 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Warped Dynamic Linear Models for Time Series of Counts
Oct 27, 2021
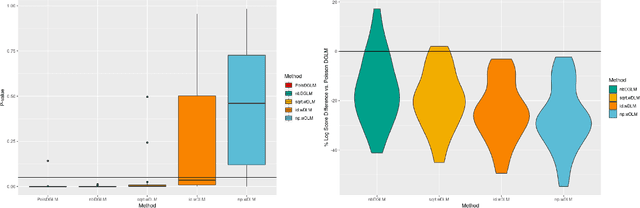
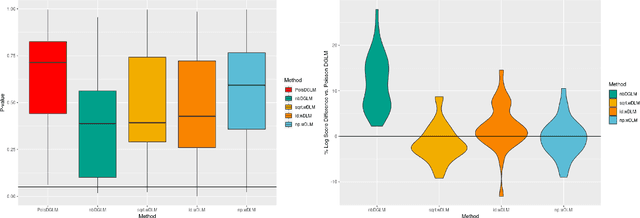
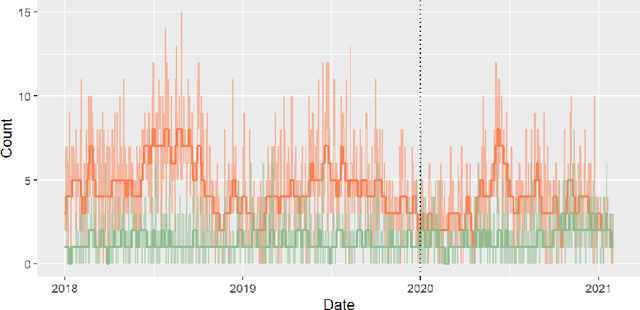
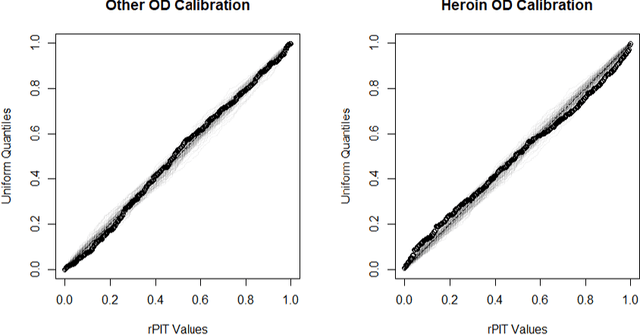
Dynamic Linear Models (DLMs) are commonly employed for time series analysis due to their versatile structure, simple recursive updating, and probabilistic forecasting. However, the options for count time series are limited: Gaussian DLMs require continuous data, while Poisson-based alternatives often lack sufficient modeling flexibility. We introduce a novel methodology for count time series by warping a Gaussian DLM. The warping function has two components: a transformation operator that provides distributional flexibility and a rounding operator that ensures the correct support for the discrete data-generating process. Importantly, we develop conjugate inference for the warped DLM, which enables analytic and recursive updates for the state space filtering and smoothing distributions. We leverage these results to produce customized and efficient computing strategies for inference and forecasting, including Monte Carlo simulation for offline analysis and an optimal particle filter for online inference. This framework unifies and extends a variety of discrete time series models and is valid for natural counts, rounded values, and multivariate observations. Simulation studies illustrate the excellent forecasting capabilities of the warped DLM. The proposed approach is applied to a multivariate time series of daily overdose counts and demonstrates both modeling and computational successes.
