 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Generalization of the Shortest Path Problem to Graphs with Multiple Edge-Cost Estimates
Aug 22, 2022
The shortest path problem in graphs is a cornerstone for both theory and applications. Existing work accounts for edge weight access time, but generally ignores edge weight computation time. In this paper we present a generalized framework for weighted directed graphs, where each edge cost can be dynamically estimated by multiple estimators, that offer different cost bounds and run-times. This raises several generalized shortest path problems, that optimize different aspects of path cost while requiring guarantees on cost uncertainty, providing a better basis for modeling realistic problems. We present complete, anytime algorithms for solving these problems, and provide guarantees on the solution quality.
Simple HF antenna efficiency comparisons using the WSPR system
Sep 19, 2022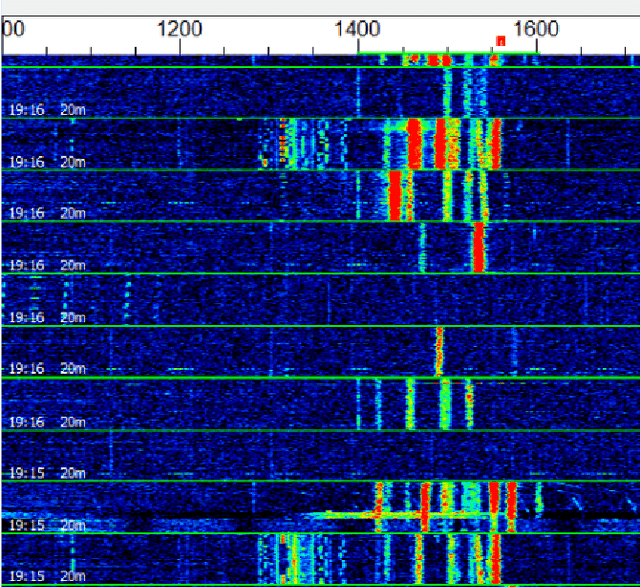
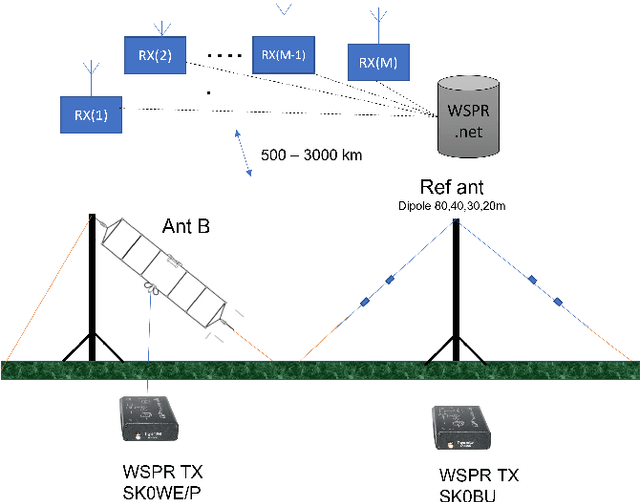

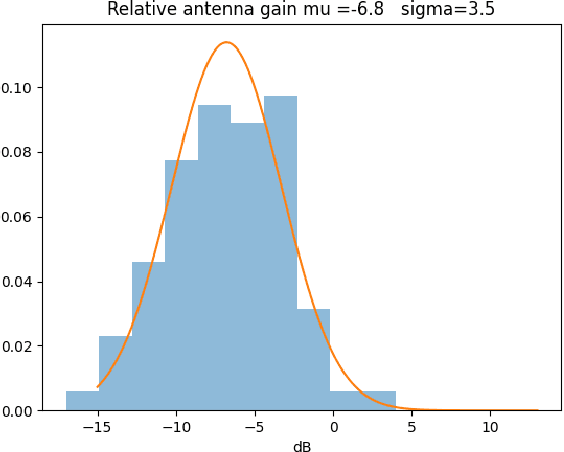
Determining the efficiency of an HF-antenna by measurements requires is a complex procedure involving expensive equipment, calibrated instruments for field strengths. In this paper we evaluate a simple, inexpensive method to determine the relative efficiency of an antenna relative a reference antenna. The method uses the Weak Signal Propagation Reporter(WSPR) network of receivers that are located all over the world. These receivers report the estimated signal-to-noise ratio of received beacon signals to the WSPR.net database where the data can be retrieved (almost) in real time. In the paper we analyze the method, estimate its accuracy and discuss advantages and limitations. Some preliminary measurement results are presented.
