 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reducing Annotation Effort by Identifying and Labeling Contextually Diverse Classes for Semantic Segmentation Under Domain Shift
Oct 13, 2022
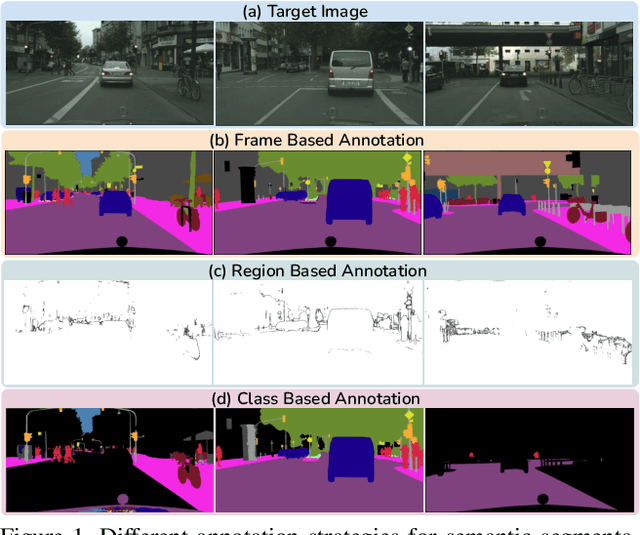
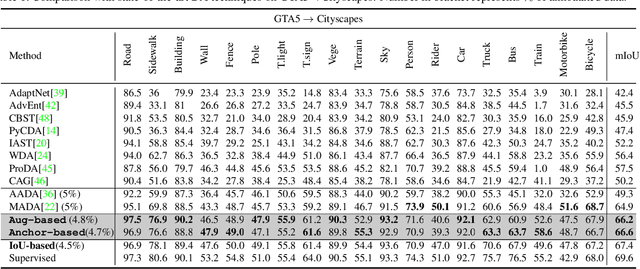
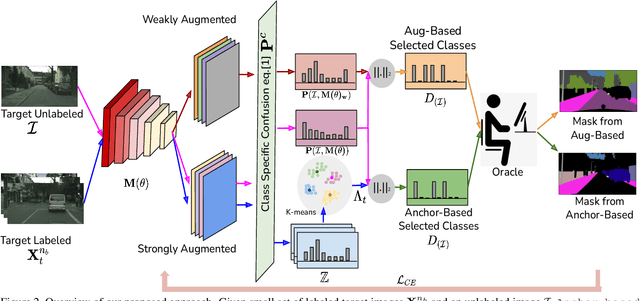
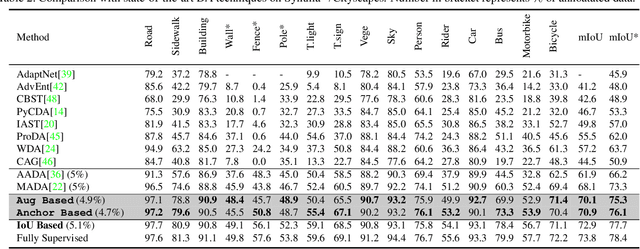
In Active Domain Adaptation (ADA), one uses Active Learning (AL) to select a subset of images from the target domain, which are then annotated and used for supervised domain adaptation (DA). Given the large performance gap between supervised and unsupervised DA techniques, ADA allows for an excellent trade-off between annotation cost and performance. Prior art makes use of measures of uncertainty or disagreement of models to identify `regions' to be annotated by the human oracle. However, these regions frequently comprise of pixels at object boundaries which are hard and tedious to annotate. Hence, even if the fraction of image pixels annotated reduces, the overall annotation time and the resulting cost still remain high. In this work, we propose an ADA strategy, which given a frame, identifies a set of classes that are hardest for the model to predict accurately, thereby recommending semantically meaningful regions to be annotated in a selected frame. We show that these set of `hard' classes are context-dependent and typically vary across frames, and when annotated help the model generalize better. We propose two ADA techniques: the Anchor-based and Augmentation-based approaches to select complementary and diverse regions in the context of the current training set. Our approach achieves 66.6 mIoU on GTA to Cityscapes dataset with an annotation budget of 4.7% in comparison to 64.9 mIoU by MADA using 5% of annotations. Our technique can also be used as a decorator for any existing frame-based AL technique, e.g., we report 1.5% performance improvement for CDAL on Cityscapes using our approach.
