 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FONDUE: an algorithm to find the optimal dimensionality of the latent representations of variational autoencoders
Sep 26, 2022
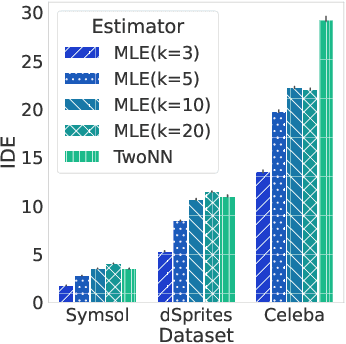

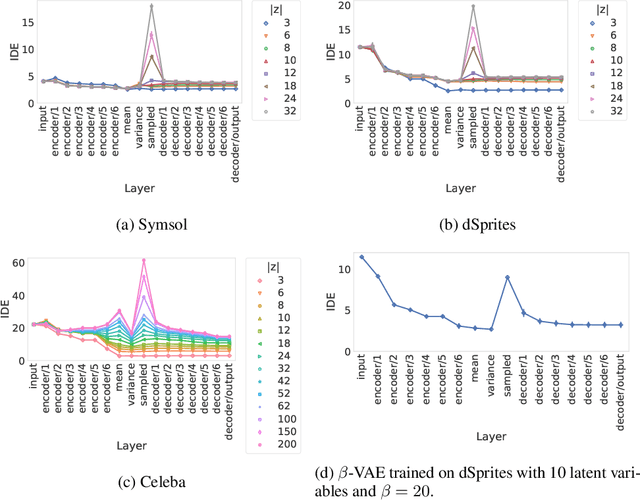
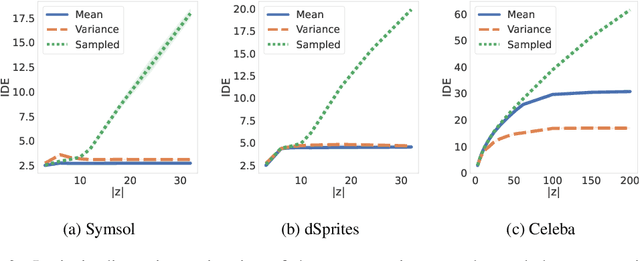
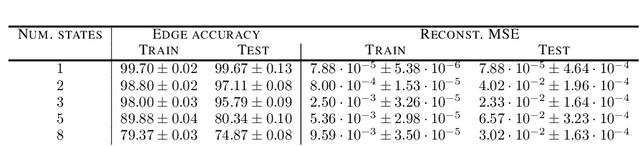
When training a variational autoencoder (VAE) on a given dataset, determining the optimal number of latent variables is mostly done by grid search: a costly process in terms of computational time and carbon footprint. In this paper, we explore the intrinsic dimension estimation (IDE) of the data and latent representations learned by VAEs. We show that the discrepancies between the IDE of the mean and sampled representations of a VAE after only a few steps of training reveal the presence of passive variables in the latent space, which, in well-behaved VAEs, indicates a superfluous number of dimensions. Using this property, we propose FONDUE: an algorithm which quickly finds the number of latent dimensions after which the mean and sampled representations start to diverge (i.e., when passive variables are introduced), providing a principled method for selecting the number of latent dimensions for VAEs and autoencoders.
