 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Real-time System for Detecting Landslide Reports on Social Media using Artificial Intelligence
Feb 14, 2022
This paper presents an online system that leverages social media data in real time to identify landslide-related information automatically using state-of-the-art artificial intelligence techniques. The designed system can (i) reduce the information overload by eliminating duplicate and irrelevant content, (ii) identify landslide images, (iii) infer geolocation of the images, and (iv) categorize the user type (organization or person) of the account sharing the information. The system was deployed in February 2020 online at https://landslide-aidr.qcri.org/landslide_system.php to monitor live Twitter data stream and has been running continuously since then to provide time-critical information to partners such as British Geological Survey and European Mediterranean Seismological Centre. We trust this system can both contribute to harvesting of global landslide data for further research and support global landslide maps to facilitate emergency response and decision making.
Pixel-Level Equalized Matching for Video Object Segmentation
Sep 04, 2022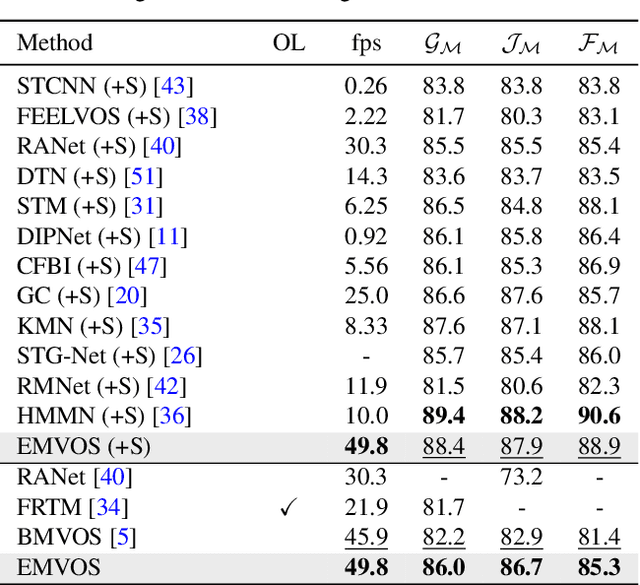
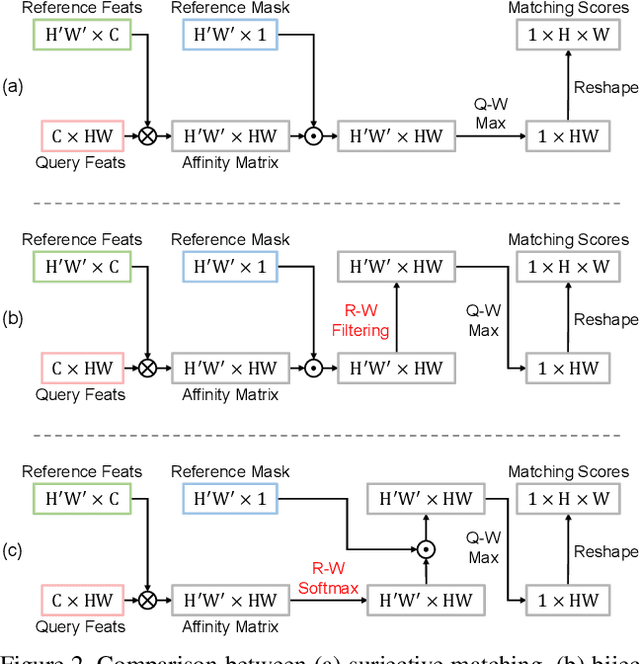
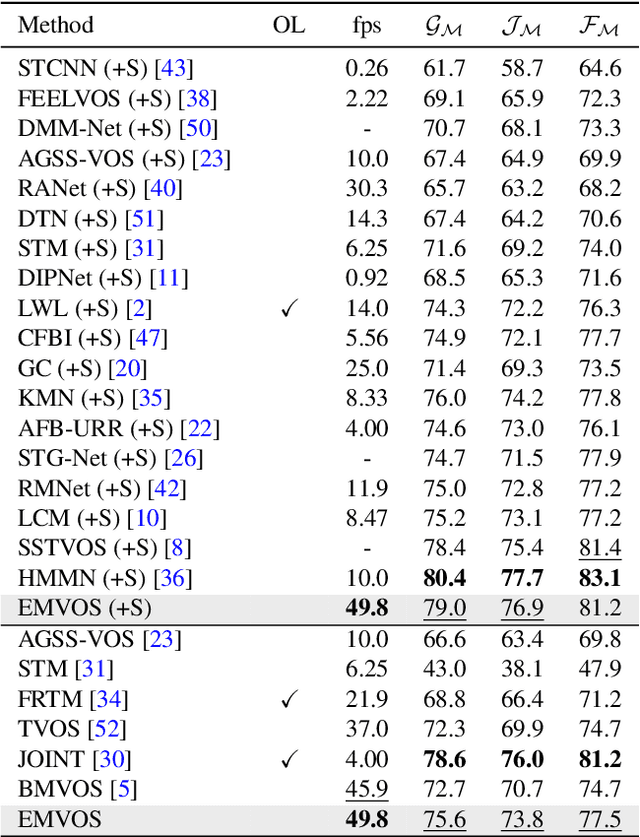
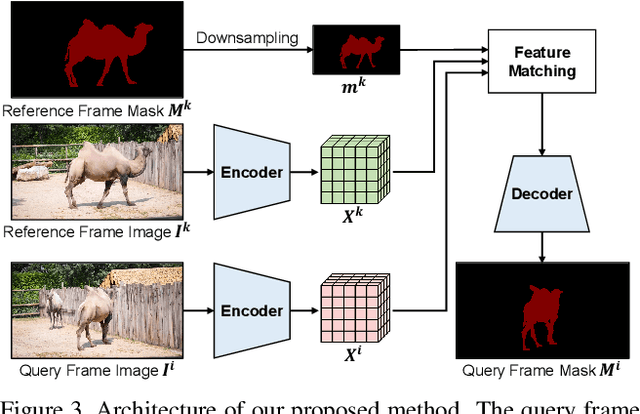
Feature similarity matching, which transfers the information of the reference frame to the query frame, is a key component in semi-supervised video object segmentation. If surjective matching is adopted, background distractors can easily occur and degrade the performance. Bijective matching mechanisms try to prevent this by restricting the amount of information being transferred to the query frame, but have two limitations: 1) surjective matching cannot be fully