 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FloatingFusion: Depth from ToF and Image-stabilized Stereo Cameras
Oct 06, 2022
High-accuracy per-pixel depth is vital for computational photography, so smartphones now have multimodal camera systems with time-of-flight (ToF) depth sensors and multiple color cameras. However, producing accurate high-resolution depth is still challenging due to the low resolution and limited active illumination power of ToF sensors. Fusing RGB stereo and ToF information is a promising direction to overcome these issues, but a key problem remains: to provide high-quality 2D RGB images, the main color sensor's lens is optically stabilized, resulting in an unknown pose for the floating lens that breaks the geometric relationships between the multimodal image sensors. Leveraging ToF depth estimates and a wide-angle RGB camera, we design an automatic calibration technique based on dense 2D/3D matching that can estimate camera extrinsic, intrinsic, and distortion parameters of a stabilized main RGB sensor from a single snapshot. This lets us fuse stereo and ToF cues via a correlation volume. For fusion, we apply deep learning via a real-world training dataset with depth supervision estimated by a neural reconstruction method. For evaluation, we acquire a test dataset using a commercial high-power depth camera and show that our approach achieves higher accuracy than existing baselines.
DexGraspNet: A Large-Scale Robotic Dexterous Grasp Dataset for General Objects Based on Simulation
Oct 06, 2022
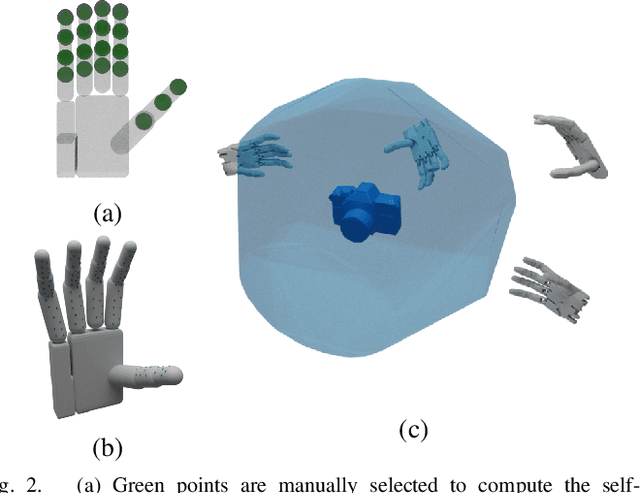
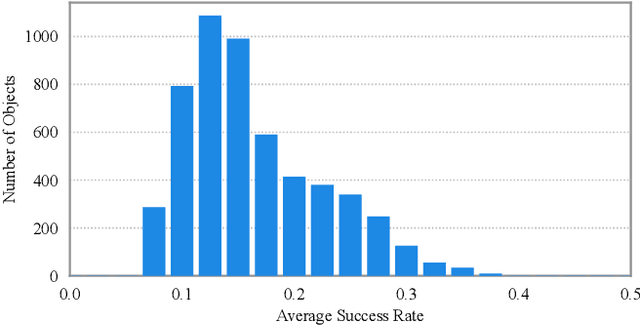

Object grasping using dexterous hands is a crucial yet challenging task for robotic dexterous manipulation. Compared with the field of object grasping with parallel grippers, dexterous grasping is very under-explored, partially owing to the lack of a large-scale dataset. In this work, we present a large-scale simulated dataset, DexGraspNet, for robotic dexterous grasping, along with a highly efficient synthesis method for diverse dexterous grasping synthesis. Leveraging a highly accelerated differentiable force closure estimator, we, for the first time, are able to synthesize stable and diverse grasps efficiently and robustly. We choose ShadowHand, a dexterous gripper commonly seen in robotics, and generated 1.32 million grasps for 5355 objects, covering more than 133 object categories and containing more than 200 diverse grasps for each object instance, with all grasps having been validated by the physics simulator. Compared to the previous dataset generated by GraspIt!, our dataset has not only more objects and grasps, but also higher diversity and quality. Via performing cross-dataset experiments, we show that training several algorithms of dexterous grasp synthesis on our datasets significantly outperforms training on the previous one, demonstrating the large scale and diversity of DexGraspNet. We will release the data and tools upon acceptance.
