 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
This is what a pandemic looks like: Visual framing of COVID-19 on search engines
Sep 22, 2022
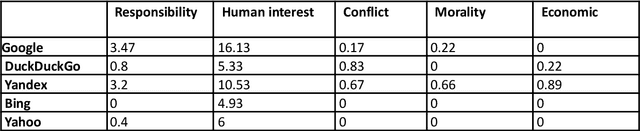
In today's high-choice media environment, search engines play an integral role in informing individuals and societies about the latest events. The importance of search algorithms is even higher at the time of crisis, when users search for information to understand the causes and the consequences of the current situation and decide on their course of action. In our paper, we conduct a comparative audit of how different search engines prioritize visual information related to COVID-19 and what consequences it has for the representation of the pandemic. Using a virtual agent-based audit approach, we examine image search results for the term "coronavirus" in English, Russian and Chinese on five major search engines: Google, Yandex, Bing, Yahoo, and DuckDuckGo. Specifically, we focus on how image search results relate to generic news frames (e.g., the attribution of responsibility, human interest, and economics) used in relation to COVID-19 and how their visual composition varies between the search engines.
Analytic Optimization-Based Microbubble Tracking in Ultrasound Super-Resolution Microscopy
Sep 21, 2022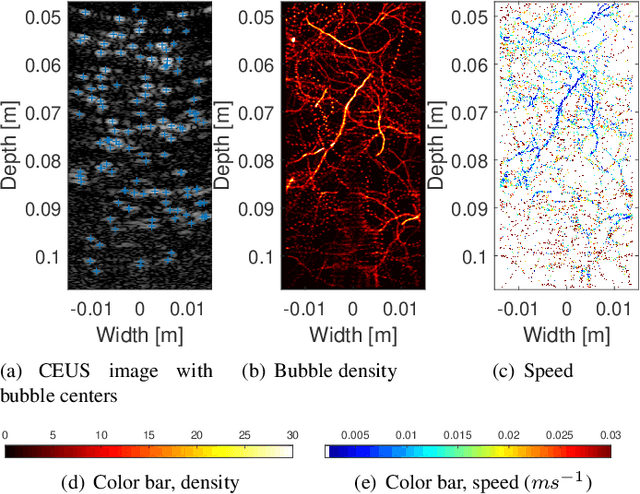
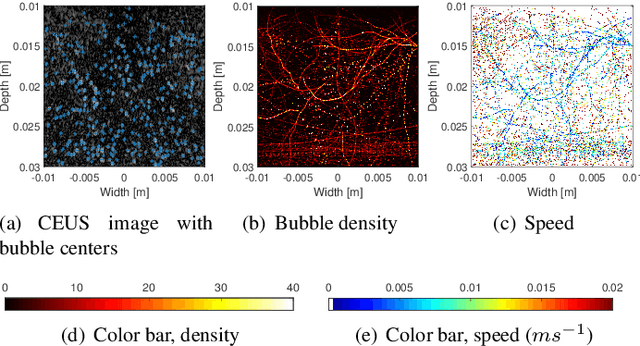
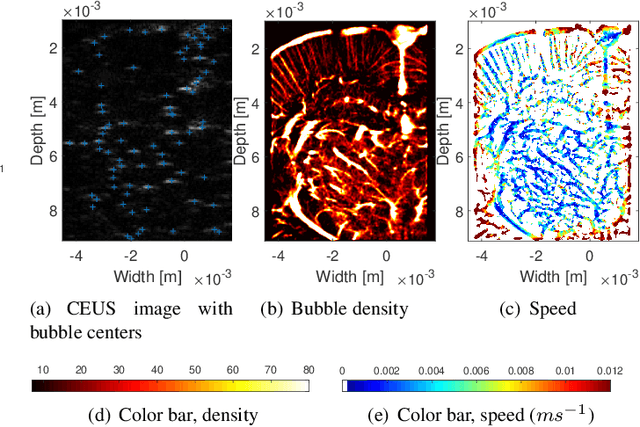
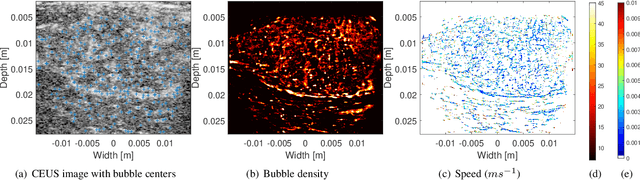
Ultrasound localization microscopy (ULM) refers to a promising medical imaging modality that systematically leverages the advantages of contrast-enhanced ultrasound (CEUS) to surpass the diffraction barrier and delineate the microvascular map. Localization and tracking of microbubbles (MBs), two significant steps of ULM, facilitate generating the vascular map and the velocity distribution, respectively. Herein, we propose a novel MB tracking technique considering temporal pairing as a bubble-set registration problem. Iterative registration is performed between the bubble sets in two consecutive time instants by analytically optimizing a cost function that takes position and point-spread function (PSF) similarities as well as physically plausible levels of bubbles' movement into account. Furthermore, we infer MBs' parity in a fuzzy manner instead of binary. The proposed technique performs well in validation experiments with two synthetic and two in vivo datasets provided by the Ultrasound Localisation and TRacking Algorithms for Super Resolution (ULTRA-SR) Challenge.
