 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Light-weight Gesture Sensing Using FMCW Radar Time Series Data
Nov 22, 2021
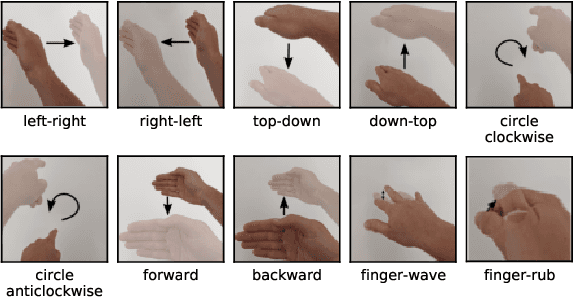
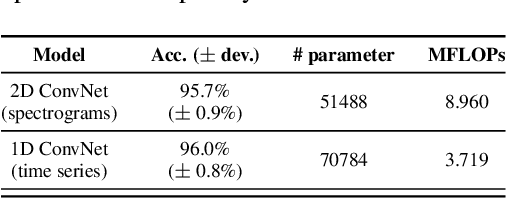
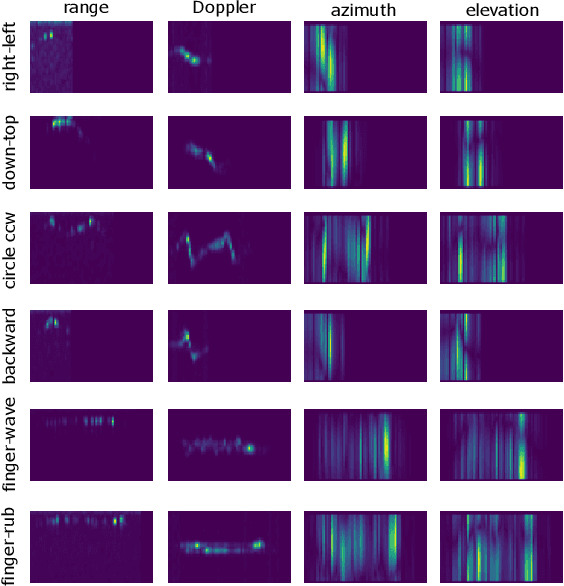
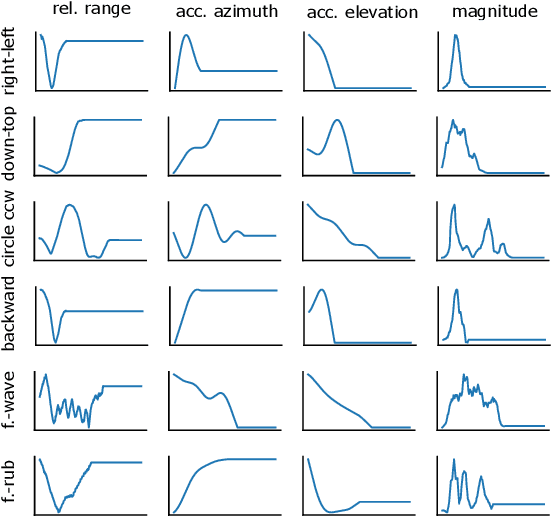
The paper proposes a novel feature extraction approach for FMCW radar systems in the field of short-range gesture sensing. A light-weight processing is proposed which reduces a series of 3D radar data cubes to four 1D time signals containing information about range, azimuth angle, elevation angle and magnitude. The processing is entirely performed in the time domain without using any Fourier transformation and enables the training of a deep neural network directly on the raw time domain data. It is shown experimentally on real world data, that the proposed processing retains the same expressive power as conventional radar processing to range-, Doppler- and angle-spectrograms. Further, the computational complexity is significantly reduced which makes it perfectly suitable for embedded devices. The system is able to recognize ten different gestures with an accuracy of about 95% and is running in real time on a Raspberry Pi 3 B. The delay between end of gesture and prediction is only 150 ms.
