 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SoftTreeMax: Policy Gradient with Tree Search
Sep 28, 2022
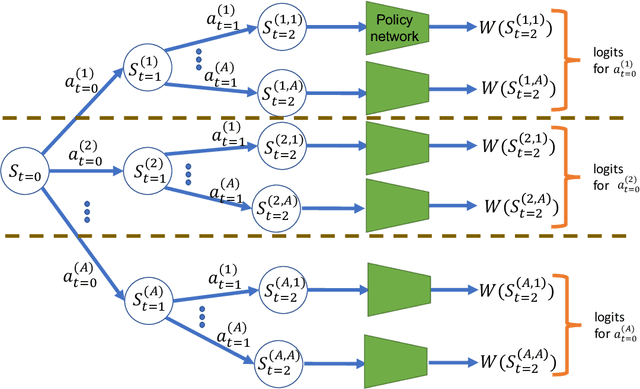
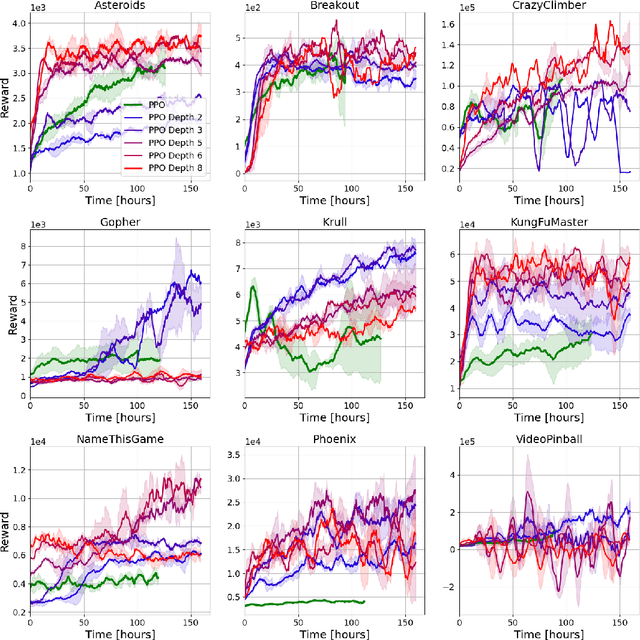
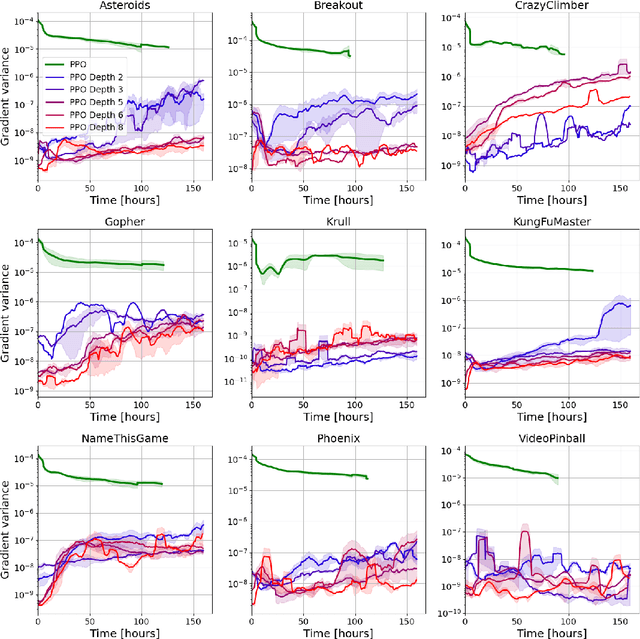
Policy-gradient methods are widely used for learning control policies. They can be easily distributed to multiple workers and reach state-of-the-art results in many domains. Unfortunately, they exhibit large variance and subsequently suffer from high-sample complexity since they aggregate gradients over entire trajectories. At the other extreme, planning methods, like tree search, optimize the policy using single-step transitions that consider future lookahead. These approaches have been mainly considered for value-based algorithms. Planning-based algorithms require a forward model and are computationally intensive at each step, but are more sample efficient. In this work, we introduce SoftTreeMax, the first approach that integrates tree-search into policy gradient. Traditionally, gradients are computed for single state-action pairs. Instead, our tree-based policy structure leverages all gradients at the tree leaves in each environment step. This allows us to reduce the variance of gradients by three orders of magnitude and to benefit from better sample complexity compared with standard policy gradient. On Atari, SoftTreeMax demonstrates up to 5x better performance in faster run-time compared with distributed PPO.
