 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Visual Detection of Diver Attentiveness for Underwater Human-Robot Interaction
Sep 28, 2022

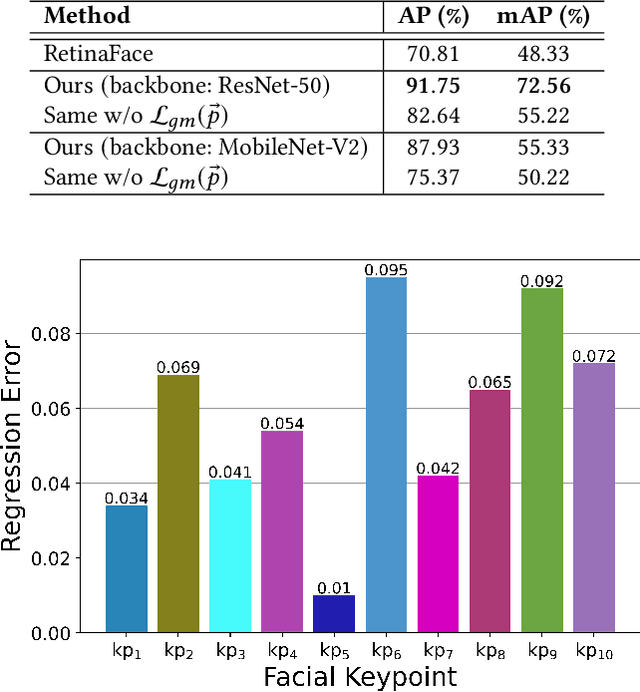


Many underwater tasks, such as cable-and-wreckage inspection, search-and-rescue, benefit from robust human-robot interaction (HRI) capabilities. With the recent advancements in vision-based underwater HRI methods, autonomous underwater vehicles (AUVs) can communicate with their human partners even during a mission. However, these interactions usually require active participation especially from humans (e.g., one must keep looking at the robot during an interaction). Therefore, an AUV must know when to start interacting with a human partner, i.e., if the human is paying attention to the AUV or not. In this paper, we present a diver attention estimation framework for AUVs to autonomously detect the attentiveness of a diver and then navigate and reorient itself, if required, with respect to the diver to initiate an interaction. The core element of the framework is a deep neural network (called DATT-Net) which exploits the geometric relation among 10 facial keypoints of the divers to determine their head orientation. Our on-the-bench experimental evaluations (using unseen data) demonstrate that the proposed DATT-Net architecture can determine the attentiveness of human divers with promising accuracy. Our real-world experiments also confirm the efficacy of DATT-Net which enables real-time inference and allows the AUV to position itself for an AUV-diver interaction.
Real-Time Seizure Detection using EEG: A Comprehensive Comparison of Recent Approaches under a Realistic Setting
Jan 21, 2022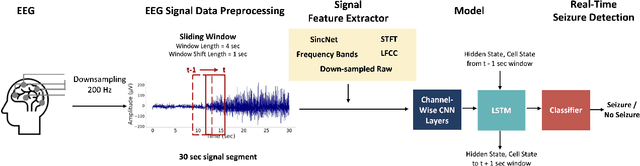
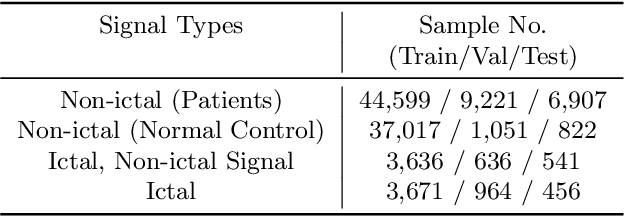
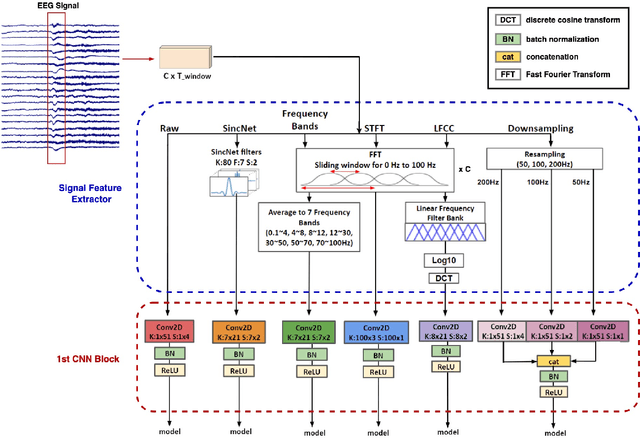
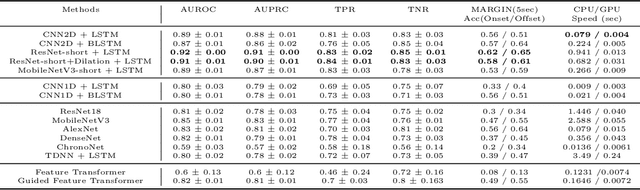
