 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Pathologist-Informed Workflow for Classification of Prostate Glands in Histopathology
Sep 27, 2022
Pathologists diagnose and grade prostate cancer by examining tissue from needle biopsies on glass slides. The cancer's severity and risk of metastasis are determined by the Gleason grade, a score based on the organization and morphology of prostate cancer glands. For diagnostic work-up, pathologists first locate glands in the whole biopsy core, and -- if they detect cancer -- they assign a Gleason grade. This time-consuming process is subject to errors and significant inter-observer variability, despite strict diagnostic criteria. This paper proposes an automated workflow that follows pathologists' \textit{modus operandi}, isolating and classifying multi-scale patches of individual glands in whole slide images (WSI) of biopsy tissues using distinct steps: (1) two fully convolutional networks segment epithelium versus stroma and gland boundaries, respectively; (2) a classifier network separates benign from cancer glands at high magnification; and (3) an additional classifier predicts the grade of each cancer gland at low magnification. Altogether, this process provides a gland-specific approach for prostate cancer grading that we compare against other machine-learning-based grading methods.
* Published as a workshop paper at MICCAI MOVI 2022
Rmagine: 3D Range Sensor Simulation in Polygonal Maps via Raytracing for Embedded Hardware on Mobile Robots
Sep 27, 2022
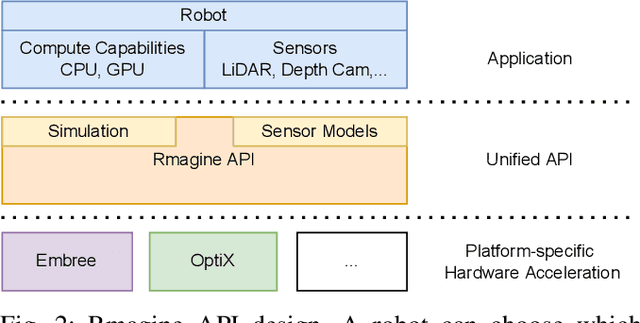
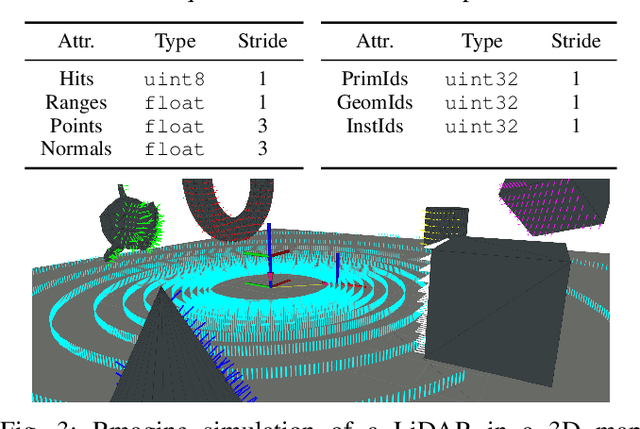
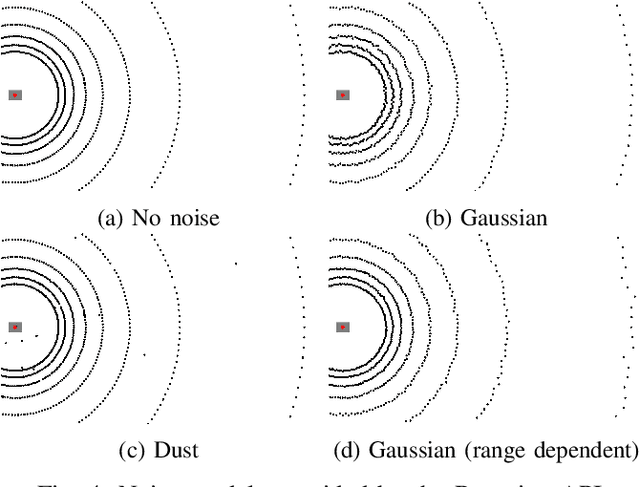
Sensor simulation has emerged as a promising and powerful technique to find solutions to many real-world robotic tasks like localization and pose tracking.However, commonly used simulators have high hardware requirements and are therefore used mostly on high-end computers. In this paper, we present an approach to simulate range sensors directly on embedded hardware of mobile robots that use triangle meshes as environment map. This library called Rmagine allows a robot to simulate sensor data for arbitrary range sensors directly on board via raytracing. Since robots typically only have limited computational resources, the Rmagine aims at being flexible and lightweight, while scaling well even to large environment maps. It runs on several platforms like Laptops or embedded computing boards like Nvidia Jetson by putting an unified API over the specific proprietary libraries provided by the hardware manufacturers. This work is designed to support the future development of robotic applications depending on simulation of range data that could previously not be computed in reasonable time on mobile systems.
