 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Performance Deterioration of Deep Learning Models after Clinical Deployment: A Case Study with Auto-segmentation for Definitive Prostate Cancer Radiotherapy
Oct 11, 2022
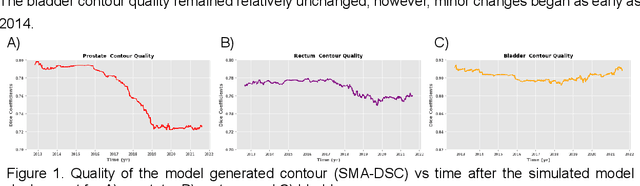
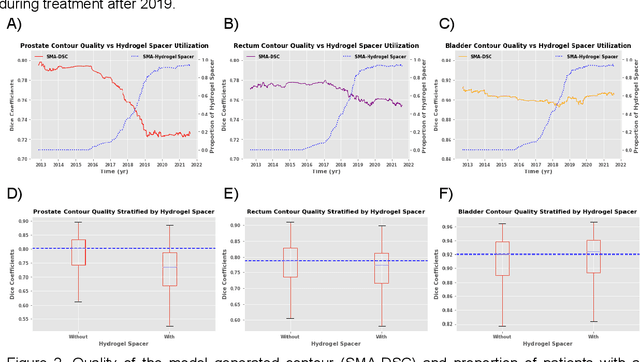
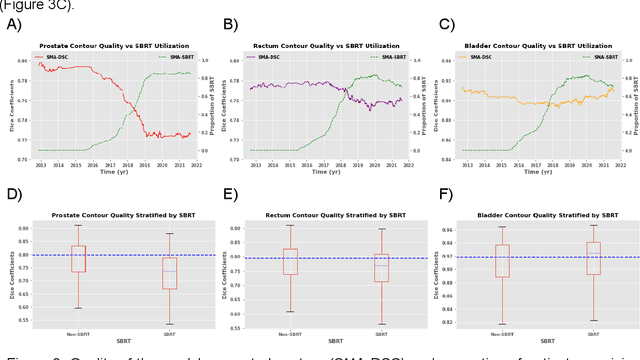
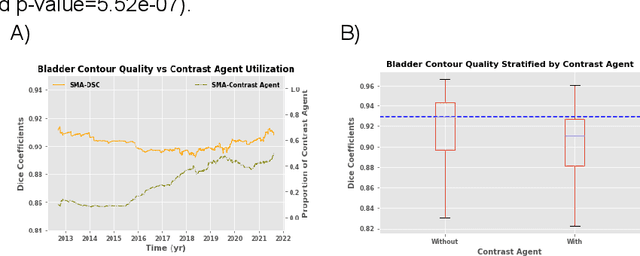
In the past decade, deep learning (DL)-based artificial intelligence (AI) has witnessed unprecedented success and has led to much excitement in medicine. However, many successful models have not been implemented in the clinic predominantly due to concerns regarding the lack of interpretability and generalizability in both spatial and temporal domains. In this work, we used a DL-based auto segmentation model for intact prostate patients to observe any temporal performance changes and then correlate them to possible explanatory variables. We retrospectively simulated the clinical implementation of our DL model to investigate temporal performance trends. Our cohort included 912 patients with prostate cancer treated with definitive radiotherapy from January 2006 to August 2021 at the University of Texas Southwestern Medical Center (UTSW). We trained a U-Net-based DL auto segmentation model on the data collected before 2012 and tested it on data collected from 2012 to 2021 to simulate the clinical deployment of the trained model starting in 2012. We visualize the trends using a simple moving average curve and used ANOVA and t-test to investigate the impact of various clinical factors. The prostate and rectum contour quality decreased rapidly after 2016-2017. Stereotactic body radiotherapy (SBRT) and hydrogel spacer use were significantly associated with prostate contour quality (p=5.6e-12 and 0.002, respectively). SBRT and physicians' styles are significantly associated with the rectum contour quality (p=0.0005 and 0.02, respectively). Only the presence of contrast within the bladder significantly affected the bladder contour quality (p=1.6e-7). We showed that DL model performance decreased over time in concordance with changes in clinical practice patterns and changes in clinical personnel.
