 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Object Recognition in Different Lighting Conditions at Various Angles by Deep Learning Method
Oct 18, 2022
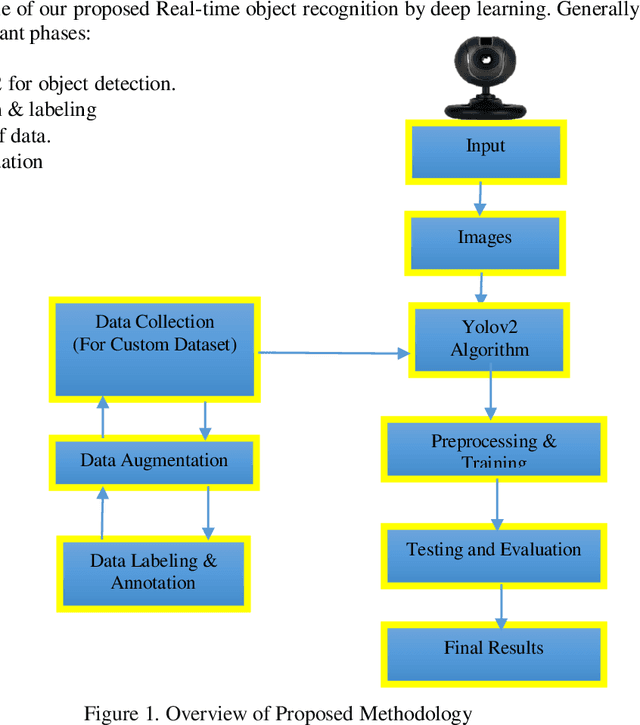
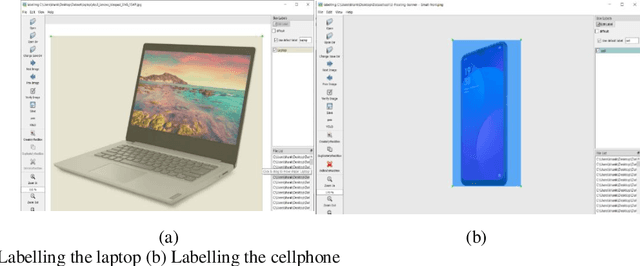
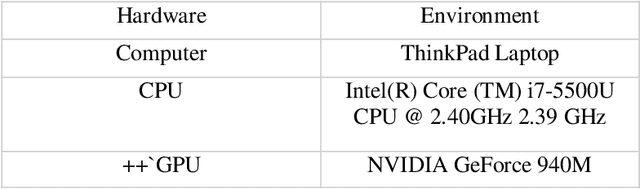
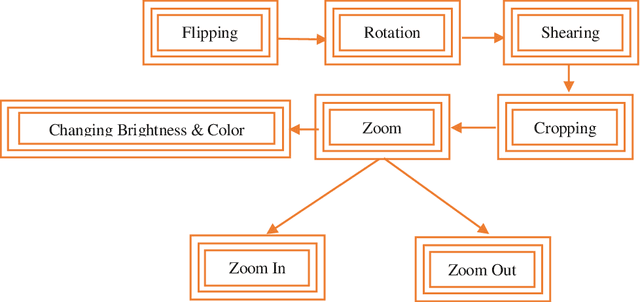
Existing computer vision and object detection methods strongly rely on neural networks and deep learning. This active research area is used for applications such as autonomous driving, aerial photography, protection, and monitoring. Futuristic object detection methods rely on rectangular, boundary boxes drawn over an object to accurately locate its location. The modern object recognition algorithms, however, are vulnerable to multiple factors, such as illumination, occlusion, viewing angle, or camera rotation as well as cost. Therefore, deep learning-based object recognition will significantly increase the recognition speed and compatible external interference. In this study, we use convolutional neural networks (CNN) to recognize items, the neural networks have the advantages of end-to-end, sparse relation, and sharing weights. This article aims to classify the name of the various object based on the position of an object's detected box. Instead, under different distances, we can get recognition results with different confidence. Through this study, we find that this model's accuracy through recognition is mainly influenced by the proportion of objects and the number of samples. When we have a small proportion of an object on camera, then we get higher recognition accuracy; if we have a much small number of samples, we can get greater accuracy in recognition. The epidemic has a great impact on the world economy where designing a cheaper object recognition system is the need of time.
