 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Risk-Aware Model Predictive Path Integral Control Using Conditional Value-at-Risk
Sep 26, 2022
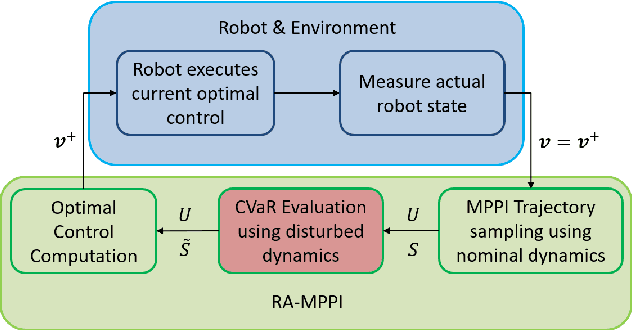
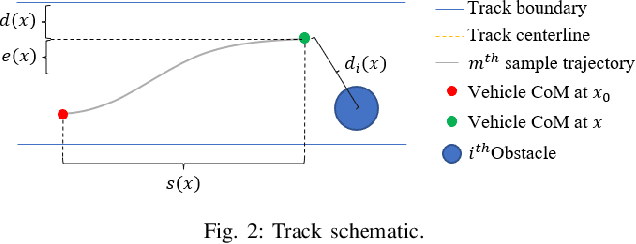
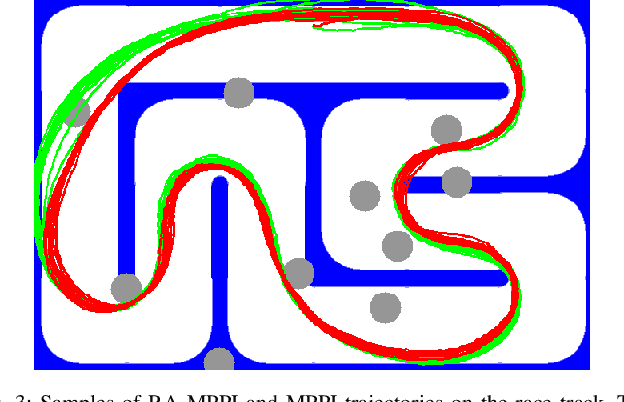
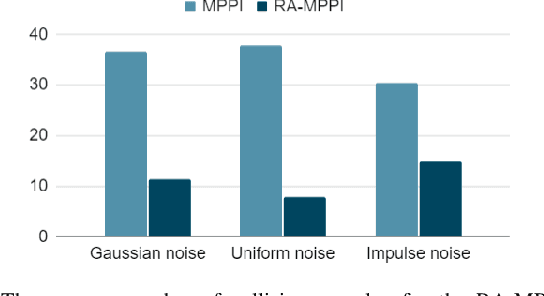
In this paper, we present a novel Model Predictive Control method for autonomous robots subject to arbitrary forms of uncertainty. The proposed Risk-Aware Model Predictive Path Integral (RA-MPPI) control utilizes the Conditional Value-at-Risk (CVaR) measure to generate optimal control actions for safety-critical robotic applications. Different from most existing Stochastic MPCs and CVaR optimization methods that linearize the original dynamics and formulate control tasks as convex programs, the proposed method directly uses the original dynamics without restricting the form of the cost functions or the noise. We apply the novel RA-MPPI controller to an autonomous vehicle to perform aggressive driving maneuvers in cluttered environments. Our simulations and experiments show that the proposed RA-MPPI controller can achieve about the same lap time with significantly fewer collisions compared to the baseline MPPI controller. The proposed controller performs on-line computation at an update frequency of up to 80Hz, utilizing modern Graphics Processing Units (GPUs) to multi-thread the generation of trajectories as well as the CVaR values.
