 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Global Prototype Encoding for Incremental Video Highlights Detection
Sep 14, 2022


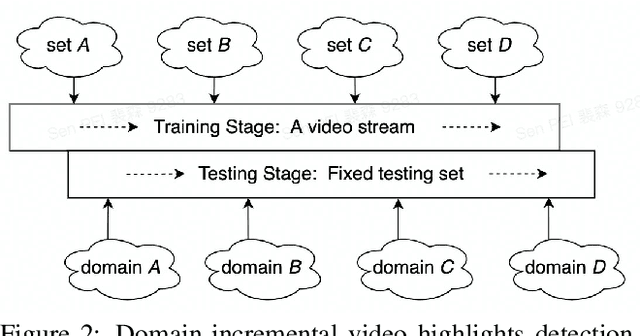
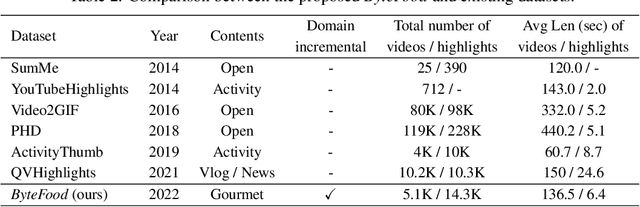
Video highlights detection has been long researched as a topic in computer vision tasks, digging the user-appealing clips out given unexposed raw video inputs. However, in most case, the mainstream methods in this line of research are built on the closed world assumption, where a fixed number of highlight categories is defined properly in advance and need all training data to be available at the same time, and as a result, leads to poor scalability with respect to both the highlight categories and the size of the dataset. To tackle the problem mentioned above, we propose a video highlights detector that is able to learn incrementally, namely \textbf{G}lobal \textbf{P}rototype \textbf{E}ncoding (GPE), capturing newly defined video highlights in the extended dataset via their corresponding prototypes. Alongside, we present a well annotated and costly dataset termed \emph{ByteFood}, including more than 5.1k gourmet videos belongs to four different domains which are \emph{cooking}, \emph{eating}, \emph{food material}, and \emph{presentation} respectively. To the best of our knowledge, this is the first time the incremental learning settings are introduced to video highlights detection, which in turn relieves the burden of training video inputs and promotes the scalability of conventional neural networks in proportion to both the size of the dataset and the quantity of domains. Moreover, the proposed GPE surpasses current incremental learning methods on \emph{ByteFood}, reporting an improvement of 1.57\% mAP at least. The code and dataset will be made available sooner.
Disentangled Counterfactual Recurrent Networks for Treatment Effect Inference over Time
Dec 07, 2021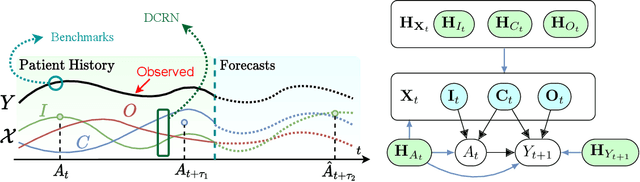
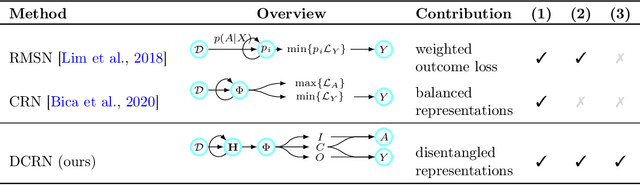
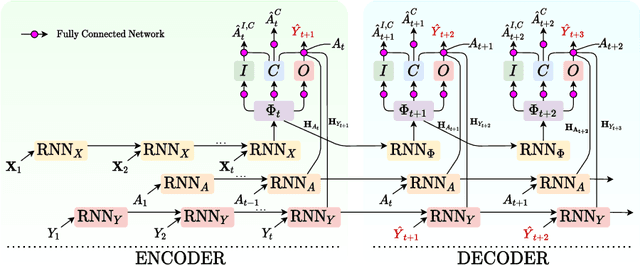

Choosing the best treatment-plan for each individual patient requires accurate forecasts of their outcome trajectories as a function of the treatment, over time. While large observational data sets constitute rich sources of information to learn from, they also contain biases as treatments are rarely assigned randomly in practice. To provide accurate and unbiased forecasts, we introduce the Disentangled Counterfactual Recurrent Network (DCRN), a novel sequence-to-sequence architecture that estimates treatment outcomes over time by learning representations of patient histories that are disentangled into three separate latent factors: a treatment factor, influencing only treatment selection; an outcome factor, influencing only the outcome; and a confounding factor, influencing both. With an architecture that is completely inspired by the causal structure of treatment influence over time, we advance forecast accuracy and disease understanding, as our architecture allows for practitioners to infer which patient features influence which part in a patient's trajectory, contrasting other approaches in this domain. We demonstrate that DCRN outperforms current state-of-the-art methods in forecasting treatment responses, on both real and simulated data.
