 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cross-Modality Domain Adaptation for Freespace Detection: A Simple yet Effective Baseline
Oct 06, 2022
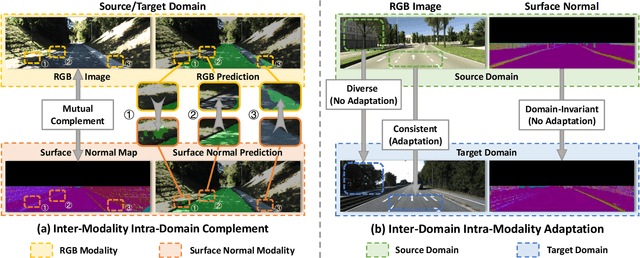
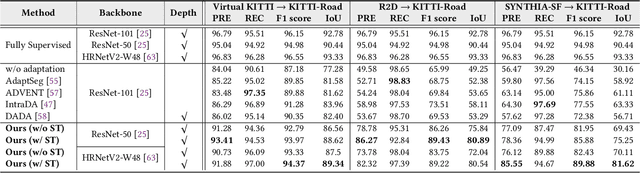
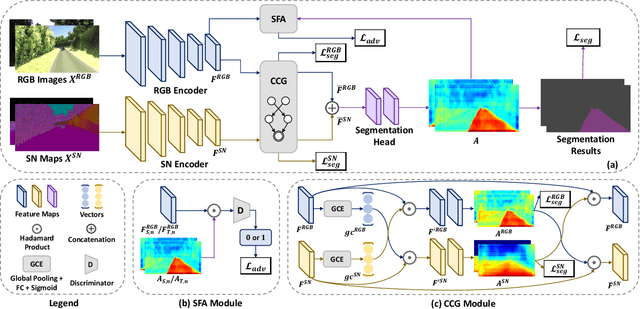
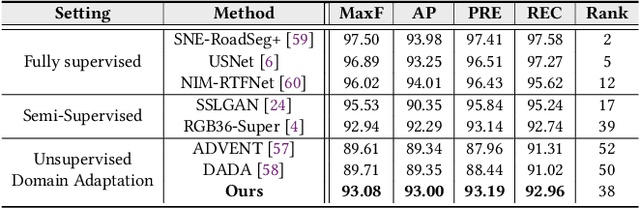
As one of the fundamental functions of autonomous driving system, freespace detection aims at classifying each pixel of the image captured by the camera as drivable or non-drivable. Current works of freespace detection heavily rely on large amount of densely labeled training data for accuracy and robustness, which is time-consuming and laborious to collect and annotate. To the best of our knowledge, we are the first work to explore unsupervised domain adaptation for freespace detection to alleviate the data limitation problem with synthetic data. We develop a cross-modality domain adaptation framework which exploits both RGB images and surface normal maps generated from depth images. A Collaborative Cross Guidance (CCG) module is proposed to leverage the context information of one modality to guide the other modality in a cross manner, thus realizing inter-modality intra-domain complement. To better bridge the domain gap between source domain (synthetic data) and target domain (real-world data), we also propose a Selective Feature Alignment (SFA) module which only aligns the features of consistent foreground area between the two domains, thus realizing inter-domain intra-modality adaptation. Extensive experiments are conducted by adapting three different synthetic datasets to one real-world dataset for freespace detection respectively. Our method performs closely to fully supervised freespace detection methods (93.08 v.s. 97.50 F1 score) and outperforms other general unsupervised domain adaptation methods for semantic segmentation with large margins, which shows the promising potential of domain adaptation for freespace detection.
On the Complexity of Finding Small Subgradients in Nonsmooth Optimization
Sep 21, 2022
We study the oracle complexity of producing $(\delta,\epsilon)$-stationary points of Lipschitz functions, in the sense proposed by Zhang et al. [2020]. While there exist dimension-free randomized algorithms for producing such points within $\widetilde{O}(1/\delta\epsilon^3)$ first-order oracle calls, we show that no dimension-free rate can be achieved by a deterministic algorithm. On the other hand, we point out that this rate can be derandomized for smooth functions with merely a logarithmic dependence on the smoothness parameter. Moreover, we establish several lower bounds for this task which hold for any randomized algorithm, with or without convexity. Finally, we show how the convergence rate of finding $(\delta,\epsilon)$-stationary points can be improved in case the function is convex, a setting which we motivate by proving that in general no finite time algorithm can produce points with small subgradients even for convex functions.
