 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dfferentiable Raycasting for Self-supervised Occupancy Forecasting
Oct 04, 2022
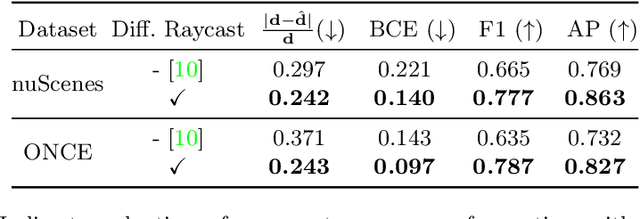


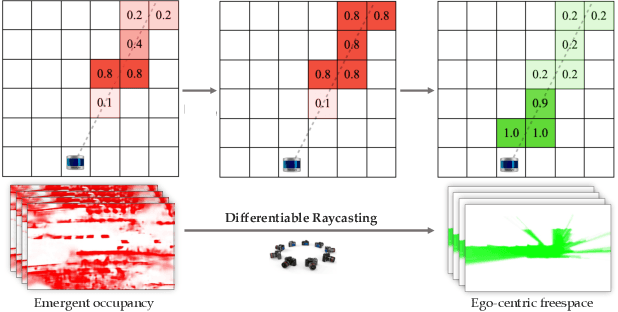
Motion planning for safe autonomous driving requires learning how the environment around an ego-vehicle evolves with time. Ego-centric perception of driveable regions in a scene not only changes with the motion of actors in the environment, but also with the movement of the ego-vehicle itself. Self-supervised representations proposed for large-scale planning, such as ego-centric freespace, confound these two motions, making the representation difficult to use for downstream motion planners. In this paper, we use geometric occupancy as a natural alternative to view-dependent representations such as freespace. Occupancy maps naturally disentangle the motion of the environment from the motion of the ego-vehicle. However, one cannot directly observe the full 3D occupancy of a scene (due to occlusion), making it difficult to use as a signal for learning. Our key insight is to use differentiable raycasting to "render" future occupancy predictions into future LiDAR sweep predictions, which can be compared with ground-truth sweeps for self-supervised learning. The use of differentiable raycasting allows occupancy to emerge as an internal representation within the forecasting network. In the absence of groundtruth occupancy, we quantitatively evaluate the forecasting of raycasted LiDAR sweeps and show improvements of upto 15 F1 points. For downstream motion planners, where emergent occupancy can be directly used to guide non-driveable regions, this representation relatively reduces the number of collisions with objects by up to 17% as compared to freespace-centric motion planners.
The optimality of word lengths. Theoretical foundations and an empirical study
