 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dual Gradient Descent EMF-Aware MU-MIMO Beamforming in RIS-Aided 6G Networks
Oct 03, 2022




Reconfigurable Intelligent Surface (RIS) is one of the key technologies for the upcoming 6th Generation (6G) communications, which can improve the signal strength at the receivers by adding artificial propagation paths. In the context of Downlink (DL) Multi-User Multiple-Input Multiple-Output (MU-MIMO) communications, designing an appropriate Beamforming (BF) scheme to take full advantage of this reconfigured propagation environment and improve the network capacity is a major challenge. Due to the spatial dimension provided by MIMO systems, independent data streams can be transmitted to multiple users simultaneously on the same radio resources. It is important to note that serving the same subset of users over a period of time may lead to undesired areas where the average Electromagnetic Field Exposure (EMFE) exceeds regulatory limits. To address this challenge, in this paper, we propose a Dual Gradient Descent (Dual-GD)-based Electromagnetic Field (EMF)-aware MU-MIMO BF scheme that aims to optimize the overall capacity under EMFE constraints in RIS-aided 6G cellular networks.
Privacy-Preserving Feature Coding for Machines
Oct 03, 2022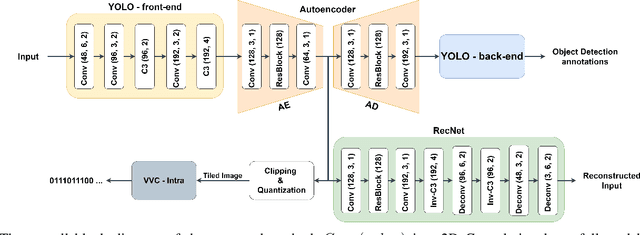
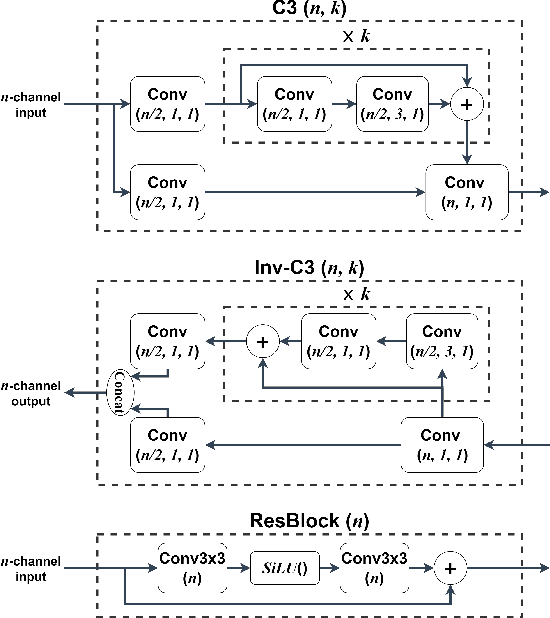

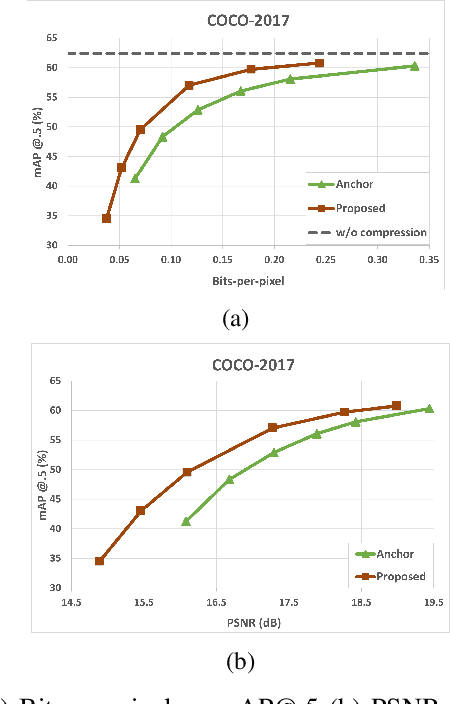
Automated machine vision pipelines do not need the exact visual content to perform their tasks. Therefore, there is a potential to remove private information from the data without significantly affecting the machine vision accuracy. We present a novel method to create a privacy-preserving latent representation of an image that could be used by a downstream machine vision model. This latent representation is constructed using adversarial training to prevent accurate reconstruction of the input while preserving the task accuracy. Specifically, we split a Deep Neural Network (DNN) model and insert an autoencoder whose purpose is to both reduce the dimensionality as well as remove information relevant to input reconstruction while minimizing the impact on task accuracy. Our results show that input reconstruction ability can be reduced by about 0.8 dB at the equivalent task accuracy, with degradation concentrated near the edges, which is important for privacy. At the same time, 30% bit savings are achieved compared to coding the features directly.
