 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data-Driven Machine Learning Models for a Multi-Objective Flapping Fin Unmanned Underwater Vehicle Control System
Sep 14, 2022
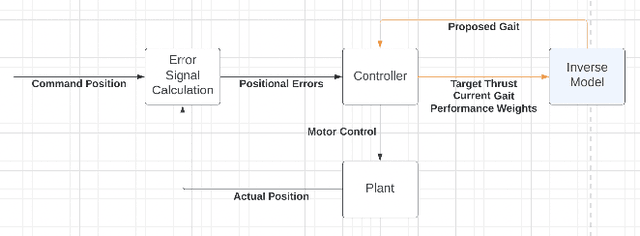

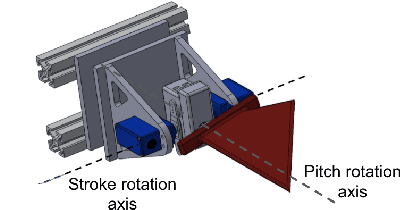
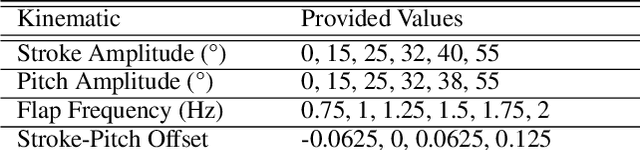
Flapping-fin unmanned underwater vehicle (UUV) propulsion systems provide high maneuverability for naval tasks such as surveillance and terrain exploration. Recent work has explored the use of time-series neural network surrogate models to predict thrust from vehicle design and fin kinematics. We develop a search-based inverse model that leverages a kinematics-to-thrust neural network model for control system design. Our inverse model finds a set of fin kinematics with the multi-objective goal of reaching a target thrust and creating a smooth kinematic transition between flapping cycles. We demonstrate how a control system integrating this inverse model can make online, cycle-to-cycle adjustments to prioritize different system objectives.
Detection and hypothesis testing of features in extremely noisy image series using topological data analysis, with applications to nanoparticle videos
Sep 28, 2022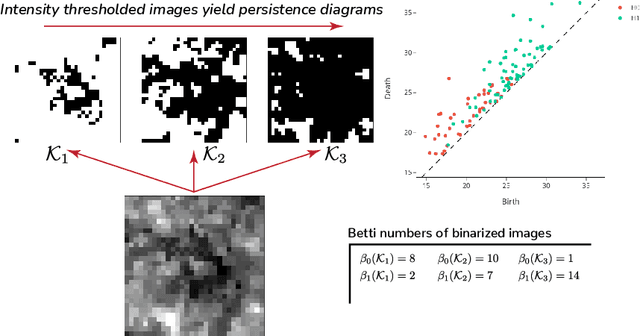
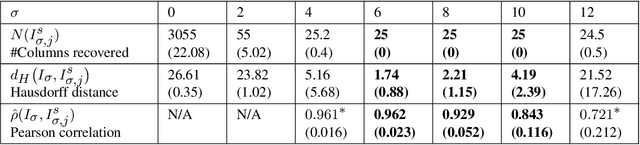
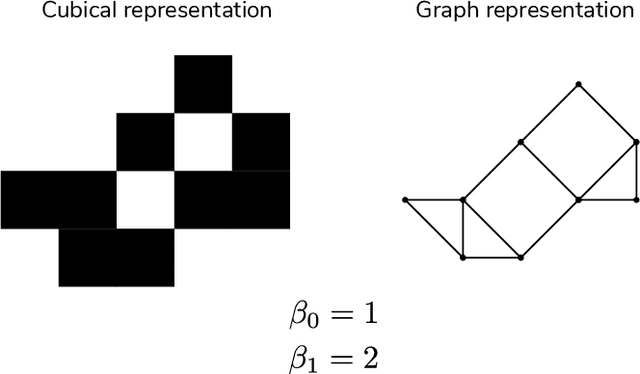

We propose a flexible approach for the detection of features in images with ultra low signal-to-noise ratio using cubical persistent homology. Our main application is in the detection of atomic columns and other features in transmission electron microscopy (TEM) images. Cubical persistent homology is used to identify local minima in subregions in the frames of nanoparticle videos, which are hypothesized to correspond to relevant atomic features. We compare the performance of our algorithm to other employed methods for the detection of columns and their intensity. Additionally, Monte Carlo goodness-of-fit testing using real-valued summaries of persistence diagrams$\unicode{8212}$including the novel ALPS statistic$\unicode{8212}$derived from smoothed images (generated from pixels residing in the vacuum region of an image) is developed and employed to identify whether or not the proposed atomic features generated by our algorithm are due to noise. Using these summaries derived from the generated persistence diagrams, one can produce univariate time series for the nanoparticle videos, thus providing a means for assessing fluxional behavior. A guarantee on the false discovery rate for multiple Monte Carlo testing of identical hypotheses is also established.