Causal discovery from conditionally stationary time-series
Oct 12, 2021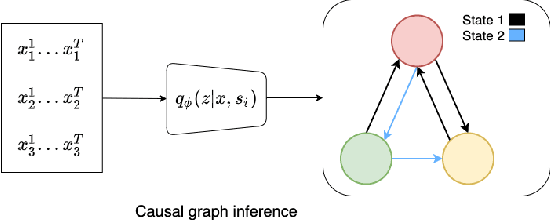

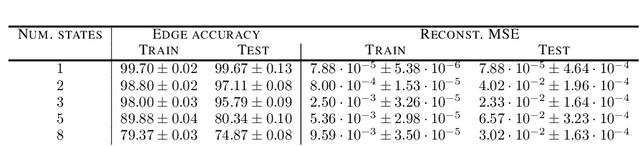
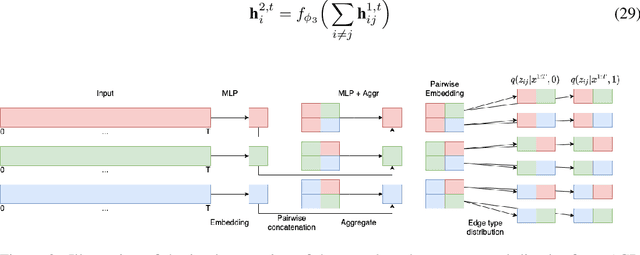
Causal discovery, i.e., inferring underlying cause-effect relationships from observations of a scene or system, is an inherent mechanism in human cognition, but has been shown to be highly challenging to automate. The majority of approaches in the literature aiming for this task consider constrained scenarios with fully observed variables or data from stationary time-series. In this work we aim for causal discovery in a more general class of scenarios, scenes with non-stationary behavior over time. For our purposes we here regard a scene as a composition objects interacting with each other over time. Non-stationarity is modeled as stationarity conditioned on an underlying variable, a state, which can be of varying dimension, more or less hidden given observations of the scene, and also depend more or less directly on these observations. We propose a probabilistic deep learning approach called State-Dependent Causal Inference (SDCI) for causal discovery in such conditionally stationary time-series data. Results in two different synthetic scenarios show that this method is able to recover the underlying causal dependencies with high accuracy even in cases with hidden states.
Zero-Shot Retargeting of Learned Quadruped Locomotion Policies Using Hybrid Kinodynamic Model Predictive Control
Sep 28, 2022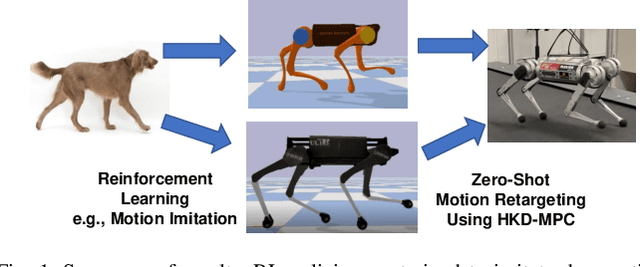
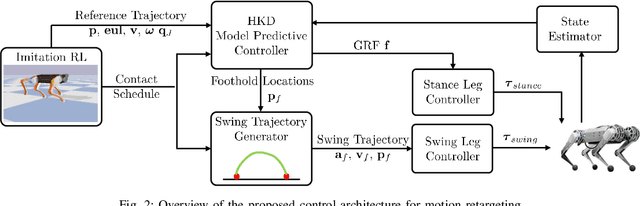


Reinforcement Learning (RL) has witnessed great strides for quadruped locomotion, with continued progress in the reliable sim-to-real transfer of policies. However, it remains a challenge to reuse a policy on another robot, which could save time for retraining. In this work, we present a framework for zero-shot policy retargeting wherein diverse motor skills can be transferred between robots of different shapes and sizes. The new framework centers on a planning-and-control pipeline that systematically integrates RL and Model Predictive Control (MPC). The planning stage employs RL to generate a dynamically plausible trajectory as well as the contact schedule, avoiding the combinatorial complexity of contact sequence optimization. This information is then used to seed the MPC to stabilize and robustify the policy roll-out via a new Hybrid Kinodynamic (HKD) model that implicitly optimizes the foothold locations. Hardware results show an ability to transfer policies from both the A1 and Laikago robots to the MIT Mini Cheetah robot without requiring any policy re-tuning.
