 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The optimality of word lengths. Theoretical foundations and an empirical study
Aug 28, 2022
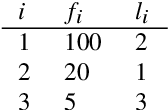
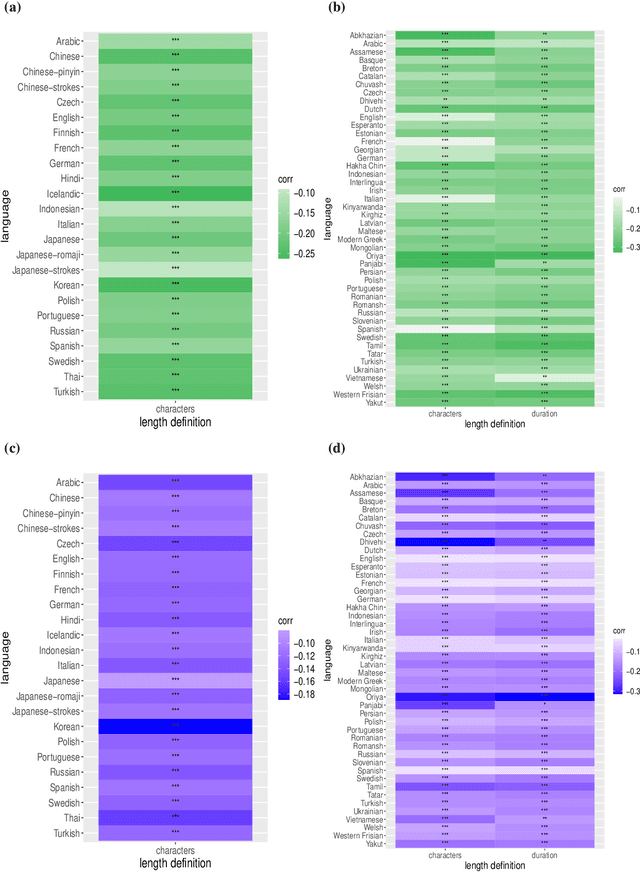
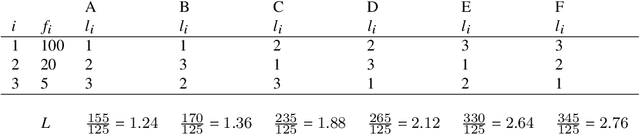
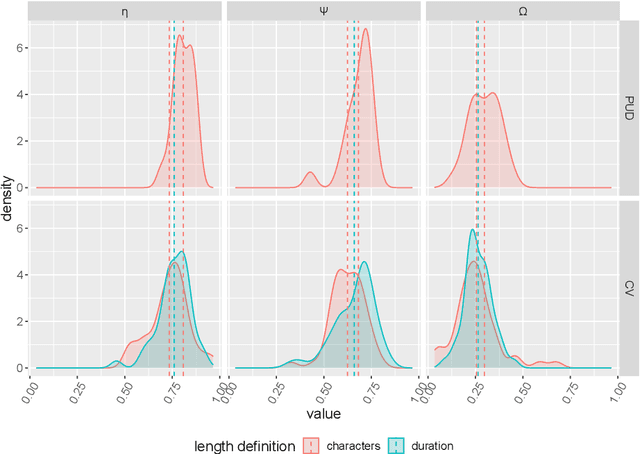
One of the most robust patterns found in human languages is Zipf's law of abbreviation, that is, the tendency of more frequent words to be shorter. Since Zipf's pioneering research, this law has been viewed as a manifestation of compression, i.e. the minimization of the length of forms - a universal principle of natural communication. Although the claim that languages are optimized has become trendy, attempts to measure the degree of optimization of languages have been rather scarce. Here we demonstrate that compression manifests itself in a wide sample of languages without exceptions, and independently of the unit of measurement. It is detectable for both word lengths in characters of written language as well as durations in time in spoken language. Moreover, to measure the degree of optimization, we derive a simple formula for a random baseline and present two scores that are dualy normalized, namely, they are normalized with respect to both the minimum and the random baseline. We analyze the theoretical and statistical pros and cons of these and other scores. Harnessing the best score, we quantify for the first time the degree of optimality of word lengths in languages. This indicates that languages are optimized to 62 or 67 percent on average (depending on the source) when word lengths are measured in characters, and to 65 percent on average when word lengths are measured in time. In general, spoken word durations are more optimized than written word lengths in characters. Beyond the analyses reported here, our work paves the way to measure the degree of optimality of the vocalizations or gestures of other species, and to compare them against written, spoken, or signed human languages.