Personalized Emotion Detection using IoT and Machine Learning
Sep 14, 2022
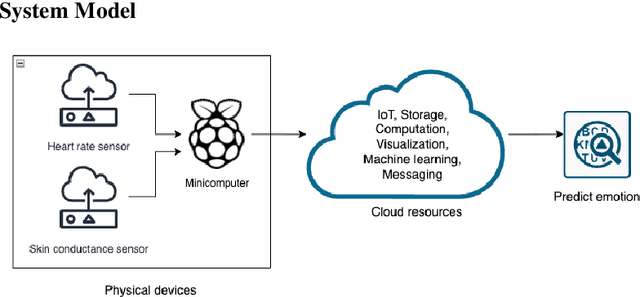


The Medical Internet of Things, a recent technological advancement in medicine, is incredibly helpful in providing real-time monitoring of health metrics. This paper presents a non-invasive IoT system that tracks patients' emotions, especially those with autism spectrum disorder. With a few affordable sensors and cloud computing services, the individual's heart rates are monitored and analyzed to study the effects of changes in sweat and heartbeats per minute for different emotions. Under normal resting conditions of the individual, the proposed system could detect the right emotion using machine learning algorithms with a performance of up to 92% accuracy. The result of the proposed approach is comparable with the state-of-the-art solutions in medical IoT.
A Novel Enhanced Convolution Neural Network with Extreme Learning Machine: Facial Emotional Recognition in Psychology Practices
Aug 05, 2022Facial emotional recognition is one of the essential tools used by recognition psychology to diagnose patients. Face and facial emotional recognition are areas where machine learning is excelling. Facial Emotion Recognition in an unconstrained environment is an open challenge for digital image processing due to different environments, such as lighting conditions, pose variation, yaw motion, and occlusions. Deep learning approaches have shown significant improvements in image recognition. However, accuracy and time still need improvements. This research aims to improve facial emotion recognition accuracy during the training session and reduce processing time using a modified Convolution Neural Network Enhanced with Extreme Learning Machine (CNNEELM). The system entails (CNNEELM) improving the accuracy in image registration during the training session. Furthermore, the system recognizes six facial emotions happy, sad, disgust, fear, surprise, and neutral with the proposed CNNEELM model. The study shows that the overall facial emotion recognition accuracy is improved by 2% than the state of art solutions with a modified Stochastic Gradient Descent (SGD) technique. With the Extreme Learning Machine (ELM) classifier, the processing time is brought down to 65ms from 113ms, which can smoothly classify each frame from a video clip at 20fps. With the pre-trained InceptionV3 model, the proposed CNNEELM model is trained with JAFFE, CK+, and FER2013 expression datasets. The simulation results show significant improvements in accuracy and processing time, making the model suitable for the video analysis process. Besides, the study solves the issue of the large processing time required to process the facial images.