Neural Matching Fields: Implicit Representation of Matching Fields for Visual Correspondence
Oct 06, 2022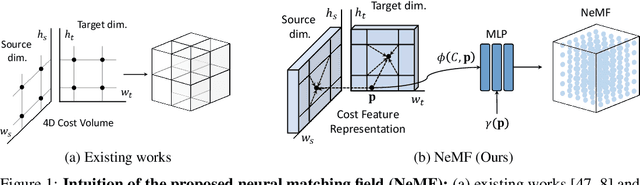

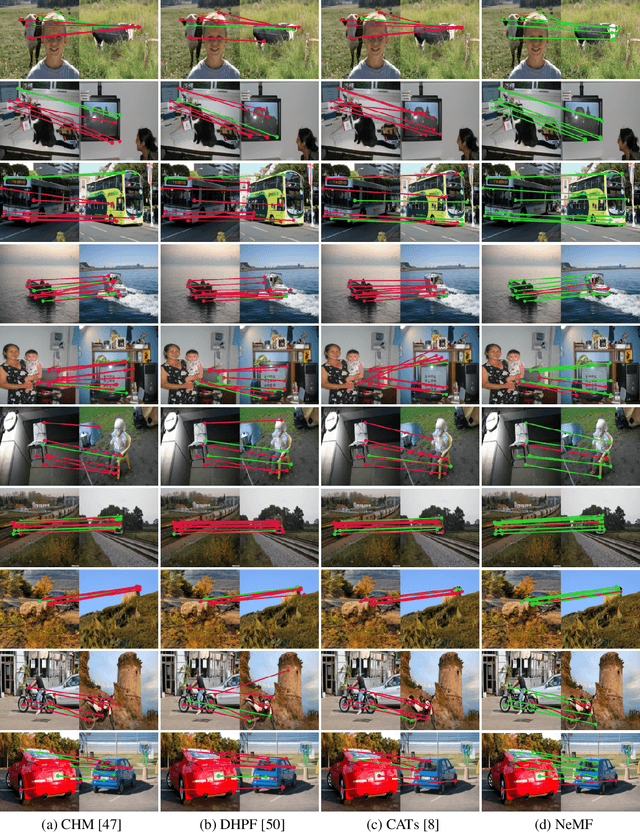

Existing pipelines of semantic correspondence commonly include extracting high-level semantic features for the invariance against intra-class variations and background clutters. This architecture, however, inevitably results in a low-resolution matching field that additionally requires an ad-hoc interpolation process as a post-processing for converting it into a high-resolution one, certainly limiting the overall performance of matching results. To overcome this, inspired by recent success of implicit neural representation, we present a novel method for semantic correspondence, called Neural Matching Field (NeMF). However, complicacy and high-dimensionality of a 4D matching field are the major hindrances, which we propose a cost embedding network to process a coarse cost volume to use as a guidance for establishing high-precision matching field through the following fully-connected network. Nevertheless, learning a high-dimensional matching field remains challenging mainly due to computational complexity, since a naive exhaustive inference would require querying from all pixels in the 4D space to infer pixel-wise correspondences. To overcome this, we propose adequate training and inference procedures, which in the training phase, we randomly sample matching candidates and in the inference phase, we iteratively performs PatchMatch-based inference and coordinate optimization at test time. With these combined, competitive results are attained on several standard benchmarks for semantic correspondence. Code and pre-trained weights are available at https://ku-cvlab.github.io/NeMF/.