Light-weight Gesture Sensing Using FMCW Radar Time Series Data
Nov 22, 2021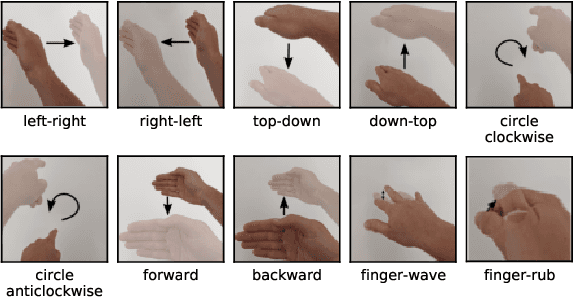
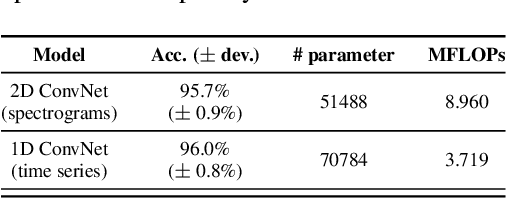
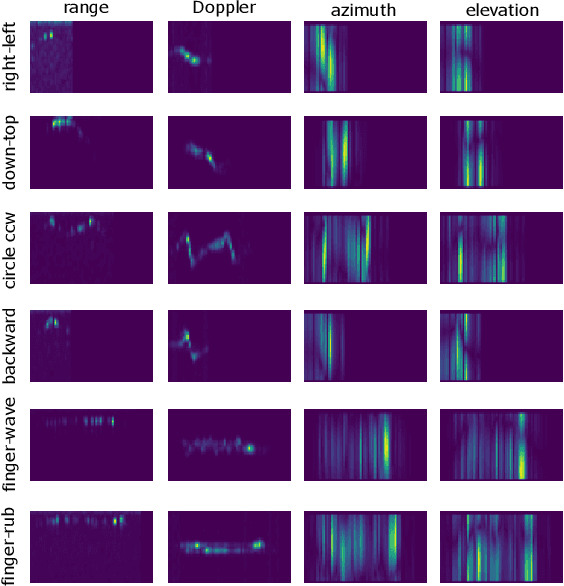
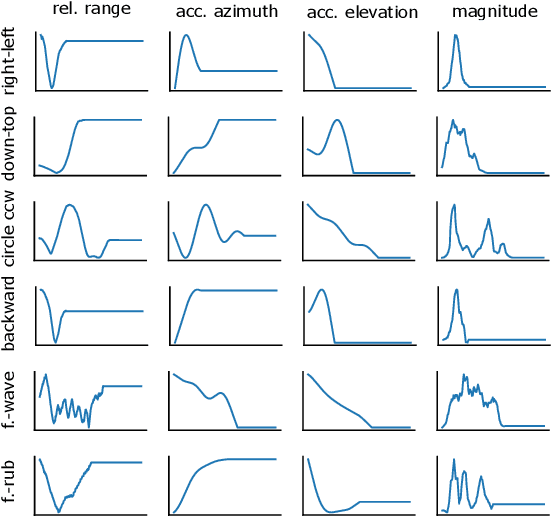
The paper proposes a novel feature extraction approach for FMCW radar systems in the field of short-range gesture sensing. A light-weight processing is proposed which reduces a series of 3D radar data cubes to four 1D time signals containing information about range, azimuth angle, elevation angle and magnitude. The processing is entirely performed in the time domain without using any Fourier transformation and enables the training of a deep neural network directly on the raw time domain data. It is shown experimentally on real world data, that the proposed processing retains the same expressive power as conventional radar processing to range-, Doppler- and angle-spectrograms. Further, the computational complexity is significantly reduced which makes it perfectly suitable for embedded devices. The system is able to recognize ten different gestures with an accuracy of about 95% and is running in real time on a Raspberry Pi 3 B. The delay between end of gesture and prediction is only 150 ms.