* 19 pages
Semantic Segmentation of Vegetation in Remote Sensing Imagery Using Deep Learning
Sep 28, 2022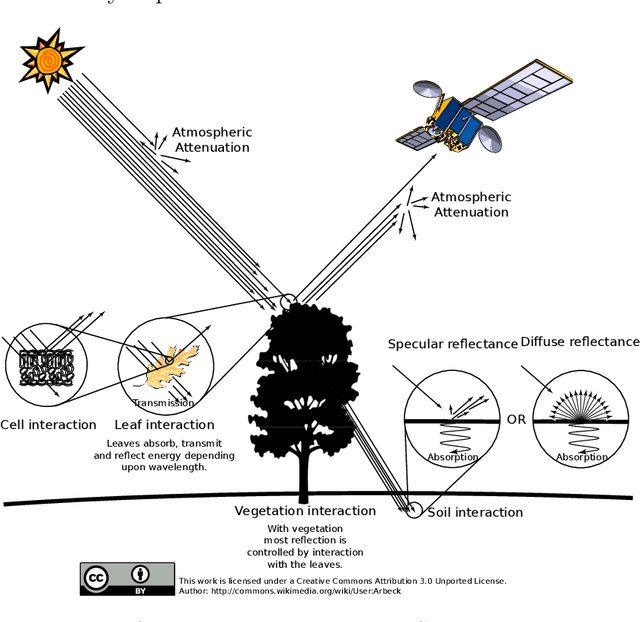
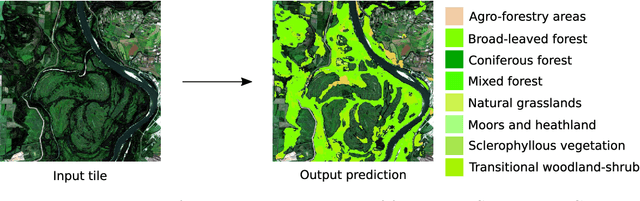
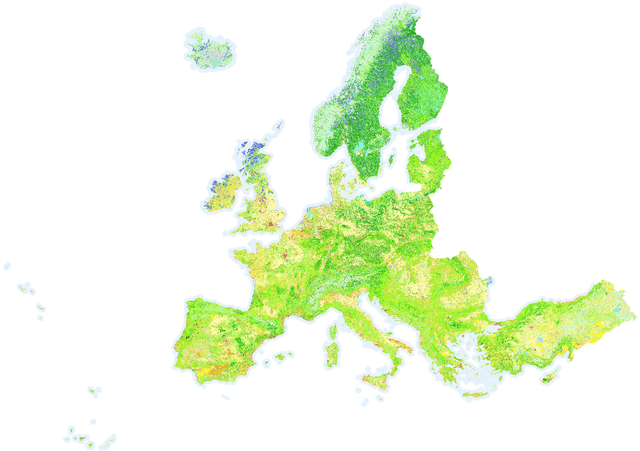
In recent years, the geospatial industry has been developing at a steady pace. This growth implies the addition of satellite constellations that produce a copious supply of satellite imagery and other Remote Sensing data on a daily basis. Sometimes, this information, even if in some cases we are referring to publicly available data, it sits unaccounted for due to the sheer size of it. Processing such large amounts of data with the help of human labour or by using traditional automation methods is not always a viable solution from the standpoint of both time and other resources. Within the present work, we propose an approach for creating a multi-modal and spatio-temporal dataset comprised of publicly available Remote Sensing data and testing for feasibility using state of the art Machine Learning (ML) techniques. Precisely, the usage of Convolutional Neural Networks (CNN) models that are capable of separating different classes of vegetation that are present in the proposed dataset. Popularity and success of similar methods in the context of Geographical Information Systems (GIS) and Computer Vision (CV) more generally indicate that methods alike should be taken in consideration and further analysed and developed.
