 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data
Feb 08, 2022
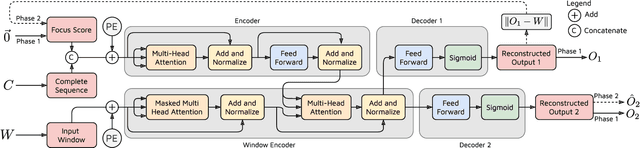
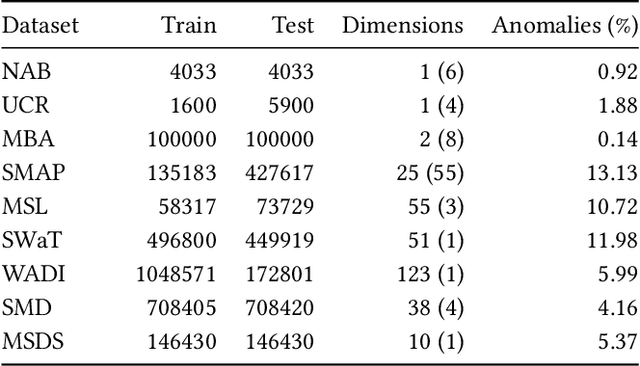
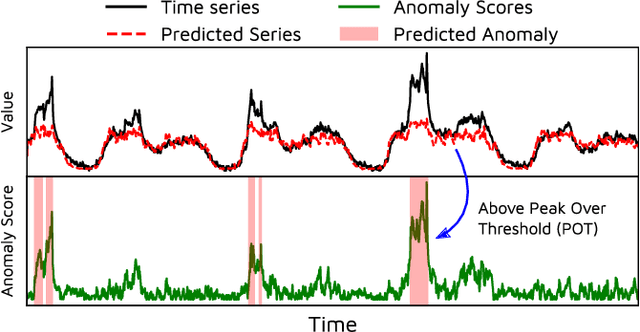
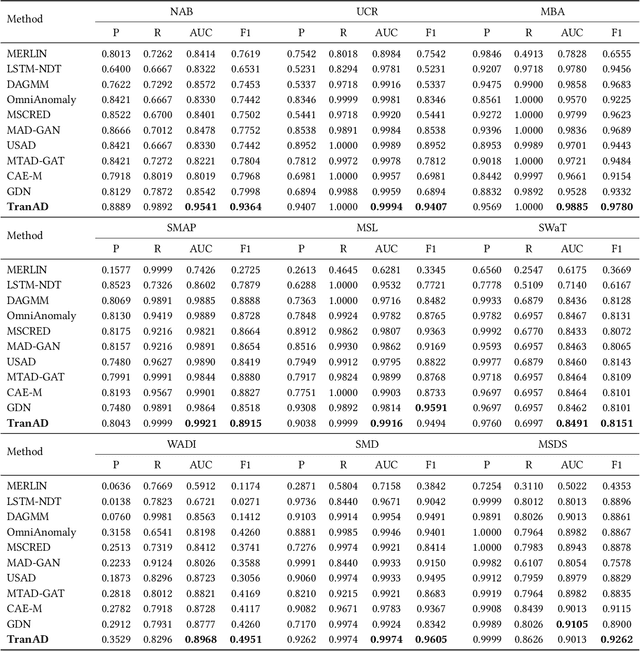
Efficient anomaly detection and diagnosis in multivariate time-series data is of great importance for modern industrial applications. However, building a system that is able to quickly and accurately pinpoint anomalous observations is a challenging problem. This is due to the lack of anomaly labels, high data volatility and the demands of ultra-low inference times in modern applications. Despite the recent developments of deep learning approaches for anomaly detection, only a few of them can address all of these challenges. In this paper, we propose TranAD, a deep transformer network based anomaly detection and diagnosis model which uses attention-based sequence encoders to swiftly perform inference with the knowledge of the broader temporal trends in the data. TranAD uses focus score-based self-conditioning to enable robust multi-modal feature extraction and adversarial training to gain stability. Additionally, model-agnostic meta learning (MAML) allows us to train the model using limited data. Extensive empirical studies on six publicly available datasets demonstrate that TranAD can outperform state-of-the-art baseline methods in detection and diagnosis performance with data and time-efficient training. Specifically, TranAD increases F1 scores by up to 17%, reducing training times by up to 99% compared to the baselines.