Understanding or Manipulation: Rethinking Online Performance Gains of Modern Recommender Systems
Oct 11, 2022

Recommender systems are expected to be assistants that help human users find relevant information in an automatic manner without explicit queries. As recommender systems evolve, increasingly sophisticated learning techniques are applied and have achieved better performance in terms of user engagement metrics such as clicks and browsing time. The increase of the measured performance, however, can have two possible attributions: a better understanding of user preferences, and a more proactive ability to utilize human bounded rationality to seduce user over-consumption. A natural following question is whether current recommendation algorithms are manipulating user preferences. If so, can we measure the manipulation level? In this paper, we present a general framework for benchmarking the degree of manipulations of recommendation algorithms, in both slate recommendation and sequential recommendation scenarios. The framework consists of three stages, initial preference calculation, algorithm training and interaction, and metrics calculation that involves two proposed metrics, Manipulation Score and Preference Shift. We benchmark some representative recommendation algorithms in both synthetic and real-world datasets under the proposed framework. We have observed that a high online click-through rate does not mean a better understanding of user initial preference, but ends in prompting users to choose more documents they initially did not favor. Moreover, we find that the properties of training data have notable impacts on the manipulation degrees, and algorithms with more powerful modeling abilities are more sensitive to such impacts. The experiments also verified the usefulness of the proposed metrics for measuring the degree of manipulations. We advocate that future recommendation algorithm studies should be treated as an optimization problem with constrained user preference manipulations.
Asymptotically Unbiased Instance-wise Regularized Partial AUC Optimization: Theory and Algorithm
Oct 11, 2022
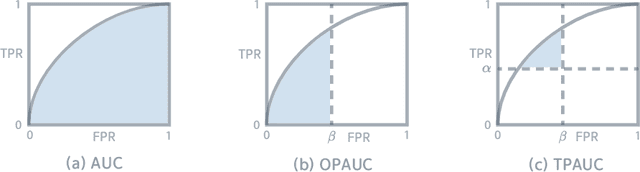
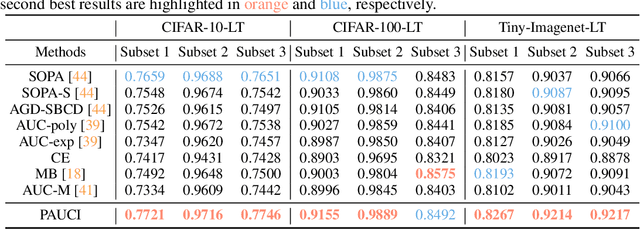
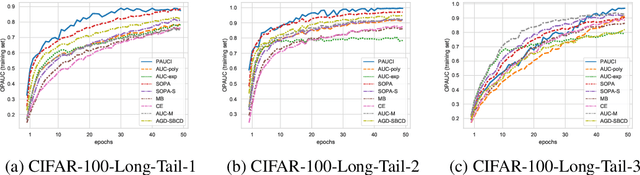
The Partial Area Under the ROC Curve (PAUC), typically including One-way Partial AUC (OPAUC) and Two-way Partial AUC (TPAUC), measures the average performance of a binary classifier within a specific false positive rate and/or true positive rate interval, which is a widely adopted measure when decision constraints must be considered. Consequently, PAUC optimization has naturally attracted increasing attention in the machine learning community within the last few years. Nonetheless, most of the existing methods could only optimize PAUC approximately, leading to inevitable biases that are not controllable. Fortunately, a recent work presents an unbiased formulation of the PAUC optimization problem via distributional robust optimization. However, it is based on the pair-wise formulation of AUC, which suffers from the limited scalability w.r.t. sample size and a slow convergence rate, especially for TPAUC. To address this issue, we present a simpler reformulation of the problem in an asymptotically unbiased and instance-wise manner. For both OPAUC and TPAUC, we come to a nonconvex strongly concave minimax regularized problem of instance-wise functions. On top of this, we employ an efficient solver enjoys a linear per-iteration computational complexity w.r.t. the sample size and a time-complexity of $O(\epsilon^{-1/3})$ to reach a $\epsilon$ stationary point. Furthermore, we find that the minimax reformulation also facilitates the theoretical analysis of generalization error as a byproduct. Compared with the existing results, we present new error bounds that are much easier to prove and could deal with hypotheses with real-valued outputs. Finally, extensive experiments on several benchmark datasets demonstrate the effectiveness of our method.
