 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Self and Mixed Supervision to Improve Training Labels for Multi-Class Medical Image Segmentation
Mar 06, 2024
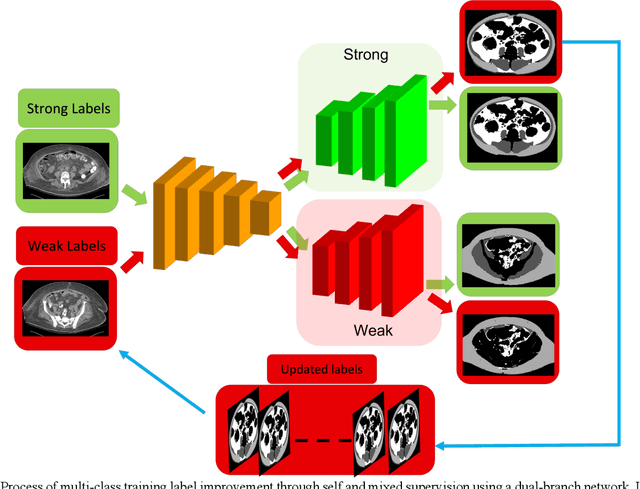
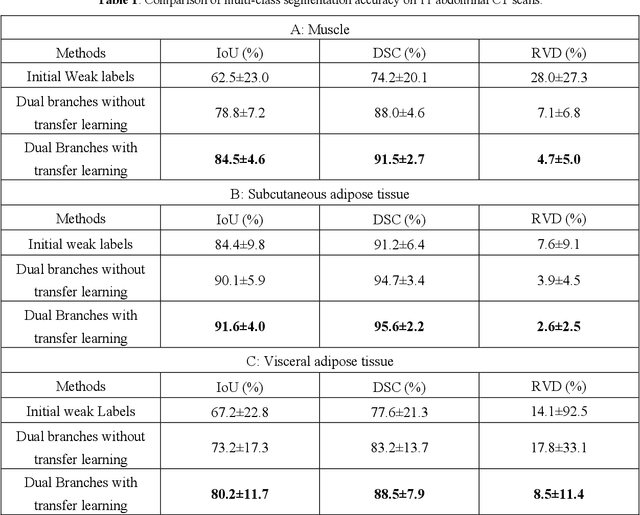
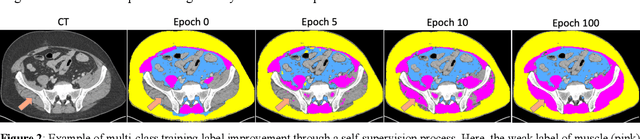
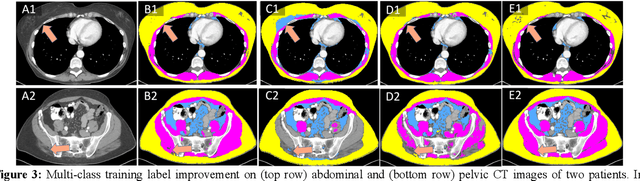
Accurate training labels are a key component for multi-class medical image segmentation. Their annotation is costly and time-consuming because it requires domain expertise. This work aims to develop a dual-branch network and automatically improve training labels for multi-class image segmentation. Transfer learning is used to train the network and improve inaccurate weak labels sequentially. The dual-branch network is first trained by weak labels alone to initialize model parameters. After the network is stabilized, the shared encoder is frozen, and strong and weak decoders are fine-tuned by strong and weak labels together. The accuracy of weak labels is iteratively improved in the fine-tuning process. The proposed method was applied to a three-class segmentation of muscle, subcutaneous and visceral adipose tissue on abdominal CT scans. Validation results on 11 patients showed that the accuracy of training labels was statistically significantly improved, with the Dice similarity coefficient of muscle, subcutaneous and visceral adipose tissue increased from 74.2% to 91.5%, 91.2% to 95.6%, and 77.6% to 88.5%, respectively (p<0.05). In comparison with our earlier method, the label accuracy was also significantly improved (p<0.05). These experimental results suggested that the combination of the dual-branch network and transfer learning is an efficient means to improve training labels for multi-class segmentation.
