 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semi-Supervised Semantic Segmentation Based on Pseudo-Labels: A Survey
Mar 04, 2024
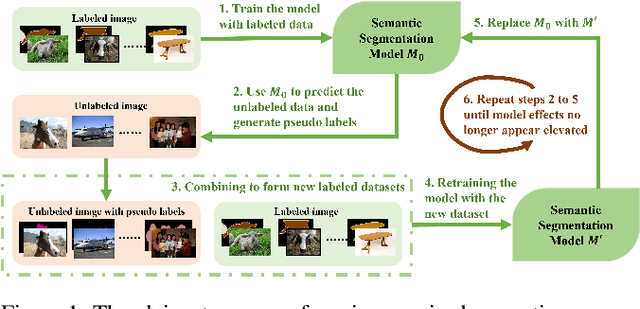
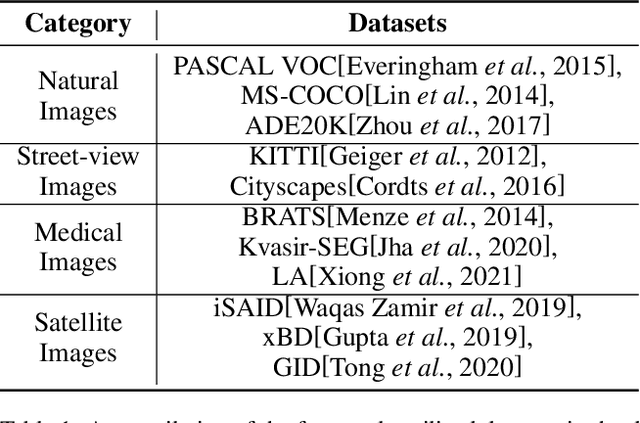
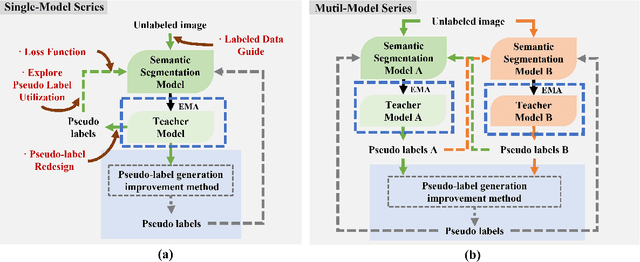
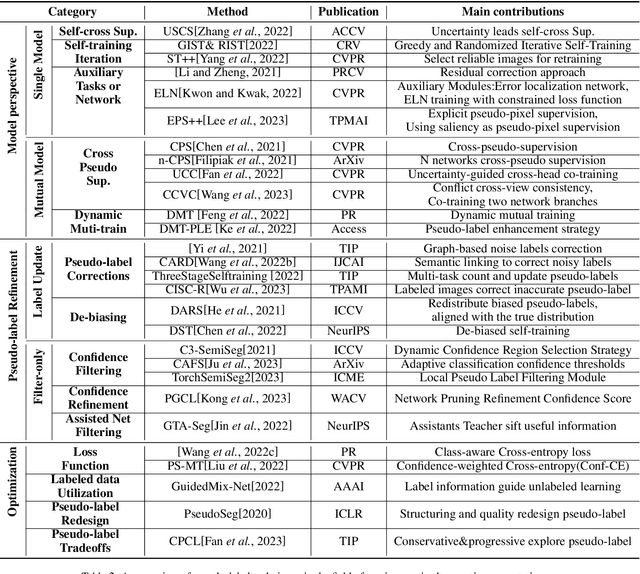
Semantic segmentation is an important and popular research area in computer vision that focuses on classifying pixels in an image based on their semantics. However, supervised deep learning requires large amounts of data to train models and the process of labeling images pixel by pixel is time-consuming and laborious. This review aims to provide a first comprehensive and organized overview of the state-of-the-art research results on pseudo-label methods in the field of semi-supervised semantic segmentation, which we categorize from different perspectives and present specific methods for specific application areas. In addition, we explore the application of pseudo-label technology in medical and remote-sensing image segmentation. Finally, we also propose some feasible future research directions to address the existing challenges.