leveraged as it is transformed to bijective matching at test time; and 2) test-time manual tuning is required for searching the optimal hyper-parameters. To overcome these limitations while ensuring reliable information transfer, we introduce an equalized matching mechanism. To prevent the reference frame information from being overly referenced, the potential contribution to the query frame is equalized by simply applying a softmax operation along with the query. On public benchmark datasets, our proposed approach achieves a comparable performance to state-of-the-art methods.
XDoc: Unified Pre-training for Cross-Format Document Understanding
Oct 06, 2022



The surge of pre-training has witnessed the rapid development of document understanding recently. Pre-training and fine-tuning framework has been effectively used to tackle texts in various formats, including plain texts, document texts, and web texts. Despite achieving promising performance, existing pre-trained models usually target one specific document format at one time, making it difficult to combine knowledge from multiple document formats. To address this, we propose XDoc, a unified pre-trained model which deals with different document formats in a single model. For parameter efficiency, we share backbone parameters for different formats such as the word embedding layer and the Transformer layers. Meanwhile, we introduce adaptive layers with lightweight parameters to enhance the distinction across different formats. Experimental results have demonstrated that with only 36.7% parameters, XDoc achieves comparable or even better performance on a variety of downstream tasks compared with the individual pre-trained models, which is cost effective for real-world deployment. The code and pre-trained models will be publicly available at \url{https://aka.ms/xdoc}.