LGTBIDS: Layer-wise Graph Theory Based Intrusion Detection System in Beyond 5G
Oct 06, 2022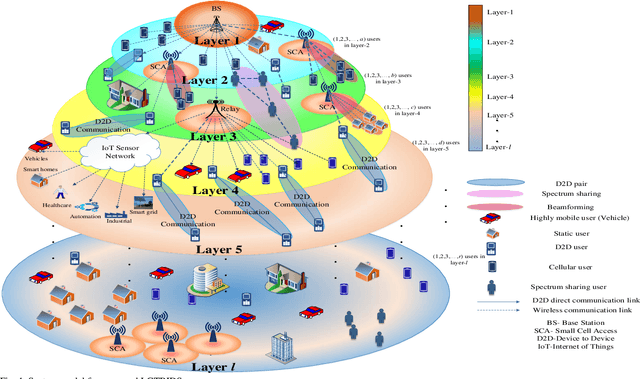
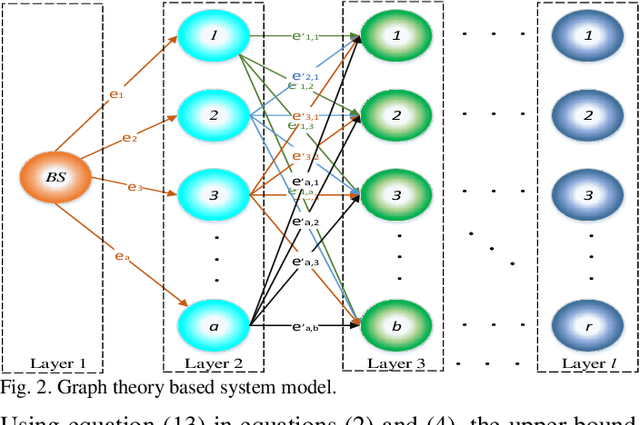
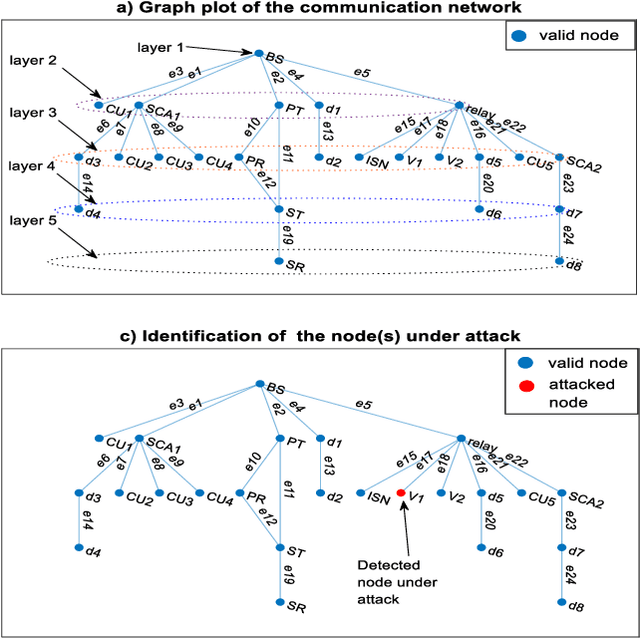
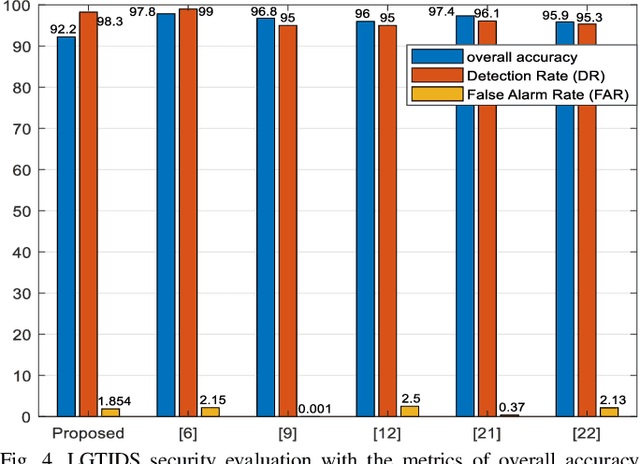
The advancement in wireless communication technologies is becoming more demanding and pervasive. One of the fundamental parameters that limit the efficiency of the network are the security challenges. The communication network is vulnerable to security attacks such as spoofing attacks and signal strength attacks. Intrusion detection signifies a central approach to ensuring the security of the communication network. In this paper, an Intrusion Detection System based on the framework of graph theory is proposed. A Layerwise Graph Theory-Based Intrusion Detection System (LGTBIDS) algorithm is designed to detect the attacked node. The algorithm performs the layer-wise analysis to extract the vulnerable nodes and ultimately the attacked node(s). For each layer, every node is scanned for the possibility of susceptible node(s). The strategy of the IDS is based on the analysis of energy efficiency and secrecy rate. The nodes with the energy efficiency and secrecy rate beyond the range of upper and lower thresholds are detected as the nodes under attack. Further, detected node(s) are transmitted with a random sequence of bits followed by the process of re-authentication. The obtained results validate the better performance, low time computations, and low complexity. Finally, the proposed approach is compared with the conventional solution of intrusion detection.