mini-ELSA: using Machine Learning to improve space efficiency in Edge Lightweight Searchable Attribute-based encryption for Industry 4.0
Sep 22, 2022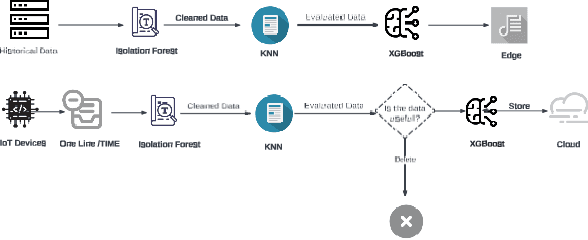
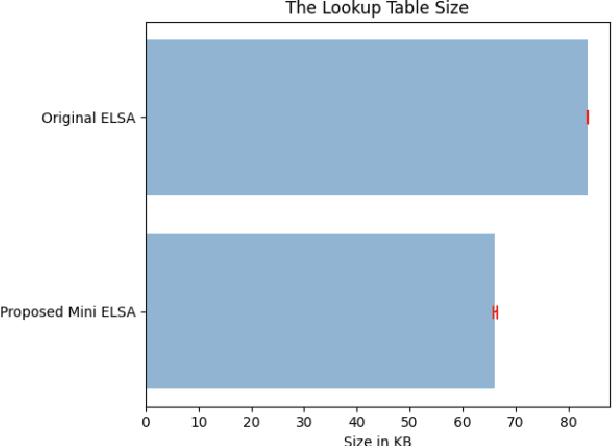
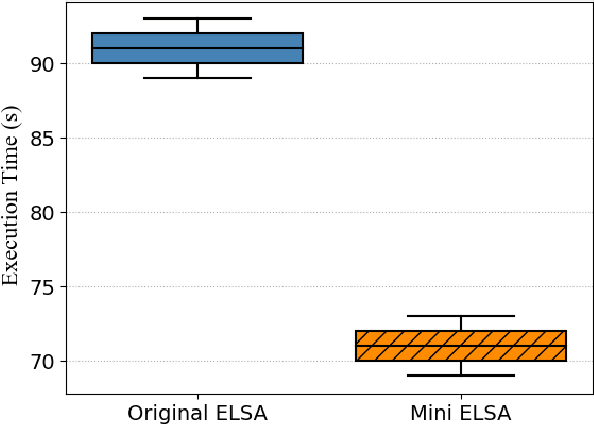
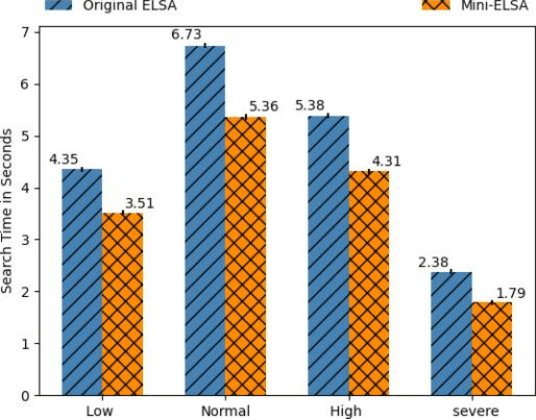
In previous work a novel Edge Lightweight Searchable Attribute-based encryption (ELSA) method was proposed to support Industry 4.0 and specifically Industrial Internet of Things applications. In this paper, we aim to improve ELSA by minimising the lookup table size and summarising the data records by integrating Machine Learning (ML) methods suitable for execution at the edge. This integration will eliminate records of unnecessary data by evaluating added value to further processing. Thus, resulting in the minimization of both the lookup table size, the cloud storage and the network traffic taking full advantage of the edge architecture benefits. We demonstrate our mini-ELSA expanded method on a well-known power plant dataset. Our results demonstrate a reduction of storage requirements by 21% while improving execution time by 1.27x.
Channel Modeling for UAV-to-Ground Communications with Posture Variation and Fuselage Scattering Effect
Oct 05, 2022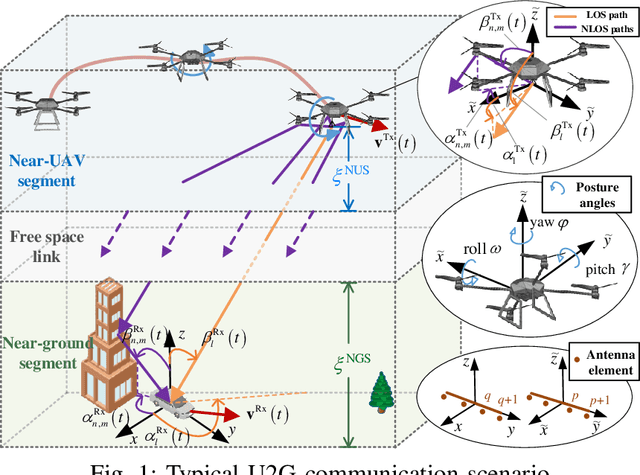
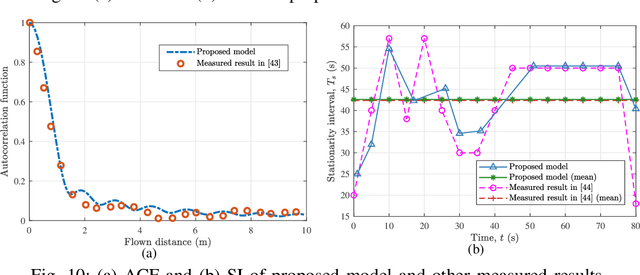
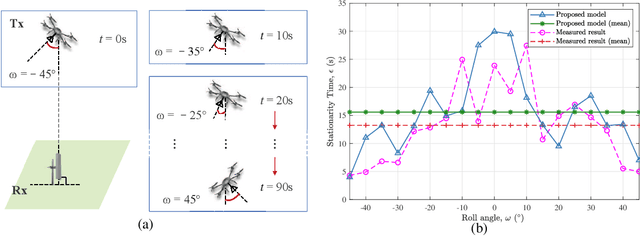
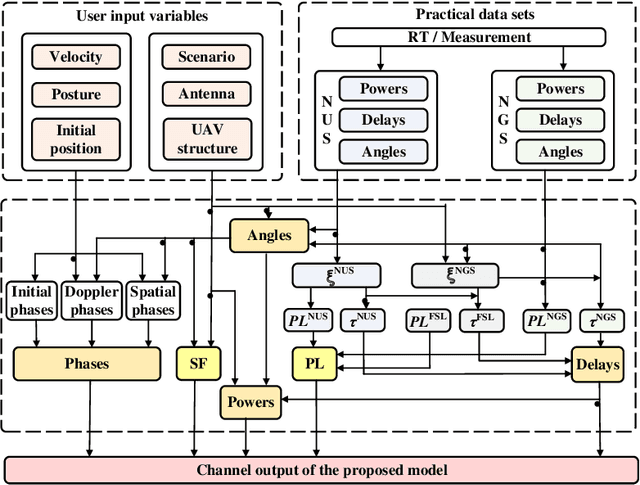
Unmanned aerial vehicle (UAV)-to-ground (U2G) channel models play a pivotal role for reliable communications between UAV and ground terminal. This paper proposes a three-dimensional (3D) non-stationary hybrid model including both large-scale and small-scale fading for U2G multiple-input-multiple-output (MIMO) channels. Distinctive channel characteristics under U2G scenarios, i.e., 3D trajectory and posture of UAV, fuselage scattering effect (FSE), and posture variation fading (PVF), are incorporated into the proposed model. The channel parameters, i.e., path loss (PL), shadow fading (SF), path delay, and path angle, are generated incorporating machine learning (ML) and ray tracing (RT) techniques to capture the structure-related characteristics. In order to guarantee the physical continuity of channel parameters such as Doppler phase and path power, the time evolution methods of inter- and intra- stationary intervals are proposed. Key statistical properties , i.e., temporal autocorrection function (ACF), power delay profile (PDP), level crossing rate (LCR), average fading duration (AFD), and stationary interval (SI) are given, and the impact of the change of fuselage and posture variation is analyzed. It is demonstrated that both posture variation and fuselage scattering have crucial effects on channel characteristics. The validity and practicability of the proposed model are verified by comparing the simulation results with the measured ones.