Inverse-Free Fast Natural Gradient Descent Method for Deep Learning
Mar 06, 2024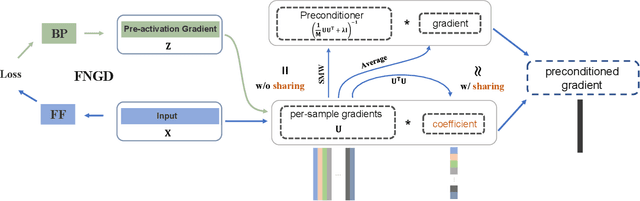
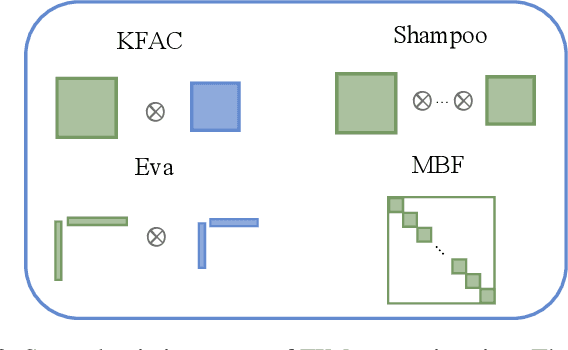
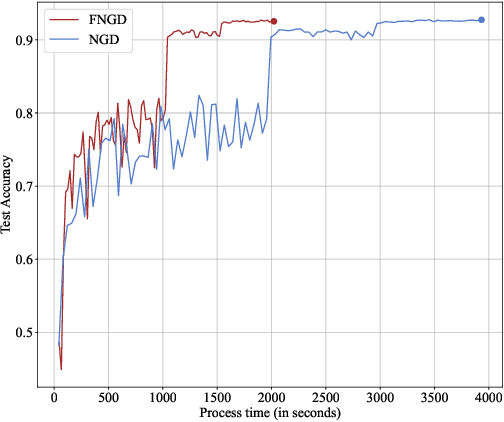
Second-order methods can converge much faster than first-order methods by incorporating second-order derivates or statistics, but they are far less prevalent in deep learning due to their computational inefficiency. To handle this, many of the existing solutions focus on reducing the size of the matrix to be inverted. However, it is still needed to perform the inverse operator in each iteration. In this paper, we present a fast natural gradient descent (FNGD) method, which only requires computing the inverse during the first epoch. Firstly, we reformulate the gradient preconditioning formula in the natural gradient descent (NGD) as a weighted sum of per-sample gradients using the Sherman-Morrison-Woodbury formula. Building upon this, to avoid the iterative inverse operation involved in computing coefficients, the weighted coefficients are shared across epochs without affecting the empirical performance. FNGD approximates the NGD as a fixed-coefficient weighted sum, akin to the average sum in first-order methods. Consequently, the computational complexity of FNGD can approach that of first-order methods. To demonstrate the efficiency of the proposed FNGD, we perform empirical evaluations on image classification and machine translation tasks. For training ResNet-18 on the CIFAR-100 dataset, FNGD can achieve a speedup of 2.05$\times$ compared with KFAC. For training Transformer on Multi30K, FNGD outperforms AdamW by 24 BLEU score while requiring almost the same training time.
GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Mar 06, 2024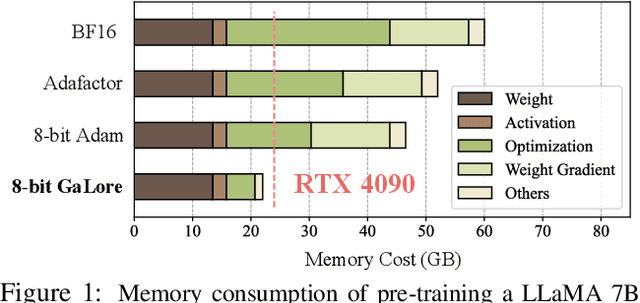
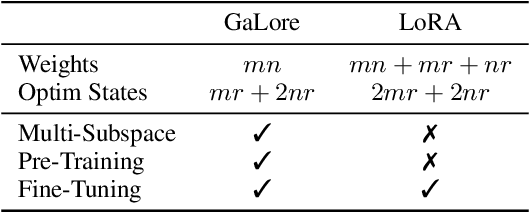
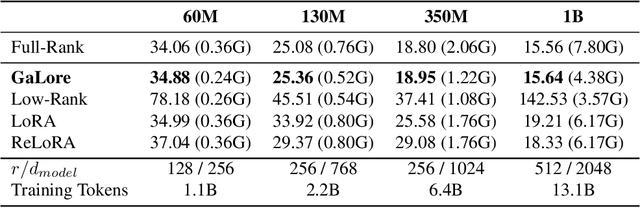
Training Large Language Models (LLMs) presents significant memory challenges, predominantly due to the growing size of weights and optimizer states. Common memory-reduction approaches, such as low-rank adaptation (LoRA), add a trainable low-rank matrix to the frozen pre-trained weight in each layer, reducing trainable parameters and optimizer states. However, such approaches typically underperform training with full-rank weights in both pre-training and fine-tuning stages since they limit the parameter search to a low-rank subspace and alter the training dynamics, and further, may require full-rank warm start. In this work, we propose Gradient Low-Rank Projection (GaLore), a training strategy that allows full-parameter learning but is more memory-efficient than common low-rank adaptation methods such as LoRA. Our approach reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for pre-training on LLaMA 1B and 7B architectures with C4 dataset with up to 19.7B tokens, and on fine-tuning RoBERTa on GLUE tasks. Our 8-bit GaLore further reduces optimizer memory by up to 82.5% and total training memory by 63.3%, compared to a BF16 baseline. Notably, we demonstrate, for the first time, the feasibility of pre-training a 7B model on consumer GPUs with 24GB memory (e.g., NVIDIA RTX 4090) without model parallel, checkpointing, or offloading strategies.
A Deep-Learning Technique to Locate Cryptographic Operations in Side-Channel Traces
Feb 29, 2024Side-channel attacks allow extracting secret information from the execution of cryptographic primitives by correlating the partially known computed data and the measured side-channel signal. However, to set up a successful side-channel attack, the attacker has to perform i) the challenging task of locating the time instant in which the target cryptographic primitive is executed inside a side-channel trace and then ii)the time-alignment of the measured data on that time instant. This paper presents a novel deep-learning technique to locate the time instant in which the target computed cryptographic operations are executed in the side-channel trace. In contrast to state-of-the-art solutions, the proposed methodology works even in the presence of trace deformations obtained through random delay insertion techniques. We validated our proposal through a successful attack against a variety of unprotected and protected cryptographic primitives that have been executed on an FPGA-implemented system-on-chip featuring a RISC-V CPU.
Benchmarking multi-component signal processing methods in the time-frequency plane
Feb 13, 2024Signal processing in the time-frequency plane has a long history and remains a field of methodological innovation. For instance, detection and denoising based on the zeros of the spectrogram have been proposed since 2015, contrasting with a long history of focusing on larger values of the spectrogram. Yet, unlike neighboring fields like optimization and machine learning, time-frequency signal processing lacks widely-adopted benchmarking tools. In this work, we contribute an open-source, Python-based toolbox termed MCSM-Benchs for benchmarking multi-component signal analysis methods, and we demonstrate our toolbox on three time-frequency benchmarks. First, we compare different methods for signal detection based on the zeros of the spectrogram, including unexplored variations of previously proposed detection tests. Second, we compare zero-based denoising methods to both classical and novel methods based on large values and ridges of the spectrogram. Finally, we compare the denoising performance of these methods against typical spectrogram thresholding strategies, in terms of post-processing artifacts commonly referred to as musical noise. At a low level, the obtained results provide new insight on the assessed approaches, and in particular research directions to further develop zero-based methods. At a higher level, our benchmarks exemplify the benefits of using a public, collaborative, common framework for benchmarking.
When do Convolutional Neural Networks Stop Learning?