Over-the-Air Gaussian Process Regression Based on Product of Experts
Oct 06, 2022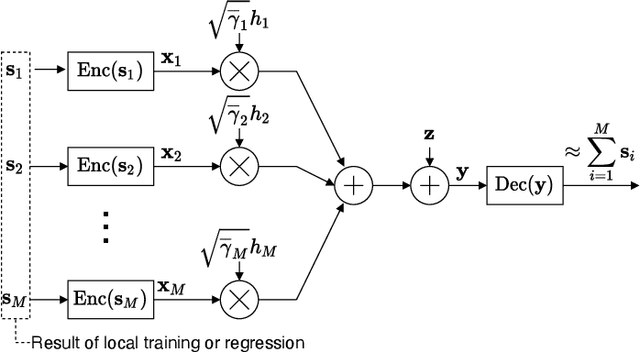
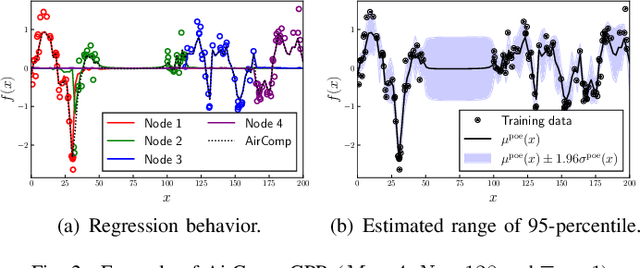
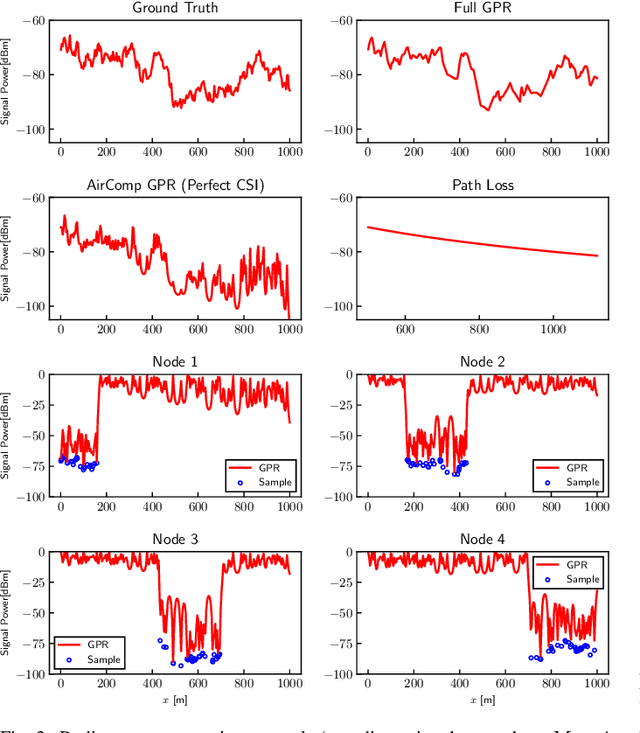
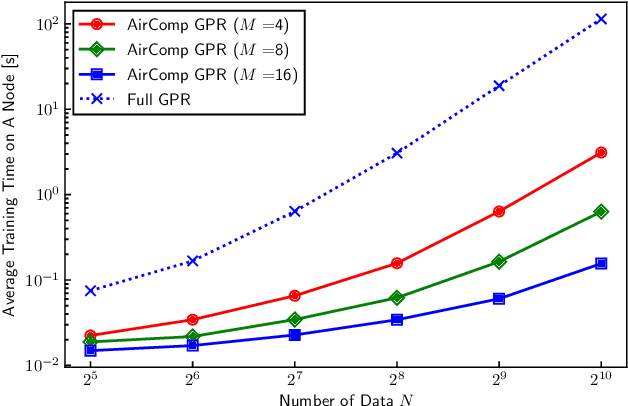
This paper proposes a distributed Gaussian process regression (GPR) with over-the-air computation, termed AirComp GPR, for communication- and computation-efficient data analysis over wireless networks. GPR is a non-parametric regression method that can model the target flexibly. However, its computational complexity and communication efficiency tend to be significant as the number of data increases. AirComp GPR focuses on that product-of-experts-based GPR approximates the exact GPR by a sum of values reported from distributed nodes. We introduce AirComp for the training and prediction steps to allow the nodes to transmit their local computation results simultaneously; the communication strategies are presented, including distributed training based on perfect and statistical channel state information cases. Applying to a radio map construction task, we demonstrate that AirComp GPR speeds up the computation time while maintaining the communication cost in training constant regardless of the numbers of data and nodes.
