 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sliding-Window Normalization to Improve the Performance of Machine-Learning Models for Real-Time Motion Prediction Using Electromyography
May 19, 2022
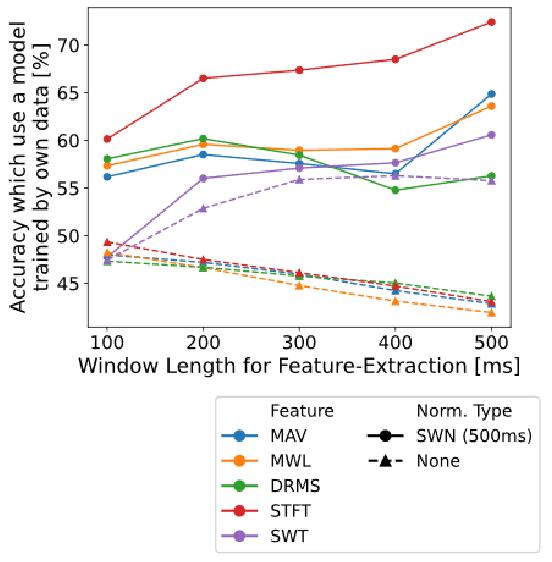
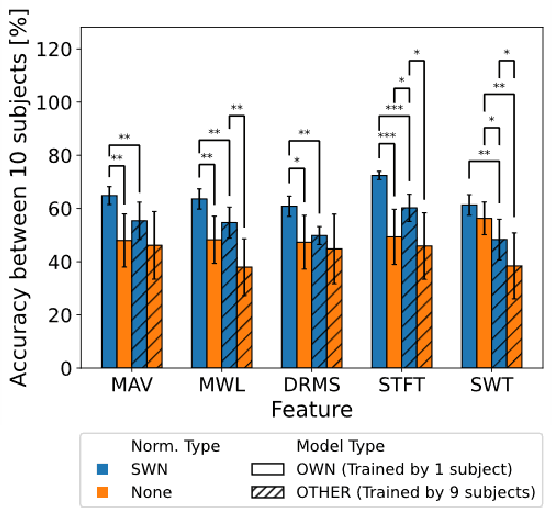
Many researchers have used machine learning models to control artificial hands, walking aids, assistance suits, etc., using the biological signal of electromyography (EMG). The use of such devices requires high classification accuracy of machine learning models. One method for improving the classification performance of machine learning models is normalization, such as z-score. However, normalization is not used in most EMG-based motion prediction studies, because of the need for calibration and fluctuation of reference value for calibration (cannot re-use). Therefore, in this study, we proposed a normalization method that combines sliding-window analysis and z-score normalization, that can be implemented in real-time processing without need for calibration. The effectiveness of this normalization method was confirmed by conducting a single-joint movement experiment of the elbow and predicting its rest, flexion, and extension movements from the EMG signal. The proposed normalization method achieved a mean accuracy of 64.6%, an improvement of 15.0% compared to the non-normalization case (mean of 49.8%). Furthermore, to improve practical applications, recent research has focused on reducing the user data required for model learning and improving classification performance in models learned from other people's data. Therefore, we investigated the classification performance of the model learned from other's data. Results showed a mean accuracy of 56.5% when the proposed method was applied, an improvement of 11.1% compared to the non-normalization case (mean of 44.1%). These two results showed the effectiveness of the simple and easy-to-implement method, and that the classification performance of the machine learning model could be improved.