Classification of hazard event via language fractal
Sep 12, 2022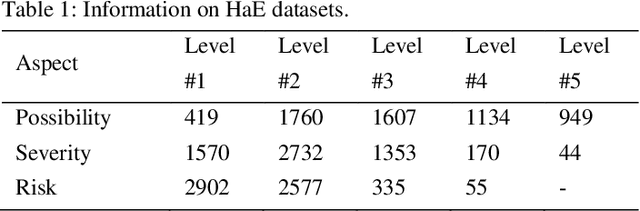
HAZOP is a safety paradigm undertaken to reveal hazards in industry, its report covers valuable hazard events (HaE). The research on HaE classification has much irreplaceable pragmatic values. However, no study has paid such attention to this topic. In this paper, we present a novel deep learning model termed DLF to explore the HaE classification through fractal method from the perspective of language. The motivation is that (1): HaE can be naturally regarded as a kind of time series; (2): the meaning of HaE is driven by word arrangement. Specifically, first we employ BERT to vectorize HaE. Then, we propose a new multifractal method termed HmF-DFA to calculate HaE fractal series by analyzing the HaE vector who is regarded as a time series. Finally, we design a new hierarchical gating neural network (HGNN) to process the HaE fractal series to accomplish the classification of HaE. We take 18 processes for case study. We launch the experiment on the basis of their HAZOP reports. Experimental results demonstrate that our DLF classifier is satisfactory and promising, the proposed HmF-DFA and HGNN are effective, and the introduction of language fractal into HaE is feasible. Our HaE classification system can serve HAZOP and bring application incentives to experts, engineers, employees, and other enterprises, which is conducive to the intelligent development of industrial safety. We hope our research can contribute added support to the daily practice in industrial safety and fractal theory.
TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data
Feb 08, 2022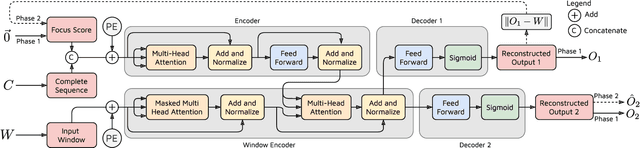
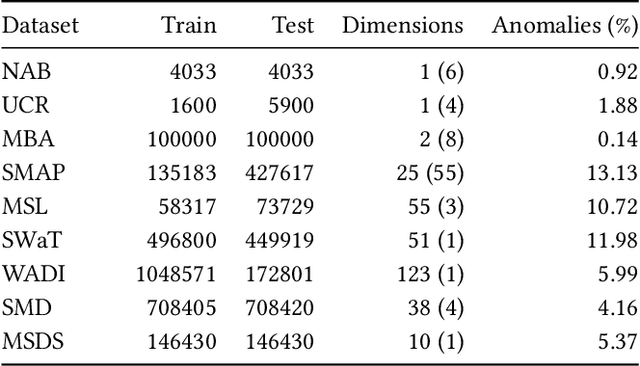
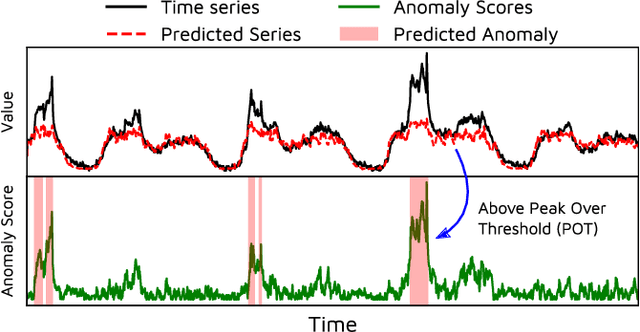
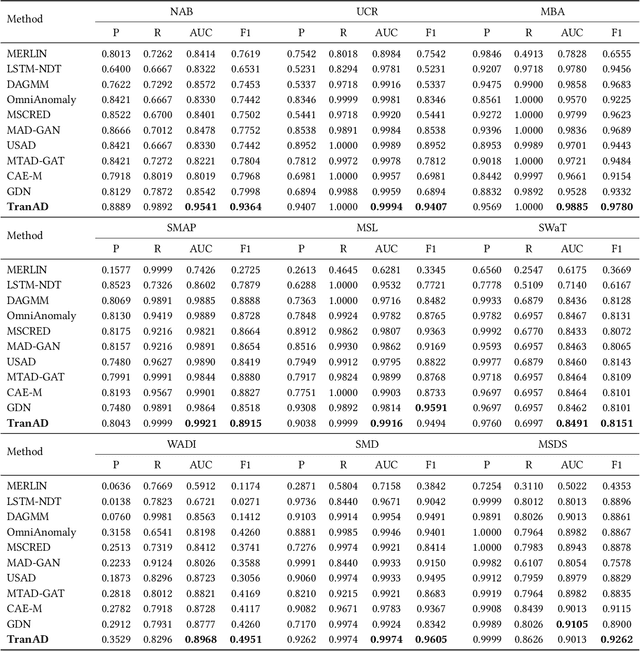
Efficient anomaly detection and diagnosis in multivariate time-series data is of great importance for modern industrial applications. However, building a system that is able to quickly and accurately pinpoint anomalous observations is a challenging problem. This is due to the lack of anomaly labels, high data volatility and the demands of ultra-low inference times in