 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Contrastive introspection (ConSpec) to rapidly identify invariant steps for success
Oct 12, 2022
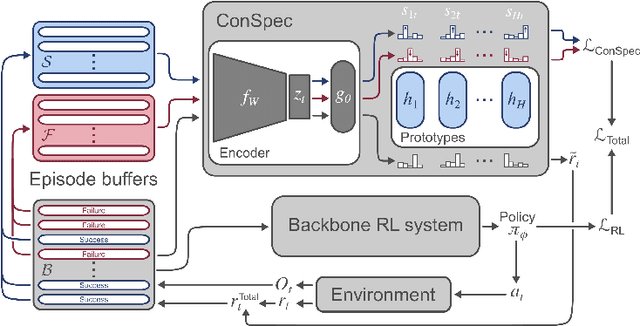
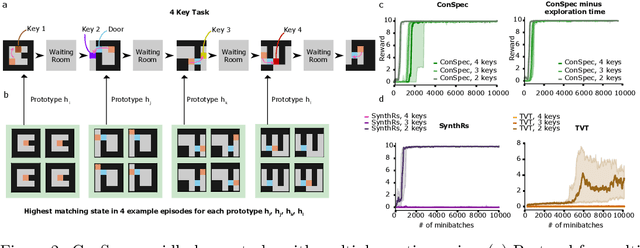
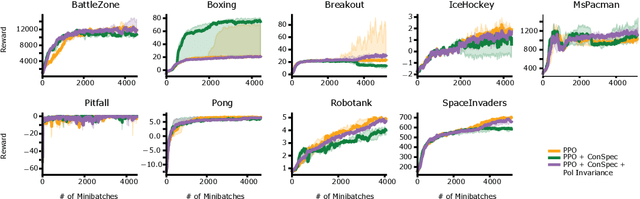
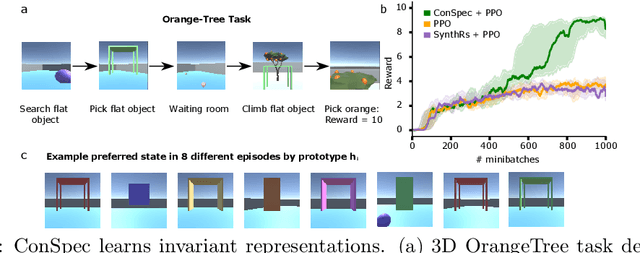
Reinforcement learning (RL) algorithms have achieved notable success in recent years, but still struggle with fundamental issues in long-term credit assignment. It remains difficult to learn in situations where success is contingent upon multiple critical steps that are distant in time from each other and from a sparse reward; as is often the case in real life. Moreover, how RL algorithms assign credit in these difficult situations is typically not coded in a way that can rapidly generalize to new situations. Here, we present an approach using offline contrastive learning, which we call contrastive introspection (ConSpec), that can be added to any existing RL algorithm and addresses both issues. In ConSpec, a contrastive loss is used during offline replay to identify invariances among successful episodes. This takes advantage of the fact that it is easier to retrospectively identify the small set of steps that success is contingent upon than it is to prospectively predict reward at every step taken in the environment. ConSpec stores this knowledge in a collection of prototypes summarizing the intermediate states required for success. During training, arrival at any state that matches these prototypes generates an intrinsic reward that is added to any external rewards. As well, the reward shaping provided by ConSpec can be made to preserve the optimal policy of the underlying RL agent. The prototypes in ConSpec provide two key benefits for credit assignment: (1) They enable rapid identification of all the critical states. (2) They do so in a readily interpretable manner, enabling out of distribution generalization when sensory features are altered. In summary, ConSpec is a modular system that can be added to any existing RL algorithm to improve its long-term credit assignment.