Analysis of Distributed Deep Learning in the Cloud
Aug 30, 2022We aim to resolve this problem by introducing a comprehensive distributed deep learning (DDL) profiler, which can determine the various execution "stalls" that DDL suffers from while running on a public cloud. We have implemented the profiler by extending prior work to additionally estimate two types of communication stalls - interconnect and network stalls. We train popular DNN models using the profiler to characterize various AWS GPU instances and list their advantages and shortcomings for users to make an informed decision. We observe that the more expensive GPU instances may not be the most performant for all DNN models and AWS may sub-optimally allocate hardware interconnect resources. Specifically, the intra-machine interconnect can introduce communication overheads up to 90% of DNN training time and network-connected instances can suffer from up to 5x slowdown compared to training on a single instance. Further, we model the impact of DNN macroscopic features such as the number of layers and the number of gradients on communication stalls. Finally, we propose a measurement-based recommendation model for users to lower their public cloud monetary costs for DDL, given a time budget.
Learning Filter-Based Compressed Blind-Deconvolution
Sep 28, 2022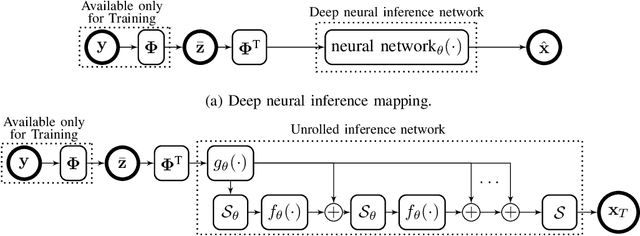
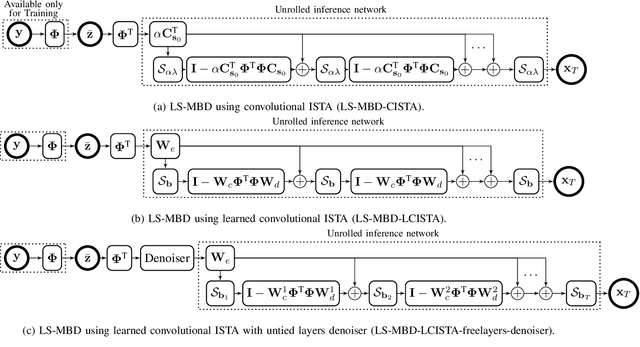
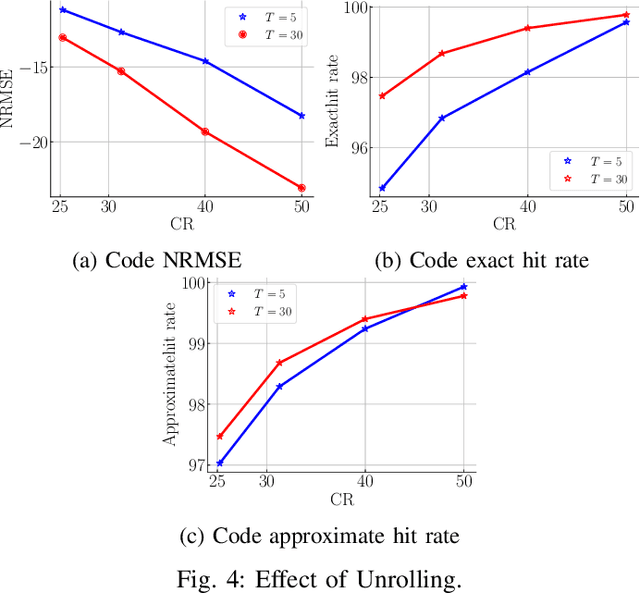
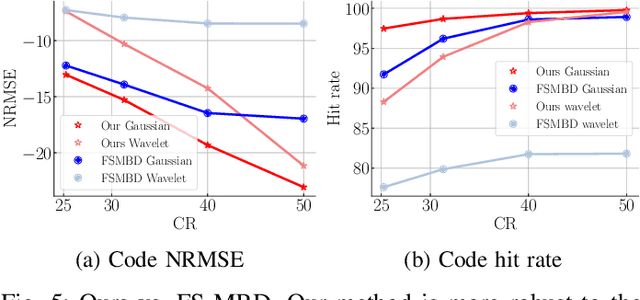
The problem of sparse multichannel blind deconvolution (S-MBD) arises frequently in many engineering applications such as radar/sonar/ultrasound imaging. To reduce its computational and implementation cost, we propose a compression method that enables blind recovery from much fewer measurements with respect to the full received signal in time. The proposed compression measures the signal through a filter followed by a subsampling, allowing for a significant reduction in implementation cost. We derive theoretical guarantees for the identifiability and recovery of a sparse filter from compressed measurements. Our