Continuous Diagnosis and Prognosis by Controlling the Update Process of Deep Neural Networks
Oct 06, 2022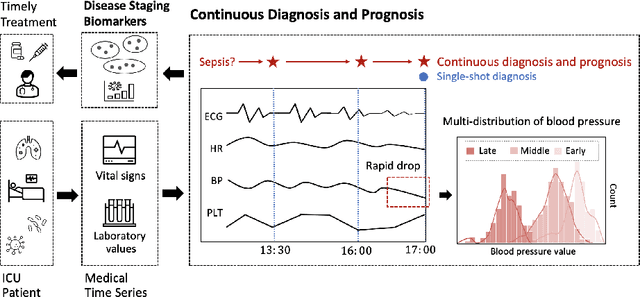
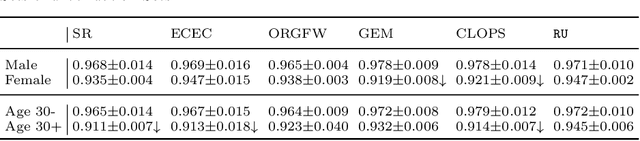
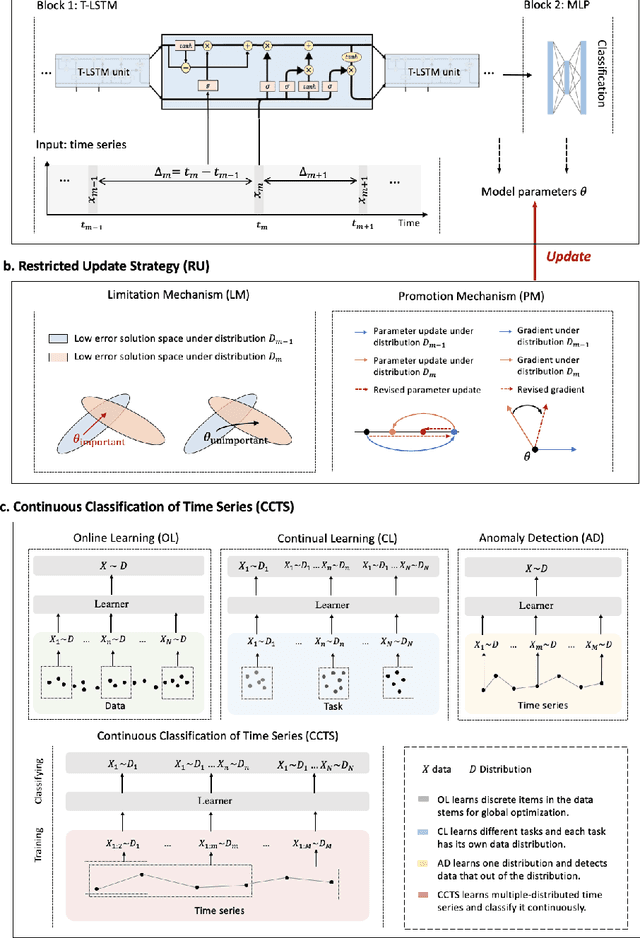
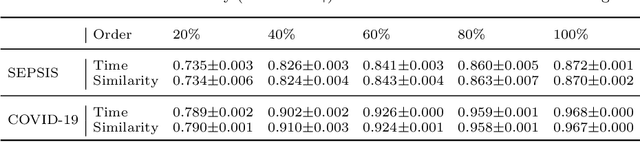
Continuous diagnosis and prognosis are essential for intensive care patients. It can provide more opportunities for timely treatment and rational resource allocation, especially for sepsis, a main cause of death in ICU, and COVID-19, a new worldwide epidemic. Although deep learning methods have shown their great superiority in many medical tasks, they tend to catastrophically forget, over fit, and get results too late when performing diagnosis and prognosis in the continuous mode. In this work, we summarized the three requirements of this task, proposed a new concept, continuous classification of time series (CCTS), and designed a novel model training method, restricted update strategy of neural networks (RU). In the context of continuous prognosis, our method outperformed all baselines and achieved the average accuracy of 90%, 97%, and 85% on sepsis prognosis, COVID-19 mortality prediction, and eight diseases classification. Superiorly, our method can also endow deep learning with interpretability, having the potential to explore disease mechanisms and provide a new horizon for medical research. We have achieved disease staging for sepsis and COVID-19, discovering four stages and three stages with their typical biomarkers respectively. Further, our method is a data-agnostic and model-agnostic plug-in, it can be used to continuously prognose other diseases with staging and even implement CCTS in other fields.