SoftGroup++: Scalable 3D Instance Segmentation with Octree Pyramid Grouping
Sep 17, 2022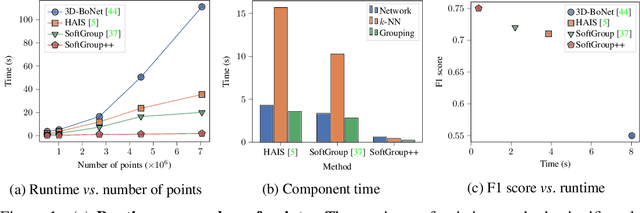
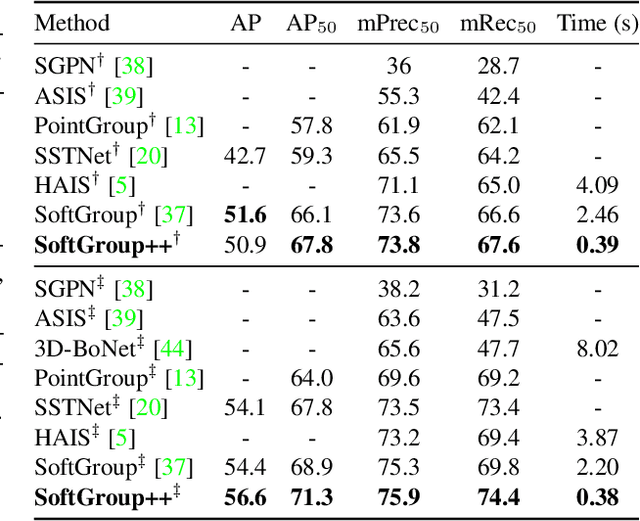
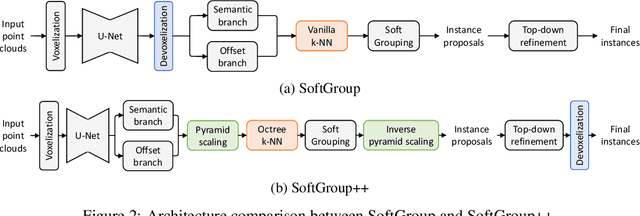
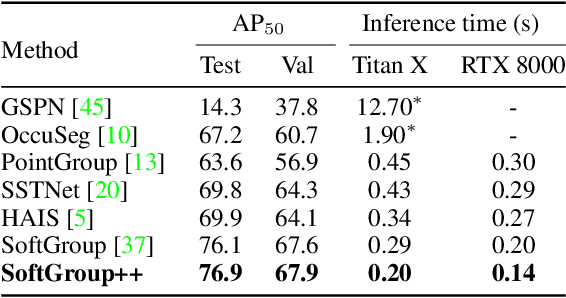
Existing state-of-the-art 3D point cloud instance segmentation methods rely on a grouping-based approach that groups points to obtain object instances. Despite improvement in producing accurate segmentation results, these methods lack scalability and commonly require dividing large input into multiple parts. To process a scene with millions of points, the existing fastest method SoftGroup \cite{vu2022softgroup} requires tens of seconds, which is under satisfaction. Our finding is that $k$-Nearest Neighbor ($k$-NN), which serves as the prerequisite of grouping, is a computational bottleneck. This bottleneck severely worsens the inference time in the scene with a large number of points. This paper proposes SoftGroup++ to address this computational bottleneck and further optimize the inference speed of the whole network. SoftGroup++ is built upon SoftGroup, which differs in three important aspects: (1) performs octree $k$-NN instead of vanilla $k$-NN to reduce time complexity from $\mathcal{O}(n^2)$ to $\mathcal{O}(n \log n)$, (2) performs pyramid scaling that adaptively downsamples backbone outputs to reduce search space for $k$-NN and grouping, and (3) performs late devoxelization that delays the conversion from voxels to points towards the end of the model such that intermediate components operate at a low computational cost. Extensive experiments on various indoor and outdoor datasets demonstrate the efficacy of the proposed SoftGroup++. Notably, SoftGroup++ processes large scenes of millions of points by a single forward without dividing the input into multiple parts, thus enriching contextual information. Especially, SoftGroup++ achieves 2.4 points AP$_{50}$ improvement while nearly $6\times$ faster than the existing fastest method on S3DIS dataset. The code and trained models will be made publicly available.
