 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
InterpretTime: a new approach for the systematic evaluation of neural-network interpretability in time series classification
Feb 11, 2022
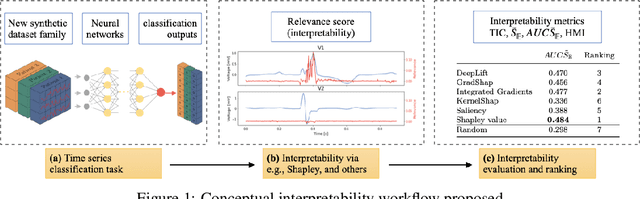
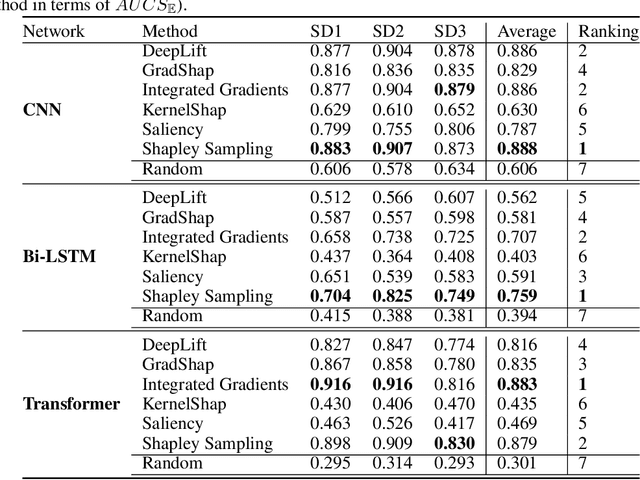
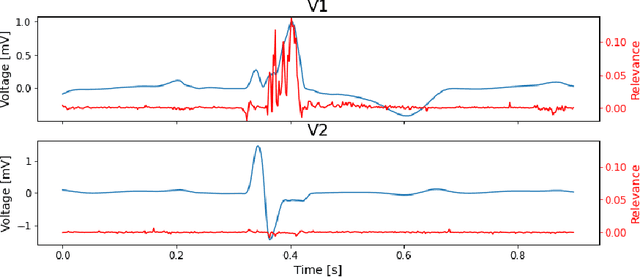
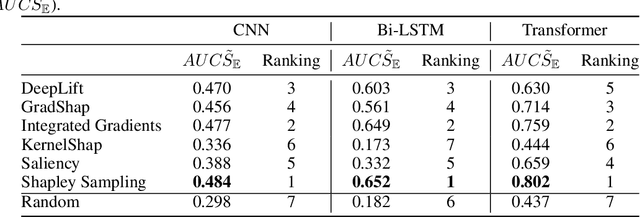
We present a novel approach to evaluate the performance of interpretability methods for time series classification, and propose a new strategy to assess the similarity between domain experts and machine data interpretation. The novel approach leverages a new family of synthetic datasets and introduces new interpretability evaluation metrics. The approach addresses several common issues encountered in the literature, and clearly depicts how well an interpretability method is capturing neural network's data usage, providing a systematic interpretability evaluation framework. The new methodology highlights the superiority of Shapley Value Sampling and Integrated Gradients for interpretability in time-series classification tasks.