Scalable Spatiotemporal Graph Neural Networks
Sep 14, 2022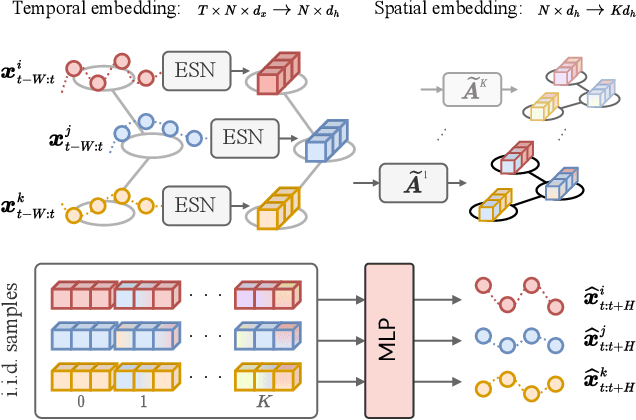
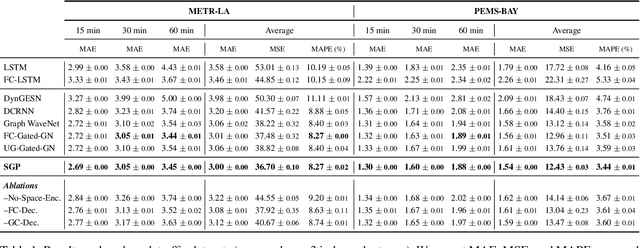
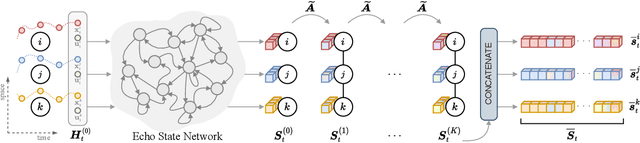
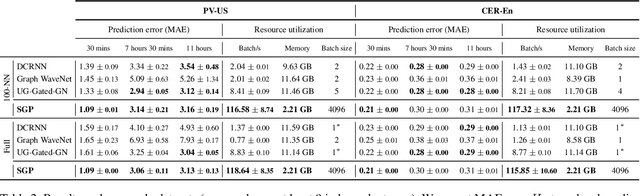
Neural forecasting of spatiotemporal time series drives both research and industrial innovation in several relevant application domains. Graph neural networks (GNNs) are often the core component of the forecasting architecture. However, in most spatiotemporal GNNs, the computational complexity scales up to a quadratic factor with the length of the sequence times the number of links in the graph, hence hindering the application of these models to large graphs and long temporal sequences. While methods to improve scalability have been proposed in the context of static graphs, few research efforts have been devoted to the spatiotemporal case. To fill this gap, we propose a scalable architecture that exploits an efficient encoding of both temporal and spatial dynamics. In particular, we use a randomized recurrent neural network to embed the history of the input time series into high-dimensional state representations encompassing multi-scale temporal dynamics. Such representations are then propagated along the spatial dimension using different powers of the graph adjacency matrix to generate node embeddings characterized by a rich pool of spatiotemporal features. The resulting node embeddings can be efficiently pre-computed in an unsupervised manner, before being fed to a feed-forward decoder that learns to map the multi-scale spatiotemporal representations to predictions. The training procedure can then be parallelized node-wise by sampling the node embeddings without breaking any dependency, thus enabling scalability to large networks. Empirical results on relevant datasets show that our approach achieves results competitive with the state of the art, while dramatically reducing the computational burden.