Knowing Where to Look: A Planning-based Architecture to Automate the Gaze Behavior of Social Robots
Oct 06, 2022
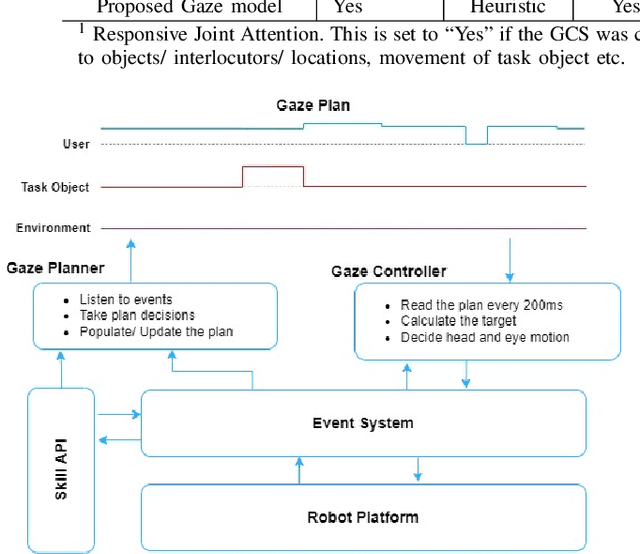
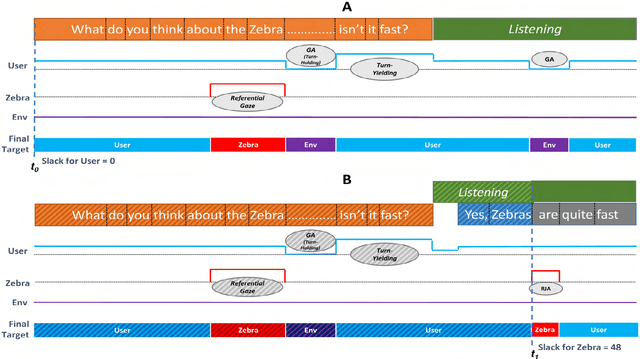
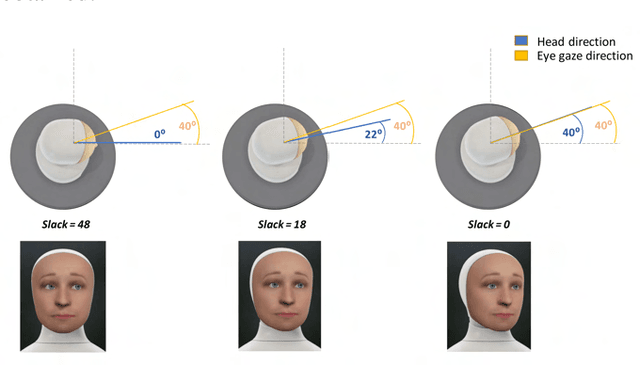
Gaze cues play an important role in human communication and are used to coordinate turn-taking and joint attention, as well as to regulate intimacy. In order to have fluent conversations with people, social robots need to exhibit human-like gaze behavior. Previous Gaze Control Systems (GCS) in HRI have automated robot gaze using data-driven or heuristic approaches. However, these systems tend to be mainly reactive in nature. Planning the robot gaze ahead of time could help in achieving more realistic gaze behavior and better eye-head coordination. In this paper, we propose and implement a novel planning-based GCS. We evaluate our system in a comparative within-subjects user study (N=26) between a reactive system and our proposed system. The results show that the users preferred the proposed system and that it was significantly more interpretable and better at regulating intimacy.