KENN: Enhancing Deep Neural Networks by Leveraging Knowledge for Time Series Forecasting
Feb 09, 2022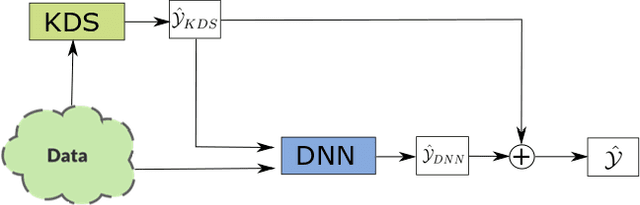
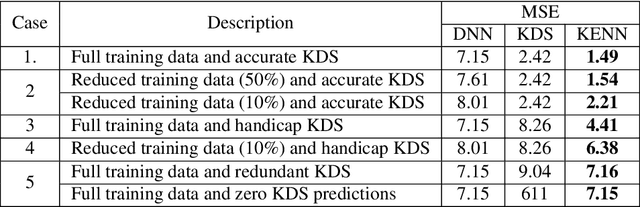
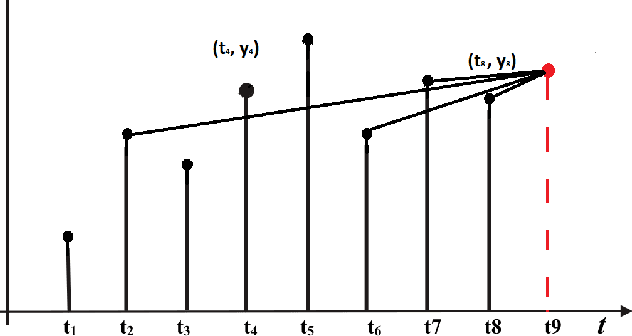
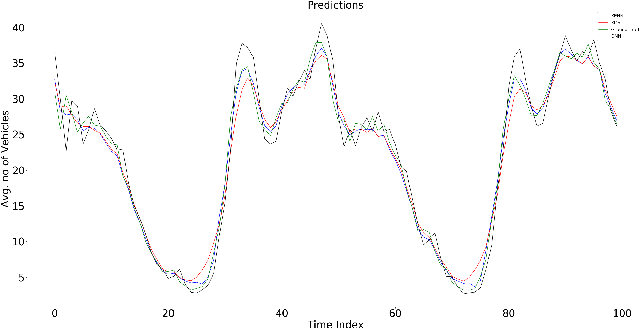
End-to-end data-driven machine learning methods often have exuberant requirements in terms of quality and quantity of training data which are often impractical to fulfill in real-world applications. This is specifically true in time series domain where problems like disaster prediction, anomaly detection, and demand prediction often do not have a large amount of historical data. Moreover, relying purely on past examples for training can be sub-optimal since in doing so we ignore one very important domain i.e knowledge, which has its own distinct advantages. In this paper, we propose a novel knowledge fusion architecture, Knowledge Enhanced Neural Network (KENN), for time series forecasting that specifically aims towards combining strengths of both knowledge and data domains while mitigating their individual weaknesses. We show that KENN not only reduces data dependency of the overall framework but also improves performance by producing predictions that are better than the ones produced by purely knowledge and data driven domains. We also compare KENN with state-of-the-art forecasting methods and show that predictions produced by KENN are significantly better even when trained on only 50\% of the data.