Aug 24, 2022
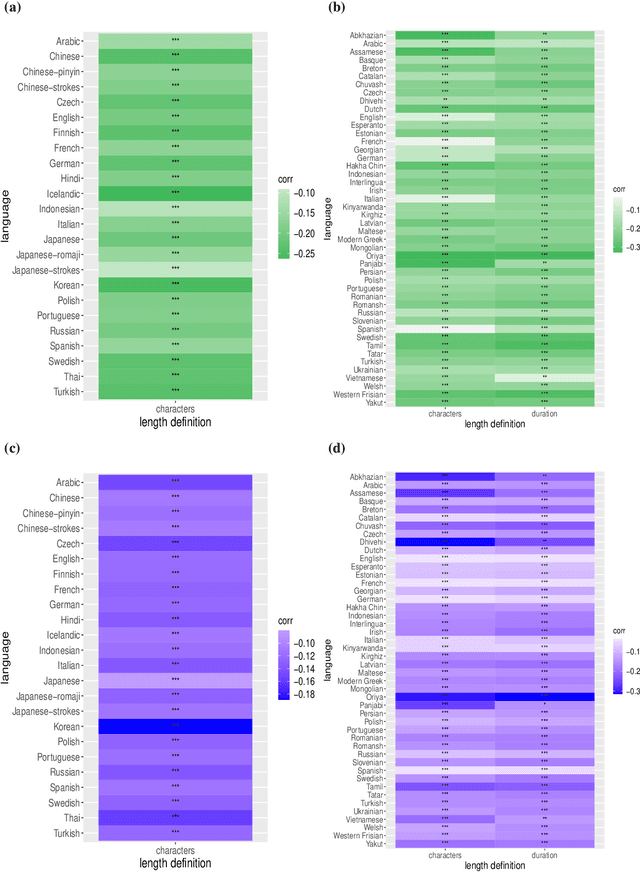
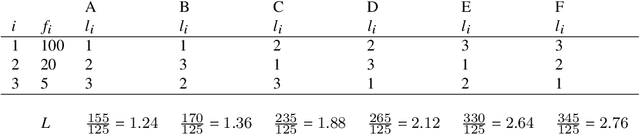
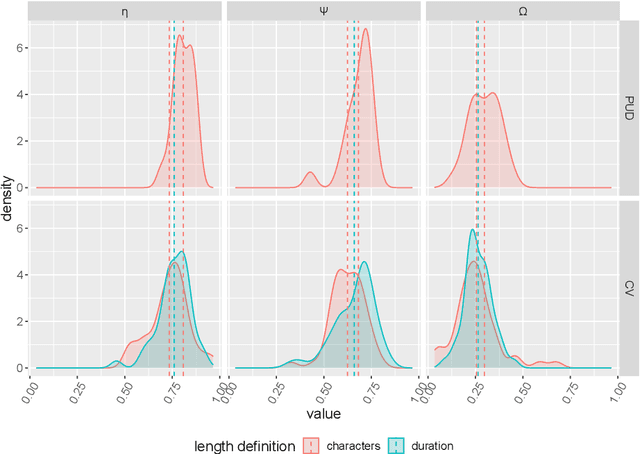
One of the most robust patterns found in human languages is Zipf's law of abbreviation, that is, the tendency of more frequent words to be shorter. Since Zipf's pioneering research, this law has been viewed as a manifestation of compression, i.e. the minimization of the length of forms - a universal principle of natural communication. Although the claim that languages are optimized has become trendy, attempts to measure the degree of optimization of languages have been rather scarce. Here we demonstrate that compression manifests itself in a wide sample of languages without exceptions, and independently of the unit of measurement. It is detectable for both word lengths in characters of written language as well as durations in time in spoken language. Moreover, to measure the degree of optimization, we derive a simple formula for a random baseline and present two scores that are dualy normalized, namely, they are normalized with respect to both the minimum and the random baseline. We analyze the theoretical and statistical advantages and disadvantages of these and other scores. Harnessing the best score, we quantify for the first time the degree of optimality of word lengths in languages. This indicates that languages are optimized to 62 or 67 percent on average (depending on the source) when word lengths are measured in characters, and to 65 percent on average when word lengths are measured in time. In general, spoken word durations are more optimized than written word lengths in characters. Beyond the analyses reported here, our work paves the way to measure the degree of optimality of the vocalizations or gestures of other species, and to compare them against written, spoken, or signed human languages.