Fault Diagnosis using eXplainable AI: a Transfer Learning-based Approach for Rotating Machinery exploiting Augmented Synthetic Data
Oct 11, 2022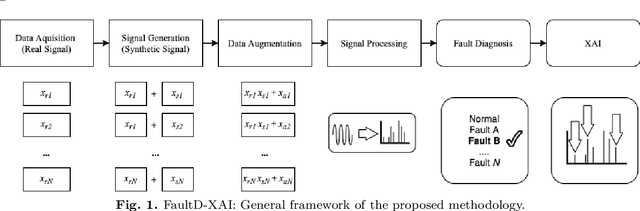
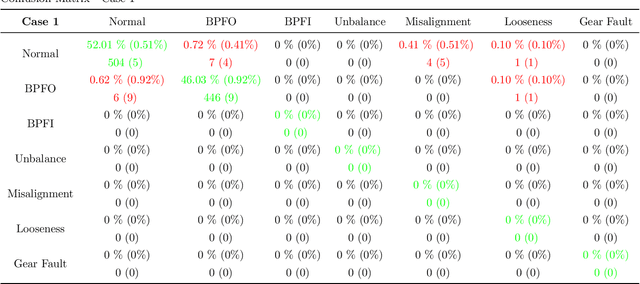

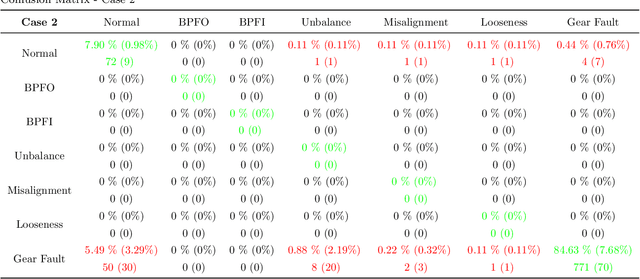
Artificial Intelligence (AI) is one of the approaches that has been proposed to analyze the collected data (e.g., vibration signals) providing a diagnosis of the asset's operating condition. It is known that models trained with labeled data (supervised) achieve excellent results, but two main problems make their application in production processes difficult: (i) impossibility or long time to obtain a sample of all operational conditions (since faults seldom happen) and (ii) high cost of experts to label all acquired data. Another limitating factor for the applicability of AI approaches in this context is the lack of interpretability of the models (black-boxes), which reduces the confidence of the diagnosis and trust/adoption from users. To overcome these problems, a new generic and interpretable approach for classifying faults in rotating machinery based on transfer learning from augmented synthetic data to real rotating machinery is here proposed, namelly FaultD-XAI (Fault Diagnosis using eXplainable AI). To provide scalability using transfer learning, synthetic vibration signals are created mimicking the characteristic behavior of failures in operation. The application of Gradient-weighted Class Activation Mapping (Grad-CAM) with 1D Convolutional Neural Network (1D CNN) allows the interpretation of results, supporting the user in decision making and increasing diagnostic confidence. The proposed approach not only obtained promising diagnostic performance, but was also able to learn characteristics used by experts to identify conditions in a source domain and apply them in another target domain. The experimental results suggest a promising approach on exploiting transfer learning, synthetic data and explainable artificial intelligence for fault diagnosis. Lastly, to guarantee reproducibility and foster research in the field, the developed dataset is made publicly available.
Repainting and Imitating Learning for Lane Detection
Oct 11, 2022

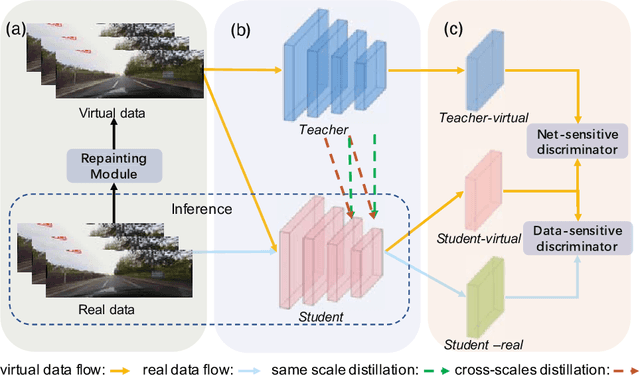
Current lane detection methods are struggling with the invisibility lane issue caused by heavy shadows, severe road mark degradation, and serious vehicle occlusion. As a result, discriminative lane features can be barely learned by the network despite elaborate designs due to the inherent invisibility of lanes in the wild. In this paper, we target at finding an enhanced feature space where the lane features are distinctive while maintaining a similar distribution of lanes in the wild. To achieve this, we propose a novel Repainting and Imitating Learning (RIL) framework containing a pair of teacher and student without any extra data or extra laborious labeling. Specifically, in the repainting step, an enhanced ideal virtual lane dataset is built in which only the lane regions are repainted while non-lane regions are kept unchanged, maintaining the similar distribution of lanes in the wild. The teacher model learns enhanced discriminative representation based on the virtual data and serves as the guidance for a student model to imitate. In the imitating learning step, through the scale-fusing distillation module, the student network is encouraged to generate features that mimic the teacher model both on the same scale and cross scales. Furthermore, the coupled adversarial module builds the bridge to connect not only teacher and student models but also virtual and real data, adjusting the imitating learning process dynamically. Note that our method introduces no extra time cost during inference and can be plug-and-play in various cutting-edge lane detection networks. Experimental results prove the effectiveness of the RIL framework both on CULane and TuSimple for four modern lane detection methods. The code and model will be available soon.