Robust Trajectory-based Density Estimation for Geometric Structure Recovery: Theory and Applications
Oct 01, 2022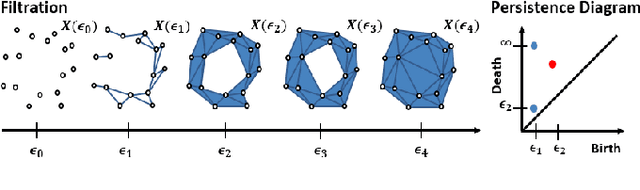
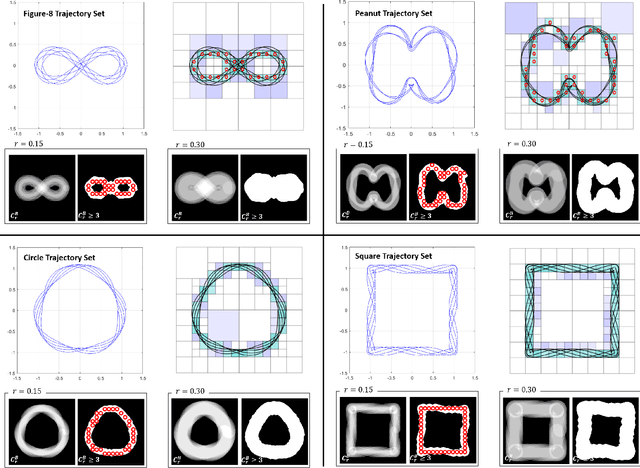
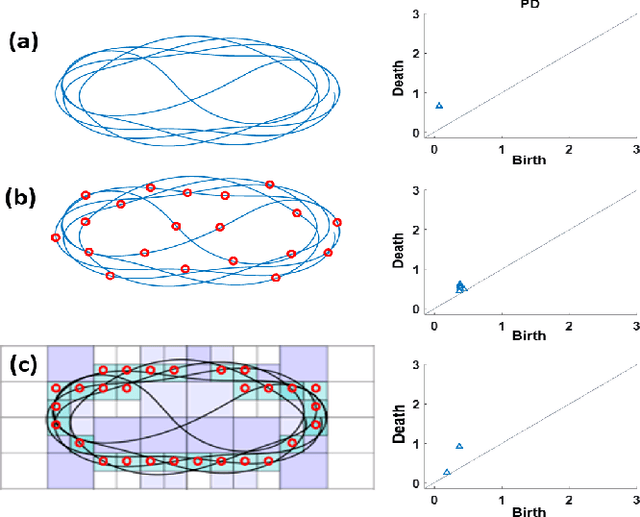
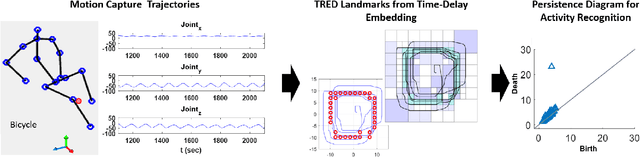
With the rise of the Internet of Things, strategies for effectively processing big data are essential for discovering meaningul insights. The time series datasets produced by groups of interconnected devices contain valuable underlying patterns. Recent works have extracted patterns from spatio-temporal datasets to aid in road network generation, activity recognition, and others. The speed and accuracy of the underlying geometry reconstruction are important in these applications. Existing methods such as kernel density estimation (KDE) have been used but are often computationally expensive. We propose modifying edge quadtrees to utilize their effective heirarchical structure. Our modification estimates density using a novel trajectory count function which provides mathematical guarantees on the stability of the count by enforcing an invariance to local perturbations. We evaluate our method's effectiveness at extracting the underlying geometry and representative subsample points. For verification, we compare against a KDE variant at extracting the underlying shape of noisy synthetic trajectories travelling alonng the shape. We compare map extraction from GPS traces against current methods. Our method significantly improves runtime while extracting the geometry better or at least comparably. We also compare against maxmin subsampling on an activity recognition data set and find a significant runtime improvement with comparable performance.
