 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DIAGNOSE: Avoiding Out-of-distribution Data using Submodular Information Measures
Oct 04, 2022
Avoiding out-of-distribution (OOD) data is critical for training supervised machine learning models in the medical imaging domain. Furthermore, obtaining labeled medical data is difficult and expensive since it requires expert annotators like doctors, radiologists, etc. Active learning (AL) is a well-known method to mitigate labeling costs by selecting the most diverse or uncertain samples. However, current AL methods do not work well in the medical imaging domain with OOD data. We propose Diagnose (avoiDing out-of-dIstribution dAta usinG submodular iNfOrmation meaSurEs), a novel active learning framework that can jointly model similarity and dissimilarity, which is crucial in mining in-distribution data and avoiding OOD data at the same time. Particularly, we use a small number of data points as exemplars that represent a query set of in-distribution data points and a private set of OOD data points. We illustrate the generalizability of our framework by evaluating it on a wide variety of real-world OOD scenarios. Our experiments verify the superiority of Diagnose over the state-of-the-art AL methods across multiple domains of medical imaging.
Differentially Private Bias-Term only Fine-tuning of Foundation Models
Oct 04, 2022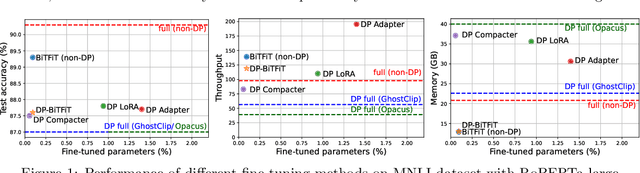
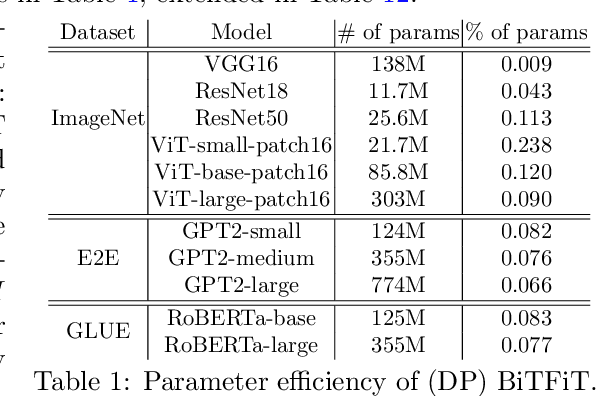
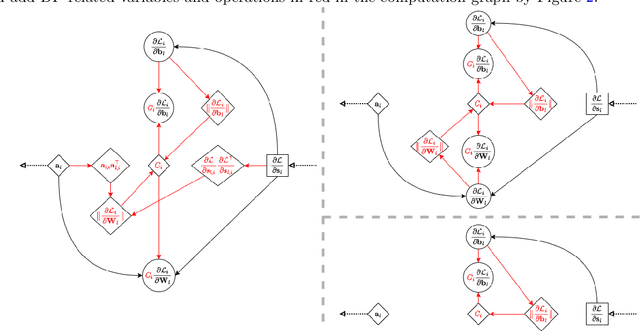
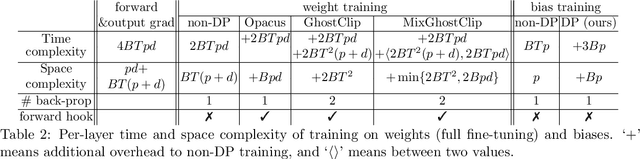
We study the problem of differentially private (DP) fine-tuning of large pre-trained models -- a recent privacy-preserving approach suitable for solving downstream tasks with sensitive data. Existing work has demonstrated that high accuracy is possible under strong privacy constraint, yet requires significant computational overhead or modifications to the network architecture. We propose differentially private bias-term fine-tuning (DP-BiTFiT), which matches the state-of-the-art accuracy for DP algorithms and the efficiency of the standard BiTFiT. DP-BiTFiT is model agnostic (not modifying the network architecture), parameter efficient (only training about $0.1\%$ of the parameters), and computation efficient (almost removing the overhead caused by DP, in both the time and space complexity). On a wide range of tasks, DP-BiTFiT is $2\sim 30\times$ faster and uses $2\sim 8\times$ less memory than DP full fine-tuning, even faster than the standard full fine-tuning. This amazing efficiency enables us to conduct DP fine-tuning on language and vision tasks with long-sequence texts and high-resolution images, which were computationally difficult using existing methods.
