 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Online and Distributed Mean Estimation Under Adversarial Data Corruption
Sep 17, 2022
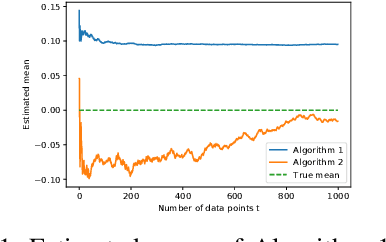
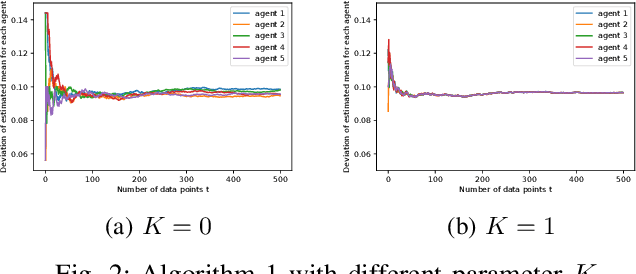
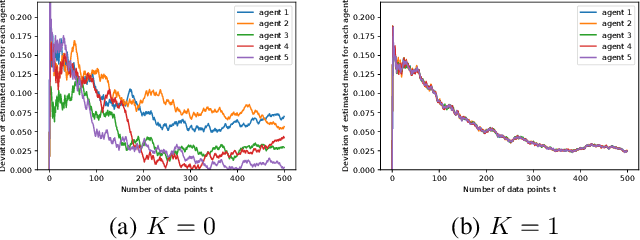
We study robust mean estimation in an online and distributed scenario in the presence of adversarial data attacks. At each time step, each agent in a network receives a potentially corrupted data point, where the data points were originally independent and identically distributed samples of a random variable. We propose online and distributed algorithms for all agents to asymptotically estimate the mean. We provide the error-bound and the convergence properties of the estimates to the true mean under our algorithms. Based on the network topology, we further evaluate each agent's trade-off in convergence rate between incorporating data from neighbors and learning with only local observations.
Learning-based Uncertainty-aware Navigation in 3D Off-Road Terrains
Sep 19, 2022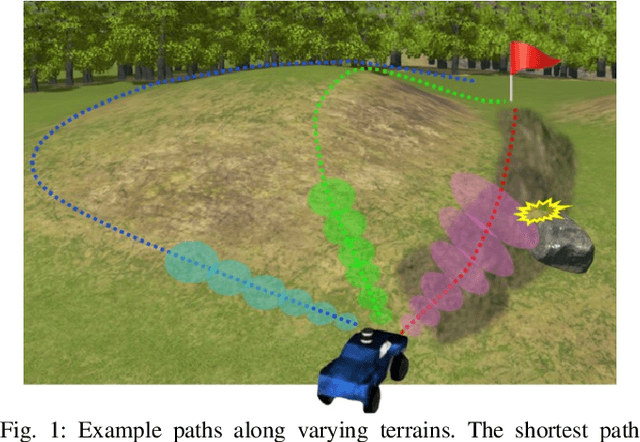
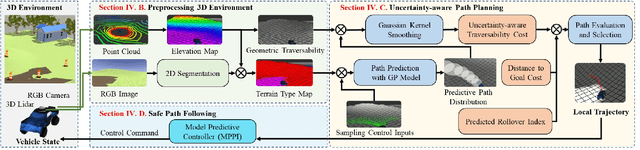
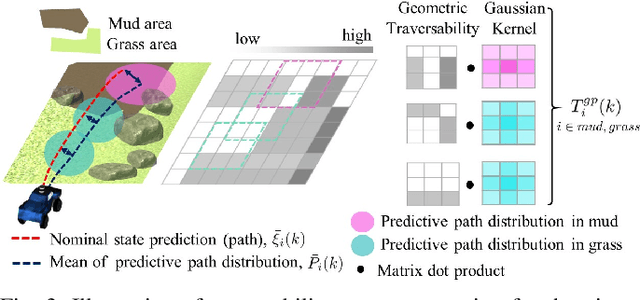
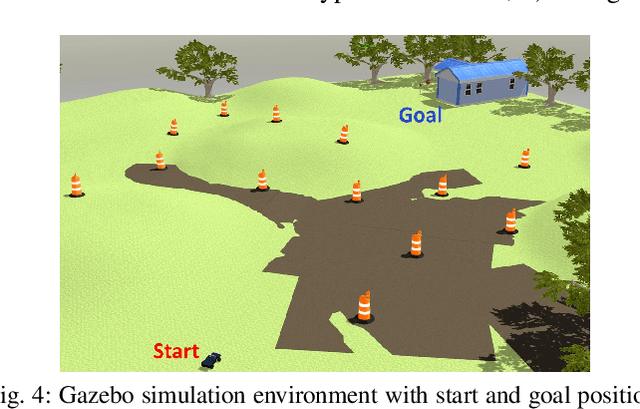
This paper presents a safe, efficient, and agile ground vehicle navigation algorithm for 3D off-road terrain environments. Off-road navigation is subject to uncertain vehicle-terrain interactions caused by different terrain conditions on top of 3D terrain topology. The existing works are limited to adopt overly simplified vehicle-terrain models. The proposed algorithm learns the terrain-induced uncertainties from driving data and encodes the learned uncertainty distribution into the traversability cost for path evaluation. The navigation path is then designed to optimize the uncertainty-aware traversability cost, resulting in a safe and agile vehicle maneuver. Assuring real-time execution, the algorithm is further implemented within parallel computation architecture running on Graphics Processing Units (GPU).