Spatio-temporal reconstruction of substance dynamics using compressed sensing in multi-spectral magnetic resonance spectroscopic imaging
Mar 01, 2024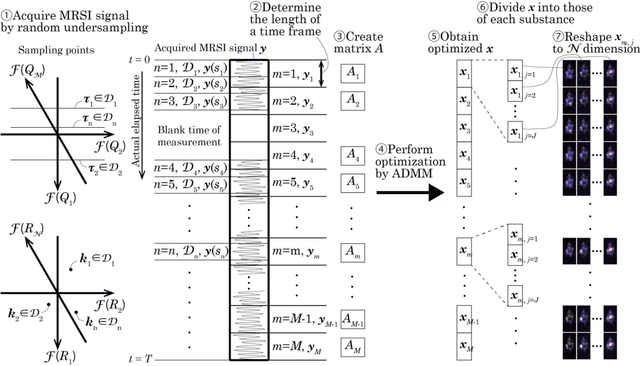
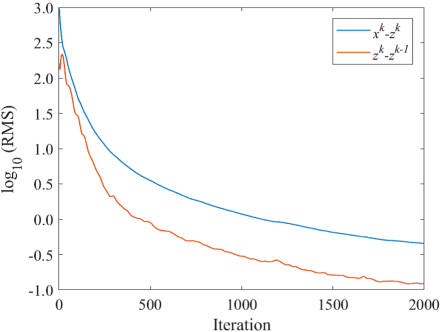
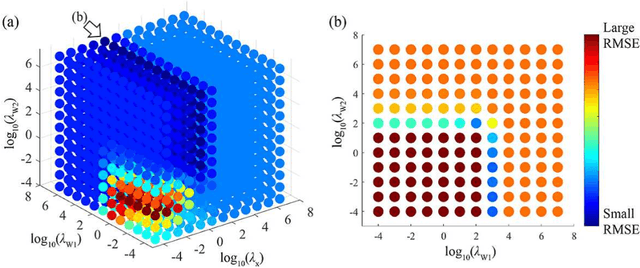
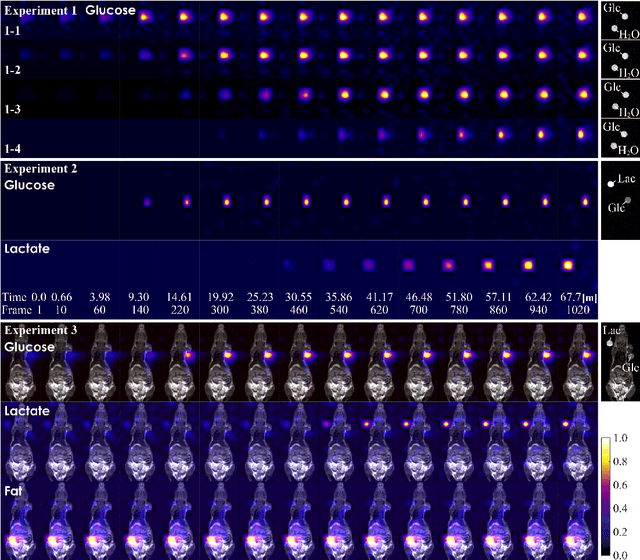
The objective of our study is to observe dynamics of multiple substances in vivo with high temporal resolution from multi-spectral magnetic resonance spectroscopic imaging (MRSI) data. The multi-spectral MRSI can effectively separate spectral peaks of multiple substances and is useful to measure spatial distributions of substances. However it is difficult to measure time-varying substance distributions directly by ordinary full sampling because the measurement requires a significantly long time. In this study, we propose a novel method to reconstruct the spatio-temporal distributions of substances from randomly undersampled multi-spectral MRSI data on the basis of compressed sensing (CS) and the partially separable function model with base spectra of substances. In our method, we have employed spatio-temporal sparsity and temporal smoothness of the substance distributions as prior knowledge to perform CS. The effectiveness of our method has been evaluated using phantom data sets of glass tubes filled with glucose or lactate solution in increasing amounts over time and animal data sets of a tumor-bearing mouse to observe the metabolic dynamics involved in the Warburg effect in vivo. The reconstructed results are consistent with the expected behaviors, showing that our method can reconstruct the spatio-temporal distribution of substances with a temporal resolution of four seconds which is extremely short time scale compared with that of full sampling. Since this method utilizes only prior knowledge naturally assumed for the spatio-temporal distributions of substances and is independent of the number of the spectral and spatial dimensions or the acquisition sequence of MRSI, it is expected to contribute to revealing the underlying substance dynamics in MRSI data already acquired or to be acquired in the future.
