 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real Time Integration Centre of Mass (riCOM) Reconstruction for 4D-STEM
Dec 14, 2021
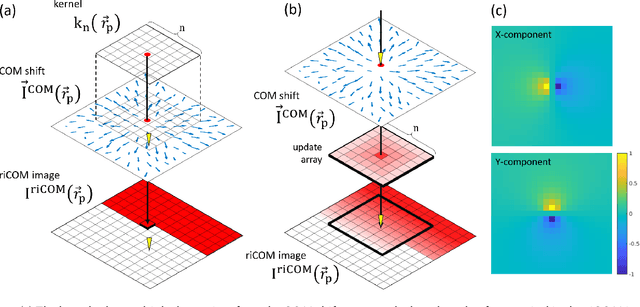
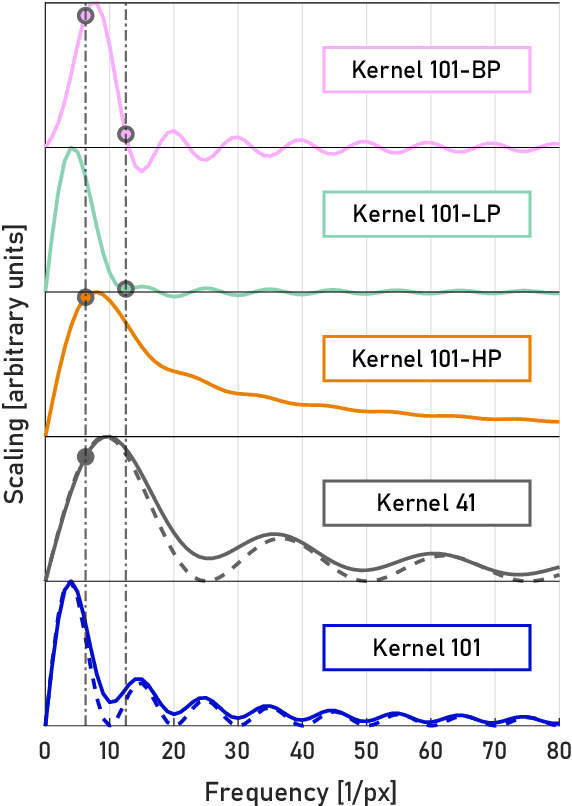
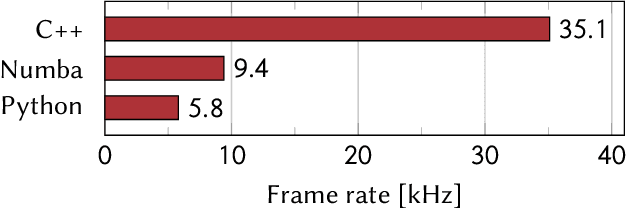
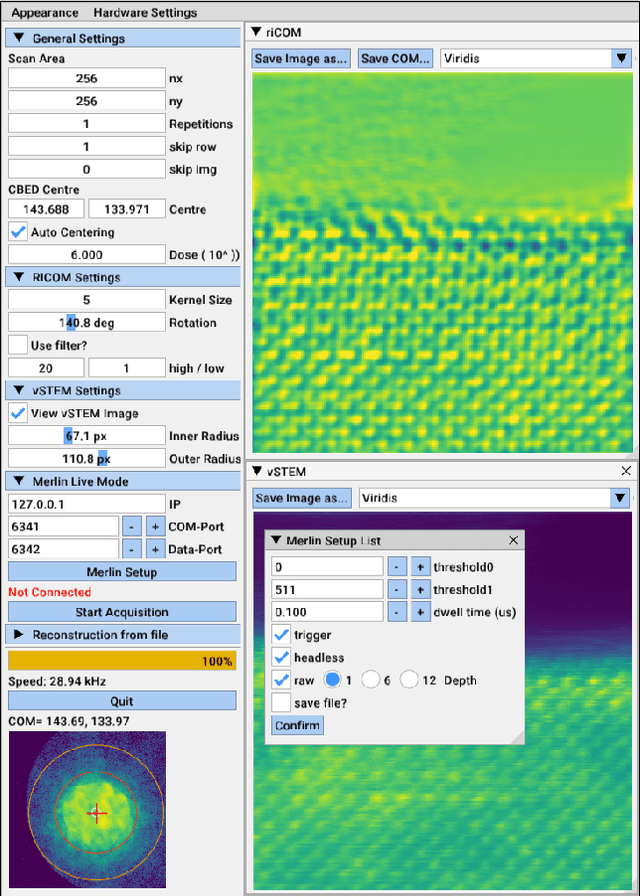
A real-time image reconstruction method for scanning transmission electron microscopy (STEM) is proposed. With an algorithm requiring only the center of mass (COM) of the diffraction pattern at one probe position at a time, it is able to update the resulting image each time a new probe position is visited without storing any intermediate diffraction patterns. The results show clear features at higher spatial frequency, such as atomic column positions. It is also demonstrated that some common post processing methods, such as band pass filtering, can be directly integrated in the real time processing flow. Compared with other reconstruction methods, the proposed method produces high quality reconstructions with good noise robustness at extremely low memory and computational requirements. An efficient, interactive open source implementation of the concept is further presented, which is compatible with frame-based, as well as event-based camera/file types. This method provides the attractive feature of immediate feedback that microscope operators have become used to, e.g. conventional high angle annular dark field STEM imaging, allowing for rapid decision making and fine tuning to obtain the best possible images for beam sensitive samples at the lowest possible dose.