A Fully Polynomial Time Approximation Scheme for Fixed-Horizon Constrained Stochastic Shortest Path Problem under Local Transitions
Apr 10, 2022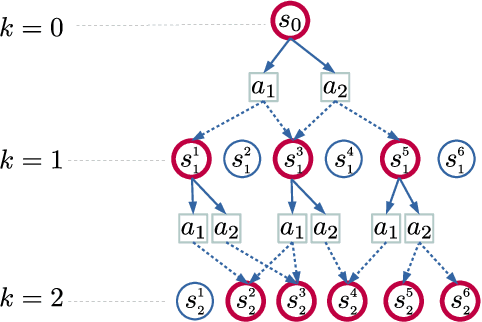
The fixed-horizon constrained stochastic shortest path problem (C-SSP) is a formalism for planning in stochastic environments under certain operating constraints. Chance-Constrained SSP (CC-SSP) is a variant that allows bounding the probability of constraint violation, which is desired in many safety-critical applications. This work considers an important variant of (C)C-SSP under local transition, capturing a broad class of SSP problems where state reachability exhibit a certain locality. Only a constant number of states can share some subsequent states. (C)C-SSP under local transition is NP-Hard even for a planning horizon of two. In this work, we propose a fully polynomial-time approximation scheme for (C)C-SSP that computes (near) optimal deterministic policies. Such an algorithm is the best approximation algorithm attainable in theory
Optimization of a Real-Time Wavelet-Based Algorithm for Improving Speech Intelligibility
Feb 05, 2022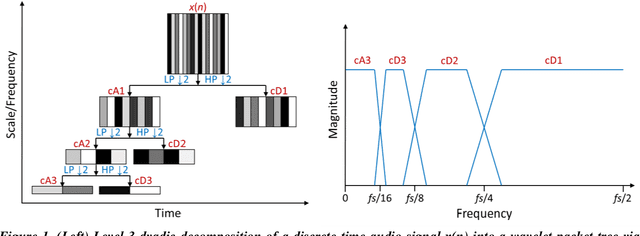
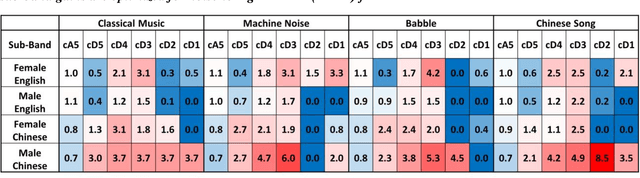

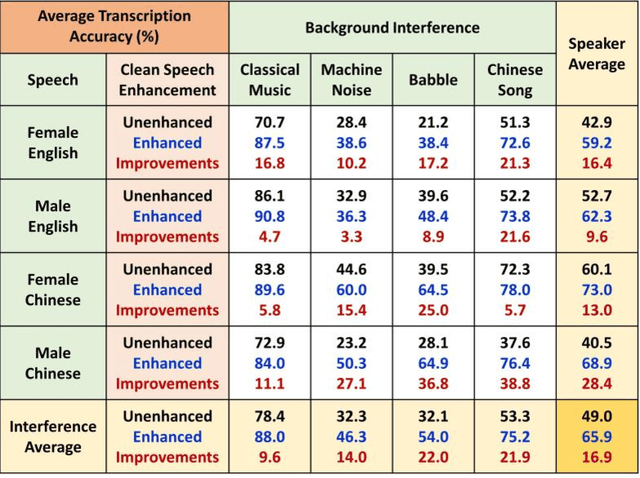
The optimization of a wavelet-based algorithm to improve speech intelligibility is reported. The discrete-time speech signal is split into frequency sub-bands via a multi-level discrete wavelet transform. Various gains are applied to the sub-band signals before they are recombined to form a modified version of the speech. The sub-band gains are adjusted while keeping the overall signal energy unchanged, and the speech intelligibility under various background interference and simulated hearing loss conditions is enhanced and evaluated objectively and quantitatively using Google Speech-to-Text transcription. For English and Chinese noise-free speech, overall intelligibility is improved, and the transcription accuracy can be increased by as much as 80 percentage points by reallocating the spectral energy toward the mid-frequency sub-bands, effectively increasing the consonant-vowel intensity ratio. This is reasonable since the consonants are relatively weak and of short duration, which are therefore the most likely to become indistinguishable in the presence of background noise or high-frequency hearing impairment. For speech already corrupted by noise, improving intelligibility is challenging but still realizable. The proposed algorithm is implementable for real-time signal processing and comparatively simpler than previous algorithms. Potential applications include speech enhancement, hearing aids, machine listening, and a better understanding of speech intelligibility.