Multi-head Temporal Attention-Augmented Bilinear Network for Financial time series prediction
Jan 14, 2022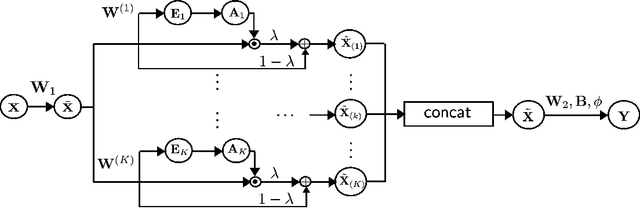
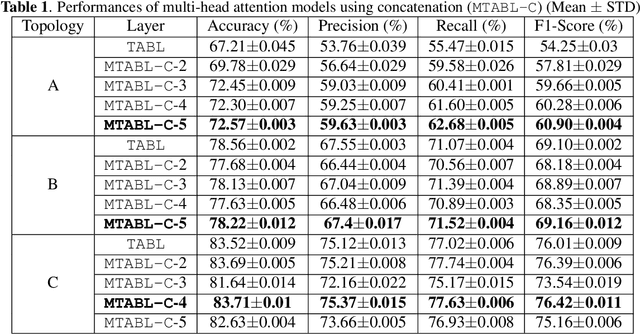
Financial time-series forecasting is one of the most challenging domains in the field of time-series analysis. This is mostly due to the highly non-stationary and noisy nature of financial time-series data. With progressive efforts of the community to design specialized neural networks incorporating prior domain knowledge, many financial analysis and forecasting problems have been successfully tackled. The temporal attention mechanism is a neural layer design that recently gained popularity due to its ability to focus on important temporal events. In this paper, we propose a neural layer based on the ideas of temporal attention and multi-head attention to extend the capability of the underlying neural network in focusing simultaneously on multiple temporal instances. The effectiveness of our approach is validated using large-scale limit-order book market data to forecast the direction of mid-price movements. Our experiments show that the use of multi-head temporal attention modules leads to enhanced prediction performances compared to baseline models.
Learning Temporal Point Processes for Efficient Retrieval of Continuous Time Event Sequences
Feb 17, 2022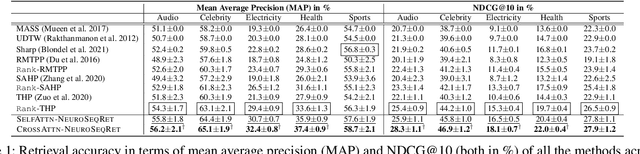

Recent developments in predictive modeling using marked temporal point processes (MTPP) have enabled an accurate characterization of several real-world applications involving continuous-time event sequences (CTESs). However, the retrieval problem of such sequences remains largely unaddressed in literature. To tackle this, we propose NEUROSEQRET which learns to retrieve and rank a relevant set of continuous-time event sequences for a given query sequence, from a large corpus of sequences. More specifically, NEUROSEQRET first applies a trainable unwarping function on the query sequence, which makes it comparable with corpus sequences, especially when a relevant query-corpus pair has individually different attributes. Next, it feeds the unwarped query sequence and the corpus sequence into MTPP guided neural relevance models. We develop two variants of the relevance model which offer a tradeoff between accuracy