Quantifying U-Net Uncertainty in Multi-Parametric MRI-based Glioma Segmentation by Spherical Image Projection
Oct 12, 2022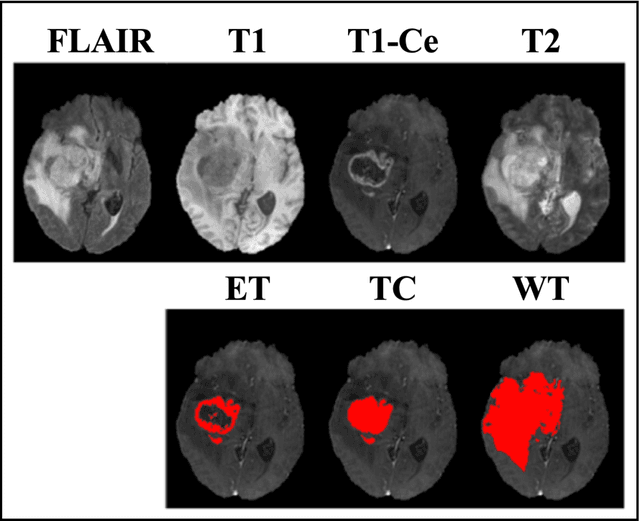

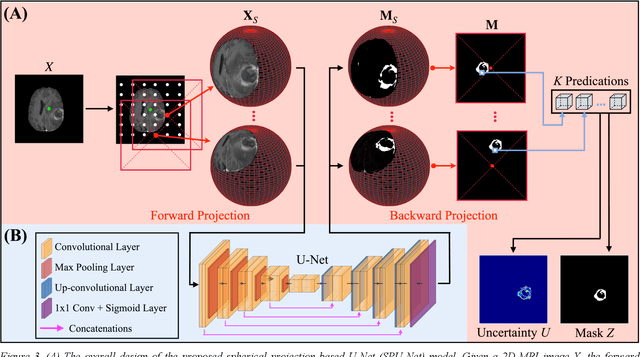
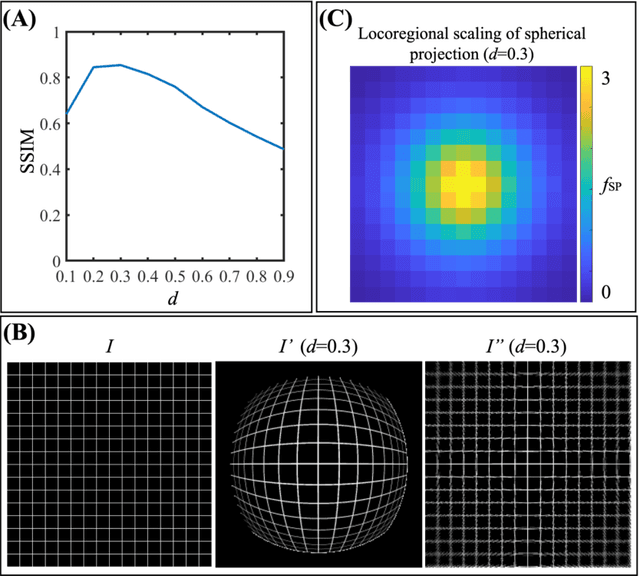
Purpose: To develop a U-Net segmentation uncertainty quantification method based on spherical image projection of multi-parametric MRI (MP-MRI) in glioma segmentation. Methods: The projection of planar MRI onto a spherical surface retains global anatomical information. By incorporating such image transformation in our proposed spherical projection-based U-Net (SPU-Net) segmentation model design, multiple segmentation predictions can be obtained for a single MRI. The final segmentation is the average of all predictions, and the variation can be shown as an uncertainty map. An uncertainty score was introduced to compare the uncertainty measurements' performance. The SPU-Net model was implemented on 369 glioma patients with MP-MRI scans. Three SPU-Nets were trained to segment enhancing tumor (ET), tumor core (TC), and whole tumor (WT), respectively. The SPU-Net was compared with (1) classic U-Net with test-time augmentation (TTA) and (2) linear scaling-based U-Net (LSU-Net) in both segmentation accuracy (Dice coefficient) and uncertainty (uncertainty map and uncertainty score). Results: The SPU-Net achieved low uncertainty for correct segmentation predictions (e.g., tumor interior or healthy tissue interior) and high uncertainty for incorrect results (e.g., tumor boundaries). This model could allow the identification of missed tumor targets or segmentation errors in U-Net. The SPU-Net achieved the highest uncertainty scores for 3 targets (ET/TC/WT): 0.826/0.848/0.936, compared to 0.784/0.643/0.872 for the U-Net with TTA and 0.743/0.702/0.876 for the LSU-Net. The SPU-Net also achieved statistically significantly higher Dice coefficients. Conclusion: The SPU-Net offers a powerful tool to quantify glioma segmentation uncertainty while improving segmentation accuracy. The proposed method can be generalized to other medical image-related deep-learning applications for uncertainty evaluation.