Graph Neural Networks for Multi-Robot Active Information Acquisition
Sep 24, 2022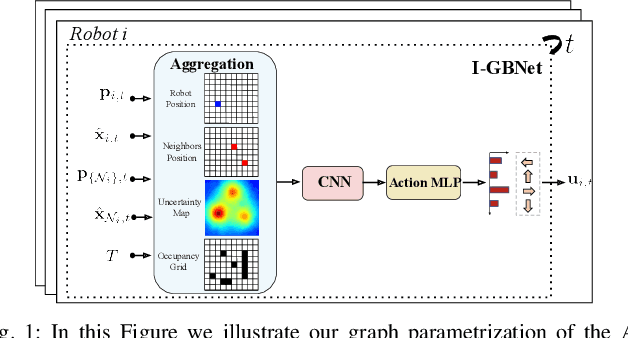
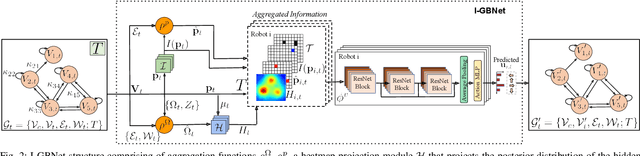
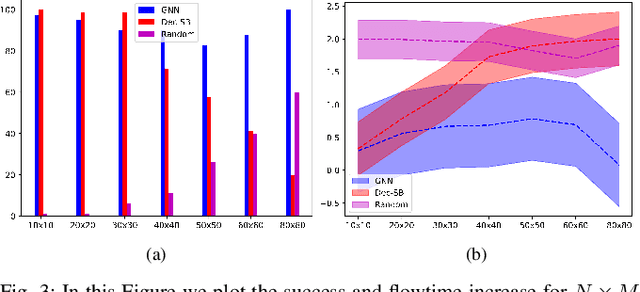
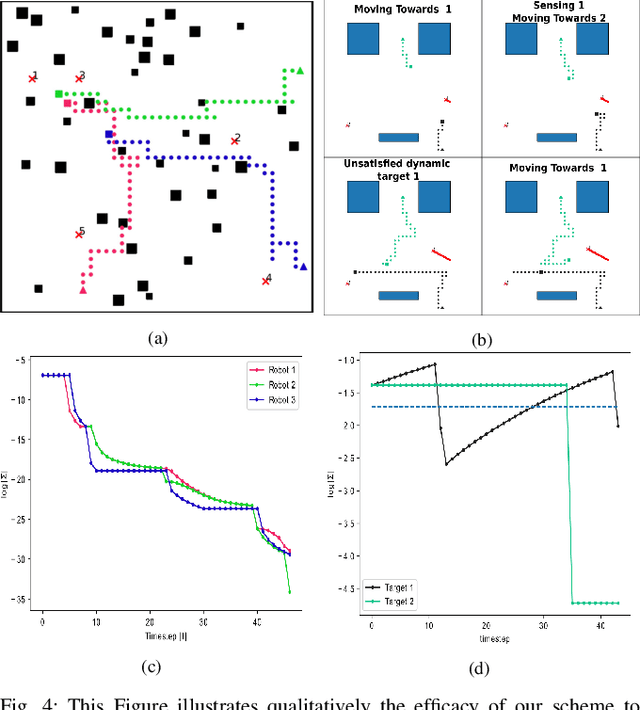
This paper addresses the Multi-Robot Active Information Acquisition (AIA) problem, where a team of mobile robots, communicating through an underlying graph, estimates a hidden state expressing a phenomenon of interest. Applications like target tracking, coverage and SLAM can be expressed in this framework. Existing approaches, though, are either not scalable, unable to handle dynamic phenomena or not robust to changes in the communication graph. To counter these shortcomings, we propose an Information-aware Graph Block Network (I-GBNet), an AIA adaptation of Graph Neural Networks, that aggregates information over the graph representation and provides sequential-decision making in a distributed manner. The I-GBNet, trained via imitation learning with a centralized sampling-based expert solver, exhibits permutation equivariance and time invariance, while harnessing the superior scalability, robustness and generalizability to previously unseen environments and robot configurations. Experiments on significantly larger graphs and dimensionality of the hidden state and more complex environments than those seen in training validate the properties of the proposed architecture and its efficacy in the application of localization and tracking of dynamic targets.