results allow for the design of a wide class of compression filters. We, then, propose a data-driven unrolled learning framework to learn the compression filter and solve the S-MBD problem. The encoder is a recurrent inference network that maps compressed measurements into an estimate of sparse filters. We demonstrate that our unrolled learning method is more robust to choices of source shapes and has better recovery performance compared to optimization-based methods. Finally, in applications with limited data (fewshot learning), we highlight the superior generalization capability of unrolled learning compared to conventional deep learning.
Automatic Analysis of Available Source Code of Top Artificial Intelligence Conference Papers
Sep 28, 2022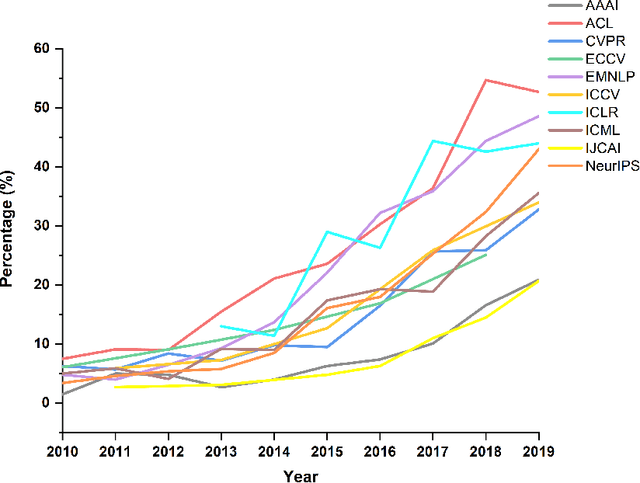
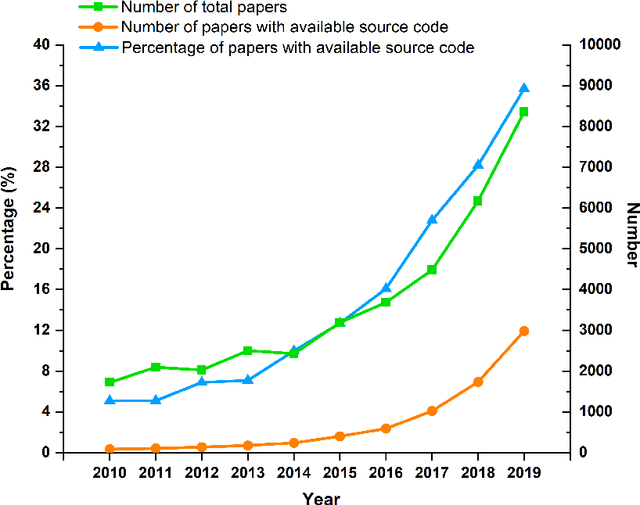


Source code is essential for researchers to reproduce the methods and replicate the results of artificial intelligence (AI) papers. Some organizations and researchers manually collect AI papers with available source code to contribute to the AI community. However, manual collection is a labor-intensive and time-consuming task. To address this issue, we propose a method to automatically identify papers with available source code and extract their source code repository URLs. With this method, we find that 20.5% of regular papers of 10 top AI conferences published from 2010 to 2019 are identified as papers with available source code and that 8.1% of these source code repositories are no longer accessible. We also create the XMU NLP Lab README Dataset, the largest dataset of labeled README files for source code document research. Through this dataset, we have discovered that quite a few README files have no installation instructions or usage tutorials provided. Further, a large-scale comprehensive statistical analysis is made for a general picture of the source code of AI conference papers. The proposed solution can also go beyond AI conference papers to analyze other scientific papers from both journals and conferences to shed light on more domains.