Multi-Field De-interlacing using Deformable Convolution Residual Blocks and Self-Attention
Sep 21, 2022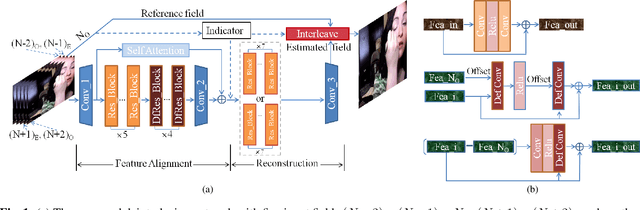
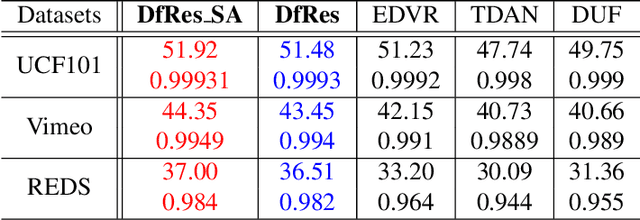
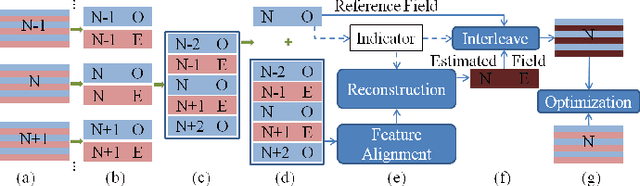

Although deep learning has made significant impact on image/video restoration and super-resolution, learned deinterlacing has so far received less attention in academia or industry. This is despite deinterlacing is well-suited for supervised learning from synthetic data since the degradation model is known and fixed. In this paper, we propose a novel multi-field full frame-rate deinterlacing network, which adapts the state-of-the-art superresolution approaches to the deinterlacing task. Our model aligns features from adjacent fields to a reference field (to be deinterlaced) using both deformable convolution residual blocks and self attention. Our extensive experimental results demonstrate that the proposed method provides state-of-the-art deinterlacing results in terms of both numerical and perceptual performance. At the time of writing, our model ranks first in the Full FrameRate LeaderBoard at https://videoprocessing.ai/benchmarks/deinterlacer.html
In-situ animal behavior classification using knowledge distillation and fixed-point quantization
Sep 09, 2022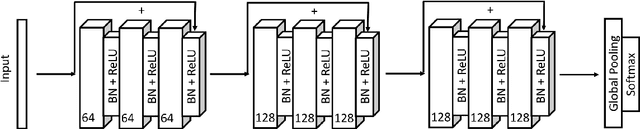
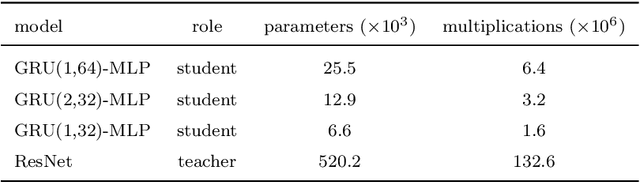
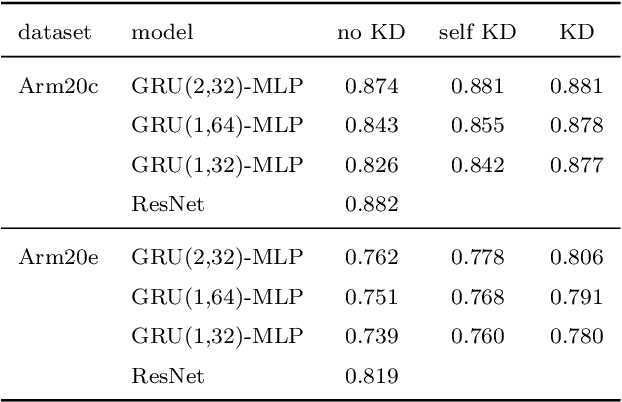
We explore the use of knowledge distillation (KD) for learning compact and accurate models that enable classification of animal behavior from accelerometry data on wearable devices. To this end, we take a deep and complex convolutional neural network, known as residual neural network (ResNet), as the teacher model. ResNet is specifically designed for multivariate time-series classification. We use ResNet to distil the knowledge of animal behavior classification datasets into soft labels, which consist of the predicted pseudo-probabilities of every class for each datapoint. We then use the soft labels to train our significantly less complex student models, which are based on the gated recurrent unit (GRU) and multilayer perceptron (MLP). The evaluation results using two real-world animal behavior classification datasets show that the classification accuracy of the student GRU-MLP models improves appreciably through KD, approaching that of the teacher ResNet model. To further reduce the computational and memory requirements of performing inference using the student models trained via