Controller Synthesis for Timeline-based Games
Sep 21, 2022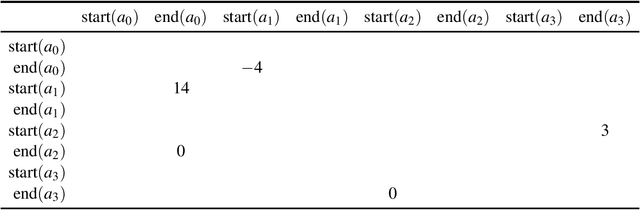
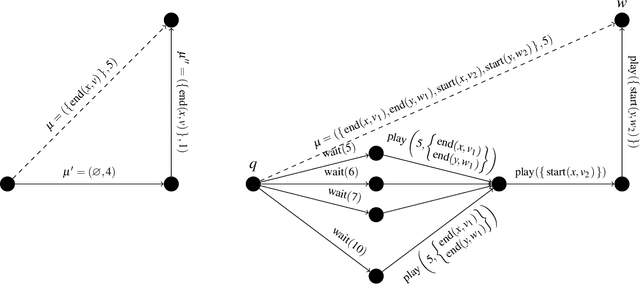
In the timeline-based approach to planning, originally born in the space sector, the evolution over time of a set of state variables (the timelines) is governed by a set of temporal constraints. Traditional timeline-based planning systems excel at the integration of planning with execution by handling temporal uncertainty. In order to handle general nondeterminism as well, the concept of timeline-based games has been recently introduced. It has been proved that finding whether a winning strategy exists for such games is 2EXPTIME-complete. However, a concrete approach to synthesize controllers implementing such strategies is missing. This paper fills this gap, outlining an approach to controller synthesis for timeline-based games.
* In Proceedings GandALF 2022, arXiv:2209.09333
Fault Signature Identification for BLDC motor Drive System -A Statistical Signal Fusion Approach
Sep 07, 2022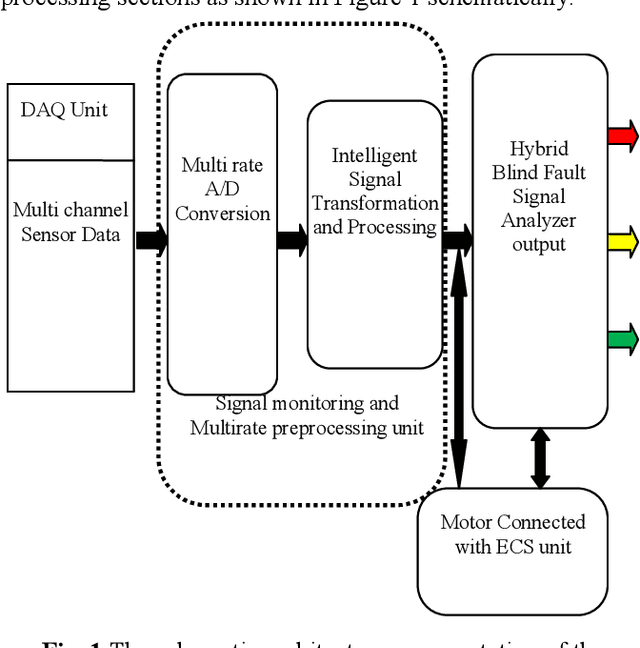
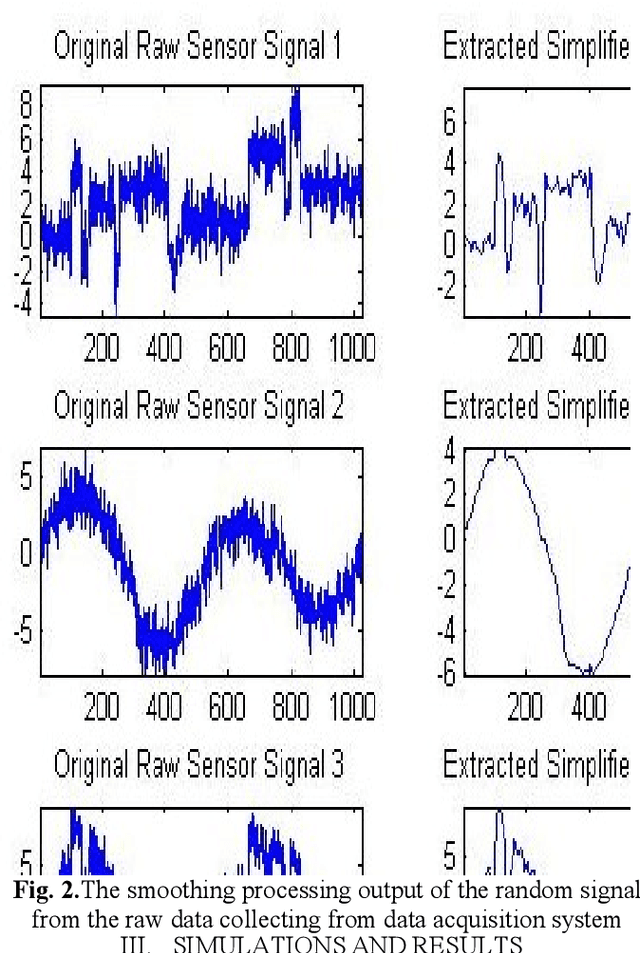
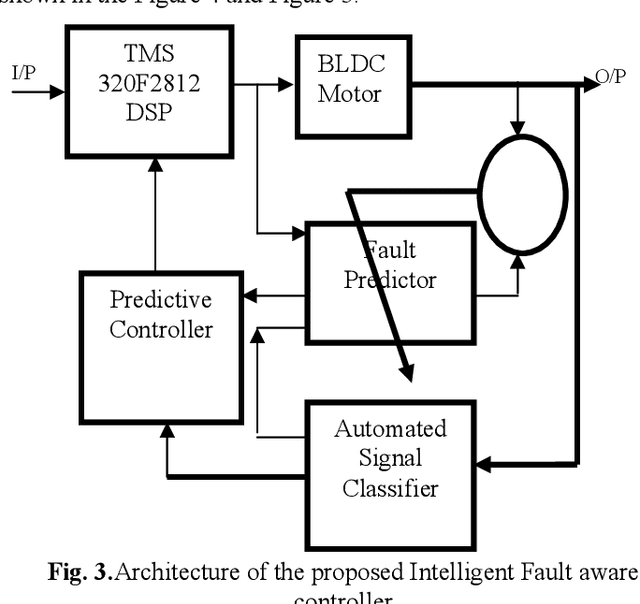
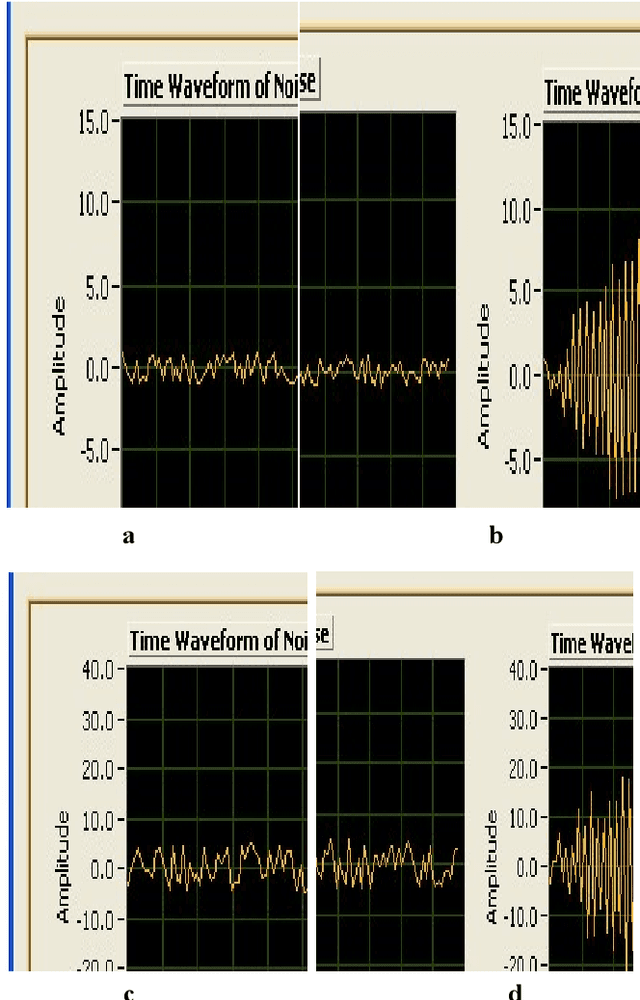