Electroencephalogram (EEG) is an important diagnostic test that physicians use to record brain activity and detect seizures by monitoring the signals. There have been several attempts to detect seizures and abnormalities in EEG signals with modern deep learning models to reduce the clinical burden. However, they cannot be fairly compared against each other as they were tested in distinct experimental settings. Also, some of them are not trained in real-time seizure detection tasks, making it hard for on-device applications. Therefore in this work, for the first time, we extensively compare multiple state-of-the-art models and signal feature extractors in a real-time seizure detection framework suitable for real-world application, using various evaluation metrics including a new one we propose to evaluate more practical aspects of seizure detection models. Our code is available at https://github.com/AITRICS/EEG_real_time_seizure_detection.
Time Series Forecasting with Ensembled Stochastic Differential Equations Driven by Lévy Noise
Nov 25, 2021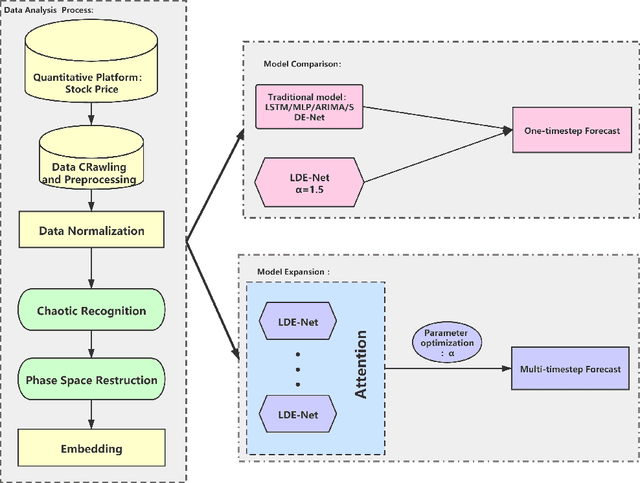

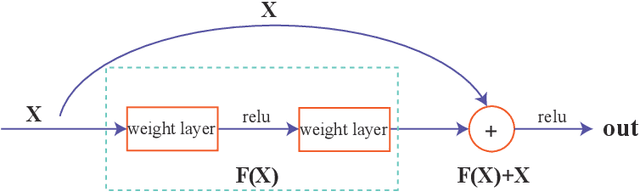
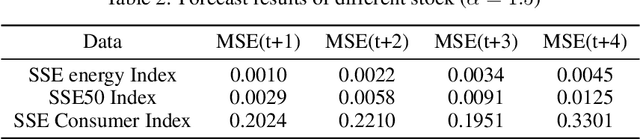
With the fast development of modern deep learning techniques, the study of dynamic systems and neural networks is increasingly benefiting each other in a lot of different ways. Since uncertainties often arise in real world observations, SDEs (stochastic differential equations) come to play an important role. To be more specific, in this paper, we use a collection of SDEs equipped with neural networks to predict long-term trend of noisy time series which has big jump properties and high probability distribution shift. Our contributions are, first, we use the phase space reconstruction method to extract intrinsic dimension of the time series data so as to determine the input structure for our forecasting model. Second, we explore SDEs driven by $\alpha$-stable L\'evy motion to model the time series data and solve the problem through neural network approximation. Third, we construct the attention mechanism to achieve multi-time step prediction. Finally, we illustrate our method by applying it to stock marketing time series prediction and show the results outperform several baseline deep learning models.