KD, we utilize dynamic fixed-point quantization through an appropriate modification of the computational graphs of the models. We implement both unquantized and quantized versions of the developed KD-based models on the embedded systems of our purpose-built collar and ear tag devices to classify animal behavior in situ and in real time. The results corroborate the effectiveness of KD and quantization in improving the inference performance in terms of both classification accuracy and computational and memory efficiency.
An Effective Technique for Increasing Capacity and Improving Bandwidth in 5G NB-IoT
Aug 29, 2022
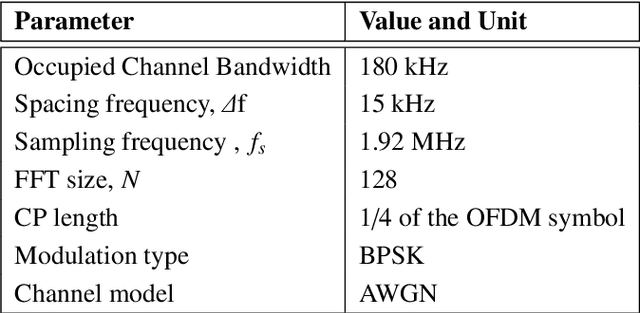
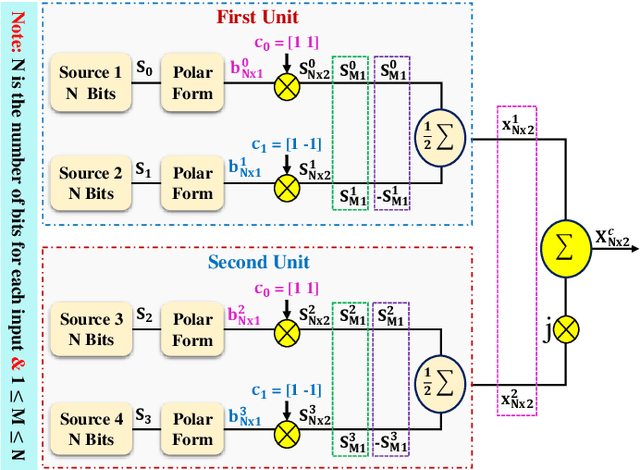

With hundreds of billions of the IoT connected devices, it is important for researchers to create effective resource management approach to satisfy the quality of service (QoS) requirements of 5th generation (5G) and beyond. Furthermore, wireless spectrum is increasingly scarce as demand for wireless services develops, demanding imaginative approaches to increase capacity within a limited spectral resource in order to meet service demands. In this article, the modified symbol time compression (M-STC) technique is suggested to paves the way for 5G networks and beyond to enhance the capacity and throughput. The M-STC method is a compressed signal waveform technique that increases the capacity by compressing the occupied bandwidth without increasing the complexity, losing data throughput or bit error rate (BER) performance. A comparative analysis is provided between the traditional orthogonal frequency division multiplexing (OFDM) system, OFDM using conventional symbol time compression (C-STC-OFDM) and OFDM using the proposed technique (M-STC-OFDM). The simulation results using Matlab-2021a show that the suggested method, M-STC-OFDM, drastically lowers the time needed for each OFDM signal by 75%. As a consequence, the M-STC-OFDM system decreases bandwidth (BW) by 75% when compared to a standard OFDM system (BW_OFDM = 180 kHz and BW_M-STC-OFDM = 45 kHz), while the C-STC-OFDM system reduces BW by 50% (BW_C-STC-OFDM = 90 kHz). Furthermore, using the M-STC-OFDM system reduces peak to average-power-ratio (PAPR) by 2.09 dB when compared to the standard OFDM system and 1.18 dB when compared to C-STC-OFDM with no BER deterioration. Moreover, as compared to the 16QAM-OFDM system, the proposed M-STC-OFDM system reduces the signal-to-noise-ratio (SNR) by 3.8 dB to transmit the same amount of data.