It's About Time: Analog Clock Reading in the Wild
Dec 06, 2021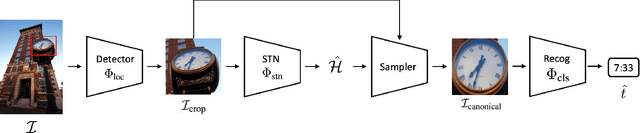
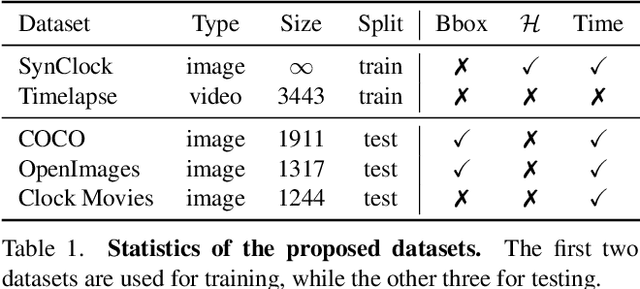

In this paper, we present a framework for reading analog clocks in natural images or videos. Specifically, we make the following contributions: First, we create a scalable pipeline for generating synthetic clocks, significantly reducing the requirements for the labour-intensive annotations; Second, we introduce a clock recognition architecture based on spatial transformer networks (STN), which is trained end-to-end for clock alignment and recognition. We show that the model trained on the proposed synthetic dataset generalises towards real clocks with good accuracy, advocating a Sim2Real training regime; Third, to further reduce the gap between simulation and real data, we leverage the special property of time, i.e. uniformity, to generate reliable pseudo-labels on real unlabelled clock videos, and show that training on these videos offers further improvements while still requiring zero manual annotations. Lastly, we introduce three benchmark datasets based on COCO, Open Images, and The Clock movie, totalling 4,472 images with clocks, with full annotations for time, accurate to the minute.
DytanVO: Joint Refinement of Visual Odometry and Motion Segmentation in Dynamic Environments
Sep 24, 2022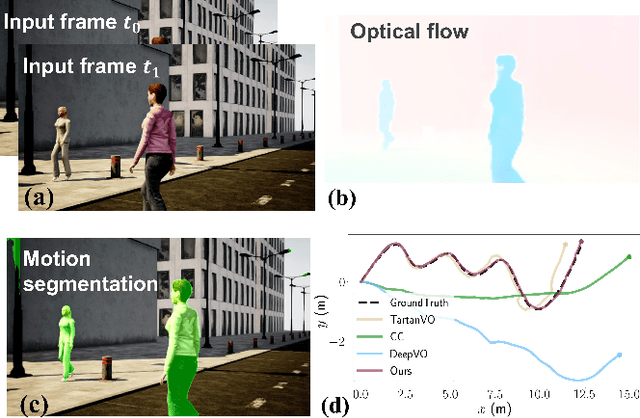
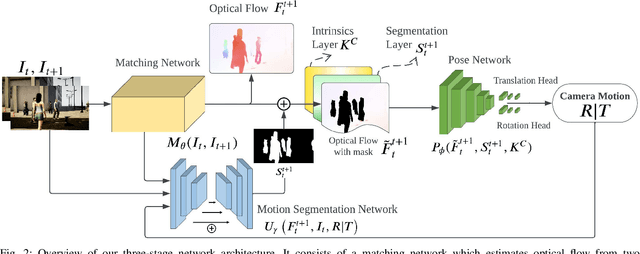
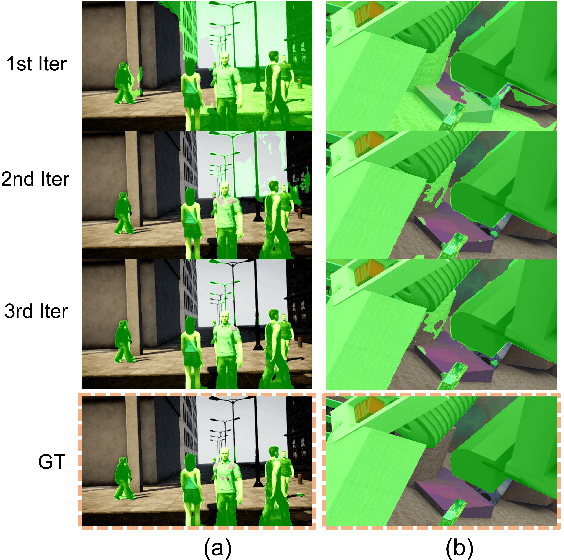
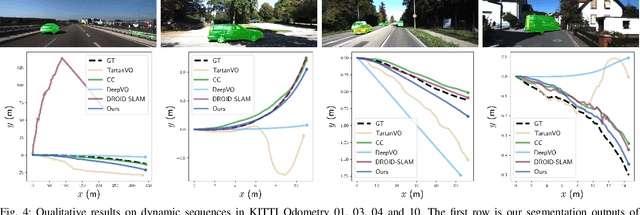
Learning-based visual odometry (VO) algorithms achieve remarkable performance on common static scenes, benefiting from high-capacity models and massive annotated data, but tend to fail in dynamic, populated environments. Semantic segmentation is largely used to discard dynamic associations before estimating camera motions but at the cost of discarding static features and is hard to scale up to unseen categories. In this paper, we leverage the mutual dependence between camera ego-motion and motion segmentation and show that