Adaptive and Collaborative Bathymetric Channel-Finding Approach for Multiple Autonomous Marine Vehicle
Sep 20, 2022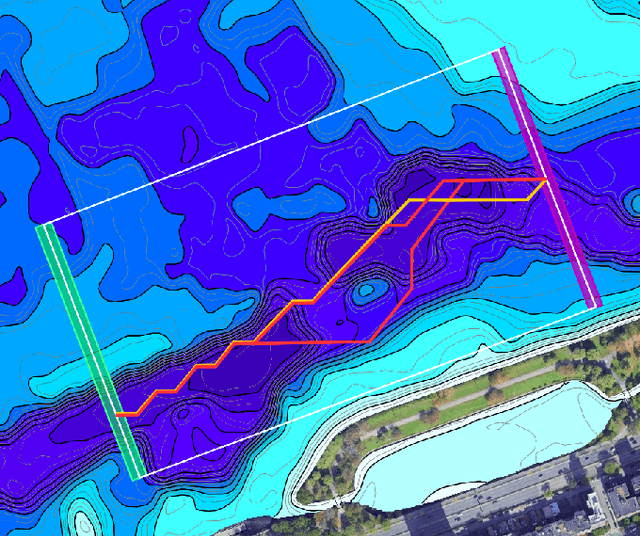

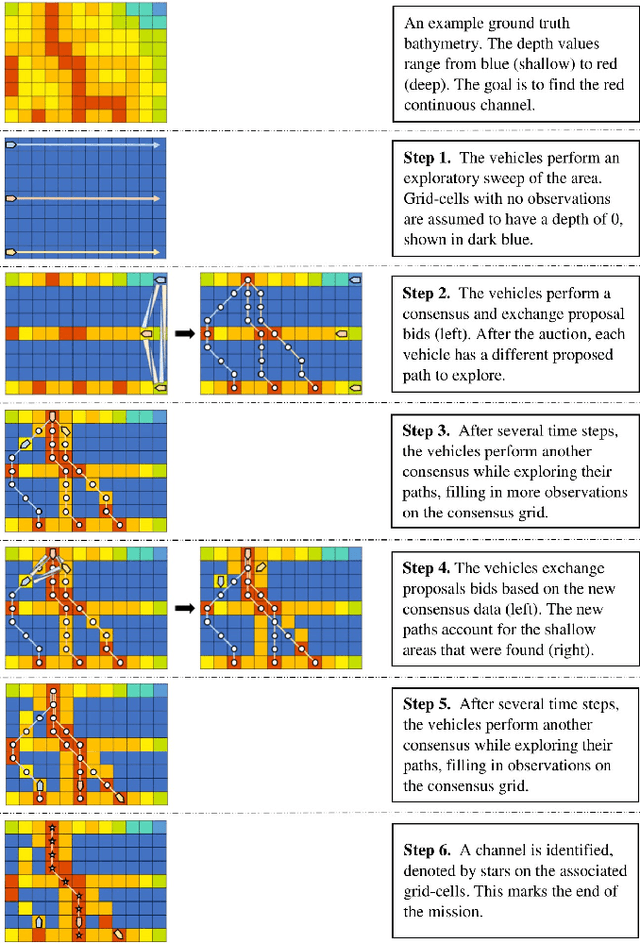
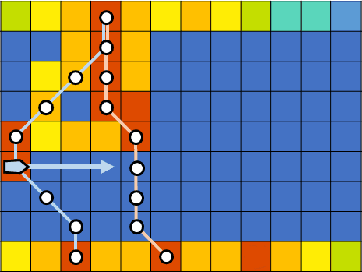
This paper reports an investigation into the problem of rapid identification of a channel that crosses a body of water using one or more Unmanned Surface Vehicles (USV). A new algorithm called Proposal Based Adaptive Channel Search (PBACS) is presented as a potential solution that improves upon current methods. The empirical performance of PBACS is compared to lawnmower surveying and to Markov decision process (MDP) planning with two state-of-the-art reward functions: Upper Confidence Bound (UCB) and Maximum Value Information (MVI). The performance of each method is evaluated through comparison of the time it takes to identify a continuous channel through an area, using one, two, three, or four USVs. The performance of each method is compared across ten simulated bathymetry scenarios and one field area, each with different channel layouts. The results from simulations and field trials indicate that on average multi-vehicle PBACS outperforms lawnmower, UCB, and MVI based methods, especially when at least three vehicles are used.