NasHD: Efficient ViT Architecture Performance Ranking using Hyperdimensional Computing
Sep 23, 2022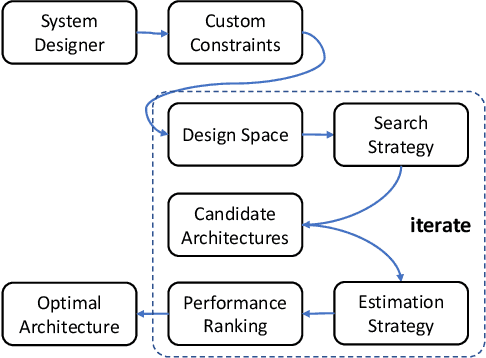
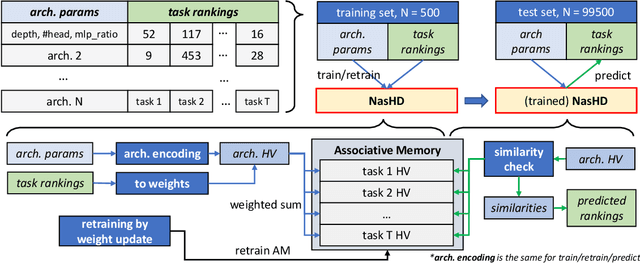
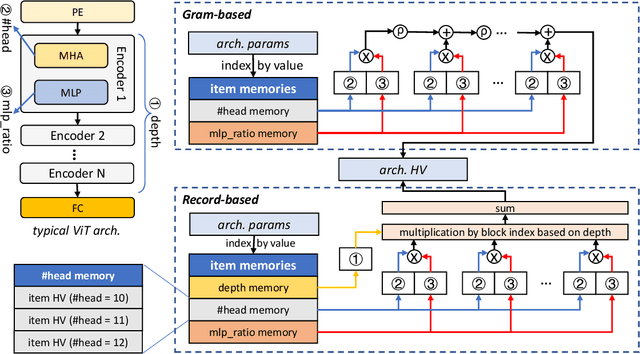
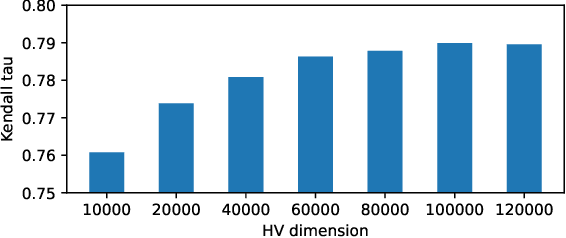
Neural Architecture Search (NAS) is an automated architecture engineering method for deep learning design automation, which serves as an alternative to the manual and error-prone process of model development, selection, evaluation and performance estimation. However, one major obstacle of NAS is the extremely demanding computation resource requirements and time-consuming iterations particularly when the dataset scales. In this paper, targeting at the emerging vision transformer (ViT), we present NasHD, a hyperdimensional computing based supervised learning model to rank the performance given the architectures and configurations. Different from other learning based methods, NasHD is faster thanks to the high parallel processing of HDC architecture. We also evaluated two HDC encoding schemes: Gram-based and Record-based of NasHD on their performance and efficiency. On the VIMER-UFO benchmark dataset of 8 applications from a diverse range of domains, NasHD Record can rank the performance of nearly 100K vision transformer models with about 1 minute while still achieving comparable results with sophisticated models.
Smells like Teen Spirit: An Exploration of Sensorial Style in Literary Genres
Sep 26, 2022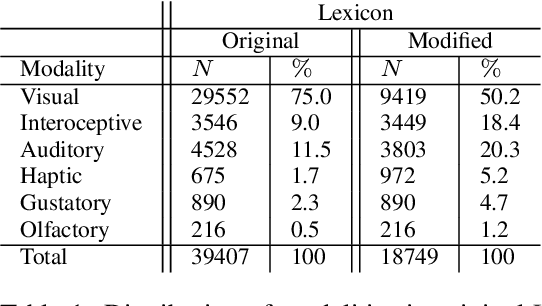
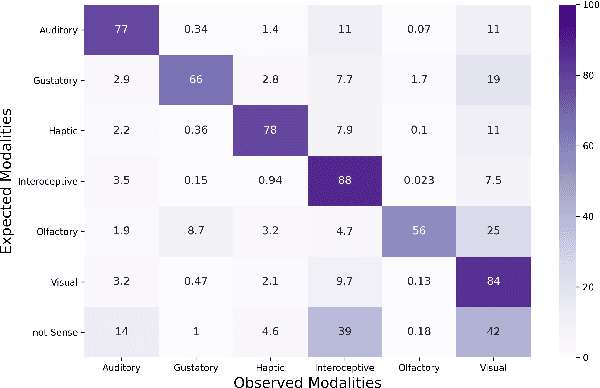
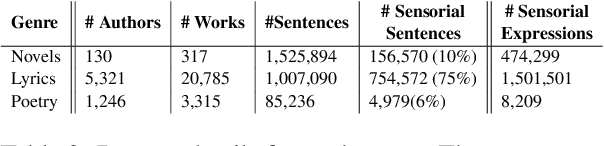
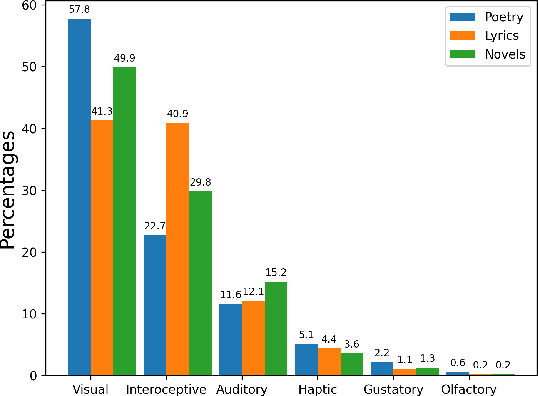
It is well recognized that sensory perceptions and language have interconnections through numerous studies in psychology, neuroscience, and sensorial linguistics. Set in this rich context we ask whether the use of sensorial language in writings is part of linguistic style? This question is important from the view of stylometrics research where a rich set