A Solver-Free Framework for Scalable Learning in Neural ILP Architectures
Oct 17, 2022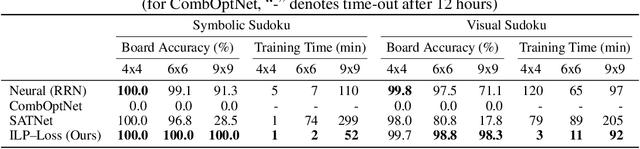
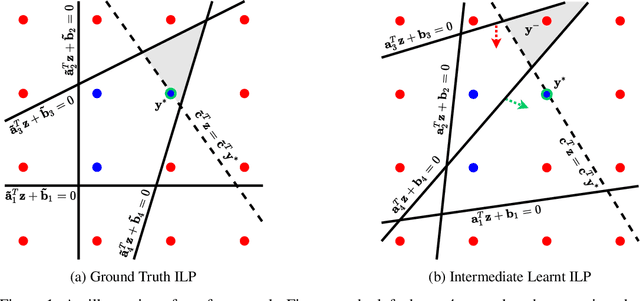
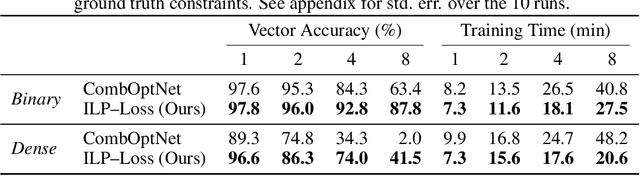

There is a recent focus on designing architectures that have an Integer Linear Programming (ILP) layer within a neural model (referred to as Neural ILP in this paper). Neural ILP architectures are suitable for pure reasoning tasks that require data-driven constraint learning or for tasks requiring both perception (neural) and reasoning (ILP). A recent SOTA approach for end-to-end training of Neural ILP explicitly defines gradients through the ILP black box (Paulus et al. 2021) - this trains extremely slowly, owing to a call to the underlying ILP solver for every training data point in a minibatch. In response, we present an alternative training strategy that is solver-free, i.e., does not call the ILP solver at all at training time. Neural ILP has a set of trainable hyperplanes (for cost and constraints in ILP), together representing a polyhedron. Our key idea is that the training loss should impose that the final polyhedron separates the positives (all constraints satisfied) from the negatives (at least one violated constraint or a suboptimal cost value), via a soft-margin formulation. While positive example(s) are provided as part of the training data, we devise novel techniques for generating negative samples. Our solution is flexible enough to handle equality as well as inequality constraints. Experiments on several problems, both perceptual as well as symbolic, which require learning the constraints of an ILP, show that our approach has superior performance and scales much better compared to purely neural baselines and other state-of-the-art models that require solver-based training. In particular, we are able to obtain excellent performance in 9 x 9 symbolic and visual sudoku, to which the other Neural ILP solver is not able to scale.