both can be jointly refined in a single learning-based framework. In particular, we present DytanVO, the first supervised learning-based VO method that deals with dynamic environments. It takes two consecutive monocular frames in real-time and predicts camera ego-motion in an iterative fashion. Our method achieves an average improvement of 27.7% in ATE over state-of-the-art VO solutions in real-world dynamic environments, and even performs competitively among dynamic visual SLAM systems which optimize the trajectory on the backend. Experiments on plentiful unseen environments also demonstrate our method's generalizability.
Accelerating hypersonic reentry simulations using deep learning-based hybridization (with guarantees)
Sep 27, 2022

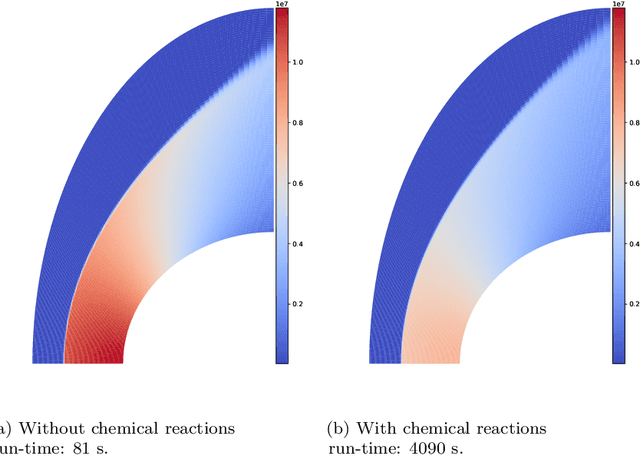
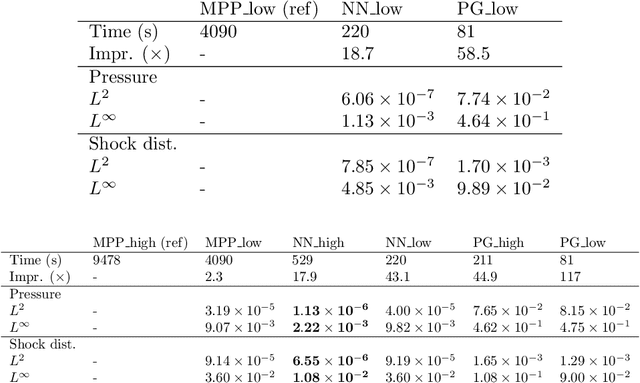
In this paper, we are interested in the acceleration of numerical simulations. We focus on a hypersonic planetary reentry problem whose simulation involves coupling fluid dynamics and chemical reactions. Simulating chemical reactions takes most of the computational time but, on the other hand, cannot be avoided to obtain accurate predictions. We face a trade-off between cost-efficiency and accuracy: the simulation code has to be sufficiently efficient to be used in an operational context but accurate enough to predict the phenomenon faithfully. To tackle this trade-off, we design a hybrid simulation code coupling a traditional fluid dynamic solver with a neural network approximating the chemical reactions. We rely on their power in terms of accuracy and dimension reduction when applied in a big data context and on their efficiency stemming from their matrix-vector structure to achieve important acceleration factors ($\times 10$ to $\times 18.6$). This paper aims to explain how we design such cost-effective hybrid simulation codes in practice. Above all, we describe methodologies to ensure accuracy guarantees, allowing us to go beyond traditional surrogate modeling and to use these codes as references.