of language features have been explored, but with insufficient attention given to features related to sensorial language. Taking this as the goal we explore several angles about sensorial language and style in collections of lyrics, novels, and poetry. We find, for example, that individual use of sensorial language is not a random phenomenon; choice is likely involved. Also, sensorial style is generally stable over time - the shifts are extremely small. Moreover, style can be extracted from just a few hundred sentences that have sensorial terms. We also identify representative and distinctive features within each genre. For example, we observe that 4 of the top 6 representative features in novels collection involved individuals using olfactory language where we expected them to use non-olfactory language.
MaxWeight With Discounted UCB: A Provably Stable Scheduling Policy for Nonstationary Multi-Server Systems With Unknown Statistics
Sep 02, 2022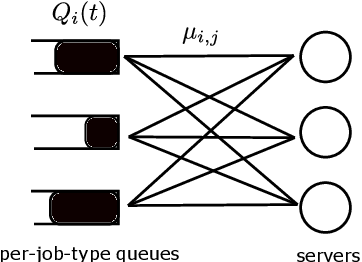
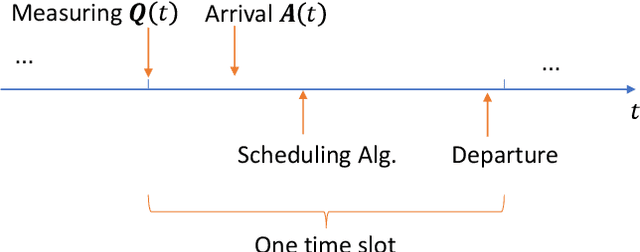
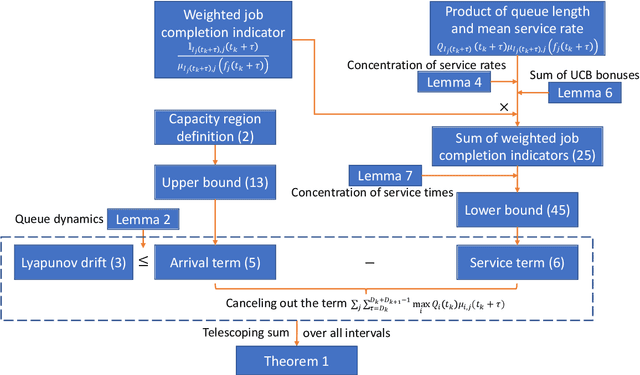
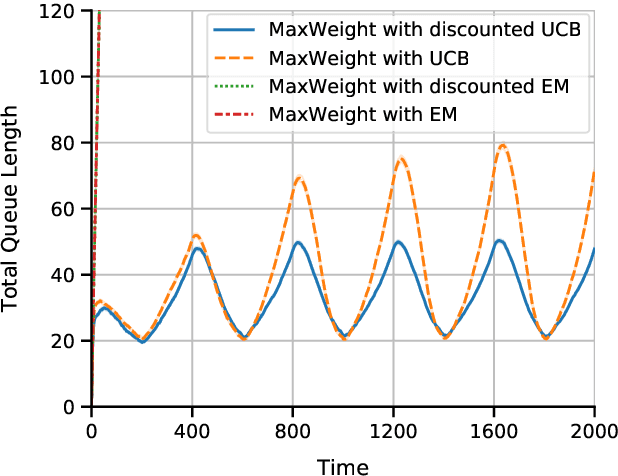
Multi-server queueing systems are widely used models for job scheduling in machine learning, wireless networks, and crowdsourcing. This paper considers a multi-server system with multiple servers and multiple types of jobs. The system maintains a separate queue for each type of jobs. For each time slot, each available server picks a job from a queue and then serves the job until it is complete. The arrival rates of the queues and the mean service times are unknown and even nonstationary. We propose the MaxWeight with discounted upper confidence bound (UCB) algorithm, which simultaneously learns the statistics and schedules jobs to servers. We prove that the proposed algorithm can stabilize the queues when the arrival rates are strictly within the service capacity region. Specifically, we prove that the queue lengths are bounded in the mean under the assumption that the