Hydra: A Real-time Spatial Perception Engine for 3D Scene Graph Construction and Optimization
Jan 31, 2022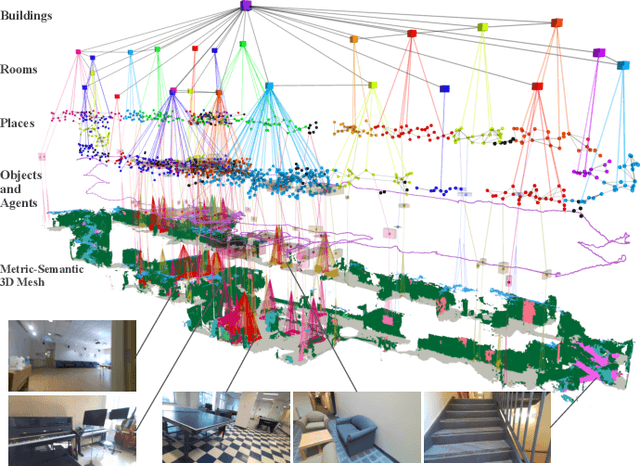
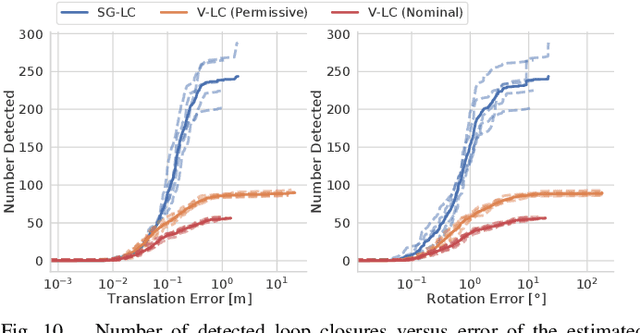
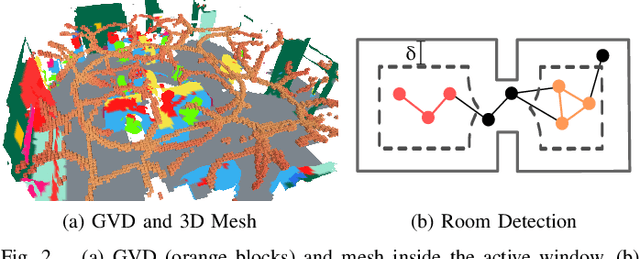
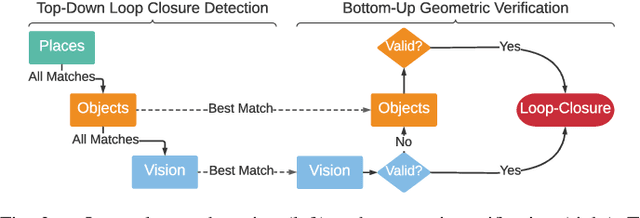
3D scene graphs have recently emerged as a powerful high-level representation of 3D environments. A 3D scene graph describes the environment as a layered graph where nodes represent spatial concepts at multiple levels of abstraction and edges represent relations between concepts. While 3D scene graphs can serve as an advanced "mental model" for robots, how to build such a rich representation in real-time is still uncharted territory. This paper describes the first real-time Spatial Perception engINe (SPIN), a suite of algorithms to build a 3D scene graph from sensor data in real-time. Our first contribution is to develop real-time algorithms to incrementally construct the layers of a scene graph as the robot explores the environment; these algorithms build a local Euclidean Signed Distance Function (ESDF) around the current robot location, extract a topological map of places from the ESDF, and then segment the places into rooms using an approach inspired by community-detection techniques. Our second contribution is to investigate loop closure detection and optimization in 3D scene graphs. We show that 3D scene graphs allow defining hierarchical descriptors for loop closure detection; our descriptors capture statistics across layers in the scene graph, ranging from low-level visual appearance, to summary statistics about objects and places. We then propose the first algorithm to optimize a 3D scene graph in response to loop closures; our approach relies on embedded deformation graphs to simultaneously correct all layers of the scene graph. We implement the proposed SPIN into a highly parallelized architecture, named Hydra, that combines fast early and mid-level perception processes with slower high-level perception. We evaluate Hydra on simulated and real data and show it is able to reconstruct 3D scene graphs with an accuracy comparable with batch offline methods, while running online.