Time-multiplexed Neural Holography: A flexible framework for holographic near-eye displays with fast heavily-quantized spatial light modulators
May 05, 2022
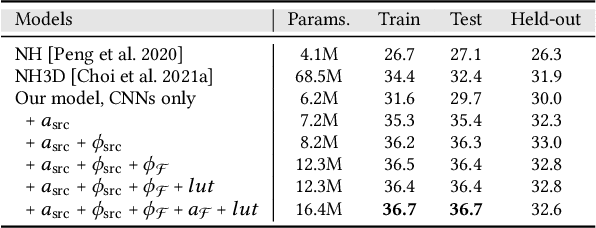

Holographic near-eye displays offer unprecedented capabilities for virtual and augmented reality systems, including perceptually important focus cues. Although artificial intelligence--driven algorithms for computer-generated holography (CGH) have recently made much progress in improving the image quality and synthesis efficiency of holograms, these algorithms are not directly applicable to emerging phase-only spatial light modulators (SLM) that are extremely fast but offer phase control with very limited precision. The speed of these SLMs offers time multiplexing capabilities, essentially enabling partially-coherent holographic display modes. Here we report advances in camera-calibrated wave propagation models for these types of holographic near-eye displays and we develop a CGH framework that robustly optimizes the heavily quantized phase patterns of fast SLMs. Our framework is flexible in supporting runtime supervision with different types of content, including 2D and 2.5D RGBD images, 3D focal stacks, and 4D light fields. Using our framework, we demonstrate state-of-the-art results for all of these scenarios in simulation and experiment.
A Semantic Segmentation Network Based Real-Time Computer-Aided Diagnosis System for Hydatidiform Mole Hydrops Lesion Recognition in Microscopic View
Apr 11, 2022
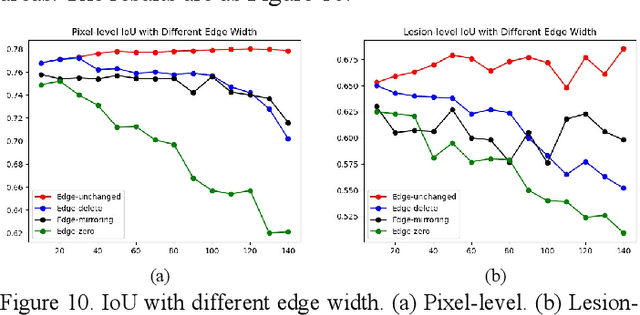
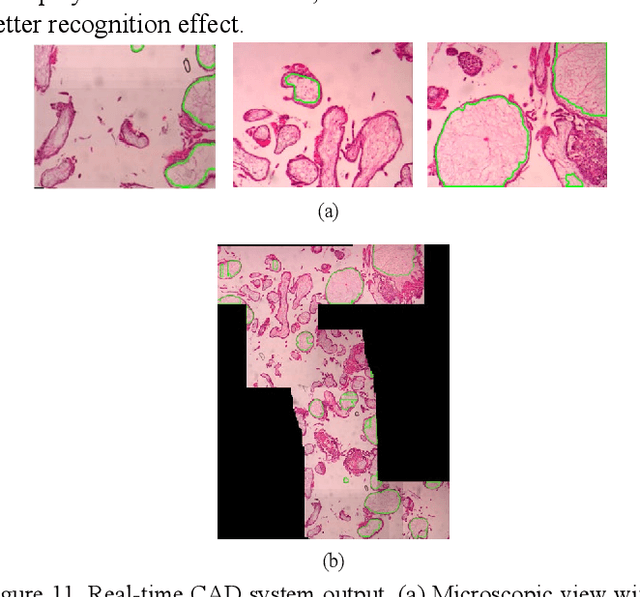
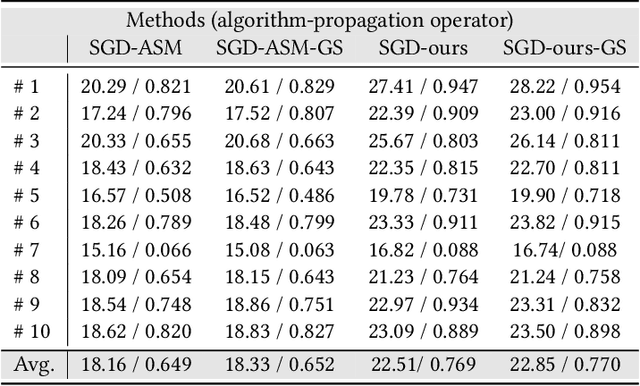