Exploring the Role of Electro-Tactile and Kinesthetic Feedback in Telemanipulation Task
Aug 30, 2022
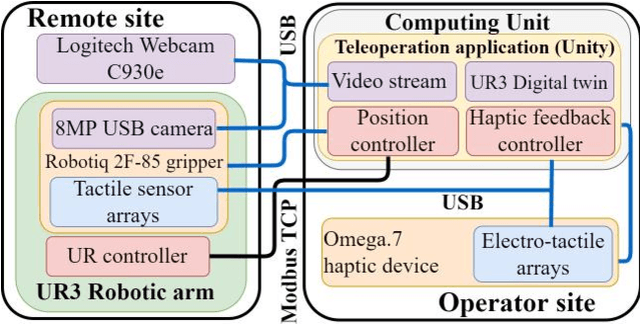


Teleoperation of robotic systems for precise and delicate object grasping requires high-fidelity haptic feedback to obtain comprehensive real-time information about the grasp. In such cases, the most common approach is to use kinesthetic feedback. However, a single contact point information is insufficient to detect the dynamically changing shape of soft objects. This paper proposes a novel telemanipulation system that provides kinesthetic and cutaneous stimuli to the user's hand to achieve accurate liquid dispensing by dexterously manipulating the deformable object (i.e., pipette). The experimental results revealed that the proposed approach to provide the user with multimodal haptic feedback considerably improves the quality of dosing with a remote pipette. Compared with pure visual feedback, the relative dosing error decreased by 66\% and task execution time decreased by 18\% when users manipulated the deformable pipette with a multimodal haptic interface in combination with visual feedback. The proposed technology can be potentially implemented in delicate dosing procedures during the antibody tests for COVID-19, chemical experiments, operation with organic materials, and telesurgery.
Using Full-Text Content to Characterize and Identify Best Seller Books
Oct 05, 2022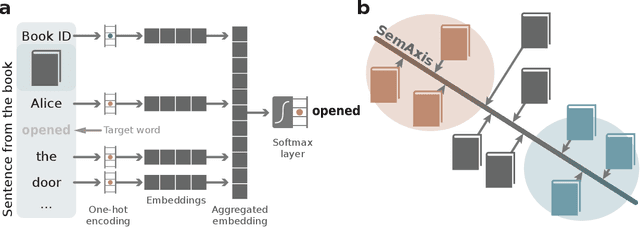
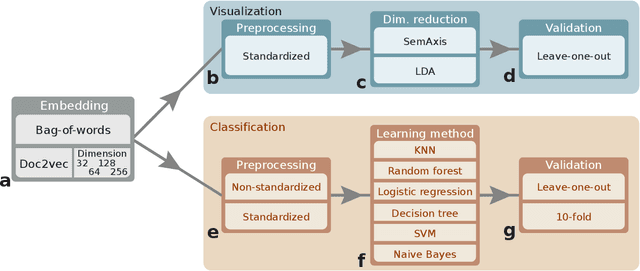
