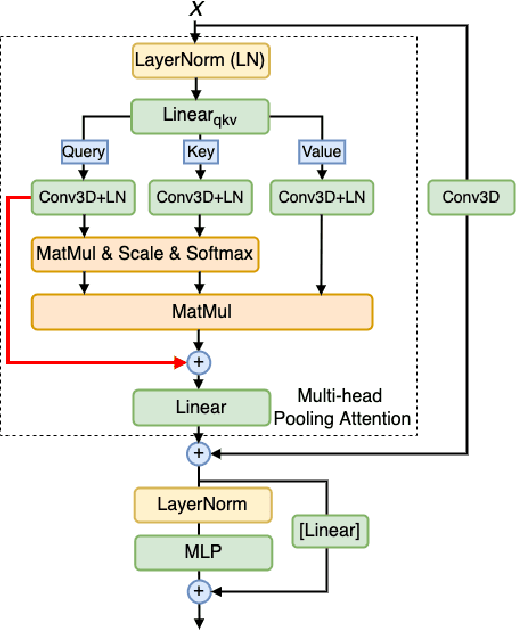

We study the task of robust feature representations, aiming to generalize well on multiple datasets for action recognition. We build our method on Transformers for its efficacy. Although we have witnessed great progress for video action recognition in the past decade, it remains challenging yet valuable how to train a single model that can perform well across multiple datasets. Here, we propose a novel multi-dataset training paradigm, MultiTrain, with the design of two new loss terms, namely informative loss and projection loss, aiming to learn robust representations for action recognition. In particular, the informative loss maximizes the expressiveness of the feature embedding while the projection loss for each dataset mines the intrinsic relations between classes across datasets. We verify the effectiveness of our method on five challenging datasets, Kinetics-400, Kinetics-700, Moments-in-Time, Activitynet and Something-something-v2 datasets. Extensive experimental results show that our method can consistently improve the state-of-the-art performance.
On Text Style Transfer via Style Masked Language Models
Oct 12, 2022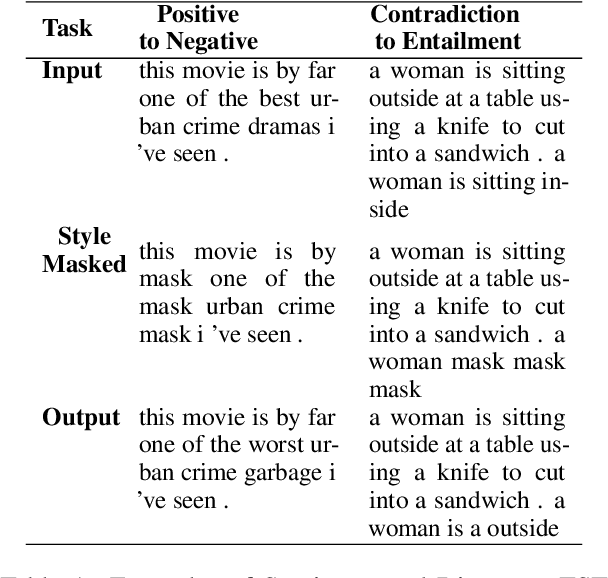
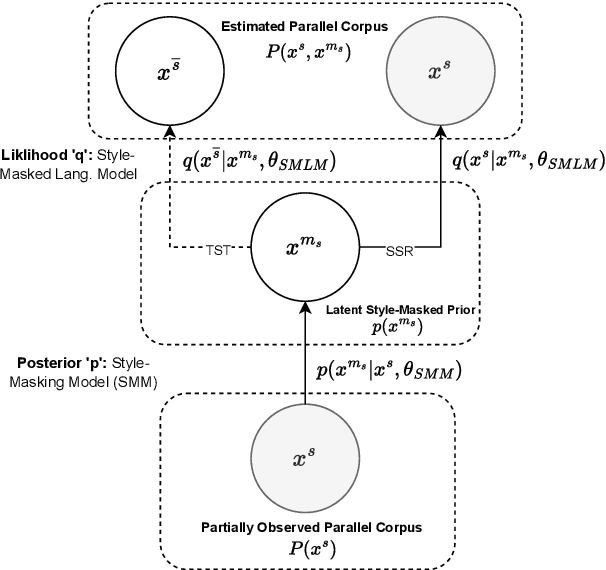
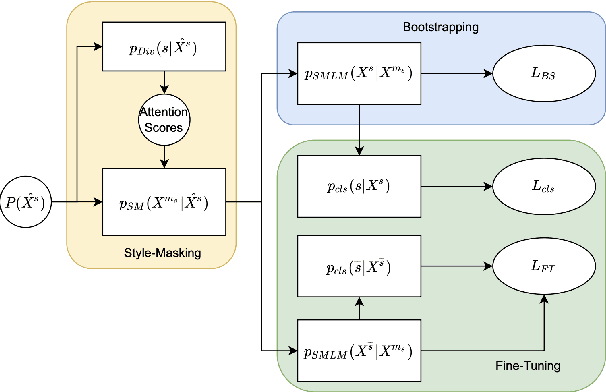
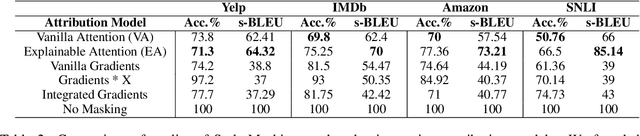
Text Style Transfer (TST) is performable through approaches such as latent space disentanglement, cycle-consistency losses, prototype editing etc. The prototype editing approach, which is known to be quite successful in TST, involves two key phases a) Masking of source style-associated tokens and b) Reconstruction of this source-style masked sentence conditioned with the target style. We follow a similar transduction method, in which we transpose the more difficult direct source to target TST task to a simpler Style-Masked Language Model (SMLM) Task, wherein, similar to BERT \cite{bert}, the goal of our model is now to reconstruct the source sentence from its style-masked version. We arrive at the SMLM mechanism naturally by formulating prototype editing/ transduction methods in a probabilistic framework, where TST resolves into estimating a hypothetical parallel dataset from a partially observed parallel dataset, wherein each domain is assumed to have a common latent style-masked prior. To generate this style-masked prior, we use "Explainable Attention" as our choice of attribution for a more precise style-masking step and also introduce a cost-effective and accurate "Attribution-Surplus" method of