 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
System-level Impact of Non-Ideal Program-Time of Charge Trap Flash (CTF) on Deep Neural Network
Feb 15, 2024
Learning of deep neural networks (DNN) using Resistive Processing Unit (RPU) architecture is energy-efficient as it utilizes dedicated neuromorphic hardware and stochastic computation of weight updates for in-memory computing. Charge Trap Flash (CTF) devices can implement RPU-based weight updates in DNNs. However, prior work has shown that the weight updates (V_T) in CTF-based RPU are impacted by the non-ideal program time of CTF. The non-ideal program time is affected by two factors of CTF. Firstly, the effects of the number of input pulses (N) or pulse width (pw), and secondly, the gap between successive update pulses (t_gap) used for the stochastic computation of weight updates. Therefore, the impact of this non-ideal program time must be studied for neural network training simulations. In this study, Firstly, we propose a pulse-train design compensation technique to reduce the total error caused by non-ideal program time of CTF and stochastic variance of a network. Secondly, we simulate RPU-based DNN with non-ideal program time of CTF on MNIST and Fashion-MNIST datasets. We find that for larger N (~1000), learning performance approaches the ideal (software-level) training level and, therefore, is not much impacted by the choice of t_gap used to implement RPU-based weight updates. However, for lower N (<500), learning performance depends on T_gap of the pulses. Finally, we also performed an ablation study to isolate the causal factor of the improved learning performance. We conclude that the lower noise level in the weight updates is the most likely significant factor to improve the learning performance of DNN. Thus, our study attempts to compensate for the error caused by non-ideal program time and standardize the pulse length (N) and pulse gap (t_gap) specifications for CTF-based RPUs for accurate system-level on-chip training.
CFTM: Continuous time fractional topic model