GEO Payload Power Minimization: Joint Precoding and Beam Hopping Design
Aug 22, 2022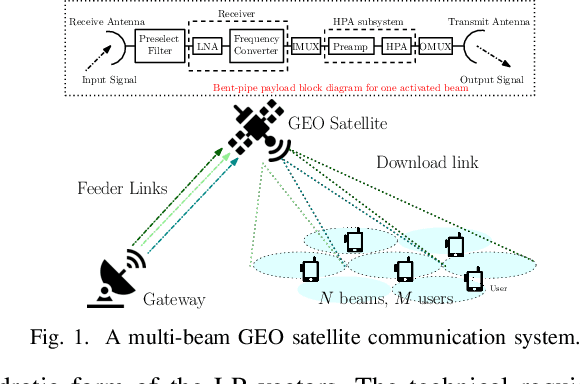
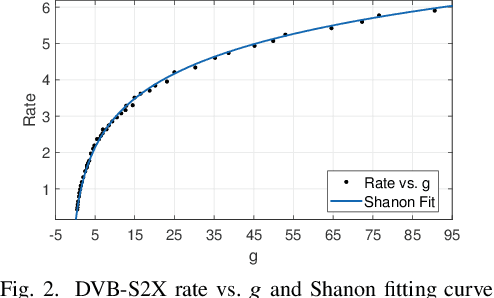
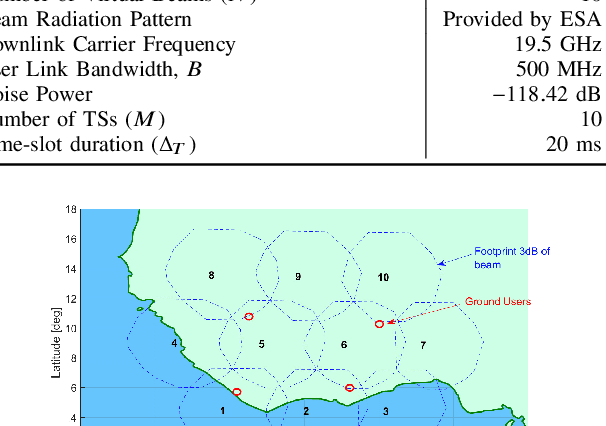
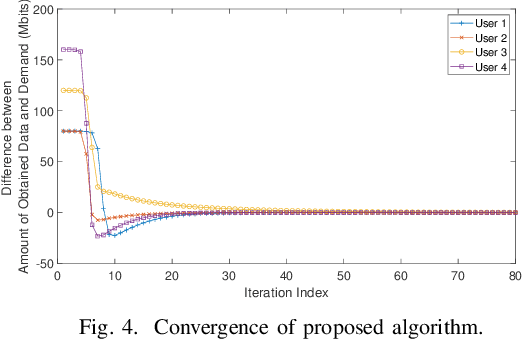
This paper aims to jointly determine linear precoding (LP) vectors, beam hopping (BH), and discrete DVB-S2X transmission rates for the GEO satellite communication systems to minimize the payload power consumption and satisfy ground users' demands within a time window. Regarding constraint on the maximum number of illuminated beams per time slot, the technical requirement is formulated as a sparse optimization problem in which the hardware-related beam illumination energy is modeled in a sparsity form of the LP vectors. To cope with this problem, the compressed sensing method is employed to transform the sparsity parts into the quadratic form of precoders. Then, an iterative window-based algorithm is developed to update the LP vectors sequentially to an efficient solution. Additionally, two other two-phase frameworks are also proposed for comparison purposes. In the first phase, these methods aim to determine the MODCOD transmission schemes for users to meet their demands by using a heuristic approach or DNN tool. In the second phase, the LP vectors of each time slot will be optimized separately based on the determined MODCOD schemes.
Space-Time-Separable Graph Convolutional Network for Pose Forecasting
Oct 09, 2021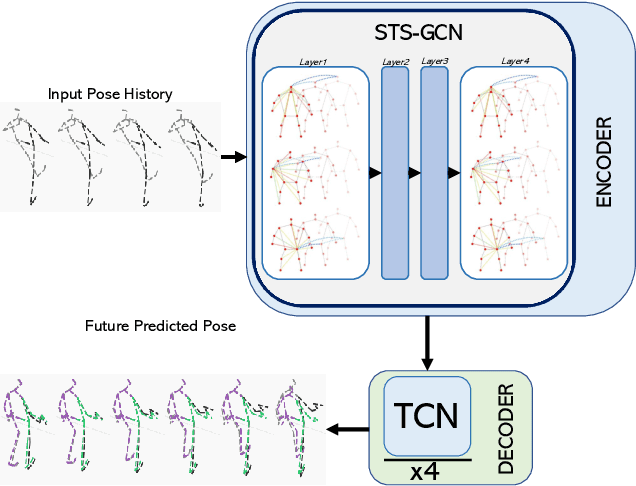
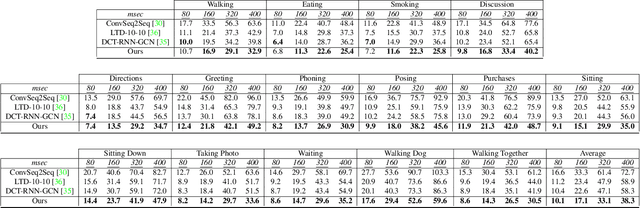
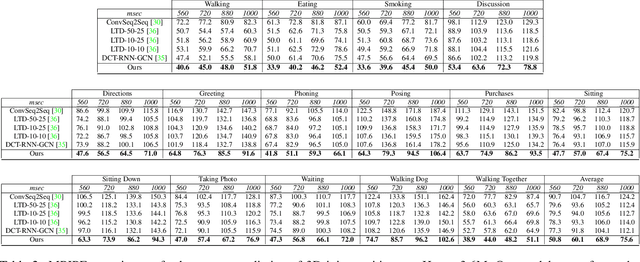
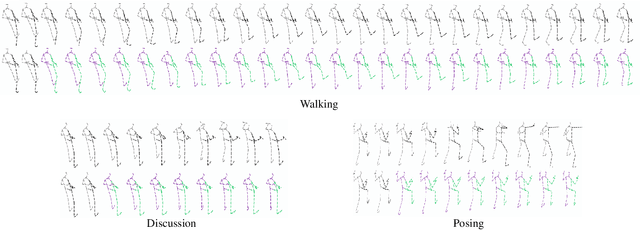
Human pose forecasting is a complex structured-data sequence-modelling task, which has received increasing attention, also due to numerous potential applications. Research has mainly addressed the temporal dimension as time series and the interaction of human body joints with a kinematic tree or by a graph. This has decoupled the two aspects and leveraged progress from the relevant fields, but it has also limited the understanding of the complex