Optimizing Industrial HVAC Systems with Hierarchical Reinforcement Learning
Sep 16, 2022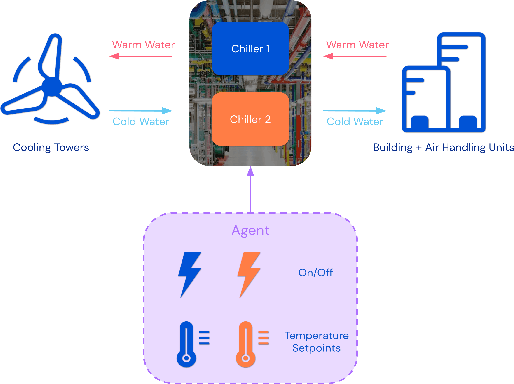
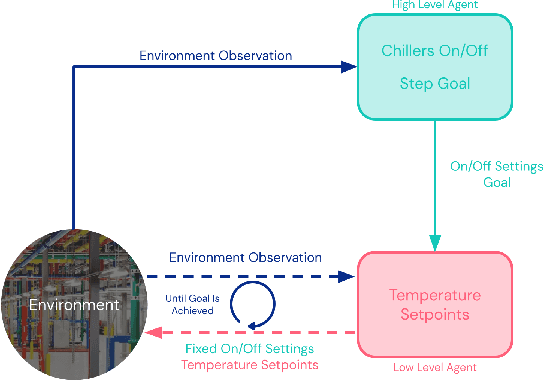
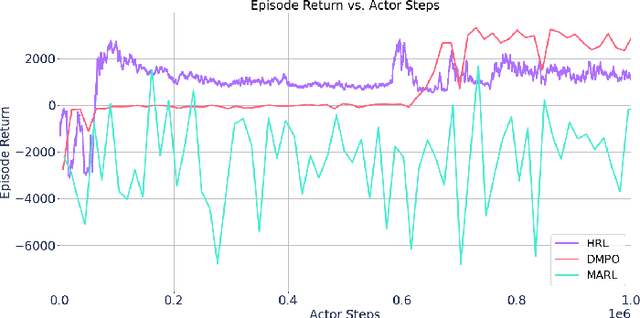
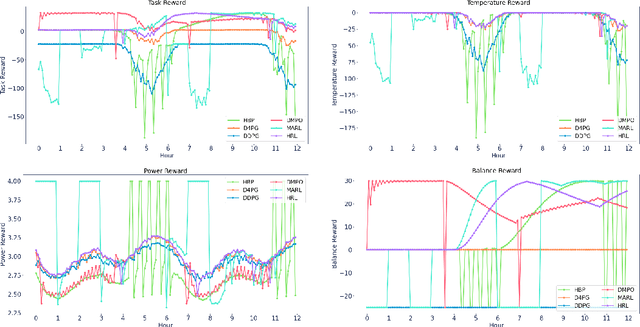
Reinforcement learning (RL) techniques have been developed to optimize industrial cooling systems, offering substantial energy savings compared to traditional heuristic policies. A major challenge in industrial control involves learning behaviors that are feasible in the real world due to machinery constraints. For example, certain actions can only be executed every few hours while other actions can be taken more frequently. Without extensive reward engineering and experimentation, an RL agent may not learn realistic operation of machinery. To address this, we use hierarchical reinforcement learning with multiple agents that control subsets of actions according to their operation time scales. Our hierarchical approach achieves energy savings over existing baselines while maintaining constraints such as operating chillers within safe bounds in a simulated HVAC control environment.
A Novel Enhanced Convolution Neural Network with Extreme Learning Machine: Facial Emotional Recognition in Psychology Practices
Aug 05, 2022Facial emotional recognition is one of the essential tools used by recognition psychology to diagnose patients. Face and facial emotional recognition are areas where machine learning is excelling. Facial Emotion Recognition in an unconstrained environment is an open challenge for digital image processing due to different environments, such as lighting conditions, pose variation, yaw motion, and occlusions. Deep learning approaches have shown significant improvements in image recognition. However, accuracy and time still need improvements. This research aims to improve facial emotion recognition accuracy during the training session and reduce processing time using a modified Convolution Neural Network Enhanced with Extreme Learning Machine (CNNEELM). The system entails (CNNEELM) improving the accuracy in image registration during the training session. Furthermore, the system recognizes six facial emotions happy, sad, disgust, fear, surprise, and neutral with the proposed CNNEELM model. The study shows that the overall facial emotion recognition accuracy is improved by 2% than the state of art solutions with a modified Stochastic Gradient Descent (SGD) technique. With the Extreme Learning Machine (ELM) classifier, the processing time is brought down to 65ms from 113ms, which can smoothly classify each frame from a video clip at 20fps. With the pre-trained InceptionV3 model, the proposed CNNEELM model is trained with JAFFE, CK+, and FER2013 expression datasets. The simulation results show significant improvements in accuracy and processing time, making the model suitable for the video analysis process. Besides, the study solves the issue of the large processing time required to process the facial images.