DELTAR: Depth Estimation from a Light-weight ToF Sensor and RGB Image
Sep 27, 2022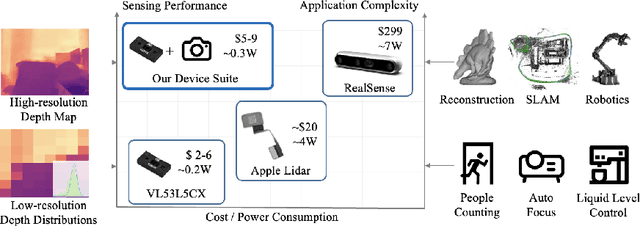
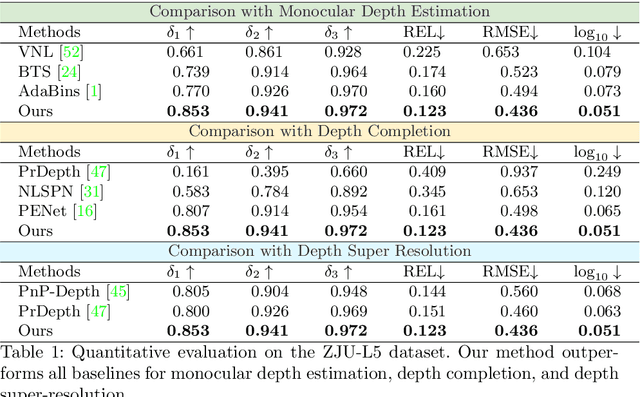
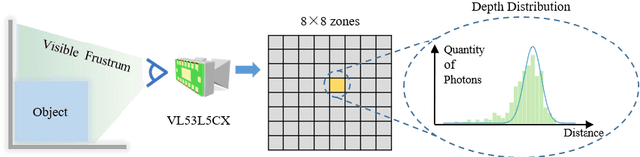
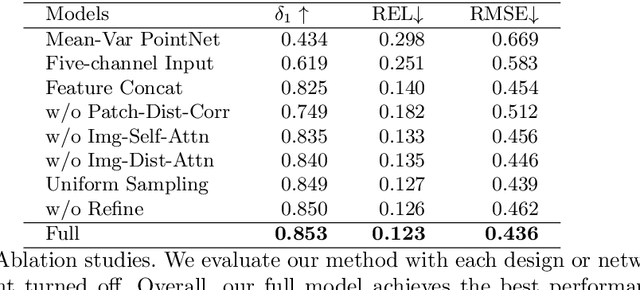
Light-weight time-of-flight (ToF) depth sensors are small, cheap, low-energy and have been massively deployed on mobile devices for the purposes like autofocus, obstacle detection, etc. However, due to their specific measurements (depth distribution in a region instead of the depth value at a certain pixel) and extremely low resolution, they are insufficient for applications requiring high-fidelity depth such as 3D reconstruction. In this paper, we propose DELTAR, a novel method to empower light-weight ToF sensors with the capability of measuring high resolution and accurate depth by cooperating with a color image. As the core of DELTAR, a feature extractor customized for depth distribution and an attention-based neural architecture is proposed to fuse the information from the color and ToF domain efficiently. To evaluate our system in real-world scenarios, we design a data collection device and propose a new approach to calibrate the RGB camera and ToF sensor. Experiments show that our method produces more accurate depth than existing frameworks designed for depth completion and depth super-resolution and achieves on par performance with a commodity-level RGB-D sensor. Code and data are available at https://zju3dv.github.io/deltar/.