determining the position of masks from any arbitrary attribution model in O(1) time. We empirically show that this non-generational approach well suites the "content preserving" criteria for a task like TST, even for a complex style like Discourse Manipulation. Our model, the Style MLM, outperforms strong TST baselines and is on par with state-of-the-art TST models, which use complex architectures and orders of more parameters.
Suspicious and Anomaly Detection
Sep 08, 2022In this project we propose a CNN architecture to detect anomaly and suspicious activities; the activities chosen for the project are running, jumping and kicking in public places and carrying gun, bat and knife in public places. With the trained model we compare it with the pre-existing models like Yolo, vgg16, vgg19. The trained Model is then implemented for real time detection and also used the. tflite format of the trained .h5 model to build an android classification.
Merged-GHCIDR: Geometrical Approach to Reduce Image Data
Sep 06, 2022
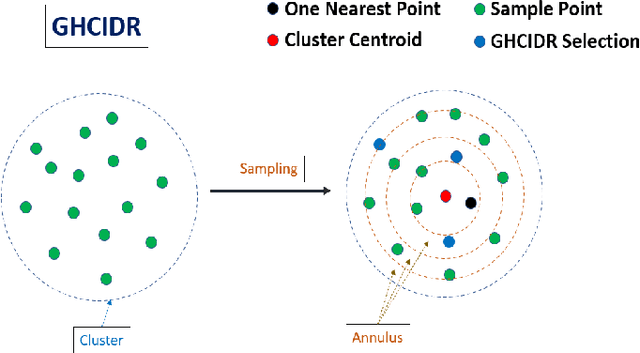
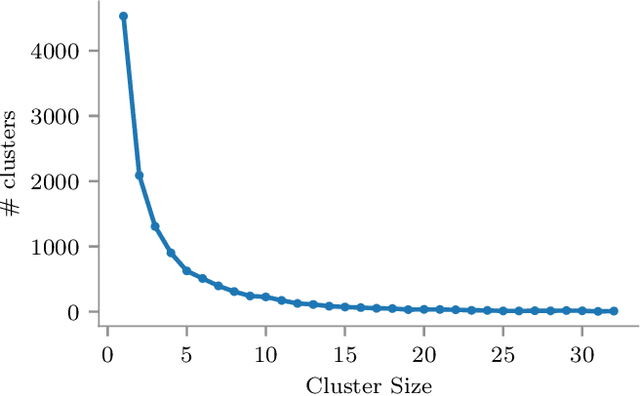
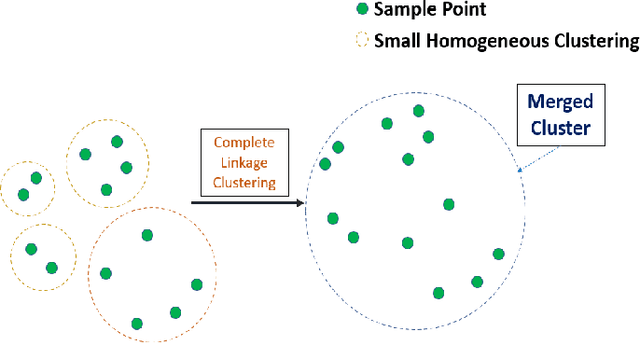
The computational resources required to train a model have been increasing since the inception of deep networks. Training neural networks on massive datasets have become a challenging and time-consuming task. So, there arises a need to reduce the dataset without compromising the accuracy. In this paper, we present novel variations of an earlier approach called reduction through homogeneous clustering for reducing dataset size. The proposed methods are based on the idea of partitioning the dataset into homogeneous clusters and selecting images that contribute significantly to the accuracy. We propose two variations: Geometrical Homogeneous Clustering for Image Data Reduction (GHCIDR) and Merged-GHCIDR upon the baseline algorithm - Reduction through Homogeneous Clustering (RHC) to achieve better accuracy and training time. The intuition behind GHCIDR involves selecting data points by cluster weights and geometrical distribution of the training set. Merged-GHCIDR involves merging clusters having the same labels using complete linkage clustering. We used three deep learning models- Fully Connected Networks (FCN), VGG1, and VGG16. We experimented with the two variants on four datasets- MNIST, CIFAR10, Fashion-MNIST, and Tiny-Imagenet. Merged-GHCIDR with the same percentage reduction as RHC showed an increase of 2.8%, 8.9%, 7.6% and 3.5% accuracy on MNIST, Fashion-MNIST, CIFAR10, and Tiny-Imagenet, respectively.