Effective Metaheuristic Based Classifiers for Multiclass Intrusion Detection
Oct 06, 2022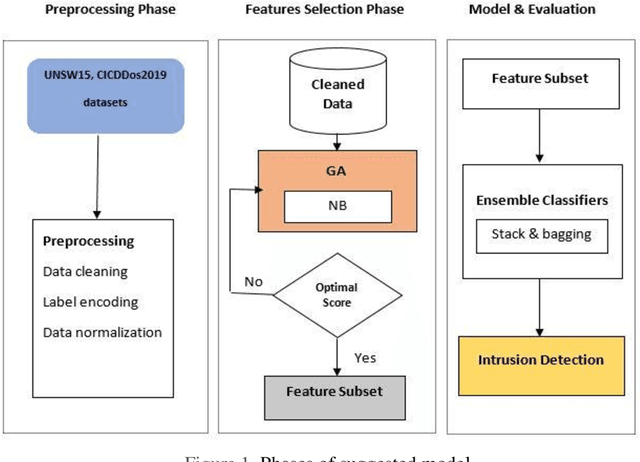
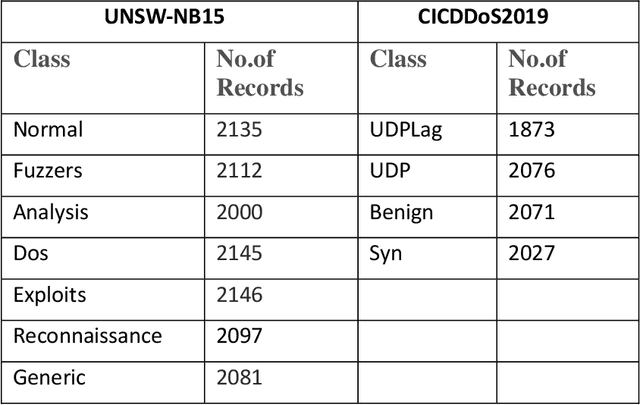
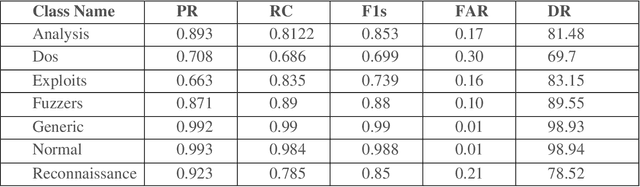
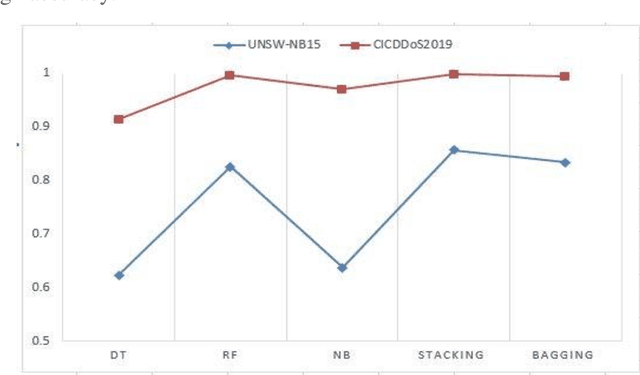
Network security has become the biggest concern in the area of cyber security because of the exponential growth in computer networks and applications. Intrusion detection plays an important role in the security of information systems or networks devices. The purpose of an intrusion detection system (IDS) is to detect malicious activities and then generate an alarm against these activities. Having a large amount of data is one of the key problems in detecting attacks. Most of the intrusion detection systems use all features of datasets to evaluate the models and result in is, low detection rate, high computational time and uses of many computer resources. For fast attacks detection IDS needs a lightweight data. A feature selection method plays a key role to select best features to achieve maximum accuracy. This research work conduct experiments by considering on two updated attacks datasets, UNSW-NB15 and CICDDoS2019. This work suggests a wrapper based Genetic Algorithm (GA) features selection method with ensemble classifiers. GA select the best feature subsets and achieve high accuracy, detection rate (DR) and low false alarm rate (FAR) compared to existing approaches. This research focuses on multi-class classification. Implements two ensemble methods: stacking and bagging to detect different types of attacks. The results show that GA improve the accuracy significantly with stacking ensemble classifier.