Dynamical Wasserstein Barycenters for Time-series Modeling
Oct 29, 2021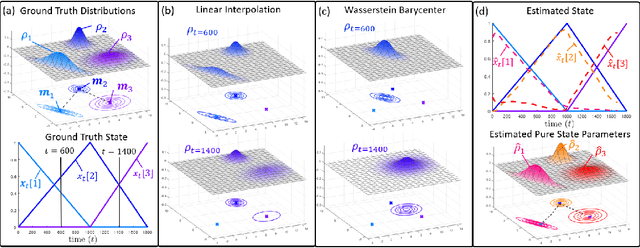
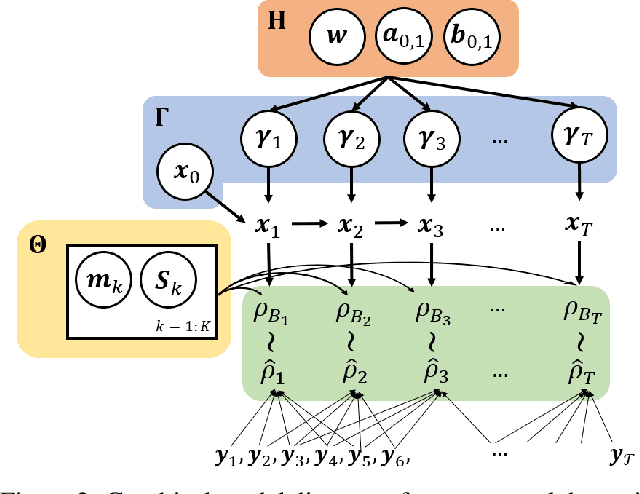
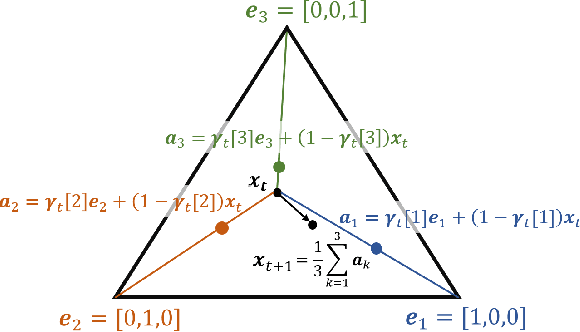
Many time series can be modeled as a sequence of segments representing high-level discrete states, such as running and walking in a human activity application. Flexible models should describe the system state and observations in stationary "pure-state" periods as well as transition periods between adjacent segments, such as a gradual slowdown between running and walking. However, most prior work assumes instantaneous transitions between pure discrete states. We propose a dynamical Wasserstein barycentric (DWB) model that estimates the system state over time as well as the data-generating distributions of pure states in an unsupervised manner. Our model assumes each pure state generates data from a multivariate normal distribution, and characterizes transitions between states via displacement-interpolation specified by the Wasserstein barycenter. The system state is represented by a barycentric weight vector which evolves over time via a random walk on the simplex. Parameter learning leverages the natural Riemannian geometry of Gaussian distributions under the Wasserstein distance, which leads to improved convergence speeds. Experiments on several human activity datasets show that our proposed DWB model accurately learns the generating distribution of pure states while improving state estimation for transition periods compared to the commonly used linear interpolation mixture models.