Behavioral graph fraud detection in E-commerce
Oct 13, 2022

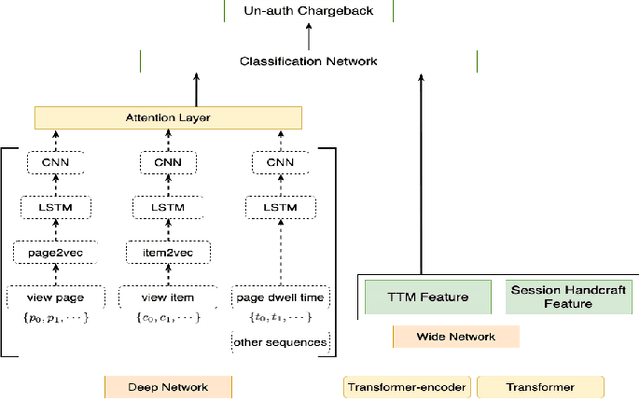
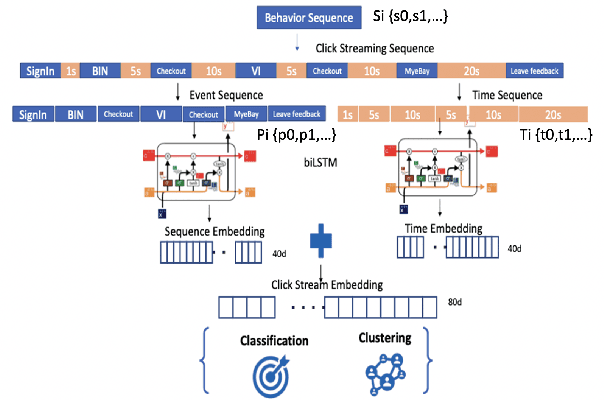
In e-commerce industry, graph neural network methods are the new trends for transaction risk modeling.The power of graph algorithms lie in the capability to catch transaction linking network information, which is very hard to be captured by other algorithms.However, in most existing approaches, transaction or user connections are defined by hard link strategies on shared properties, such as same credit card, same device, same ip address, same shipping address, etc. Those types of strategies will result in sparse linkages by entities with strong identification characteristics (ie. device) and over-linkages by entities that could be widely shared (ie. ip address), making it more difficult to learn useful information from graph. To address aforementioned problems, we present a novel behavioral biometric based method to establish transaction linkings based on user behavioral similarities, then train an unsupervised GNN to extract embedding features for downstream fraud prediction tasks. To our knowledge, this is the first time similarity based soft link has been used in graph embedding applications. To speed up similarity calculation, we apply an in-house GPU based HDBSCAN clustering method to remove highly concentrated and isolated nodes before graph construction. Our experiments show that embedding features learned from similarity based behavioral graph have achieved significant performance increase to the baseline fraud detection model in various business scenarios. In new guest buyer transaction scenario, this segment is a challenge for traditional method, we can make precision increase from 0.82 to 0.86 at the same recall of 0.27, which means we can decrease false positive rate using this method.
From Gradient Flow on Population Loss to Learning with Stochastic Gradient Descent
Oct 13, 2022Stochastic Gradient Descent (SGD) has been the method of choice for learning large-scale non-convex models. While a general analysis of when SGD works has been elusive, there has been a lot of recent progress in understanding the convergence of Gradient Flow (GF) on the population loss, partly due to the simplicity that a continuous-time analysis buys us. An overarching theme of our paper is providing general conditions under which SGD converges, assuming that GF on the population loss converges. Our main tool to establish this connection is a general converse Lyapunov like theorem, which implies the existence of a Lyapunov potential under mild assumptions on the rates of convergence of GF. In fact, using these potentials, we show a one-to-one correspondence between rates of convergence of GF and geometrical properties of the underlying objective. When these potentials further satisfy certain self-bounding properties, we show that they can be used to provide a convergence guarantee for Gradient Descent (GD) and SGD (even when the paths of GF and GD/SGD are quite far apart). It turns out that these self-bounding assumptions are in a sense also necessary for GD/SGD to work. Using our framework, we provide a unified analysis for GD/SGD not only for classical settings like convex losses, or objectives that satisfy PL / KL properties, but also for more complex problems including Phase Retrieval and Matrix sq-root, and extending the results in the recent work of Chatterjee 2022.