SoLo T-DIRL: Socially-Aware Dynamic Local Planner based on Trajectory-Ranked Deep Inverse Reinforcement Learning
Sep 16, 2022
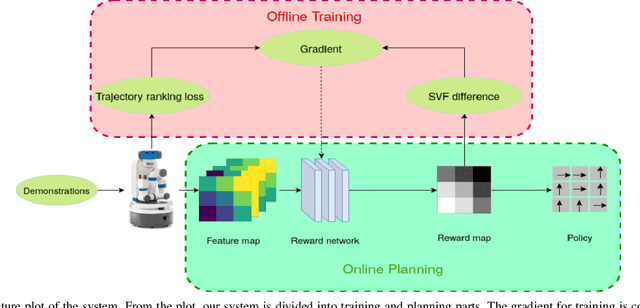

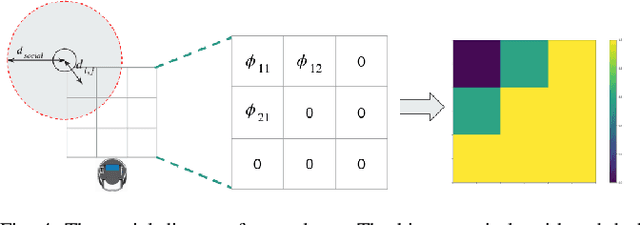
This work proposes a new framework for a socially-aware dynamic local planner in crowded environments by building on the recently proposed Trajectory-ranked Maximum Entropy Deep Inverse Reinforcement Learning (T-MEDIRL). To address the social navigation problem, our multi-modal learning planner explicitly considers social interaction factors, as well as social-awareness factors into T-MEDIRL pipeline to learn a reward function from human demonstrations. Moreover, we propose a novel trajectory ranking score using the sudden velocity change of pedestrians around the robot to address the sub-optimality in human demonstrations. Our evaluation shows that this method can successfully make a robot navigate in a crowded social environment and outperforms the state-of-art social navigation methods in terms of the success rate, navigation time, and invasion rate.
StyleGAN Encoder-Based Attack for Block Scrambled Face Images
Sep 16, 2022
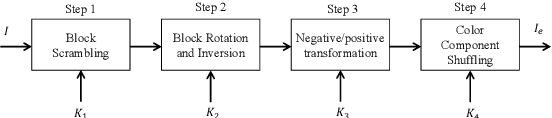

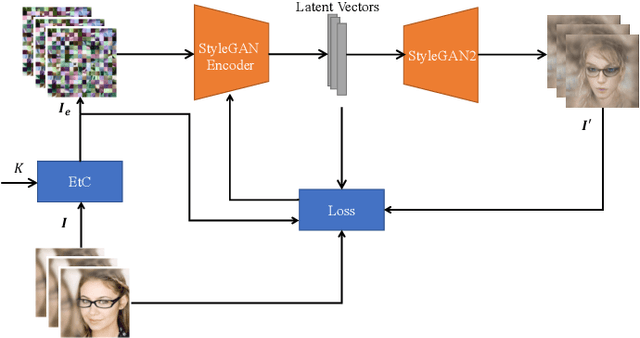
In this paper, we propose an attack method to block scrambled face images, particularly Encryption-then-Compression (EtC) applied images by utilizing the existing powerful StyleGAN encoder and decoder for the first time. Instead of reconstructing identical images as plain ones from encrypted images, we focus on recovering styles that can reveal identifiable information from the encrypted images. The proposed method trains an encoder by using plain and encrypted image pairs with a particular training strategy. While state-of-the-art attack methods cannot recover any perceptual information from EtC images, the proposed method discloses personally identifiable information such as hair color, skin color, eyeglasses, gender, etc. Experiments were carried out on the CelebA dataset, and results show that reconstructed images have some perceptual similarities compared to plain images.