Enhancing Code Classification by Mixup-Based Data Augmentation
Oct 06, 2022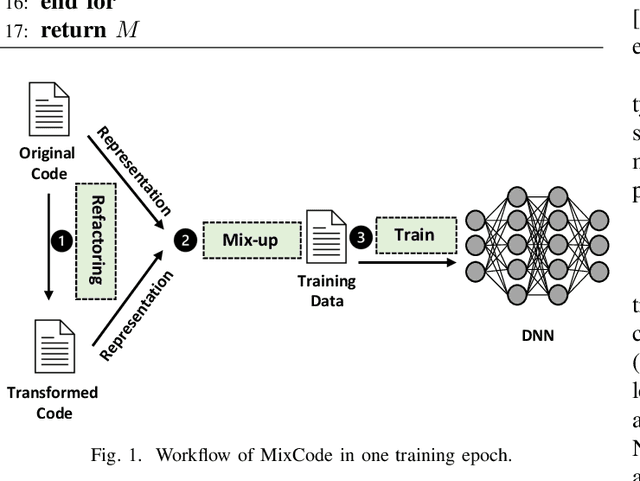
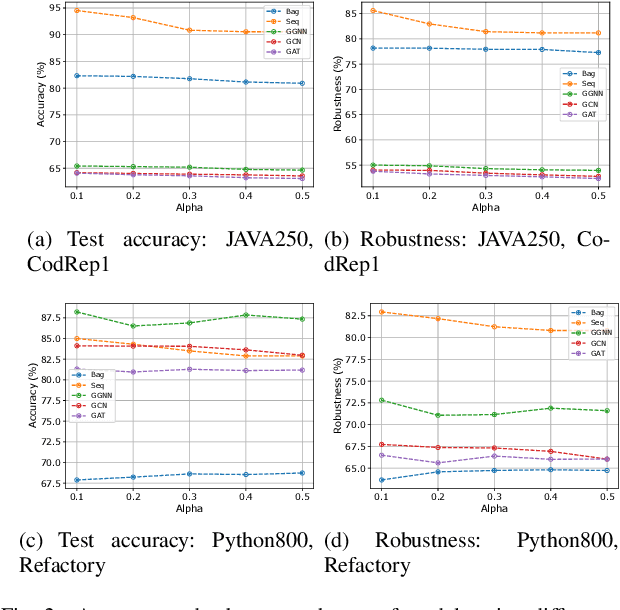
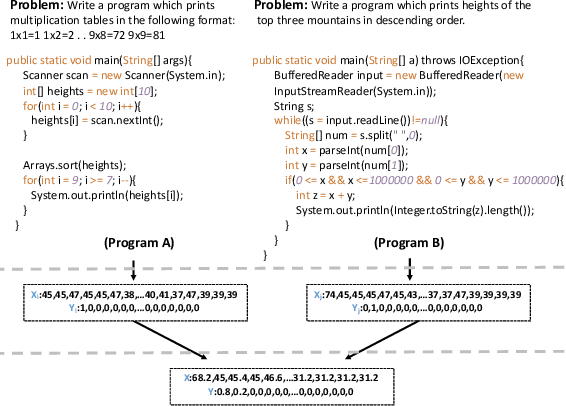
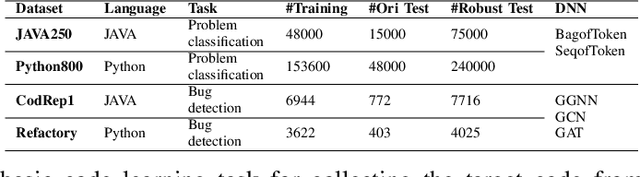
Recently, deep neural networks (DNNs) have been widely applied in programming language understanding. Generally, training a DNN model with competitive performance requires massive and high-quality labeled training data. However, collecting and labeling such data is time-consuming and labor-intensive. To tackle this issue, data augmentation has been a popular solution, which delicately increases the training data size, e.g., adversarial example generation. However, few works focus on employing it for programming language-related tasks. In this paper, we propose a Mixup-based data augmentation approach, MixCode, to enhance the source code classification task. First, we utilize multiple code refactoring methods to generate label-consistent code data. Second, the Mixup technique is employed to mix the original code and transformed code to form the new training data to train the model. We evaluate MixCode on two programming languages (JAVA and Python), two code tasks (problem classification and bug detection), four datasets (JAVA250, Python800, CodRep1, and Refactory), and 5 model architectures. Experimental results demonstrate that MixCode outperforms the standard data augmentation baseline by up to 6.24\% accuracy improvement and 26.06\% robustness improvement.