Trajectory Prediction for Vehicle Conflict Identification at Intersections Using Sequence-to-Sequence Recurrent Neural Networks
Oct 13, 2022
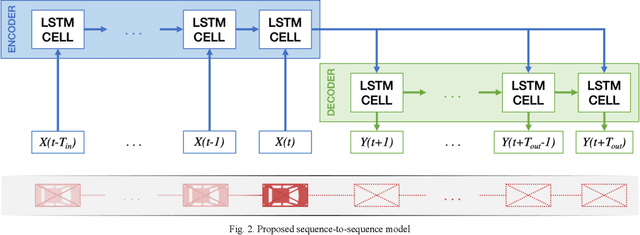
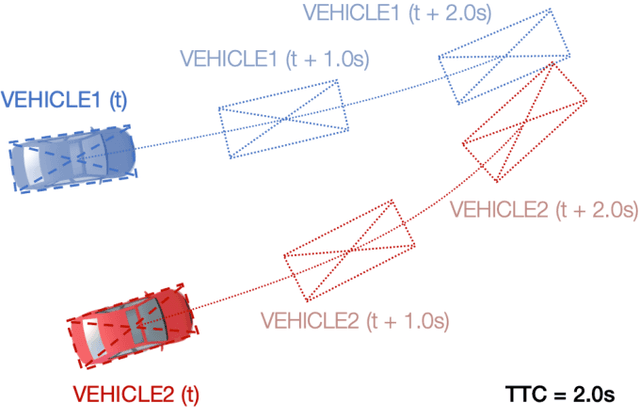
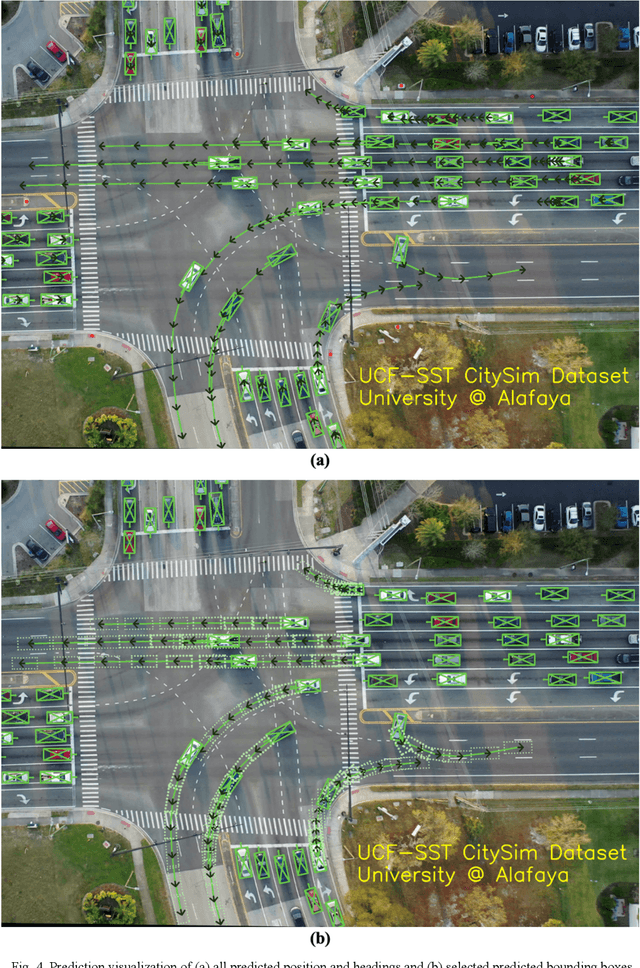
Surrogate safety measures in the form of conflict indicators are indispensable components of the proactive traffic safety toolbox. Conflict indicators can be classified into past-trajectory-based conflicts and predicted-trajectory-based conflicts. While the calculation of the former class of conflicts is deterministic and unambiguous, the latter category is computed using predicted vehicle trajectories and is thus more stochastic. Consequently, the accuracy of prediction-based conflicts is contingent on the accuracy of the utilized trajectory prediction algorithm. Trajectory prediction can be a challenging task, particularly at intersections where vehicle maneuvers are diverse. Furthermore, due to limitations relating to the road user trajectory extraction pipelines, accurate geometric representation of vehicles during conflict analysis is a challenging task. Misrepresented geometries distort the real distances between vehicles under observation. In this research, a prediction-based conflict identification methodology was proposed. A sequence-to-sequence Recurrent Neural Network was developed to sequentially predict future vehicle trajectories for up to 3 seconds ahead. Furthermore, the proposed network was trained using the CitySim Dataset to forecast both future vehicle positions and headings to facilitate the prediction of future bounding boxes, thus maintaining accurate vehicle geometric representations. It was experimentally determined that the proposed method outperformed frequently used trajectory prediction models for conflict analysis at intersections. A comparison between Time-to-Collision (TTC) conflict identification using vehicle bounding boxes versus the commonly used vehicle center points for geometric representation was conducted. Compared to the bounding box method, the center point approach often failed to identify TTC conflicts or underestimated their severity.