Actor-Critic Network for O-RAN Resource Allocation: xApp Design, Deployment, and Analysis
Sep 26, 2022
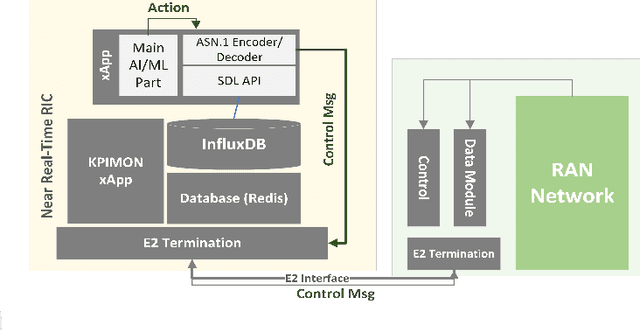
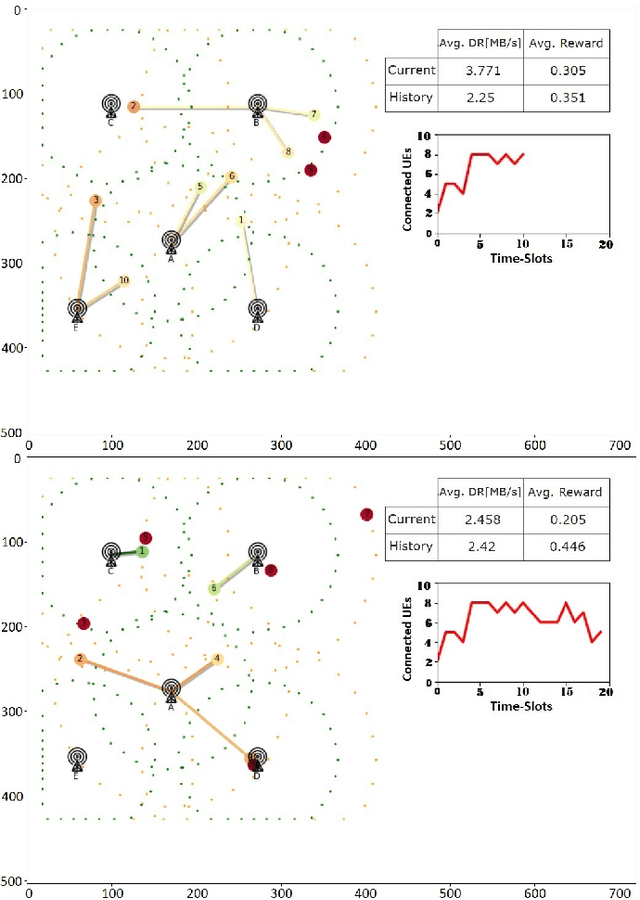
Open Radio Access Network (O-RAN) has introduced an emerging RAN architecture that enables openness, intelligence, and automated control. The RAN Intelligent Controller (RIC) provides the platform to design and deploy RAN controllers. xApps are the applications which will take this responsibility by leveraging machine learning (ML) algorithms and acting in near-real time. Despite the opportunities provided by this new architecture, the progress of practical artificial intelligence (AI)-based solutions for network control and automation has been slow. This is mostly because of the lack of an endto-end solution for designing, deploying, and testing AI-based xApps fully executable in real O-RAN network. In this paper we introduce an end-to-end O-RAN design and evaluation procedure and provide a detailed discussion of developing a Reinforcement Learning (RL) based xApp by using two different RL approaches and considering the latest released O-RAN architecture and interfaces.