Evaluating and Crafting Datasets Effective for Deep Learning With Data Maps
Aug 22, 2022
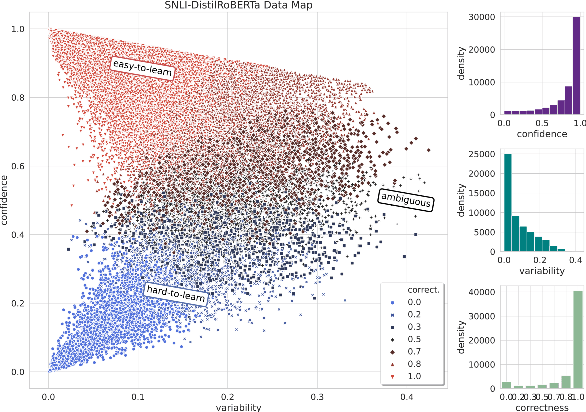
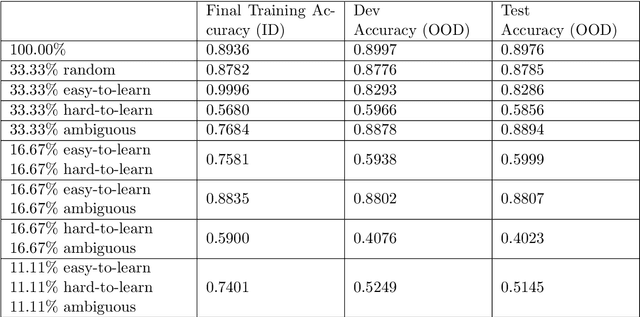
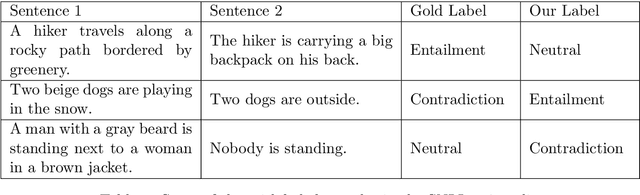
Rapid development in deep learning model construction has prompted an increased need for appropriate training data. The popularity of large datasets - sometimes known as "big data" - has diverted attention from assessing their quality. Training on large datasets often requires excessive system resources and an infeasible amount of time. Furthermore, the supervised machine learning process has yet to be fully automated: for supervised learning, large datasets require more time for manually labeling samples. We propose a method of curating smaller datasets with comparable out-of-distribution model accuracy after an initial training session using an appropriate distribution of samples classified by how difficult it is for a model to learn from them.
Self-organizing nest migration dynamics synthesis for ant colony systems
Oct 08, 2022In this study, we synthesize a novel dynamical approach for ant colonies enabling them to migrate to new nest sites in a self-organizing fashion. In other words, we realize ant colony migration as a self-organizing phenotype-level collective behavior. For this purpose, we first segment the edges of the graph of ants' pathways. Then, each segment, attributed to its own pheromone profile, may host an ant. So, multiple ants may occupy an edge at the same time. Thanks to this segment-wise edge formulation, ants have more selection options in the course of their pathway determination, thereby increasing the diversity of their colony's emergent behaviors. In light of the continuous pheromone dynamics of segments, each edge owns a spatio-temporal piece-wise continuous pheromone profile in which both deposit and evaporation processes are unified. The passive dynamics of the proposed migration mechanism is sufficiently rich so that an ant colony can migrate to the vicinity of a new nest site in a self-organizing manner without any external supervision. In particular, we perform extensive simulations to test our migration dynamics applied to a colony including 500 ants traversing a pathway graph comprising 200 nodes and 4000 edges which are segmented based on various resolutions. The obtained results exhibit the effectiveness of our strategy.