ConserWeightive Behavioral Cloning for Reliable Offline Reinforcement Learning
Oct 11, 2022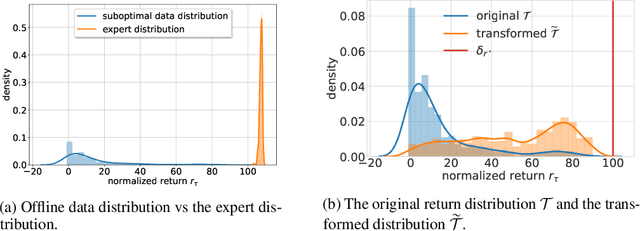
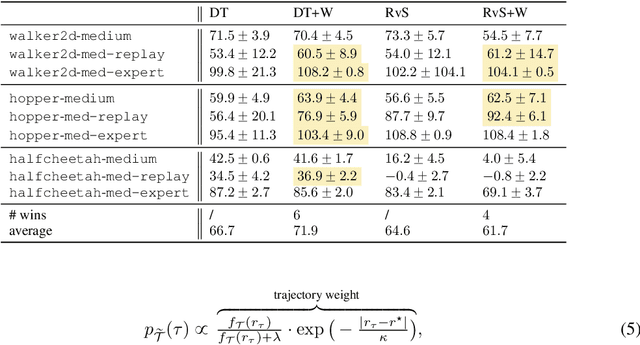
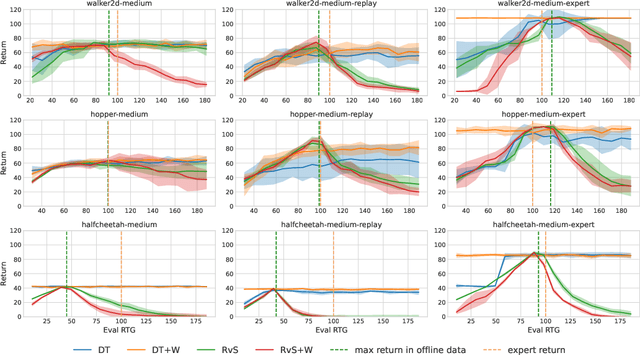
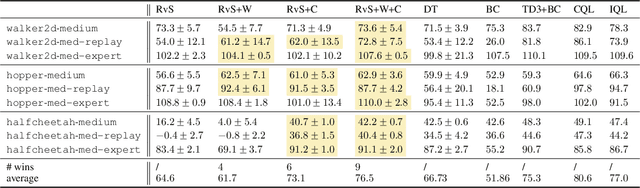
The goal of offline reinforcement learning (RL) is to learn near-optimal policies from static logged datasets, thus sidestepping expensive online interactions. Behavioral cloning (BC) provides a straightforward solution to offline RL by mimicking offline trajectories via supervised learning. Recent advances (Chen et al., 2021; Janner et al., 2021; Emmons et al., 2021) have shown that by conditioning on desired future returns, BC can perform competitively to their value-based counterparts, while enjoying much more simplicity and training stability. However, the distribution of returns in the offline dataset can be arbitrarily skewed and suboptimal, which poses a unique challenge for conditioning BC on expert returns at test time. We propose ConserWeightive Behavioral Cloning (CWBC), a simple and effective method for improving the performance of conditional BC for offline RL with two key components: trajectory weighting and conservative regularization. Trajectory weighting addresses the bias-variance tradeoff in conditional BC and provides a principled mechanism to learn from both low return trajectories (typically plentiful) and high return trajectories (typically few). Further, we analyze the notion of conservatism in existing BC methods, and propose a novel conservative regularize that explicitly encourages the policy to stay close to the data distribution. The regularizer helps achieve more reliable performance, and removes the need for ad-hoc tuning of the conditioning value during evaluation. We instantiate CWBC in the context of Reinforcement Learning via Supervised Learning (RvS) (Emmons et al., 2021) and Decision Transformer (DT) (Chen et al., 2021), and empirically show that it significantly boosts the performance and stability of prior methods on various offline RL benchmarks. Code is available at https://github.com/tung-nd/cwbc.