Probabilistic Traversability Model for Risk-Aware Motion Planning in Off-Road Environments
Oct 01, 2022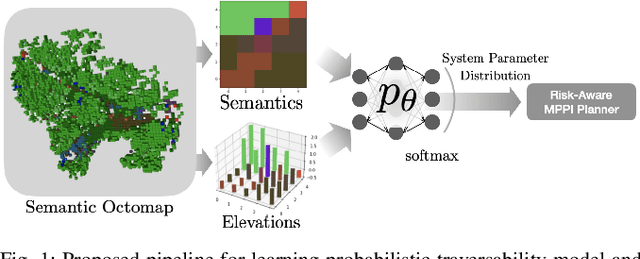
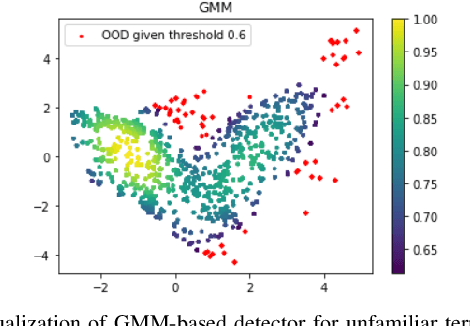
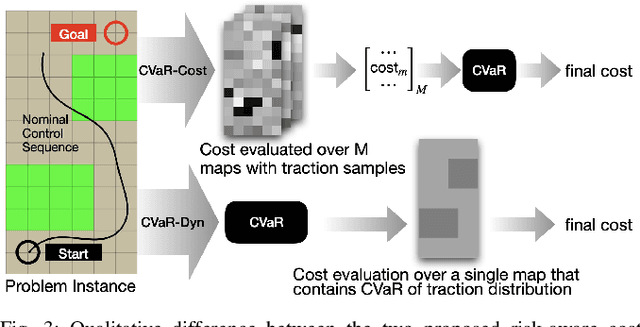
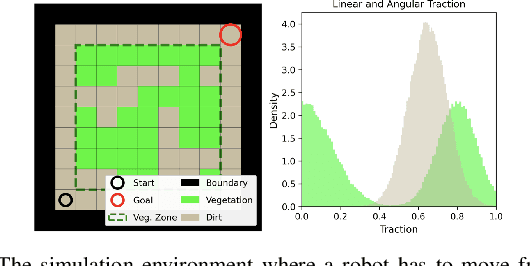
A key challenge in off-road navigation is that even visually similar or semantically identical terrain may have substantially different traction properties. Existing work typically assumes a nominal or expected robot dynamical model for planning, which can lead to degraded performance if the assumed models are not realizable given the terrain properties. In contrast, this work introduces a new probabilistic representation of traversability as a distribution of parameters in the robot's dynamical model that are conditioned on the terrain characteristics. This model is learned in a self-supervised manner by fitting a probability distribution over the parameters identified online, encoded as a neural network that takes terrain features as input. This work then presents two risk-aware planning algorithms that leverage the learned traversability model to plan risk-aware trajectories. Finally, a method for detecting unfamiliar terrain with respect to the training data is introduced based on a Gaussian Mixture Model fit to the latent space of the trained model. Experiments demonstrate that the proposed approach outperforms existing work that assumes nominal or expected robot dynamics in both success rate and completion time for representative navigation tasks. Furthermore, when the proposed approach is deployed in an unseen environment, excluding unfamiliar terrains during planning leads to improved success rate.