SSDNet: State Space Decomposition Neural Network for Time Series Forecasting
Dec 19, 2021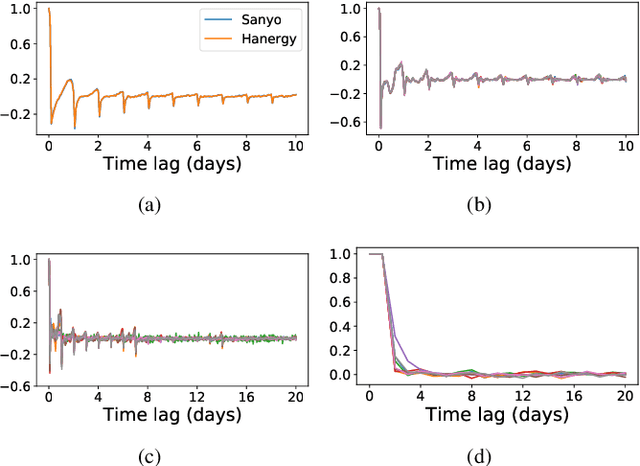
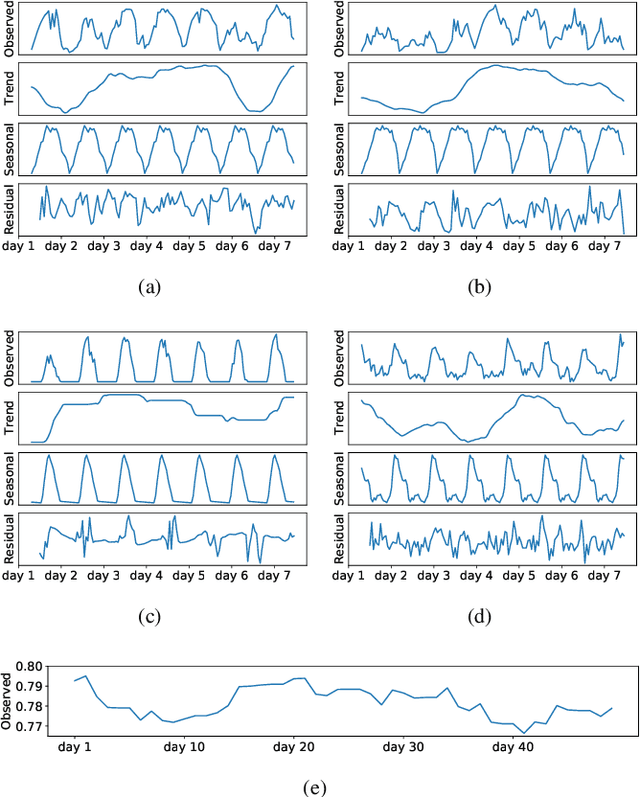
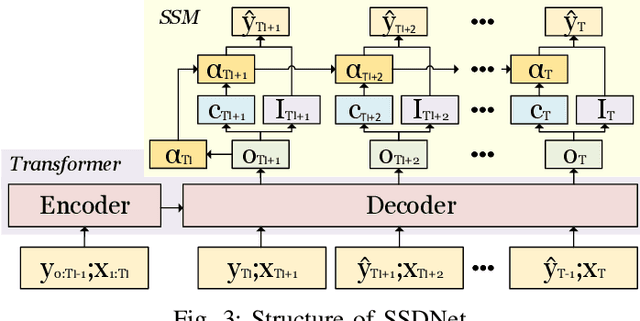
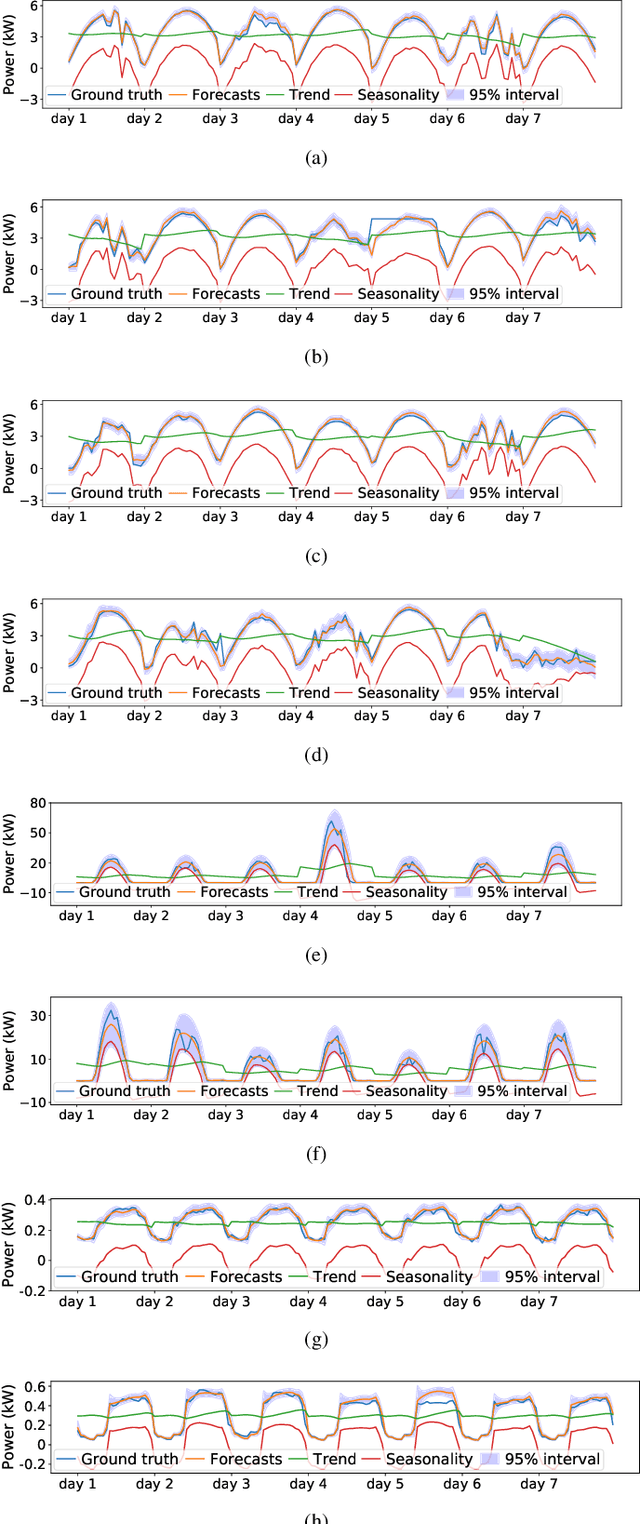
In this paper, we present SSDNet, a novel deep learning approach for time series forecasting. SSDNet combines the Transformer architecture with state space models to provide probabilistic and interpretable forecasts, including trend and seasonality components and previous time steps important for the prediction. The Transformer architecture is used to learn the temporal patterns and estimate the parameters of the state space model directly and efficiently, without the need for Kalman filters. We comprehensively evaluate the performance of SSDNet on five data sets, showing that SSDNet is an effective method in terms of accuracy and speed, outperforming state-of-the-art deep learning and statistical methods, and able to provide meaningful trend and seasonality components.
Multi-dataset Training of Transformers for Robust Action Recognition
Sep 27, 2022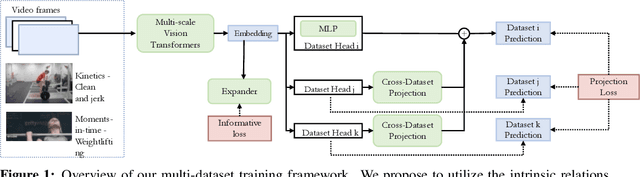