An Ensemble of Convolutional Neural Networks to Detect Foliar Diseases in Apple Plants
Oct 01, 2022
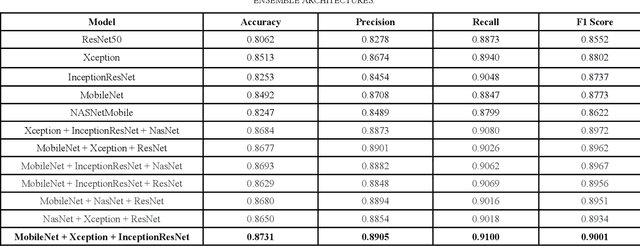
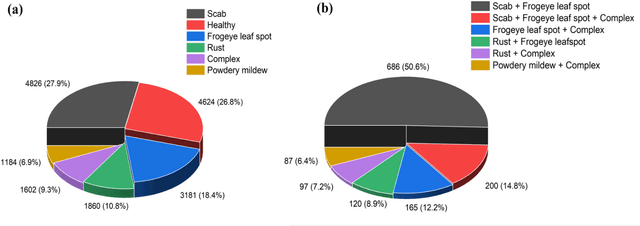
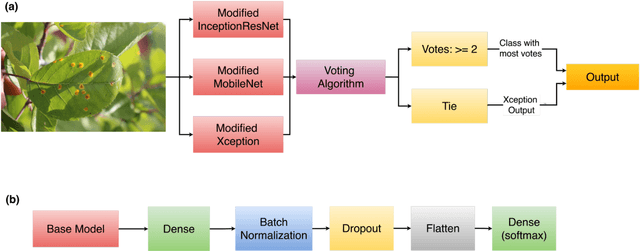
Apple diseases, if not diagnosed early, can lead to massive resource loss and pose a serious threat to humans and animals who consume the infected apples. Hence, it is critical to diagnose these diseases early in order to manage plant health and minimize the risks associated with them. However, the conventional approach of monitoring plant diseases entails manual scouting and analyzing the features, texture, color, and shape of the plant leaves, resulting in delayed diagnosis and misjudgments. Our work proposes an ensembled system of Xception, InceptionResNet, and MobileNet architectures to detect 5 different types of apple plant diseases. The model has been trained on the publicly available Plant Pathology 2021 dataset and can classify multiple diseases in a given plant leaf. The system has achieved outstanding results in multi-class and multi-label classification and can be used in a real-time setting to monitor large apple plantations to aid the farmers manage their yields effectively.
Learning Large-Time-Step Molecular Dynamics with Graph Neural Networks
Nov 30, 2021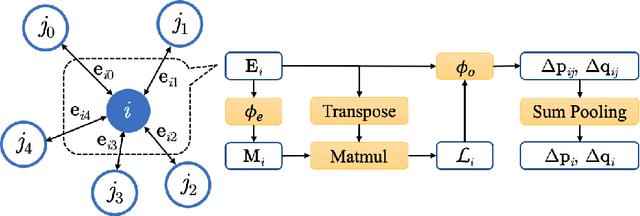

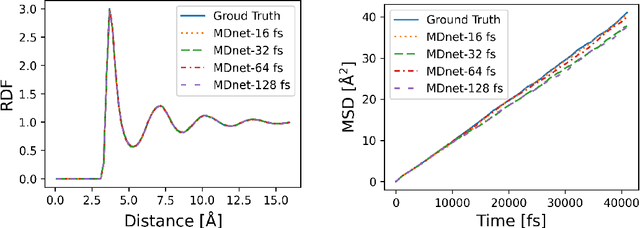
Molecular dynamics (MD) simulation predicts the trajectory of atoms by solving Newton's equation of motion with a numeric integrator. Due to physical constraints, the time step of the integrator need to be small to maintain sufficient precision. This limits the efficiency of simulation. To this end, we introduce a graph neural network (GNN) based model, MDNet, to predict the evolution of coordinates and momentum with large time steps. In addition, MDNet can easily scale to a larger system, due to its linear complexity with respect to the system size. We demonstrate the performance of MDNet on a 4000-atom system with large time steps, and show that MDNet can predict good equilibrium and transport properties, well aligned with standard MD simulations.