Digital Twin and Artificial Intelligence Incorporated With Surrogate Modeling for Hybrid and Sustainable Energy Systems
Sep 30, 2022
Surrogate modeling has brought about a revolution in computation in the branches of science and engineering. Backed by Artificial Intelligence, a surrogate model can present highly accurate results with a significant reduction in computation time than computer simulation of actual models. Surrogate modeling techniques have found their use in numerous branches of science and engineering, energy system modeling being one of them. Since the idea of hybrid and sustainable energy systems is spreading rapidly in the modern world for the paradigm of the smart energy shift, researchers are exploring the future application of artificial intelligence-based surrogate modeling in analyzing and optimizing hybrid energy systems. One of the promising technologies for assessing applicability for the energy system is the digital twin, which can leverage surrogate modeling. This work presents a comprehensive framework/review on Artificial Intelligence-driven surrogate modeling and its applications with a focus on the digital twin framework and energy systems. The role of machine learning and artificial intelligence in constructing an effective surrogate model is explained. After that, different surrogate models developed for different sustainable energy sources are presented. Finally, digital twin surrogate models and associated uncertainties are described.
Accelerating hypersonic reentry simulations using deep learning-based hybridization (with guarantees)
Sep 30, 2022

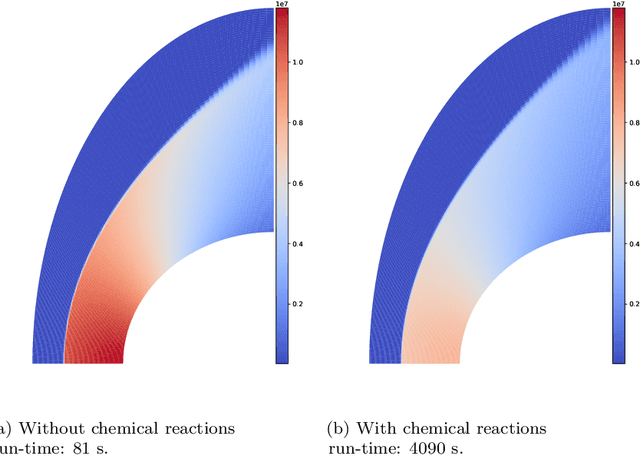
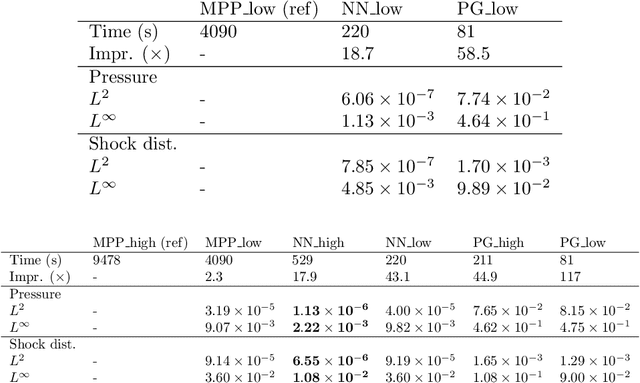
In this paper, we are interested in the acceleration of numerical simulations. We focus on a hypersonic planetary reentry problem whose simulation involves coupling fluid dynamics and chemical reactions. Simulating chemical reactions takes most of the computational time but, on the other hand, cannot be avoided to obtain accurate predictions. We face a trade-off between cost-efficiency and accuracy: the simulation code has to be sufficiently efficient to be used in an operational context but accurate enough to predict the phenomenon faithfully. To tackle this trade-off, we design a hybrid simulation code coupling a traditional fluid dynamic solver with a neural network approximating the chemical reactions. We rely on their power in terms of accuracy and dimension reduction when applied in a big data context and on their efficiency stemming from their matrix-vector structure to achieve important acceleration factors ($\times 10$ to $\times 18.6$). This paper aims to explain how we design such cost-effective hybrid simulation codes in practice. Above all, we describe methodologies to ensure accuracy guarantees, allowing us to go beyond traditional surrogate modeling and to use these codes as references.