A hybrid approach based on multirate signal processing and sensory data fusion is proposed for the condition monitoring and identification of fault signal signatures used in the Flight ECS (Engine Control System) unit. Though motor current signature analysis (MCSA) is widely used for fault detection now-a-days, the proposed hybrid method qualifies as one of the most powerful online/offline techniques for diagnosing the process faults. Existing approaches have some drawbacks that can degrade the performance and accuracy of a process-diagnosis system. In particular, it is very difficult to detect random stochastic noise due to the nonlinear behavior of valve controller. Using only Short Time Fourier Transform (STFT), frequency leakage and the small amplitude of the current components related to the fault can be observed, but the fault due to the controller behavior cannot be observed. Therefore, a framework of advanced multirate signal and data-processing aided with sensor fusion algorithms is proposed in this article and satisfactory results are obtained. For implementing the system, a DSP-based BLDC motor controller with three-phase inverter module (TMS 320F2812) is used and the performance of the proposed method is validated on real time data.
GEMEL: Model Merging for Memory-Efficient, Real-Time Video Analytics at the Edge
Jan 19, 2022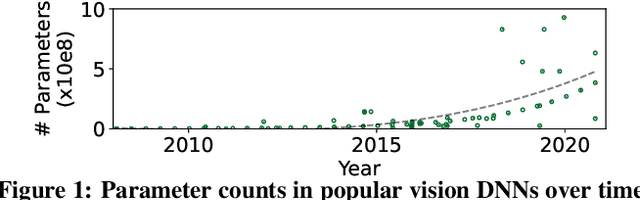
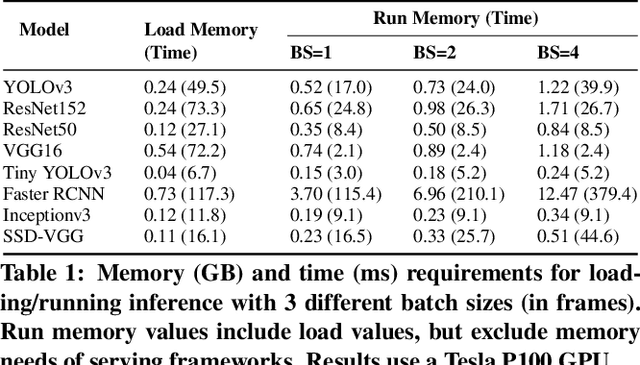