* 19 pages
Differentiable physics-enabled closure modeling for Burgers' turbulence
Sep 23, 2022
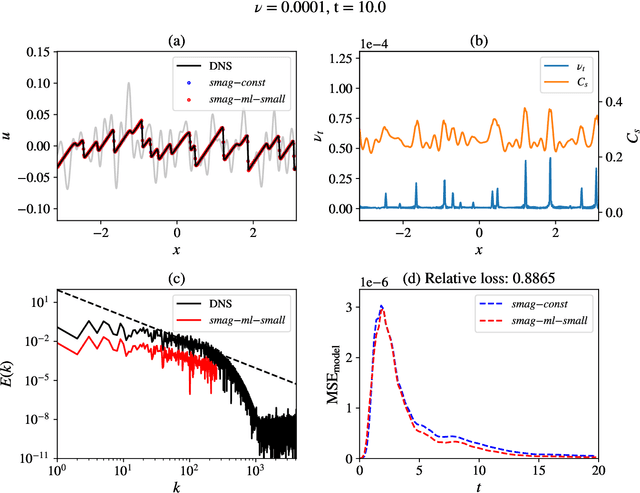
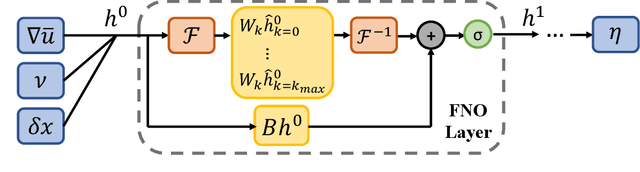
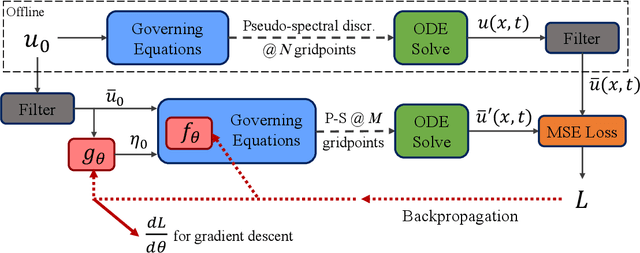
Data-driven turbulence modeling is experiencing a surge in interest following algorithmic and hardware developments in the data sciences. We discuss an approach using the differentiable physics paradigm that combines known physics with machine learning to develop closure models for Burgers' turbulence. We consider the 1D Burgers system as a prototypical test problem for modeling the unresolved terms in advection-dominated turbulence problems. We train a series of models that incorporate varying degrees of physical assumptions on an a posteriori loss function to test the efficacy of models across a range of system parameters, including viscosity, time, and grid resolution. We find that constraining models with inductive biases in the form of partial differential equations that contain known physics or existing closure approaches produces highly data-efficient, accurate, and generalizable models, outperforming state-of-the-art baselines. Addition of structure in the form of physics information also brings a level of interpretability to the models, potentially offering a stepping stone to the future of closure modeling.
Detection of Interacting Variables for Generalized Linear Models via Neural Networks
Sep 16, 2022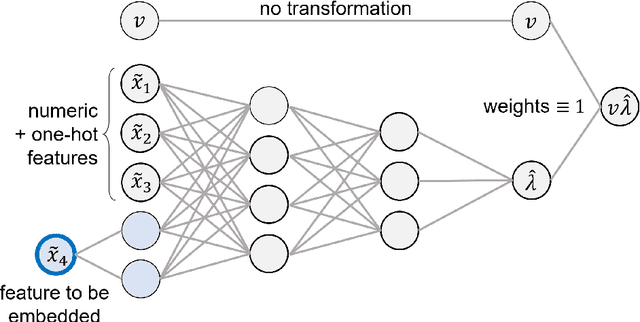
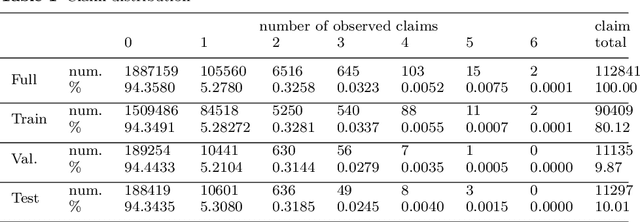
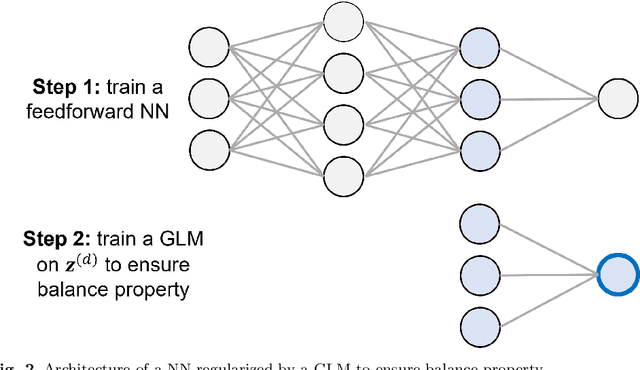

The quality of generalized linear models (GLMs), frequently used by insurance companies, depends on the choice of interacting variables. The search for interactions is time-consuming, especially for data sets with a large number of variables, depends much on expert judgement of actuaries, and often relies on visual performance indicators. Therefore, we present an approach to automating the process of finding interactions that should be added to GLMs to improve their predictive power. Our approach relies on neural networks and a model-specific interaction detection method, which is computationally faster than the traditionally used methods like Friedman H-Statistic or SHAP values. In numerical studies, we provide the results of our approach on different data sets: open-source data, artificial data, and proprietary data.