Orthogonal Delay Scale Space Modulation: A New Technique for Wideband Time-Varying Channels
Dec 03, 2021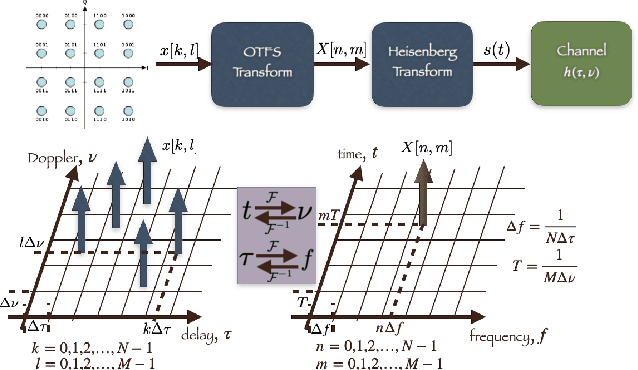
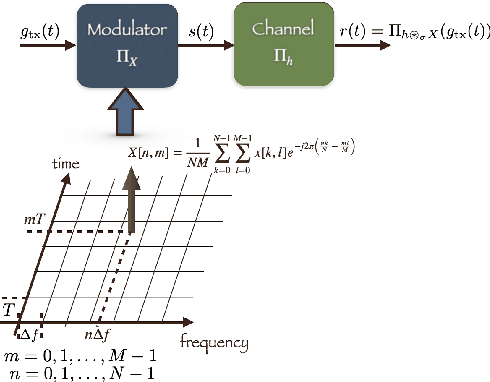
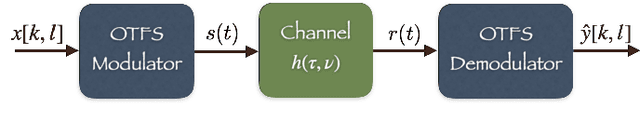
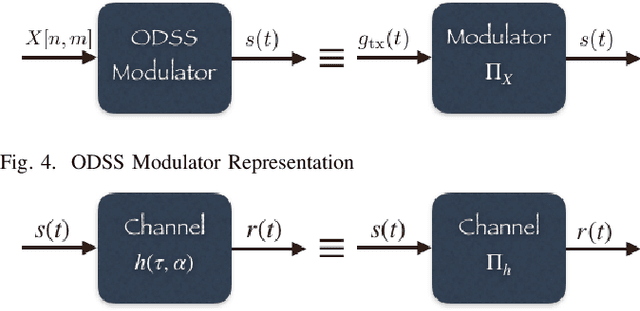
Orthogonal Time Frequency Space (OTFS) modulation is a recently proposed scheme for time-varying narrowband channels in terrestrial radio-frequency communications. Underwater acoustic (UWA) and ultra-wideband (UWB) communication systems, on the other hand, confront wideband time-varying channels. Unlike narrowband channels, for which time contractions or dilations due to Doppler effect can be approximated by frequency-shifts, the Doppler effect in wideband channels results in frequency-dependent non uniform shift of signal frequencies across the band. In this paper, we develop an OTFS-like modulation scheme -- Orthogonal Delay Scale Space (ODSS) modulation -- for handling wideband time-varying channels. We derive the ODSS transmission and reception schemes from first principles. In the process, we introduce the notion of $\omega$ convolution in the delay-scale space that parallels the twisted convolution used in the time-frequency space. The preprocessing 2D transformation from the Fourier-Mellin domain to the delay-scale space in ODSS, which plays the role of inverse symplectic Fourier transform (ISFFT) in OTFS, improves the bit error rate performance compared to OTFS and Orthogonal Frequency Division Multiplexing (OFDM) in wideband time-varying channels. Furthermore, since the channel matrix is rendered near-diagonal, ODSS retains the advantage of OFDM in terms of its low-complexity receiver structure.