ALIFE: Adaptive Logit Regularizer and Feature Replay for Incremental Semantic Segmentation
Oct 13, 2022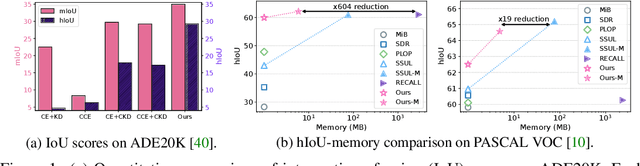
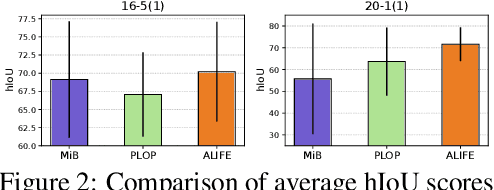
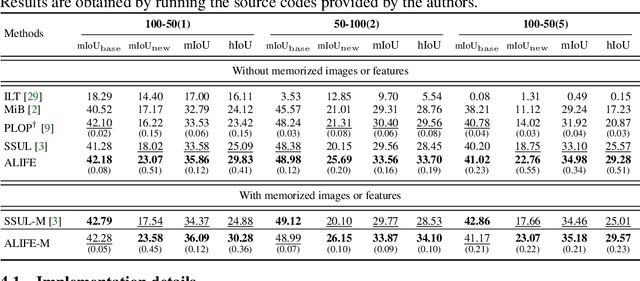
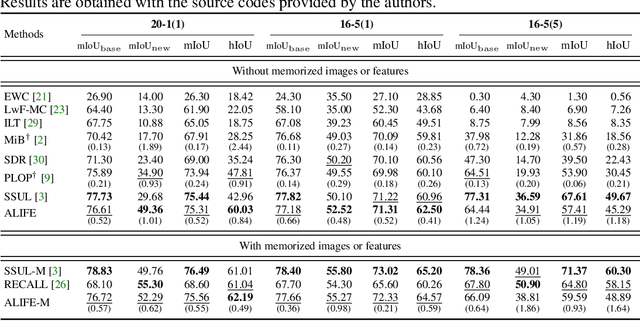
We address the problem of incremental semantic segmentation (ISS) recognizing novel object/stuff categories continually without forgetting previous ones that have been learned. The catastrophic forgetting problem is particularly severe in ISS, since pixel-level ground-truth labels are available only for the novel categories at training time. To address the problem, regularization-based methods exploit probability calibration techniques to learn semantic information from unlabeled pixels. While such techniques are effective, there is still a lack of theoretical understanding of them. Replay-based methods propose to memorize a small set of images for previous categories. They achieve state-of-the-art performance at the cost of large memory footprint. We propose in this paper a novel ISS method, dubbed ALIFE, that provides a better compromise between accuracy and efficiency. To this end, we first show an in-depth analysis on the calibration techniques to better understand the effects on ISS. Based on this, we then introduce an adaptive logit regularizer (ALI) that enables our model to better learn new categories, while retaining knowledge for previous ones. We also present a feature replay scheme that memorizes features, instead of images directly, in order to reduce memory requirements significantly. Since a feature extractor is changed continually, memorized features should also be updated at every incremental stage. To handle this, we introduce category-specific rotation matrices updating the features for each category separately. We demonstrate the effectiveness of our approach with extensive experiments on standard ISS benchmarks, and show that our method achieves a better trade-off in terms of accuracy and efficiency.