Modelling Patient Trajectories Using Multimodal Information
Sep 09, 2022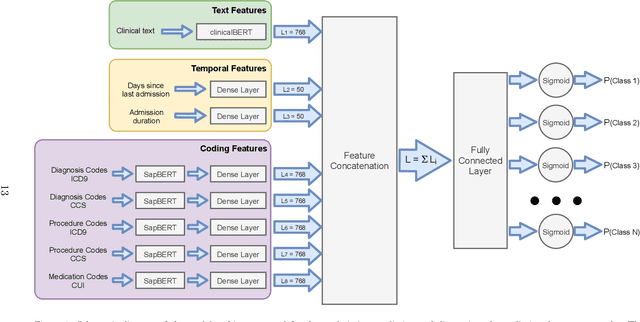
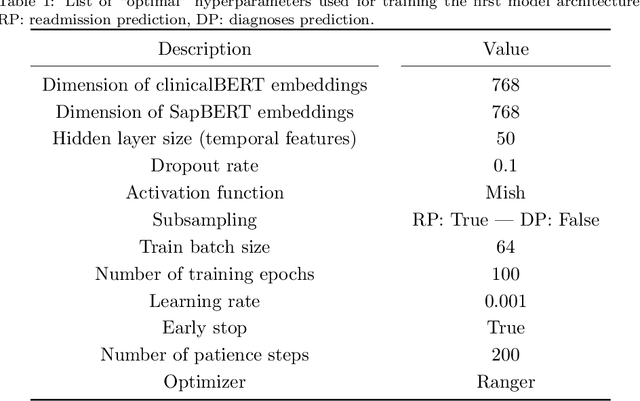
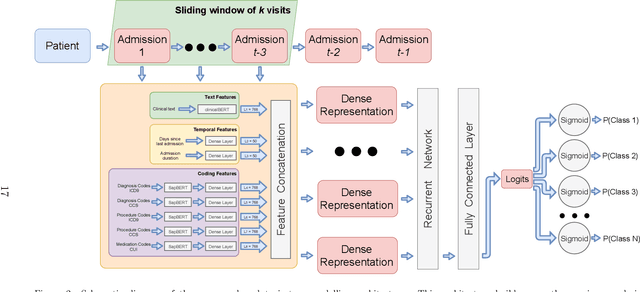

Electronic Health Records (EHRs) aggregate diverse information at the patient level, holding a trajectory representative of the evolution of the patient health status throughout time. Although this information provides context and can be leveraged by physicians to monitor patient health and make more accurate prognoses/diagnoses, patient records can contain information from very long time spans, which combined with the rapid generation rate of medical data makes clinical decision making more complex. Patient trajectory modelling can assist by exploring existing information in a scalable manner, and can contribute in augmenting health care quality by fostering preventive medicine practices. We propose a solution to model patient trajectories that combines different types of information and considers the temporal aspect of clinical data. This solution leverages two different architectures: one supporting flexible sets of input features, to convert patient admissions into dense representations; and a second exploring extracted admission representations in a recurrent-based architecture, where patient trajectories are processed in sub-sequences using a sliding window mechanism. The developed solution was evaluated on two different clinical outcomes, unexpected patient readmission and disease progression, using the publicly available MIMIC-III clinical database. The results obtained demonstrate the potential of the first architecture to model readmission and diagnoses prediction using single patient admissions. While information from clinical text did not show the discriminative power observed in other existing works, this may be explained by the need to fine-tune the clinicalBERT model. Finally, we demonstrate the potential of the sequence-based architecture using a sliding window mechanism to represent the input data, attaining comparable performances to other existing solutions.