End-to-End Neural Audio Coding for Real-Time Communications
Jan 25, 2022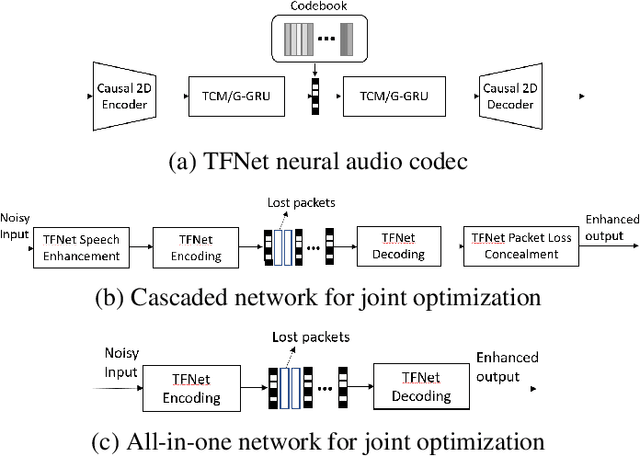
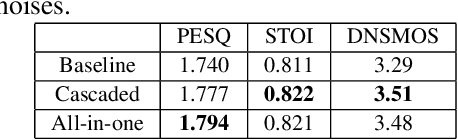
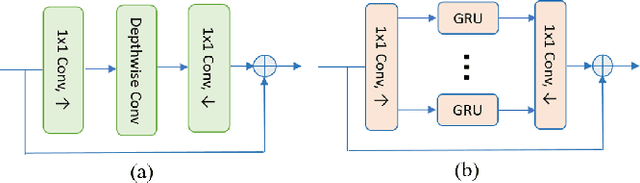
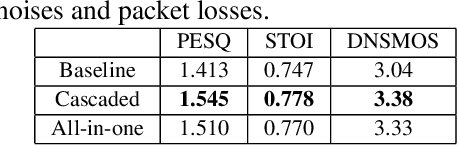
Deep-learning based methods have shown their advantages in audio coding over traditional ones but limited attention has been paid on real-time communications (RTC). This paper proposes the TFNet, an end-to-end neural audio codec with low latency for RTC. It takes an encoder-temporal filtering-decoder paradigm that seldom being investigated in audio coding. An interleaved structure is proposed for temporal filtering to capture both short-term and long-term temporal dependencies. Furthermore, with end-to-end optimization, the TFNet is jointly optimized with speech enhancement and packet loss concealment, yielding a one-for-all network for three tasks. Both subjective and objective results demonstrate the efficiency of the proposed TFNet.
Effective Multi-User Delay-Constrained Scheduling with Deep Recurrent Reinforcement Learning
Aug 30, 2022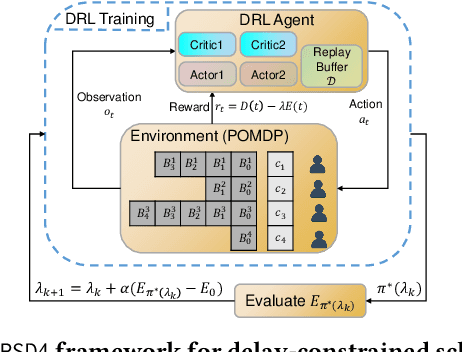

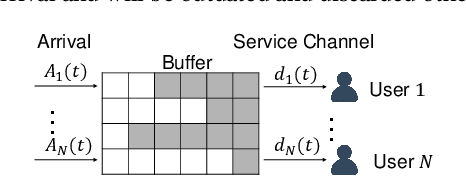
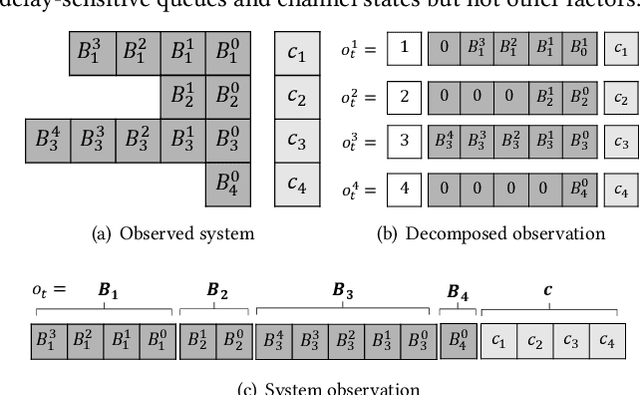
Multi-user delay constrained scheduling is important in many real-world applications including wireless communication, live streaming, and cloud computing. Yet, it poses a critical challenge since the scheduler needs to make real-time decisions to guarantee the delay and resource constraints simultaneously without prior information of system dynamics, which can be time-varying and hard to estimate. Moreover, many practical scenarios suffer from partial observability issues, e.g., due to sensing noise or hidden correlation. To tackle these challenges, we propose a deep reinforcement learning (DRL) algorithm, named Recurrent Softmax Delayed Deep Double Deterministic Policy Gradient ($\mathtt{RSD4}$), which is a data-driven method based on a Partially Observed Markov Decision Process (POMDP) formulation. $\mathtt{RSD4}$ guarantees resource and delay constraints by Lagrangian dual and delay-sensitive queues, respectively. It also efficiently tackles partial observability with a memory mechanism enabled by the recurrent neural network (RNN) and introduces user-level decomposition and node-level merging to ensure scalability. Extensive experiments on simulated/real-world datasets demonstrate that $\mathtt{RSD4}$ is robust to system dynamics and partially observable environments, and achieves superior performances over existing DRL and non-DRL-based methods.