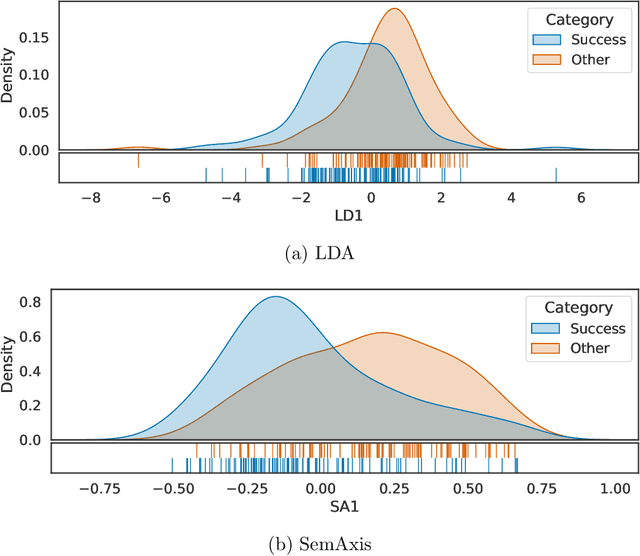
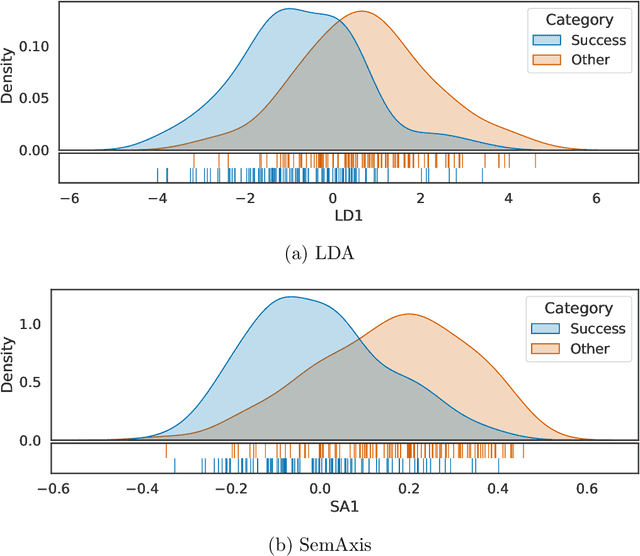
Artistic pieces can be studied from several perspectives, one example being their reception among readers over time. In the present work, we approach this interesting topic from the standpoint of literary works, particularly assessing the task of predicting whether a book will become a best seller. Dissimilarly from previous approaches, we focused on the full content of books and considered visualization and classification tasks. We employed visualization for the preliminary exploration of the data structure and properties, involving SemAxis and linear discriminant analyses. Then, to obtain quantitative and more objective results, we employed various classifiers. Such approaches were used along with a dataset containing (i) books published from 1895 to 1924 and consecrated as best sellers by the \emph{Publishers Weekly Bestseller Lists} and (ii) literary works published in the same period but not being mentioned in that list. Our comparison of methods revealed that the best-achieved result - combining a bag-of-words representation with a logistic regression classifier - led to an average accuracy of 0.75 both for the leave-one-out and 10-fold cross-validations. Such an outcome suggests that it is unfeasible to predict the success of books with high accuracy using only the full content of the texts. Nevertheless, our findings provide insights into the factors leading to the relative success of a literary work.