Feb 07, 2024In this paper, we propose the Continuous Time Fractional Topic Model (cFTM), a new method for dynamic topic modeling. This approach incorporates fractional Brownian motion~(fBm) to effectively identify positive or negative correlations in topic and word distribution over time, revealing long-term dependency or roughness. Our theoretical analysis shows that the cFTM can capture these long-term dependency or roughness in both topic and word distributions, mirroring the main characteristics of fBm. Moreover, we prove that the parameter estimation process for the cFTM is on par with that of LDA, traditional topic models. To demonstrate the cFTM's property, we conduct empirical study using economic news articles. The results from these tests support the model's ability to identify and track long-term dependency or roughness in topics over time.
Task Attribute Distance for Few-Shot Learning: Theoretical Analysis and Applications
Mar 06, 2024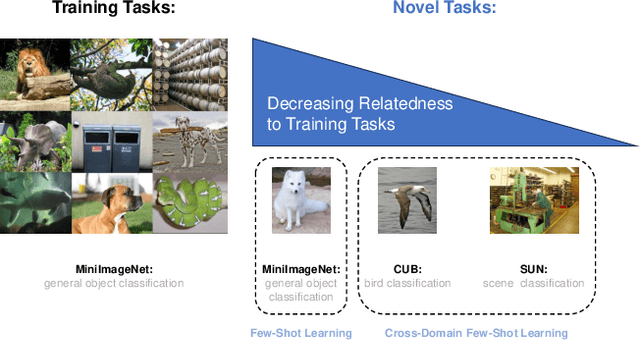
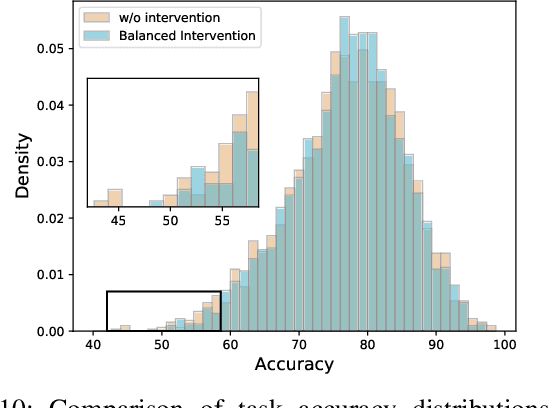
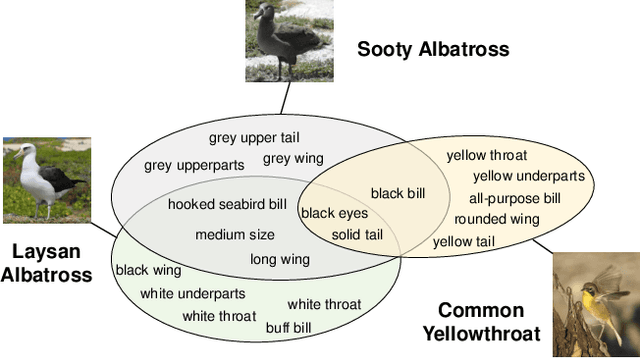
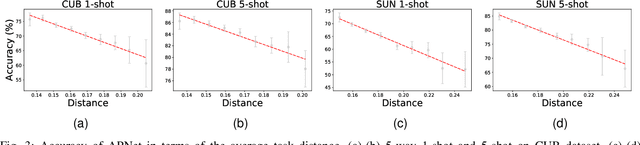
Few-shot learning (FSL) aims to learn novel tasks with very few labeled samples by leveraging experience from \emph{related} training tasks. In this paper, we try to understand FSL by delving into two key questions: (1) How to quantify the relationship between \emph{training} and \emph{novel} tasks? (2) How does the relationship affect the \emph{adaptation difficulty} on novel tasks for different models? To answer the two questions, we introduce Task Attribute Distance (TAD) built upon attributes as a metric to quantify the task relatedness. Unlike many existing metrics, TAD is model-agnostic, making it applicable to different FSL models. Then, we utilize TAD metric to establish a theoretical connection between task relatedness and task adaptation difficulty. By deriving the generalization error bound on a novel task, we discover how TAD measures the adaptation difficulty on novel tasks for FSL models. To validate our TAD metric and theoretical findings, we conduct experiments on three benchmarks. Our experimental results confirm that TAD metric effectively quantifies the task relatedness and reflects the adaptation difficulty on novel tasks for various FSL methods, even if some of them do not learn attributes explicitly or human-annotated attributes are not available. Finally, we present two applications of the proposed TAD metric: data augmentation and test-time intervention, which further verify its effectiveness and general applicability. The source code is available at https://github.com/hu-my/TaskAttributeDistance.