Automatic Scene-based Topic Channel Construction System for E-Commerce
Oct 06, 2022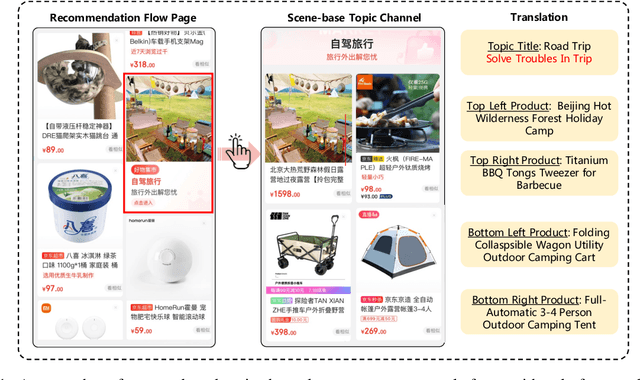

Scene marketing that well demonstrates user interests within a certain scenario has proved effective for offline shopping. To conduct scene marketing for e-commerce platforms, this work presents a novel product form, scene-based topic channel which typically consists of a list of diverse products belonging to the same usage scenario and a topic title that describes the scenario with marketing words. As manual construction of channels is time-consuming due to billions of products as well as dynamic and diverse customers' interests, it is necessary to leverage AI techniques to automatically construct channels for certain usage scenarios and even discover novel topics. To be specific, we first frame the channel construction task as a two-step problem, i.e., scene-based topic generation and product clustering, and propose an E-commerce Scene-based Topic Channel construction system (i.e., ESTC) to achieve automated production, consisting of scene-based topic generation model for the e-commerce domain, product clustering on the basis of topic similarity, as well as quality control based on automatic model filtering and human screening. Extensive offline experiments and online A/B test validates the effectiveness of such a novel product form as well as the proposed system. In addition, we also introduce the experience of deploying the proposed system on a real-world e-commerce recommendation platform.
Novel View Synthesis with Diffusion Models
Oct 06, 2022
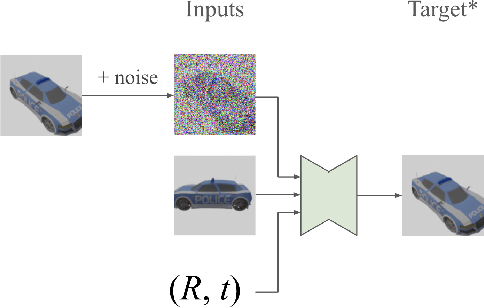
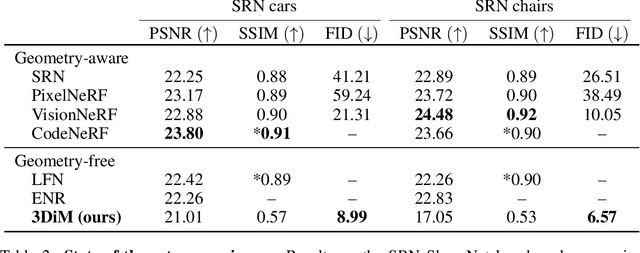
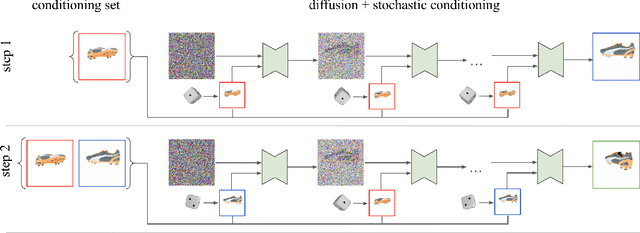
We present 3DiM, a diffusion model for 3D novel view synthesis, which is able to translate a single input view into consistent and sharp completions across many views. The core component of 3DiM is a pose-conditional image-to-image diffusion model, which takes a source view and its pose as inputs, and generates a novel view for a target pose as output. 3DiM can generate multiple views that are 3D consistent using a novel technique called stochastic conditioning. The output views are generated autoregressively, and during the generation of each novel view, one selects a random conditioning view from the set of available views at each denoising step. We demonstrate that stochastic conditioning significantly improves the 3D consistency of a naive sampler for an image-to-image diffusion model, which involves conditioning on a single fixed view. We compare 3DiM to prior work on the SRN ShapeNet dataset, demonstrating that 3DiM's generated completions from a single view achieve much higher fidelity, while being approximately 3D consistent. We also introduce a new evaluation methodology, 3D consistency scoring, to measure the 3D consistency of a generated object by training a neural field on the model's output views. 3DiM is geometry free, does not rely on hyper-networks or test-time optimization for novel view synthesis, and allows a single model to easily scale to a large number of scenes.