Deep Learning of Near Field Beam Focusing in Terahertz Wideband Massive MIMO Systems
Oct 06, 2022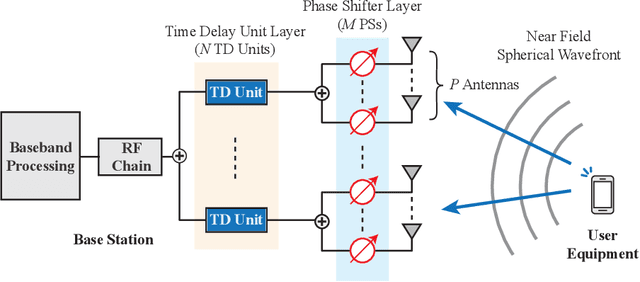
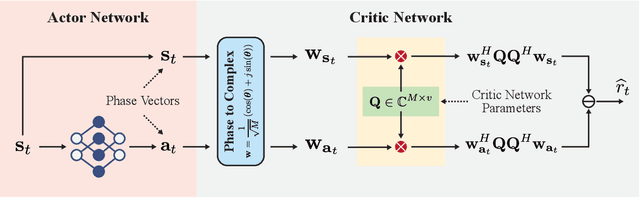
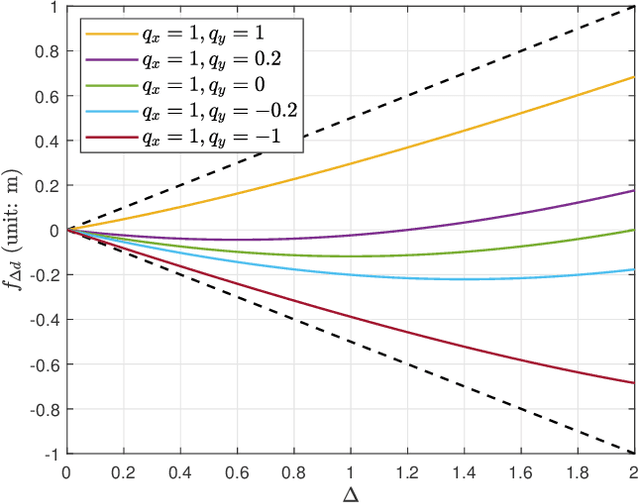
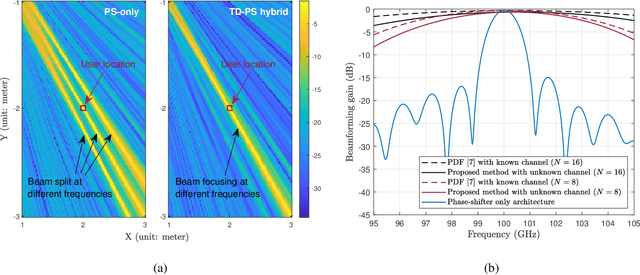
Employing large antenna arrays and utilizing large bandwidth have the potential of bringing very high data rates to future wireless communication systems. To achieve that, however, new challenges associated with these systems need to be addressed. First, the large array aperture brings the communications to the near-field region, where the far-field assumptions no longer hold. Second, the analog-only (phase shifter based) beamforming architectures result in performance degradation in wideband systems due to their frequency unawareness. To address these problems, this paper proposes a low-complexity frequency-aware near-field beamforming framework for hybrid time-delay (TD) and phase-shifter (PS) based RF architectures. Specifically, a \textit{signal model inspired online learning} framework is proposed to learn the phase shifts of the quantized analog phase-shifters. Thanks to the model-inspired design, the proposed learning approach has fast convergence performance. Further, a low-complexity \textit{geometry-assisted} method is developed to configure the delay settings of the TD units. Simulation results highlight the efficacy of the proposed solution in achieving robust near-field beamforming performance for wideband large antenna array systems.
Designing a Robust Low-Level Agnostic Controller for a Quadrotor with Actor-Critic Reinforcement Learning
Oct 06, 2022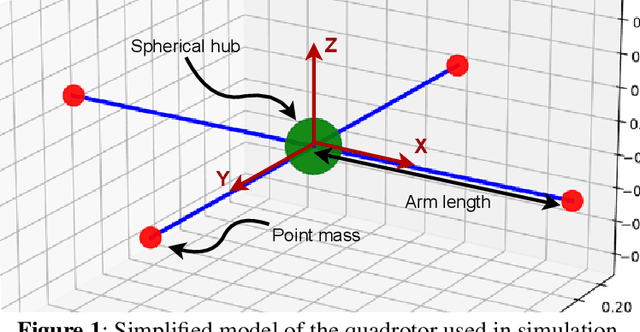
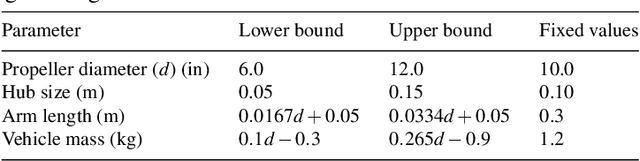

Purpose: Real-life applications using quadrotors introduce a number of disturbances and time-varying properties that pose a challenge to flight controllers. We observed that, when a quadrotor is tasked with picking up and dropping a payload, traditional PID and RL-based controllers found in literature struggle to maintain flight after the vehicle changes its dynamics due to interaction with this external object. Methods: In this work, we introduce domain randomization during the training phase of a low-level waypoint guidance controller based on Soft Actor-Critic. The resulting controller is evaluated on the proposed payload pick up and drop task with added disturbances that emulate real-life operation of the vehicle. Results & Conclusion: We show that, by introducing a certain degree of uncertainty in quadrotor dynamics during training, we can obtain a controller that is capable to perform the proposed task using a larger variation of quadrotor parameters. Additionally, the RL-based controller outperforms a traditional positional PID controller with optimized gains in this task, while remaining agnostic to different simulation parameters.