As a disease with malignant potential, hydatidiform mole (HM) is one of the most common gestational trophoblastic diseases. For pathologists, the HM section of hydrops lesions is an important basis for diagnosis. In pathology departments, the diverse microscopic manifestations of HM lesions and the limited view under the microscope mean that physicians with extensive diagnostic experience are required to prevent missed diagnosis and misdiagnosis. Feature extraction can significantly improve the accuracy and speed of the diagnostic process. As a remarkable diagnosis assisting technology, computer-aided diagnosis (CAD) has been widely used in clinical practice. We constructed a deep-learning-based CAD system to identify HM hydrops lesions in the microscopic view in real-time. The system consists of three modules; the image mosaic module and edge extension module process the image to improve the outcome of the hydrops lesion recognition module, which adopts a semantic segmentation network, our novel compound loss function, and a stepwise training function in order to achieve the best performance in identifying hydrops lesions. We evaluated our system using an HM hydrops dataset. Experiments show that our system is able to respond in real-time and correctly display the entire microscopic view with accurately labeled HM hydrops lesions.
PL-$k$NN: A Parameterless Nearest Neighbors Classifier
Sep 26, 2022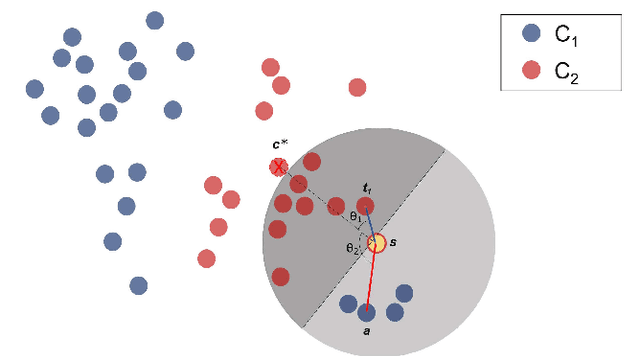
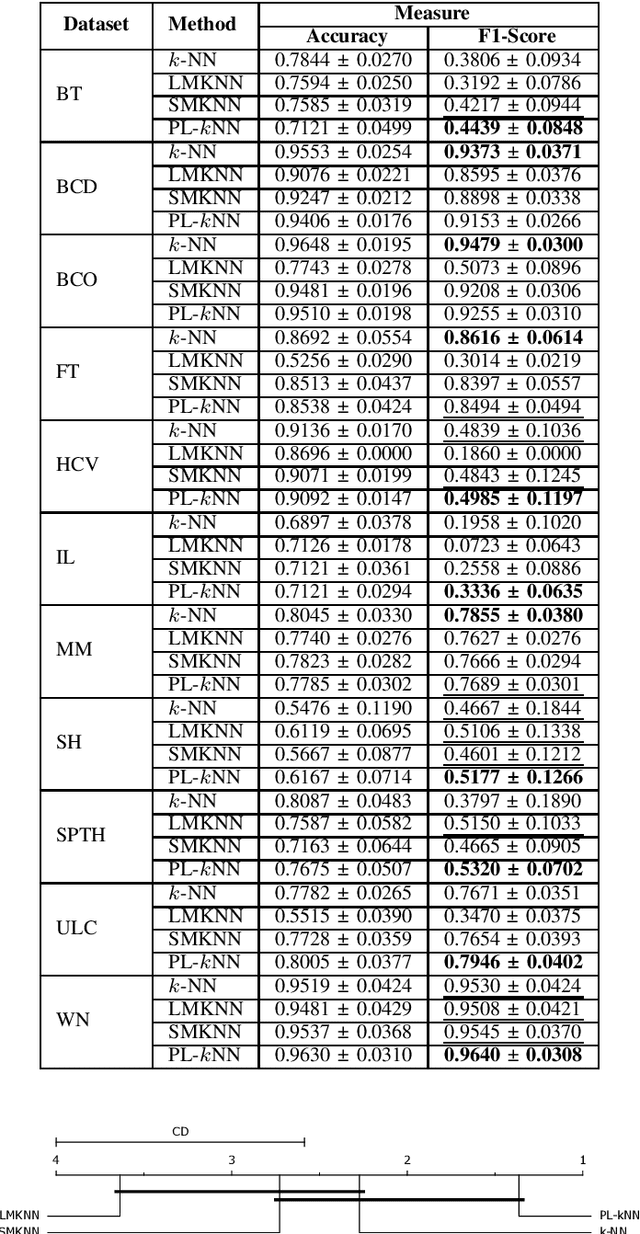