Causal discovery from conditionally stationary time-series
Oct 12, 2021

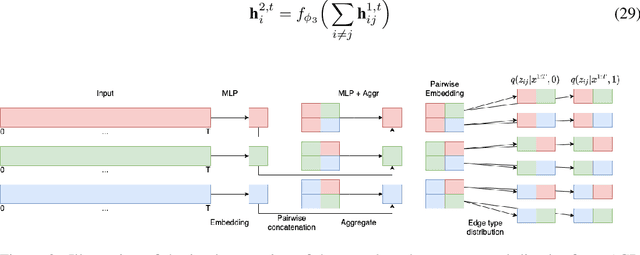
Causal discovery, i.e., inferring underlying cause-effect relationships from observations of a scene or system, is an inherent mechanism in human cognition, but has been shown to be highly challenging to automate. The majority of approaches in the literature aiming for this task consider constrained scenarios with fully observed variables or data from stationary time-series. In this work we aim for causal discovery in a more general class of scenarios, scenes with non-stationary behavior over time. For our purposes we here regard a scene as a composition objects interacting with each other over time. Non-stationarity is modeled as stationarity conditioned on an underlying variable, a state, which can be of varying dimension, more or less hidden given observations of the scene, and also depend more or less directly on these observations. We propose a probabilistic deep learning approach called State-Dependent Causal Inference (SDCI) for causal discovery in such conditionally stationary time-series data. Results in two different synthetic scenarios show that this method is able to recover the underlying causal dependencies with high accuracy even in cases with hidden states.
Deep Explicit Duration Switching Models for Time Series
Oct 26, 2021



Many complex time series can be effectively subdivided into distinct regimes that exhibit persistent dynamics. Discovering the switching behavior and the statistical patterns in these regimes is important for understanding the underlying dynamical system. We propose the Recurrent Explicit Duration Switching Dynamical System (RED-SDS), a flexible model that is capable of identifying both state- and time-dependent switching dynamics. State-dependent switching is enabled by a recurrent state-to-switch connection and an explicit duration count variable is used to improve the time-dependent switching behavior. We demonstrate how to perform efficient inference using a hybrid algorithm that approximates the posterior of the continuous states via an inference network and performs exact inference for the discrete switches and counts. The model is trained by maximizing a Monte Carlo lower bound of the marginal log-likelihood that can be computed efficiently as a byproduct of the inference routine. Empirical results on multiple datasets demonstrate that RED-SDS achieves considerable improvement in time series segmentation and competitive forecasting performance against the state of the art.