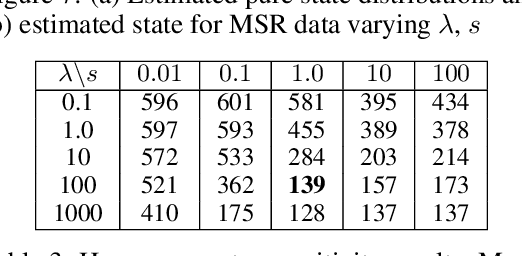
MLT-LE: predicting drug-target binding affinity with multi-task residual neural networks
Sep 13, 2022

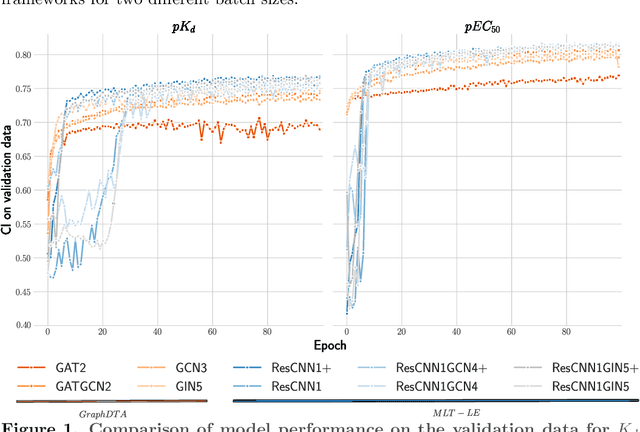
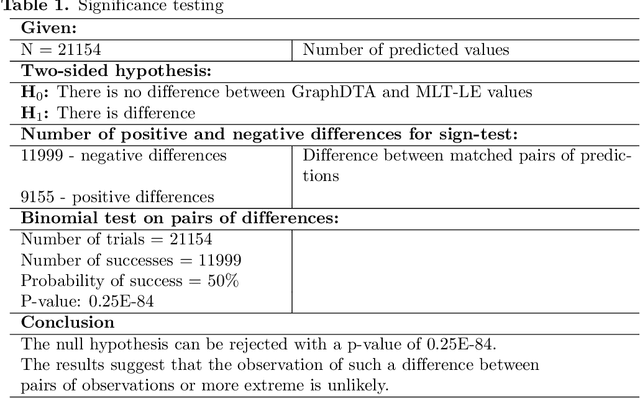
Assessing drug-target affinity is a critical step in the drug discovery and development process, but to obtain such data experimentally is both time consuming and expensive. For this reason, computational methods for predicting binding strength are being widely developed. However, these methods typically use a single-task approach for prediction, thus ignoring the additional information that can be extracted from the data and used to drive the learning process. Thereafter in this work, we present a multi-task approach for binding strength prediction. Our results suggest that these prediction can indeed benefit from a multi-task learning approach, by utilizing added information from related tasks and multi-task induced regularization.