Mar 04, 2024
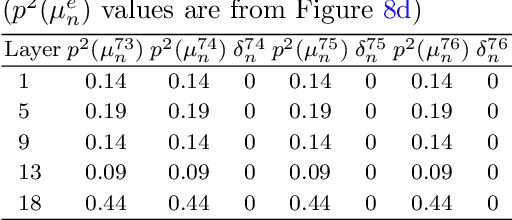
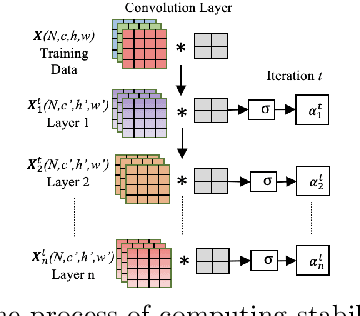
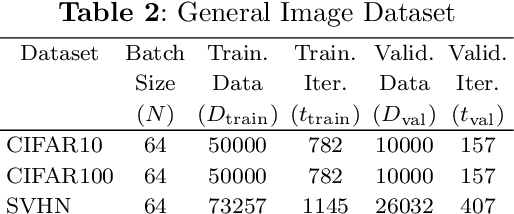
Convolutional Neural Networks (CNNs) have demonstrated outstanding performance in computer vision tasks such as image classification, detection, segmentation, and medical image analysis. In general, an arbitrary number of epochs is used to train such neural networks. In a single epoch, the entire training data -- divided by batch size -- are fed to the network. In practice, validation error with training loss is used to estimate the neural network's generalization, which indicates the optimal learning capacity of the network. Current practice is to stop training when the training loss decreases and the gap between training and validation error increases (i.e., the generalization gap) to avoid overfitting. However, this is a trial-and-error-based approach which raises a critical question: Is it possible to estimate when neural networks stop learning based on training data? This research work introduces a hypothesis that analyzes the data variation across all the layers of a CNN variant to anticipate its near-optimal learning capacity. In the training phase, we use our hypothesis to anticipate the near-optimal learning capacity of a CNN variant without using any validation data. Our hypothesis can be deployed as a plug-and-play to any existing CNN variant without introducing additional trainable parameters to the network. We test our hypothesis on six different CNN variants and three different general image datasets (CIFAR10, CIFAR100, and SVHN). The result based on these CNN variants and datasets shows that our hypothesis saves 58.49\% of computational time (on average) in training. We further conduct our hypothesis on ten medical image datasets and compared with the MedMNIST-V2 benchmark. Based on our experimental result, we save $\approx$ 44.1\% of computational time without losing accuracy against the MedMNIST-V2 benchmark.
System-level Impact of Non-Ideal Program-Time of Charge Trap Flash (CTF) on Deep Neural Network
Feb 15, 2024Learning of deep neural networks (DNN) using Resistive Processing Unit (RPU) architecture is energy-efficient as it utilizes dedicated neuromorphic hardware and stochastic computation of weight updates for in-memory computing. Charge Trap Flash (CTF) devices can implement RPU-based weight updates in DNNs. However, prior work has shown that the weight updates (V_T) in CTF-based RPU are impacted by the non-ideal program time of CTF. The non-ideal program time is affected by two factors of CTF. Firstly, the effects of the number of input pulses (N) or pulse width (pw), and secondly, the gap between successive update pulses (t_gap) used for the stochastic computation of weight updates. Therefore, the impact of this non-ideal program time must be studied for neural network training simulations. In this study, Firstly, we propose a pulse-train design compensation technique to reduce the total error caused by non-ideal program time of CTF and stochastic variance of a network. Secondly, we simulate RPU-based DNN with non-ideal program time of CTF on MNIST and Fashion-MNIST datasets. We find that for larger N (~1000), learning performance approaches the ideal (software-level) training level and, therefore, is not much impacted by the choice of t_gap used to implement RPU-based weight updates. However, for lower N (<500), learning performance depends on T_gap of the pulses. Finally, we also performed an ablation study to isolate the causal factor of the improved learning performance. We conclude that the lower noise level in the weight updates is the most likely significant factor to improve the learning performance of DNN. Thus, our study attempts to compensate for the error caused by non-ideal program time and standardize the pulse length (N) and pulse gap (t_gap) specifications for CTF-based RPUs for accurate system-level on-chip training.