UV Volumes for Real-time Rendering of Editable Free-view Human Performance
Mar 27, 2022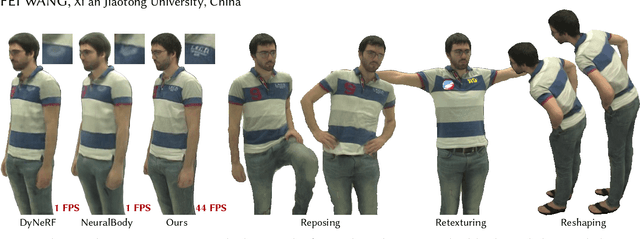
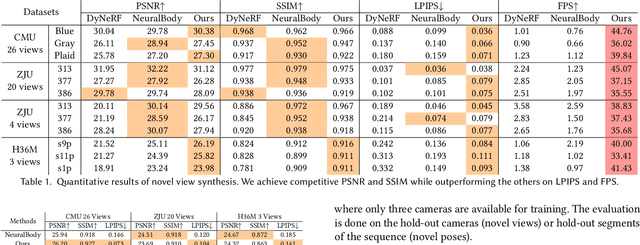
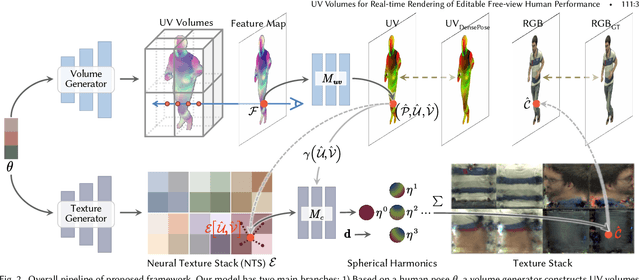

Neural volume rendering has been proven to be a promising method for efficient and photo-realistic rendering of a human performer in free-view, a critical task in many immersive VR/AR applications. However, existing approaches are severely limited by their high computational cost in the rendering process. To solve this problem, we propose the UV Volumes, an approach that can render an editable free-view video of a human performer in real-time. It is achieved by removing the high-frequency (i.e., non-smooth) human textures from the 3D volume and encoding them into a 2D neural texture stack (NTS). The smooth UV volume allows us to employ a much smaller and shallower structure for 3D CNN and MLP, to obtain the density and texture coordinates without losing image details. Meanwhile, the NTS only needs to be queried once for each pixel in the UV image to retrieve its RGB value. For editability, the 3D CNN and MLP decoder can easily fit the function that maps the input structured-and-posed latent codes to the relatively smooth densities and texture coordinates. It gives our model a better generalization ability to handle novel poses and shapes. Furthermore, the use of NST enables new applications, e.g., retexturing. Extensive experiments on CMU Panoptic, ZJU Mocap, and H36M datasets show that our model can render 900 * 500 images in 40 fps on average with comparable photorealism to state-of-the-art methods. The project and supplementary materials are available at https://fanegg.github.io/UV-Volumes.