Revisiting Graph Contrastive Learning from the Perspective of Graph Spectrum
Oct 05, 2022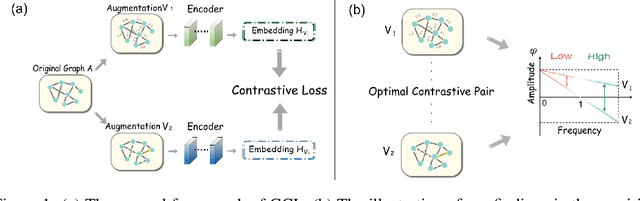

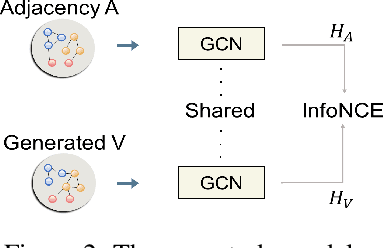
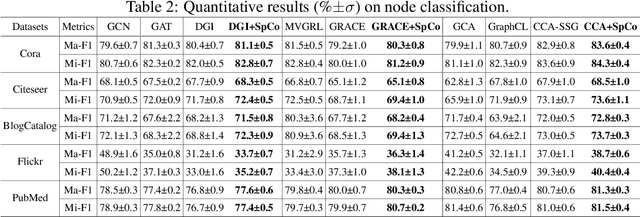
Graph Contrastive Learning (GCL), learning the node representations by augmenting graphs, has attracted considerable attentions. Despite the proliferation of various graph augmentation strategies, some fundamental questions still remain unclear: what information is essentially encoded into the learned representations by GCL? Are there some general graph augmentation rules behind different augmentations? If so, what are they and what insights can they bring? In this paper, we answer these questions by establishing the connection between GCL and graph spectrum. By an experimental investigation in spectral domain, we firstly find the General grAph augMEntation (GAME) rule for GCL, i.e., the difference of the high-frequency parts between two augmented graphs should be larger than that of low-frequency parts. This rule reveals the fundamental principle to revisit the current graph augmentations and design new effective graph augmentations. Then we theoretically prove that GCL is able to learn the invariance information by contrastive invariance theorem, together with our GAME rule, for the first time, we uncover that the learned representations by GCL essentially encode the low-frequency information, which explains why GCL works. Guided by this rule, we propose a spectral graph contrastive learning module (SpCo), which is a general and GCL-friendly plug-in. We combine it with different existing GCL models, and extensive experiments well demonstrate that it can further improve the performances of a wide variety of different GCL methods.