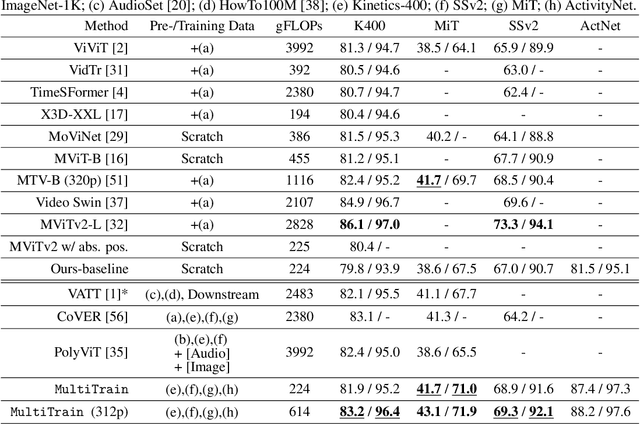
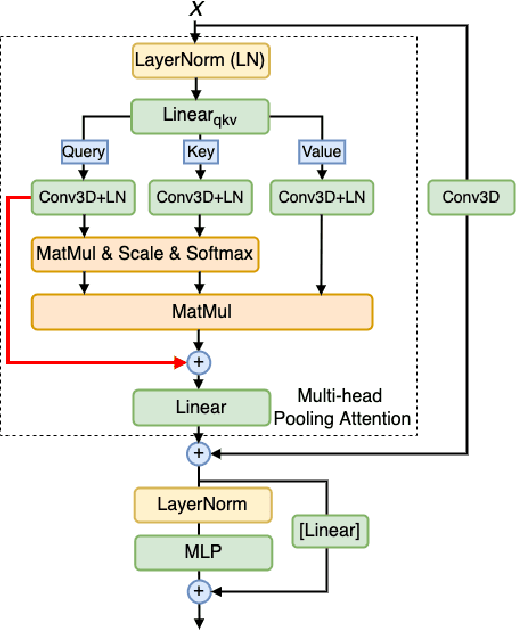

We study the task of robust feature representations, aiming to generalize well on multiple datasets for action recognition. We build our method on Transformers for its efficacy. Although we have witnessed great progress for video action recognition in the past decade, it remains challenging yet valuable how to train a single model that can perform well across multiple datasets. Here, we propose a novel multi-dataset training paradigm, MultiTrain, with the design of two new loss terms, namely informative loss and projection loss, aiming to learn robust representations for action recognition. In particular, the informative loss maximizes the expressiveness of the feature embedding while the projection loss for each dataset mines the intrinsic relations between classes across datasets. We verify the effectiveness of our method on five challenging datasets, Kinetics-400, Kinetics-700, Moments-in-Time, Activitynet and Something-something-v2 datasets. Extensive experimental results show that our method can consistently improve the state-of-the-art performance.