modern applications. Despite the recent developments of deep learning approaches for anomaly detection, only a few of them can address all of these challenges. In this paper, we propose TranAD, a deep transformer network based anomaly detection and diagnosis model which uses attention-based sequence encoders to swiftly perform inference with the knowledge of the broader temporal trends in the data. TranAD uses focus score-based self-conditioning to enable robust multi-modal feature extraction and adversarial training to gain stability. Additionally, model-agnostic meta learning (MAML) allows us to train the model using limited data. Extensive empirical studies on six publicly available datasets demonstrate that TranAD can outperform state-of-the-art baseline methods in detection and diagnosis performance with data and time-efficient training. Specifically, TranAD increases F1 scores by up to 17%, reducing training times by up to 99% compared to the baselines.
Hydra: A Real-time Spatial Perception Engine for 3D Scene Graph Construction and Optimization
Jan 31, 2022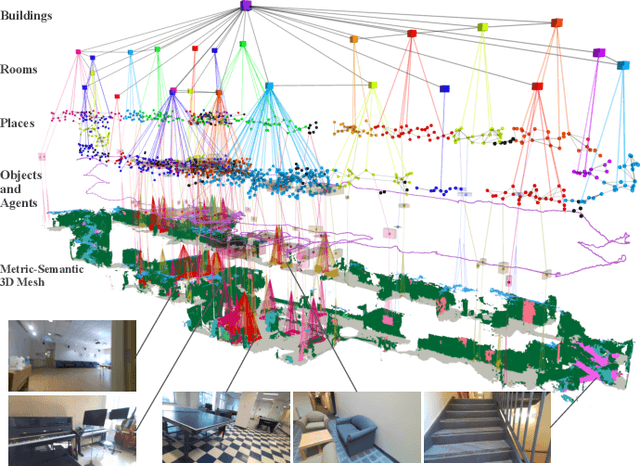
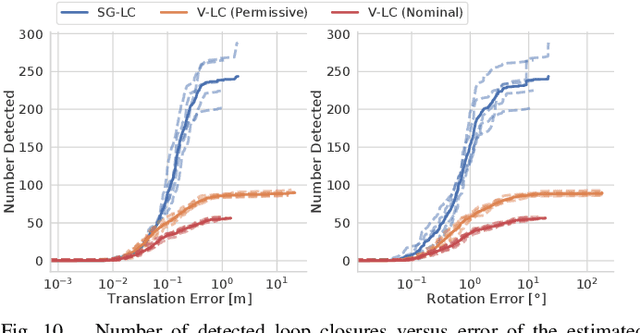
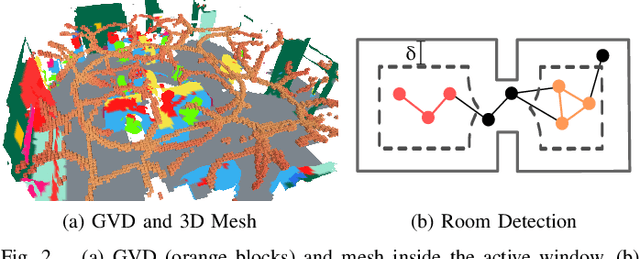
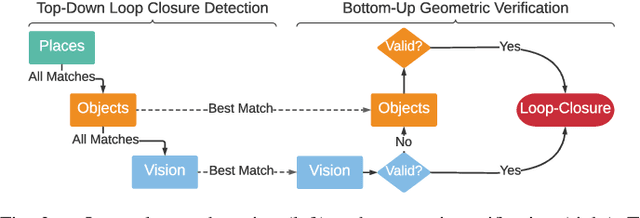
3D scene graphs have recently emerged as a powerful high-level representation of 3D environments. A 3D scene graph describes the environment as a layered graph where nodes represent spatial concepts at multiple levels of abstraction and edges represent relations between concepts. While 3D scene graphs can serve as an advanced "mental model" for robots, how to build such a rich representation in real-time is still uncharted territory. This paper describes the first real-time Spatial Perception engINe (SPIN), a suite of algorithms to build a 3D scene graph from sensor data in real-time. Our first contribution is to develop real-time algorithms to incrementally construct the layers of a scene graph as the robot explores the environment; these algorithms build a local Euclidean Signed Distance Function (ESDF) around the current robot location, extract a topological map of places from the ESDF, and then segment the places into rooms using an approach inspired by