Out-of-Distribution Detection and Selective Generation for Conditional Language Models
Sep 30, 2022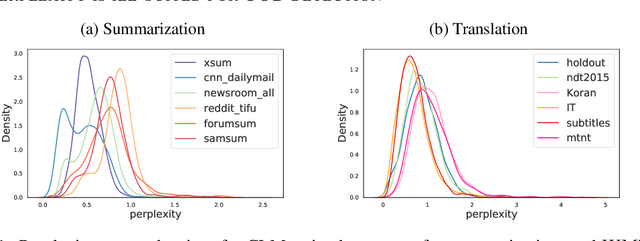
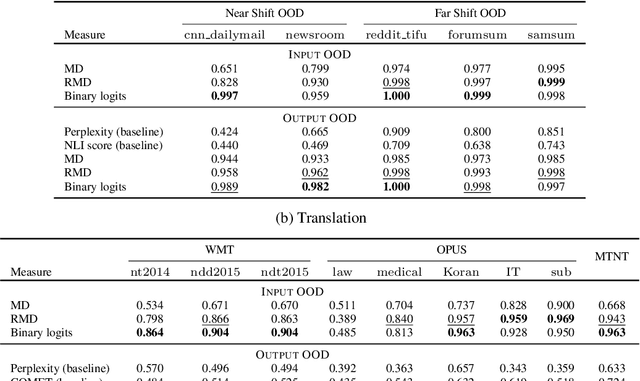
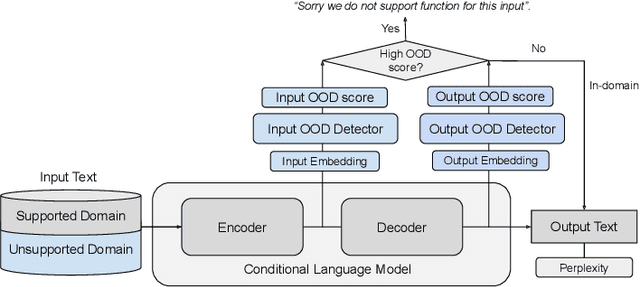
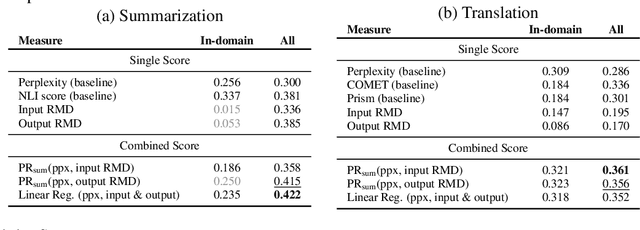
Machine learning algorithms typically assume independent and identically distributed samples in training and at test time. Much work has shown that high-performing ML classifiers can degrade significantly and provide overly-confident, wrong classification predictions, particularly for out-of-distribution (OOD) inputs. Conditional language models (CLMs) are predominantly trained to classify the next token in an output sequence, and may suffer even worse degradation on OOD inputs as the prediction is done auto-regressively over many steps. Furthermore, the space of potential low-quality outputs is larger as arbitrary text can be generated and it is important to know when to trust the generated output. We present a highly accurate and lightweight OOD detection method for CLMs, and demonstrate its effectiveness on abstractive summarization and translation. We also show how our method can be used under the common and realistic setting of distribution shift for selective generation (analogous to selective prediction for classification) of high-quality outputs, while automatically abstaining from low-quality ones, enabling safer deployment of generative language models.
Efficient LSTM Training with Eligibility Traces
Sep 30, 2022Training recurrent neural networks is predominantly achieved via backpropagation through time (BPTT). However, this algorithm is not an optimal solution from both a biological and computational perspective. A more efficient and biologically plausible alternative for BPTT is e-prop. We investigate the applicability of e-prop to long short-term memorys (LSTMs), for both supervised and reinforcement learning (RL) tasks. We show that e-prop is a suitable optimization algorithm for LSTMs by comparing it to BPTT on two benchmarks for supervised learning. This proves that e-prop can achieve learning even for problems with long sequences of several hundred timesteps. We introduce extensions that improve the performance of e-prop, which can partially be applied to other network architectures. With the help of these extensions we show that, under certain conditions, e-prop can outperform BPTT for one of the two benchmarks for supervised learning. Finally, we deliver a proof of concept for the integration of e-prop to RL in the domain of deep recurrent Q-learning.