Learning Video-independent Eye Contact Segmentation from In-the-Wild Videos
Oct 05, 2022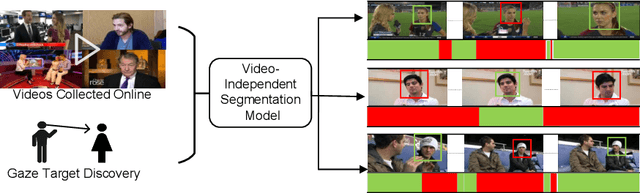

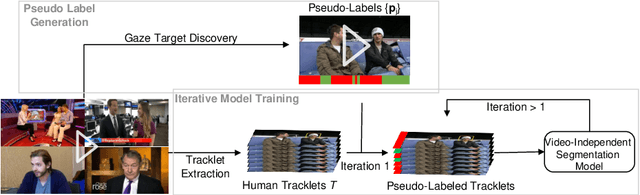
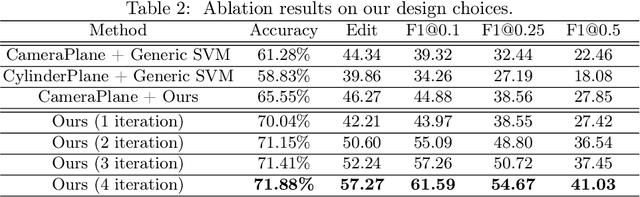
Human eye contact is a form of non-verbal communication and can have a great influence on social behavior. Since the location and size of the eye contact targets vary across different videos, learning a generic video-independent eye contact detector is still a challenging task. In this work, we address the task of one-way eye contact detection for videos in the wild. Our goal is to build a unified model that can identify when a person is looking at his gaze targets in an arbitrary input video. Considering that this requires time-series relative eye movement information, we propose to formulate the task as a temporal segmentation. Due to the scarcity of labeled training data, we further propose a gaze target discovery method to generate pseudo-labels for unlabeled videos, which allows us to train a generic eye contact segmentation model in an unsupervised way using in-the-wild videos. To evaluate our proposed approach, we manually annotated a test dataset consisting of 52 videos of human conversations. Experimental results show that our eye contact segmentation model outperforms the previous video-dependent eye contact detector and can achieve 71.88% framewise accuracy on our annotated test set. Our code and evaluation dataset are available at https://github.com/ut-vision/Video-Independent-ECS.
A Unified Multi-Task Learning Framework of Real-Time Drone Supervision for Crowd Counting
Feb 08, 2022In this paper, a novel Unified Multi-Task Learning Framework of Real-Time Drone Supervision for Crowd Counting (MFCC) is proposed, which utilizes an image fusion network architecture to fuse images from the visible and thermal infrared image, and a crowd counting network architecture to estimate the density map. The purpose of our framework is to fuse two modalities, including visible and thermal infrared images captured by drones in real-time, that exploit the complementary information to accurately count the dense population and then automatically guide the flight of the drone to supervise the dense crowd. To this end, we propose the unified multi-task learning framework for crowd counting for the first time and re-design the unified training loss functions to align the image fusion network and crowd counting network. We also design the Assisted Learning Module (ALM) to fuse the density map feature to the image fusion encoder process for learning the counting features. To improve the accuracy, we propose the Extensive Context Extraction Module (ECEM) that is based on a dense connection architecture to encode multi-receptive-fields contextual information and apply the Multi-domain Attention Block (MAB) for concerning the head region in the drone view. Finally, we apply the prediction map to automatically guide the drones to supervise the dense crowd. The experimental results on the DroneRGBT dataset show that, compared with the existing methods, ours has comparable results on objective evaluations and an easier training process.