mean service times change relatively slowly over time and the arrival rates are bounded away from the capacity region by a constant whose value depends on the discount factor used in the discounted UCB. Simulation results confirm that the proposed algorithm can stabilize the queues and that it outperforms MaxWeight with empirical mean and MaxWeight with discounted empirical mean. The proposed algorithm is also better than MaxWeight with UCB in the nonstationary setting.
Lead-lag detection and network clustering for multivariate time series with an application to the US equity market
Jan 20, 2022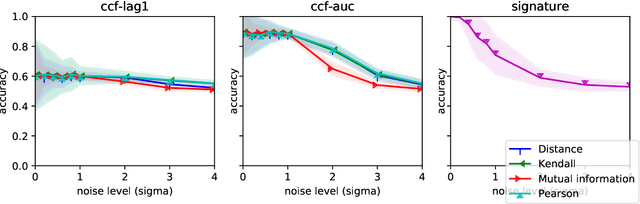
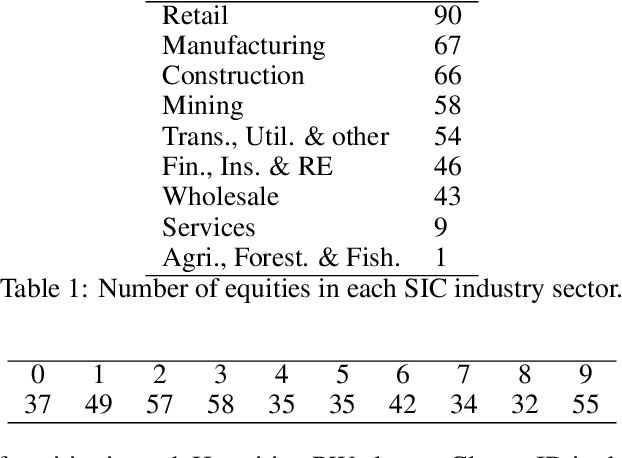
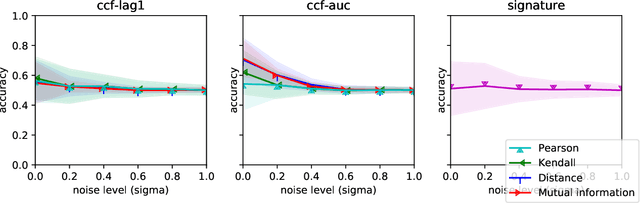
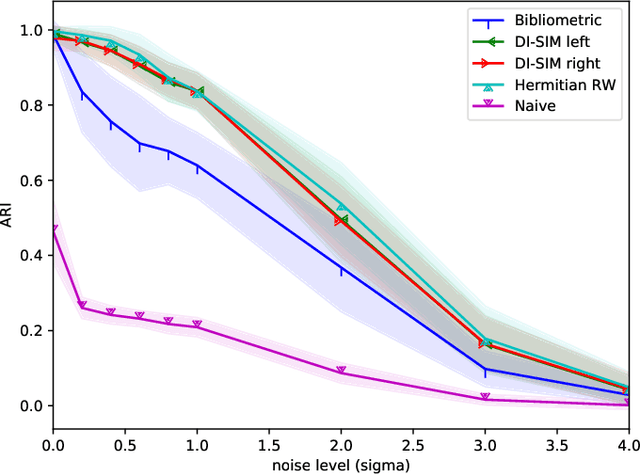
In multivariate time series systems, it has been observed that certain groups of variables partially lead the evolution of the system, while other variables follow this evolution with a time delay; the result is a lead-lag structure amongst the time series variables. In this paper, we propose a method for the detection of lead-lag clusters of time series in multivariate systems. We demonstrate that the web of pairwise lead-lag relationships between time series can be helpfully construed as a directed network, for which there exist suitable algorithms for the detection of pairs of lead-lag clusters with high pairwise imbalance. Within our framework, we consider a number of choices for the pairwise lead-lag metric and directed network clustering components. Our framework is validated on both a synthetic generative model for multivariate lead-lag time series systems and daily real-world US equity prices data. We showcase that our method is able to detect statistically significant lead-lag clusters in the US equity market. We study the nature of these clusters in the context of the empirical finance literature on lead-lag relations and demonstrate how these can be used for the construction of predictive financial signals.