Macroscopic auxiliary asymptotic preserving neural networks for the linear radiative transfer equations
Mar 04, 2024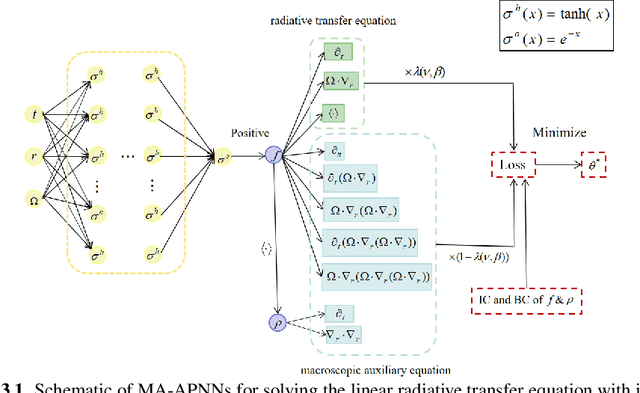
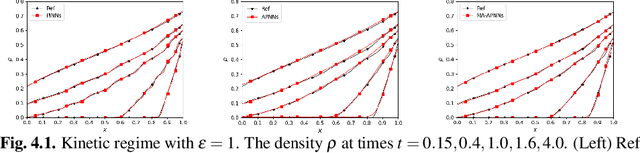

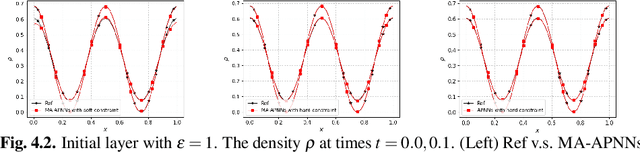
We develop a Macroscopic Auxiliary Asymptotic-Preserving Neural Network (MA-APNN) method to solve the time-dependent linear radiative transfer equations (LRTEs), which have a multi-scale nature and high dimensionality. To achieve this, we utilize the Physics-Informed Neural Networks (PINNs) framework and design a new adaptive exponentially weighted Asymptotic-Preserving (AP) loss function, which incorporates the macroscopic auxiliary equation that is derived from the original transfer equation directly and explicitly contains the information of the diffusion limit equation. Thus, as the scale parameter tends to zero, the loss function gradually transitions from the transport state to the diffusion limit state. In addition, the initial data, boundary conditions, and conservation laws serve as the regularization terms for the loss. We present several numerical examples to demonstrate the effectiveness of MA-APNNs.
Twisting Lids Off with Two Hands
Mar 04, 2024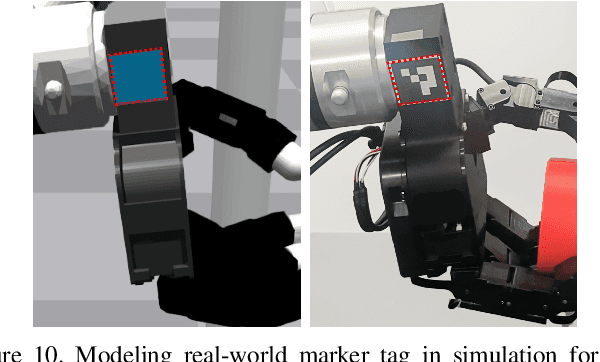

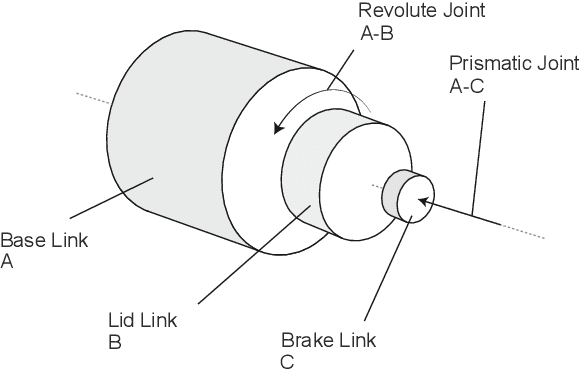

Manipulating objects with two multi-fingered hands has been a long-standing challenge in robotics, attributed to the contact-rich nature of many manipulation tasks and the complexity inherent in coordinating a high-dimensional bimanual system. In this work, we consider the problem of twisting lids of various bottle-like objects with two hands, and demonstrate that policies trained in simulation using deep reinforcement learning can be effectively transferred to the real world. With novel engineering insights into physical modeling, real-time perception, and reward design, the policy demonstrates generalization capabilities across a diverse set of unseen objects, showcasing dynamic and dexterous behaviors. Our findings serve as compelling evidence that deep reinforcement learning combined with sim-to-real transfer remains a promising approach for addressing manipulation problems of unprecedented complexity.