WUDA: Unsupervised Domain Adaptation Based on Weak Source Domain Labels
Oct 05, 2022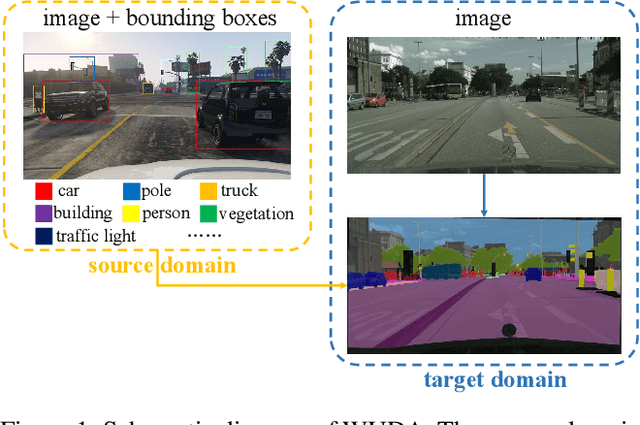

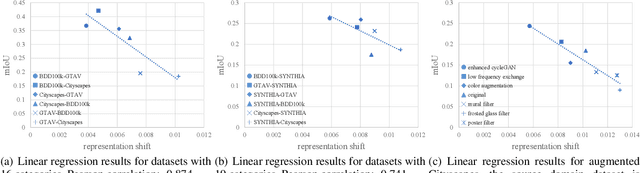
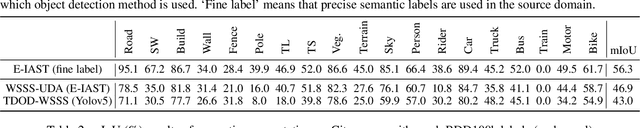
Unsupervised domain adaptation (UDA) for semantic segmentation addresses the cross-domain problem with fine source domain labels. However, the acquisition of semantic labels has always been a difficult step, many scenarios only have weak labels (e.g. bounding boxes). For scenarios where weak supervision and cross-domain problems coexist, this paper defines a new task: unsupervised domain adaptation based on weak source domain labels (WUDA). To explore solutions for this task, this paper proposes two intuitive frameworks: 1) Perform weakly supervised semantic segmentation in the source domain, and then implement unsupervised domain adaptation; 2) Train an object detection model using source domain data, then detect objects in the target domain and implement weakly supervised semantic segmentation. We observe that the two frameworks behave differently when the datasets change. Therefore, we construct dataset pairs with a wide range of domain shifts and conduct extended experiments to analyze the impact of different domain shifts on the two frameworks. In addition, to measure domain shift, we apply the metric representation shift to urban landscape image segmentation for the first time. The source code and constructed datasets are available at \url{https://github.com/bupt-ai-cz/WUDA}.
ToupleGDD: A Fine-Designed Solution of Influence Maximization by Deep Reinforcement Learning
Oct 18, 2022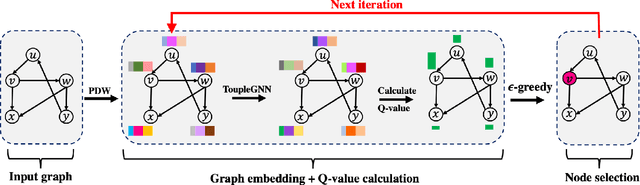
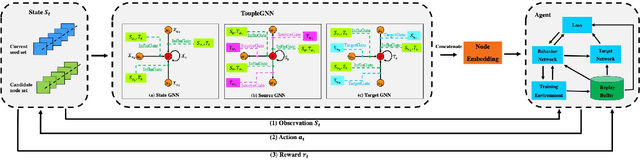
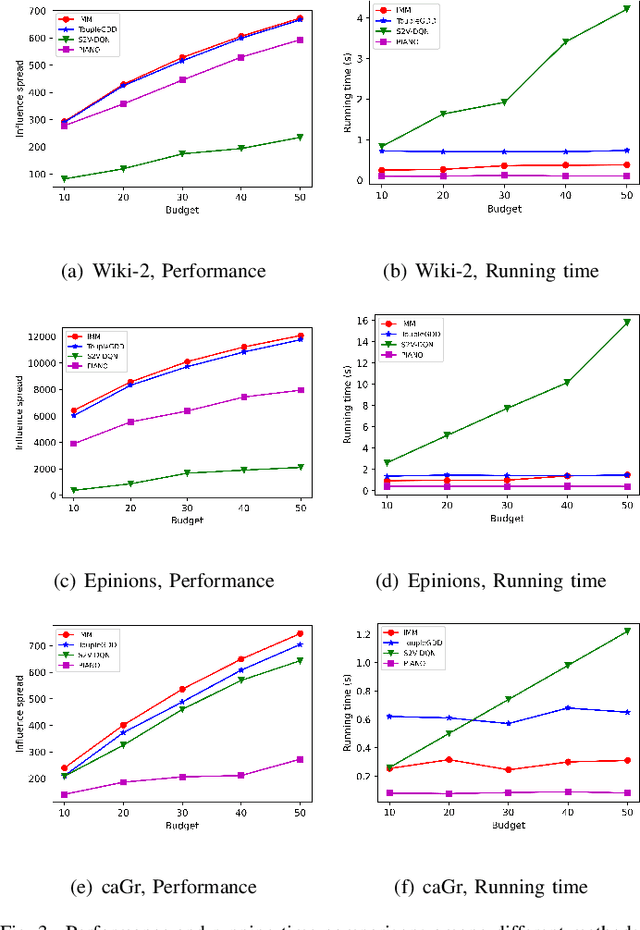
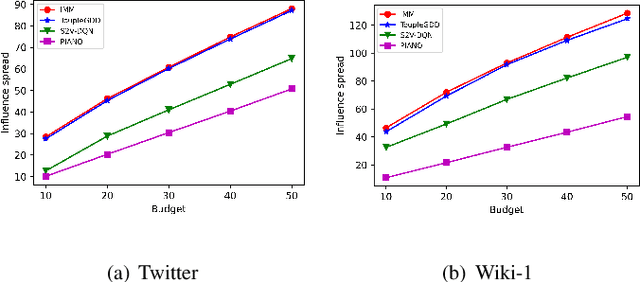
Online social platforms have become more and more popular, and the dissemination of information on social networks has attracted wide attention of the industries and academia. Aiming at selecting a small subset of nodes with maximum influence on networks, the Influence Maximization (IM) problem has been extensively studied. Since it is #P-hard to compute the influence spread given a seed set, the