Deep Translation Prior: Test-time Training for Photorealistic Style Transfer
Dec 12, 2021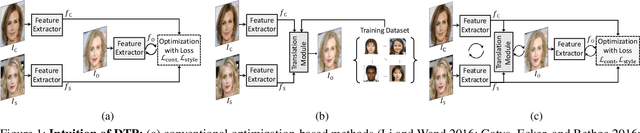
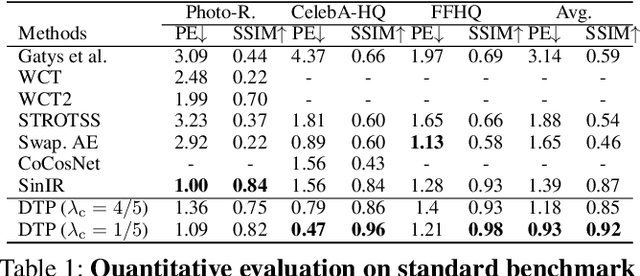
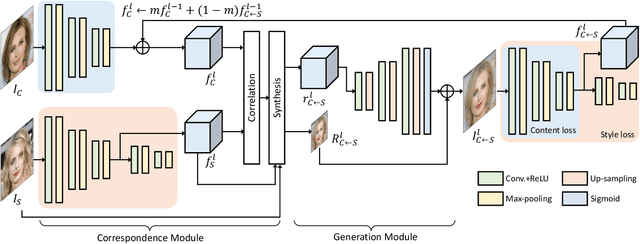
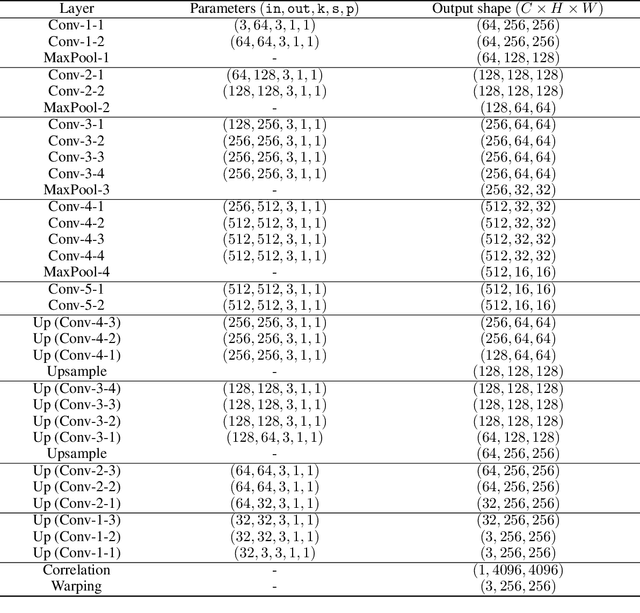
Recent techniques to solve photorealistic style transfer within deep convolutional neural networks (CNNs) generally require intensive training from large-scale datasets, thus having limited applicability and poor generalization ability to unseen images or styles. To overcome this, we propose a novel framework, dubbed Deep Translation Prior (DTP), to accomplish photorealistic style transfer through test-time training on given input image pair with untrained networks, which learns an image pair-specific translation prior and thus yields better performance and generalization. Tailored for such test-time training for style transfer, we present novel network architectures, with two sub-modules of correspondence and generation modules, and loss functions consisting of contrastive content, style, and cycle consistency losses. Our framework does not require offline training phase for style transfer, which has been one of the main challenges in existing methods, but the networks are to be solely learned during test-time. Experimental results prove that our framework has a better generalization ability to unseen image pairs and even outperforms the state-of-the-art methods.