Optimizing Industrial HVAC Systems with Hierarchical Reinforcement Learning
Sep 16, 2022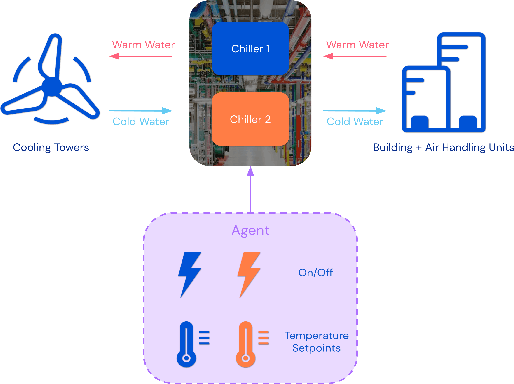
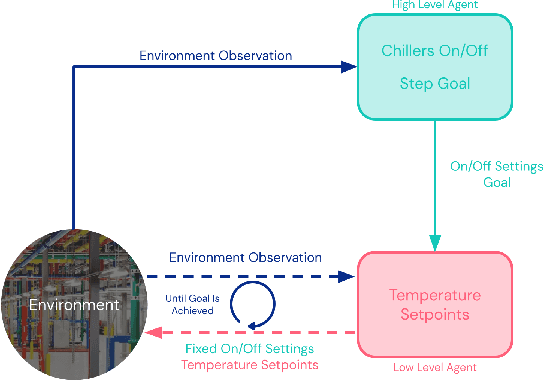
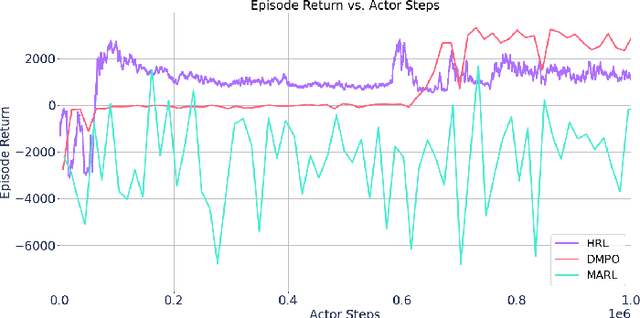
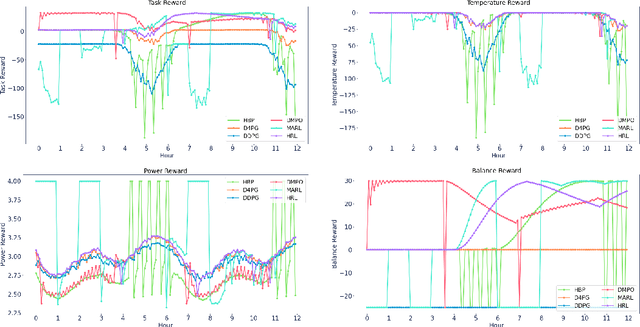
Reinforcement learning (RL) techniques have been developed to optimize industrial cooling systems, offering substantial energy savings compared to traditional heuristic policies. A major challenge in industrial control involves learning behaviors that are feasible in the real world due to machinery constraints. For example, certain actions can only be executed every few hours while other actions can be taken more frequently. Without extensive reward engineering and experimentation, an RL agent may not learn realistic operation of machinery. To address this, we use hierarchical reinforcement learning with multiple agents that control subsets of actions according to their operation time scales. Our hierarchical approach achieves energy savings over existing baselines while maintaining constraints such as operating chillers within safe bounds in a simulated HVAC control environment.