Sustainable Online Reinforcement Learning for Auto-bidding
Oct 13, 2022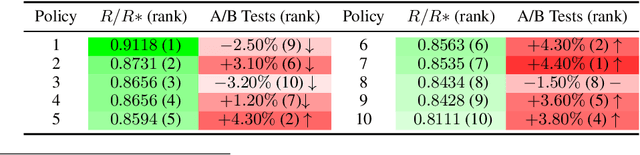
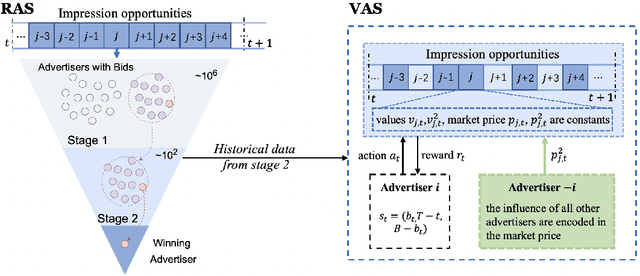

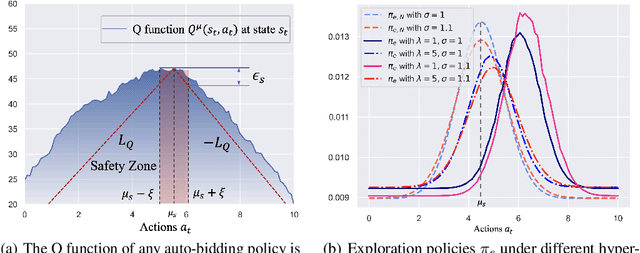
Recently, auto-bidding technique has become an essential tool to increase the revenue of advertisers. Facing the complex and ever-changing bidding environments in the real-world advertising system (RAS), state-of-the-art auto-bidding policies usually leverage reinforcement learning (RL) algorithms to generate real-time bids on behalf of the advertisers. Due to safety concerns, it was believed that the RL training process can only be carried out in an offline virtual advertising system (VAS) that is built based on the historical data generated in the RAS. In this paper, we argue that there exists significant gaps between the VAS and RAS, making the RL training process suffer from the problem of inconsistency between online and offline (IBOO). Firstly, we formally define the IBOO and systematically analyze its causes and influences. Then, to avoid the IBOO, we propose a sustainable online RL (SORL) framework that trains the auto-bidding policy by directly interacting with the RAS, instead of learning in the VAS. Specifically, based on our proof of the Lipschitz smooth property of the Q function, we design a safe and efficient online exploration (SER) policy for continuously collecting data from the RAS. Meanwhile, we derive the theoretical lower bound on the safety of the SER policy. We also develop a variance-suppressed conservative Q-learning (V-CQL) method to effectively and stably learn the auto-bidding policy with the collected data. Finally, extensive simulated and real-world experiments validate the superiority of our approach over the state-of-the-art auto-bidding algorithm.