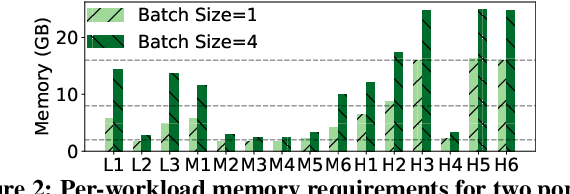

Video analytics pipelines have steadily shifted to edge deployments to reduce bandwidth overheads and privacy violations, but in doing so, face an ever-growing resource tension. Most notably, edge-box GPUs lack the memory needed to concurrently house the growing number of (increasingly complex) models for real-time inference. Unfortunately, existing solutions that rely on time/space sharing of GPU resources are insufficient as the required swapping delays result in unacceptable frame drops and accuracy violations. We present model merging, a new memory management technique that exploits architectural similarities between edge vision models by judiciously sharing their layers (including weights) to reduce workload memory costs and swapping delays. Our system, GEMEL, efficiently integrates merging into existing pipelines by (1) leveraging several guiding observations about per-model memory usage and inter-layer dependencies to quickly identify fruitful and accuracy-preserving merging configurations, and (2) altering edge inference schedules to maximize merging benefits. Experiments across diverse workloads reveal that GEMEL reduces memory usage by up to 60.7%, and improves overall accuracy by 8-39% relative to time/space sharing alone.