and efficiency. We also propose an optimization framework to learn binary sequence embeddings from the relevance scores, suitable for the locality-sensitive hashing leading to a significant speedup in returning top-K results for a given query sequence. Our experiments with several datasets show the significant accuracy boost of NEUROSEQRET beyond several baselines, as well as the efficacy of our hashing mechanism.
VIBUS: Data-efficient 3D Scene Parsing with VIewpoint Bottleneck and Uncertainty-Spectrum Modeling
Oct 20, 2022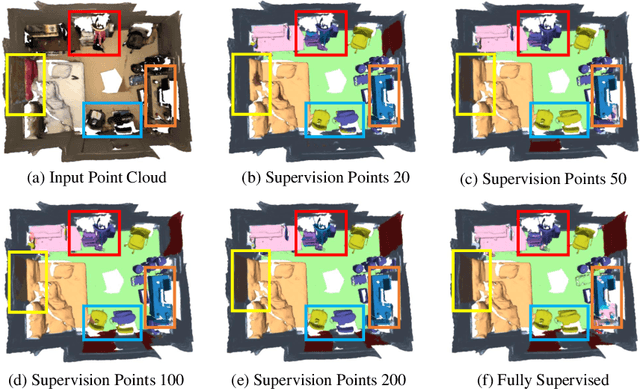
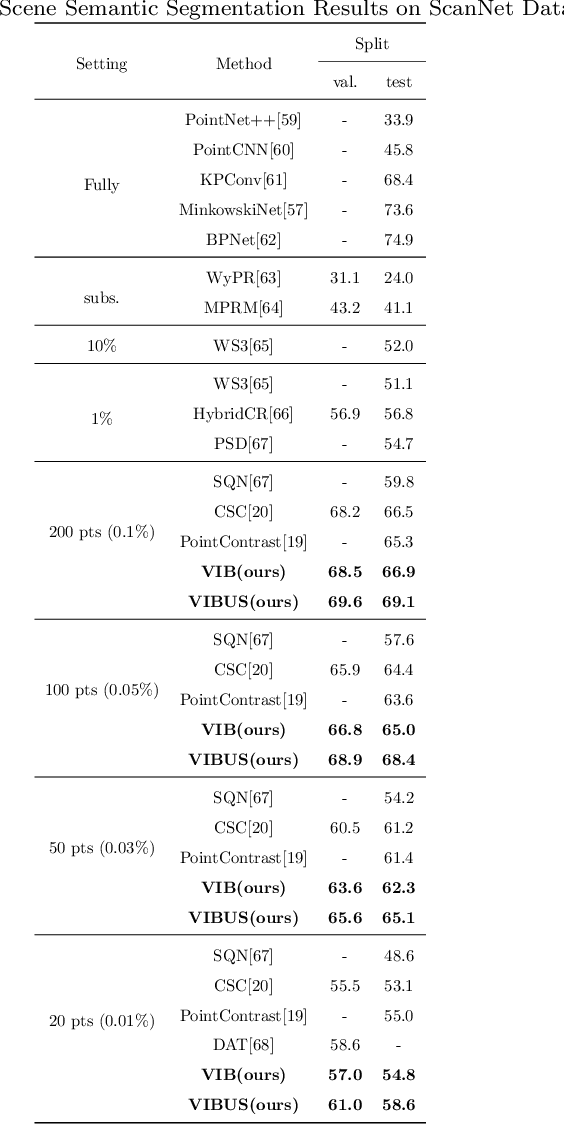
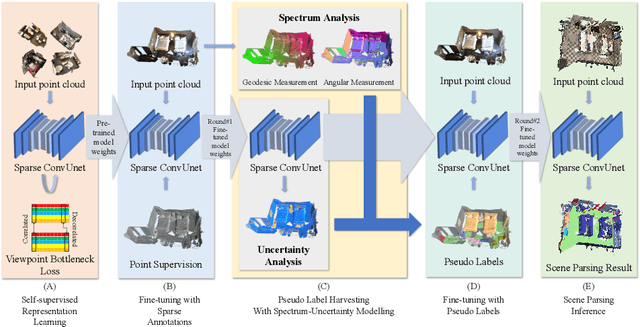
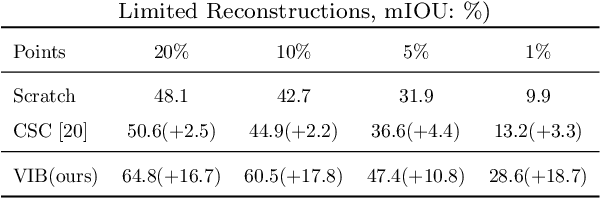
Recently, 3D scenes parsing with deep learning approaches has been a heating topic. However, current methods with fully-supervised models require manually annotated point-wise supervision which is extremely user-unfriendly and time-consuming to obtain. As such, training 3D scene parsing models with sparse supervision is an intriguing alternative. We term this task as data-efficient 3D scene parsing and propose an effective two-stage framework named VIBUS to resolve it by exploiting the enormous unlabeled points. In the first stage, we perform self-supervised representation learning on unlabeled points with the proposed Viewpoint Bottleneck loss function. The loss function is derived from an information bottleneck objective imposed on scenes under different viewpoints, making the process of representation learning free of degradation and sampling. In the second stage, pseudo labels are harvested from the sparse labels based on uncertainty-spectrum modeling. By combining data-driven uncertainty measures and 3D mesh spectrum measures (derived from normal directions and geodesic distances), a robust local affinity metric is obtained. Finite gamma/beta mixture models are used to decompose category-wise distributions of these measures, leading to automatic selection of thresholds. We evaluate VIBUS on the public benchmark ScanNet and achieve state-of-the-art results on both validation set and online test server. Ablation studies show that both Viewpoint Bottleneck and uncertainty-spectrum modeling bring significant improvements. Codes and models are publicly available at https://github.com/AIR-DISCOVER/VIBUS.