Graph2Vid: Flow graph to Video Grounding forWeakly-supervised Multi-Step Localization
Oct 10, 2022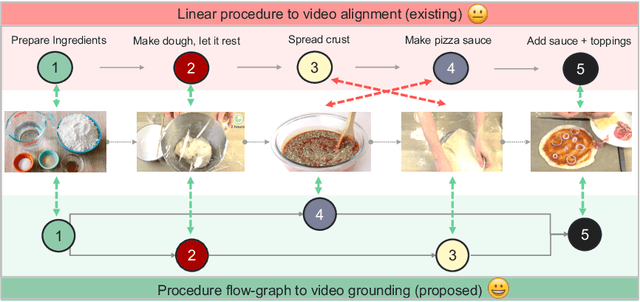
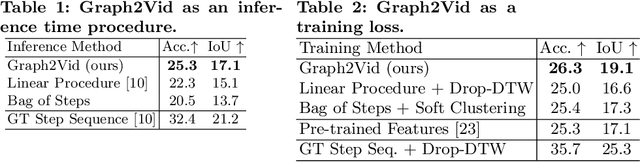

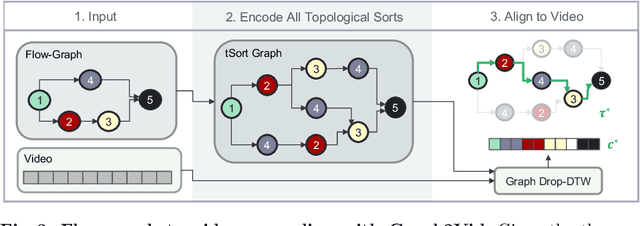
In this work, we consider the problem of weakly-supervised multi-step localization in instructional videos. An established approach to this problem is to rely on a given list of steps. However, in reality, there is often more than one way to execute a procedure successfully, by following the set of steps in slightly varying orders. Thus, for successful localization in a given video, recent works require the actual order of procedure steps in the video, to be provided by human annotators at both training and test times. Instead, here, we only rely on generic procedural text that is not tied to a specific video. We represent the various ways to complete the procedure by transforming the list of instructions into a procedure flow graph which captures the partial order of steps. Using the flow graphs reduces both training and test time annotation requirements. To this end, we introduce the new problem of flow graph to video grounding. In this setup, we seek the optimal step ordering consistent with the procedure flow graph and a given video. To solve this problem, we propose a new algorithm - Graph2Vid - that infers the actual ordering of steps in the video and simultaneously localizes them. To show the advantage of our proposed formulation, we extend the CrossTask dataset with procedure flow graph information. Our experiments show that Graph2Vid is both more efficient than the baselines and yields strong step localization results, without the need for step order annotation.
* ECCV'22, oral
On Text Style Transfer via Style Masked Language Models
Oct 12, 2022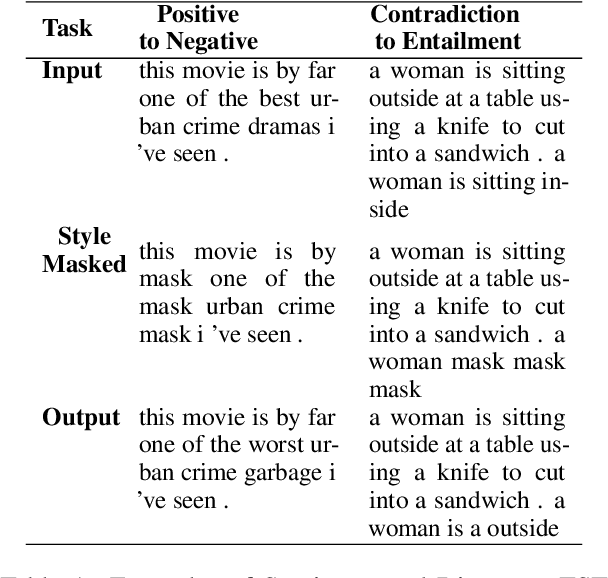
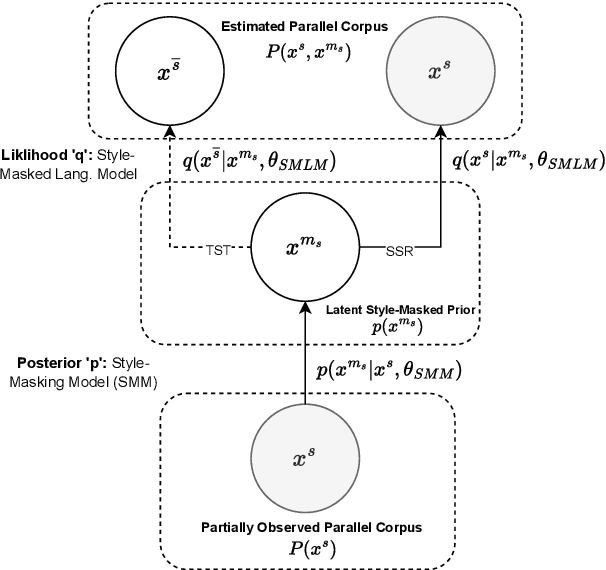
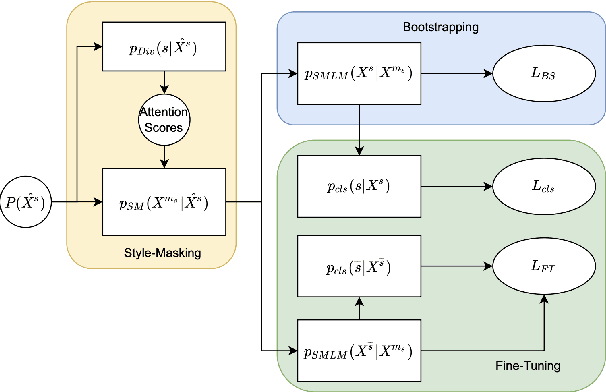
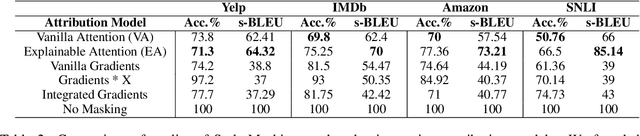