Online Training of Large Language Models: Learn while chatting
Mar 04, 2024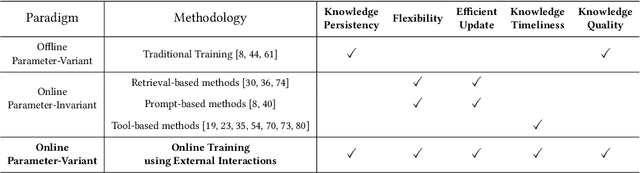
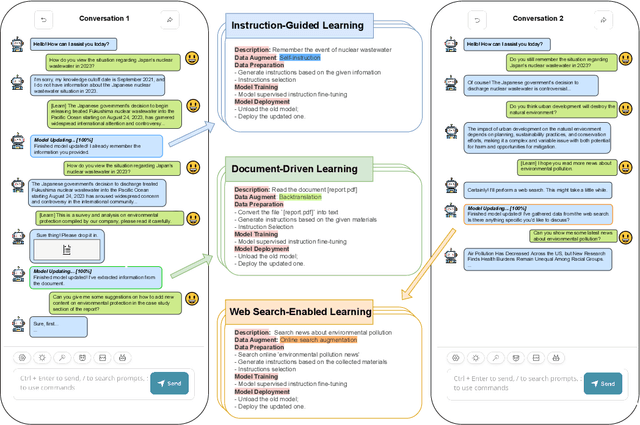
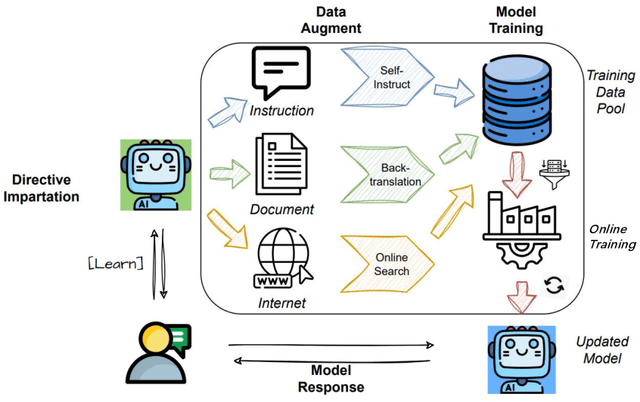

Large Language Models(LLMs) have dramatically revolutionized the field of Natural Language Processing(NLP), offering remarkable capabilities that have garnered widespread usage. However, existing interaction paradigms between LLMs and users are constrained by either inflexibility, limitations in customization, or a lack of persistent learning. This inflexibility is particularly evident as users, especially those without programming skills, have restricted avenues to enhance or personalize the model. Existing frameworks further complicate the model training and deployment process due to their computational inefficiencies and lack of user-friendly interfaces. To overcome these challenges, this paper introduces a novel interaction paradigm-'Online Training using External Interactions'-that merges the benefits of persistent, real-time model updates with the flexibility for individual customization through external interactions such as AI agents or online/offline knowledge bases.
CURATRON: Complete Robust Preference Data for Robust Alignment of Large Language Models
Mar 05, 2024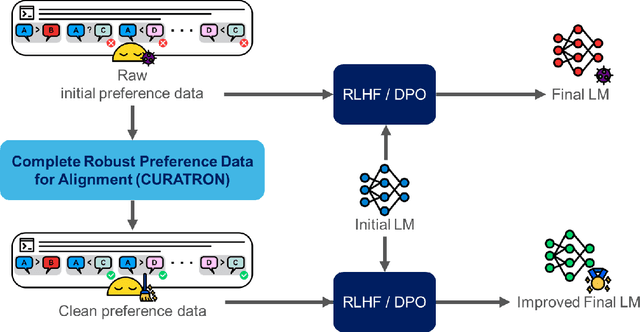

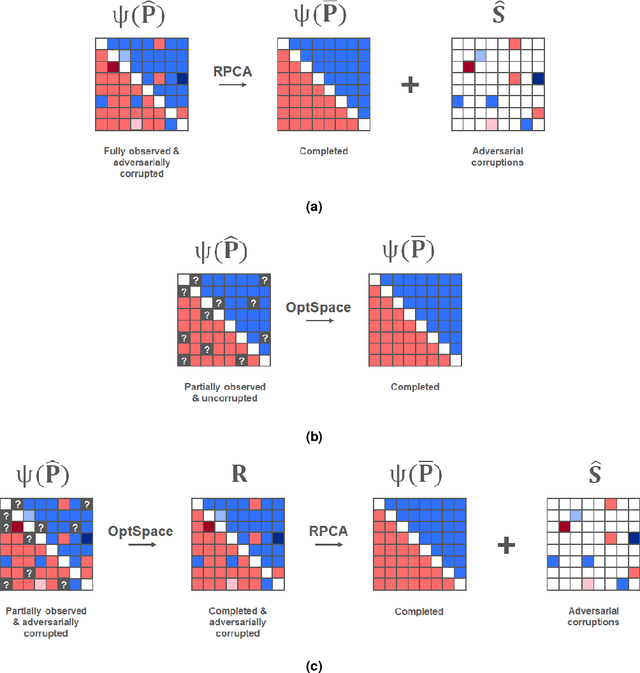
This paper addresses the challenges of aligning large language models (LLMs) with human values via preference learning (PL), with a focus on the issues of incomplete and corrupted data in preference datasets. We propose a novel method for robustly and completely recalibrating values within these datasets to enhance LLMs resilience against the issues. In particular, we devise a guaranteed polynomial time ranking algorithm that robustifies several existing models, such as the classic Bradley--Terry--Luce (BTL) (Bradley and Terry, 1952) model and certain generalizations of it. To the best of our knowledge, our present work is the first to propose an algorithm that provably recovers an {\epsilon}-optimal ranking with high probability while allowing as large as O(n) perturbed pairwise comparison results per model response. Furthermore, we show robust recovery results in the partially observed setting. Our experiments confirm that our algorithms handle adversarial noise and unobserved comparisons well in both general and LLM preference dataset settings. This work contributes to the development and scaling of more reliable and ethically aligned AI models by equipping the dataset curation pipeline with the ability to handle missing and maliciously manipulated inputs.