Dynamical Wasserstein Barycenters for Time-series Modeling
Oct 29, 2021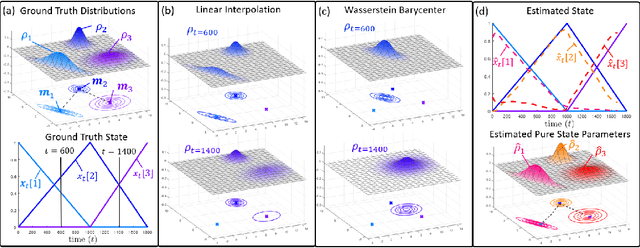
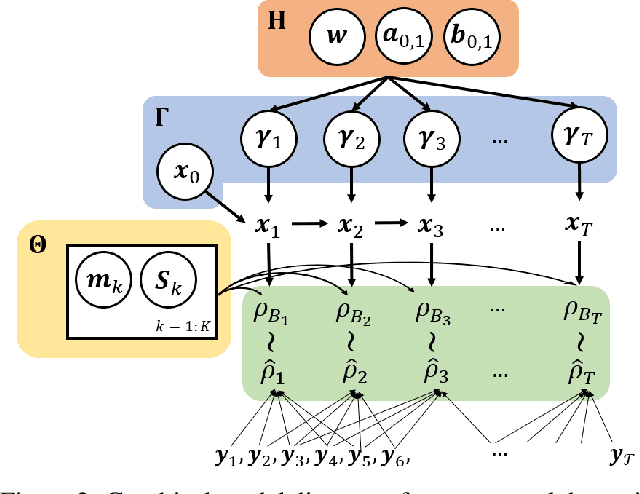
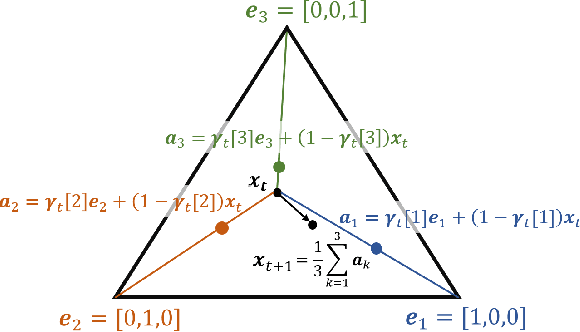
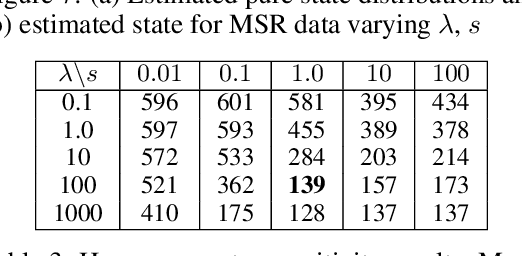
Many time series can be modeled as a sequence of segments representing high-level discrete states, such as running and walking in a human activity application. Flexible models should describe the system state and observations in stationary "pure-state" periods as well as transition periods between adjacent segments, such as a gradual slowdown between running and walking. However, most prior work assumes instantaneous transitions between pure discrete states. We propose a dynamical Wasserstein barycentric (DWB) model that estimates the system state over time as well as the data-generating distributions of pure states in an unsupervised manner. Our model assumes each pure state generates data from a multivariate normal distribution, and characterizes transitions between states via displacement-interpolation specified by the Wasserstein barycenter. The system state is represented by a barycentric weight vector which evolves over time via a random walk on the simplex. Parameter learning leverages the natural Riemannian geometry of Gaussian distributions under the Wasserstein distance, which leads to improved convergence speeds. Experiments on several human activity datasets show that our proposed DWB model accurately learns the generating distribution of pure states while improving state estimation for transition periods compared to the commonly used linear interpolation mixture models.