DuETA: Traffic Congestion Propagation Pattern Modeling via Efficient Graph Learning for ETA Prediction at Baidu Maps
Aug 15, 2022
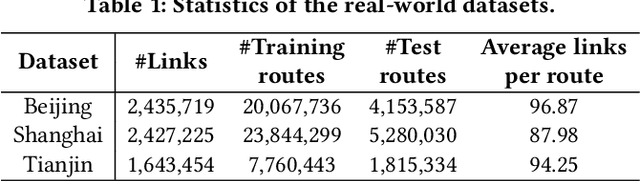
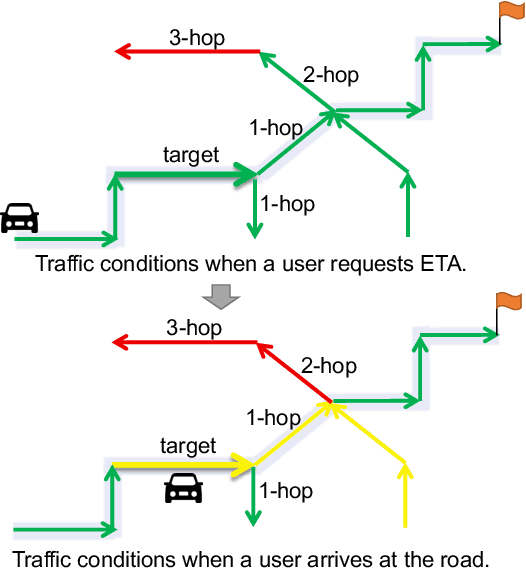
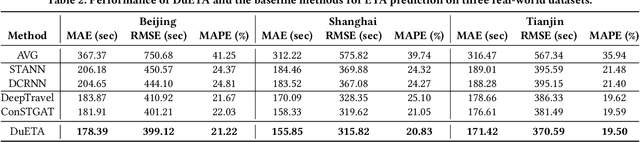
Estimated time of arrival (ETA) prediction, also known as travel time estimation, is a fundamental task for a wide range of intelligent transportation applications, such as navigation, route planning, and ride-hailing services. To accurately predict the travel time of a route, it is essential to take into account both contextual and predictive factors, such as spatial-temporal interaction, driving behavior, and traffic congestion propagation inference. The ETA prediction models previously deployed at Baidu Maps have addressed the factors of spatial-temporal interaction (ConSTGAT) and driving behavior (SSML). In this work, we focus on modeling traffic congestion propagation patterns to improve ETA performance. Traffic congestion propagation pattern modeling is challenging, and it requires accounting for impact regions over time and cumulative effect of delay variations over time caused by traffic events on the road network. In this paper, we present a practical industrial-grade ETA prediction framework named DuETA. Specifically, we construct a congestion-sensitive graph based on the correlations of traffic patterns, and we develop a route-aware graph transformer to directly learn the long-distance correlations of the road segments. This design enables DuETA to capture the interactions between the road segment pairs that are spatially distant but highly correlated with traffic conditions. Extensive experiments are conducted on large-scale, real-world datasets collected from Baidu Maps. Experimental results show that ETA prediction can significantly benefit from the learned traffic congestion propagation patterns. In addition, DuETA has already been deployed in production at Baidu Maps, serving billions of requests every day. This demonstrates that DuETA is an industrial-grade and robust solution for large-scale ETA prediction services.