Text Style Transfer (TST) is performable through approaches such as latent space disentanglement, cycle-consistency losses, prototype editing etc. The prototype editing approach, which is known to be quite successful in TST, involves two key phases a) Masking of source style-associated tokens and b) Reconstruction of this source-style masked sentence conditioned with the target style. We follow a similar transduction method, in which we transpose the more difficult direct source to target TST task to a simpler Style-Masked Language Model (SMLM) Task, wherein, similar to BERT \cite{bert}, the goal of our model is now to reconstruct the source sentence from its style-masked version. We arrive at the SMLM mechanism naturally by formulating prototype editing/ transduction methods in a probabilistic framework, where TST resolves into estimating a hypothetical parallel dataset from a partially observed parallel dataset, wherein each domain is assumed to have a common latent style-masked prior. To generate this style-masked prior, we use "Explainable Attention" as our choice of attribution for a more precise style-masking step and also introduce a cost-effective and accurate "Attribution-Surplus" method of determining the position of masks from any arbitrary attribution model in O(1) time. We empirically show that this non-generational approach well suites the "content preserving" criteria for a task like TST, even for a complex style like Discourse Manipulation. Our model, the Style MLM, outperforms strong TST baselines and is on par with state-of-the-art TST models, which use complex architectures and orders of more parameters.
SSDNet: State Space Decomposition Neural Network for Time Series Forecasting
Dec 19, 2021
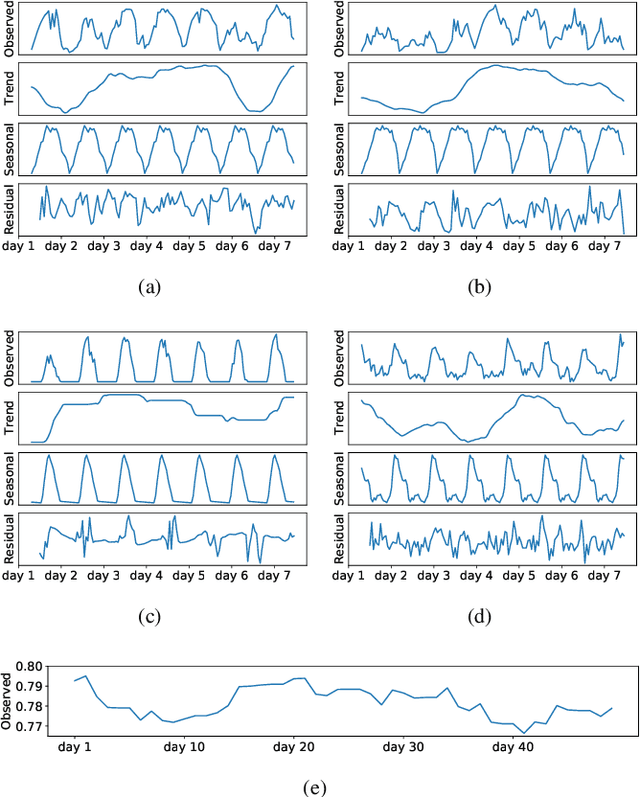
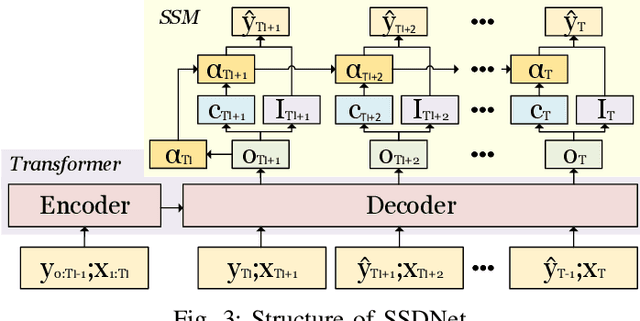
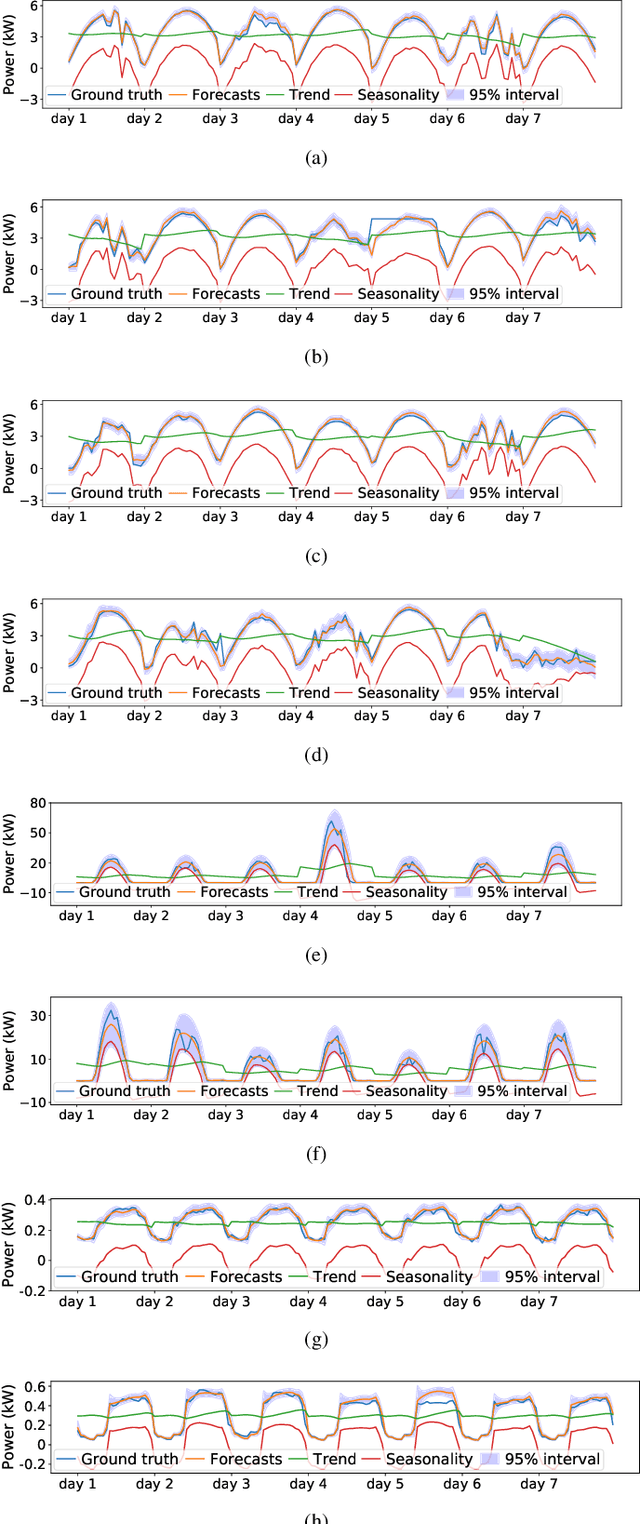