Nowcasting the Financial Time Series with Streaming Data Analytics under Apache Spark
Feb 23, 2022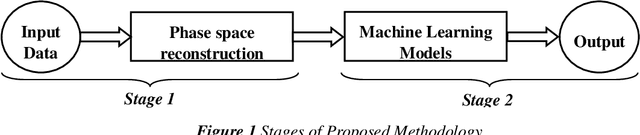
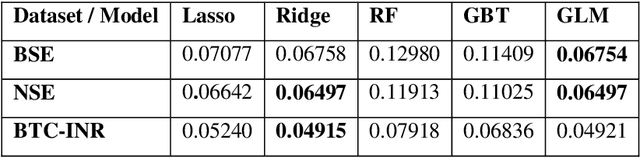
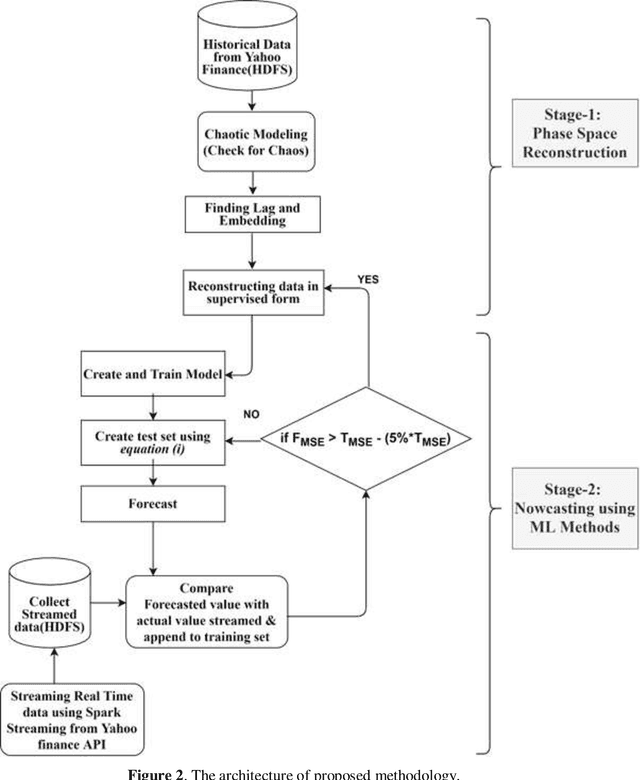
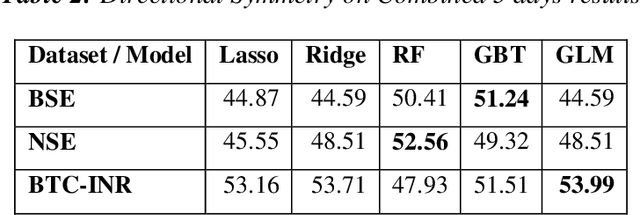
This paper proposes nowcasting of high-frequency financial datasets in real-time with a 5-minute interval using the streaming analytics feature of Apache Spark. The proposed 2 stage method consists of modelling chaos in the first stage and then using a sliding window approach for training with machine learning algorithms namely Lasso Regression, Ridge Regression, Generalised Linear Model, Gradient Boosting Tree and Random Forest available in the MLLib of Apache Spark in the second stage. For testing the effectiveness of the proposed methodology, 3 different datasets, of which two are stock markets namely National Stock Exchange & Bombay Stock Exchange, and finally One Bitcoin-INR conversion dataset. For evaluating the proposed methodology, we used metrics such as Symmetric Mean Absolute Percentage Error, Directional Symmetry, and Theil U Coefficient. We tested the significance of each pair of models using the Diebold Mariano (DM) test.