Automatic driving path plan based on iterative and triple optimization method
Sep 08, 2022
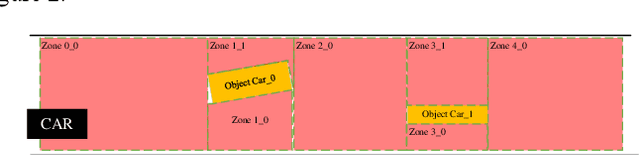
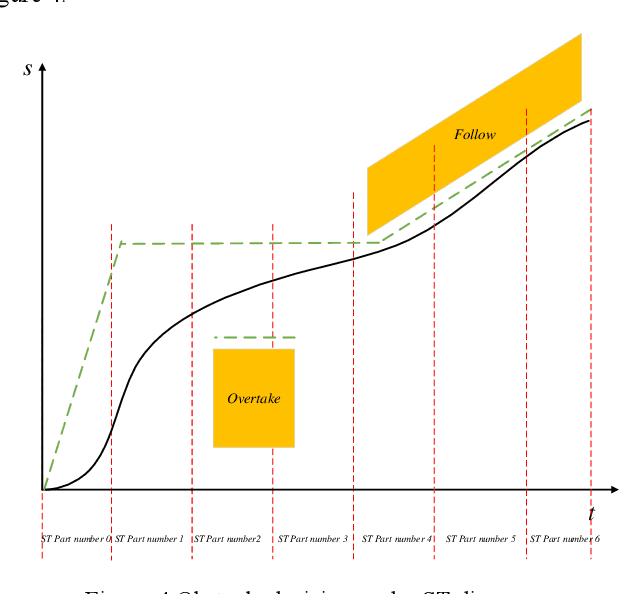
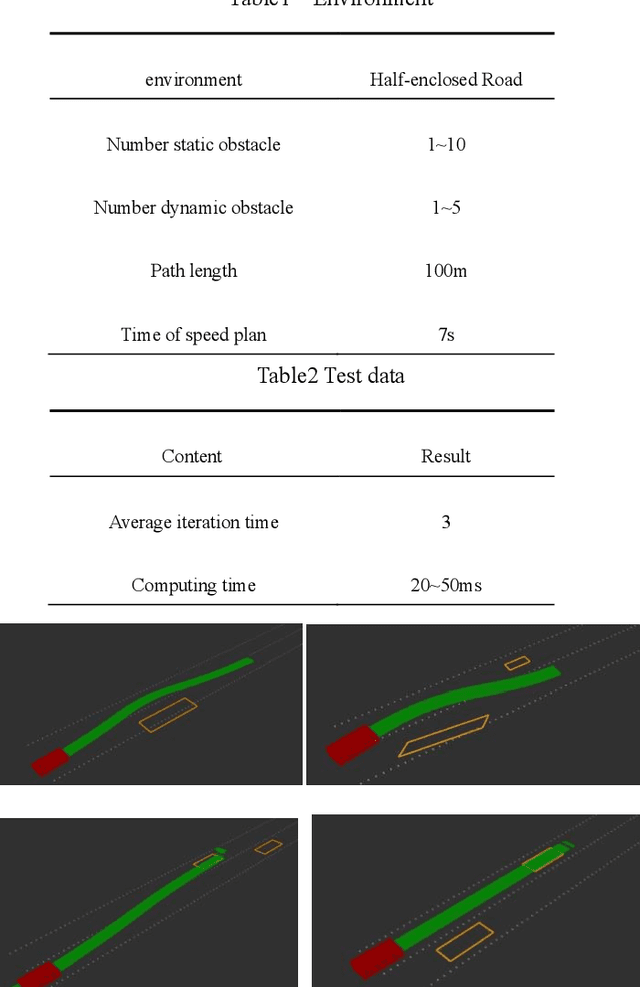
This paper presents a triple optimization algorithm of two-dimensional space, driving path and driving speed, and iterates in the time dimension to obtain the local optimal solution of path and speed in the optimal driving area. Design iterative algorithm to solve the best driving path and speed within the limited conditions. The algorithm can meet the path planning needs of automatic driving vehicle in complex scenes and medium and high-speed scenes.
Attention Augmented ConvNeXt UNet For Rectal Tumour Segmentation
Oct 01, 2022

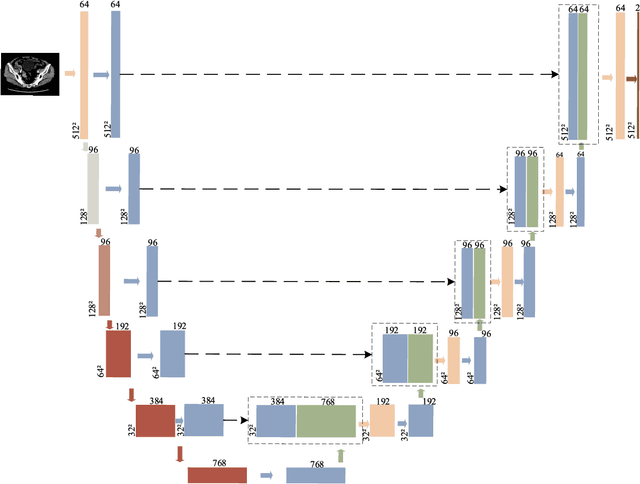
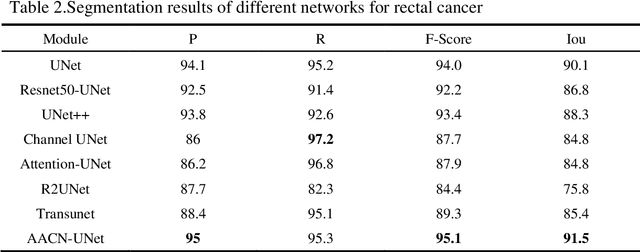
It is a challenge to segment the location and size of rectal cancer tumours through deep learning. In this paper, in order to improve the ability of extracting suffi-cient feature information in rectal tumour segmentation, attention enlarged ConvNeXt UNet (AACN-UNet), is proposed. The network mainly includes two improvements: 1) the encoder stage of UNet is changed to ConvNeXt structure for encoding operation, which can not only integrate multi-scale semantic information on a large scale, but al-so reduce information loss and extract more feature information from CT images; 2) CBAM attention mechanism is added to improve the connection of each feature in channel and space, which is conducive to extracting the effective feature of the target and improving the segmentation accuracy.The experiment with UNet and its variant network shows that AACN-UNet is 0.9% ,1.1% and 1.4% higher than the current best results in P, F1 and Miou.Compared with the training time, the number of parameters in UNet network is less. This shows that our proposed AACN-UNet has achieved ex-cellent results in CT image segmentation of rectal cancer.