Collision-Free 6-DoF Trajectory Generation for Omnidirectional Multi-rotor Aerial Vehicle
Sep 26, 2022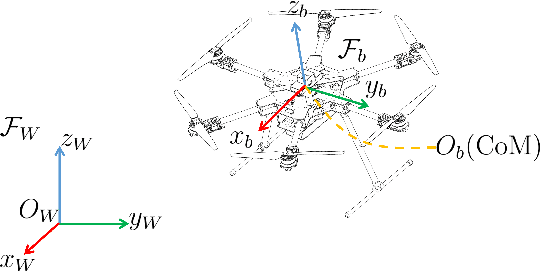
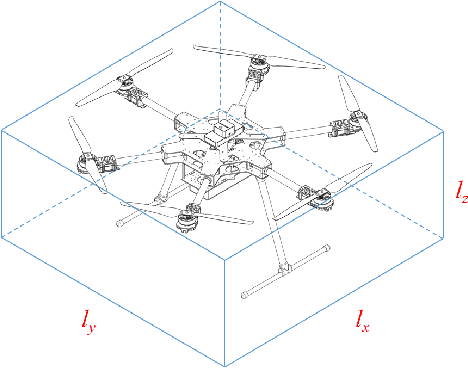
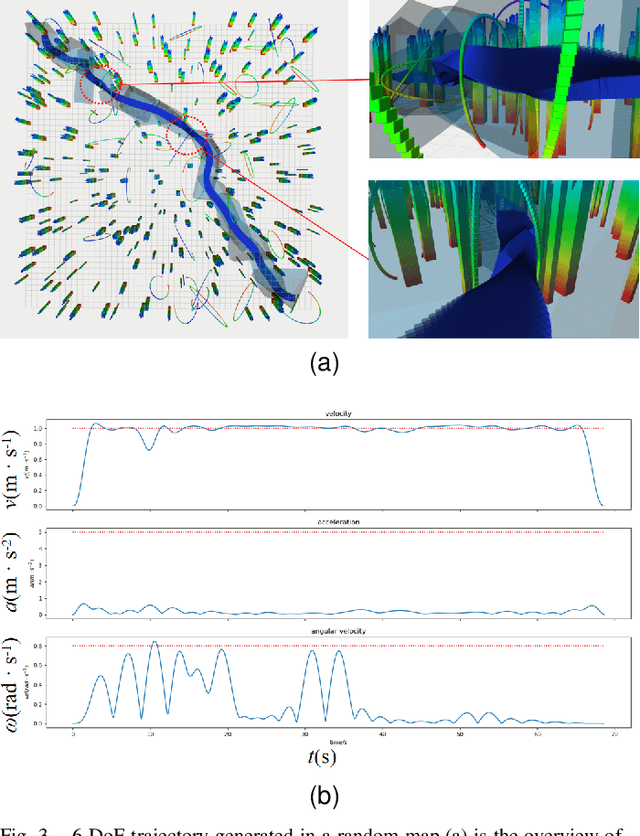

As a kind of fully actuated system, omnidirectional multirotor aerial vehicles (OMAVs) has more flexible maneuverability than traditional underactuated multirotor aircraft, and it also has more significant advantages in obstacle avoidance flight in complex environments.However, there is almost no way to generate the full degrees of freedom trajectory that can play the OMAVs' potential.Due to the high dimensionality of configuration space, it is challenging to make the designed trajectory generation algorithm efficient and scalable.This paper aims to achieve obstacle avoidance planning of OMAV in complex environments. A 6-DoF trajectory generation framework for OMAVs was designed for the first time based on the geometrically constrained Minimum Control Effort (MINCO) trajectory generation framework.According to the safe regions represented by a series of convex polyhedra, combined with the aircraft's overall shape and dynamic constraints, the framework finally generates a collision-free optimal 6-DoF trajectory.The vehicle's attitude is parameterized into a 3D vector by stereographic projection.Simulation experiments based on Gazebo and PX4 Autopilot are conducted to verify the performance of the proposed framework.
Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy
Oct 11, 2021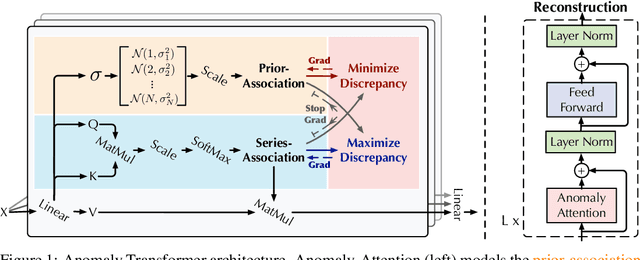
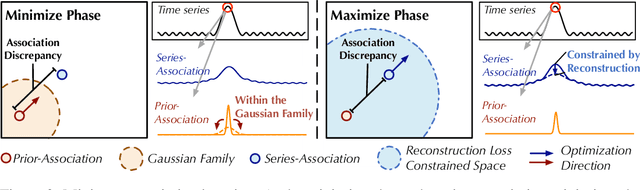
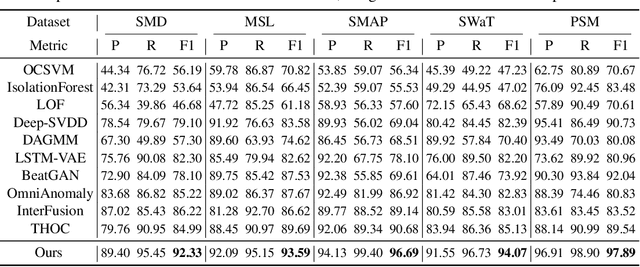
Unsupervisedly detecting anomaly points in time series is challenging, which requires the model to learn informative representations and derive a distinguishable criterion. Prior methods mainly detect anomalies based on the recurrent network representation of each time point. However, the point-wise representation is less informative for complex temporal patterns and can be dominated by normal patterns, making rare anomalies less distinguishable. We find that in each time series, each time point can also be described by its associations with all time points, presenting as a point-wise distribution that is more expressive for temporal modeling. We further observe that due to the rarity of anomalies, it is harder for anomalies to build strong associations with the whole series and their associations shall mainly concentrate on the adjacent time points. This observation implies an inherently distinguishable criterion between normal and abnormal points, which we highlight as the \emph{Association Discrepancy}. Technically we propose the \emph{Anomaly Transformer} with an \emph{Anomaly-Attention} mechanism to compute the association discrepancy. A minimax strategy is devised to amplify the normal-abnormal distinguishability of the association discrepancy. Anomaly Transformer achieves state-of-the-art performance on six unsupervised time series anomaly detection benchmarks for three applications: service monitoring, space \& earth exploration, and water treatment.
Visualization of Real-time Displacement Time History superimposed with Dynamic Experiments using Wireless Smart Sensors (WSS) and Augmented Reality (AR)
Oct 17, 2021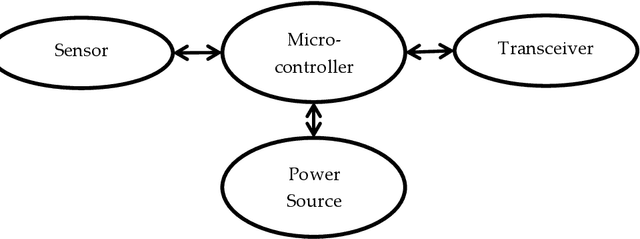
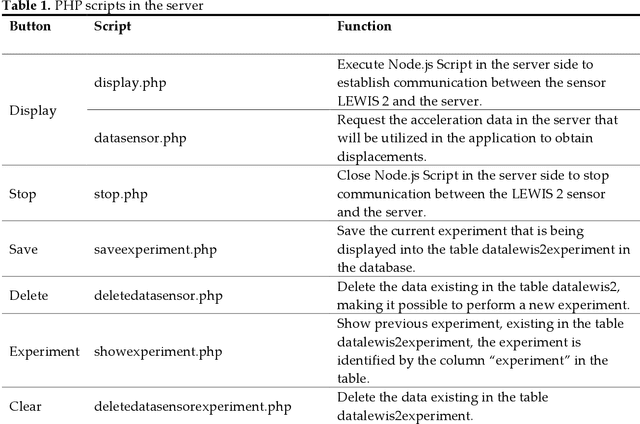

Wireless Smart Sensors (WSS) process field data and inform structural engineers and owners about the infrastructure health and safety. In bridge engineering, inspectors make decisions using objective data from each bridge. They decide about repairs and replacements and prioritize the maintenance of certain structure elements on the basis of changes in displacements under loads. However, access to displacement information in the field and in real-time remains a challenge. Displacement data provided by WSS in the field undergoes additional processing and is seen at a different location by an inspector and a sensor specialist. When the data is shared and streamed to the field inspector, there is a inter-dependence between inspectors, sensor specialists, and infrastructure owners, which limits the actionability of the data related to the bridge condition. If inspectors were able to see structural displacements in real-time at the locations of interest, they could conduct additional observations, which would create a new, information-based, decision-making reality in the field. This paper develops a new, human-centered interface that provides inspectors with real-time access to actionable structural data (real-time displacements under loads) during inspection and monitoring enhanced by Augmented Reality (AR). It summarizes the development and validation of the new human-infrastructure interface and evaluates its efficiency through laboratory experiments. The experiments demonstrate that the interface accurately estimates dynamic displacements in comparison with the laser. Using this new AR interface tool, inspectors can observe and compare displacement data, share it across space and time, and visualize displacements in time history.