structural joint spatio-temporal dynamics of the human pose. Here we propose a novel Space-Time-Separable Graph Convolutional Network (STS-GCN) for pose forecasting. For the first time, STS-GCN models the human pose dynamics only with a graph convolutional network (GCN), including the temporal evolution and the spatial joint interaction within a single-graph framework, which allows the cross-talk of motion and spatial correlations. Concurrently, STS-GCN is the first space-time-separable GCN: the space-time graph connectivity is factored into space and time affinity matrices, which bottlenecks the space-time cross-talk, while enabling full joint-joint and time-time correlations. Both affinity matrices are learnt end-to-end, which results in connections substantially deviating from the standard kinematic tree and the linear-time time series. In experimental evaluation on three complex, recent and large-scale benchmarks, Human3.6M [Ionescu et al. TPAMI'14], AMASS [Mahmood et al. ICCV'19] and 3DPW [Von Marcard et al. ECCV'18], STS-GCN outperforms the state-of-the-art, surpassing the current best technique [Mao et al. ECCV'20] by over 32% in average at the most difficult long-term predictions, while only requiring 1.7% of its parameters. We explain the results qualitatively and illustrate the graph interactions by the factored joint-joint and time-time learnt graph connections. Our source code is available at: https://github.com/FraLuca/STSGCN
Sampling-Based Trajectory (re)planning for Differentially Flat Systems: Application to a 3D Gantry Crane
Sep 12, 2022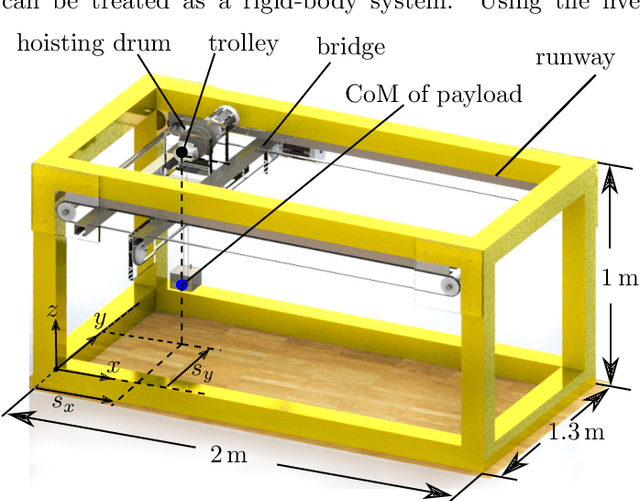
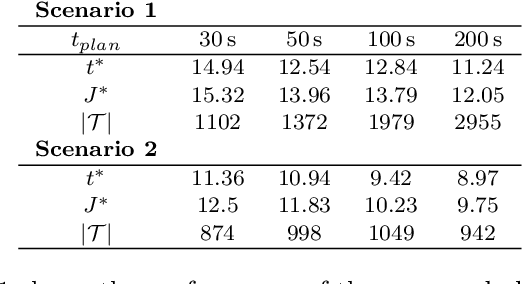
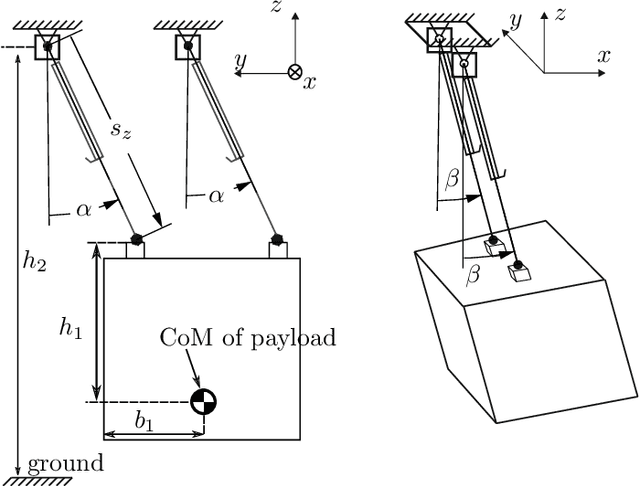
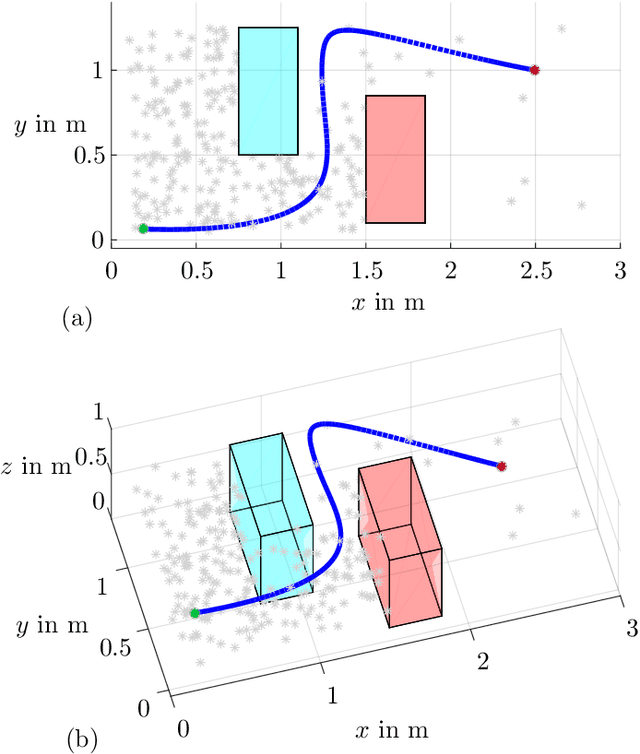
In this paper, a sampling-based trajectory planning algorithm for a laboratory-scale 3D gantry crane in an environment with static obstacles and subject to bounds on the velocity and acceleration of the gantry crane system is presented. The focus is on developing a fast motion planning algorithm for differentially flat systems, where intermediate results