state-of-art methods, including heuristic and approximation algorithms, faced with great difficulties such as theoretical guarantee, time efficiency, generalization, etc. This makes it unable to adapt to large-scale networks and more complex applications. With the latest achievements of Deep Reinforcement Learning (DRL) in artificial intelligence and other fields, a lot of works has focused on exploiting DRL to solve the combinatorial optimization problems. Inspired by this, we propose a novel end-to-end DRL framework, ToupleGDD, to address the IM problem in this paper, which incorporates three coupled graph neural networks for network embedding and double deep Q-networks for parameters learning. Previous efforts to solve the IM problem with DRL trained their models on the subgraph of the whole network, and then tested their performance on the whole graph, which makes the performance of their models unstable among different networks. However, our model is trained on several small randomly generated graphs and tested on completely different networks, and can obtain results that are very close to the state-of-the-art methods. In addition, our model is trained with a small budget, and it can perform well under various large budgets in the test, showing strong generalization ability. Finally, we conduct entensive experiments on synthetic and realistic datasets, and the experimental results prove the effectiveness and superiority of our model.
A multi view multi stage and multi window framework for pulmonary artery segmentation from CT scans
Sep 14, 2022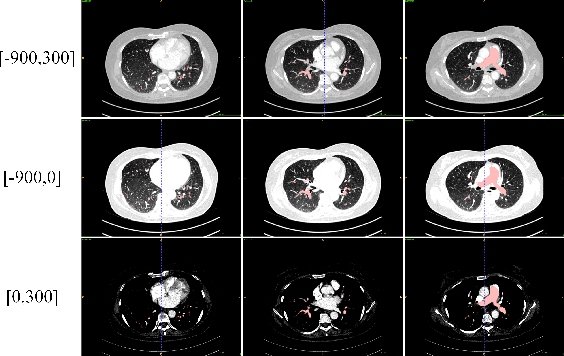

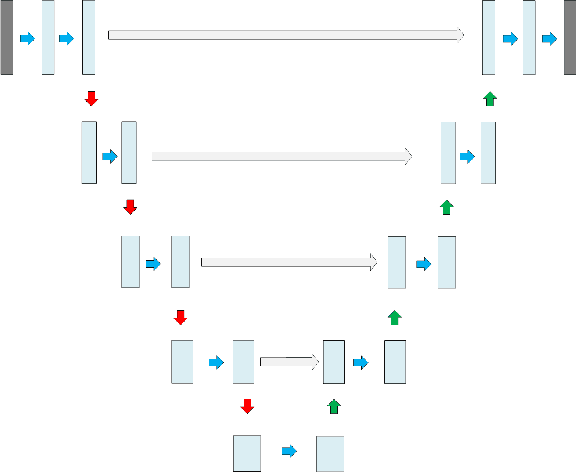

This is the technical report of the 9th place in the final result of PARSE2022 Challenge. We solve the segmentation problem of the pulmonary artery by using a two-stage method based on a 3D CNN network. The coarse model is used to locate the ROI, and the fine model is used to refine the segmentation result. In addition, in order to improve the segmentation performance, we adopt multi-view and multi-window level method, at the same time we employ a fine-tune strategy to mitigate the impact of inconsistent labeling.