Rethinking Clustered Federated Learning in NOMA Enhanced Wireless Networks
Mar 05, 2024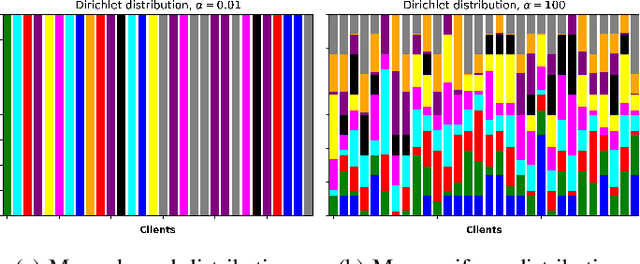
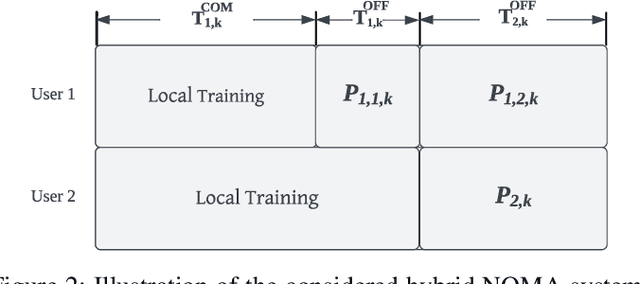
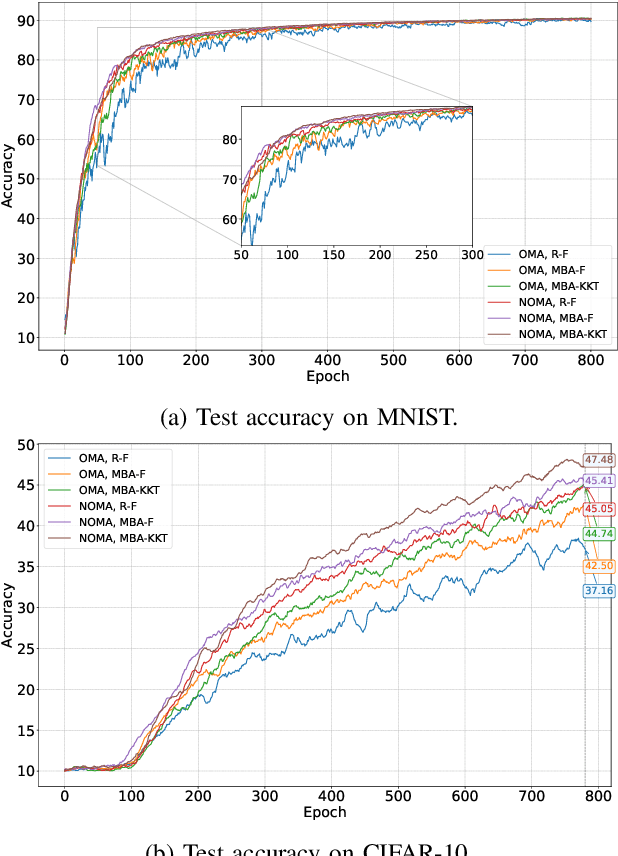
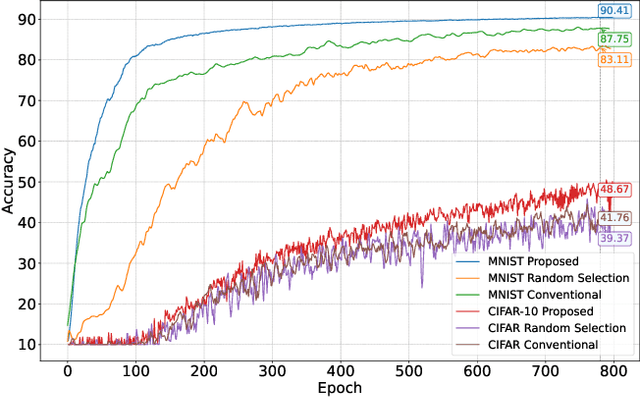
This study explores the benefits of integrating the novel clustered federated learning (CFL) approach with non-orthogonal multiple access (NOMA) under non-independent and identically distributed (non-IID) datasets, where multiple devices participate in the aggregation with time limitations and a finite number of sub-channels. A detailed theoretical analysis of the generalization gap that measures the degree of non-IID in the data distribution is presented. Following that, solutions to address the challenges posed by non-IID conditions are proposed with the analysis of the properties. Specifically, users' data distributions are parameterized as concentration parameters and grouped using spectral clustering, with Dirichlet distribution serving as the prior. The investigation into the generalization gap and convergence rate guides the design of sub-channel assignments through the matching-based algorithm, and the power allocation is achieved by Karush-Kuhn-Tucker (KKT) conditions with the derived closed-form solution. The extensive simulation results show that the proposed cluster-based FL framework can outperform FL baselines in terms of both test accuracy and convergence rate. Moreover, jointly optimizing sub-channel and power allocation in NOMA-enhanced networks can lead to a significant improvement.