can be stored and reused for further tasks, such as replanning. The proposed approach is based on the informed optimal rapidly exploring random tree algorithm (informed RRT*), which is utilized to build trajectory trees that are reused for replanning when the start and/or target states change. In contrast to state-of-the-art approaches, the proposed motion planning algorithm incorporates a linear quadratic minimum time (LQTM) local planner. Thus, dynamic properties such as time optimality and the smoothness of the trajectory are directly considered in the proposed algorithm. Moreover, by integrating the branch-and-bound method to perform the pruning process on the trajectory tree, the proposed algorithm can eliminate points in the tree that do not contribute to finding better solutions. This helps to curb memory consumption and reduce the computational complexity during motion (re)planning. Simulation results for a validated mathematical model of a 3D gantry crane show the feasibility of the proposed approach.
Access Control with Encrypted Feature Maps for Object Detection Models
Sep 29, 2022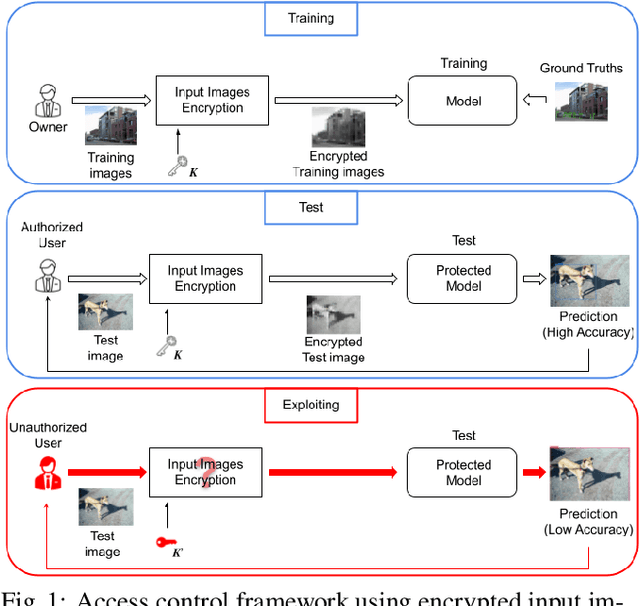
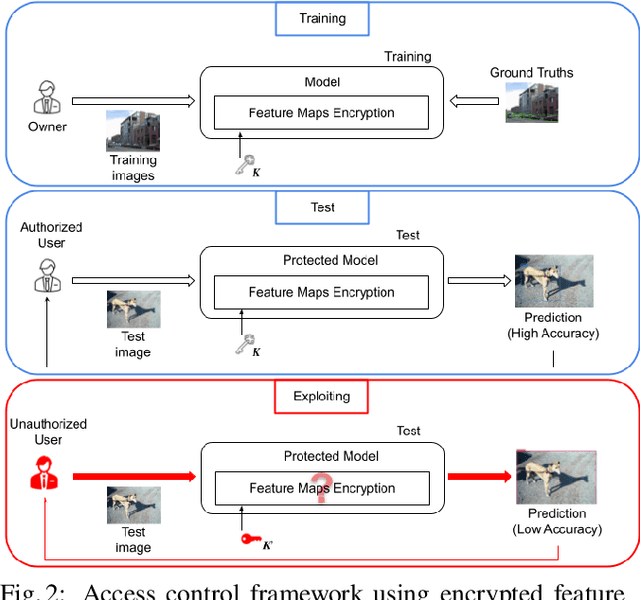
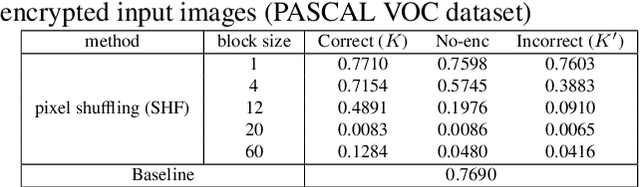
In this paper, we propose an access control method with a secret key for object detection models for the first time so that unauthorized users without a secret key cannot benefit from the performance of trained models. The method enables us not only to provide a high detection performance to authorized users but to also degrade the performance for unauthorized users. The use of transformed images was proposed for the access control of image classification models, but these images cannot be used for object detection models due to performance degradation. Accordingly, in this paper, selected feature maps are encrypted with a secret key for training and testing models, instead of input images. In an experiment, the protected models allowed authorized users to obtain almost the same performance as that of non-protected models but also with robustness against unauthorized access without a key.