Dynamical Wasserstein Barycenters for Time-series Modeling
Oct 29, 2021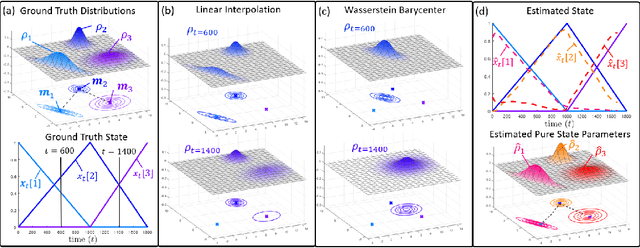
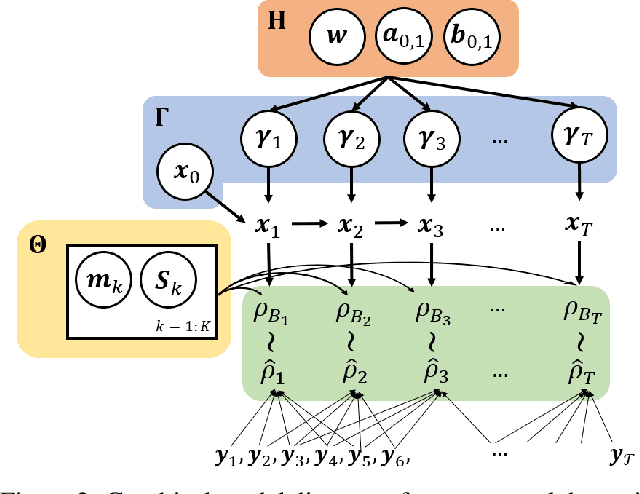
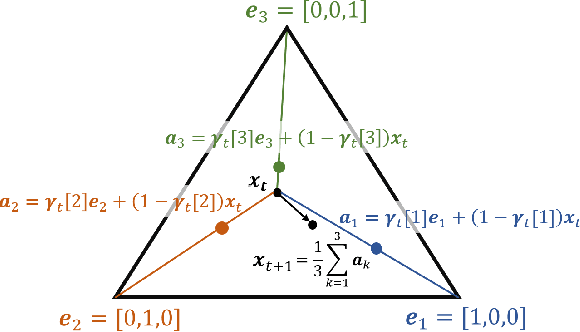
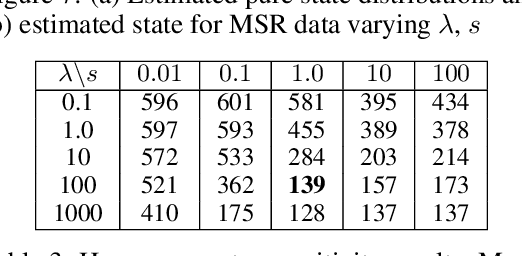
Many time series can be modeled as a sequence of segments representing high-level discrete states, such as running and walking in a human activity application. Flexible models should describe the system state and observations in stationary "pure-state" periods as well as transition periods between adjacent segments, such as a gradual slowdown between running and walking. However, most prior work assumes instantaneous transitions between pure discrete states. We propose a dynamical Wasserstein barycentric (DWB) model that estimates the system state over time as well as the data-generating distributions of pure states in an unsupervised manner. Our model assumes each pure state generates data from a multivariate normal distribution, and characterizes transitions between states via displacement-interpolation specified by the Wasserstein barycenter. The system state is represented by a barycentric weight vector which evolves over time via a random walk on the simplex. Parameter learning leverages the natural Riemannian geometry of Gaussian distributions under the Wasserstein distance, which leads to improved convergence speeds. Experiments on several human activity datasets show that our proposed DWB model accurately learns the generating distribution of pure states while improving state estimation for transition periods compared to the commonly used linear interpolation mixture models.