HDDL 2.1: Towards Defining an HTN Formalism with Time
Jun 03, 2022



Real world applications of planning, like in industry and robotics, require modelling rich and diverse scenarios. Their resolution usually requires coordinated and concurrent action executions. In several cases, such planning problems are naturally decomposed in a hierarchical way and expressed by a Hierarchical Task Network (HTN) formalism. The PDDL language used to specify planning domains has evolved to cover the different planning paradigms. However, formulating real and complex scenarios where numerical and temporal constraints concur in defining a solution is still a challenge. Our proposition aims at filling the gap between existing planning languages and operational needs. To do so, we propose to extend HDDL taking inspiration from PDDL 2.1 and ANML to express temporal and numerical expressions. This paper opens discussions on the semantics and the syntax needed to extend HDDL, and illustrate these needs with the modelling of an Earth Observing Satellite planning problem.
FONDUE: an algorithm to find the optimal dimensionality of the latent representations of variational autoencoders
Sep 26, 2022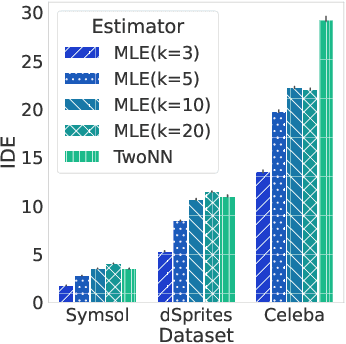

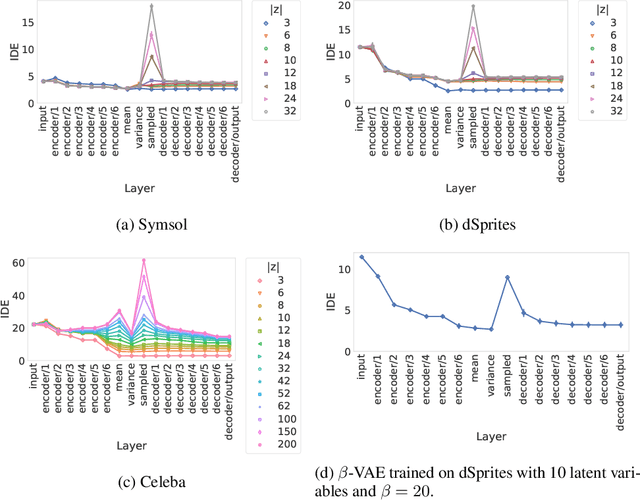
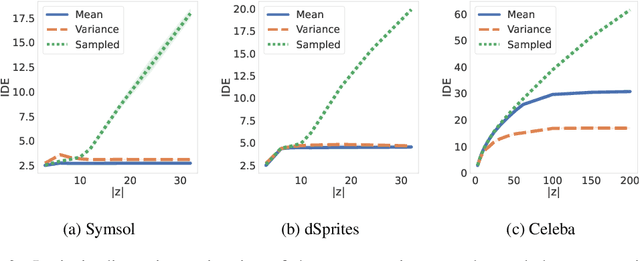
When training a variational autoencoder (VAE) on a given dataset, determining the optimal number of latent variables is mostly done by grid search: a costly process in terms of computational time and carbon footprint. In this paper, we explore the intrinsic dimension estimation (IDE) of the data and latent representations learned by VAEs. We show that the discrepancies between the IDE of the mean and sampled representations of a VAE after only a few steps of training reveal the presence of passive variables in the latent space, which, in well-behaved VAEs, indicates a superfluous number of dimensions. Using this property, we propose FONDUE: an algorithm which quickly finds the number of latent dimensions after which the mean and sampled representations start to diverge (i.e., when passive variables are introduced), providing a principled method for selecting the number of latent dimensions for VAEs and autoencoders.