Data Budgeting for Machine Learning
Oct 03, 2022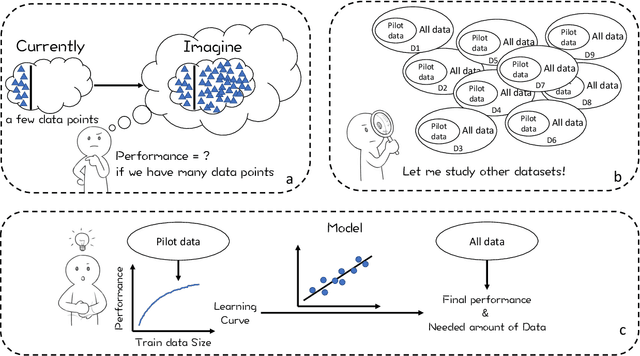


Data is the fuel powering AI and creates tremendous value for many domains. However, collecting datasets for AI is a time-consuming, expensive, and complicated endeavor. For practitioners, data investment remains to be a leap of faith in practice. In this work, we study the data budgeting problem and formulate it as two sub-problems: predicting (1) what is the saturating performance if given enough data, and (2) how many data points are needed to reach near the saturating performance. Different from traditional dataset-independent methods like PowerLaw, we proposed a learning method to solve data budgeting problems. To support and systematically evaluate the learning-based method for data budgeting, we curate a large collection of 383 tabular ML datasets, along with their data vs performance curves. Our empirical evaluation shows that it is possible to perform data budgeting given a small pilot study dataset with as few as $50$ data points.
One-shot Detail Retouching with Patch Space Neural Field based Transformation Blending
Oct 03, 2022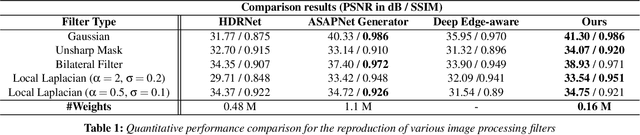
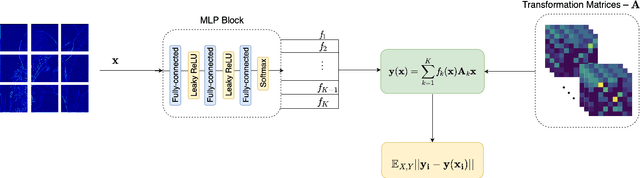

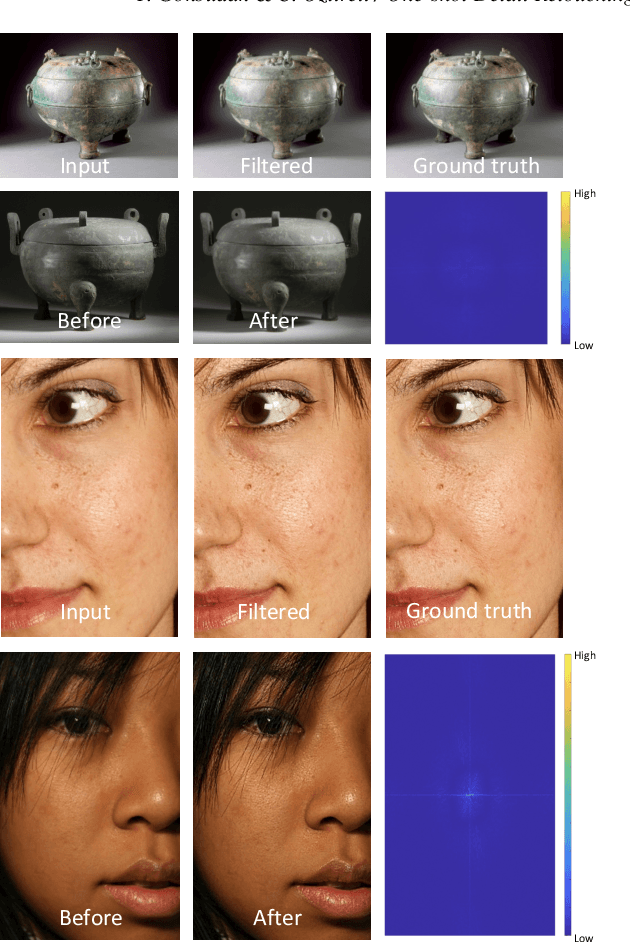
Photo retouching is a difficult task for novice users as it requires expert knowledge and advanced tools. Photographers often spend a great deal of time generating high-quality retouched photos with intricate details. In this paper, we introduce a one-shot learning based technique to automatically retouch details of an input image based on just a single