Feature embedding in click-through rate prediction
Sep 20, 2022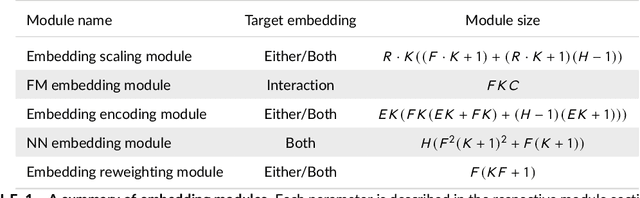
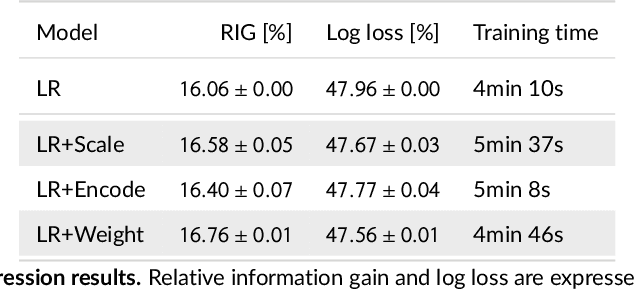
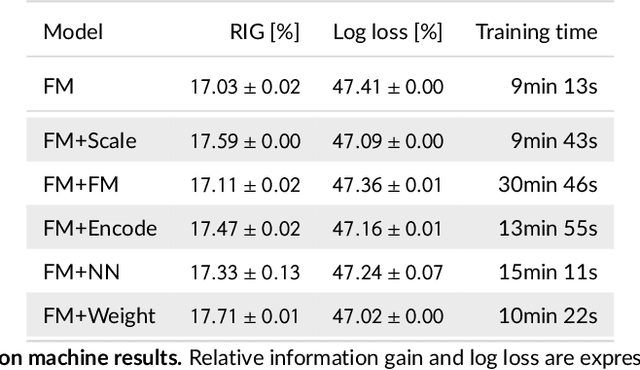
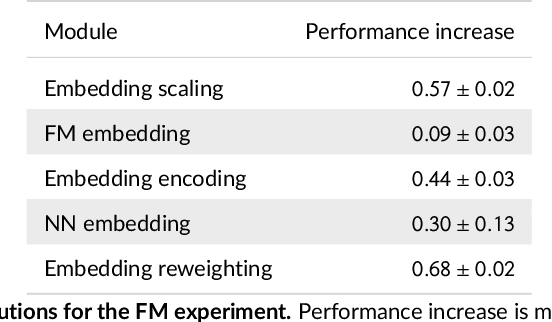
We tackle the challenge of feature embedding for the purposes of improving the click-through rate prediction process. We select three models: logistic regression, factorization machines and deep factorization machines, as our baselines and propose five different feature embedding modules: embedding scaling, FM embedding, embedding encoding, NN embedding and the embedding reweighting module. The embedding modules act as a way to improve baseline model feature embeddings and are trained alongside the rest of the model parameters in an end-to-end manner. Each module is individually added to a baseline model to obtain a new augmented model. We test the predictive performance of our augmented models on a publicly accessible dataset used for benchmarking click-through rate prediction models. Our results show that several proposed embedding modules provide an important increase in predictive performance without a drastic increase in training time.