Change Detection for Local Explainability in Evolving Data Streams
Sep 06, 2022
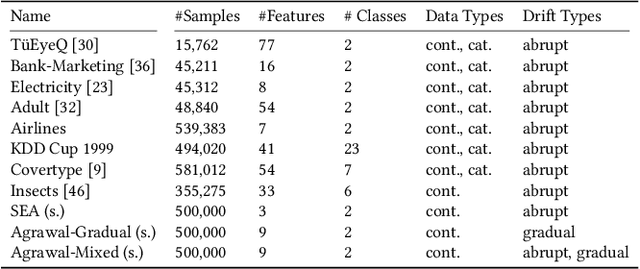
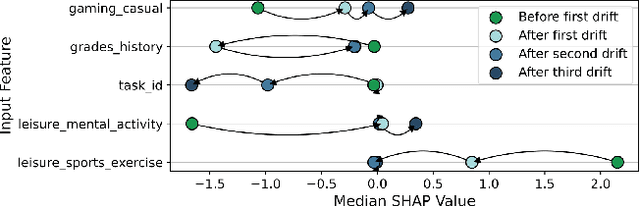
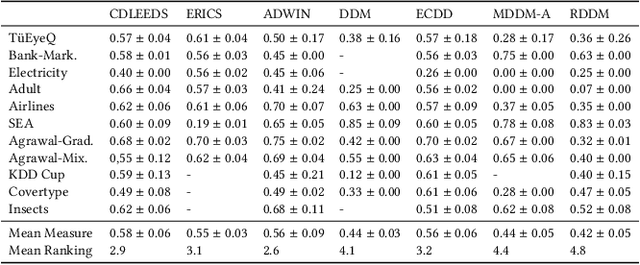
As complex machine learning models are increasingly used in sensitive applications like banking, trading or credit scoring, there is a growing demand for reliable explanation mechanisms. Local feature attribution methods have become a popular technique for post-hoc and model-agnostic explanations. However, attribution methods typically assume a stationary environment in which the predictive model has been trained and remains stable. As a result, it is often unclear how local attributions behave in realistic, constantly evolving settings such as streaming and online applications. In this paper, we discuss the impact of temporal change on local feature attributions. In particular, we show that local attributions can become obsolete each time the predictive model is updated or concept drift alters the data generating distribution. Consequently, local feature attributions in data streams provide high explanatory power only when combined with a mechanism that allows us to detect and respond to local changes over time. To this end, we present CDLEEDS, a flexible and model-agnostic framework for detecting local change and concept drift. CDLEEDS serves as an intuitive extension of attribution-based explanation techniques to identify outdated local attributions and enable more targeted recalculations. In experiments, we also show that the proposed framework can reliably detect both local and global concept drift. Accordingly, our work contributes to a more meaningful and robust explainability in online machine learning.
Using Entropy Measures for Monitoring the Evolution of Activity Patterns
Oct 05, 2022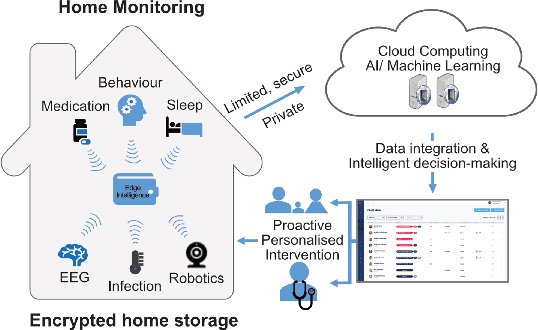
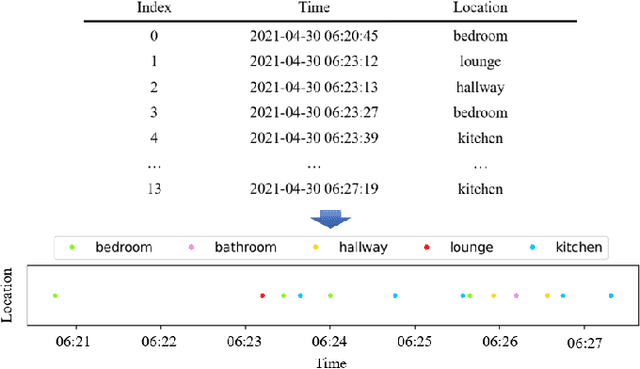
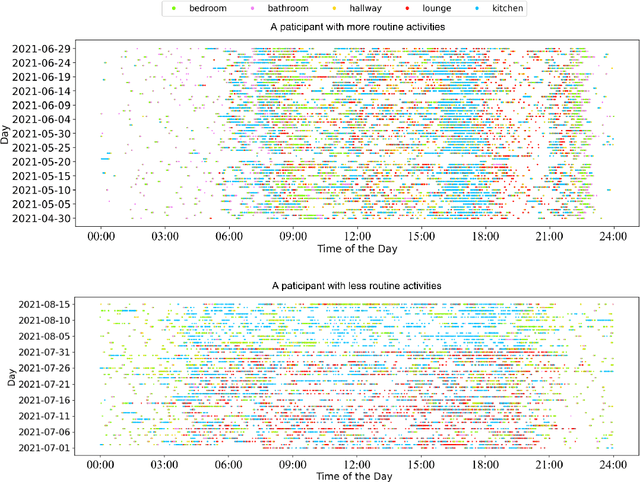
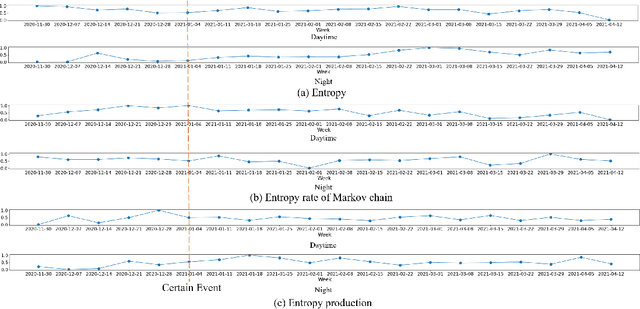
In this work, we apply information theory inspired methods to quantify changes in daily activity patterns. We use in-home movement monitoring data and show how they can help indicate the occurrence of healthcare-related events. Three different types of entropy measures namely Shannon's entropy, entropy rates for Markov chains, and entropy production