Hybrid Quantum Neural Network Advantage for Radar-Based Drone Detection and Classification in Low Signal-to-Noise Ratio
Mar 04, 2024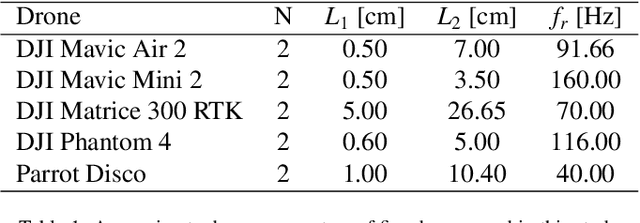
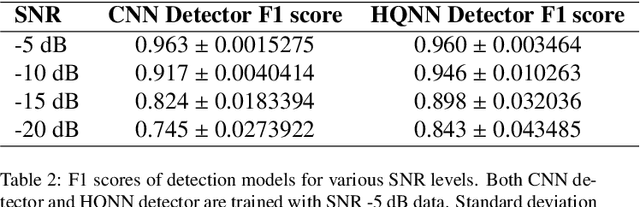
In this paper, we investigate the performance of a Hybrid Quantum Neural Network (HQNN) and a comparable classical Convolution Neural Network (CNN) for detection and classification problem using a radar. Specifically, we take a fairly complex radar time-series model derived from electromagnetic theory, namely the Martin-Mulgrew model, that is used to simulate radar returns of objects with rotating blades, such as drones. We find that when that signal-to-noise ratio (SNR) is high, CNN outperforms the HQNN for detection and classification. However, in the low SNR regime (which is of greatest interest in practice) the performance of HQNN is found to be superior to that of the CNN of a similar architecture.
RIFF: Learning to Rephrase Inputs for Few-shot Fine-tuning of Language Models
Mar 04, 2024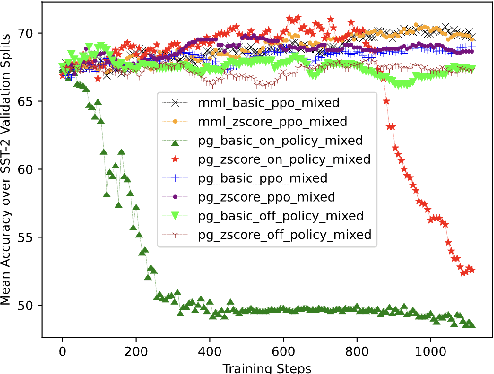
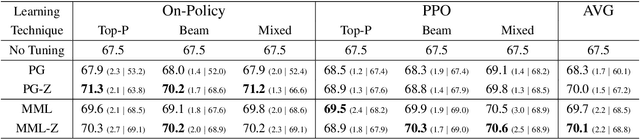

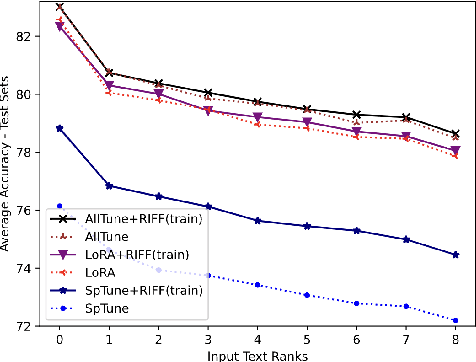
Pre-trained Language Models (PLMs) can be accurately fine-tuned for downstream text processing tasks. Recently, researchers have introduced several parameter-efficient fine-tuning methods that optimize input prompts or adjust a small number of model parameters (e.g LoRA). In this study, we explore the impact of altering the input text of the original task in conjunction with parameter-efficient fine-tuning methods. To most effectively rewrite the input text, we train a few-shot paraphrase model with a Maximum-Marginal Likelihood objective. Using six few-shot text classification datasets, we show that enriching data with paraphrases at train and test time enhances the performance beyond what can be achieved with parameter-efficient fine-tuning alone.