Shuffle-QUDIO: accelerate distributed VQE with trainability enhancement and measurement reduction
Sep 26, 2022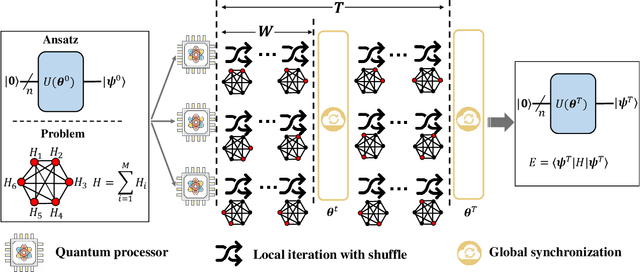

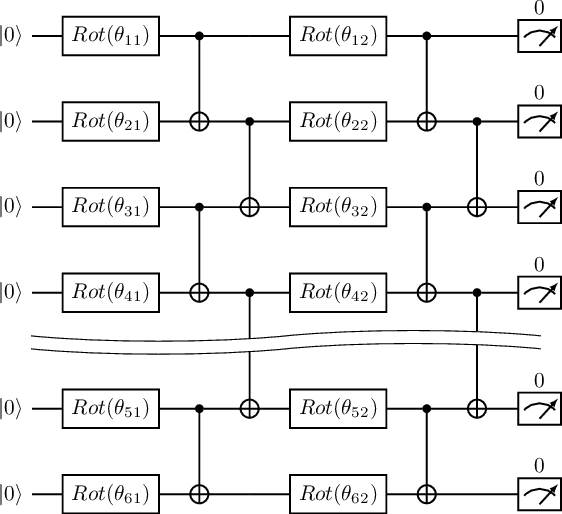
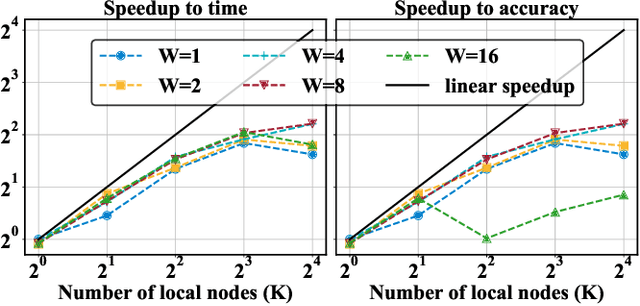
The variational quantum eigensolver (VQE) is a leading strategy that exploits noisy intermediate-scale quantum (NISQ) machines to tackle chemical problems outperforming classical approaches. To gain such computational advantages on large-scale problems, a feasible solution is the QUantum DIstributed Optimization (QUDIO) scheme, which partitions the original problem into $K$ subproblems and allocates them to $K$ quantum machines followed by the parallel optimization. Despite the provable acceleration ratio, the efficiency of QUDIO may heavily degrade by the synchronization operation. To conquer this issue, here we propose Shuffle-QUDIO to involve shuffle operations into local Hamiltonians during the quantum distributed optimization. Compared with QUDIO, Shuffle-QUDIO significantly reduces the communication frequency among quantum processors and simultaneously achieves better trainability. Particularly, we prove that Shuffle-QUDIO enables a faster convergence rate over QUDIO. Extensive numerical experiments are conducted to verify that Shuffle-QUDIO allows both a wall-clock time speedup and low approximation error in the tasks of estimating the ground state energy of molecule. We empirically demonstrate that our proposal can be seamlessly integrated with other acceleration techniques, such as operator grouping, to further improve the efficacy of VQE.