Blockchain-based Monitoring for Poison Attack Detection in Decentralized Federated Learning
Sep 30, 2022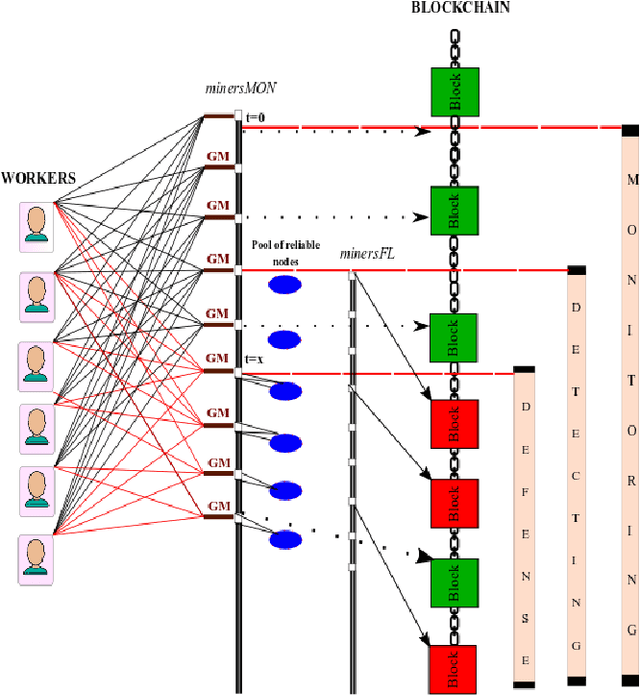
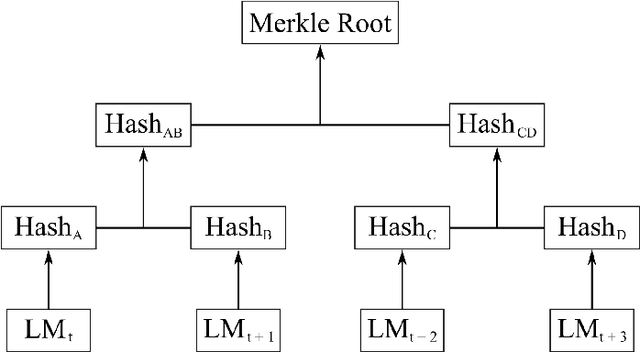
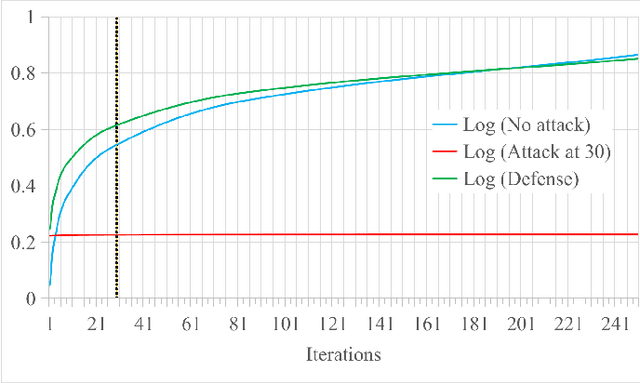
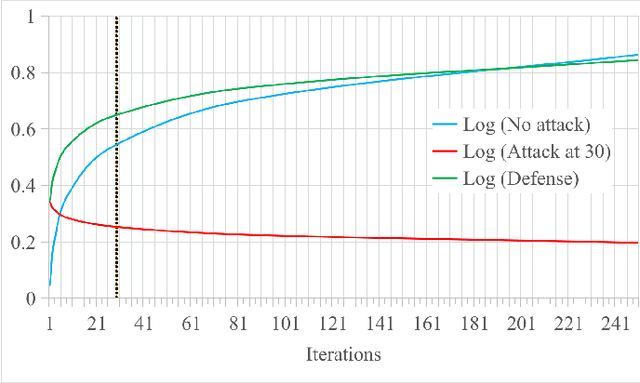
Federated Learning (FL) is a machine learning technique that addresses the privacy challenges in terms of access rights of local datasets by enabling the training of a model across nodes holding their data samples locally. To achieve decentralized federated learning, blockchain-based FL was proposed as a distributed FL architecture. In decentralized FL, the chief is eliminated from the learning process as workers collaborate between each other to train the global model. Decentralized FL applications need to account for the additional delay incurred by blockchain-based FL deployments. Particularly in this setting, to detect targeted/untargeted poisoning attacks, we investigate the end-to-end learning completion latency of a realistic decentralized FL process protected against poisoning attacks. We propose a technique which consists in decoupling the monitoring phase from the detection phase in defenses against poisoning attacks in a decentralized federated learning deployment that aim at monitoring the behavior of the workers. We demonstrate that our proposed blockchain-based monitoring improved network scalability, robustness and time efficiency. The parallelization of operations results in minimized latency over the end-to-end communication, computation, and consensus delays incurred during the FL and blockchain operations.