Feature embedding in click-through rate prediction
Sep 20, 2022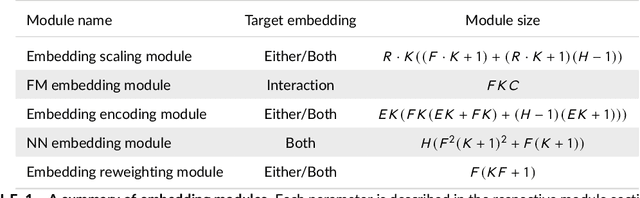
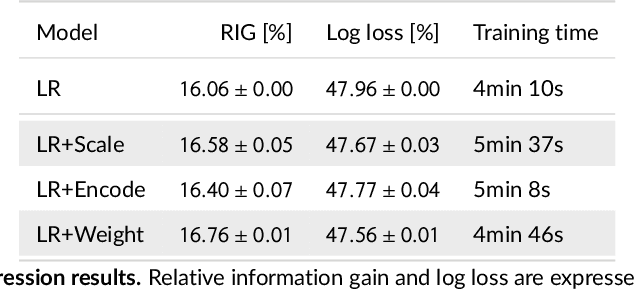
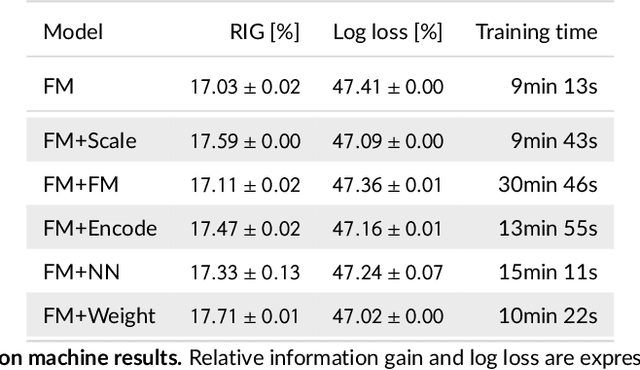
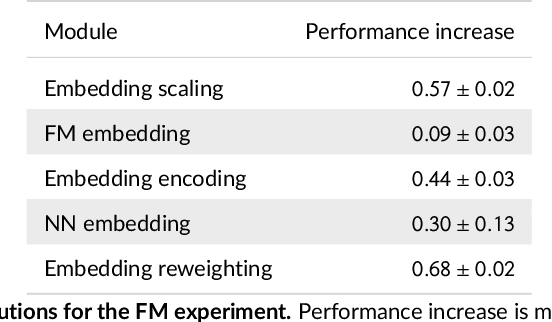
We tackle the challenge of feature embedding for the purposes of improving the click-through rate prediction process. We select three models: logistic regression, factorization machines and deep factorization machines, as our baselines and propose five different feature embedding modules: embedding scaling, FM embedding, embedding encoding, NN embedding and the embedding reweighting module. The embedding modules act as a way to improve baseline model feature embeddings and are trained alongside the rest of the model parameters in an end-to-end manner. Each module is individually added to a baseline model to obtain a new augmented model. We test the predictive performance of our augmented models on a publicly accessible dataset used for benchmarking click-through rate prediction models. Our results show that several proposed embedding modules provide an important increase in predictive performance without a drastic increase in training time.