Happy or grumpy? A Machine Learning Approach to Analyze the Sentiment of Airline Passengers' Tweets
Sep 28, 2022
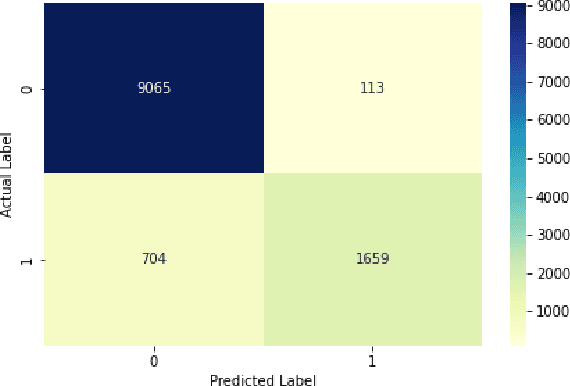
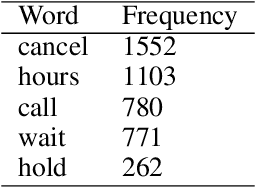
As one of the most extensive social networking services, Twitter has more than 300 million active users as of 2022. Among its many functions, Twitter is now one of the go-to platforms for consumers to share their opinions about products or experiences, including flight services provided by commercial airlines. This study aims to measure customer satisfaction by analyzing sentiments of Tweets that mention airlines using a machine learning approach. Relevant Tweets are retrieved from Twitter's API and processed through tokenization and vectorization. After that, these processed vectors are passed into a pre-trained machine learning classifier to predict the sentiments. In addition to sentiment analysis, we also perform lexical analysis on the collected Tweets to model keywords' frequencies, which provide meaningful contexts to facilitate the interpretation of sentiments. We then apply time series methods such as Bollinger Bands to detect abnormalities in sentiment data. Using historical records from January to July 2022, our approach is proven to be capable of capturing sudden and significant changes in passengers' sentiment. This study has the potential to be developed into an application that can help airlines, along with several other customer-facing businesses, efficiently detect abrupt changes in customers' sentiments and take adequate measures to counteract them.
Jacobian Computation for Cumulative B-splines on SE(3) and Application to Continuous-Time Object Tracking
Jan 25, 2022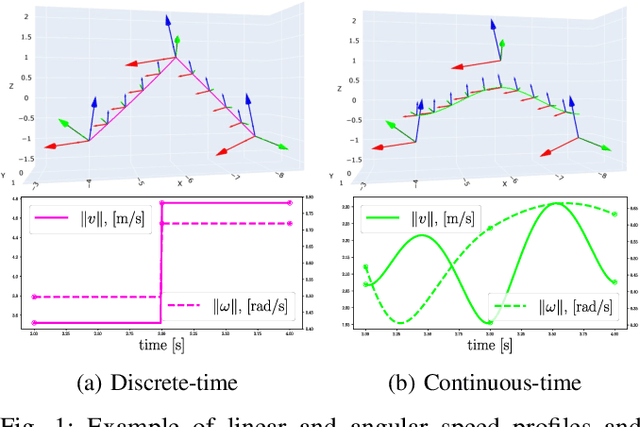
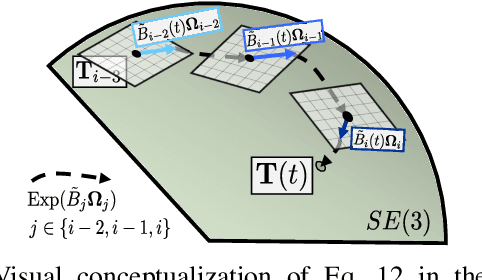
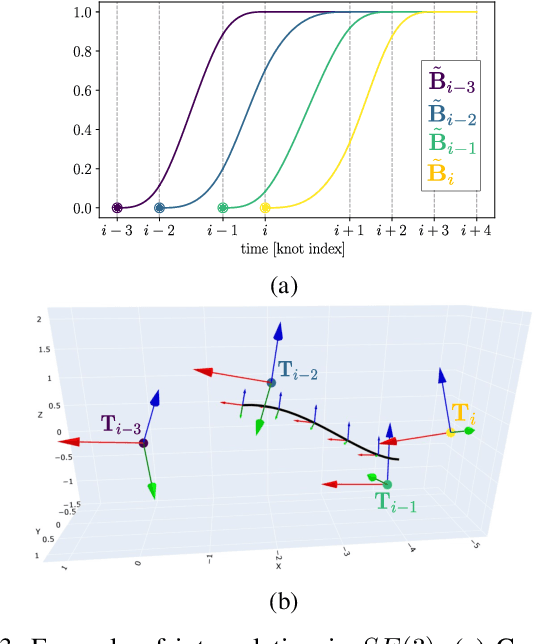

In this paper we propose a method that estimates the $SE(3)$ continuous trajectories (orientation and translation) of the dynamic rigid objects present in a scene, from multiple RGB-D views. Specifically, we fit the object trajectories to cumulative B-Splines curves, which allow us to interpolate, at any intermediate time stamp, not only their poses but also their linear and angular velocities and accelerations. Additionally, we derive in this work the analytical $SE(3)$ Jacobians needed by the optimization, being applicable to any other approach that uses