A Realistic 3D Non-Stationary Channel Model for UAV-to-Vehicle Communications Incorporating Fuselage Posture
Sep 19, 2022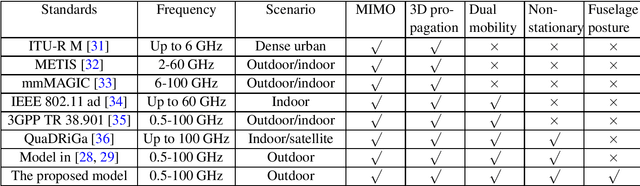
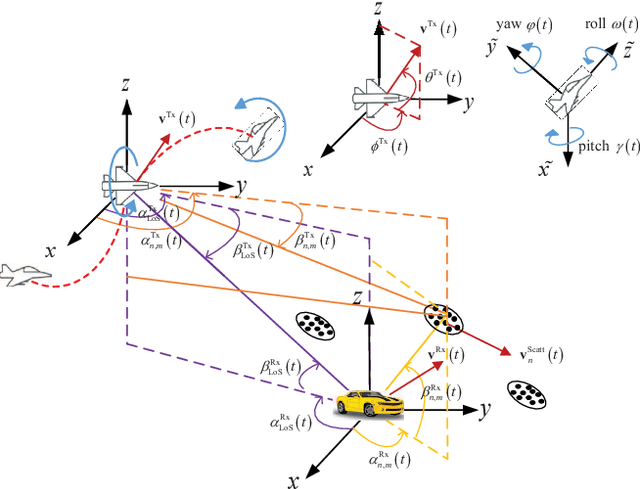
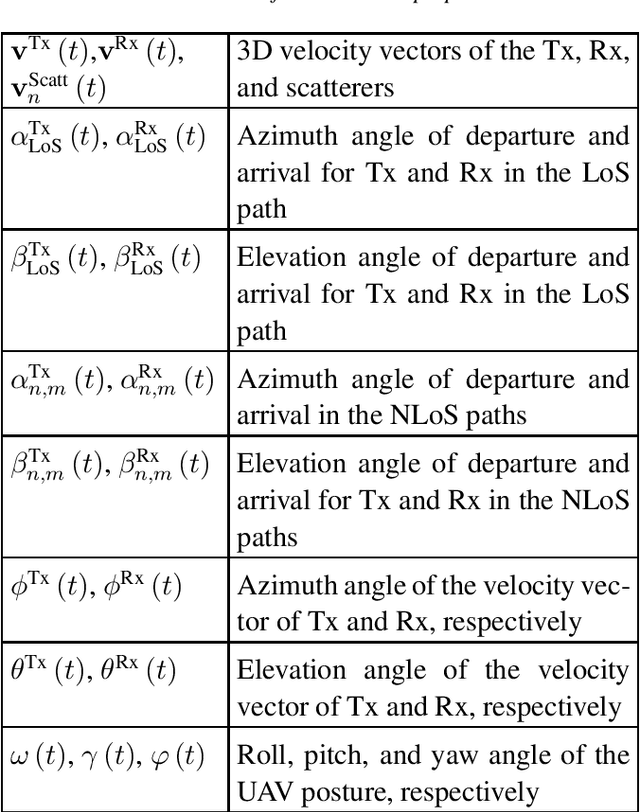
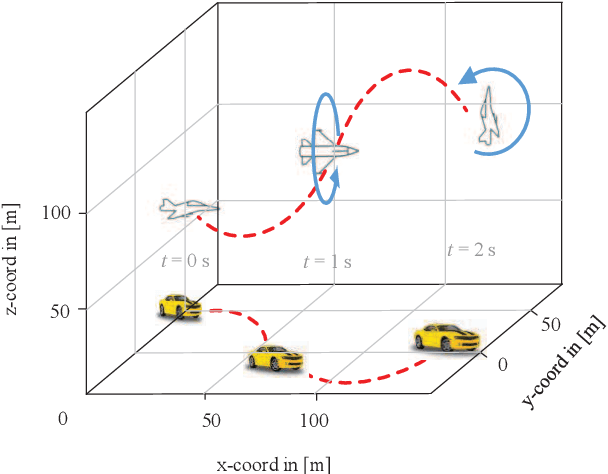
Considering the unmanned aerial vehicle (UAV) three-dimensional (3D) posture, a novel 3D non-stationary geometry-based stochastic model (GBSM) is proposed for multiple-input multiple-output (MIMO) UAV-to-vehicle (U2V) channels. It consists of a line-of-sight (LoS) and non-line-of-sight (NLoS) components. The factor of fuselage posture is considered by introducing a time-variant 3D posture matrix. Some important statistical properties, i.e. the temporal autocorrelation function (ACF) and spatial cross correlation function (CCF), are derived and investigated. Simulation results show that the fuselage posture has significant impact on the U2V channel characteristic and aggravate the non-stationarity. The agreements between analytical, simulated, and measured results verify the correctness of proposed model and derivations. Moreover, it is demonstrated that the proposed model is also compatible to the existing GBSM without considering fuselage posture.