Learning 6D Pose Estimation from Synthetic RGBD Images for Robotic Applications
Aug 30, 2022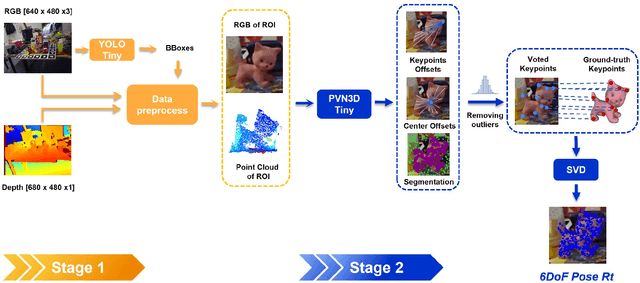
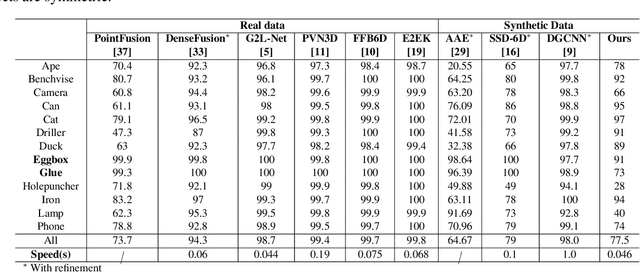

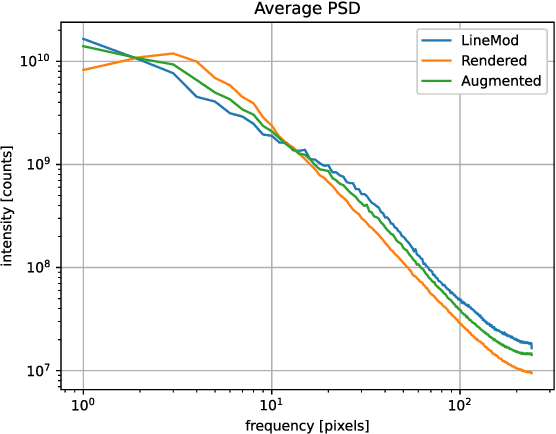
In this work, we propose a data generation pipeline by leveraging the 3D suite Blender to produce synthetic RGBD image datasets with 6D poses for robotic picking. The proposed pipeline can efficiently generate large amounts of photo-realistic RGBD images for the object of interest. In addition, a collection of domain randomization techniques is introduced to bridge the gap between real and synthetic data. Furthermore, we develop a real-time two-stage 6D pose estimation approach by integrating the object detector YOLO-V4-tiny and the 6D pose estimation algorithm PVN3D for time sensitive robotics applications. With the proposed data generation pipeline, our pose estimation approach can be trained from scratch using only synthetic data without any pre-trained models. The resulting network shows competitive performance compared to state-of-the-art methods when evaluated on LineMod dataset. We also demonstrate the proposed approach in a robotic experiment, grasping a household object from cluttered background under different lighting conditions.