community-detection techniques. Our second contribution is to investigate loop closure detection and optimization in 3D scene graphs. We show that 3D scene graphs allow defining hierarchical descriptors for loop closure detection; our descriptors capture statistics across layers in the scene graph, ranging from low-level visual appearance, to summary statistics about objects and places. We then propose the first algorithm to optimize a 3D scene graph in response to loop closures; our approach relies on embedded deformation graphs to simultaneously correct all layers of the scene graph. We implement the proposed SPIN into a highly parallelized architecture, named Hydra, that combines fast early and mid-level perception processes with slower high-level perception. We evaluate Hydra on simulated and real data and show it is able to reconstruct 3D scene graphs with an accuracy comparable with batch offline methods, while running online.
Deep Translation Prior: Test-time Training for Photorealistic Style Transfer
Dec 12, 2021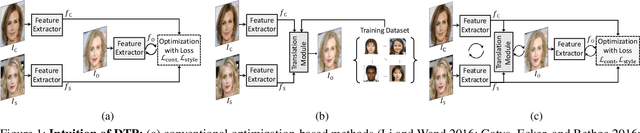
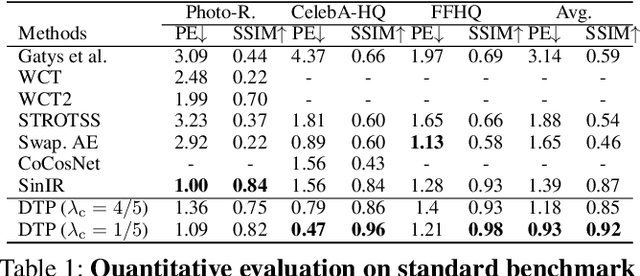
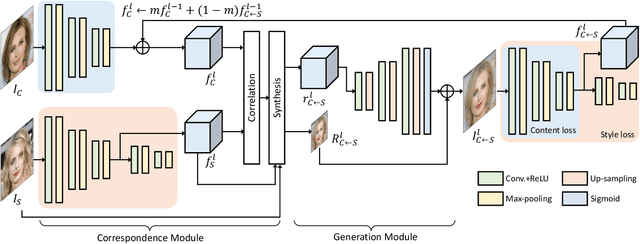
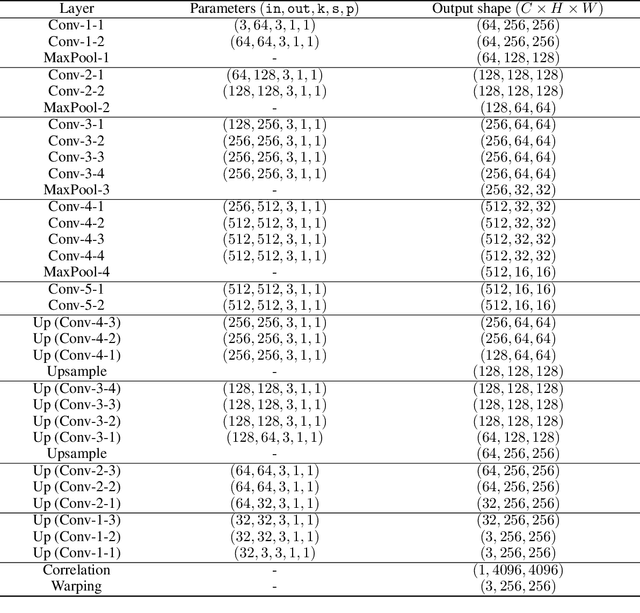
Recent techniques to solve photorealistic style transfer within deep convolutional neural networks (CNNs) generally require intensive training from large-scale datasets, thus having limited applicability and poor generalization ability to unseen images or styles. To overcome this, we propose a novel framework, dubbed Deep Translation Prior (DTP), to accomplish photorealistic style transfer through test-time training on given input image pair with untrained networks, which learns an image pair-specific translation prior and thus yields better performance and generalization. Tailored for such test-time training for style transfer, we present novel network architectures, with two sub-modules of correspondence and generation modules, and loss functions consisting of contrastive content, style, and cycle consistency losses. Our framework does not require offline training phase for style transfer, which has been one of the main challenges in existing methods, but the networks are to be solely learned during test-time. Experimental results prove that our framework has a better generalization ability to unseen image pairs and even outperforms the state-of-the-art methods.