The complexity of unsupervised learning of lexicographic preferences
Sep 23, 2022This paper considers the task of learning users' preferences on a combinatorial set of alternatives, as generally used by online configurators, for example. In many settings, only a set of selected alternatives during past interactions is available to the learner. Fargier et al. [2018] propose an approach to learn, in such a setting, a model of the users' preferences that ranks previously chosen alternatives as high as possible; and an algorithm to learn, in this setting, a particular model of preferences: lexicographic preferences trees (LP-trees). In this paper, we study complexity-theoretical problems related to this approach. We give an upper bound on the sample complexity of learning an LP-tree, which is logarithmic in the number of attributes. We also prove that computing the LP tree that minimises the empirical risk can be done in polynomial time when restricted to the class of linear LP-trees.
Reactive Anticipatory Robot Skills with Memory
Sep 23, 2022



Optimal control in robotics has been increasingly popular in recent years and has been applied in many applications involving complex dynamical systems. Closed-loop optimal control strategies include model predictive control (MPC) and time-varying linear controllers optimized through iLQR. However, such feedback controllers rely on the information of the current state, limiting the range of robotic applications where the robot needs to remember what it has done before to act and plan accordingly. The recently proposed system level synthesis (SLS) framework circumvents this limitation via a richer controller structure with memory. In this work, we propose to optimally design reactive anticipatory robot skills with memory by extending SLS to tracking problems involving nonlinear systems and nonquadratic cost functions. We showcase our method with two scenarios exploiting task precisions and object affordances in pick-and-place tasks in a simulated and a real environment with a 7-axis Franka Emika robot.
Optimizing Anchor-based Detectors for Autonomous Driving Scenes
Aug 11, 2022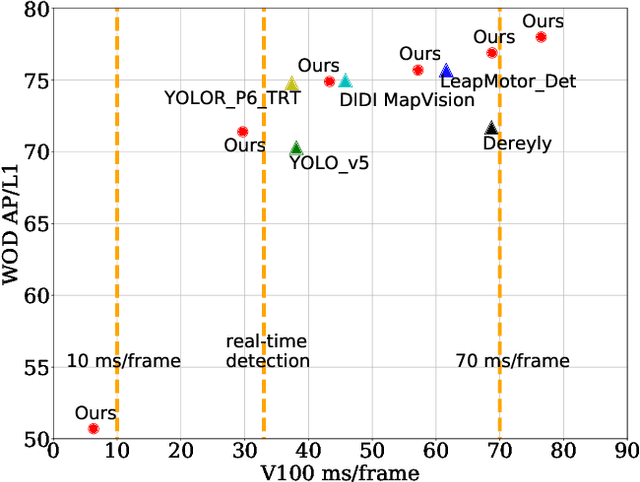
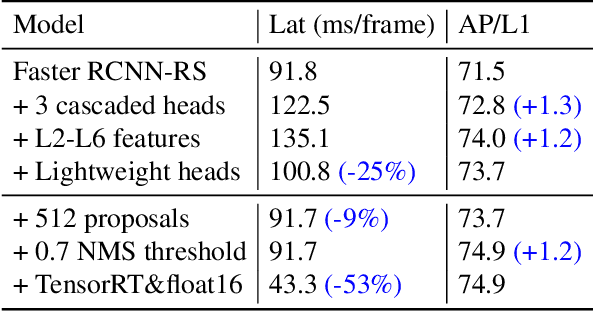
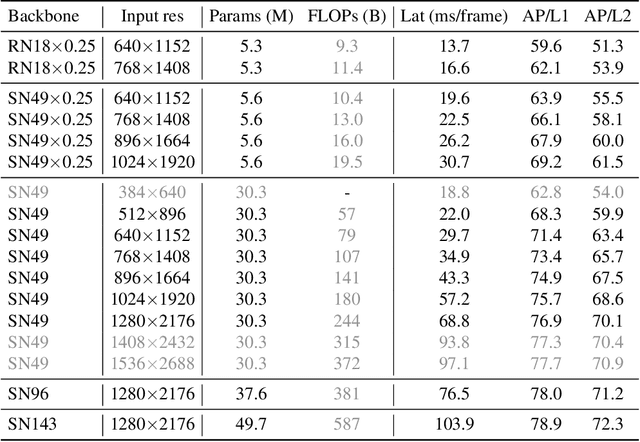
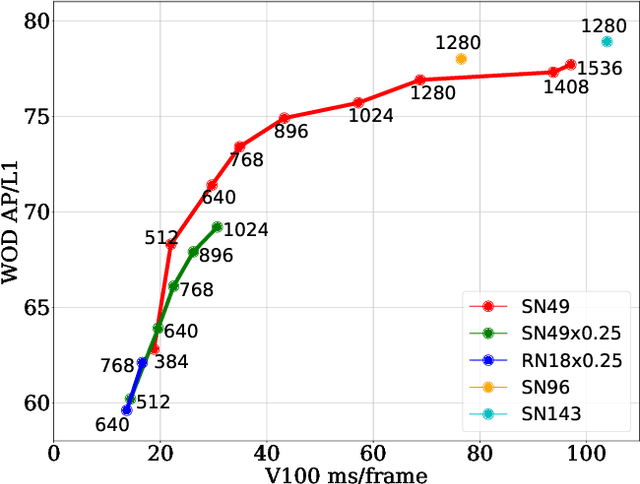
This paper summarizes model improvements and inference-time optimizations for the popular anchor-based detectors in the scenes of autonomous driving. Based on the high-performing RCNN-RS and RetinaNet-RS detection frameworks designed for common detection scenes, we study a set of framework improvements to adapt the detectors to better detect small objects in crowd scenes. Then, we propose a model scaling strategy by scaling input resolution and model size to achieve a better speed-accuracy trade-off curve. We evaluate our family of models on the real-time 2D detection track of the Waymo Open Dataset (WOD). Within the 70 ms/frame latency constraint on a V100 GPU, our largest Cascade RCNN-RS model achieves 76.9% AP/L1 and 70.1% AP/L2, attaining the new state-of-the-art on WOD real-time 2D detection. Our fastest RetinaNet-RS model achieves 6.3 ms/frame while maintaining a reasonable detection precision at 50.7% AP/L1 and 42.9% AP/L2.