A multi view multi stage and multi window framework for pulmonary artery segmentation from CT scans
Sep 12, 2022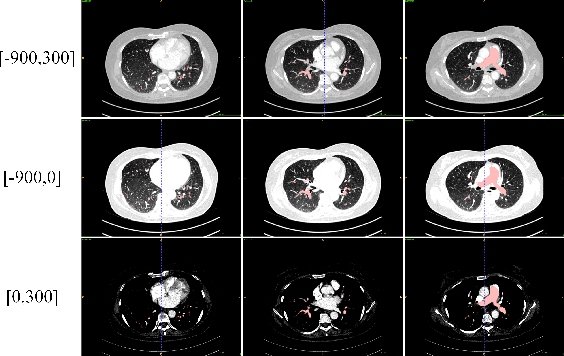


This is the technical report of the 9th place in the final result of PARSE2022 Challenge. We solve the segmentation problem of the pulmonary artery by using a two-stage method based on a 3D CNN network. The coarse model is used to locate the ROI, and the fine model is used to refine the segmentation result. In addition, in order to improve the segmentation performance, we adopt multi-view and multi-window level method, at the same time we employ a fine-tune strategy to mitigate the impact of inconsistent labeling.
Real-Time and Robust 3D Object Detection Within Road-Side LiDARs Using Domain Adaptation
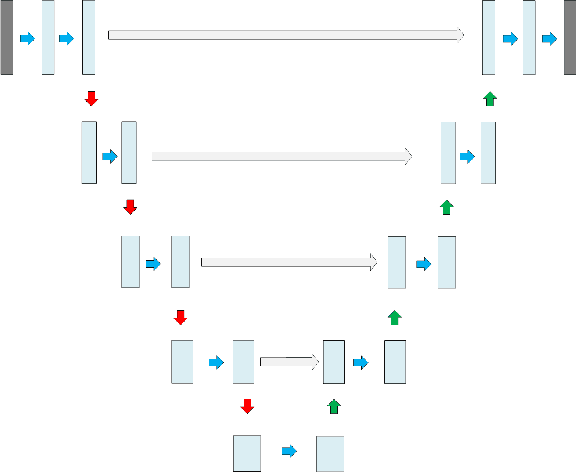
Mar 31, 2022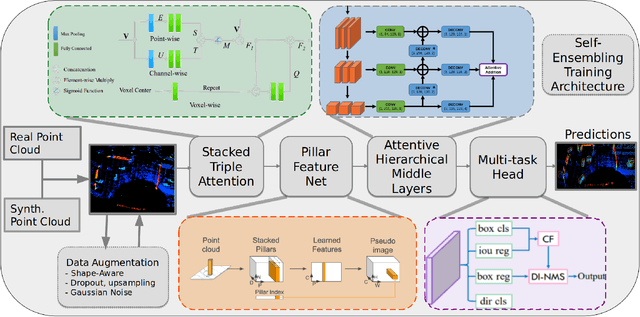

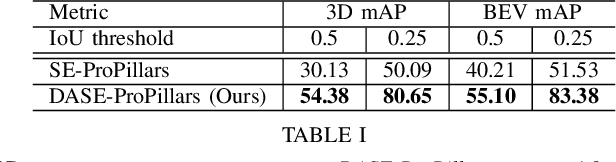
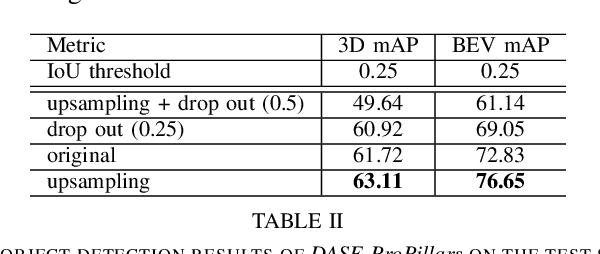
This work aims to address the challenges in domain adaptation of 3D object detection using infrastructure LiDARs. We design a model DASE-ProPillars that can detect vehicles in infrastructure-based LiDARs in real-time. Our model uses PointPillars as the baseline model with additional modules to improve the 3D detection performance. To prove the effectiveness of our proposed modules in DASE-ProPillars, we train and evaluate the model on two datasets, the open source A9-Dataset and a semi-synthetic infrastructure dataset created within the Regensburg Next project. We do several sets of experiments for each module in the DASE-ProPillars detector that show that our model outperforms the SE-ProPillars baseline on the real A9 test set and a semi-synthetic A9 test set, while maintaining an inference speed of 45 Hz (22 ms). We apply domain adaptation from the semi-synthetic A9-Dataset to the semi-synthetic dataset from the Regensburg Next project by applying transfer learning and achieve a 3D mAP@0.25 of 93.49% on the Car class of the target test set using 40 recall positions.