A Cooperative Positioning Flamework for Robot and Smart Phone Based on Visible Light Communication
Aug 25, 2022A cooperative positioning flamework of human and robots based on visible light communication (VLC) is proposed. Based on the experiment system, we demonstrated it has high accuracy and real-time performance.
Bayesian Statistical Model Checking for Multi-agent Systems using HyperPCTL*
Sep 06, 2022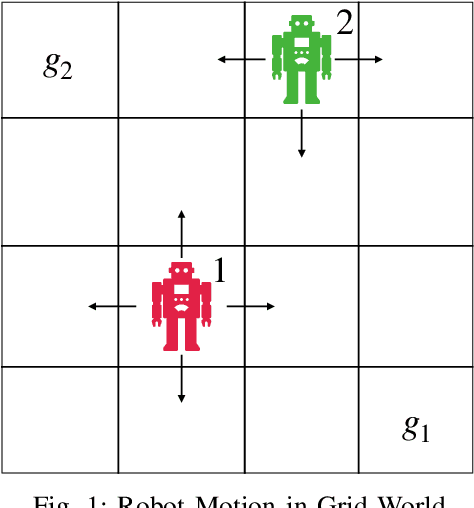
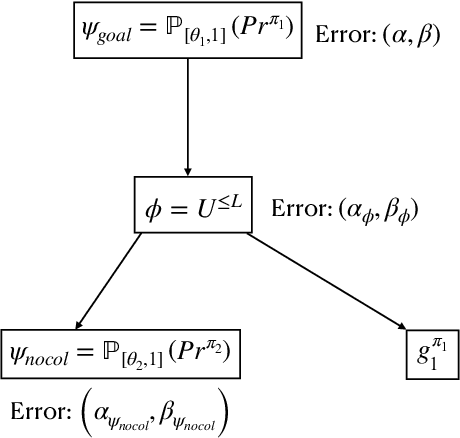

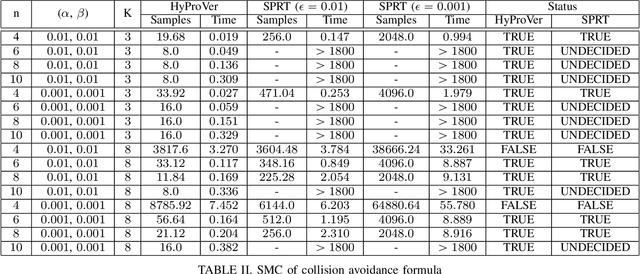
In this paper, we present a Bayesian method for statistical model checking (SMC) of probabilistic hyperproperties specified in the logic HyperPCTL* on discrete-time Markov chains (DTMCs). While SMC of HyperPCTL* using sequential probability ratio test (SPRT) has been explored before, we develop an alternative SMC algorithm based on Bayesian hypothesis testing. In comparison to PCTL*, verifying HyperPCTL* formulae is complex owing to their simultaneous interpretation on multiple paths of the DTMC. In addition, extending the bottom-up model-checking algorithm of the non-probabilistic setting is not straight forward due to the fact that SMC does not return exact answers to the satisfiability problems of subformulae, instead, it only returns correct answers with high-confidence. We propose a recursive algorithm for SMC of HyperPCTL* based on a modified Bayes' test that factors in the uncertainty in the recursive satisfiability results. We have implemented our algorithm in a Python toolbox, HyProVer, and compared our approach with the SPRT based SMC. Our experimental evaluation demonstrates that our Bayesian SMC algorithm performs better both in terms of the verification time and the number of samples required to deduce satisfiability of a given HyperPCTL* formula.