Adaptive-SpikeNet: Event-based Optical Flow Estimation using Spiking Neural Networks with Learnable Neuronal Dynamics
Sep 21, 2022
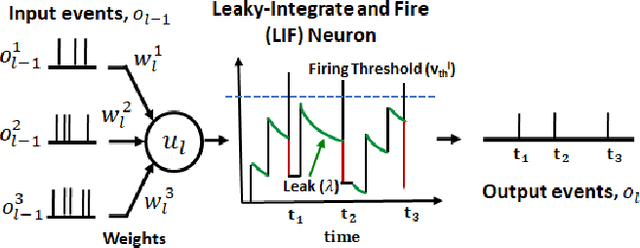
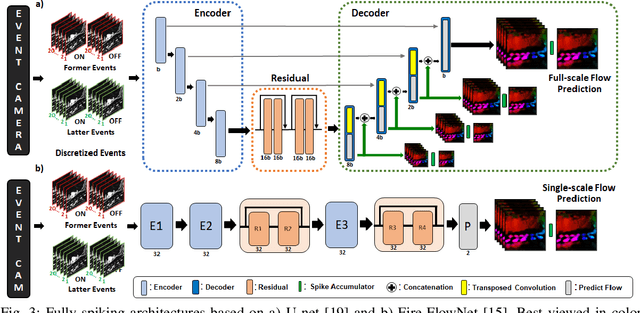
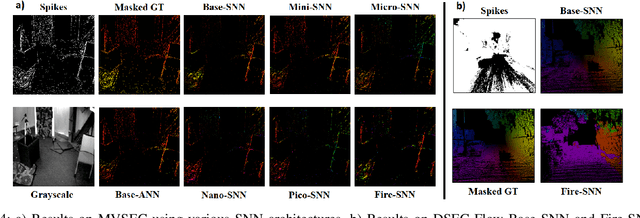
Event-based cameras have recently shown great potential for high-speed motion estimation owing to their ability to capture temporally rich information asynchronously. Spiking Neural Networks (SNNs), with their neuro-inspired event-driven processing can efficiently handle such asynchronous data, while neuron models such as the leaky-integrate and fire (LIF) can keep track of the quintessential timing information contained in the inputs. SNNs achieve this by maintaining a dynamic state in the neuron memory, retaining important information while forgetting redundant data over time. Thus, we posit that SNNs would allow for better performance on sequential regression tasks compared to similarly sized Analog Neural Networks (ANNs). However, deep SNNs are difficult to train due to vanishing spikes at later layers. To that effect, we propose an adaptive fully-spiking framework with learnable neuronal dynamics to alleviate the spike vanishing problem. We utilize surrogate gradient-based backpropagation through time (BPTT) to train our deep SNNs from scratch. We validate our approach for the task of optical flow estimation on the Multi-Vehicle Stereo Event-Camera (MVSEC) dataset and the DSEC-Flow dataset. Our experiments on these datasets show an average reduction of 13% in average endpoint error (AEE) compared to state-of-the-art ANNs. We also explore several down-scaled models and observe that our SNN models consistently outperform similarly sized ANNs offering 10%-16% lower AEE. These results demonstrate the importance of SNNs for smaller models and their suitability at the edge. In terms of efficiency, our SNNs offer substantial savings in network parameters (48x) and computational energy (51x) while attaining ~10% lower EPE compared to the state-of-the-art ANN implementations.