Machine Unlearning Method Based On Projection Residual
Sep 30, 2022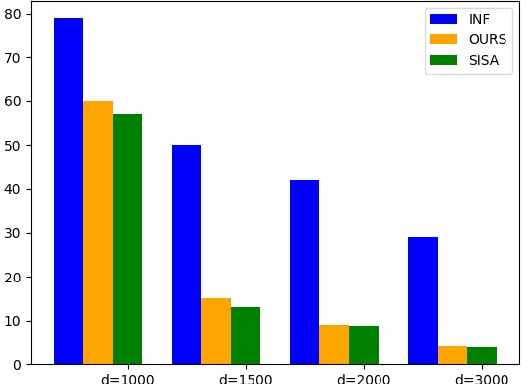
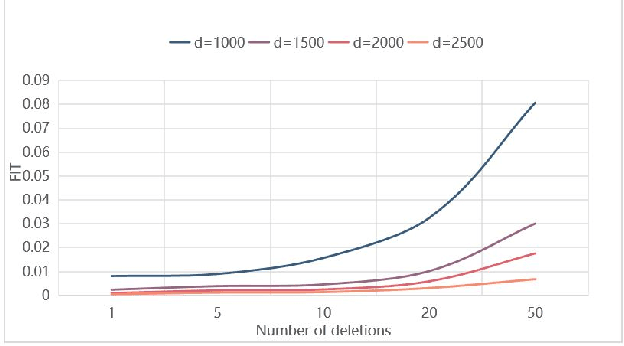
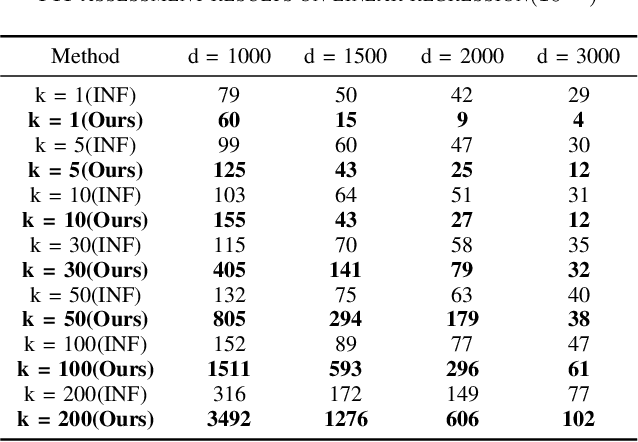

Machine learning models (mainly neural networks) are used more and more in real life. Users feed their data to the model for training. But these processes are often one-way. Once trained, the model remembers the data. Even when data is removed from the dataset, the effects of these data persist in the model. With more and more laws and regulations around the world protecting data privacy, it becomes even more important to make models forget this data completely through machine unlearning. This paper adopts the projection residual method based on Newton iteration method. The main purpose is to implement machine unlearning tasks in the context of linear regression models and neural network models. This method mainly uses the iterative weighting method to completely forget the data and its corresponding influence, and its computational cost is linear in the feature dimension of the data. This method can improve the current machine learning method. At the same time, it is independent of the size of the training set. Results were evaluated by feature injection testing (FIT). Experiments show that this method is more thorough in deleting data, which is close to model retraining.