Automatic driving path plan based on iterative and triple optimization method
Sep 08, 2022
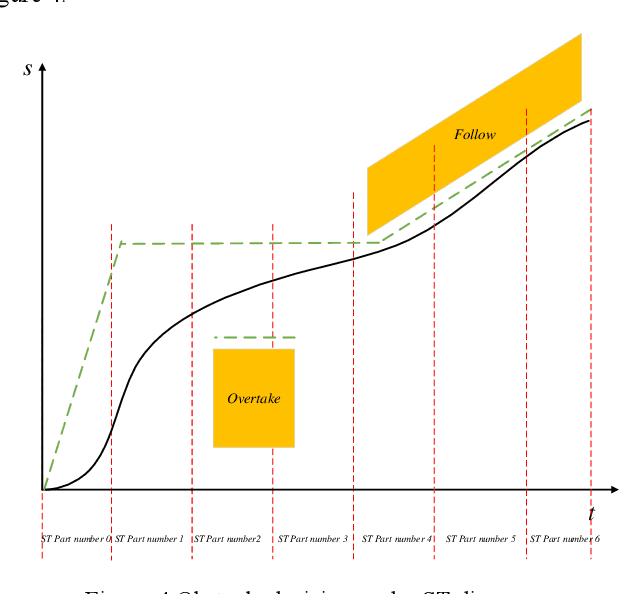
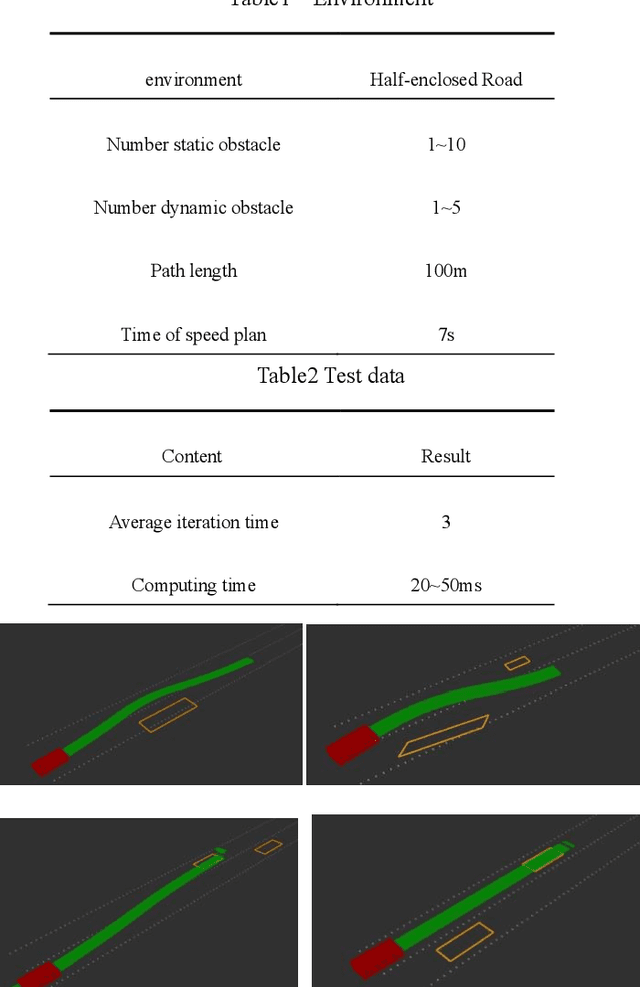
This paper presents a triple optimization algorithm of two-dimensional space, driving path and driving speed, and iterates in the time dimension to obtain the local optimal solution of path and speed in the optimal driving area. Design iterative algorithm to solve the best driving path and speed within the limited conditions. The algorithm can meet the path planning needs of automatic driving vehicle in complex scenes and medium and high-speed scenes.
Hyperactive Learning (HAL) for Data-Driven Interatomic Potentials
Oct 09, 2022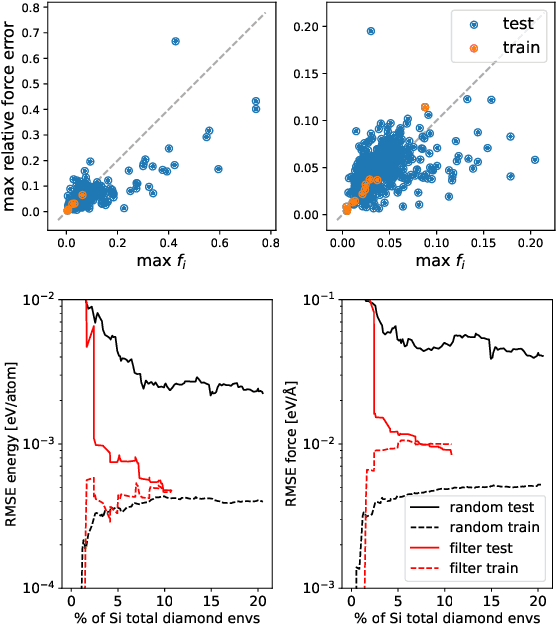
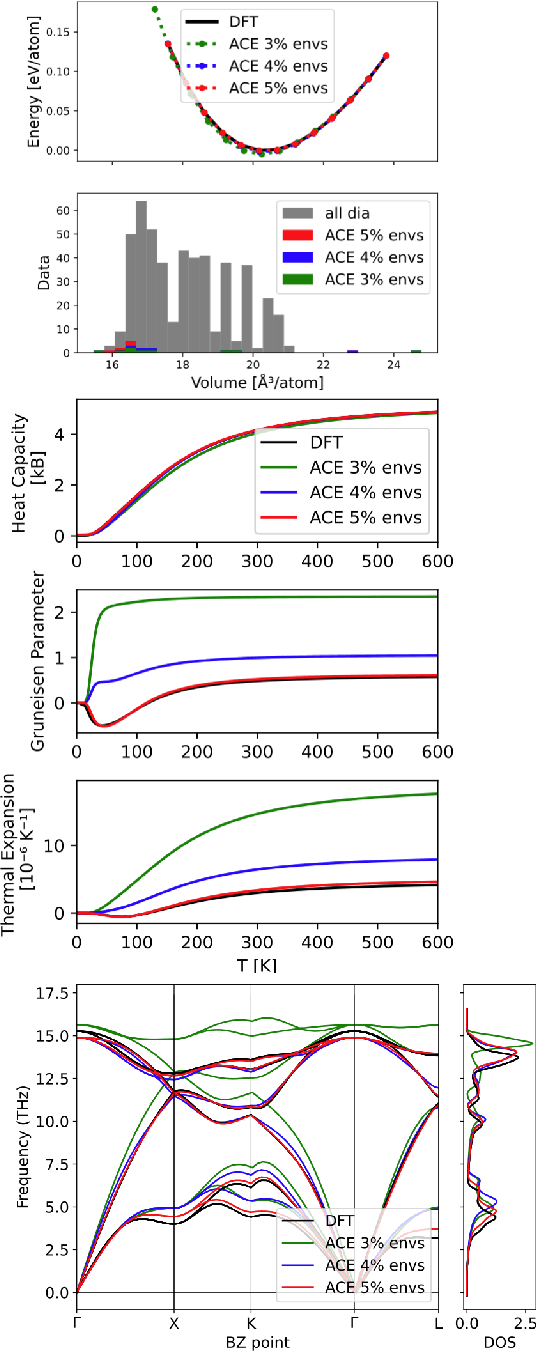
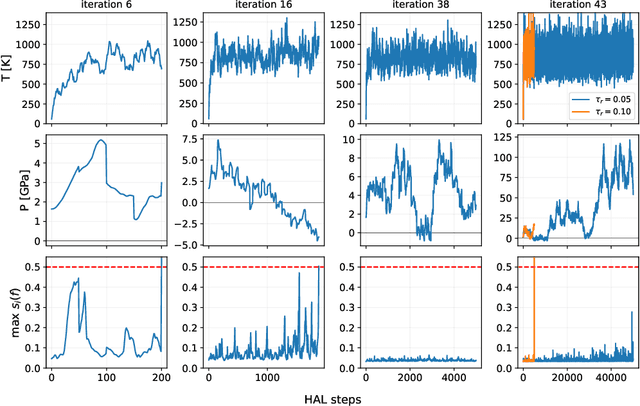
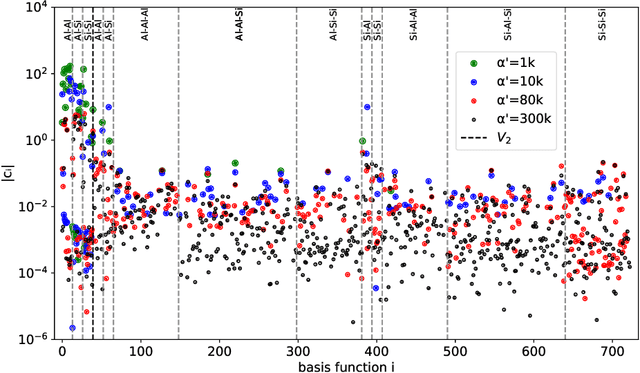
Data-driven interatomic potentials have emerged as a powerful class of surrogate models for ab initio potential energy surfaces that are able to reliably predict macroscopic properties with experimental accuracy. In generating accurate and transferable potentials the most time-consuming and arguably most important task is generating the training set, which still requires significant expert user input. To accelerate this process, this work presents hyperactive learning (HAL), a framework for formulating an accelerated sampling algorithm specifically for the task of training database generation. The overarching idea is to start from a physically motivated sampler (e.g., molecular dynamics) and a biasing term that drives the system towards high uncertainty and thus to unseen training configurations. Building on this framework, general protocols for building training databases for alloys and polymers leveraging the HAL framework will be presented. For alloys, fast (< 100 microsecond/atom/cpu-core) ACE potentials for AlSi10 are created that able to predict the melting temperature with good accuracy by fitting to a minimal HAL-generated database containing 88 configurations (32 atoms each) in 17 seconds using 8 cpu threads. For polymers, a HAL database is built using ACE able to determine the density of a long polyethylene glycol (PEG) polymer formed of 200 monomer units with experimental accuracy by only fitting to small isolated PEG polymers with sizes ranging from 2 to 32.