One-Shot Learning of Stochastic Differential Equations with Computational Graph Completion
Sep 24, 2022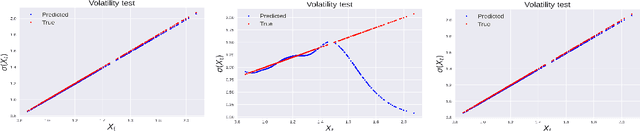

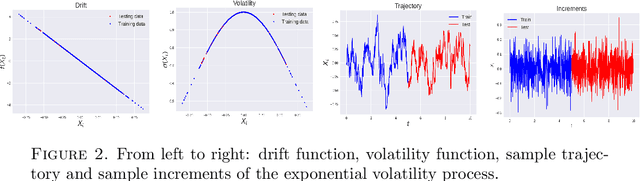

We consider the problem of learning Stochastic Differential Equations of the form $dX_t = f(X_t)dt+\sigma(X_t)dW_t $ from one sample trajectory. This problem is more challenging than learning deterministic dynamical systems because one sample trajectory only provides indirect information on the unknown functions $f$, $\sigma$, and stochastic process $dW_t$ representing the drift, the diffusion, and the stochastic forcing terms, respectively. We propose a simple kernel-based solution to this problem that can be decomposed as follows: (1) Represent the time-increment map $X_t \rightarrow X_{t+dt}$ as a Computational Graph in which $f$, $\sigma$ and $dW_t$ appear as unknown functions and random variables. (2) Complete the graph (approximate unknown functions and random variables) via Maximum a Posteriori Estimation (given the data) with Gaussian Process (GP) priors on the unknown functions. (3) Learn the covariance functions (kernels) of the GP priors from data with randomized cross-validation. Numerical experiments illustrate the efficacy, robustness, and scope of our method.
Suture Thread Spline Reconstruction from Endoscopic Images for Robotic Surgery with Reliability-driven Keypoint Detection