Expander Graph Propagation
Oct 06, 2022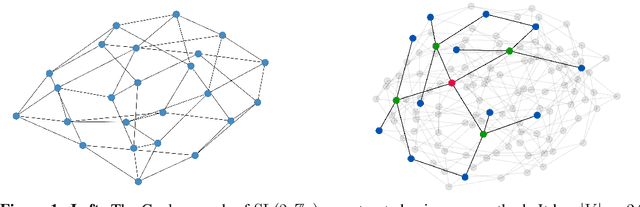



Deploying graph neural networks (GNNs) on whole-graph classification or regression tasks is known to be challenging: it often requires computing node features that are mindful of both local interactions in their neighbourhood and the global context of the graph structure. GNN architectures that navigate this space need to avoid pathological behaviours, such as bottlenecks and oversquashing, while ideally having linear time and space complexity requirements. In this work, we propose an elegant approach based on propagating information over expander graphs. We provide an efficient method for constructing expander graphs of a given size, and use this insight to propose the EGP model. We show that EGP is able to address all of the above concerns, while requiring minimal effort to set up, and provide evidence of its empirical utility on relevant datasets and baselines in the Open Graph Benchmark. Importantly, using expander graphs as a template for message passing necessarily gives rise to negative curvature. While this appears to be counterintuitive in light of recent related work on oversquashing, we theoretically demonstrate that negatively curved edges are likely to be required to obtain scalable message passing without bottlenecks. To the best of our knowledge, this is a previously unstudied result in the context of graph representation learning, and we believe our analysis paves the way to a novel class of scalable methods to counter oversquashing in GNNs.
Novel Features for Time Series Analysis: A Complex Networks Approach
Oct 11, 2021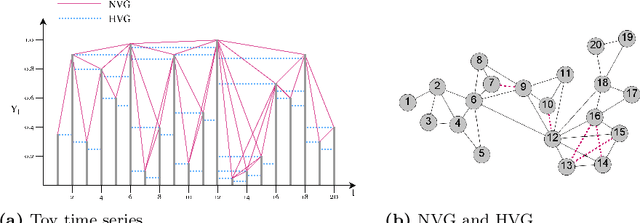
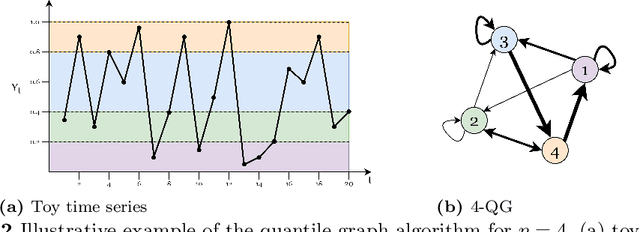
Time series data are ubiquitous in several domains as climate, economics and health care. Mining features from these time series is a crucial task with a multidisciplinary impact. Usually, these features are obtained from structural characteristics of time series, such as trend, seasonality and autocorrelation, sometimes requiring data transformations and parametric models. A recent conceptual approach relies on time series mapping to complex networks, where the network science methodologies can help characterize time series. In this paper, we consider two mapping concepts, visibility and transition probability and propose network topological measures as a new set of time series features. To evaluate the usefulness of the proposed features, we address the problem of time series clustering. More specifically, we propose a clustering method that consists in mapping the time series into visibility graphs and quantile graphs, calculating global topological metrics of the resulting networks, and using data mining techniques to form clusters. We apply this method to a data sets of synthetic and empirical time series. The results indicate that network-based features capture the information encoded in each of the time series models, resulting in high accuracy in a clustering task. Our results are promising and show that network analysis can be used to characterize different types of time series and that different mapping methods capture different characteristics of the time series.
USEEK: Unsupervised SE(3)-Equivariant 3D Keypoints for Generalizable Manipulation
Sep 28, 2022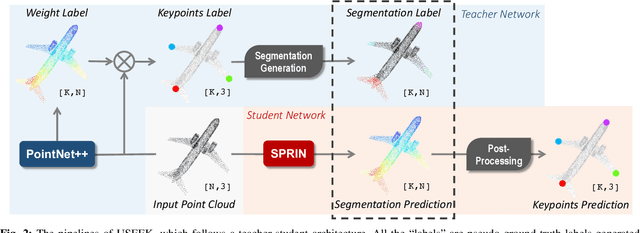
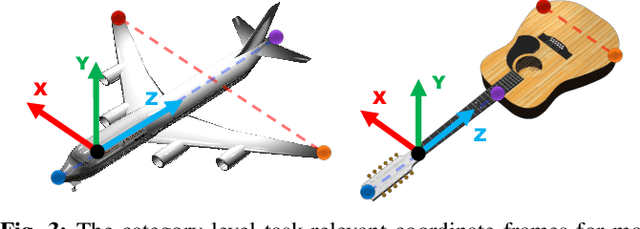

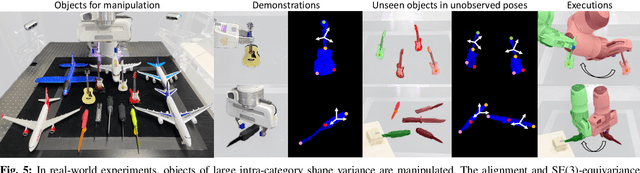
Can a robot manipulate intra-category unseen objects in arbitrary poses with the help of a mere demonstration of grasping pose on a single object instance? In this paper, we try to address this intriguing challenge by using USEEK, an unsupervised SE(3)-equivariant keypoints method that enjoys alignment across instances in a category, to perform generalizable manipulation. USEEK follows a teacher-student structure to decouple the unsupervised keypoint discovery and SE(3)-equivariant keypoint detection. With USEEK in hand, the robot can infer the category-level task-relevant object frames in an efficient and explainable manner, enabling manipulation of any intra-category objects from and to any poses. Through extensive experiments, we demonstrate that the keypoints produced by USEEK possess rich semantics, thus successfully transferring the functional knowledge from the demonstration object to the novel ones. Compared with other object representations for manipulation, USEEK is more adaptive in the face of large intra-category shape variance, more robust with limited demonstrations, and more efficient at inference time.