Super-Resolution by Predicting Offsets: An Ultra-Efficient Super-Resolution Network for Rasterized Images
Oct 09, 2022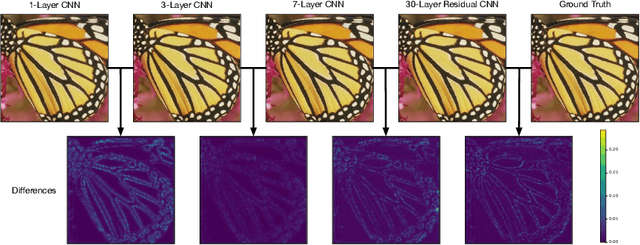
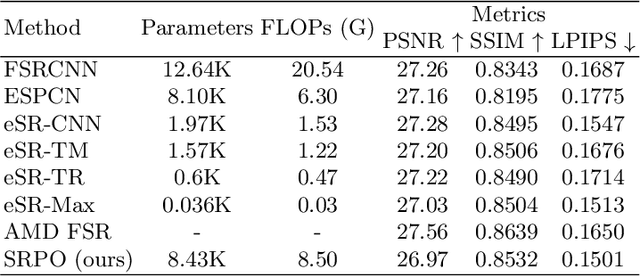
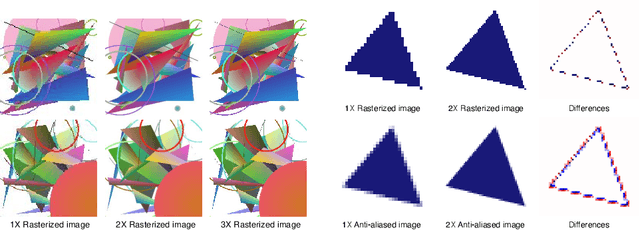
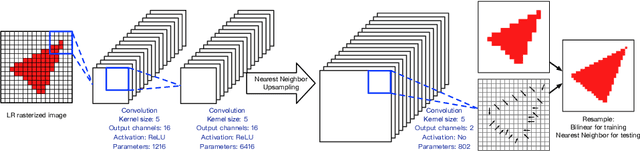
Rendering high-resolution (HR) graphics brings substantial computational costs. Efficient graphics super-resolution (SR) methods may achieve HR rendering with small computing resources and have attracted extensive research interests in industry and research communities. We present a new method for real-time SR for computer graphics, namely Super-Resolution by Predicting Offsets (SRPO). Our algorithm divides the image into two parts for processing, i.e., sharp edges and flatter areas. For edges, different from the previous SR methods that take the anti-aliased images as inputs, our proposed SRPO takes advantage of the characteristics of rasterized images to conduct SR on the rasterized images. To complement the residual between HR and low-resolution (LR) rasterized images, we train an ultra-efficient network to predict the offset maps to move the appropriate surrounding pixels to the new positions. For flat areas, we found simple interpolation methods can already generate reasonable output. We finally use a guided fusion operation to integrate the sharp edges generated by the network and flat areas by the interpolation method to get the final SR image. The proposed network only contains 8,434 parameters and can be accelerated by network quantization. Extensive experiments show that the proposed SRPO can achieve superior visual effects at a smaller computational cost than the existing state-of-the-art methods.