Identifying Differential Equations to predict Blood Glucose using Sparse Identification of Nonlinear Systems
Sep 28, 2022
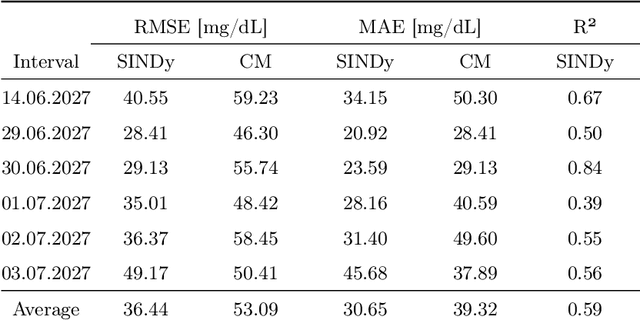
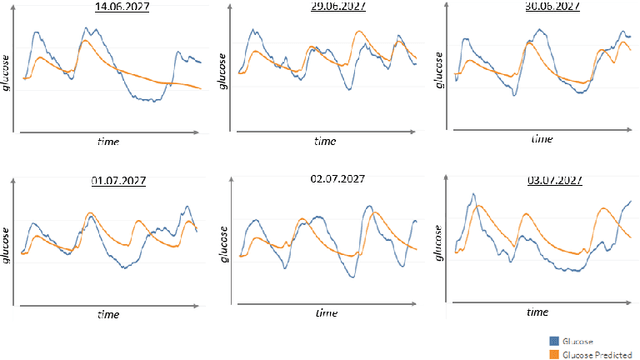
Describing dynamic medical systems using machine learning is a challenging topic with a wide range of applications. In this work, the possibility of modeling the blood glucose level of diabetic patients purely on the basis of measured data is described. A combination of the influencing variables insulin and calories are used to find an interpretable model. The absorption speed of external substances in the human body depends strongly on external influences, which is why time-shifts are added for the influencing variables. The focus is put on identifying the best timeshifts that provide robust models with good prediction accuracy that are independent of other unknown external influences. The modeling is based purely on the measured data using Sparse Identification of Nonlinear Dynamics. A differential equation is determined which, starting from an initial value, simulates blood glucose dynamics. By applying the best model to test data, we can show that it is possible to simulate the long-term blood glucose dynamics using differential equations and few, influencing variables.
Homotopy-based training of NeuralODEs for accurate dynamics discovery
Oct 04, 2022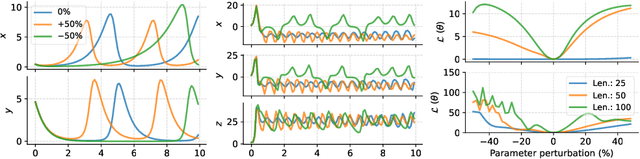
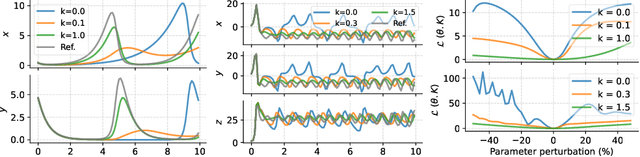
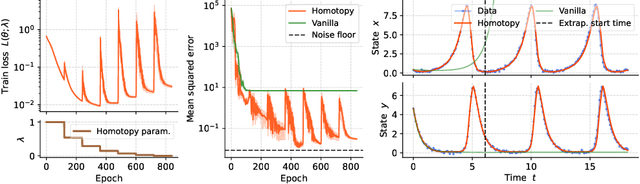
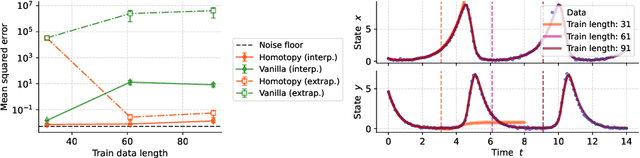
Conceptually, Neural Ordinary Differential Equations (NeuralODEs) pose an attractive way to extract dynamical laws from time series data, as they are natural extensions of the traditional differential equation-based modeling paradigm of the physical sciences. In practice, NeuralODEs display long training times and suboptimal results, especially for longer duration data where they may fail to fit the data altogether. While methods have been proposed to stabilize NeuralODE training, many of these involve placing a strong constraint on the functional form the trained NeuralODE can take that the actual underlying governing equation does not guarantee satisfaction. In this work, we present a novel NeuralODE training algorithm that leverages tools from the chaos and mathematical optimization communities - synchronization and homotopy optimization - for a breakthrough in tackling the NeuralODE training obstacle. We demonstrate architectural changes are unnecessary for effective NeuralODE training. Compared to the conventional training methods, our algorithm achieves drastically lower loss values without any changes to the model architectures. Experiments on both simulated and real systems with complex temporal behaviors demonstrate NeuralODEs trained with our algorithm are able to accurately capture true long term behaviors and correctly extrapolate into the future.