pair of before and after example images. Our approach provides accurate and generalizable detail edit transfer to new images. We achieve these by proposing a new representation for image to image maps. Specifically, we propose neural field based transformation blending in the patch space for defining patch to patch transformations for each frequency band. This parametrization of the map with anchor transformations and associated weights, and spatio-spectral localized patches, allows us to capture details well while staying generalizable. We evaluate our technique both on known ground truth filtes and artist retouching edits. Our method accurately transfers complex detail retouching edits.
Optimizing Data Collection for Machine Learning
Oct 03, 2022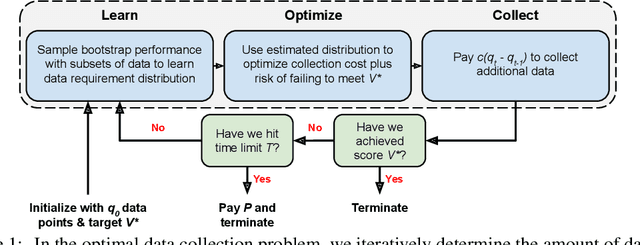
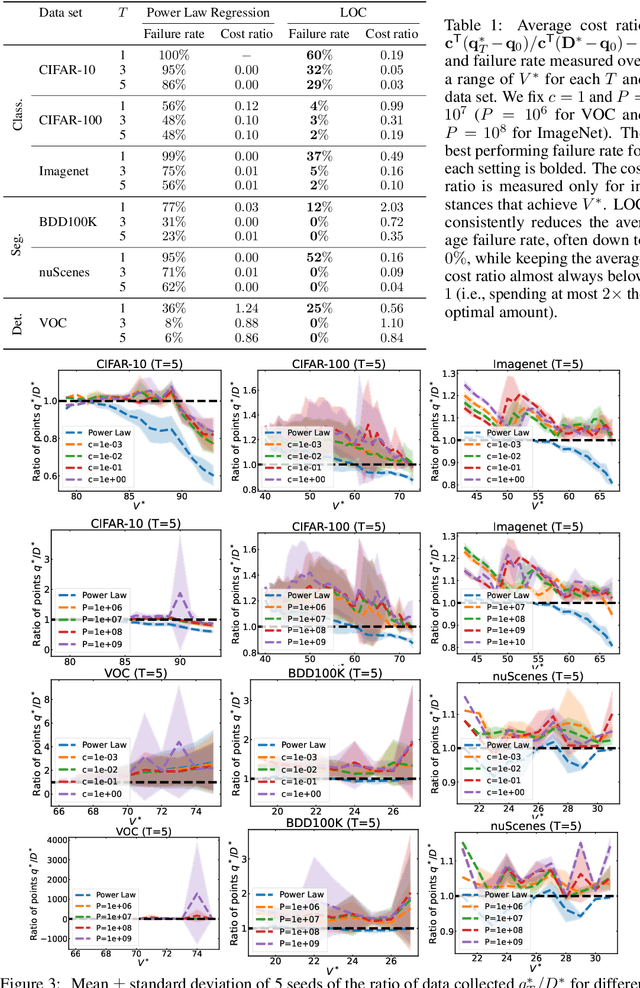
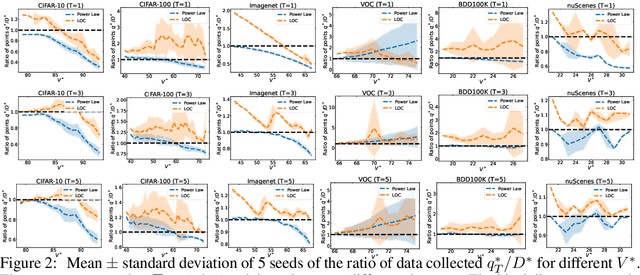
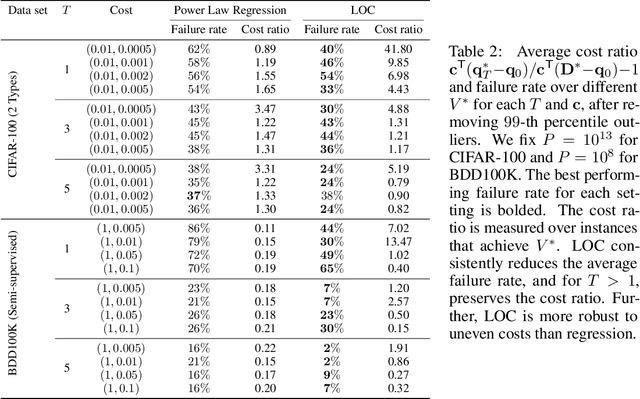
Modern deep learning systems require huge data sets to achieve impressive performance, but there is little guidance on how much or what kind of data to collect. Over-collecting data incurs unnecessary present costs, while under-collecting may incur future costs and delay workflows. We propose a new paradigm for modeling the data collection workflow as a formal optimal data collection problem that allows designers to specify performance targets, collection costs, a time horizon, and penalties for failing to meet the targets. Additionally, this formulation generalizes to tasks requiring multiple data sources, such as labeled and unlabeled data used in semi-supervised learning. To solve our