Space-Time-Separable Graph Convolutional Network for Pose Forecasting
Oct 09, 2021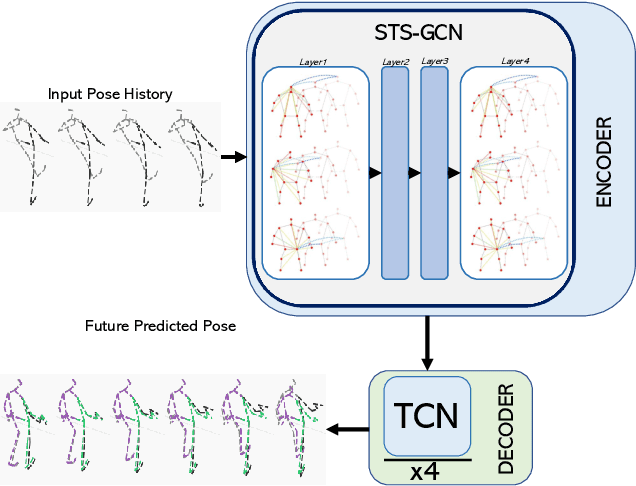
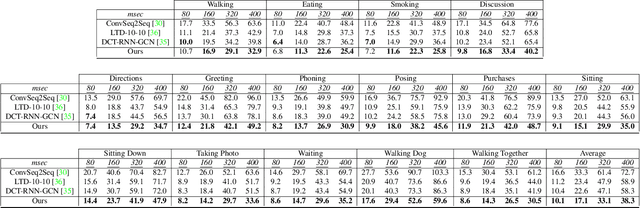
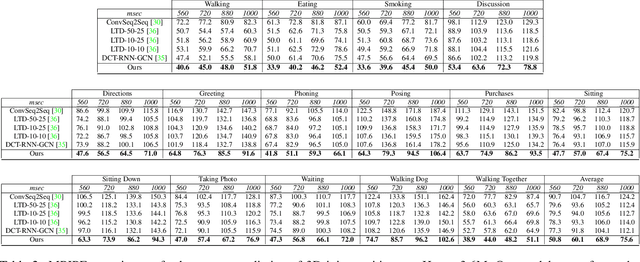
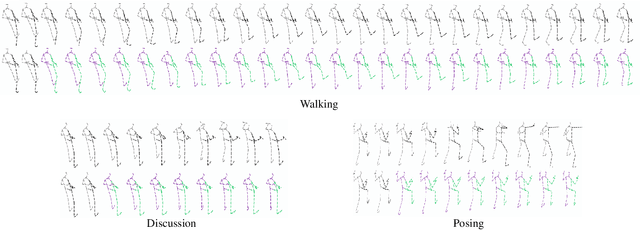
Human pose forecasting is a complex structured-data sequence-modelling task, which has received increasing attention, also due to numerous potential applications. Research has mainly addressed the temporal dimension as time series and the interaction of human body joints with a kinematic tree or by a graph. This has decoupled the two aspects and leveraged progress from the relevant fields, but it has also limited the understanding of the complex structural joint spatio-temporal dynamics of the human pose. Here we propose a novel Space-Time-Separable Graph Convolutional Network (STS-GCN) for pose forecasting. For the first time, STS-GCN models the human pose dynamics only with a graph convolutional network (GCN), including the temporal evolution and the spatial joint interaction within a single-graph framework, which allows the cross-talk of motion and spatial correlations. Concurrently, STS-GCN is the first space-time-separable GCN: the space-time graph connectivity is factored into space and time affinity matrices, which bottlenecks the space-time cross-talk, while enabling full joint-joint and time-time correlations. Both affinity matrices are learnt end-to-end, which results in connections substantially deviating from the standard kinematic tree and the linear-time time series. In