Cyclical Self-Supervision for Semi-Supervised Ejection Fraction Prediction from Echocardiogram Videos
Oct 20, 2022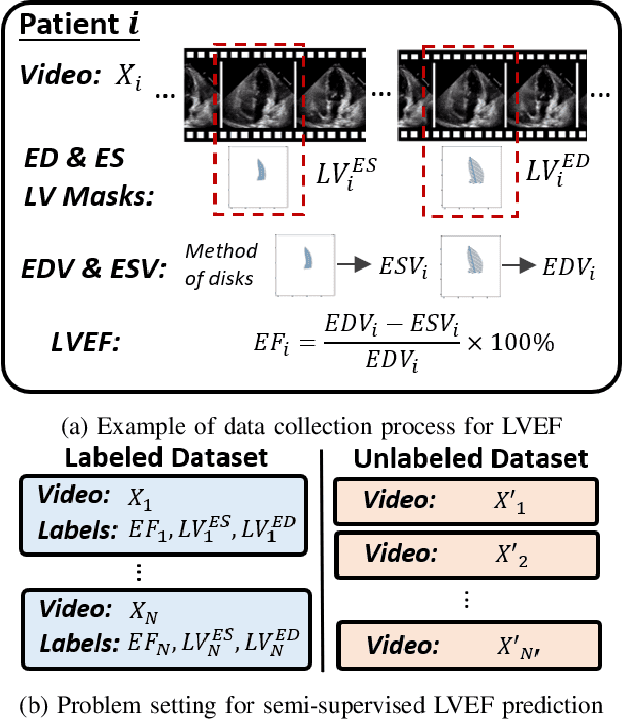
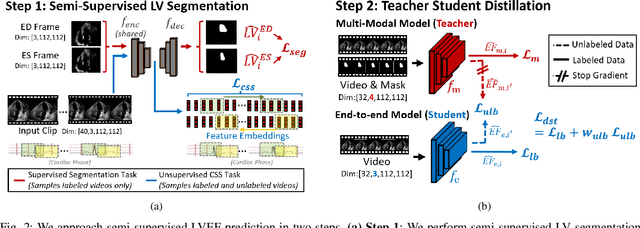
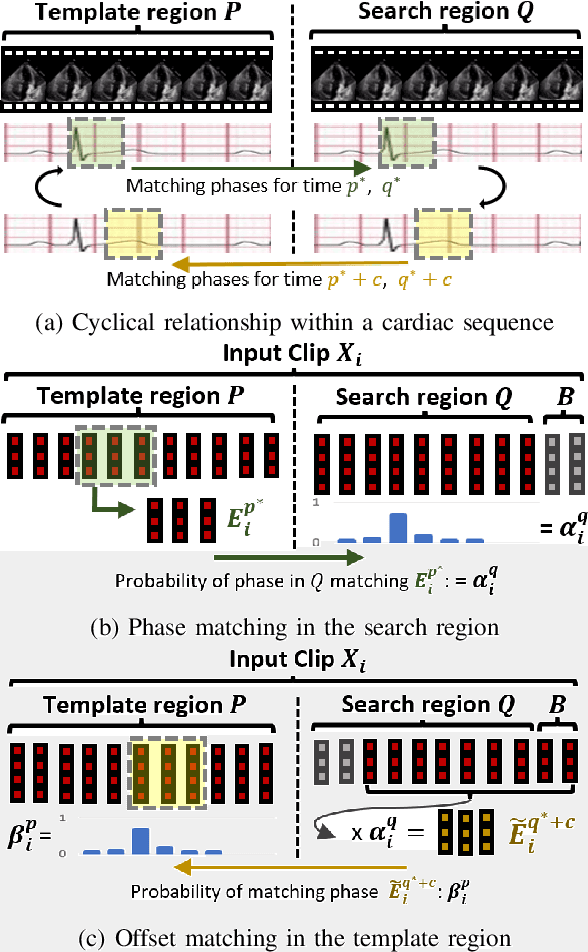
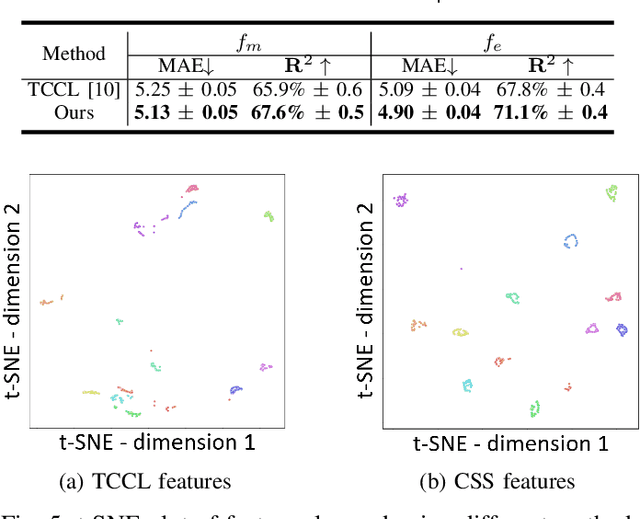
Left-ventricular ejection fraction (LVEF) is an important indicator of heart failure. Existing methods for LVEF estimation from video require large amounts of annotated data to achieve high performance, e.g. using 10,030 labeled echocardiogram videos to achieve mean absolute error (MAE) of 4.10. Labeling these videos is time-consuming however and limits potential downstream applications to other heart diseases. This paper presents the first semi-supervised approach for LVEF prediction. Unlike general video prediction tasks, LVEF prediction is specifically related to changes in the left ventricle (LV) in echocardiogram videos. By incorporating knowledge learned from predicting LV segmentations into LVEF regression, we can provide additional context to the model for better predictions. To this end, we propose a novel Cyclical Self-Supervision (CSS) method for learning video-based LV segmentation, which is motivated by the observation that the heartbeat is a cyclical process with temporal repetition. Prediction masks from our segmentation model can then be used as additional input for LVEF regression to provide spatial context for the LV region. We also introduce teacher-student distillation to distill the information from LV segmentation masks into an end-to-end LVEF regression model that only requires video inputs. Results show our method outperforms alternative semi-supervised methods and can achieve MAE of 4.17, which is competitive with state-of-the-art supervised performance, using half the number of labels. Validation on an external dataset also shows improved generalization ability from using our method.