Detection of Interacting Variables for Generalized Linear Models via Neural Networks
Sep 16, 2022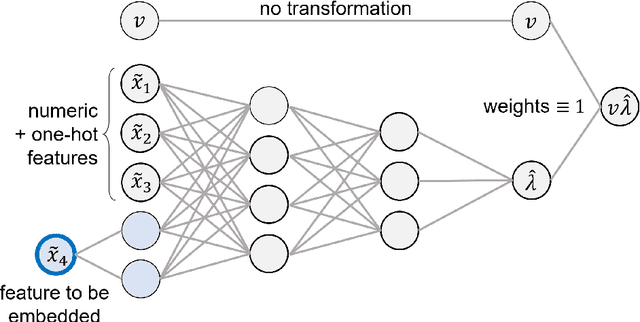
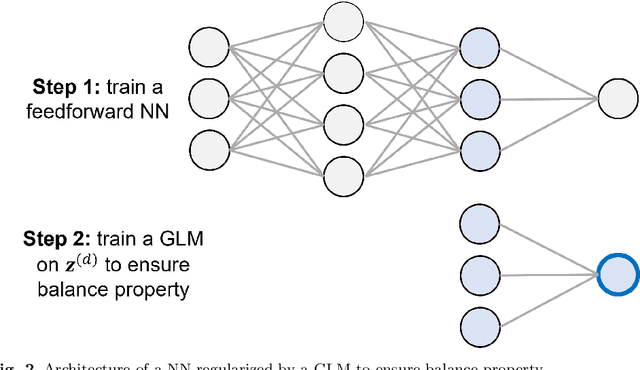

The quality of generalized linear models (GLMs), frequently used by insurance companies, depends on the choice of interacting variables. The search for interactions is time-consuming, especially for data sets with a large number of variables, depends much on expert judgement of actuaries, and often relies on visual performance indicators. Therefore, we present an approach to automating the process of finding interactions that should be added to GLMs to improve their predictive power. Our approach relies on neural networks and a model-specific interaction detection method, which is computationally faster than the traditionally used methods like Friedman H-Statistic or SHAP values. In numerical studies, we provide the results of our approach on different data sets: open-source data, artificial data, and proprietary data.
Speech Forensics: Blind Voice Mimicry Detection
Sep 26, 2022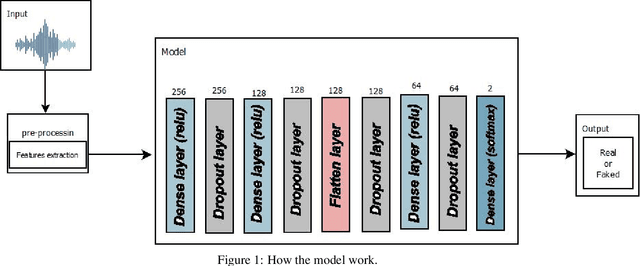
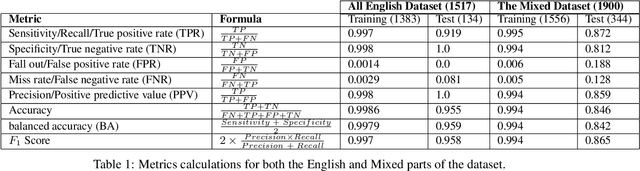

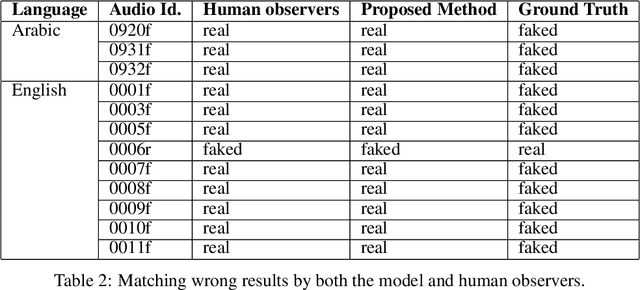
Audio is one of the most used way of human communication, but at the same time it can be easily misused by to trick people. With the revolution of AI, the related technologies are now accessible to almost everyone thus making it simple for the criminals to commit crimes and forgeries. In this work, we introduce a deep learning method to develop a classifier that will blindly classify an input audio as real or mimicked. The proposed model was trained on a set of important features extracted from a large dataset of audios to get a classifier that was tested on the same set of features from different audios. Two datasets were created for this work; an all English data set and a mixed data set (Arabic and English). These datasets have been made available through GitHub for the use of the research community at https://github.com/SaSs7/Dataset. For the purpose of comparison, the audios were also classified through human inspection with the subjects being the native speakers. The ensued results were interesting and exhibited formidable accuracy.