Demands for minimum parameter setup in machine learning models are desirable to avoid time-consuming optimization processes. The $k$-Nearest Neighbors is one of the most effective and straightforward models employed in numerous problems. Despite its well-known performance, it requires the value of $k$ for specific data distribution, thus demanding expensive computational efforts. This paper proposes a $k$-Nearest Neighbors classifier that bypasses the need to define the value of $k$. The model computes the $k$ value adaptively considering the data distribution of the training set. We compared the proposed model against the standard $k$-Nearest Neighbors classifier and two parameterless versions from the literature. Experiments over 11 public datasets confirm the robustness of the proposed approach, for the obtained results were similar or even better than its counterpart versions.
Learning Large-Time-Step Molecular Dynamics with Graph Neural Networks
Nov 30, 2021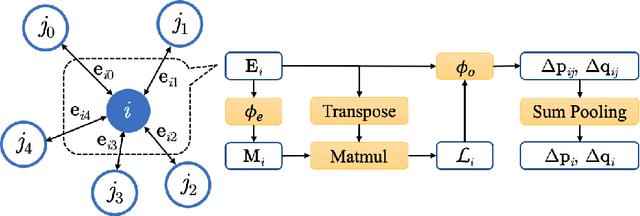

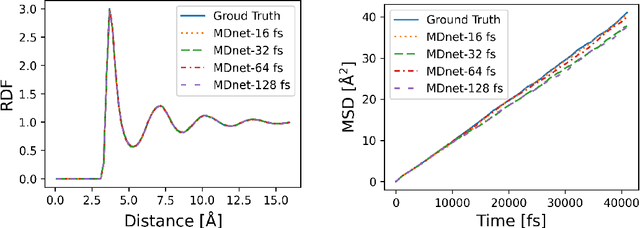
Molecular dynamics (MD) simulation predicts the trajectory of atoms by solving Newton's equation of motion with a numeric integrator. Due to physical constraints, the time step of the integrator need to be small to maintain sufficient precision. This limits the efficiency of simulation. To this end, we introduce a graph neural network (GNN) based model, MDNet, to predict the evolution of coordinates and momentum with large time steps. In addition, MDNet can easily scale to a larger system, due to its linear complexity with respect to the system size. We demonstrate the performance of MDNet on a 4000-atom system with large time steps, and show that MDNet can predict good equilibrium and transport properties, well aligned with standard MD simulations.