Type theory in human-like learning and inference
Oct 04, 2022Humans can generate reasonable answers to novel queries (Schulz, 2012): if I asked you what kind of food you want to eat for lunch, you would respond with a food, not a time. The thought that one would respond "After 4pm" to "What would you like to eat" is either a joke or a mistake, and seriously entertaining it as a lunch option would likely never happen in the first place. While understanding how people come up with new ideas, thoughts, explanations, and hypotheses that obey the basic constraints of a novel search space is of central importance to cognitive science, there is no agreed-on formal model for this kind of reasoning. We propose that a core component of any such reasoning system is a type theory: a formal imposition of structure on the kinds of computations an agent can perform, and how they're performed. We motivate this proposal with three empirical observations: adaptive constraints on learning and inference (i.e. generating reasonable hypotheses), how people draw distinctions between improbability and impossibility, and people's ability to reason about things at varying levels of abstraction.
Wi-Closure: Reliable and Efficient Search of Inter-robot Loop Closures Using Wireless Sensing
Oct 04, 2022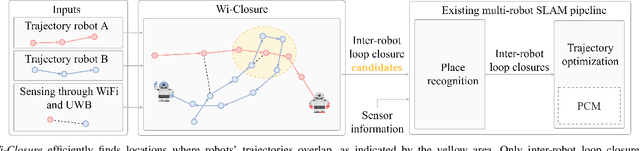
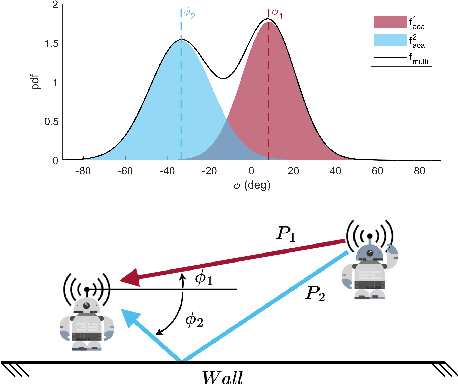
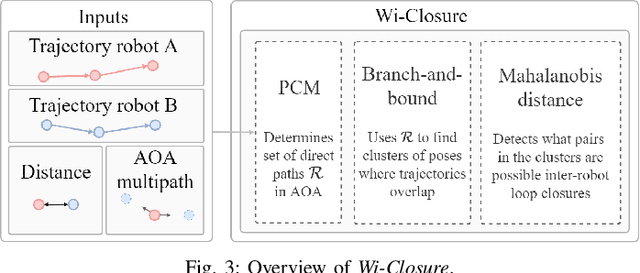
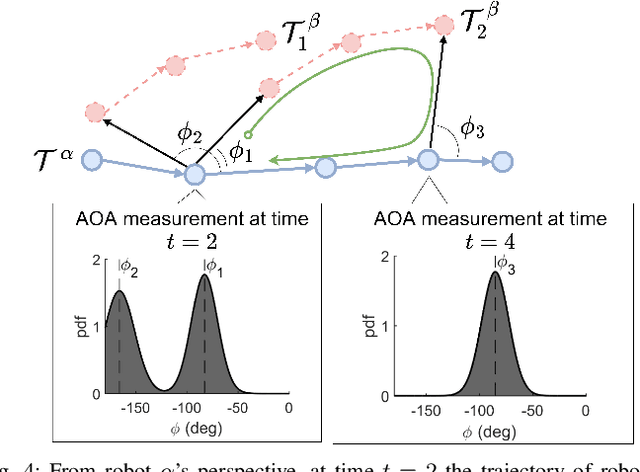
In this paper we propose a novel algorithm, Wi-Closure, to improve computational efficiency and robustness of loop closure detection in multi-robot SLAM. Our approach decreases the computational overhead of classical approaches by pruning the search space of potential loop closures, prior to evaluation by a typical multi-robot SLAM pipeline. Wi-Closure achieves this by identifying candidates that are spatially close to each other by using sensing over the wireless communication signal between robots, even when they are operating in non-line-of-sight or in remote areas of the environment from one another. We demonstrate the validity of our approach in simulation and hardware experiments. Our results show that using Wi-closure greatly reduces computation time, by 54% in simulation and by 77% in hardware compared, with a multi-robot SLAM baseline. Importantly, this is achieved without sacrificing accuracy. Using Wi-Closure reduces absolute trajectory estimation error by 99% in simulation and 89.2% in hardware experiments. This improvement is due in part to Wi-Closure's ability to avoid catastrophic optimization failure that typically occurs with classical approaches in challenging repetitive environments.