Light curve completion and forecasting using fast and scalable Gaussian processes (MuyGPs)
Aug 31, 2022

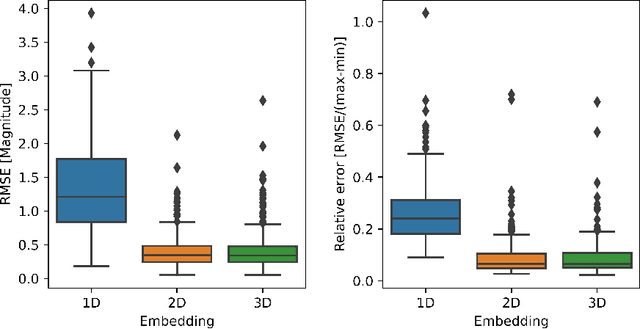
Temporal variations of apparent magnitude, called light curves, are observational statistics of interest captured by telescopes over long periods of time. Light curves afford the exploration of Space Domain Awareness (SDA) objectives such as object identification or pose estimation as latent variable inference problems. Ground-based observations from commercial off the shelf (COTS) cameras remain inexpensive compared to higher precision instruments, however, limited sensor availability combined with noisier observations can produce gappy time-series data that can be difficult to model. These external factors confound the automated exploitation of light curves, which makes light curve prediction and extrapolation a crucial problem for applications. Traditionally, image or time-series completion problems have been approached with diffusion-based or exemplar-based methods. More recently, Deep Neural Networks (DNNs) have become the tool of choice due to their empirical success at learning complex nonlinear embeddings. However, DNNs often require large training data that are not necessarily available when looking at unique features of a light curve of a single satellite. In this paper, we present a novel approach to predicting missing and future data points of light curves using Gaussian Processes (GPs). GPs are non-linear probabilistic models that infer posterior distributions over functions and naturally quantify uncertainty. However, the cubic scaling of GP inference and training is a major barrier to their adoption in applications. In particular, a single light curve can feature hundreds of thousands of observations, which is well beyond the practical realization limits of a conventional GP on a single machine. Consequently, we employ MuyGPs, a scalable framework for hyperparameter estimation of GP models that uses nearest neighbors sparsification and local cross-validation. MuyGPs...