Collision-Free 6-DoF Trajectory Generation for Omnidirectional Multi-rotor Aerial Vehicle
Sep 26, 2022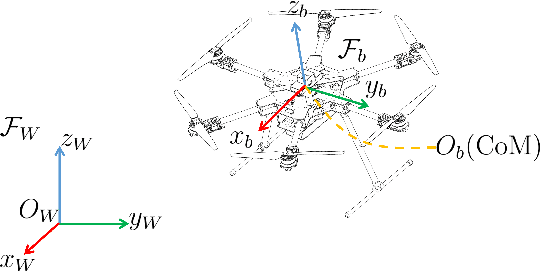
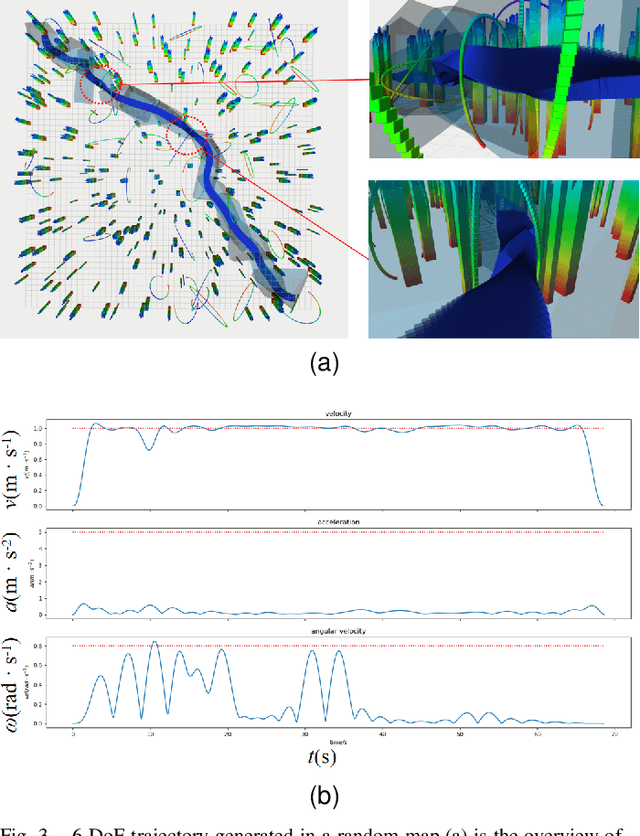

As a kind of fully actuated system, omnidirectional multirotor aerial vehicles (OMAVs) has more flexible maneuverability than traditional underactuated multirotor aircraft, and it also has more significant advantages in obstacle avoidance flight in complex environments.However, there is almost no way to generate the full degrees of freedom trajectory that can play the OMAVs' potential.Due to the high dimensionality of configuration space, it is challenging to make the designed trajectory generation algorithm efficient and scalable.This paper aims to achieve obstacle avoidance planning of OMAV in complex environments. A 6-DoF trajectory generation framework for OMAVs was designed for the first time based on the geometrically constrained Minimum Control Effort (MINCO) trajectory generation framework.According to the safe regions represented by a series of convex polyhedra, combined with the aircraft's overall shape and dynamic constraints, the framework finally generates a collision-free optimal 6-DoF trajectory.The vehicle's attitude is parameterized into a 3D vector by stereographic projection.Simulation experiments based on Gazebo and PX4 Autopilot are conducted to verify the performance of the proposed framework.
Temporal negative refraction
Sep 21, 2022
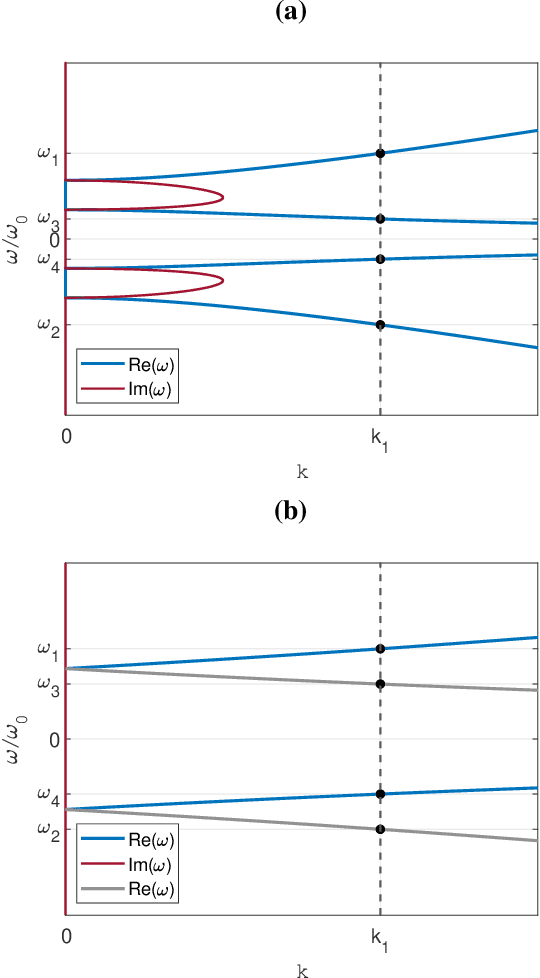
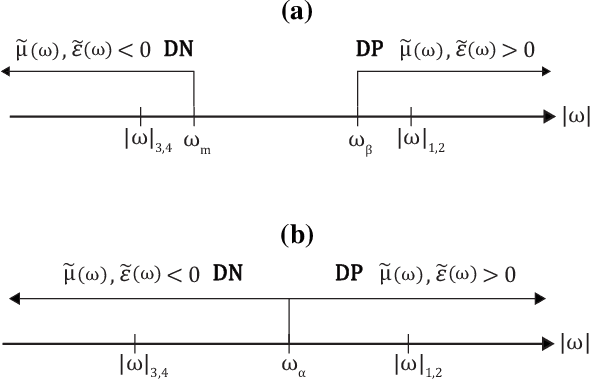
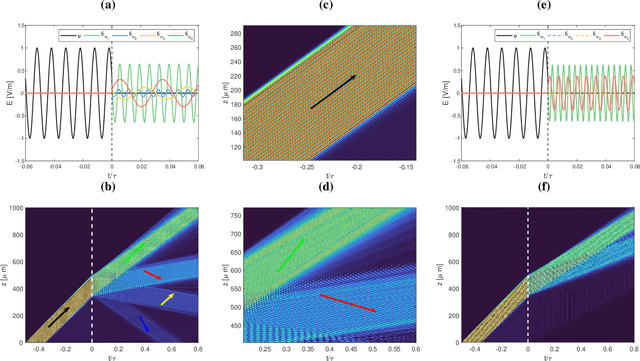
Negative refraction is a peculiar wave propagation phenomenon that occurs when a wave crosses a boundary between a regular medium and a medium with both constitutive parameters negative at the given frequency. The phase and group velocities of the transmitted wave then turn anti-parallel. Here we propose a temporal analogue of