TinyGC-Net: An Extremely Tiny Network for Calibrating MEMS Gyroscopes
Mar 05, 2024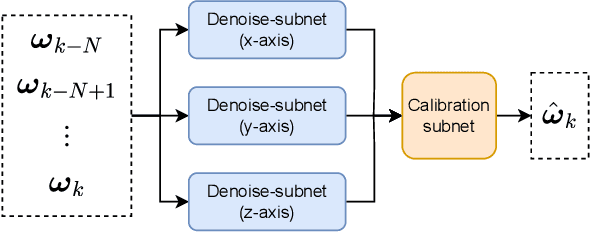
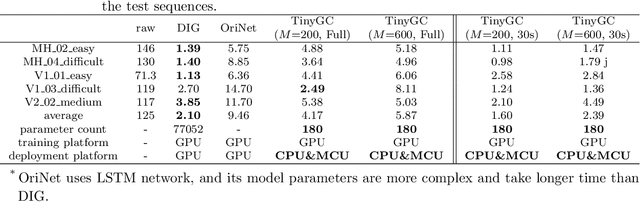
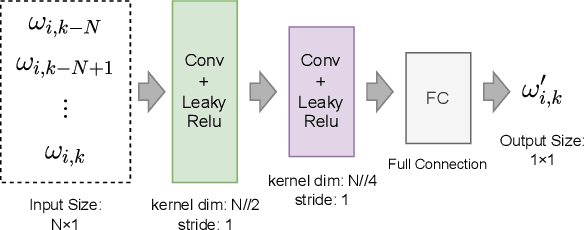
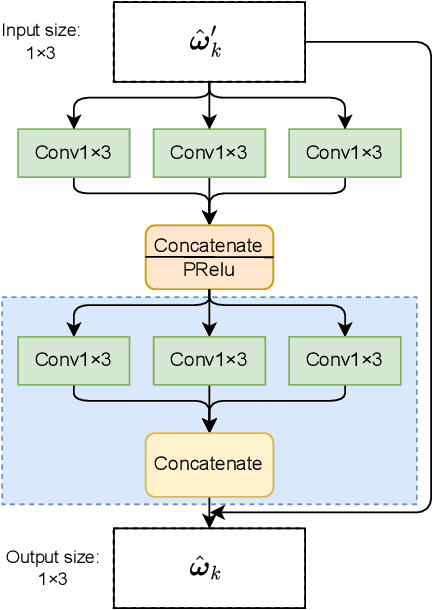
As the errors of microelectromechanical system (MEMS) gyroscopes are complex and nonlinear, the current calibration methods, which rely on linear models or networks with numerous parameters, are inadequate for low-cost embedded computing platforms to achieve both precision and real-time performance. In this paper, we introduce a extremely tiny network (TGC-Net) that characterizes the measurement model of MEMS gyroscopes. The network has a small number of parameters and can be trained on a central processing unit (CPU) before being deployed on a microcontroller unit (MCU). The TGC-Net leverage the robust data processing capabilities of deep learning to derive a nonlinear measurement model from fragmented gyroscope data. Subsequently, this model is used to regress errors on the gyroscope data. Moreover, we analyze the relationship between the compact network and the traditional linear model for MEMS gyroscopes, and emphasize the significance of the adequate angular motion stimulation for train the network. The experimental results, based on public datasets and real-world scenarios, demonstrate the practicality and effectiveness of the proposed method. These findings suggest that this technique is a viable candidate for applications that require MEMS gyroscopes.