A Deep Neural Networks ensemble workflow from hyperparameter search to inference leveraging GPU clusters
Aug 30, 2022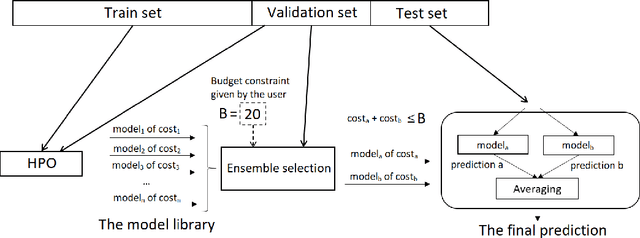

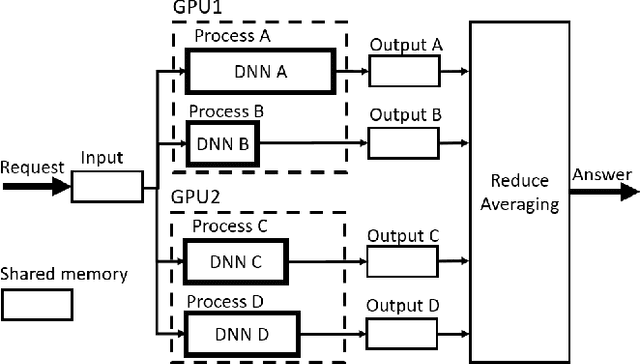
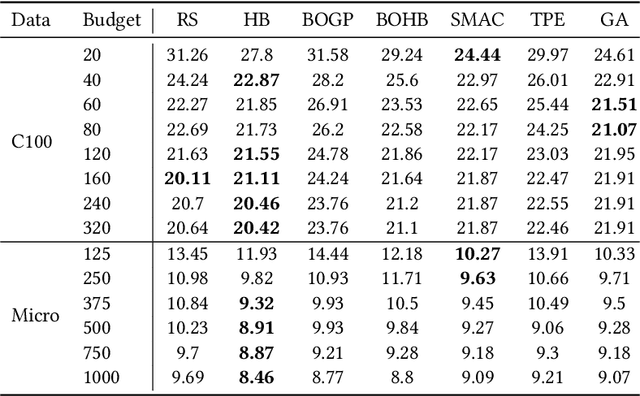
Automated Machine Learning with ensembling (or AutoML with ensembling) seeks to automatically build ensembles of Deep Neural Networks (DNNs) to achieve qualitative predictions. Ensemble of DNNs are well known to avoid over-fitting but they are memory and time consuming approaches. Therefore, an ideal AutoML would produce in one single run time different ensembles regarding accuracy and inference speed. While previous works on AutoML focus to search for the best model to maximize its generalization ability, we rather propose a new AutoML to build a larger library of accurate and diverse individual models to then construct ensembles. First, our extensive benchmarks show asynchronous Hyperband is an efficient and robust way to build a large number of diverse models to combine them. Then, a new ensemble selection method based on a multi-objective greedy algorithm is proposed to generate accurate ensembles by controlling their computing cost. Finally, we propose a novel algorithm to optimize the inference of the DNNs ensemble in a GPU cluster based on allocation optimization. The produced AutoML with ensemble method shows robust results on two datasets using efficiently GPU clusters during both the training phase and the inference phase.