mini-ELSA: using Machine Learning to improve space efficiency in Edge Lightweight Searchable Attribute-based encryption for Industry 4.0
Sep 22, 2022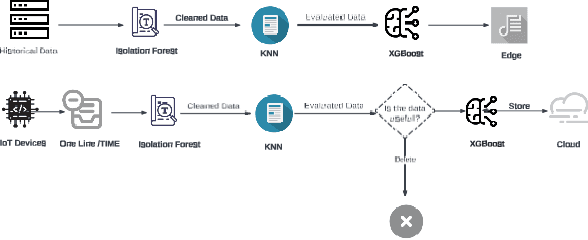
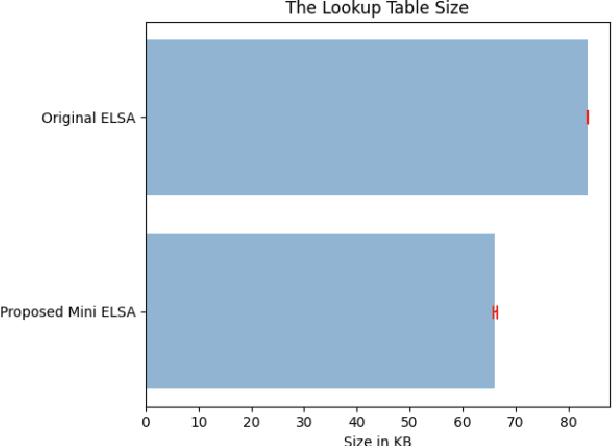
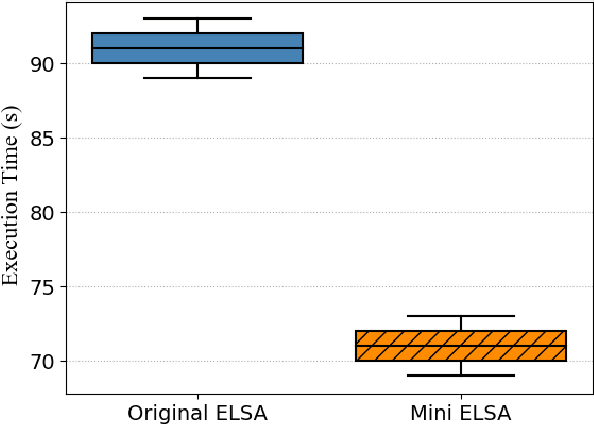
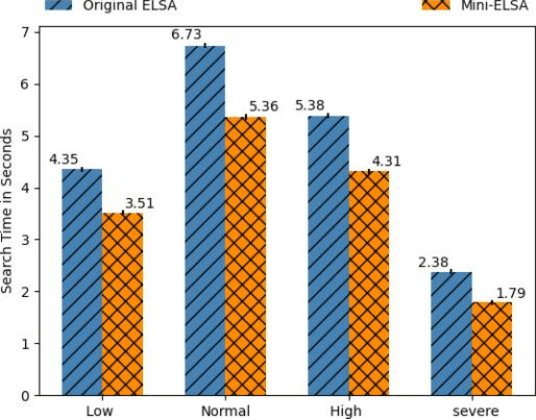
In previous work a novel Edge Lightweight Searchable Attribute-based encryption (ELSA) method was proposed to support Industry 4.0 and specifically Industrial Internet of Things applications. In this paper, we aim to improve ELSA by minimising the lookup table size and summarising the data records by integrating Machine Learning (ML) methods suitable for execution at the edge. This integration will eliminate records of unnecessary data by evaluating added value to further processing. Thus, resulting in the minimization of both the lookup table size, the cloud storage and the network traffic taking full advantage of the edge architecture benefits. We demonstrate our mini-ELSA expanded method on a well-known power plant dataset. Our results demonstrate a reduction of storage requirements by 21% while improving execution time by 1.27x.