Common human diseases prediction using machine learning based on survey data
Sep 22, 2022



In this era, the moment has arrived to move away from disease as the primary emphasis of medical treatment. Although impressive, the multiple techniques that have been developed to detect the diseases. In this time, there are some types of diseases COVID-19, normal flue, migraine, lung disease, heart disease, kidney disease, diabetics, stomach disease, gastric, bone disease, autism are the very common diseases. In this analysis, we analyze disease symptoms and have done disease predictions based on their symptoms. We studied a range of symptoms and took a survey from people in order to complete the task. Several classification algorithms have been employed to train the model. Furthermore, performance evaluation matrices are used to measure the model's performance. Finally, we discovered that the part classifier surpasses the others.
Out-of-Distribution Detection and Selective Generation for Conditional Language Models
Sep 30, 2022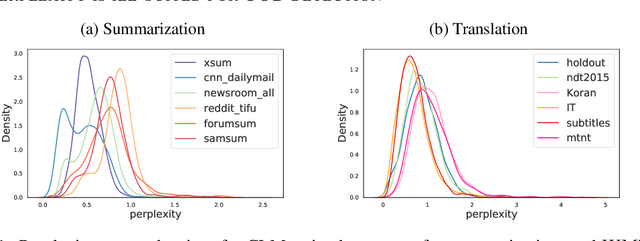
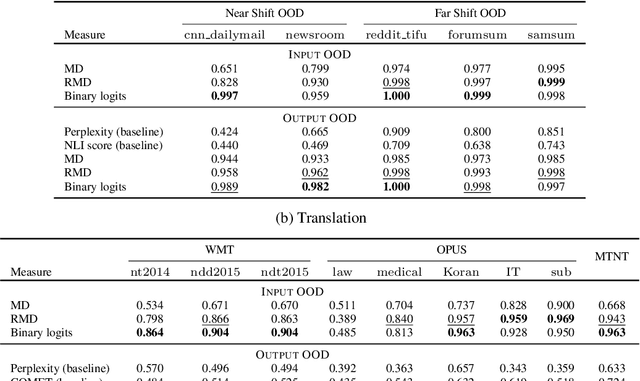
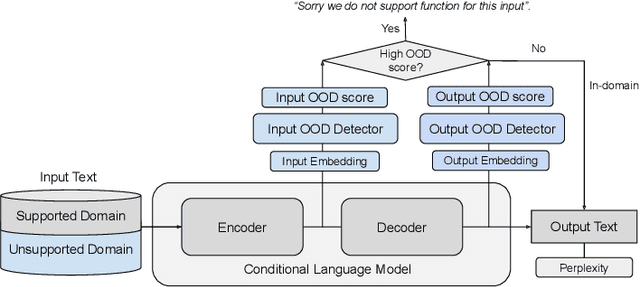
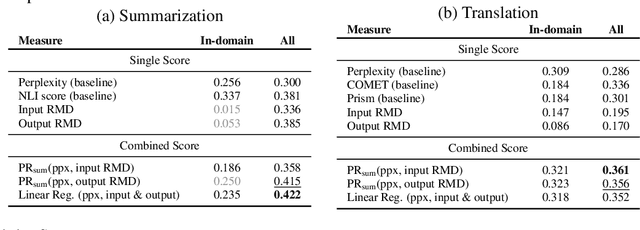
Machine learning algorithms typically assume independent and identically distributed samples in training and at test time. Much work has shown that high-performing ML classifiers can degrade significantly and provide overly-confident, wrong classification predictions, particularly for out-of-distribution (OOD) inputs. Conditional language models (CLMs) are predominantly trained to classify the next token in an output sequence, and may suffer even worse degradation on OOD inputs as the prediction is done auto-regressively over many steps. Furthermore, the space of potential low-quality outputs is larger as arbitrary text can be generated and it is important to know when to trust the generated output. We present a highly accurate and lightweight OOD detection method for CLMs, and demonstrate its effectiveness on abstractive summarization and translation. We also show how our method can be used under the common and realistic setting of distribution shift for selective generation (analogous to selective prediction for classification) of high-quality outputs, while automatically abstaining from low-quality ones, enabling safer deployment of generative language models.