CrossDTR: Cross-view and Depth-guided Transformers for 3D Object Detection
Oct 12, 2022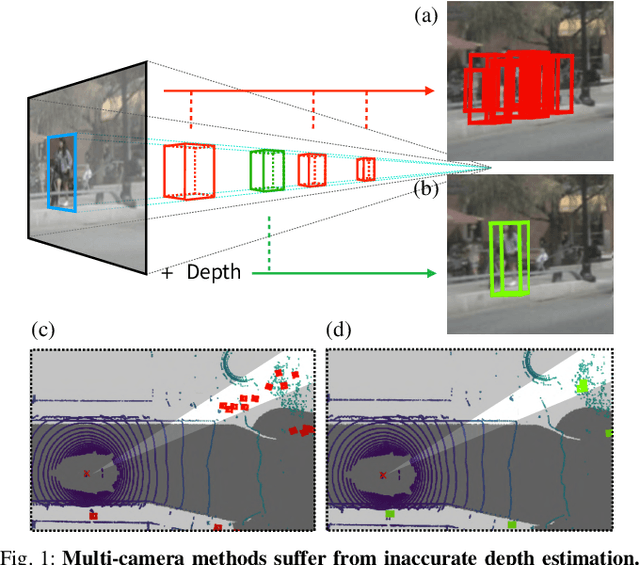
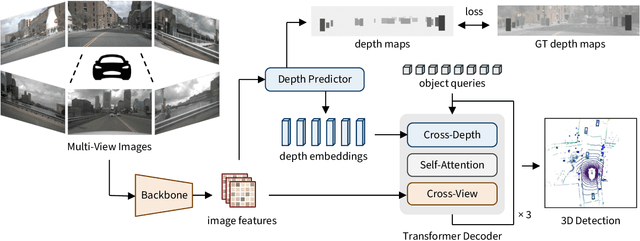
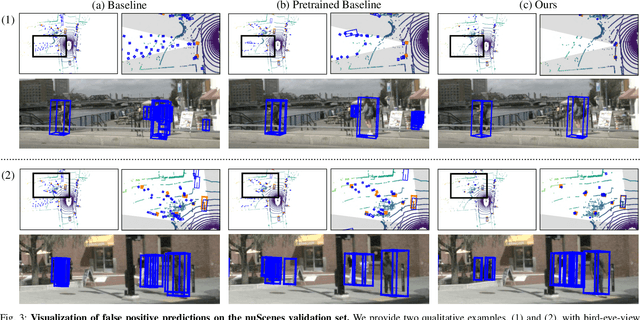
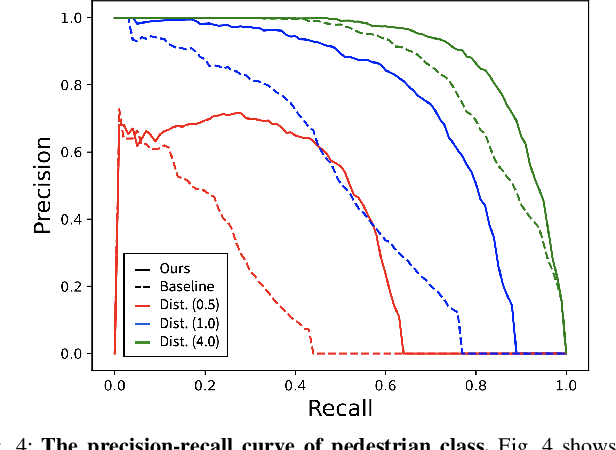
To achieve accurate 3D object detection at a low cost for autonomous driving, many multi-camera methods have been proposed and solved the occlusion problem of monocular approaches. However, due to the lack of accurate estimated depth, existing multi-camera methods often generate multiple bounding boxes along a ray of depth direction for difficult small objects such as pedestrians, resulting in an extremely low recall. Furthermore, directly applying depth prediction modules to existing multi-camera methods, generally composed of large network architectures, cannot meet the real-time requirements of self-driving applications. To address these issues, we propose Cross-view and Depth-guided Transformers for 3D Object Detection, CrossDTR. First, our lightweight depth predictor is designed to produce precise object-wise sparse depth maps and low-dimensional depth embeddings without extra depth datasets during supervision. Second, a cross-view depth-guided transformer is developed to fuse the depth embeddings as well as image features from cameras of different views and generate 3D bounding boxes. Extensive experiments demonstrated that our method hugely surpassed existing multi-camera methods by 10 percent in pedestrian detection and about 3 percent in overall mAP and NDS metrics. Also, computational analyses showed that our method is 5 times faster than prior approaches. Our codes will be made publicly available at https://github.com/sty61010/CrossDTR.