* Please cite the version of IJSEKE
Inducing Early Neural Collapse in Deep Neural Networks for Improved Out-of-Distribution Detection
Sep 17, 2022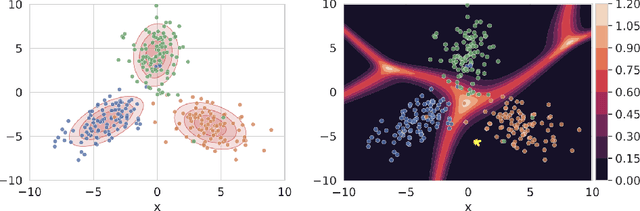
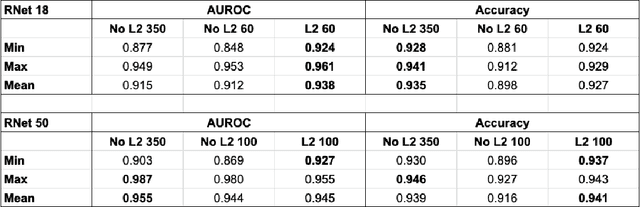
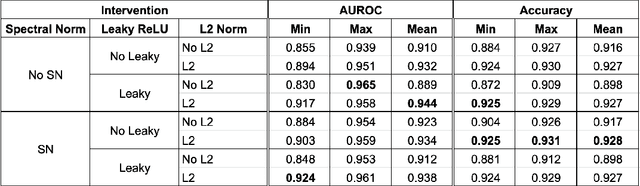
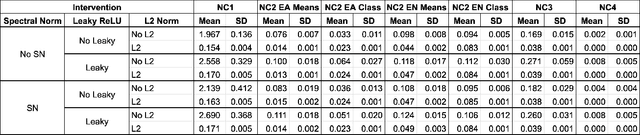
We propose a simple modification to standard ResNet architectures--L2 regularization over feature space--that substantially improves out-of-distribution (OoD) performance on the previously proposed Deep Deterministic Uncertainty (DDU) benchmark. This change also induces early Neural Collapse (NC), which we show is an effect under which better OoD performance is more probable. Our method achieves comparable or superior OoD detection scores and classification accuracy in a small fraction of the training time of the benchmark. Additionally, it substantially improves worst case OoD performance over multiple, randomly initialized models. Though we do not suggest that NC is the sole mechanism or comprehensive explanation for OoD behaviour in deep neural networks (DNN), we believe NC's simple mathematical and geometric structure can provide an framework for analysis of this complex phenomenon in future work.
Recipro-CAM: Gradient-free reciprocal class activation map
Sep 28, 2022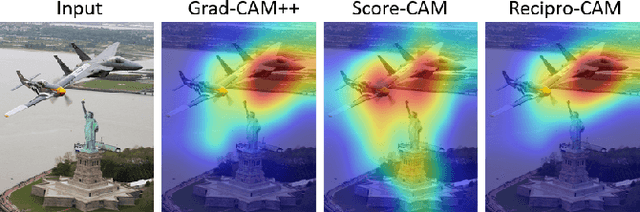
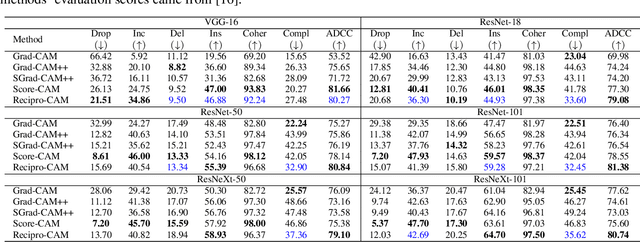
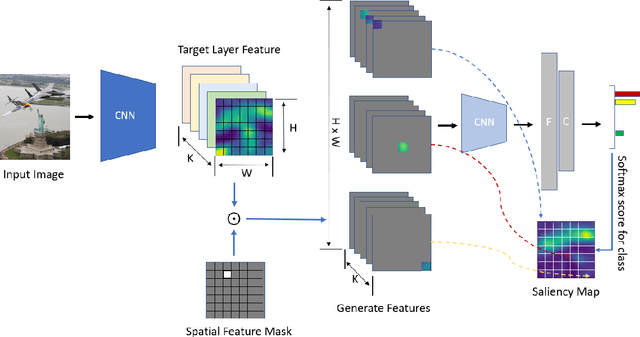
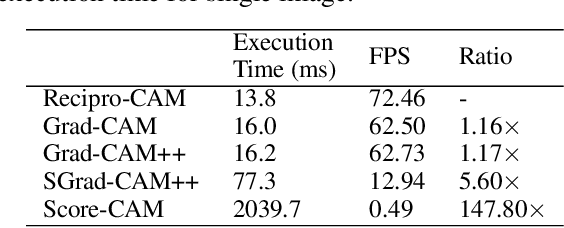
Convolutional neural network (CNN) becomes one of the most popular and prominent deep learning architectures for computer vision, but its black box feature hides the internal prediction process. For this reason, AI practitioners have shed light on explainable AI to provide the interpretability of the model behavior. In particular, class activation map (CAM) and Grad-CAM based methods have shown promise results, but they have architectural limitation or gradient computing burden. To resolve these, Score-CAM has been suggested as a gradient-free method, however, it