YOWO-Plus: An Incremental Improvement
Oct 20, 2022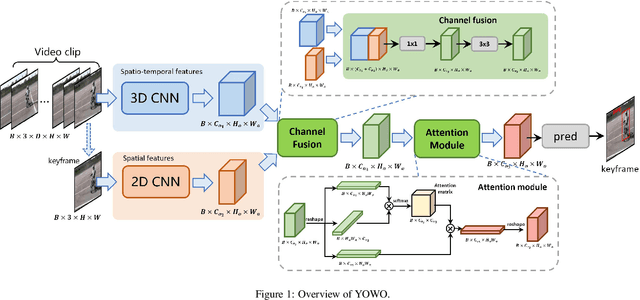
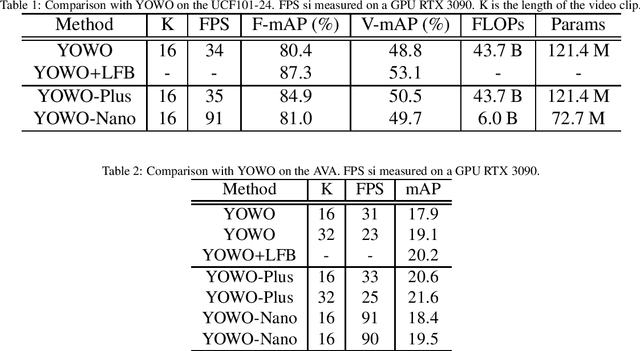
In this technical report, we would like to introduce our updates to YOWO, a real-time method for spatio-temporal action detection. We make a bunch of little design changes to make it better. For network structure, we use the same ones of official implemented YOWO, including 3D-ResNext-101 and YOLOv2, but we use a better pretrained weight of our reimplemented YOLOv2, which is better than the official YOLOv2. We also optimize the label assignment used in YOWO. To accurately detection action instances, we deploy GIoU loss for box regression. After our incremental improvement, YOWO achieves 84.9\% frame mAP and 50.5\% video mAP on the UCF101-24, significantly higher than the official YOWO. On the AVA, our optimized YOWO achieves 20.6\% frame mAP with 16 frames, also exceeding the official YOWO. With 32 frames, our YOWO achieves 21.6 frame mAP with 25 FPS on an RTX 3090 GPU. We name the optimized YOWO as YOWO-Plus. Moreover, we replace the 3D-ResNext-101 with the efficient 3D-ShuffleNet-v2 to design a lightweight action detector, YOWO-Nano. YOWO-Nano achieves 81.0 \% frame mAP and 49.7\% video frame mAP with over 90 FPS on the UCF101-24. It also achieves 18.4 \% frame mAP with about 90 FPS on the AVA. As far as we know, YOWO-Nano is the fastest state-of-the-art action detector. Our code is available on https://github.com/yjh0410/PyTorch_YOWO.