A distributed Gibbs Sampler with Hypergraph Structure for High-Dimensional Inverse Problems
Oct 05, 2022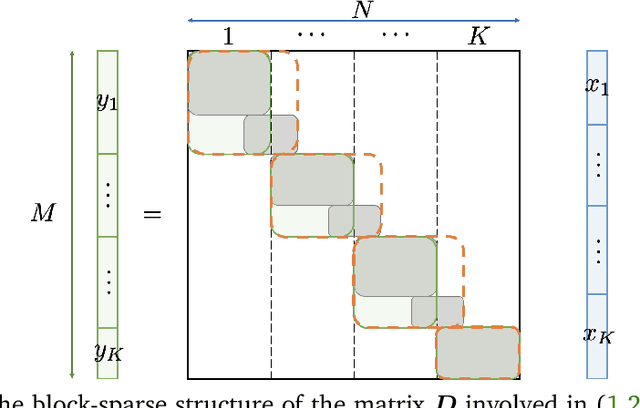
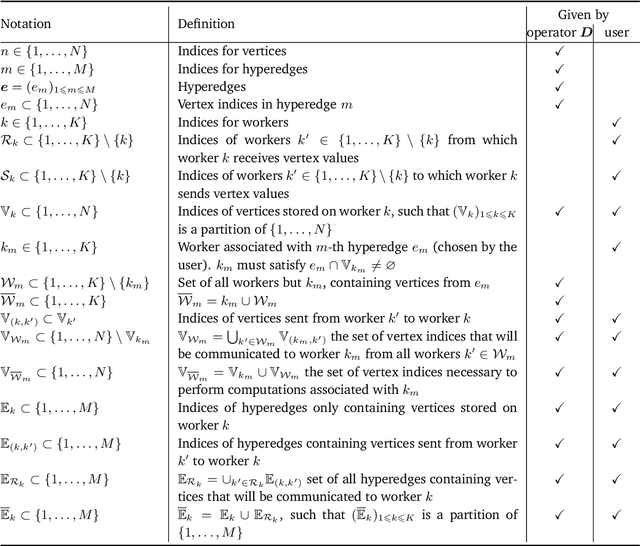

Sampling-based algorithms are classical approaches to perform Bayesian inference in inverse problems. They provide estimators with the associated credibility intervals to quantify the uncertainty on the estimators. Although these methods hardly scale to high dimensional problems, they have recently been paired with optimization techniques, such as proximal and splitting approaches, to address this issue. Such approaches pave the way to distributed samplers, splitting computations to make inference more scalable and faster. We introduce a distributed Gibbs sampler to efficiently solve such problems, considering posterior distributions with multiple smooth and non-smooth functions composed with linear operators. The proposed approach leverages a recent approximate augmentation technique reminiscent of primal-dual optimization methods. It is further combined with a block-coordinate approach to split the primal and dual variables into blocks, leading to a distributed block-coordinate Gibbs sampler. The resulting algorithm exploits the hypergraph structure of the involved linear operators to efficiently distribute the variables over multiple workers under controlled communication costs. It accommodates several distributed architectures, such as the Single Program Multiple Data and client-server architectures. Experiments on a large image deblurring problem show the performance of the proposed approach to produce high quality estimates with credibility intervals in a small amount of time.