Continuous Monte Carlo Graph Search
Oct 04, 2022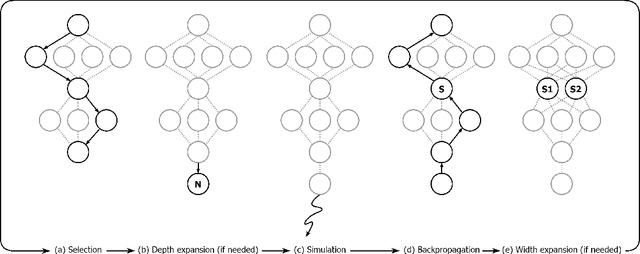

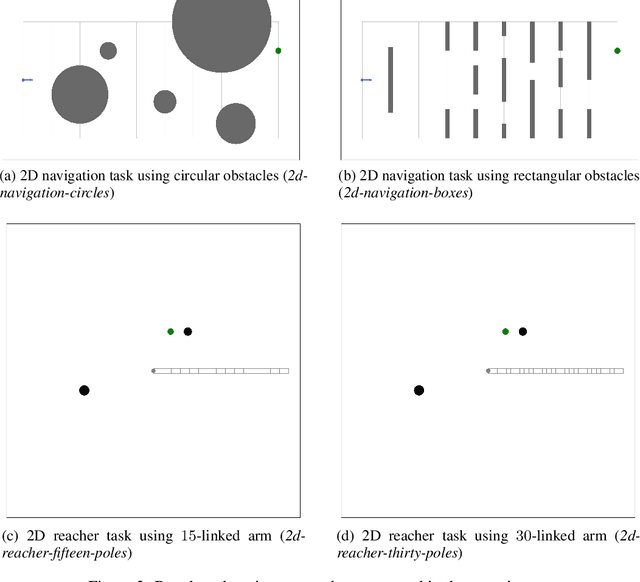

In many complex sequential decision making tasks, online planning is crucial for high-performance. For efficient online planning, Monte Carlo Tree Search (MCTS) employs a principled mechanism for trading off between exploration and exploitation. MCTS outperforms comparison methods in various discrete decision making domains such as Go, Chess, and Shogi. Following, extensions of MCTS to continuous domains have been proposed. However, the inherent high branching factor and the resulting explosion of search tree size is limiting existing methods. To solve this problem, this paper proposes Continuous Monte Carlo Graph Search (CMCGS), a novel extension of MCTS to online planning in environments with continuous state and action spaces. CMCGS takes advantage of the insight that, during planning, sharing the same action policy between several states can yield high performance. To implement this idea, at each time step CMCGS clusters similar states into a limited number of stochastic action bandit nodes, which produce a layered graph instead of an MCTS search tree. Experimental evaluation with limited sample budgets shows that CMCGS outperforms comparison methods in several complex continuous DeepMind Control Suite benchmarks and a 2D navigation task.