Homotopy-based training of NeuralODEs for accurate dynamics discovery
Oct 04, 2022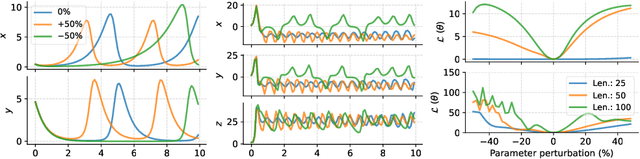
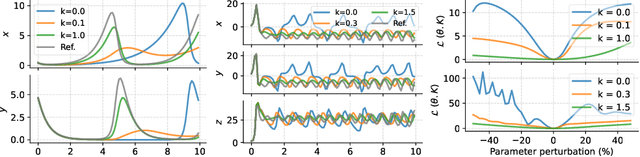
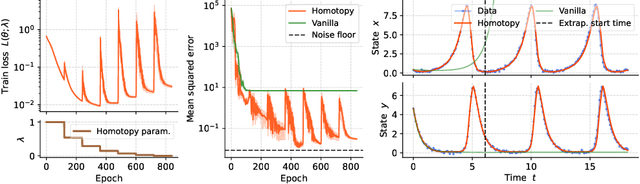
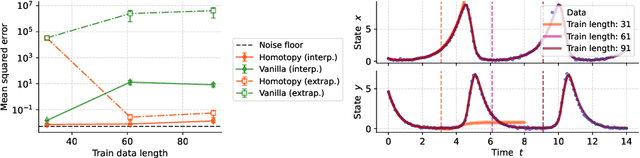
Conceptually, Neural Ordinary Differential Equations (NeuralODEs) pose an attractive way to extract dynamical laws from time series data, as they are natural extensions of the traditional differential equation-based modeling paradigm of the physical sciences. In practice, NeuralODEs display long training times and suboptimal results, especially for longer duration data where they may fail to fit the data altogether. While methods have been proposed to stabilize NeuralODE training, many of these involve placing a strong constraint on the functional form the trained NeuralODE can take that the actual underlying governing equation does not guarantee satisfaction. In this work, we present a novel NeuralODE training algorithm that leverages tools from the chaos and mathematical optimization communities - synchronization and homotopy optimization - for a breakthrough in tackling the NeuralODE training obstacle. We demonstrate architectural changes are unnecessary for effective NeuralODE training. Compared to the conventional training methods, our algorithm achieves drastically lower loss values without any changes to the model architectures. Experiments on both simulated and real systems with complex temporal behaviors demonstrate NeuralODEs trained with our algorithm are able to accurately capture true long term behaviors and correctly extrapolate into the future.
Type theory in human-like learning and inference
Oct 04, 2022Humans can generate reasonable answers to novel queries (Schulz, 2012): if I asked you what kind of food you want to eat for lunch, you would respond with a food, not a time. The thought that one would respond "After 4pm" to "What would you like to eat" is either a joke or a mistake, and seriously entertaining it as a lunch option would likely never happen in the first place. While understanding how people come up with new ideas, thoughts, explanations, and hypotheses that obey the basic constraints of a novel search space is of central importance to cognitive science, there is no agreed-on formal model for this kind of reasoning. We propose that a core component of any such reasoning system is a type theory: a formal imposition of structure on the kinds of computations an agent can perform, and how they're performed. We motivate this proposal with three empirical observations: adaptive constraints on learning and inference (i.e. generating reasonable hypotheses), how people draw distinctions between improbability and impossibility, and people's ability to reason about things at varying levels of abstraction.