problem, we develop Learn-Optimize-Collect (LOC), which minimizes expected future collection costs. Finally, we numerically compare our framework to the conventional baseline of estimating data requirements by extrapolating from neural scaling laws. We significantly reduce the risks of failing to meet desired performance targets on several classification, segmentation, and detection tasks, while maintaining low total collection costs.
An attention-based backend allowing efficient fine-tuning of transformer models for speaker verification
Oct 03, 2022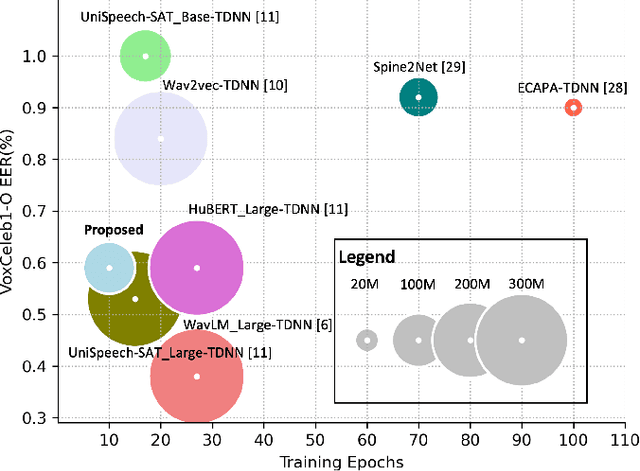

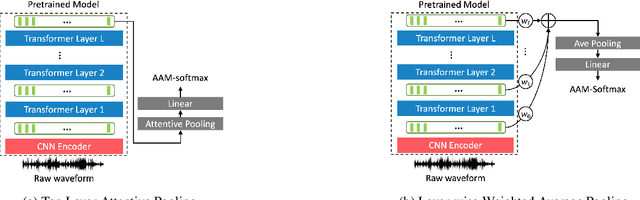

In recent years, self-supervised learning paradigm has received extensive attention due to its great success in various down-stream tasks. However, the fine-tuning strategies for adapting those pre-trained models to speaker verification task have yet to be fully explored. In this paper, we analyze several feature extraction approaches built on top of a pre-trained model, as well as regularization and learning rate schedule to stabilize the fine-tuning process and further boost performance: multi-head factorized attentive pooling is proposed to factorize the comparison of speaker representations into multiple phonetic clusters. We regularize towards the parameters of the pre-trained model and we set different learning rates for each layer of the pre-trained model during fine-tuning. The experimental results show our method can significantly shorten the training time to 4 hours and achieve SOTA performance: 0.59%, 0.79% and 1.77% EER on Vox1-O, Vox1-E and Vox1-H, respectively.