Phantom -- An RL-driven framework for agent-based modeling of complex economic systems and markets
Oct 12, 2022



Agent based modeling (ABM) is a computational approach to modeling complex systems by specifying the behavior of autonomous decision-making components or agents in the system and allowing the system dynamics to emerge from their interactions. Recent advances in the field of Multi-agent reinforcement learning (MARL) have made it feasible to learn the equilibrium of complex environments where multiple agents learn at the same time - opening up the possibility of building ABMs where agent behaviors are learned and system dynamics can be analyzed. However, most ABM frameworks are not RL-native, in that they do not offer concepts and interfaces that are compatible with the use of MARL to learn agent behaviors. In this paper, we introduce a new framework, Phantom, to bridge the gap between ABM and MARL. Phantom is an RL-driven framework for agent-based modeling of complex multi-agent systems such as economic systems and markets. To enable this, the framework provides tools to specify the ABM in MARL-compatible terms - including features to encode dynamic partial observability, agent utility / reward functions, heterogeneity in agent preferences or types, and constraints on the order in which agents can act (e.g. Stackelberg games, or complex turn-taking environments). In this paper, we present these features, their design rationale and show how they were used to model and simulate Over-The-Counter (OTC) markets.
Censored Deep Reinforcement Patrolling with Information Criterion for Monitoring Large Water Resources using Autonomous Surface Vehicles
Oct 12, 2022
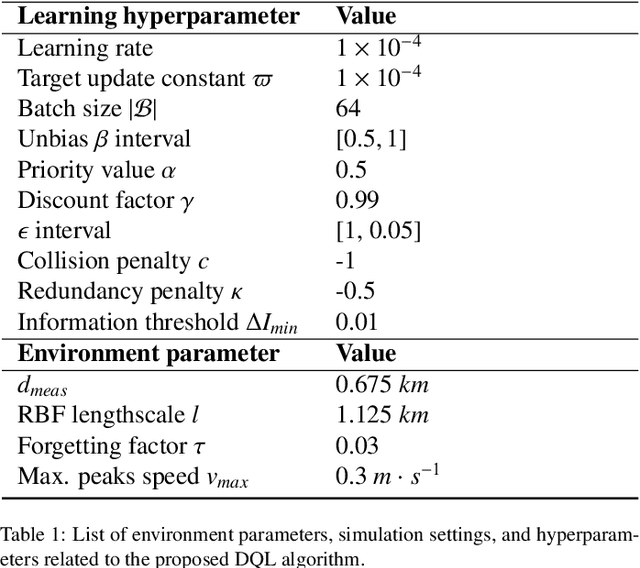
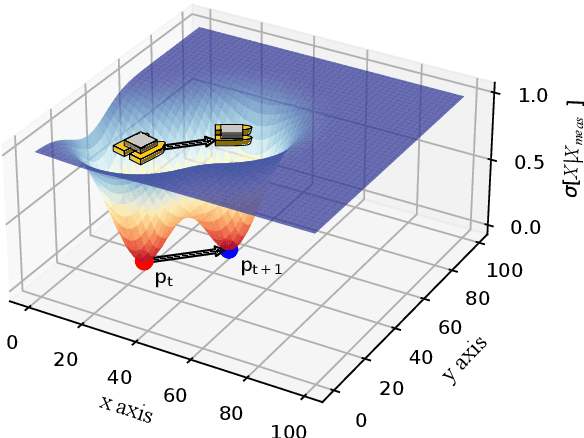
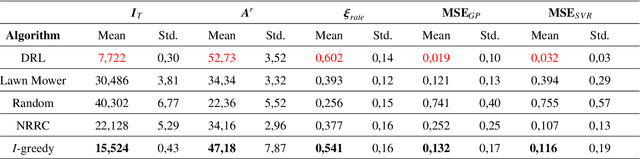
Monitoring and patrolling large water resources is a major challenge for conservation. The problem of acquiring data of an underlying environment that usually changes within time involves a proper formulation of the information. The use of Autonomous Surface Vehicles equipped with water quality sensor modules can serve as an early-warning system agents for contamination peak-detection, algae blooms monitoring, or oil-spill scenarios. In addition to information gathering, the vehicle must plan routes that are free of obstacles on non-convex maps. This work proposes a framework to obtain a collision-free policy that addresses the patrolling task for static and dynamic scenarios. Using information gain as a measure of the uncertainty reduction over data, it is proposed a Deep Q-Learning algorithm improved by a Q-Censoring mechanism for model-based obstacle avoidance. The obtained results demonstrate the usefulness of the proposed algorithm for water resource monitoring for static and dynamic scenarios. Simulations showed the use of noise-networks are a good choice for enhanced exploration, with 3 times less redundancy in the paths. Previous coverage strategies are also outperformed both in the accuracy of the obtained contamination model by a 13% on average and by a 37% in the detection of dangerous contamination peaks. Finally, these results indicate the appropriateness of the proposed framework for monitoring scenarios with autonomous vehicles.