requires more execution time compared to CAM or Grad-CAM based methods. Therefore, we propose a lightweight architecture and gradient free Reciprocal CAM (Recipro-CAM) by spatially masking the extracted feature maps to exploit the correlation between activation maps and network outputs. With the proposed method, we achieved the gains of 1:78 - 3:72% in the ResNet family compared to Score-CAM in Average Drop- Coherence-Complexity (ADCC) metric, excluding the VGG-16 (1:39% drop). In addition, Recipro-CAM exhibits a saliency map generation rate similar to Grad-CAM and approximately 148 times faster than Score-CAM.
Monitoring ROS2: from Requirements to Autonomous Robots
Sep 28, 2022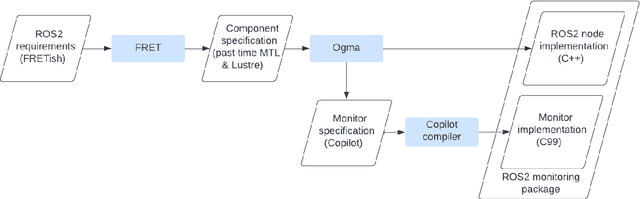
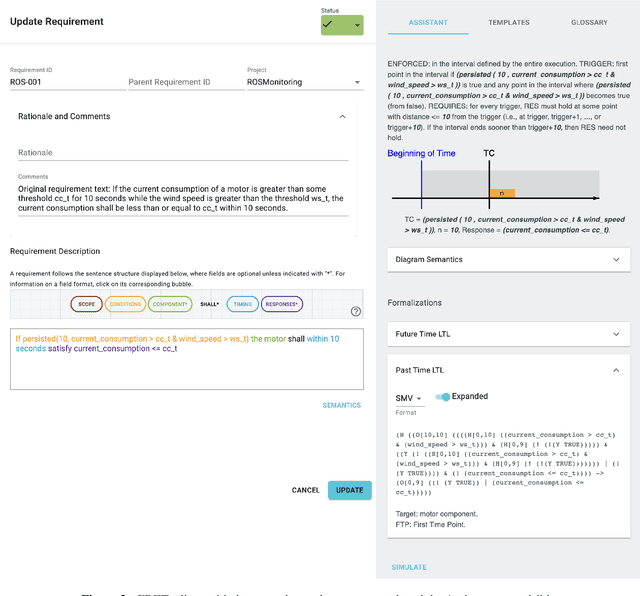

Runtime verification (RV) has the potential to enable the safe operation of safety-critical systems that are too complex to formally verify, such as Robot Operating System 2 (ROS2) applications. Writing correct monitors can itself be complex, and errors in the monitoring subsystem threaten the mission as a whole. This paper provides an overview of a formal approach to generating runtime monitors for autonomous robots from requirements written in a structured natural language. Our approach integrates the Formal Requirement Elicitation Tool (FRET) with Copilot, a runtime verification framework, through the Ogma integration tool. FRET is used to specify requirements with unambiguous semantics, which are then automatically translated into temporal logic formulae. Ogma generates monitor specifications from the FRET output, which are compiled into hard-real time C99. To facilitate integration of the monitors in ROS2, we have extended Ogma to generate ROS2 packages defining monitoring nodes, which run the monitors when new data becomes available, and publish the results of any violations. The goal of our approach is to treat the generated ROS2 packages as black boxes and integrate them into larger ROS2 systems with minimal effort.