experimental evaluation on three complex, recent and large-scale benchmarks, Human3.6M [Ionescu et al. TPAMI'14], AMASS [Mahmood et al. ICCV'19] and 3DPW [Von Marcard et al. ECCV'18], STS-GCN outperforms the state-of-the-art, surpassing the current best technique [Mao et al. ECCV'20] by over 32% in average at the most difficult long-term predictions, while only requiring 1.7% of its parameters. We explain the results qualitatively and illustrate the graph interactions by the factored joint-joint and time-time learnt graph connections. Our source code is available at: https://github.com/FraLuca/STSGCN
Clustering Without Knowing How To: Application and Evaluation
Sep 21, 2022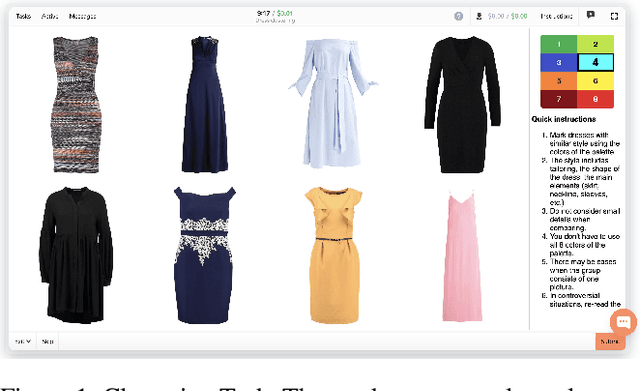
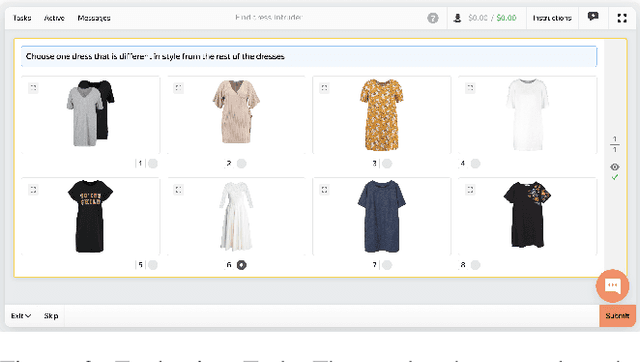
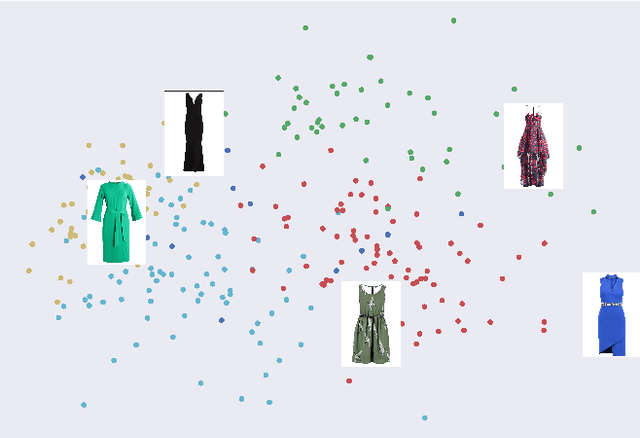
Crowdsourcing allows running simple human intelligence tasks on a large crowd of workers, enabling solving problems for which it is difficult to formulate an algorithm or train a machine learning model in reasonable time. One of such problems is data clustering by an under-specified criterion that is simple for humans, but difficult for machines. In this demonstration paper, we build a crowdsourced system for image clustering and release its code under a free license at https://github.com/Toloka/crowdclustering. Our experiments on two different image datasets, dresses from Zalando's FEIDEGGER and shoes from the Toloka Shoes Dataset, confirm that one can yield meaningful clusters with no machine learning algorithms purely with crowdsourcing.