In this paper, we present SSDNet, a novel deep learning approach for time series forecasting. SSDNet combines the Transformer architecture with state space models to provide probabilistic and interpretable forecasts, including trend and seasonality components and previous time steps important for the prediction. The Transformer architecture is used to learn the temporal patterns and estimate the parameters of the state space model directly and efficiently, without the need for Kalman filters. We comprehensively evaluate the performance of SSDNet on five data sets, showing that SSDNet is an effective method in terms of accuracy and speed, outperforming state-of-the-art deep learning and statistical methods, and able to provide meaningful trend and seasonality components.
CaiRL: A High-Performance Reinforcement Learning Environment Toolkit
Oct 03, 2022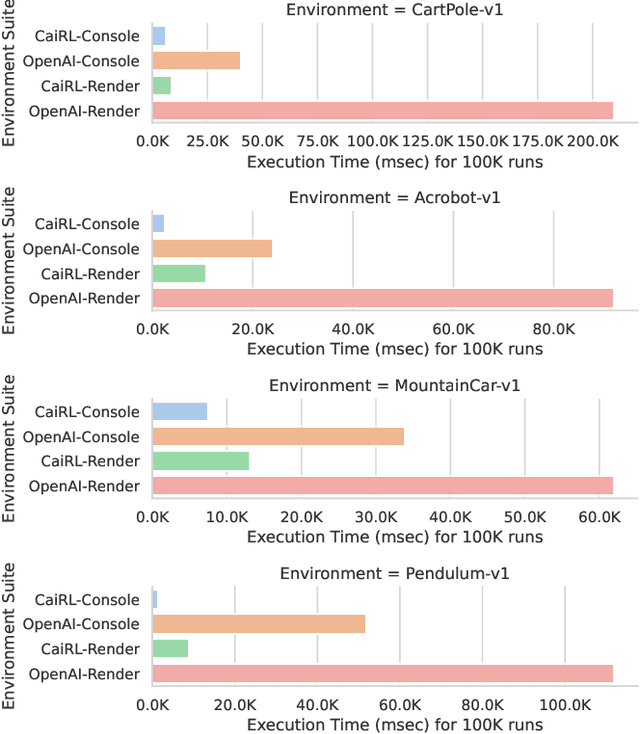
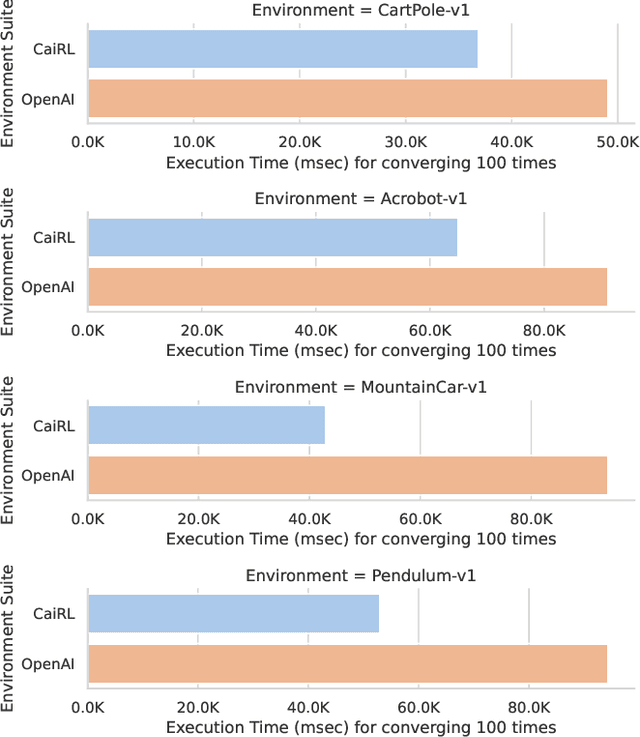
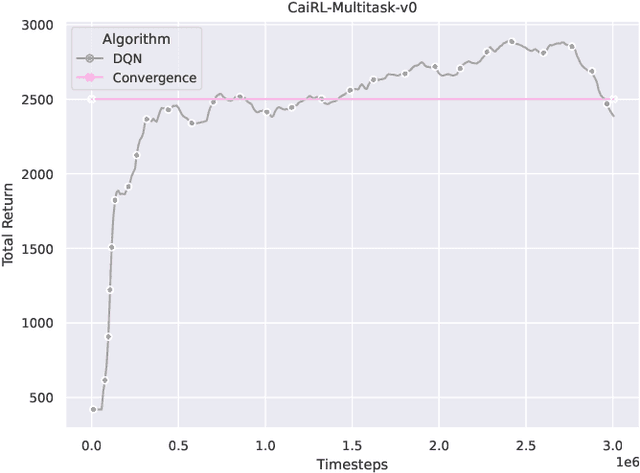
This paper addresses the dire need for a platform that efficiently provides a framework for running reinforcement learning (RL) experiments. We propose the CaiRL Environment Toolkit as an efficient, compatible, and more sustainable alternative for training learning agents and propose methods to develop more efficient environment simulations. There is an increasing focus on developing sustainable artificial intelligence. However, little effort has been made to improve the efficiency of running environment simulations. The most popular development toolkit for reinforcement learning, OpenAI Gym, is built using Python, a powerful but slow programming language. We propose a toolkit written in C++ with the same flexibility level but works orders of magnitude faster to make up for Python's inefficiency. This would drastically cut climate emissions. CaiRL also presents the first reinforcement learning toolkit with a built-in JVM and Flash support for running legacy flash games for reinforcement learning research. We demonstrate