Channel Modeling for UAV-to-Ground Communications with Posture Variation and Fuselage Scattering Effect
Oct 11, 2022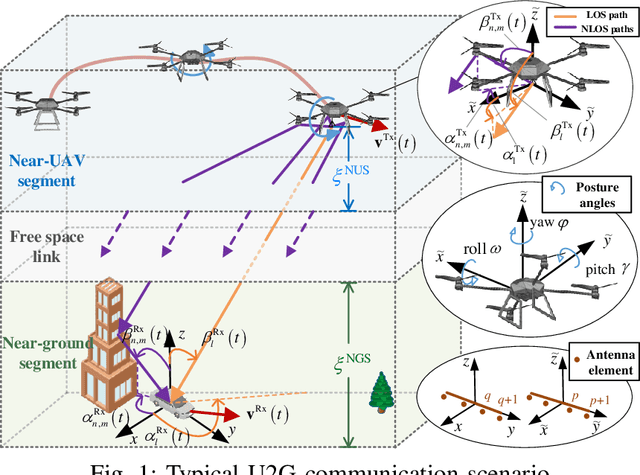
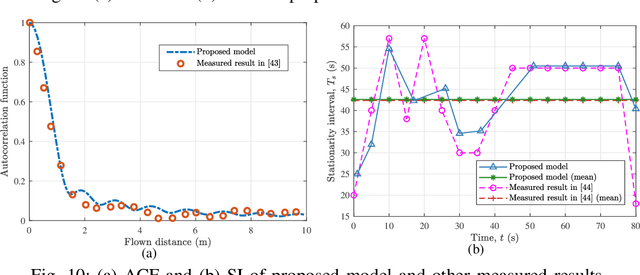
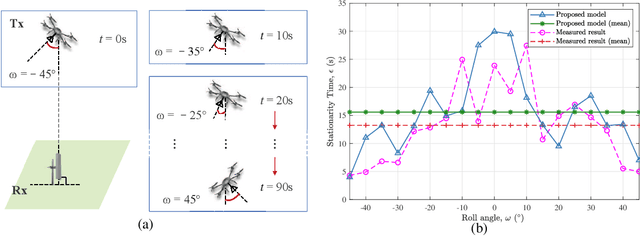
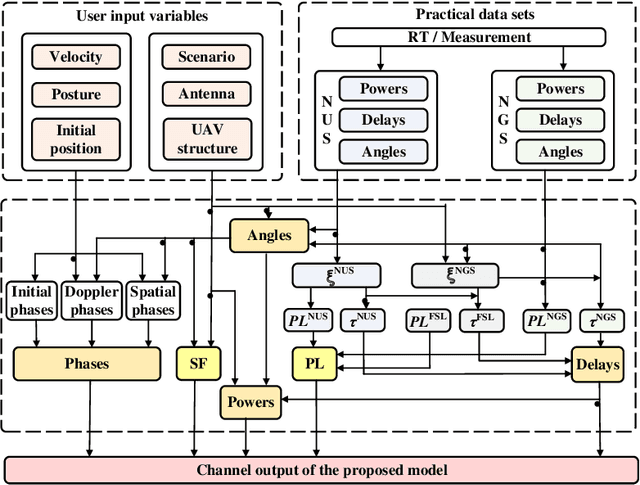
Unmanned aerial vehicle (UAV)-to-ground (U2G) channel models play a pivotal role for reliable communications between UAV and ground terminal. This paper proposes a three-dimensional (3D) non-stationary hybrid model including both large-scale and small-scale fading for U2G multiple-input-multiple-output (MIMO) channels. Distinctive channel characteristics under U2G scenarios, i.e., 3D trajectory and posture of UAV, fuselage scattering effect (FSE), and posture variation fading (PVF), are incorporated into the proposed model. The channel parameters, i.e., path loss (PL), shadow fading (SF), path delay, and path angle, are generated incorporating machine learning (ML) and ray tracing (RT) techniques to capture the structure-related characteristics. In order to guarantee the physical continuity of channel parameters such as Doppler phase and path power, the time evolution methods of inter- and intra- stationary intervals are proposed. Key statistical properties , i.e., temporal autocorrection function (ACF), power delay profile (PDP), level crossing rate (LCR), average fading duration (AFD), and stationary interval (SI) are given, and the impact of the change of fuselage and posture variation is analyzed. It is demonstrated that both posture variation and fuselage scattering have crucial effects on channel characteristics. The validity and practicability of the proposed model are verified by comparing the simulation results with the measured ones.