Energy-Efficiency Maximization for a WPT-D2D Pair in a MISO-NOMA Downlink Network
Oct 08, 2022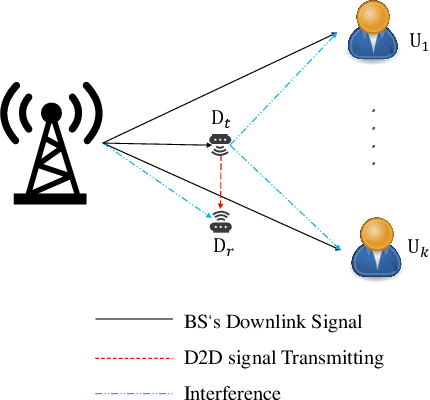
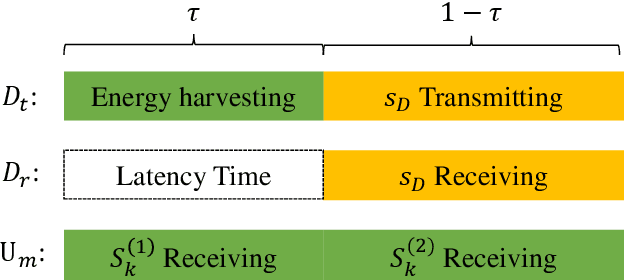
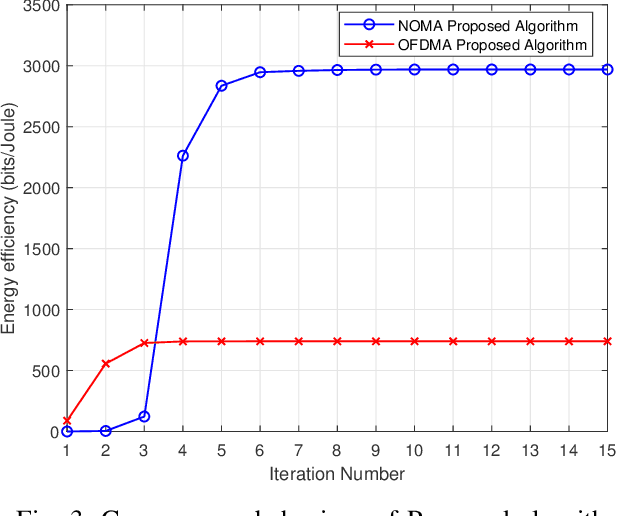
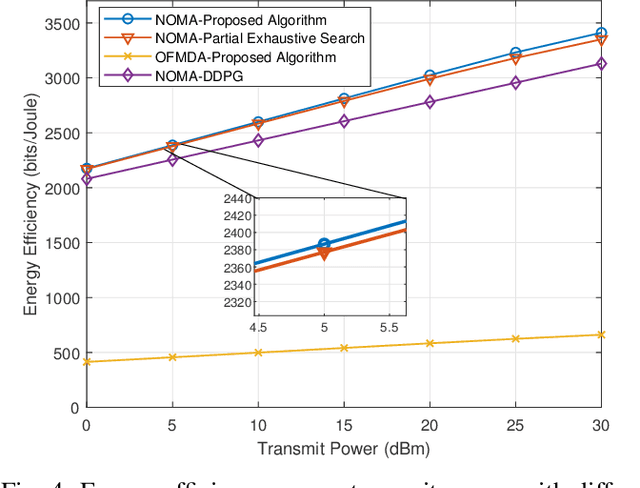
The combination of non-orthogonal multiple access (NOMA) and wireless power transfer (WPT) is a promising solution to enhance the energy efficiency of Device-to-Device (D2D) enabled wireless communication networks. In this paper, we focus on maximizing the energy efficiency of a WPT-D2D pair in a multiple-input single-output (MISO)-NOMA downlink network, by alternatively optimizing the beamforming vectors of the base station (BS) and the time switching coefficient of the WPT assisted D2D transmitter. The formulated energy efficiency maximization problem is non-convex due to the highly coupled variables. To efficiently address the non-convex problem, we first divide it into two subproblems. Afterwards, an alternating algorithm based on the Dinkelbach method and quadratic transform is proposed to solve the two subproblems iteratively. To verify the proposed alternating algorithm's accuracy, partial exhaustive search algorithm is proposed as a benchmark. We also utilize a deep reinforcement learning (DRL) method to solve the non-convex problem and compare it with the proposed algorithm. To demonstrate the respective superiority of the proposed algorithm and DRL-based method, simulations are performed for two scenarios of perfect and imperfect channel state information (CSI). Simulation results are provided to compare NOMA and orthogonal multiple access (OMA), which demonstrate the superior performance of energy efficiency of the NOMA scheme.