this type of curves. To the best of our knowledge this is the first work that proposes 6-DoF continuous-time object tracking, which we endorse with significant computational cost reduction thanks to our analytical derivations. We evaluate our proposal in synthetic data and in a public benchmark, showing competitive results in localization and significant improvements in velocity estimation in comparison to discrete-time approaches.
Precise Single-stage Detector
Oct 09, 2022
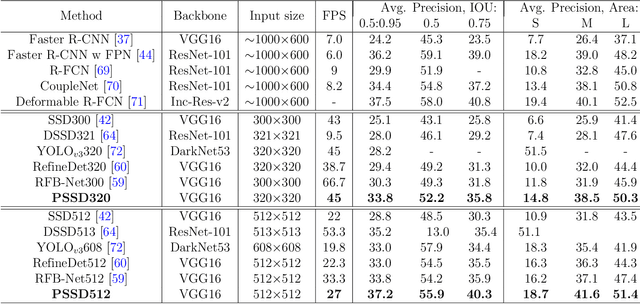
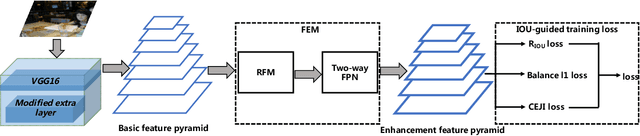

There are still two problems in SDD causing some inaccurate results: (1) In the process of feature extraction, with the layer-by-layer acquisition of semantic information, local information is gradually lost, resulting into less representative feature maps; (2) During the Non-Maximum Suppression (NMS) algorithm due to inconsistency in classification and regression tasks, the classification confidence and predicted detection position cannot accurately indicate the position of the prediction boxes. Methods: In order to address these aforementioned issues, we propose a new architecture, a modified version of Single Shot Multibox Detector (SSD), named Precise Single Stage Detector (PSSD). Firstly, we improve the features by adding extra layers to SSD. Secondly, we construct a simple and effective feature enhancement module to expand the receptive field step by step for each layer and enhance its local and semantic information. Finally, we design a more efficient loss function to predict the IOU between the prediction boxes and ground truth boxes, and the threshold IOU guides classification training and attenuates the scores, which are used by the NMS algorithm. Main Results: Benefiting from the above optimization, the proposed model PSSD achieves exciting performance in real-time. Specifically, with the hardware of Titan Xp and the input size of 320 pix, PSSD achieves 33.8 mAP at 45 FPS speed on MS COCO benchmark and 81.28 mAP at 66 FPS speed on Pascal VOC 2007 outperforming state-of-the-art object detection models. Besides, the proposed model performs significantly well with larger input size. Under 512 pix, PSSD can obtain 37.2 mAP with 27 FPS on MS COCO and 82.82 mAP with 40 FPS on Pascal VOC 2007. The experiment results prove that the proposed model has a better trade-off between speed and accuracy.