TempoWiC: An Evaluation Benchmark for Detecting Meaning Shift in Social Media
Sep 16, 2022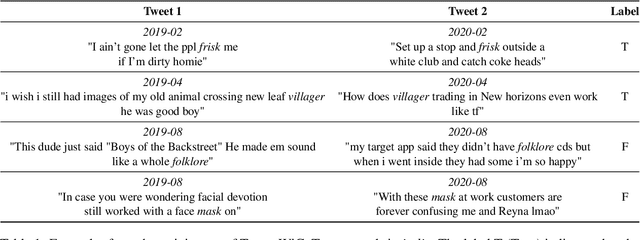
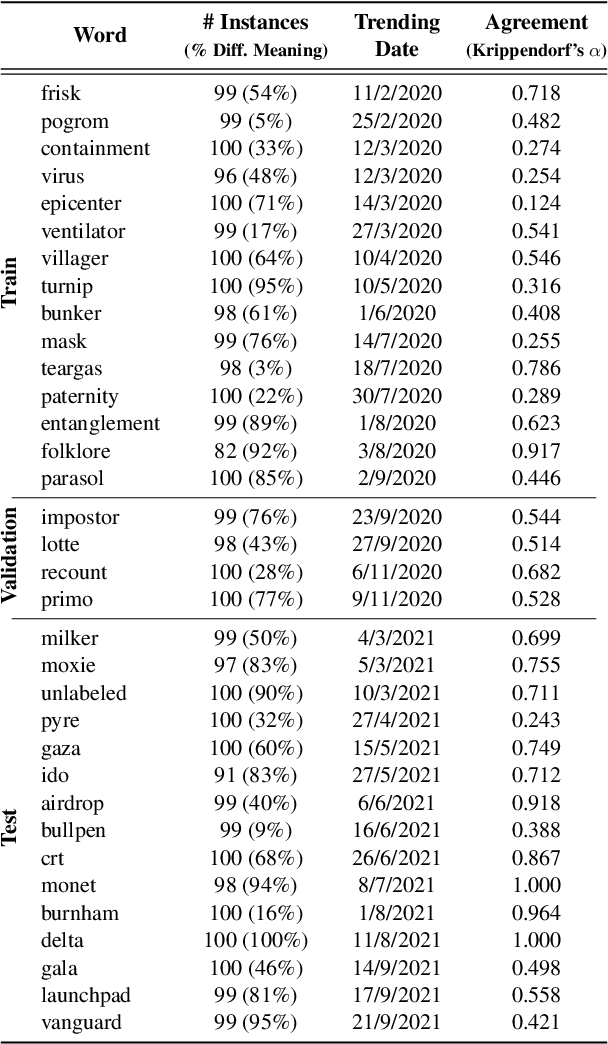
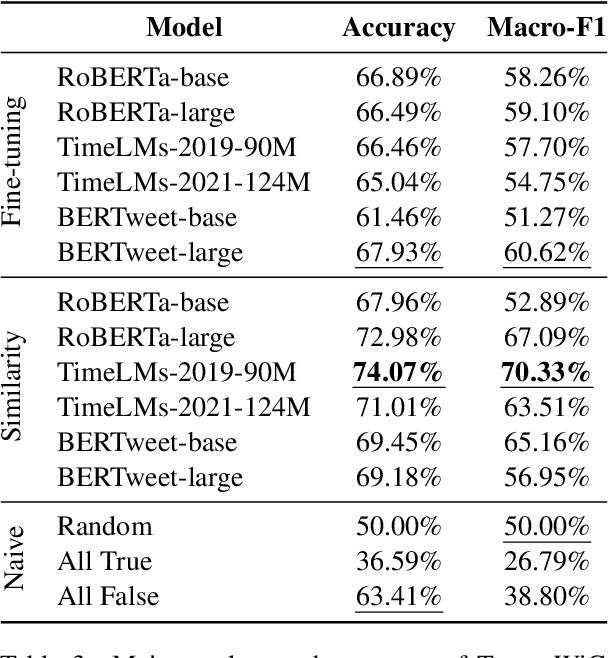
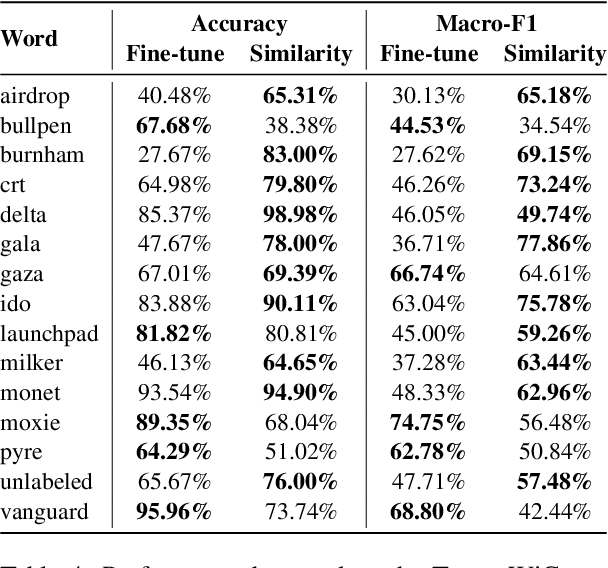
Language evolves over time, and word meaning changes accordingly. This is especially true in social media, since its dynamic nature leads to faster semantic shifts, making it challenging for NLP models to deal with new content and trends. However, the number of datasets and models that specifically address the dynamic nature of these social platforms is scarce. To bridge this gap, we present TempoWiC, a new benchmark especially aimed at accelerating research in social media-based meaning shift. Our results show that TempoWiC is a challenging benchmark, even for recently-released language models specialized in social media.
Mega: Moving Average Equipped Gated Attention
Sep 26, 2022
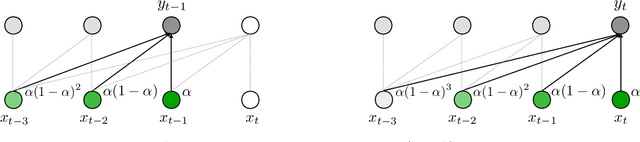
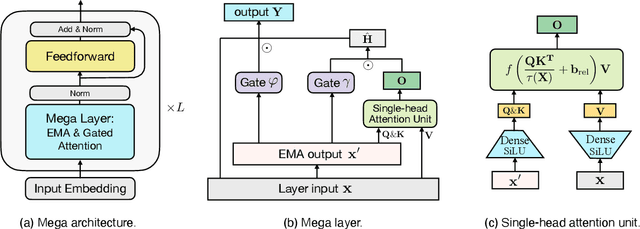
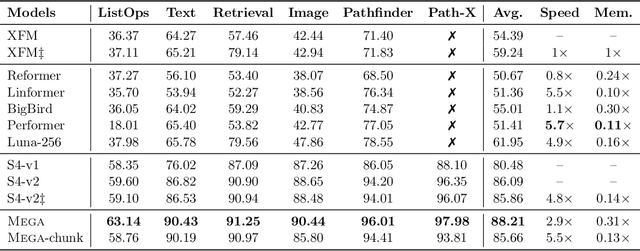
The design choices in the Transformer attention mechanism, including weak inductive bias and quadratic computational complexity, have limited its application for modeling long sequences. In this paper, we introduce Mega, a simple, theoretically grounded, single-head gated attention mechanism equipped with (exponential) moving average to incorporate inductive bias of position-aware local dependencies into the position-agnostic attention mechanism. We further propose a variant of Mega that offers linear time and space complexity yet yields only minimal quality loss, by efficiently splitting the whole sequence into multiple chunks with fixed length. Extensive experiments on a wide range of sequence modeling benchmarks, including the Long Range Arena, neural machine translation, auto-regressive language modeling, and image and speech classification, show that Mega achieves significant improvements over other sequence models, including variants of Transformers and recent state space models.