SSDNet: State Space Decomposition Neural Network for Time Series Forecasting
Dec 19, 2021
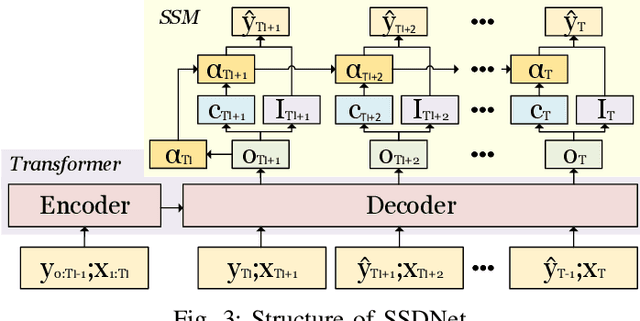
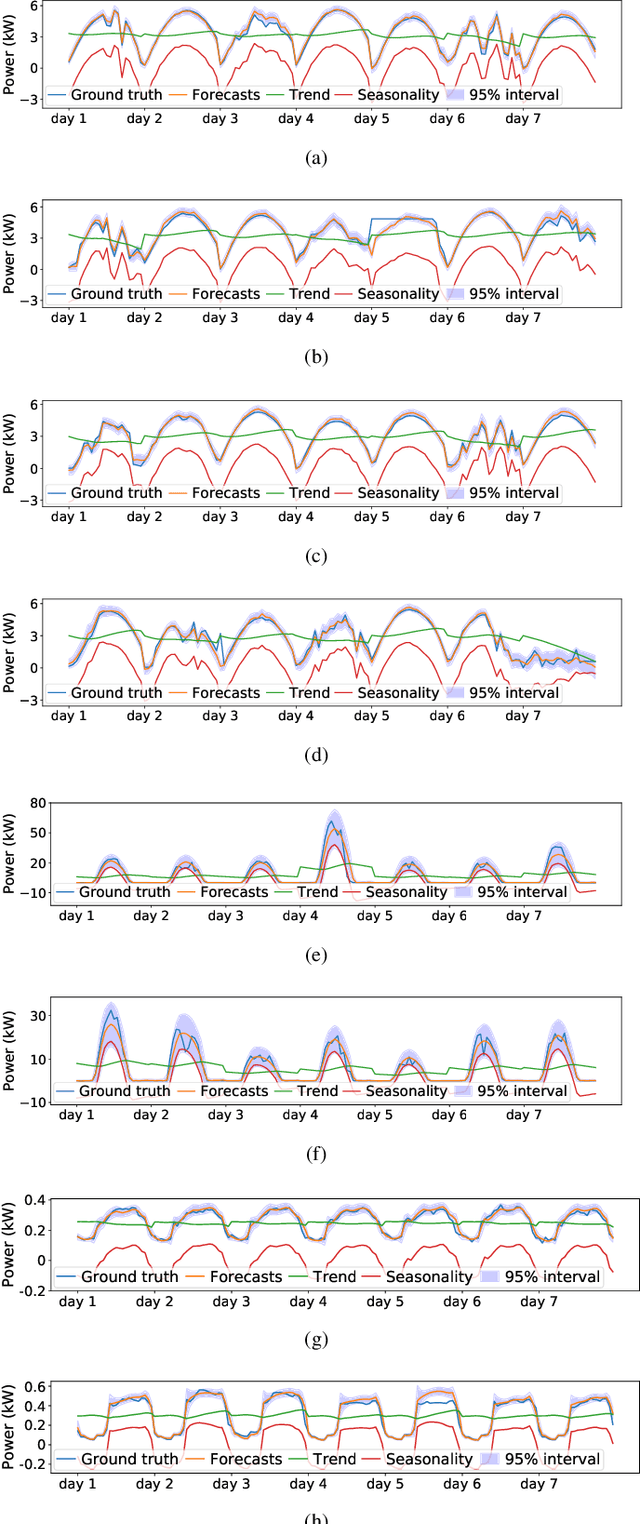
In this paper, we present SSDNet, a novel deep learning approach for time series forecasting. SSDNet combines the Transformer architecture with state space models to provide probabilistic and interpretable forecasts, including trend and seasonality components and previous time steps important for the prediction. The Transformer architecture is used to learn the temporal patterns and estimate the parameters of the state space model directly and efficiently, without the need for Kalman filters. We comprehensively evaluate the performance of SSDNet on five data sets, showing that SSDNet is an effective method in terms of accuracy and speed, outperforming state-of-the-art deep learning and statistical methods, and able to provide meaningful trend and seasonality components.