ProxNF: Neural Field Proximal Training for High-Resolution 4D Dynamic Image Reconstruction
Mar 06, 2024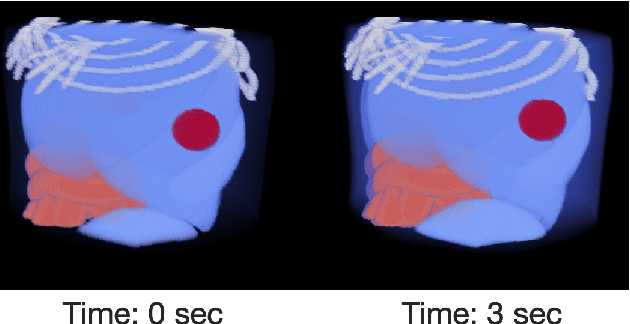

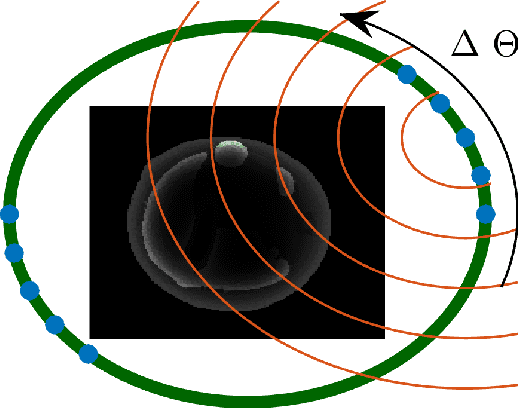
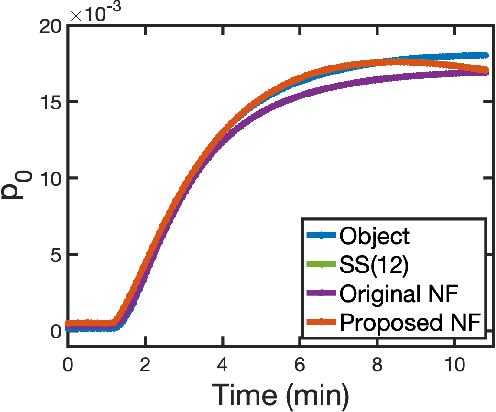
Accurate spatiotemporal image reconstruction methods are needed for a wide range of biomedical research areas but face challenges due to data incompleteness and computational burden. Data incompleteness arises from the undersampling often required to increase frame rates and reduce acquisition times, while computational burden emerges due to the memory footprint of high-resolution images with three spatial dimensions and extended time horizons. Neural fields, an emerging class of neural networks that act as continuous representations of spatiotemporal objects, have previously been introduced to solve these dynamic imaging problems by reframing image reconstruction to a problem of estimating network parameters. Neural fields can address the twin challenges of data incompleteness and computational burden by exploiting underlying redundancies in these spatiotemporal objects. This work proposes ProxNF, a novel neural field training approach for spatiotemporal image reconstruction leveraging proximal splitting methods to separate computations involving the imaging operator from updates of the network parameter. Specifically, ProxNF evaluates the (subsampled) gradient of the data-fidelity term in the image domain and uses a fully supervised learning approach to update the neural field parameters. By reducing the memory footprint and the computational cost of evaluating the imaging operator, the proposed ProxNF approach allows for reconstructing large, high-resolution spatiotemporal images. This method is demonstrated in two numerical studies involving virtual dynamic contrast-enhanced photoacoustic computed tomography imaging of an anatomically realistic dynamic numerical mouse phantom and a two-compartment model of tumor perfusion.
Pooling Image Datasets With Multiple Covariate Shift and Imbalance
Mar 05, 2024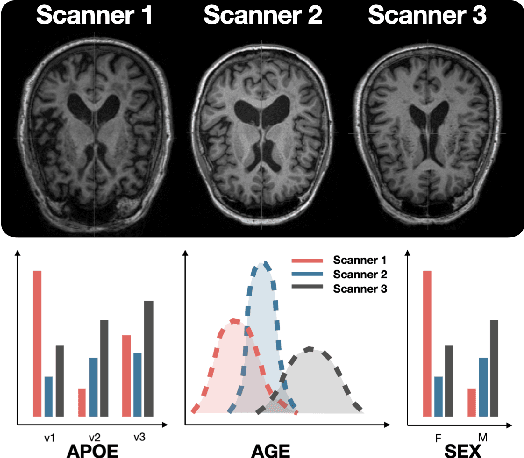
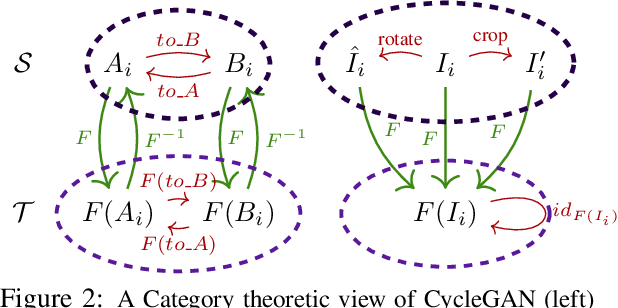
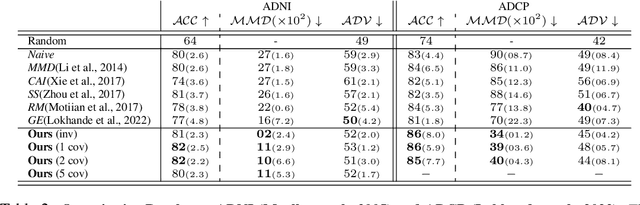
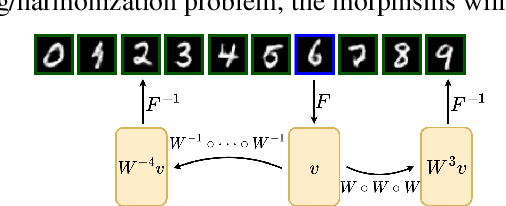