Detection and hypothesis testing of features in extremely noisy image series using topological data analysis, with applications to nanoparticle videos
Sep 28, 2022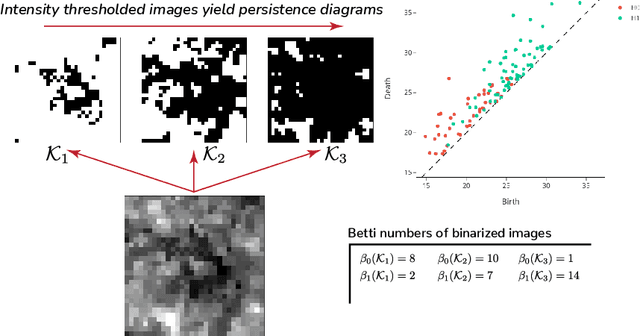
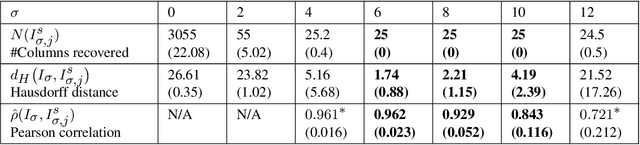
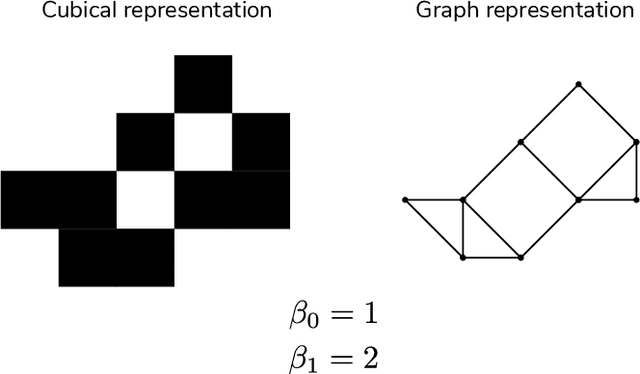

We propose a flexible approach for the detection of features in images with ultra low signal-to-noise ratio using cubical persistent homology. Our main application is in the detection of atomic columns and other features in transmission electron microscopy (TEM) images. Cubical persistent homology is used to identify local minima in subregions in the frames of nanoparticle videos, which are hypothesized to correspond to relevant atomic features. We compare the performance of our algorithm to other employed methods for the detection of columns and their intensity. Additionally, Monte Carlo goodness-of-fit testing using real-valued summaries of persistence diagrams$\unicode{8212}$including the novel ALPS statistic$\unicode{8212}$derived from smoothed images (generated from pixels residing in the vacuum region of an image) is developed and employed to identify whether or not the proposed atomic features generated by our algorithm are due to noise. Using these summaries derived from the generated persistence diagrams, one can produce univariate time series for the nanoparticle videos, thus providing a means for assessing fluxional behavior. A guarantee on the false discovery rate for multiple Monte Carlo testing of identical hypotheses is also established.