FINDE: Neural Differential Equations for Finding and Preserving Invariant Quantities
Oct 01, 2022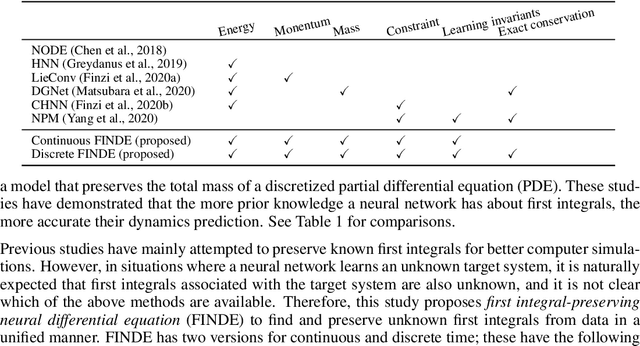

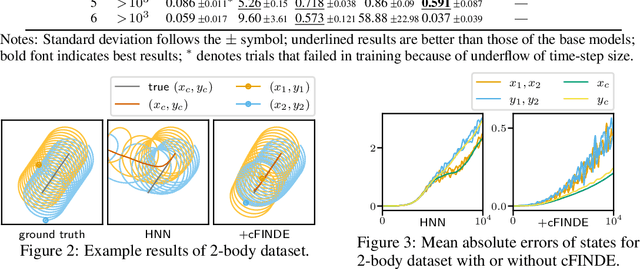
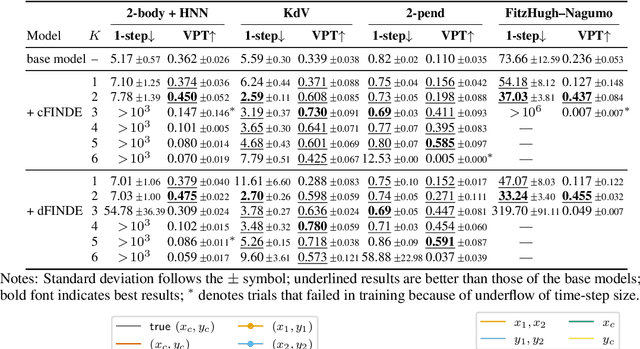
Many real-world dynamical systems are associated with first integrals (a.k.a. invariant quantities), which are quantities that remain unchanged over time. The discovery and understanding of first integrals are fundamental and important topics both in the natural sciences and in industrial applications. First integrals arise from the conservation laws of system energy, momentum, and mass, and from constraints on states; these are typically related to specific geometric structures of the governing equations. Existing neural networks designed to ensure such first integrals have shown excellent accuracy in modeling from data. However, these models incorporate the underlying structures, and in most situations where neural networks learn unknown systems, these structures are also unknown. This limitation needs to be overcome for scientific discovery and modeling of unknown systems. To this end, we propose first integral-preserving neural differential equation (FINDE). By leveraging the projection method and the discrete gradient method, FINDE finds and preserves first integrals from data, even in the absence of prior knowledge about underlying structures. Experimental results demonstrate that FINDE can predict future states of target systems much longer and find various quantities consistent with well-known first integrals in a unified manner.