the effectiveness of CaiRL in the classic control benchmark, comparing the execution speed to OpenAI Gym. Furthermore, we illustrate that CaiRL can act as a drop-in replacement for OpenAI Gym to leverage significantly faster training speeds because of the reduced environment computation time.
* Published in 2022 IEEE Conference on Games (CoG)
Acoustic Localization and Communication Using a MEMS Microphone for Low-cost and Low-power Bio-inspired Underwater Robots
Oct 03, 2022
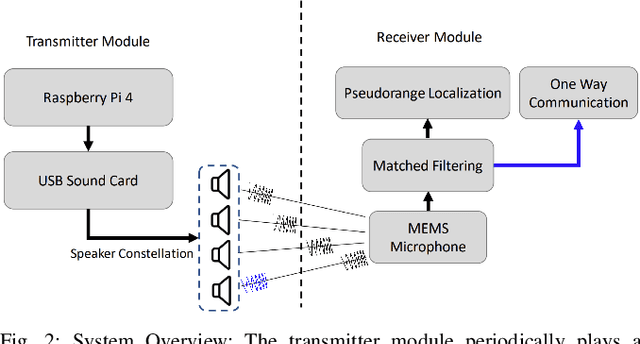

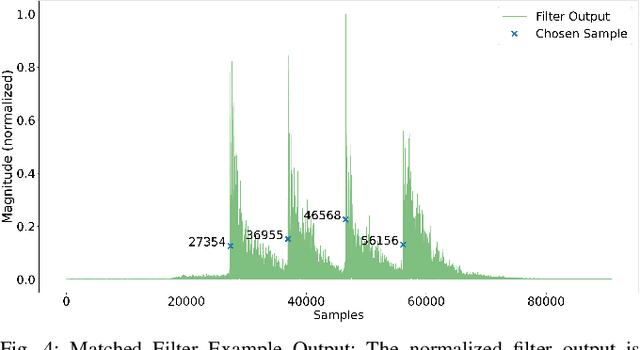
Having accurate localization capabilities is one of the fundamental requirements of autonomous robots. For underwater vehicles, the choices for effective localization are limited due to limitations of GPS use in water and poor environmental visibility that makes camera-based methods ineffective. Popular inertial navigation methods for underwater localization using Doppler-velocity log sensors, sonar, high-end inertial navigation systems, or acoustic positioning systems require bulky expensive hardware which are incompatible with low cost, bio-inspired underwater robots. In this paper, we introduce an approach for underwater robot localization inspired by GPS methods known as acoustic pseudoranging. Our method allows us to potentially localize multiple bio-inspired robots equipped with commonly available micro electro-mechanical systems microphones. This is achieved through estimating the time difference of arrival of acoustic signals sent simultaneously through four speakers with a known constellation geometry. We also leverage the same acoustic framework to perform oneway communication with the robot to execute some primitive motions. To our knowledge, this is the first application of the approach for the on-board localization of small bio-inspired robots in water. Hardware schematics and the accompanying code are released to aid further development in the field3.