Deep Explicit Duration Switching Models for Time Series
Oct 26, 2021



Many complex time series can be effectively subdivided into distinct regimes that exhibit persistent dynamics. Discovering the switching behavior and the statistical patterns in these regimes is important for understanding the underlying dynamical system. We propose the Recurrent Explicit Duration Switching Dynamical System (RED-SDS), a flexible model that is capable of identifying both state- and time-dependent switching dynamics. State-dependent switching is enabled by a recurrent state-to-switch connection and an explicit duration count variable is used to improve the time-dependent switching behavior. We demonstrate how to perform efficient inference using a hybrid algorithm that approximates the posterior of the continuous states via an inference network and performs exact inference for the discrete switches and counts. The model is trained by maximizing a Monte Carlo lower bound of the marginal log-likelihood that can be computed efficiently as a byproduct of the inference routine. Empirical results on multiple datasets demonstrate that RED-SDS achieves considerable improvement in time series segmentation and competitive forecasting performance against the state of the art.
A Trio-Method for Retinal Vessel Segmentation using Image Processing
Sep 19, 2022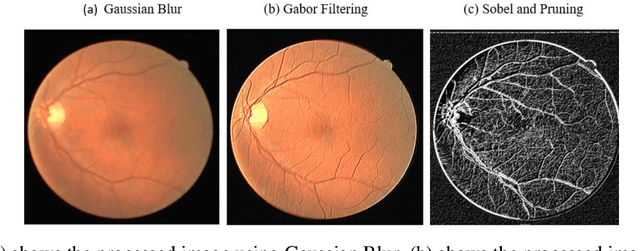

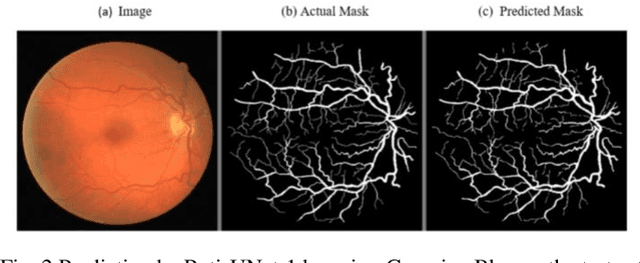

Inner Retinal neurons are a most essential part of the retina and they are supplied with blood via retinal vessels. This paper primarily focuses on the segmentation of retinal vessels using a triple preprocessing approach. DRIVE database was taken into consideration and preprocessed by Gabor Filtering, Gaussian Blur, and Edge Detection by Sobel and Pruning. Segmentation was driven out by 2 proposed U-Net architectures. Both the architectures were compared in terms of all the standard performance metrics. Preprocessing generated varied interesting results which impacted the results shown by the UNet architectures for segmentation. This real-time deployment can help in the efficient pre-processing of images with better segmentation and detection.
Autonomous Cooking with Digital Twin Methodology
Sep 07, 2022

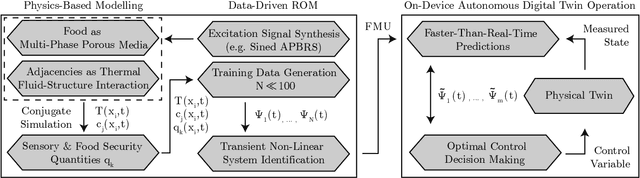
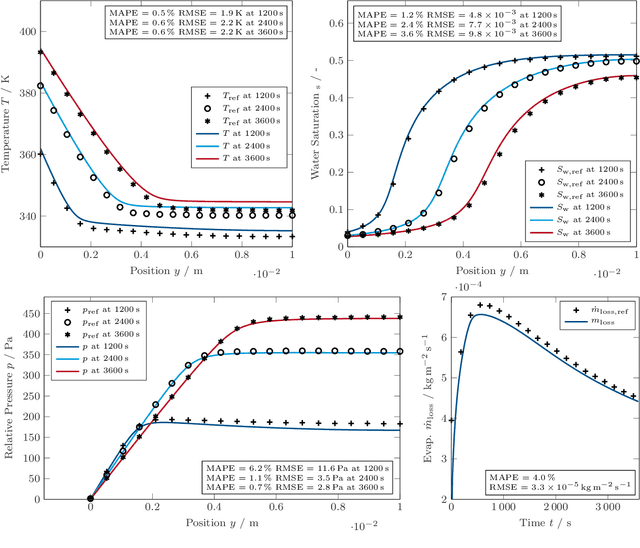
This work introduces the concept of an autonomous cooking process based on Digital Twin method- ology. It proposes a hybrid approach of physics-based full order simulations followed by a data-driven system identification process with low errors. It makes faster-than-real-time simulations of Digital Twins feasible on a device level, without the need for cloud or high-performance computing. The concept is universally applicable to various physical processes.