Efficient Quantum Agnostic Improper Learning of Decision Trees
Oct 01, 2022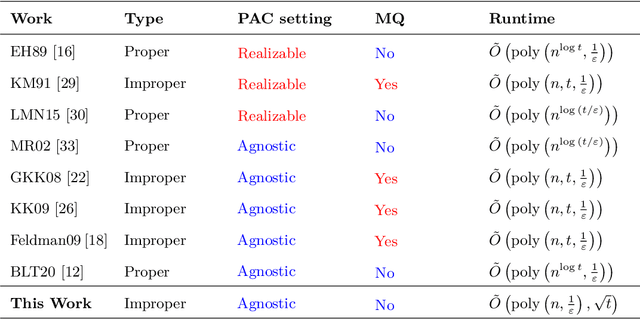
The agnostic setting is the hardest generalization of the PAC model since it is akin to learning with adversarial noise. We study an open question on the existence of efficient quantum boosting algorithms in this setting. We answer this question in the affirmative by providing a quantum version of the Kalai-Kanade potential boosting algorithm. This algorithm shows the standard quadratic speedup in the VC dimension of the weak learner compared to the classical case. Using our boosting algorithm as a subroutine, we give a quantum algorithm for agnostically learning decision trees in polynomial running time without using membership queries. To the best of our knowledge, this is the first algorithm (quantum or classical) to do so. Learning decision trees without membership queries is hard (and an open problem) in the standard classical realizable setting. In general, even coming up with weak learners in the agnostic setting is a challenging task. We show how to construct a quantum agnostic weak learner using standard quantum algorithms, which is of independent interest for designing ensemble learning setups.
Design of Economical Fuzzy Logic Controller for Washing Machine
Oct 01, 2022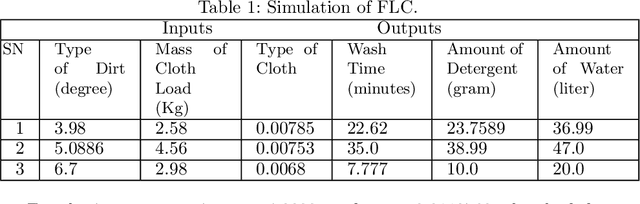
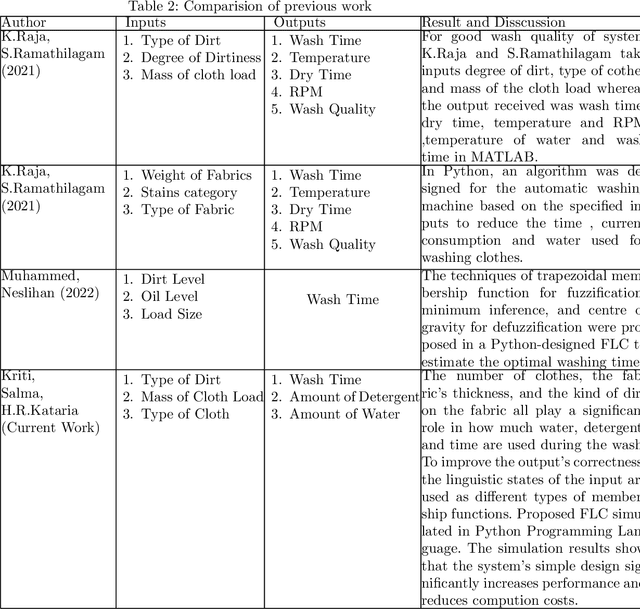
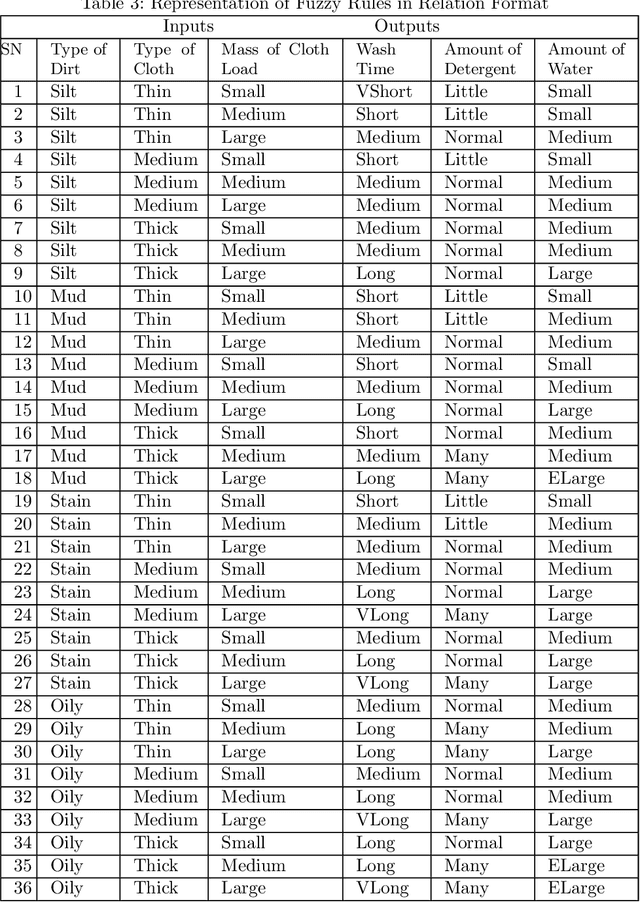