Dynamic Task Software Caching-assisted Computation Offloading for Multi-Access Edge Computing
Aug 15, 2022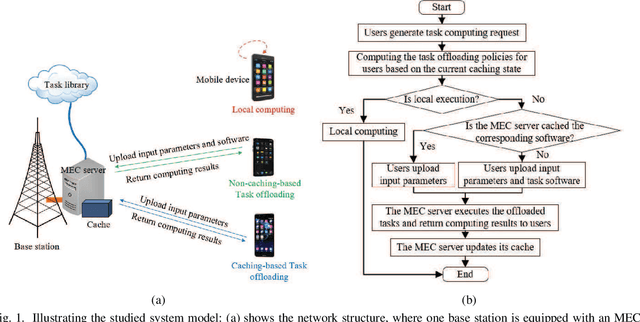
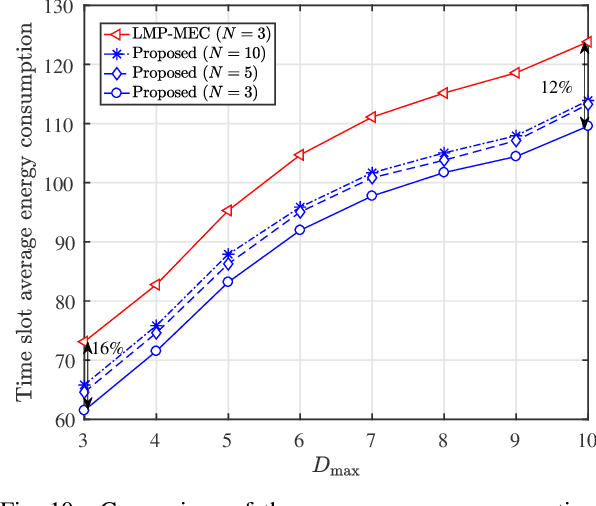
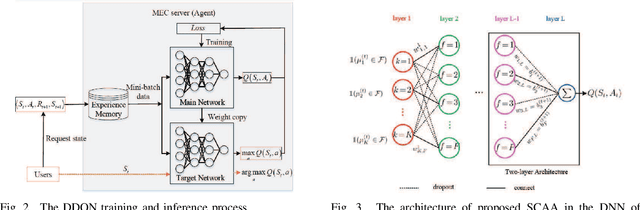

In multi-access edge computing (MEC), most existing task software caching works focus on statically caching data at the network edge, which may hardly preserve high reusability due to the time-varying user requests in practice. To this end, this work considers dynamic task software caching at the MEC server to assist users' task execution. Specifically, we formulate a joint task software caching update (TSCU) and computation offloading (COMO) problem to minimize users' energy consumption while guaranteeing delay constraints, where the limited cache size and computation capability of the MEC server, as well as the time-varying task demand of users are investigated. This problem is proved to be non-deterministic polynomial-time hard, so we transform it into two sub-problems according to their temporal correlations, i.e., the real-time COMO problem and the Markov decision process-based TSCU problem. We first model the COMO problem as a multi-user game and propose a decentralized algorithm to address its Nash equilibrium solution. We then propose a double deep Q-network (DDQN)-based method to solve the TSCU policy. To reduce the computation complexity and convergence time, we provide a new design for the deep neural network (DNN) in DDQN, named state coding and action aggregation (SCAA). In SCAA-DNN, we introduce a dropout mechanism in the input layer to code users' activity states. Additionally, at the output layer, we devise a two-layer architecture to dynamically aggregate caching actions, which is able to solve the huge state-action space problem. Simulation results show that the proposed solution outperforms existing schemes, saving over 12% energy, and converges with fewer training episodes.