From Counter-intuitive Observations to a Fresh Look at Recommender System
Oct 09, 2022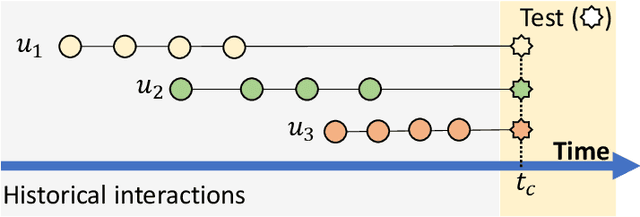
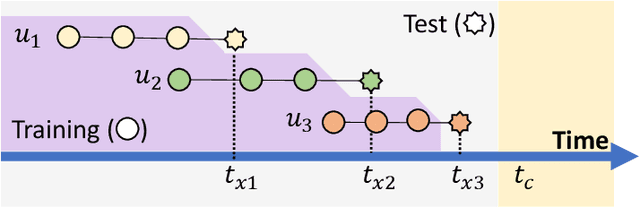
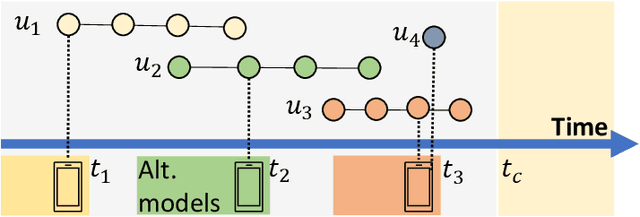
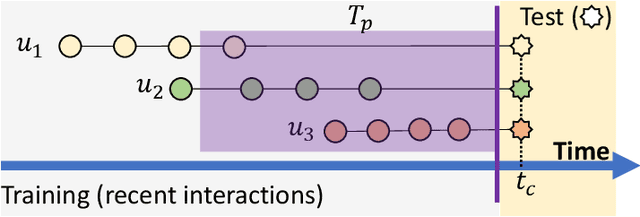
Recently, a few papers report counter-intuitive observations made from experiments on recommender system (RecSys). One observation is that users who spend more time and users who have many interactions with a recommendation system receive poorer recommendations. Another observation is that models trained by using only the more recent parts of a dataset show significant performance improvement. In this opinion paper, we interpret these counter-intuitive observations from two perspectives. First, the observations are made with respect to the global timeline of user-item interactions. Second, the observations are considered counter-intuitive because they contradict our expectation on a recommender: the more interactions a user has, the higher chance that the recommender better learns the user preference. For the first perspective, we discuss the importance of the global timeline by using the simplest baseline Popularity as a starting point. We answer two questions: (i) why the simplest model popularity is often ill-defined in academic research? and (ii) why the popularity baseline is evaluated in this way? The questions lead to a detailed discussion on the data leakage issue in many offline evaluations. As the result, model accuracies reported in many academic papers are less meaningful and incomparable. For the second perspective, we try to answer two more questions: (i) why models trained by using only the more recent parts of data demonstrate better performance? and (ii) why more interactions from users lead to poorer recommendations? The key to both questions is user preference modeling. We then propose to have a fresh look at RecSys. We discuss how to conduct more practical offline evaluations and possible ways to effectively model user preferences. The discussion and opinions in this paper are on top-N recommendation only, not on rating prediction.