Small sample sizes are common in many disciplines, which necessitates pooling roughly similar datasets across multiple institutions to study weak but relevant associations between images and disease outcomes. Such data often manifest shift/imbalance in covariates (i.e., secondary non-imaging data). Controlling for such nuisance variables is common within standard statistical analysis, but the ideas do not directly apply to overparameterized models. Consequently, recent work has shown how strategies from invariant representation learning provides a meaningful starting point, but the current repertoire of methods is limited to accounting for shifts/imbalances in just a couple of covariates at a time. In this paper, we show how viewing this problem from the perspective of Category theory provides a simple and effective solution that completely avoids elaborate multi-stage training pipelines that would otherwise be needed. We show the effectiveness of this approach via extensive experiments on real datasets. Further, we discuss how this style of formulation offers a unified perspective on at least 5+ distinct problem settings, from self-supervised learning to matching problems in 3D reconstruction.
Simplicity in Complexity
Mar 05, 2024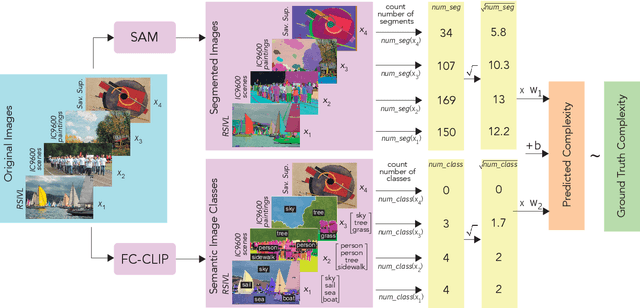
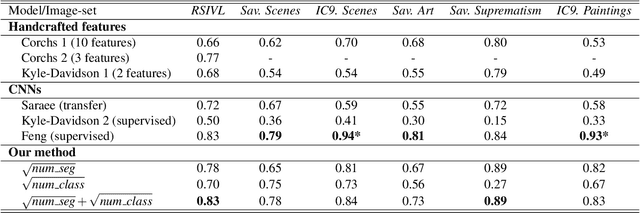
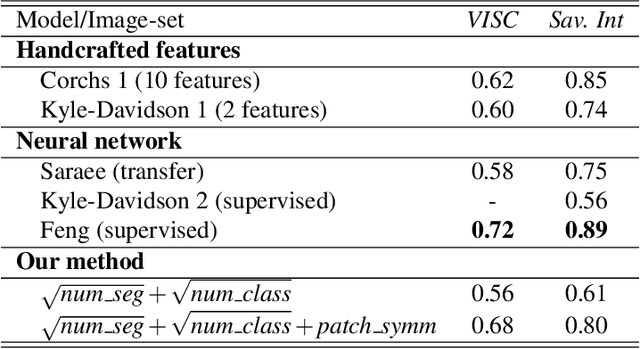

The complexity of visual stimuli plays an important role in many cognitive phenomena, including attention, engagement, memorability, time perception and aesthetic evaluation. Despite its importance, complexity is poorly understood and ironically, previous models of image complexity have been quite \textit{complex}. There have been many attempts to find handcrafted features that explain complexity, but these features are usually dataset specific, and hence fail to generalise. On the other hand, more recent work has employed deep neural networks to predict complexity, but these models remain difficult to interpret, and do not guide a theoretical understanding of the problem. Here we propose to model complexity using segment-based representations of images. We use state-of-the-art segmentation models, SAM and FC-CLIP, to quantify the number of segments at multiple granularities, and the number of classes in an image respectively. We find that complexity is well-explained by a simple linear model with these two features across six diverse image-sets of naturalistic scene and art images. This suggests that the complexity of images can be surprisingly simple.