A Practical, Progressively-Expressive GNN
Oct 18, 2022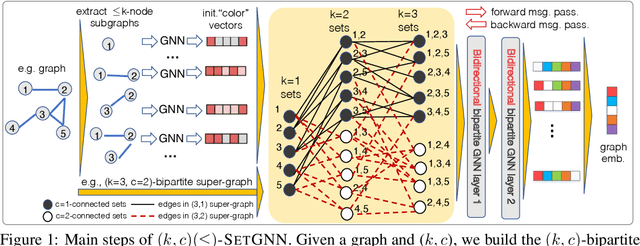
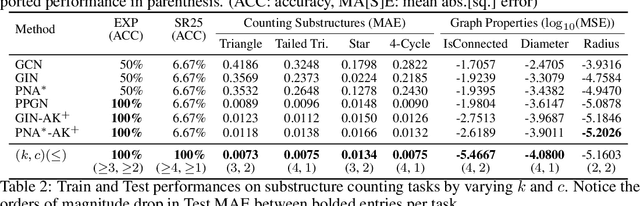
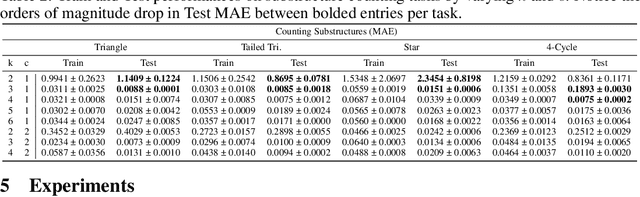
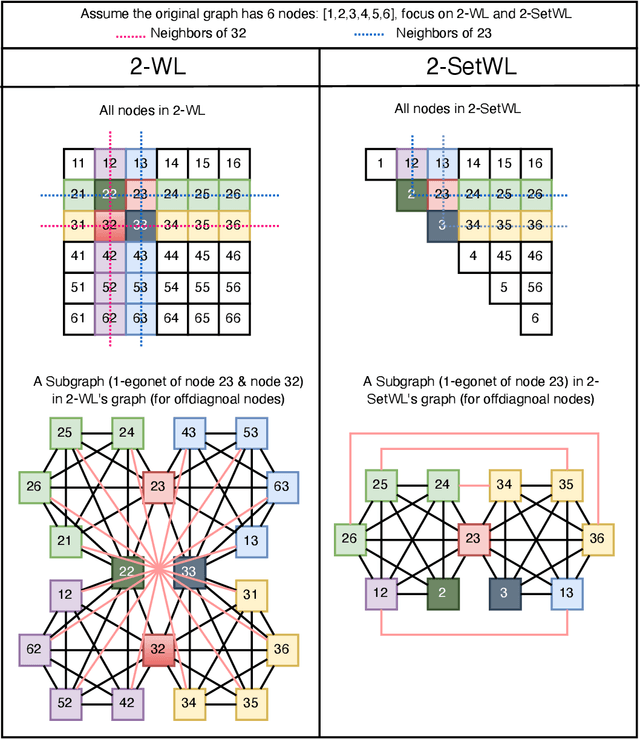
Message passing neural networks (MPNNs) have become a dominant flavor of graph neural networks (GNNs) in recent years. Yet, MPNNs come with notable limitations; namely, they are at most as powerful as the 1-dimensional Weisfeiler-Leman (1-WL) test in distinguishing graphs in a graph isomorphism testing frame-work. To this end, researchers have drawn inspiration from the k-WL hierarchy to develop more expressive GNNs. However, current k-WL-equivalent GNNs are not practical for even small values of k, as k-WL becomes combinatorially more complex as k grows. At the same time, several works have found great empirical success in graph learning tasks without highly expressive models, implying that chasing expressiveness with a coarse-grained ruler of expressivity like k-WL is often unneeded in practical tasks. To truly understand the expressiveness-complexity tradeoff, one desires a more fine-grained ruler, which can more gradually increase expressiveness. Our work puts forth such a proposal: Namely, we first propose the (k, c)(<=)-SETWL hierarchy with greatly reduced complexity from k-WL, achieved by moving from k-tuples of nodes to sets with <=k nodes defined over <=c connected components in the induced original graph. We show favorable theoretical results for this model in relation to k-WL, and concretize it via (k, c)(<=)-SETGNN, which is as expressive as (k, c)(<=)-SETWL. Our model is practical and progressively-expressive, increasing in power with k and c. We demonstrate effectiveness on several benchmark datasets, achieving several state-of-the-art results with runtime and memory usage applicable to practical graphs. We open source our implementation at https://github.com/LingxiaoShawn/KCSetGNN.