rate have been utilised. The measures are evaluated on a large-scale in-home monitoring dataset that has been collected within our dementia care clinical study. The study uses Internet of Things (IoT) enabled solutions for continuous monitoring of in-home activity, sleep, and physiology to develop care and early intervention solutions to support people living with dementia (PLWD) in their own homes. Our main goal is to show the applicability of the entropy measures to time-series activity data analysis and to use the extracted measures as new engineered features that can be fed into inference and analysis models. The results of our experiments show that in most cases the combination of these measures can indicate the occurrence of healthcare-related events. We also find that different participants with the same events may have different measures based on one entropy measure. So using a combination of these measures in an inference model will be more effective than any of the single measures.
Frame Interpolation for Dynamic Scenes with Implicit Flow Encoding
Sep 27, 2022
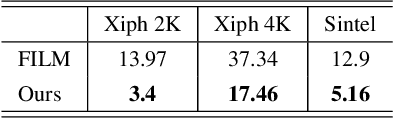
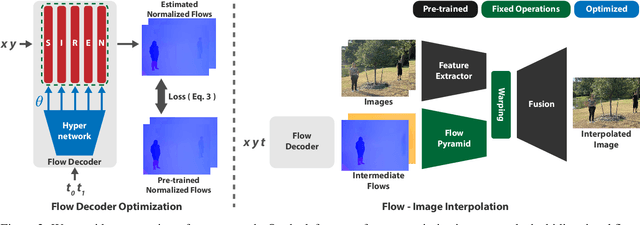
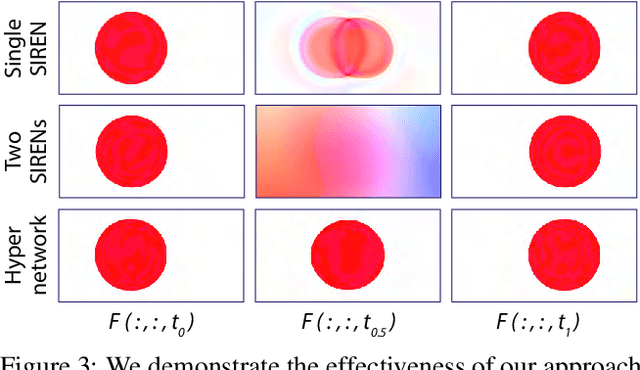
In this paper, we propose an algorithm to interpolate between a pair of images of a dynamic scene. While in the past years significant progress in frame interpolation has been made, current approaches are not able to handle images with brightness and illumination changes, which are common even when the images are captured shortly apart. We propose to address this problem by taking advantage of the existing optical flow methods that are highly robust to the variations in the illumination. Specifically, using the bidirectional flows estimated using an existing pre-trained flow network, we predict the flows from an intermediate frame to the two input images. To do this, we propose to encode the bidirectional flows into a coordinate-based network, powered by a hypernetwork, to obtain a continuous representation of the flow across time. Once we obtain the estimated flows, we use them within an existing blending network to obtain the final intermediate frame. Through extensive experiments, we demonstrate that our approach is able to produce significantly better results than state-of-the-art frame interpolation algorithms.