Motion-Corrected Moving Average: Including Post-Hoc Temporal Information for Improved Video Segmentation
Mar 05, 2024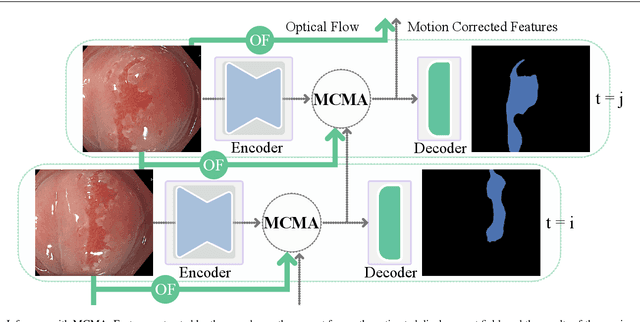
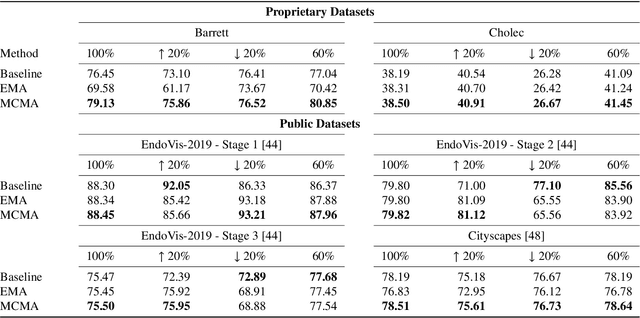
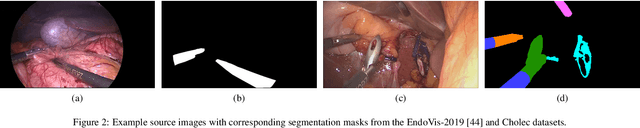
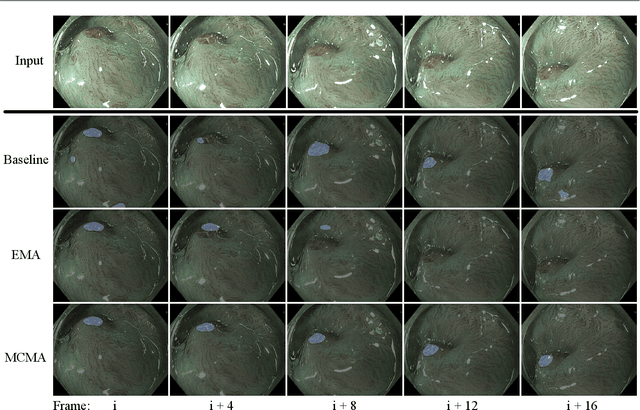
Real-time computational speed and a high degree of precision are requirements for computer-assisted interventions. Applying a segmentation network to a medical video processing task can introduce significant inter-frame prediction noise. Existing approaches can reduce inconsistencies by including temporal information but often impose requirements on the architecture or dataset. This paper proposes a method to include temporal information in any segmentation model and, thus, a technique to improve video segmentation performance without alterations during training or additional labeling. With Motion-Corrected Moving Average, we refine the exponential moving average between the current and previous predictions. Using optical flow to estimate the movement between consecutive frames, we can shift the prior term in the moving-average calculation to align with the geometry of the current frame. The optical flow calculation does not require the output of the model and can therefore be performed in parallel, leading to no significant runtime penalty for our approach. We evaluate our approach on two publicly available segmentation datasets and two proprietary endoscopic datasets and show improvements over a baseline approach.