FastOcc: Accelerating 3D Occupancy Prediction by Fusing the 2D Bird's-Eye View and Perspective View
Mar 05, 2024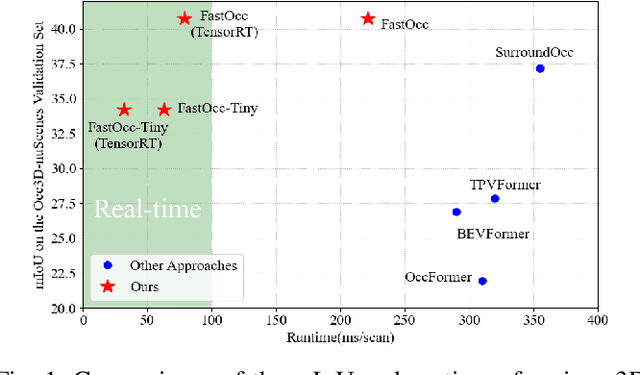
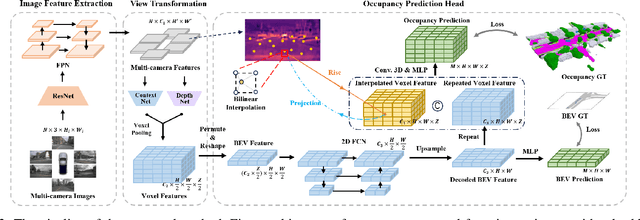
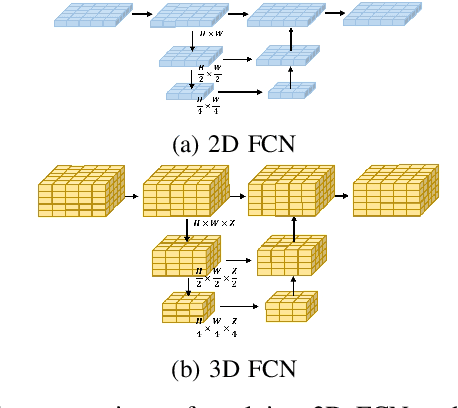
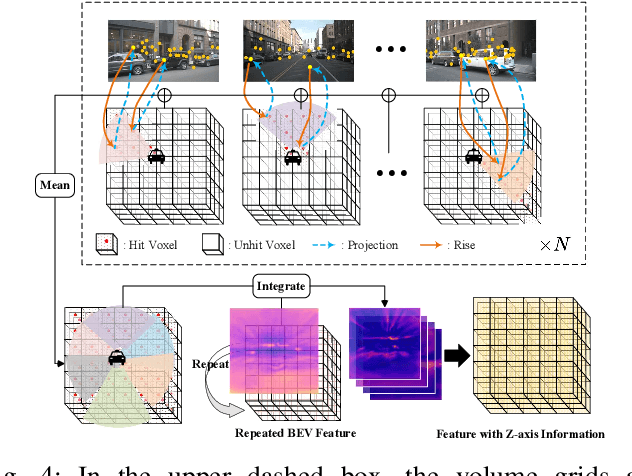
In autonomous driving, 3D occupancy prediction outputs voxel-wise status and semantic labels for more comprehensive understandings of 3D scenes compared with traditional perception tasks, such as 3D object detection and bird's-eye view (BEV) semantic segmentation. Recent researchers have extensively explored various aspects of this task, including view transformation techniques, ground-truth label generation, and elaborate network design, aiming to achieve superior performance. However, the inference speed, crucial for running on an autonomous vehicle, is neglected. To this end, a new method, dubbed FastOcc, is proposed. By carefully analyzing the network effect and latency from four parts, including the input image resolution, image backbone, view transformation, and occupancy prediction head, it is found that the occupancy prediction head holds considerable potential for accelerating the model while keeping its accuracy. Targeted at improving this component, the time-consuming 3D convolution network is replaced with a novel residual-like architecture, where features are mainly digested by a lightweight 2D BEV convolution network and compensated by integrating the 3D voxel features interpolated from the original image features. Experiments on the Occ3D-nuScenes benchmark demonstrate that our FastOcc achieves state-of-the-art results with a fast inference speed.