Efficient first-order predictor-corrector multiple objective optimization for fair misinformation detection
Sep 15, 2022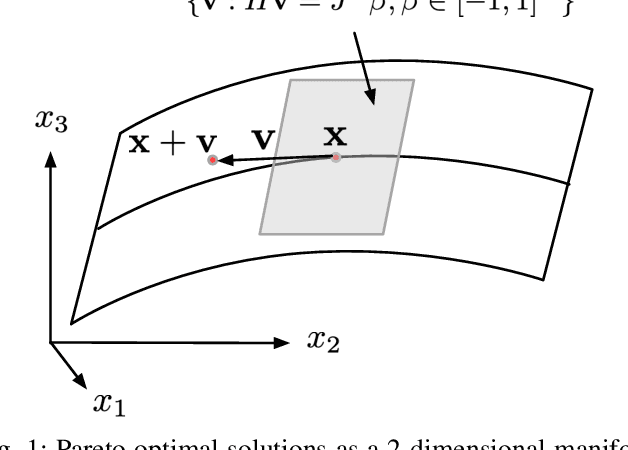
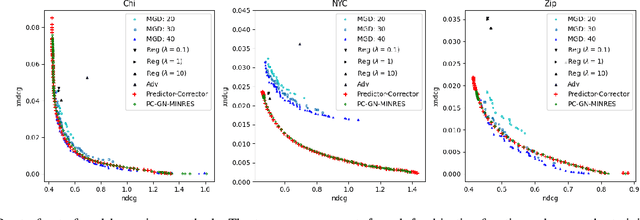
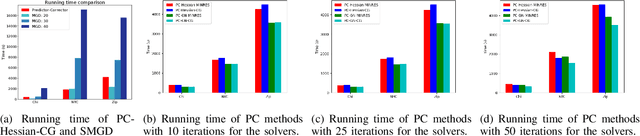
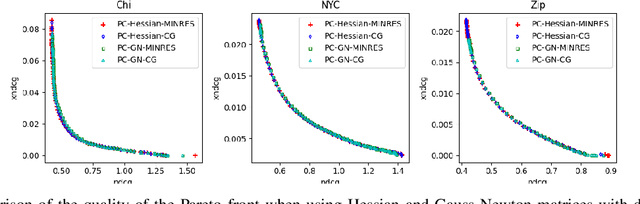
Multiple-objective optimization (MOO) aims to simultaneously optimize multiple conflicting objectives and has found important applications in machine learning, such as minimizing classification loss and discrepancy in treating different populations for fairness. At optimality, further optimizing one objective will necessarily harm at least another objective, and decision-makers need to comprehensively explore multiple optima (called Pareto front) to pinpoint one final solution. We address the efficiency of finding the Pareto front. First, finding the front from scratch using stochastic multi-gradient descent (SMGD) is expensive with large neural networks and datasets. We propose to explore the Pareto front as a manifold from a few initial optima, based on a predictor-corrector method. Second, for each exploration step, the predictor solves a large-scale linear system that scales quadratically in the number of model parameters and requires one backpropagation to evaluate a second-order Hessian-vector product per iteration of the solver. We propose a Gauss-Newton approximation that only scales linearly, and that requires only first-order inner-product per iteration. This also allows for a choice between the MINRES and conjugate gradient methods when approximately solving the linear system. The innovations make predictor-corrector possible for large networks. Experiments on multi-objective (fairness and accuracy) misinformation detection tasks show that 1) the predictor-corrector method can find Pareto fronts better than or similar to SMGD with less time; and 2) the proposed first-order method does not harm the quality of the Pareto front identified by the second-order method, while further reduce running time.