Over-the-Air Federated Learning with Privacy Protection via Correlated Additive Perturbations
Oct 05, 2022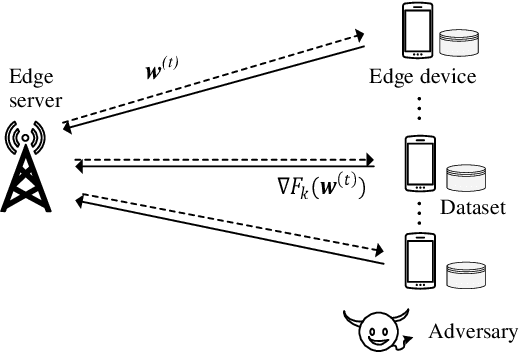
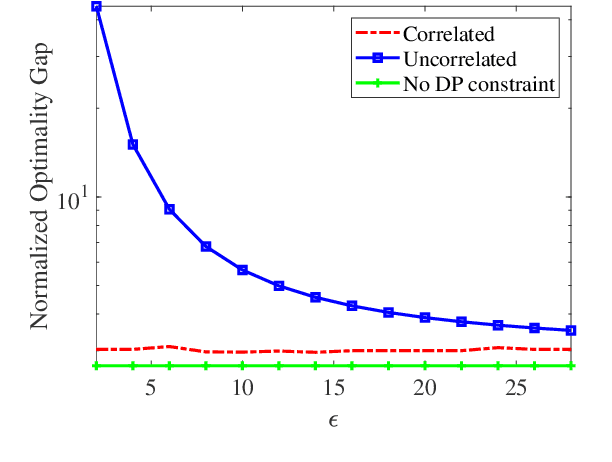
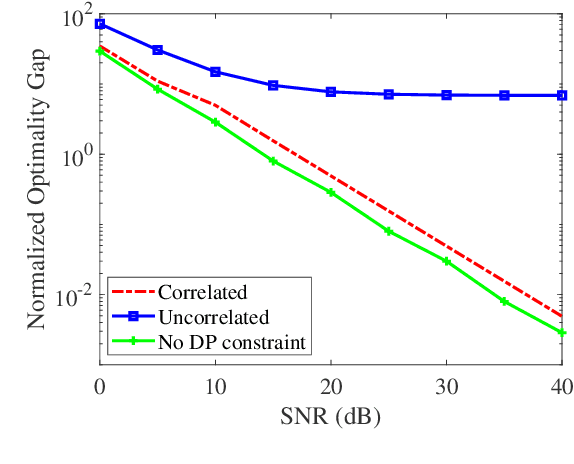
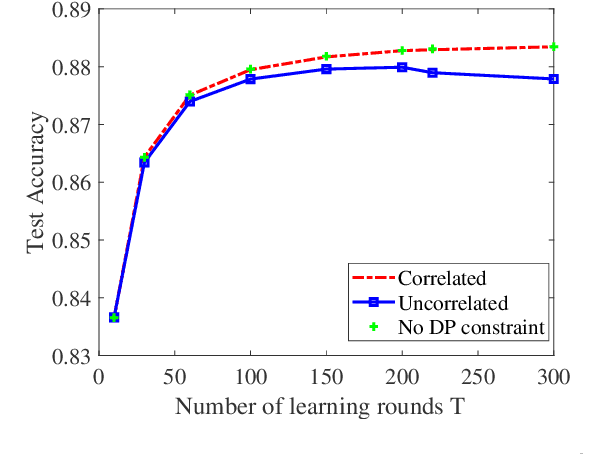
In this paper, we consider privacy aspects of wireless federated learning (FL) with Over-the-Air (OtA) transmission of gradient updates from multiple users/agents to an edge server. By exploiting the waveform superposition property of multiple access channels, OtA FL enables the users to transmit their updates simultaneously with linear processing techniques, which improves resource efficiency. However, this setting is vulnerable to privacy leakage since an adversary node can hear directly the uncoded message. Traditional perturbation-based methods provide privacy protection while sacrificing the training accuracy due to the reduced signal-to-noise ratio. In this work, we aim at minimizing privacy leakage to the adversary and the degradation of model accuracy at the edge server at the same time. More explicitly, spatially correlated perturbations are added to the gradient vectors at the users before transmission. Using the zero-sum property of the correlated perturbations, the side effect of the added perturbation on the aggregated gradients at the edge server can be minimized. In the meanwhile, the added perturbation will not be canceled out at the adversary, which prevents privacy leakage. Theoretical analysis of the perturbation covariance matrix, differential privacy, and model convergence is provided, based on which an optimization problem is formulated to jointly design the covariance matrix and the power scaling factor to balance between privacy protection and convergence performance. Simulation results validate the correlated perturbation approach can provide strong defense ability while guaranteeing high learning accuracy.