Identifying Causal Effects using Instrumental Time Series: Nuisance IV and Correcting for the Past
Mar 11, 2022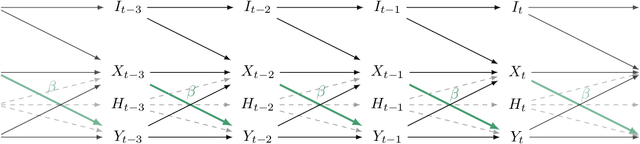
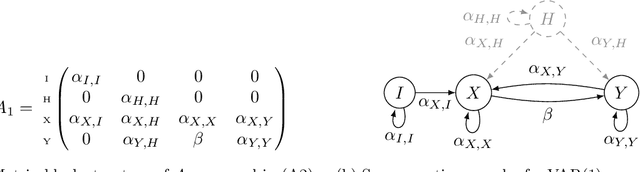
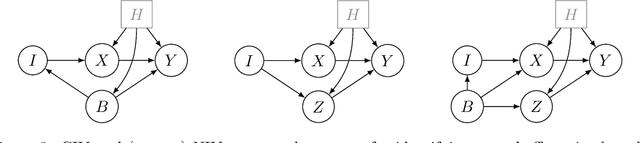
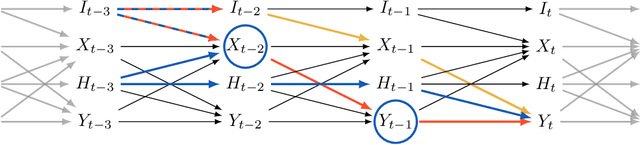
Instrumental variable (IV) regression relies on instruments to infer causal effects from observational data with unobserved confounding. We consider IV regression in time series models, such as vector auto-regressive (VAR) processes. Direct applications of i.i.d. techniques are generally inconsistent as they do not correctly adjust for dependencies in the past. In this paper, we propose methodology for constructing identifying equations that can be used for consistently estimating causal effects. To do so, we develop nuisance IV, which can be of interest even in the i.i.d. case, as it generalizes existing IV methods. We further propose a graph marginalization framework that allows us to apply nuisance and other IV methods in a principled way to time series. Our framework builds on the global Markov property, which we prove holds for VAR processes. For VAR(1) processes, we prove identifiability conditions that relate to Jordan forms and are different from the well-known rank conditions in the i.i.d. case (they do not require as many instruments as covariates, for example). We provide methods, prove their consistency, and show how the inferred causal effect can be used for distribution generalization. Simulation experiments corroborate our theoretical results. We provide ready-to-use Python code.
Inductive Logical Query Answering in Knowledge Graphs
Oct 13, 2022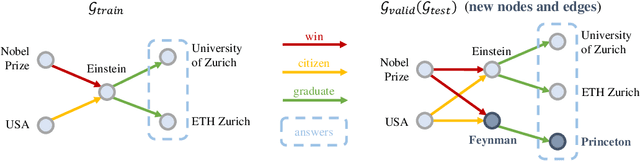
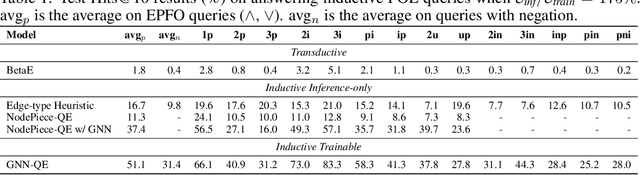
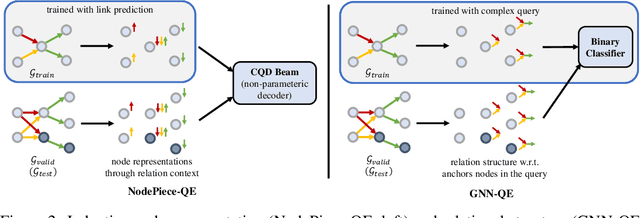

Formulating and answering logical queries is a standard communication interface for knowledge graphs (KGs). Alleviating the notorious incompleteness of real-world KGs, neural methods achieved impressive results in link prediction and complex query answering tasks by learning representations of entities, relations, and queries. Still, most existing query answering methods rely on transductive entity embeddings and cannot generalize to KGs containing new entities without retraining the entity embeddings. In this work, we study the inductive query answering task where inference is performed on a graph containing new entities with queries over both seen and unseen entities. To this end, we devise two mechanisms leveraging inductive node and relational structure representations powered by graph neural networks (GNNs). Experimentally, we show that inductive models are able to perform logical reasoning at inference time over unseen nodes generalizing to graphs up to 500% larger than training ones. Exploring the efficiency--effectiveness trade-off, we find the inductive relational structure representation method generally achieves higher performance, while the inductive node representation method is able to answer complex queries in the inference-only regime without any training on queries and scales to graphs of millions of nodes. Code is available at https://github.com/DeepGraphLearning/InductiveQE.