Less is More: Facial Landmarks can Recognize a Spontaneous Smile
Oct 09, 2022
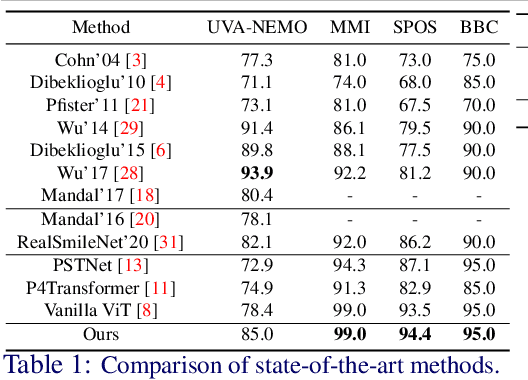
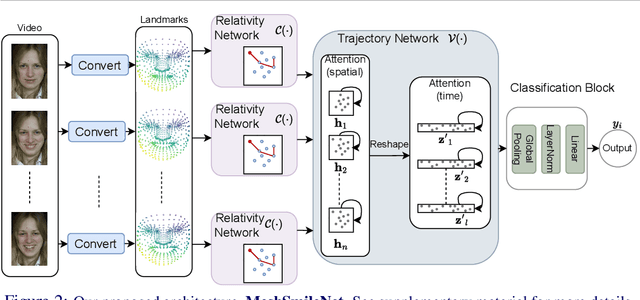
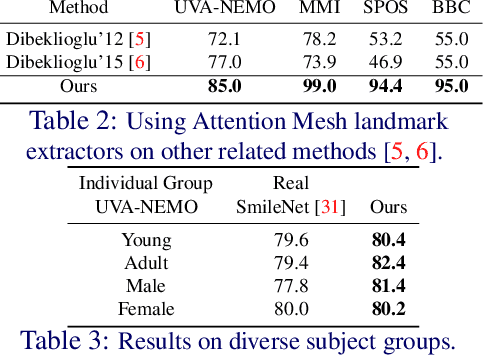
Smile veracity classification is a task of interpreting social interactions. Broadly, it distinguishes between spontaneous and posed smiles. Previous approaches used hand-engineered features from facial landmarks or considered raw smile videos in an end-to-end manner to perform smile classification tasks. Feature-based methods require intervention from human experts on feature engineering and heavy pre-processing steps. On the contrary, raw smile video inputs fed into end-to-end models bring more automation to the process with the cost of considering many redundant facial features (beyond landmark locations) that are mainly irrelevant to smile veracity classification. It remains unclear to establish discriminative features from landmarks in an end-to-end manner. We present a MeshSmileNet framework, a transformer architecture, to address the above limitations. To eliminate redundant facial features, our landmarks input is extracted from Attention Mesh, a pre-trained landmark detector. Again, to discover discriminative features, we consider the relativity and trajectory of the landmarks. For the relativity, we aggregate facial landmark that conceptually formats a curve at each frame to establish local spatial features. For the trajectory, we estimate the movements of landmark composed features across time by self-attention mechanism, which captures pairwise dependency on the trajectory of the same landmark. This idea allows us to achieve state-of-the-art performances on UVA-NEMO, BBC, MMI Facial Expression, and SPOS datasets.
Noise-Robust De-Duplication at Scale
Oct 09, 2022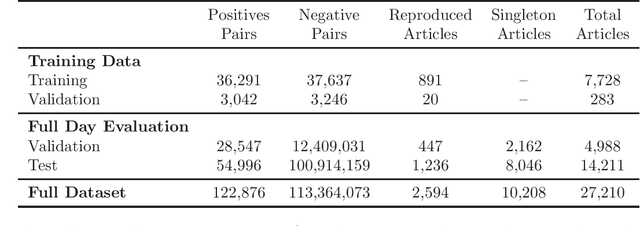



Identifying near duplicates within large, noisy text corpora has a myriad of applications that range from de-duplicating training datasets, reducing privacy risk, and evaluating test set leakage, to identifying reproduced news articles and literature within large corpora. Across these diverse applications, the overwhelming majority of work relies on N-grams. Limited efforts have been made to evaluate how well N-gram methods perform, in part because it is unclear how one could create an unbiased evaluation dataset for a massive corpus. This study uses the unique timeliness of historical news wires to create a 27,210 document dataset, with 122,876 positive duplicate pairs, for studying noise-robust de-duplication. The time-sensitivity of news makes comprehensive hand labelling feasible - despite the massive overall size of the corpus - as duplicates occur within a narrow date range. The study then develops and evaluates a range of de-duplication methods: hashing and N-gram overlap (which predominate in the literature), a contrastively trained bi-encoder, and a re-rank style approach combining a bi- and cross-encoder. The neural approaches significantly outperform hashing and N-gram overlap. We show that the bi-encoder scales well, de-duplicating a 10 million article corpus on a single GPU card in a matter of hours. The public release of our NEWS-COPY de-duplication dataset will facilitate further research and applications.