Time-multiplexed Neural Holography: A flexible framework for holographic near-eye displays with fast heavily-quantized spatial light modulators
May 05, 2022
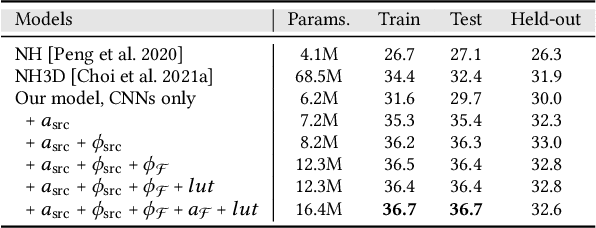
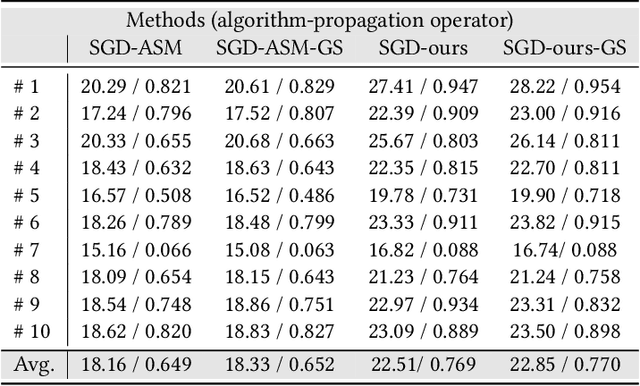

Holographic near-eye displays offer unprecedented capabilities for virtual and augmented reality systems, including perceptually important focus cues. Although artificial intelligence--driven algorithms for computer-generated holography (CGH) have recently made much progress in improving the image quality and synthesis efficiency of holograms, these algorithms are not directly applicable to emerging phase-only spatial light modulators (SLM) that are extremely fast but offer phase control with very limited precision. The speed of these SLMs offers time multiplexing capabilities, essentially enabling partially-coherent holographic display modes. Here we report advances in camera-calibrated wave propagation models for these types of holographic near-eye displays and we develop a CGH framework that robustly optimizes the heavily quantized phase patterns of fast SLMs. Our framework is flexible in supporting runtime supervision with different types of content, including 2D and 2.5D RGBD images, 3D focal stacks, and 4D light fields. Using our framework, we demonstrate state-of-the-art results for all of these scenarios in simulation and experiment.
Learning Self-Modulating Attention in Continuous Time Space with Applications to Sequential Recommendation
Mar 30, 2022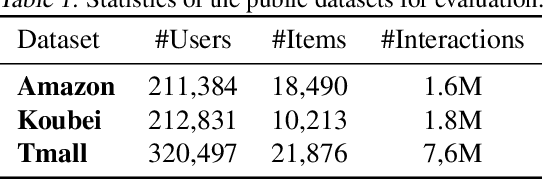
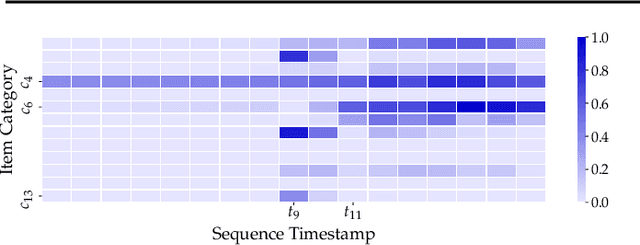
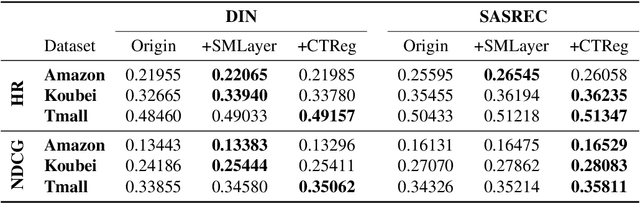
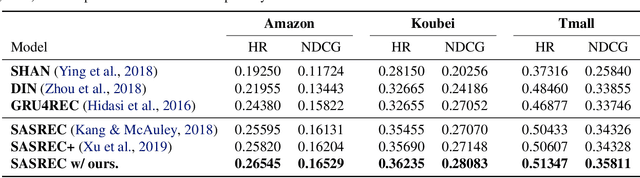
User interests are usually dynamic in the real world, which poses both theoretical and practical challenges for learning accurate preferences from rich behavior data. Among existing user behavior modeling solutions, attention networks are widely adopted for its effectiveness and relative simplicity. Despite being extensively studied, existing attentions still suffer from two limitations: i) conventional attentions mainly take into account the spatial correlation between user behaviors, regardless the distance between those behaviors in the continuous time space; and ii) these attentions mostly provide a dense and undistinguished distribution over all past behaviors then attentively encode them into the output latent representations. This is however not suitable in practical scenarios where a user's future actions are relevant to a small subset of her/his historical behaviors. In this paper, we propose a novel attention network, named self-modulating attention, that models the complex and non-linearly evolving dynamic user preferences. We empirically demonstrate the effectiveness of our method on top-N sequential recommendation tasks, and the results on three large-scale real-world datasets show that our model can achieve state-of-the-art performance.