The Typical Behavior of Bandit Algorithms
Oct 11, 2022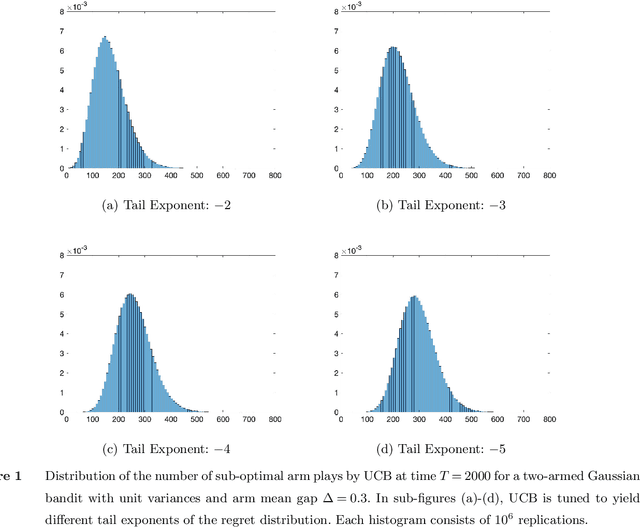
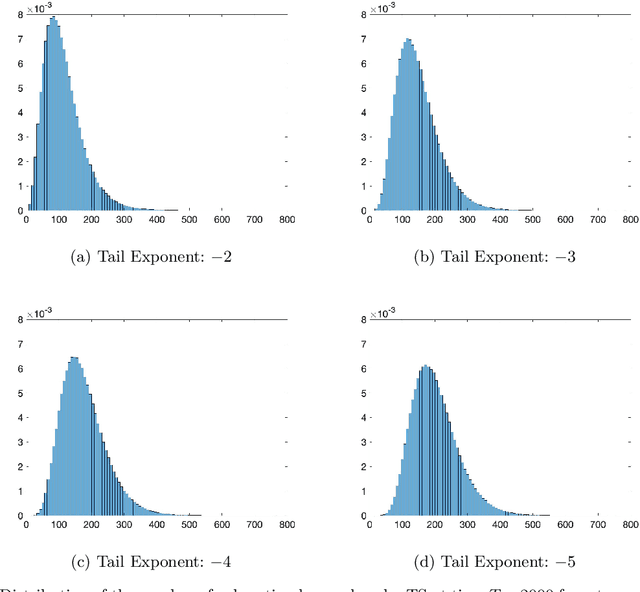
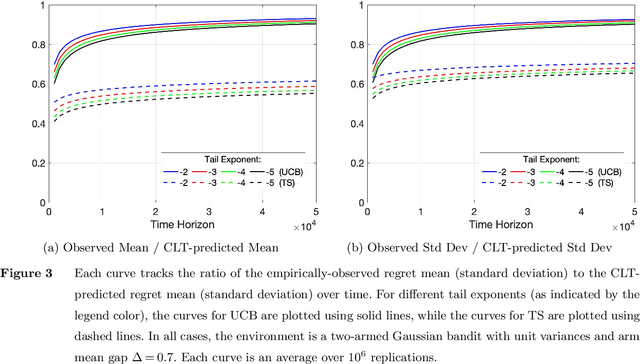
We establish strong laws of large numbers and central limit theorems for the regret of two of the most popular bandit algorithms: Thompson sampling and UCB. Here, our characterizations of the regret distribution complement the characterizations of the tail of the regret distribution recently developed by Fan and Glynn (2021) (arXiv:2109.13595). The tail characterizations there are associated with atypical bandit behavior on trajectories where the optimal arm mean is under-estimated, leading to mis-identification of the optimal arm and large regret. In contrast, our SLLN's and CLT's here describe the typical behavior and fluctuation of regret on trajectories where the optimal arm mean is properly estimated. We find that Thompson sampling and UCB satisfy the same SLLN and CLT, with the asymptotics of both the SLLN and the (mean) centering sequence in the CLT matching the asymptotics of expected regret. Both the mean and variance in the CLT grow at $\log(T)$ rates with the time horizon $T$. Asymptotically as $T \to \infty$, the variability in the number of plays of each sub-optimal arm depends only on the rewards received for that arm, which indicates that each sub-optimal arm contributes independently to the overall CLT variance.