Actor-Critic Network for O-RAN Resource Allocation: xApp Design, Deployment, and Analysis
Sep 26, 2022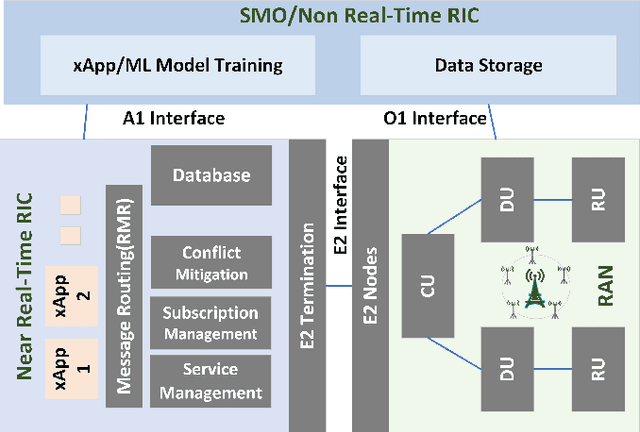
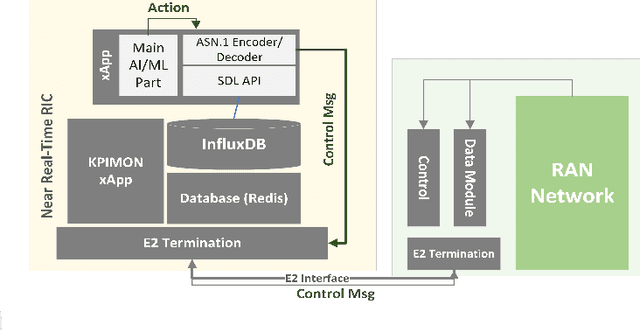
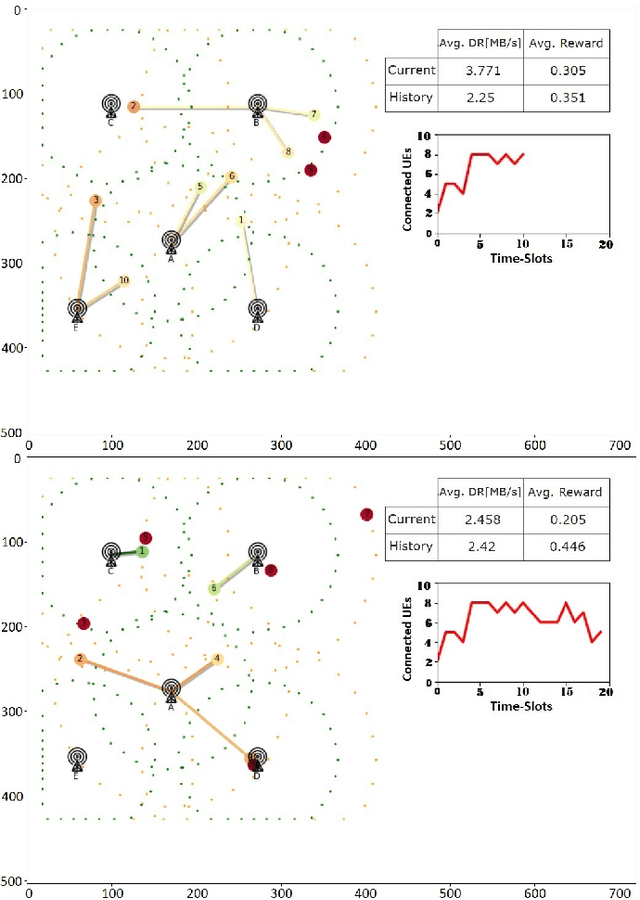
Open Radio Access Network (O-RAN) has introduced an emerging RAN architecture that enables openness, intelligence, and automated control. The RAN Intelligent Controller (RIC) provides the platform to design and deploy RAN controllers. xApps are the applications which will take this responsibility by leveraging machine learning (ML) algorithms and acting in near-real time. Despite the opportunities provided by this new architecture, the progress of practical artificial intelligence (AI)-based solutions for network control and automation has been slow. This is mostly because of the lack of an endto-end solution for designing, deploying, and testing AI-based xApps fully executable in real O-RAN network. In this paper we introduce an end-to-end O-RAN design and evaluation procedure and provide a detailed discussion of developing a Reinforcement Learning (RL) based xApp by using two different RL approaches and considering the latest released O-RAN architecture and interfaces.