SoftGroup++: Scalable 3D Instance Segmentation with Octree Pyramid Grouping
Sep 17, 2022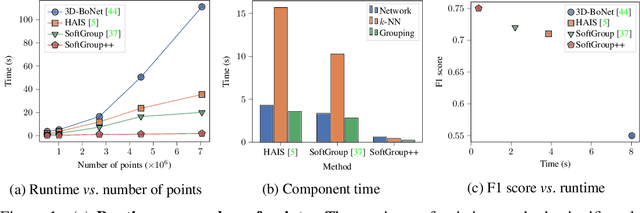
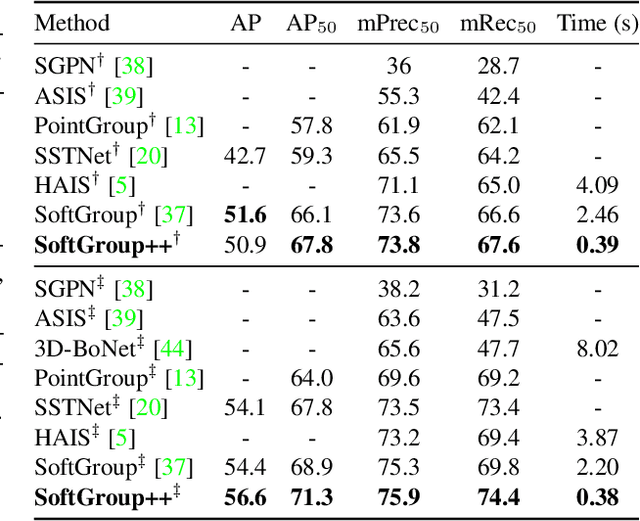
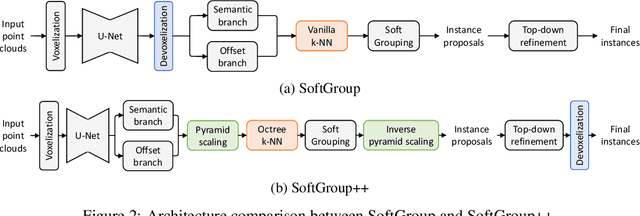
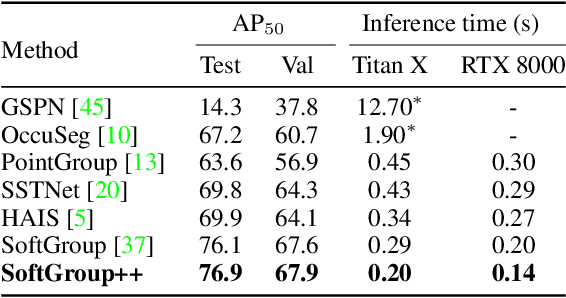
Existing state-of-the-art 3D point cloud instance segmentation methods rely on a grouping-based approach that groups points to obtain object instances. Despite improvement in producing accurate segmentation results, these methods lack scalability and commonly require dividing large input into multiple parts. To process a scene with millions of points, the existing fastest method SoftGroup \cite{vu2022softgroup} requires tens of seconds, which is under satisfaction. Our finding is that $k$-Nearest Neighbor ($k$-NN), which serves as the prerequisite of grouping, is a computational bottleneck. This bottleneck severely worsens the inference time in the scene with a large number of points. This paper proposes SoftGroup++ to address this computational bottleneck and further optimize the inference speed of the whole network. SoftGroup++ is built upon SoftGroup, which differs in three important aspects: (1) performs octree $k$-NN instead of vanilla $k$-NN to reduce time complexity from $\mathcal{O}(n^2)$ to $\mathcal{O}(n \log n)$, (2) performs pyramid scaling that adaptively downsamples backbone outputs to reduce search space for $k$-NN and grouping, and (3) performs late devoxelization that delays the conversion from voxels to points towards the end of the model such that intermediate components operate at a low computational cost. Extensive experiments on various indoor and outdoor datasets demonstrate the efficacy of the proposed SoftGroup++. Notably, SoftGroup++ processes large scenes of millions of points by a single forward without dividing the input into multiple parts, thus enriching contextual information. Especially, SoftGroup++ achieves 2.4 points AP$_{50}$ improvement while nearly $6\times$ faster than the existing fastest method on S3DIS dataset. The code and trained models will be made publicly available.