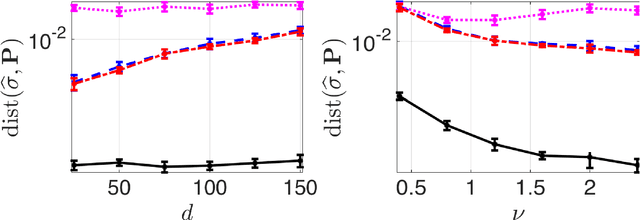
Matrix Completion with Convex Optimization and Column Subset Selection
Mar 05, 2024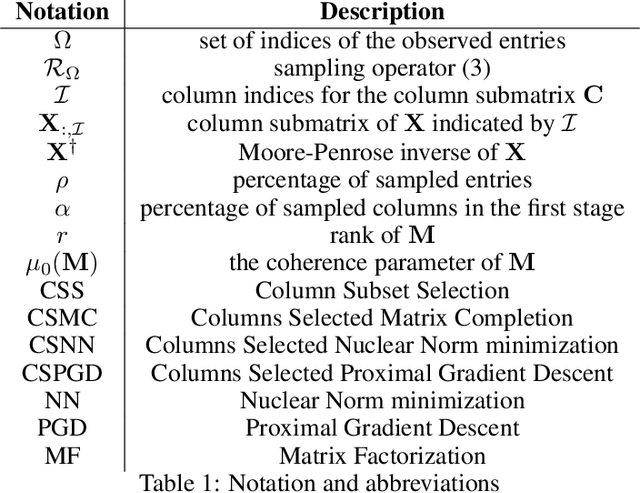
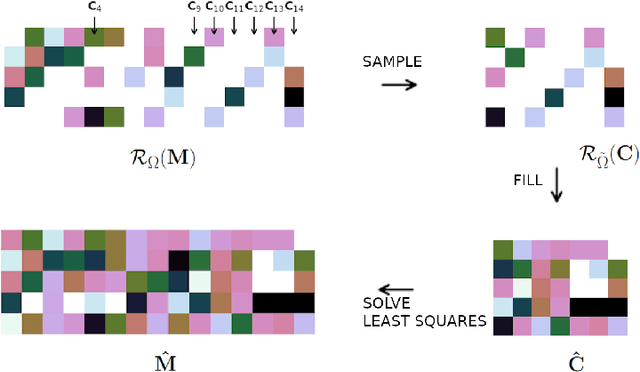
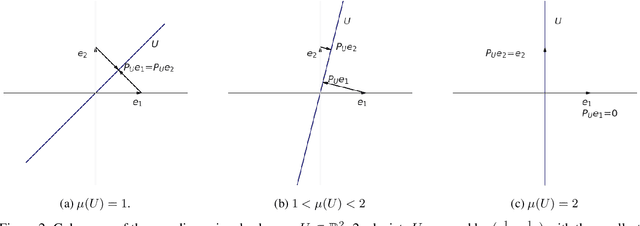
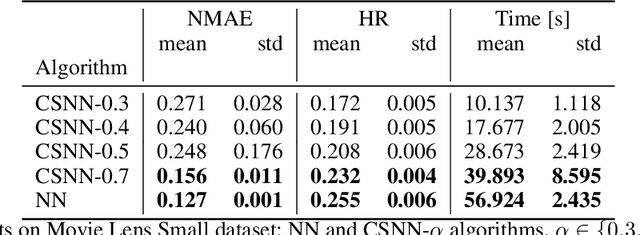
We introduce a two-step method for the matrix recovery problem. Our approach combines the theoretical foundations of the Column Subset Selection and Low-rank Matrix Completion problems. The proposed method, in each step, solves a convex optimization task. We present two algorithms that implement our Columns Selected Matrix Completion (CSMC) method, each dedicated to a different size problem. We performed a formal analysis of the presented method, in which we formulated the necessary assumptions and the probability of finding a correct solution. In the second part of the paper, we present the results of the experimental work. Numerical experiments verified the correctness and performance of the algorithms. To study the influence of the matrix size, rank, and the proportion of missing elements on the quality of the solution and the computation time, we performed experiments on synthetic data. The presented method was applied to two real-life problems problems: prediction of movie rates in a recommendation system and image inpainting. Our thorough analysis shows that CSMC provides solutions of comparable quality to matrix completion algorithms, which are based on convex optimization. However, CSMC offers notable savings in terms of runtime.