DIFNet: SAR RFI suppression based on domain invariant features
Mar 05, 2024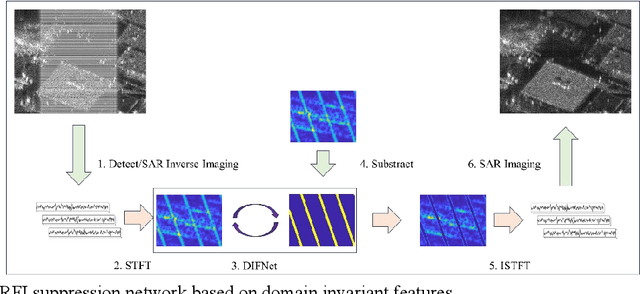
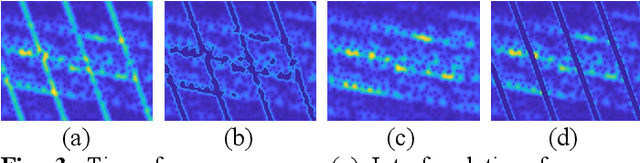

Synthetic aperture radar is a high-resolution two-dimensional imaging radar, however, during the imaging process, SAR is susceptible to intentional and unintentional interference, with radio frequency interference (RFI) being the most common type, leading to a severe degradation in image quality. Although inpainting networks have achieved excellent results, their generalization is unclear, and whether they still work effectively in cross-sensor experiments needs further verification. Through time-frequency analysis of interference signals, we find that interference holds domain invariant features between different sensors. Therefore, this paper reconstructs the loss function and extracts the domain invariant features to improve the generalization. Ultimately, this paper proposes a SAR RFI suppression method based on domain invariant features, and embeds the RFI suppression into SAR imaging process. Compared to traditional notch filtering methods, the proposed approach not only removes interference but also effectively preserves strong scattering targets. Compared to PISNet, our method can extract domain invariant features and holds better generalization ability, and even in the cross-sensor experiment, our method can still achieve excellent results.
Online Learning of Human Constraints from Feedback in Shared Autonomy
Mar 05, 2024
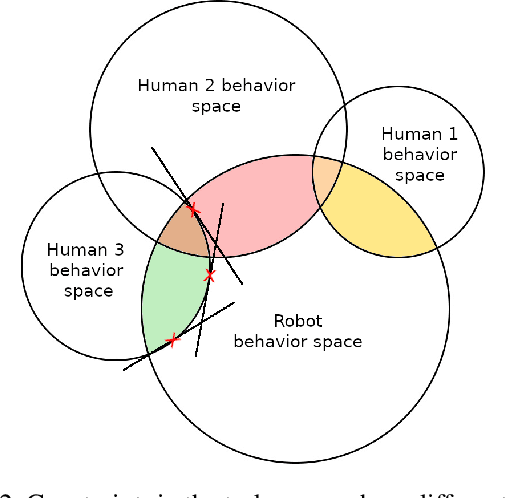
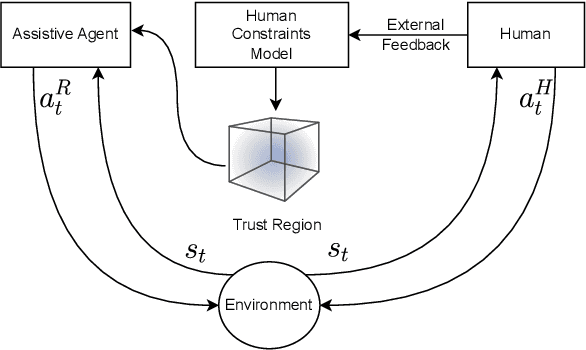

Real-time collaboration with humans poses challenges due to the different behavior patterns of humans resulting from diverse physical constraints. Existing works typically focus on learning safety constraints for collaboration, or how to divide and distribute the subtasks between the participating agents to carry out the main task. In contrast, we propose to learn a human constraints model that, in addition, considers the diverse behaviors of different human operators. We consider a type of collaboration in a shared-autonomy fashion, where both a human operator and an assistive robot act simultaneously in the same task space that affects each other's actions. The task of the assistive agent is to augment the skill of humans to perform a shared task by supporting humans as much as possible, both in terms of reducing the workload and minimizing the discomfort for the human operator. Therefore, we propose an augmentative assistant agent capable of learning and adapting to human physical constraints, aligning its actions with the ergonomic preferences and limitations of the human operator.