Over-the-Air Computation over Balanced Numerals
Sep 22, 2022
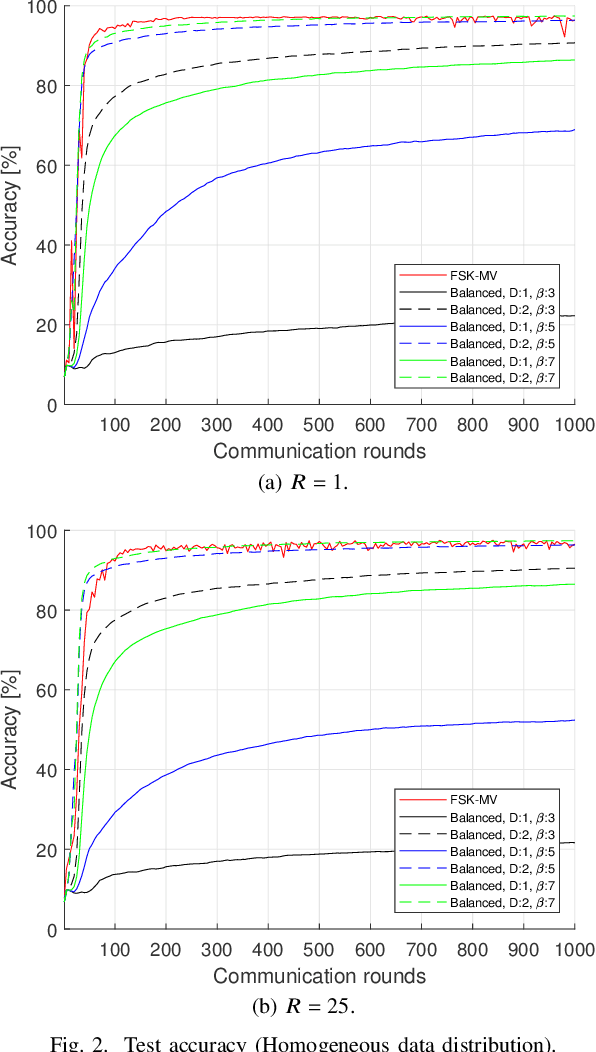
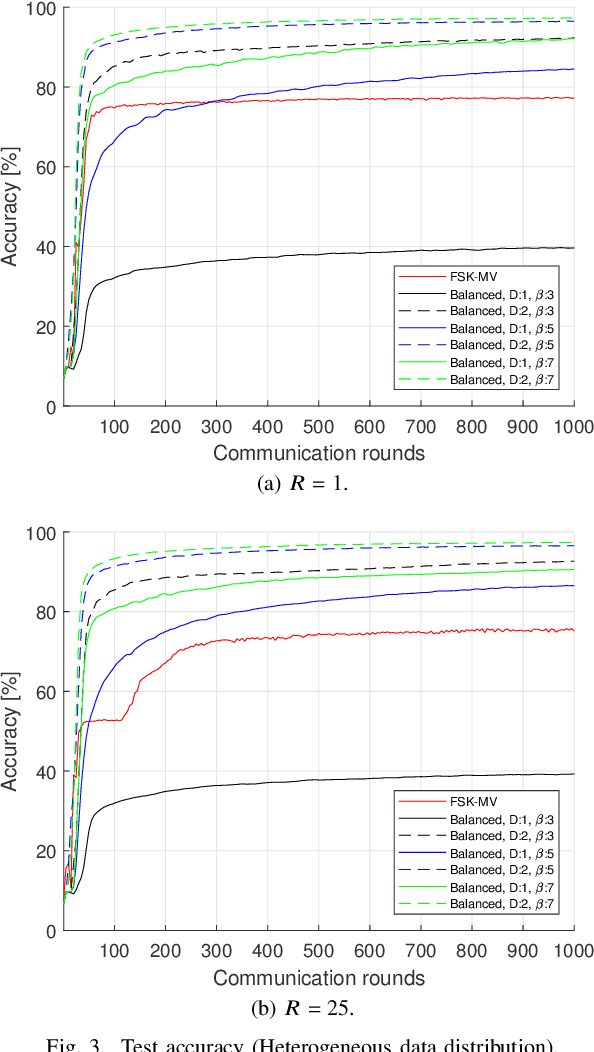
In this study, a digital over-the-air computation (OAC) scheme for achieving continuous-valued gradient aggregation is proposed. It is shown that the average of a set of real-valued parameters can be calculated approximately by using the average of the corresponding numerals, where the numerals are obtained based on a balanced number system. By using this property, the proposed scheme encodes the local gradients into a set of numerals. It then determines the positions of the activated orthogonal frequency division multiplexing (OFDM) subcarriers by using the values of the numerals. To eliminate the need for a precise sample-level time synchronization, channel estimation overhead, and power instabilities due to the channel inversion, the proposed scheme also uses a non-coherent receiver at the edge server (ES) and does not utilize a pre-equalization at the edge devices (EDs). Finally, the theoretical mean squared error (MSE) performance of the proposed scheme is derived and its performance for federated edge learning (FEEL) is demonstrated.