Predicting large scale cosmological structure evolution with GAN-based autoencoders
Mar 04, 2024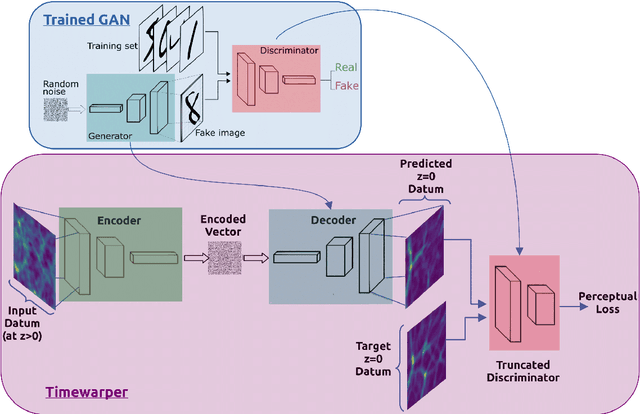
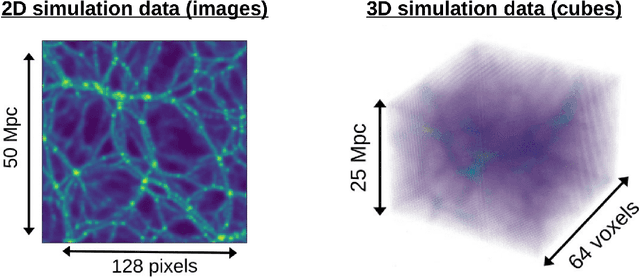
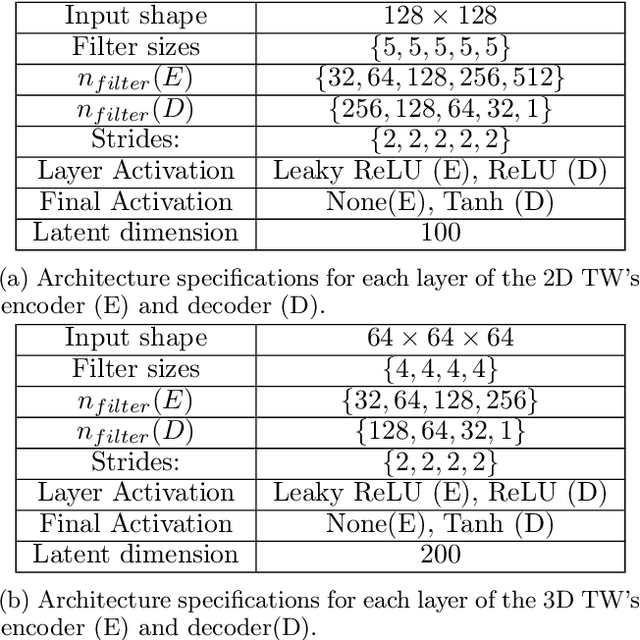
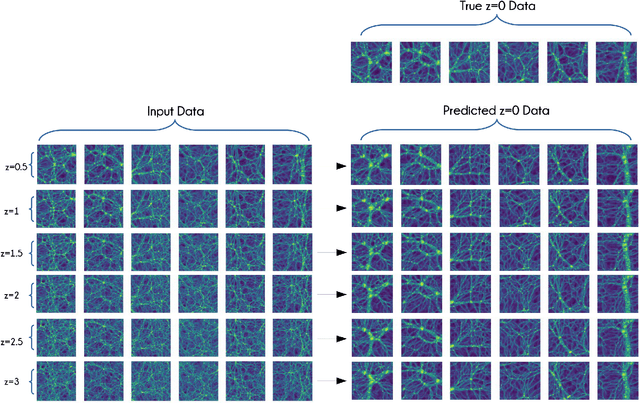
Cosmological simulations play a key role in the prediction and understanding of large scale structure formation from initial conditions. We make use of GAN-based Autoencoders (AEs) in an attempt to predict structure evolution within simulations. The AEs are trained on images and cubes issued from respectively 2D and 3D N-body simulations describing the evolution of the dark matter (DM) field. We find that while the AEs can predict structure evolution for 2D simulations of DM fields well, using only the density fields as input, they perform significantly more poorly in similar conditions for 3D simulations. However, additionally providing velocity fields as inputs greatly improves results, with similar predictions regardless of time-difference between input and target.