Hyperactive Learning (HAL) for Data-Driven Interatomic Potentials
Oct 09, 2022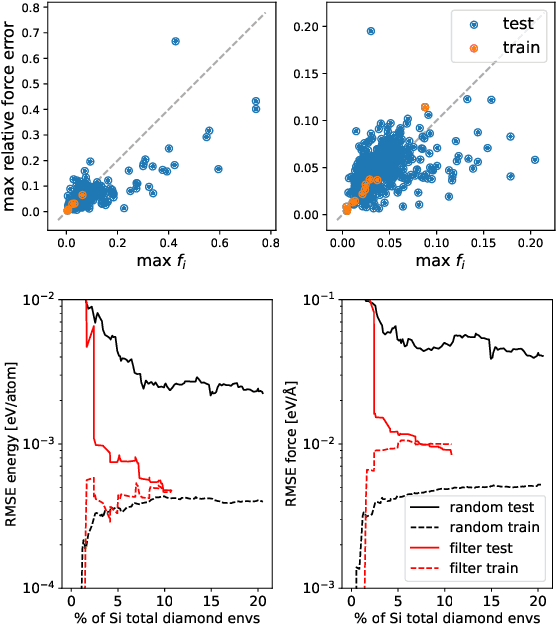
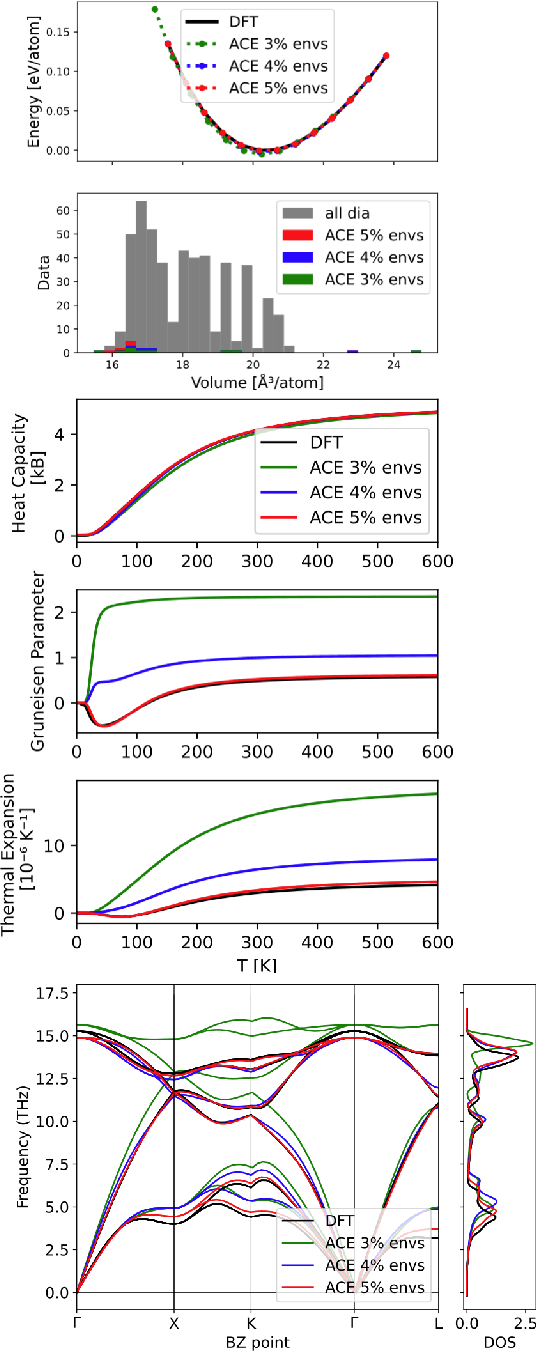
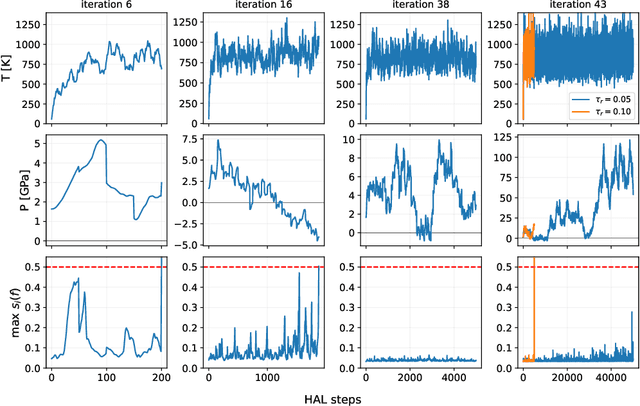
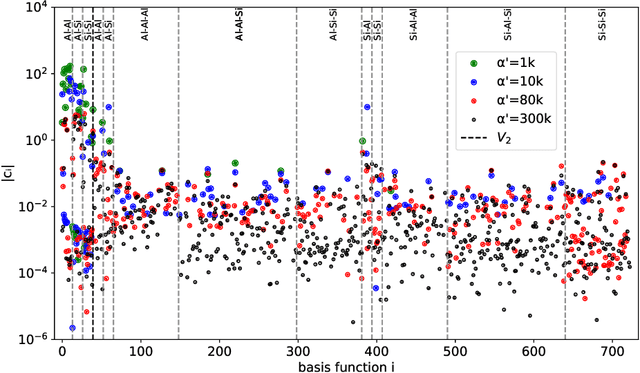
Data-driven interatomic potentials have emerged as a powerful class of surrogate models for ab initio potential energy surfaces that are able to reliably predict macroscopic properties with experimental accuracy. In generating accurate and transferable potentials the most time-consuming and arguably most important task is generating the training set, which still requires significant expert user input. To accelerate this process, this work presents hyperactive learning (HAL), a framework for formulating an accelerated sampling algorithm specifically for the task of training database generation. The overarching idea is to start from a physically motivated sampler (e.g., molecular dynamics) and a biasing term that drives the system towards high uncertainty and thus to unseen training configurations. Building on this framework, general protocols for building training databases for alloys and polymers leveraging the HAL framework will be presented. For alloys, fast (< 100 microsecond/atom/cpu-core) ACE potentials for AlSi10 are created that able to predict the melting temperature with good accuracy by fitting to a minimal HAL-generated database containing 88 configurations (32 atoms each) in 17 seconds using 8 cpu threads. For polymers, a HAL database is built using ACE able to determine the density of a long polyethylene glycol (PEG) polymer formed of 200 monomer units with experimental accuracy by only fitting to small isolated PEG polymers with sizes ranging from 2 to 32.