Dynamic Adaptive and Adversarial Graph Convolutional Network for Traffic Forecasting
Aug 05, 2022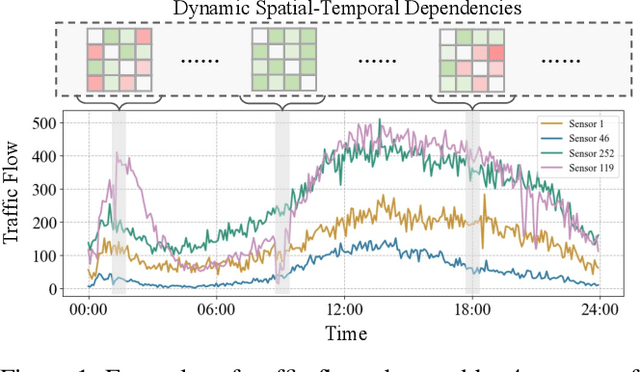
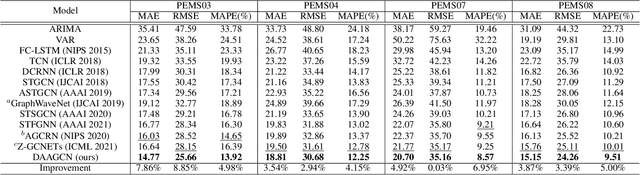
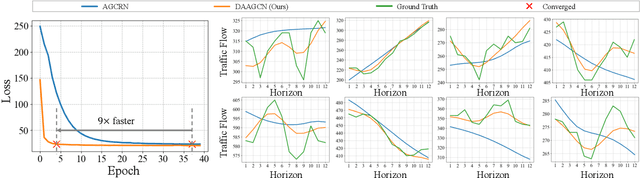
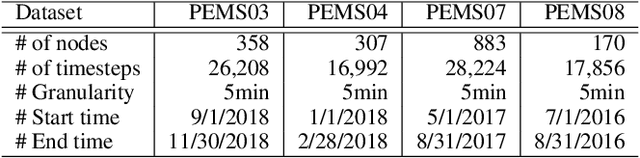
Traffic forecasting is challenging due to dynamic and complicated spatial-temporal dependencies. However, existing methods still suffer from two critical limitations. Firstly, many approaches typically utilize static pre-defined or adaptively learned spatial graphs to capture dynamic spatial-temporal dependencies in the traffic system, which limits the flexibility and only captures shared patterns for the whole time, thus leading to sub-optimal performance. In addition, most approaches individually and independently consider the absolute error between ground truth and predictions at each time step, which fails to maintain the global properties and statistics of time series as a whole and results in trend discrepancy between ground truth and predictions. To this end, in this paper, we propose a Dynamic Adaptive and Adversarial Graph Convolutional Network (DAAGCN), which combines Graph Convolution Networks (GCNs) with Generative Adversarial Networks (GANs) for traffic forecasting. Specifically, DAAGCN leverages a universal paradigm with a gate module to integrate time-varying embeddings with node embeddings to generate dynamic adaptive graphs for inferring spatial-temporal dependencies at each time step. Then, two discriminators are designed to maintain the consistency of the global properties and statistics of predicted time series with ground truth at the sequence and graph levels. Extensive experiments on four benchmark datasets manifest that DAAGCN outperforms the state-of-the-art by average 5.05%, 3.80%, and 5.27%, in terms of MAE, RMSE, and MAPE, meanwhile, speeds up convergence up to 9 times. Code is available at https://github.com/juyongjiang/DAAGCN.