Things are becoming more advanced as technology advances, and machines now perform the majority of the manual work. The most often used home appliance is the washing machine for cloths. Modification and research in this field is essential since it pertains to the amount of time, water, and electricity required for washing. In this work, a Fuzzy Logic Controller has been developed for smart washing machines. The objective of this paper is to optimize the consumption of electricity, water, and detergent for washing machines. The type of dirt, volume of clothes, and type of cloth play a vital role in saving water, electricity, and detergent. However, none of the work on the Fuzzy Logic Controller provided a design procedure endowed with the specified inputs and outputs implemented in Python. In this paper, we used the Mamdani approach and created an algorithm based on multi-input multi-output. The algorithm is implemented in Python. The results of this simulation show that the washing machine provides better execution at a low computation cost.
Deterministic Sequencing of Exploration and Exploitation for Reinforcement Learning
Sep 15, 2022We propose Deterministic Sequencing of Exploration and Exploitation (DSEE) algorithm with interleaving exploration and exploitation epochs for model-based RL problems that aim to simultaneously learn the system model, i.e., a Markov decision process (MDP), and the associated optimal policy. During exploration, DSEE explores the environment and updates the estimates for expected reward and transition probabilities. During exploitation, the latest estimates of the expected reward and transition probabilities are used to obtain a robust policy with high probability. We design the lengths of the exploration and exploitation epochs such that the cumulative regret grows as a sub-linear function of time.