Continuous Monte Carlo Graph Search
Oct 04, 2022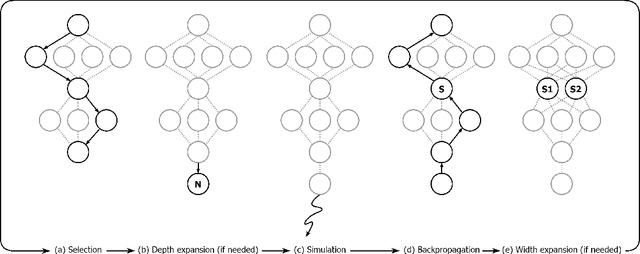


In many complex sequential decision making tasks, online planning is crucial for high-performance. For efficient online planning, Monte Carlo Tree Search (MCTS) employs a principled mechanism for trading off between exploration and exploitation. MCTS outperforms comparison methods in various discrete decision making domains such as Go, Chess, and Shogi. Following, extensions of MCTS to continuous domains have been proposed. However, the inherent high branching factor and the resulting explosion of search tree size is limiting existing methods. To solve this problem, this paper proposes Continuous Monte Carlo Graph Search (CMCGS), a novel extension of MCTS to online planning in environments with continuous state and action spaces. CMCGS takes advantage of the insight that, during planning, sharing the same action policy between several states can yield high performance. To implement this idea, at each time step CMCGS clusters similar states into a limited number of stochastic action bandit nodes, which produce a layered graph instead of an MCTS search tree. Experimental evaluation with limited sample budgets shows that CMCGS outperforms comparison methods in several complex continuous DeepMind Control Suite benchmarks and a 2D navigation task.
Wi-Closure: Reliable and Efficient Search of Inter-robot Loop Closures Using Wireless Sensing
Oct 04, 2022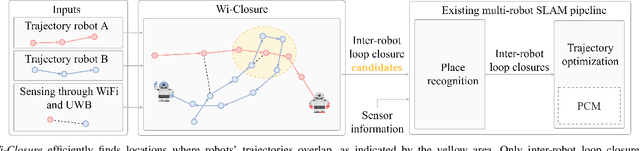
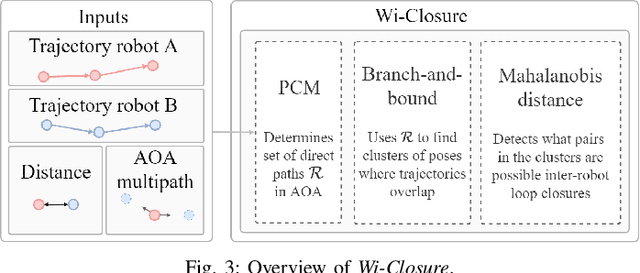
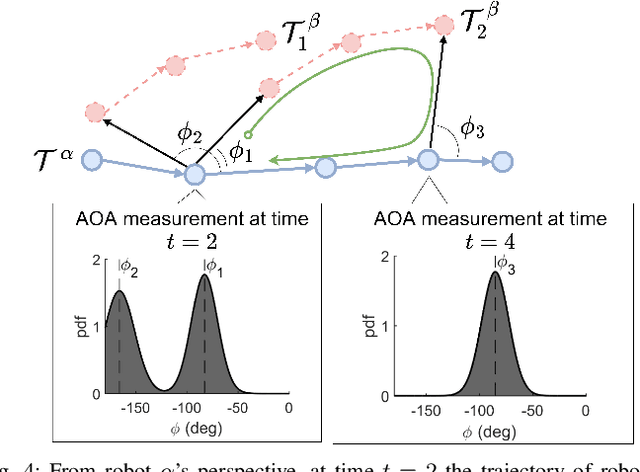
In this paper we propose a novel algorithm, Wi-Closure, to improve computational efficiency and robustness of loop closure detection in multi-robot SLAM. Our approach decreases the computational overhead of classical approaches by pruning the search space of potential loop closures, prior to evaluation by a typical multi-robot SLAM pipeline. Wi-Closure achieves this by identifying candidates that are spatially close to each other by using sensing over the wireless communication signal between robots, even when they are operating in non-line-of-sight or in remote areas of the environment from one another. We demonstrate the validity of our approach in simulation and hardware experiments. Our results show that using Wi-closure greatly reduces computation time, by 54% in simulation and by 77% in hardware compared, with a multi-robot SLAM baseline. Importantly, this is achieved without sacrificing accuracy. Using Wi-Closure reduces absolute trajectory estimation error by 99% in simulation and 89.2% in hardware experiments. This improvement is due in part to Wi-Closure's ability to avoid catastrophic optimization failure that typically occurs with classical approaches in challenging repetitive environments.