Super-Resolution by Predicting Offsets: An Ultra-Efficient Super-Resolution Network for Rasterized Images
Oct 09, 2022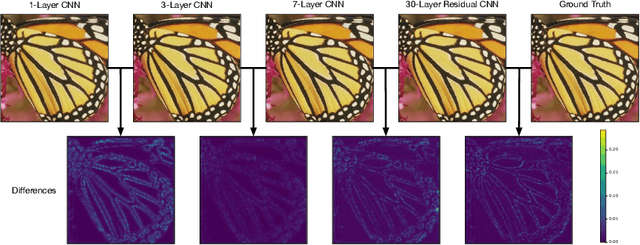
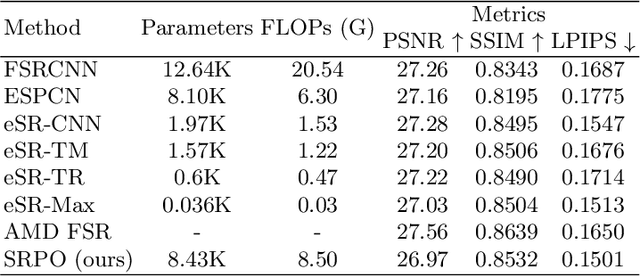
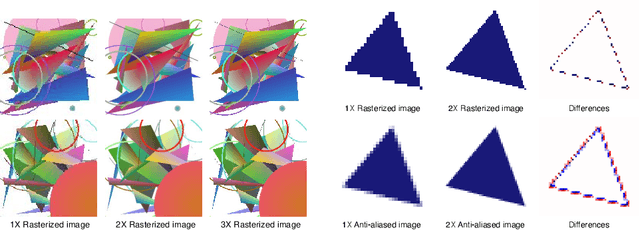
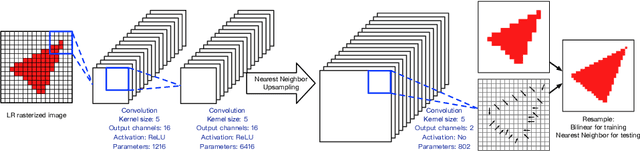
Rendering high-resolution (HR) graphics brings substantial computational costs. Efficient graphics super-resolution (SR) methods may achieve HR rendering with small computing resources and have attracted extensive research interests in industry and research communities. We present a new method for real-time SR for computer graphics, namely Super-Resolution by Predicting Offsets (SRPO). Our algorithm divides the image into two parts for processing, i.e., sharp edges and flatter areas. For edges, different from the previous SR methods that take the anti-aliased images as inputs, our proposed SRPO takes advantage of the characteristics of rasterized images to conduct SR on the rasterized images. To complement the residual between HR and low-resolution (LR) rasterized images, we train an ultra-efficient network to predict the offset maps to move the appropriate surrounding pixels to the new positions. For flat areas, we found simple interpolation methods can already generate reasonable output. We finally use a guided fusion operation to integrate the sharp edges generated by the network and flat areas by the interpolation method to get the final SR image. The proposed network only contains 8,434 parameters and can be accelerated by network quantization. Extensive experiments show that the proposed SRPO can achieve superior visual effects at a smaller computational cost than the existing state-of-the-art methods.