* In Proceedings FMAS2022 ASYDE2022, arXiv:2209.13181
Time Series Forecasting with Ensembled Stochastic Differential Equations Driven by Lévy Noise
Nov 25, 2021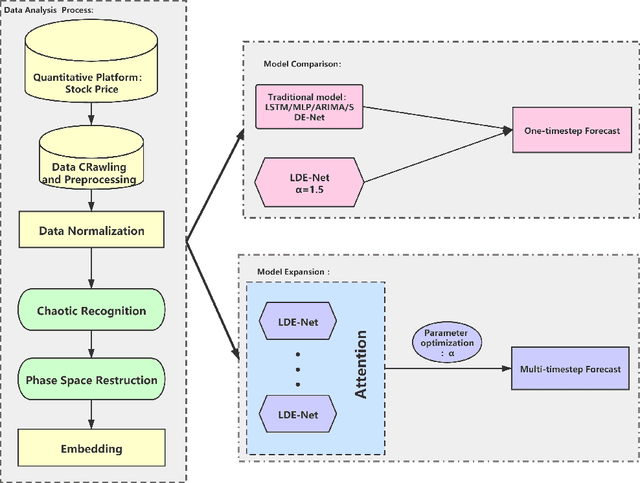

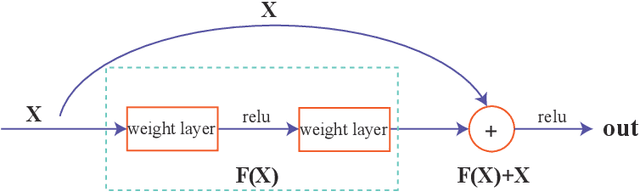
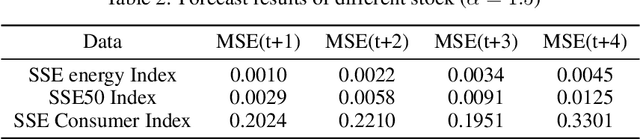
With the fast development of modern deep learning techniques, the study of dynamic systems and neural networks is increasingly benefiting each other in a lot of different ways. Since uncertainties often arise in real world observations, SDEs (stochastic differential equations) come to play an important role. To be more specific, in this paper, we use a collection of SDEs equipped with neural networks to predict long-term trend of noisy time series which has big jump properties and high probability distribution shift. Our contributions are, first, we use the phase space reconstruction method to extract intrinsic dimension of the time series data so as to determine the input structure for our forecasting model. Second, we explore SDEs driven by $\alpha$-stable L\'evy motion to model the time series data and solve the problem through neural network approximation. Third, we construct the attention mechanism to achieve multi-time step prediction. Finally, we illustrate our method by applying it to stock marketing time series prediction and show the results outperform several baseline deep learning models.
This is what a pandemic looks like: Visual framing of COVID-19 on search engines
Sep 22, 2022
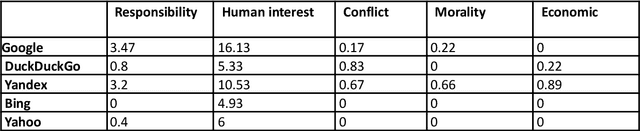
In today's high-choice media environment, search engines play an integral role in informing individuals and societies about the latest events. The importance of search algorithms is even higher at the time of crisis, when users search for information to understand the causes and the consequences of the current situation and decide on their course of action. In our paper, we conduct a comparative audit of how different search engines prioritize visual information related to COVID-19 and what consequences it has for the representation of the pandemic. Using a virtual agent-based audit approach, we examine image search results for the term "coronavirus" in English, Russian and Chinese on five major search engines: Google, Yandex, Bing, Yahoo, and DuckDuckGo. Specifically, we focus on how image search results relate to generic news frames (e.g., the attribution of responsibility, human interest, and economics) used in relation to COVID-19 and how their visual composition varies between the search engines.