ChatCite: LLM Agent with Human Workflow Guidance for Comparative Literature Summary
Mar 05, 2024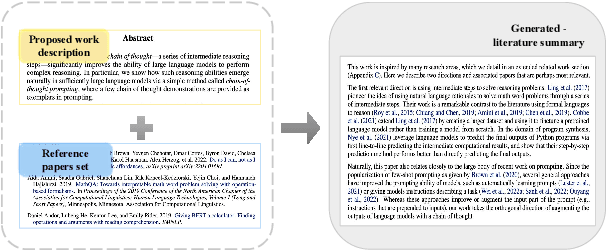
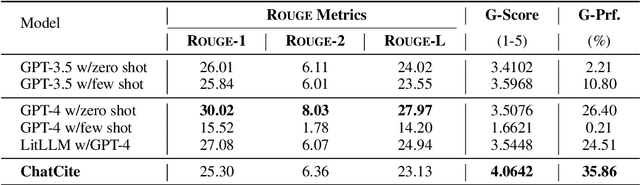
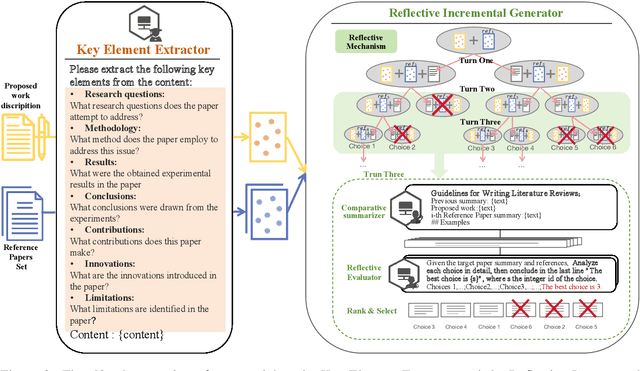
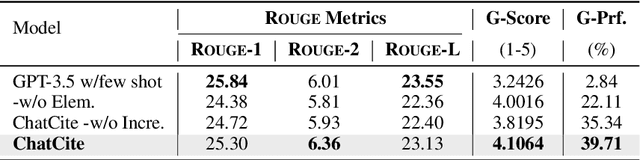
The literature review is an indispensable step in the research process. It provides the benefit of comprehending the research problem and understanding the current research situation while conducting a comparative analysis of prior works. However, literature summary is challenging and time consuming. The previous LLM-based studies on literature review mainly focused on the complete process, including literature retrieval, screening, and summarization. However, for the summarization step, simple CoT method often lacks the ability to provide extensive comparative summary. In this work, we firstly focus on the independent literature summarization step and introduce ChatCite, an LLM agent with human workflow guidance for comparative literature summary. This agent, by mimicking the human workflow, first extracts key elements from relevant literature and then generates summaries using a Reflective Incremental Mechanism. In order to better evaluate the quality of the generated summaries, we devised a LLM-based automatic evaluation metric, G-Score, in refer to the human evaluation criteria. The ChatCite agent outperformed other models in various dimensions in the experiments. The literature summaries generated by ChatCite can also be directly used for drafting literature reviews.