Experts in the Loop: Conditional Variable Selection for Accelerating Post-Silicon Analysis Based on Deep Learning
Sep 30, 2022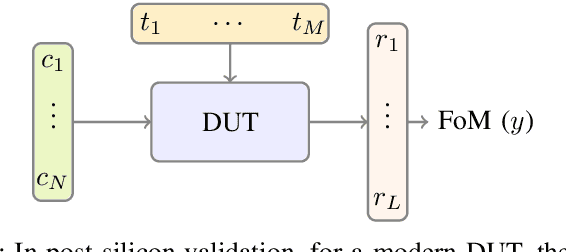
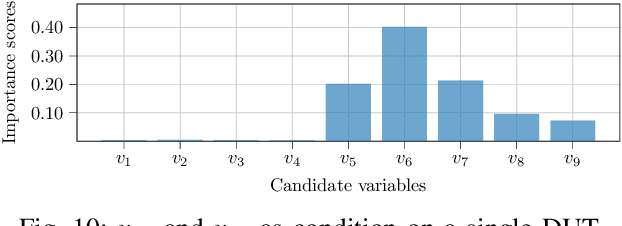
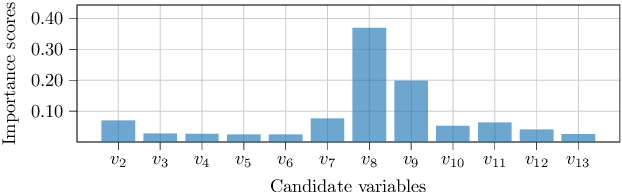
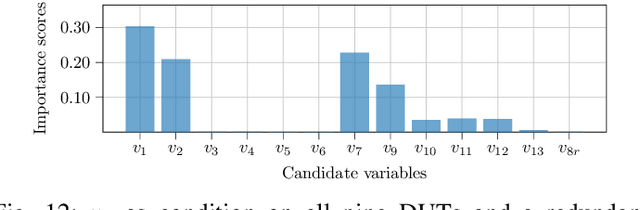
Post-silicon validation is one of the most critical processes in modern semiconductor manufacturing. Specifically, correct and deep understanding in test cases of manufactured devices is key to enable post-silicon tuning and debugging. This analysis is typically performed by experienced human experts. However, with the fast development in semiconductor industry, test cases can contain hundreds of variables. The resulting high-dimensionality poses enormous challenges to experts. Thereby, some recent prior works have introduced data-driven variable selection algorithms to tackle these problems and achieved notable success. Nevertheless, for these methods, experts are not involved in training and inference phases, which may lead to bias and inaccuracy due to the lack of prior knowledge. Hence, this work for the first time aims to design a novel conditional variable selection approach while keeping experts in the loop. In this way, we expect that our algorithm can be more efficiently and effectively trained to identify the most critical variables under certain expert knowledge. Extensive experiments on both synthetic and real-world datasets from industry have been conducted and shown the effectiveness of our method.
Efficient LSTM Training with Eligibility Traces
Sep 30, 2022Training recurrent neural networks is predominantly achieved via backpropagation through time (BPTT). However, this algorithm is not an optimal solution from both a biological and computational perspective. A more efficient and biologically plausible alternative for BPTT is e-prop. We investigate the applicability of e-prop to long short-term memorys (LSTMs), for both supervised and reinforcement learning (RL) tasks. We show that e-prop is a suitable optimization algorithm for LSTMs by comparing it to BPTT on two benchmarks for supervised learning. This proves that e-prop can achieve learning even for problems with long sequences of several hundred timesteps. We introduce extensions that improve the performance of e-prop, which can partially be applied to other network architectures. With the help of these extensions we show that, under certain conditions, e-prop can outperform BPTT for one of the two benchmarks for supervised learning. Finally, we deliver a proof of concept for the integration of e-prop to RL in the domain of deep recurrent Q-learning.
Learning Decoupled Retrieval Representation for Nearest Neighbour Neural Machine Translation
Sep 20, 2022



K-Nearest Neighbor Neural Machine Translation (kNN-MT) successfully incorporates external corpus by retrieving word-level representations at test time. Generally, kNN-MT borrows the off-the-shelf context representation in the translation task, e.g., the output of the last decoder layer, as the query vector of the retrieval task. In this work, we highlight that coupling the representations of these two tasks is sub-optimal for fine-grained retrieval. To alleviate it, we leverage supervised contrastive learning to learn the distinctive retrieval representation derived from the original context representation. We also propose a fast and effective approach to constructing hard negative samples. Experimental results on five domains show that our approach improves the retrieval accuracy and BLEU score compared to vanilla kNN-MT.