the negative refraction phenomenon using time-dependent media. Instead of transmitting the wave through a spatial boundary we transmit it through an artificial temporal boundary, created by switching both parameters from constant to dispersive with frequency. We show that the resulting dynamics is sharply different from the spatial case, featuring both reflection and refraction in positive and negative regimes simultaneously. We demonstrate our results analytically and numerically using electromagnetic medium. In addition, we show that by a targeted dispersion tuning the temporal boundary can be made nonreflecting, while preserving both positive and negative refraction.
Speech Forensics: Blind Voice Mimicry Detection
Sep 26, 2022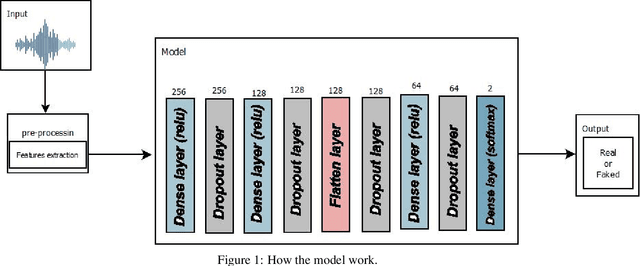
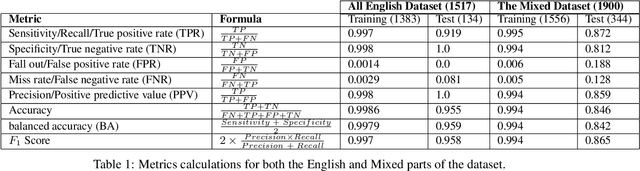

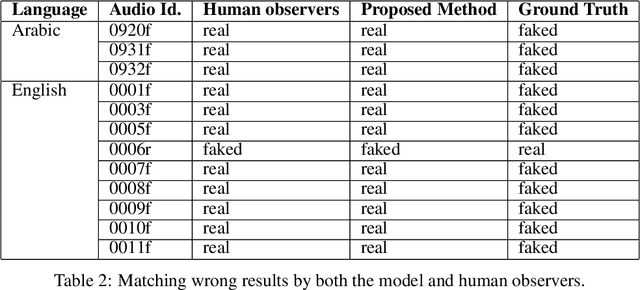
Audio is one of the most used way of human communication, but at the same time it can be easily misused by to trick people. With the revolution of AI, the related technologies are now accessible to almost everyone thus making it simple for the criminals to commit crimes and forgeries. In this work, we introduce a deep learning method to develop a classifier that will blindly classify an input audio as real or mimicked. The proposed model was trained on a set of important features extracted from a large dataset of audios to get a classifier that was tested on the same set of features from different audios. Two datasets were created for this work; an all English data set and a mixed data set (Arabic and English). These datasets have been made available through GitHub for the use of the research community at https://github.com/SaSs7/Dataset. For the purpose of comparison, the audios were also classified through human inspection with the subjects being the native speakers. The ensued results were interesting and exhibited formidable accuracy.