Less is More: Facial Landmarks can Recognize a Spontaneous Smile
Oct 09, 2022
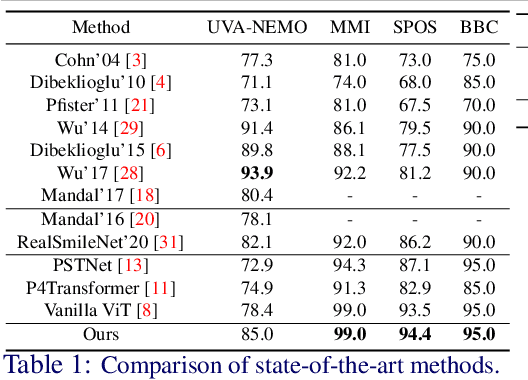
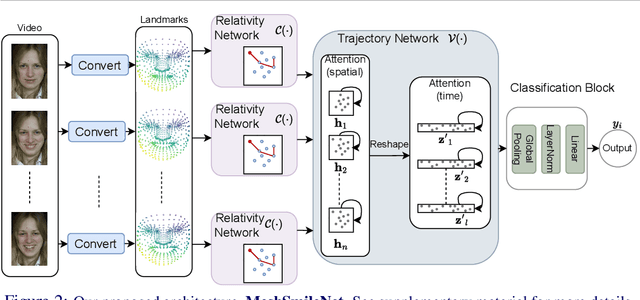
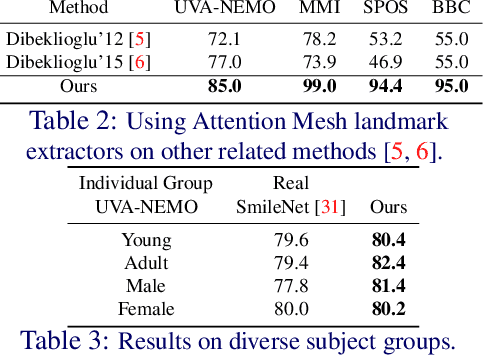
Smile veracity classification is a task of interpreting social interactions. Broadly, it distinguishes between spontaneous and posed smiles. Previous approaches used hand-engineered features from facial landmarks or considered raw smile videos in an end-to-end manner to perform smile classification tasks. Feature-based methods require intervention from human experts on feature engineering and heavy pre-processing steps. On the contrary, raw smile video inputs fed into end-to-end models bring more automation to the process with the cost of considering many redundant facial features (beyond landmark locations) that are mainly irrelevant to smile veracity classification. It remains unclear to establish discriminative features from landmarks in an end-to-end manner. We present a MeshSmileNet framework, a transformer architecture, to address the above limitations. To eliminate redundant facial features, our landmarks input is extracted from Attention Mesh, a pre-trained landmark detector. Again, to discover discriminative features, we consider the relativity and trajectory of the landmarks. For the relativity, we aggregate facial landmark that conceptually formats a curve at each frame to establish local spatial features. For the trajectory, we estimate the movements of landmark composed features across time by self-attention mechanism, which captures pairwise dependency on the trajectory of the same landmark. This idea allows us to achieve state-of-the-art performances on UVA-NEMO, BBC, MMI Facial Expression, and SPOS datasets.