Sep 27, 2022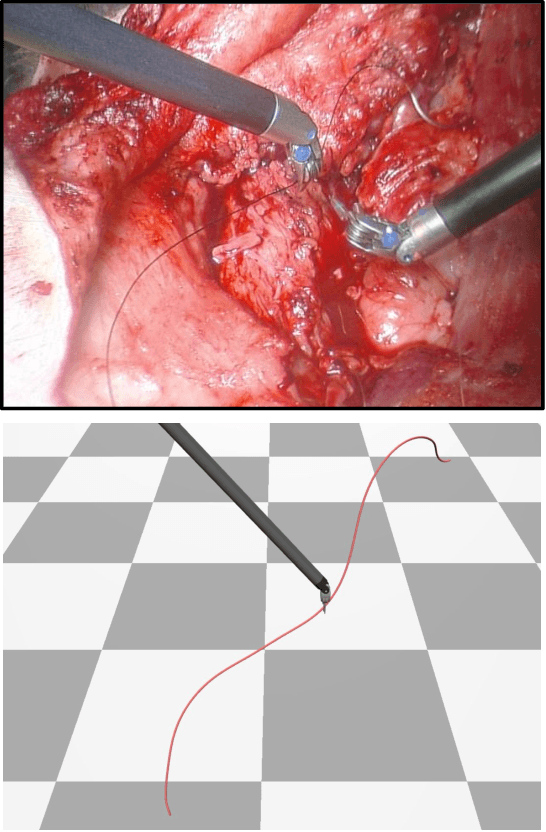
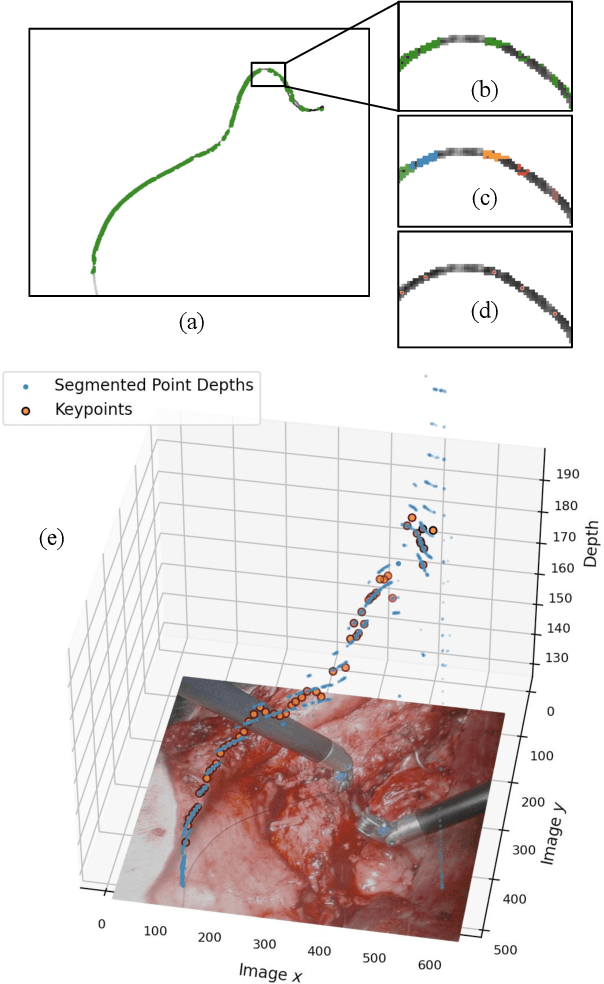
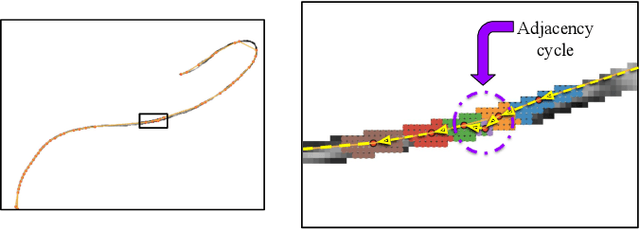
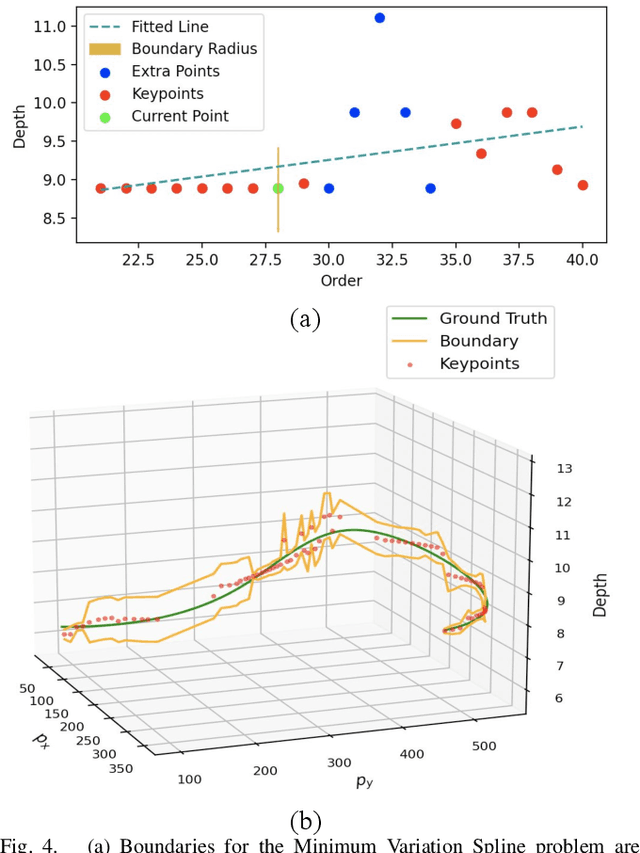
Automating the process of manipulating and delivering sutures during robotic surgery is a prominent problem at the frontier of surgical robotics, as automating this task can significantly reduce surgeons' fatigue during tele-operated surgery and allow them to spend more time addressing higher-level clinical decision making. Accomplishing autonomous suturing and suture manipulation in the real world requires accurate suture thread localization and reconstruction, the process of creating a 3D shape representation of suture thread from 2D stereo camera surgical image pairs. This is a very challenging problem due to how limited pixel information is available for the threads, as well as their sensitivity to lighting and specular reflection. We present a suture thread reconstruction work that uses reliable keypoints and a Minimum Variation Spline (MVS) smoothing optimization to construct a 3D centerline from a segmented surgical image pair. This method is comparable to previous suture thread reconstruction works, with the possible benefit of increased accuracy of grasping point estimation. Our code and datasets will be available at: https://github.com/ucsdarclab/thread-reconstruction.