Exploring Cross-Point Embeddings for 3D Dense Uncertainty Estimation
Sep 29, 2022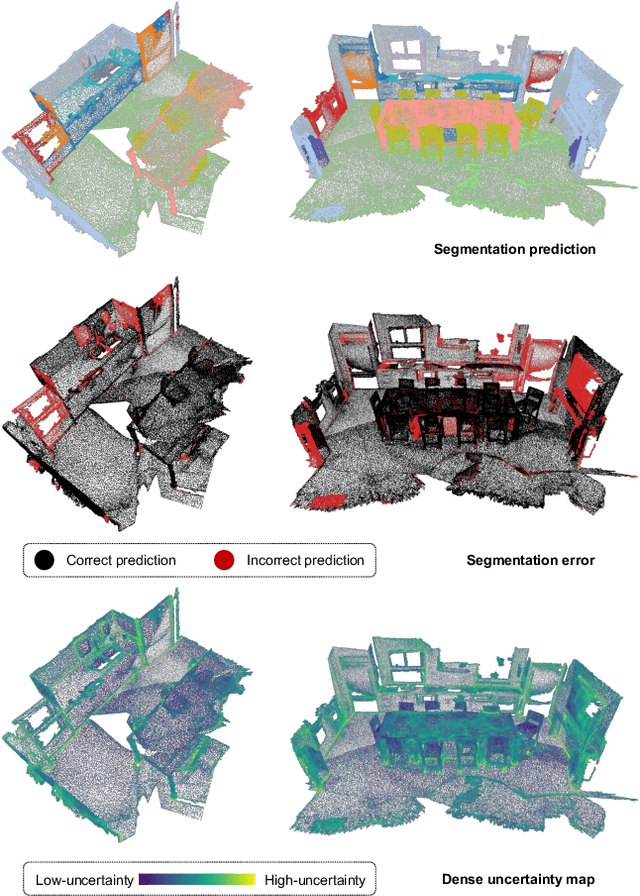
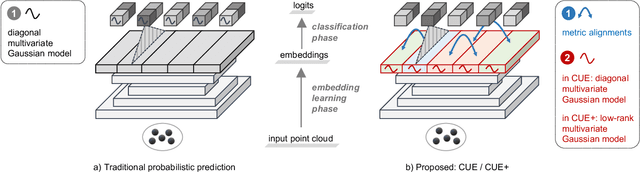
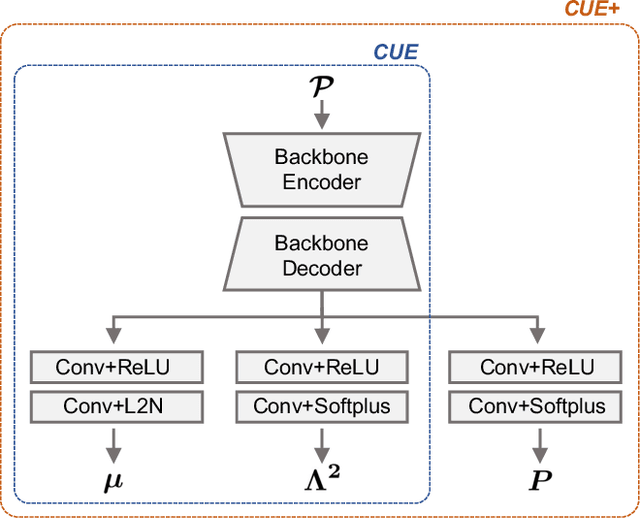
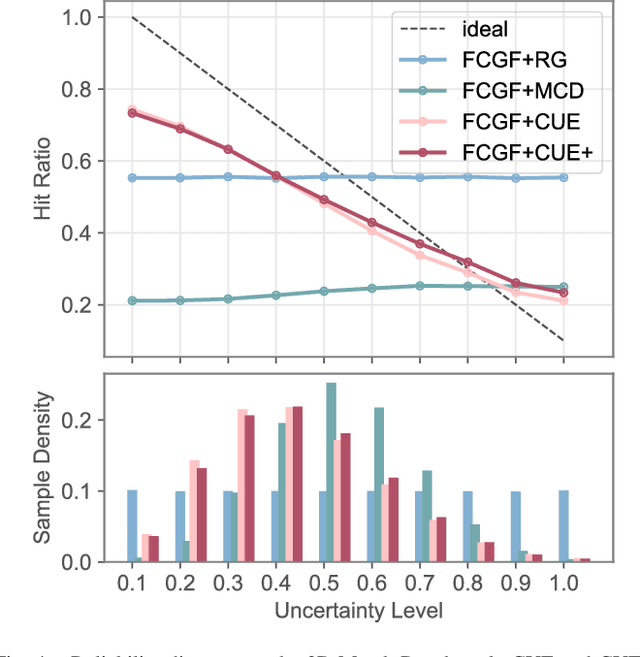
Dense prediction tasks are common for 3D point clouds, but the inherent uncertainties in massive points and their embeddings have long been ignored. In this work, we present CUE, a novel uncertainty estimation method for dense prediction tasks of 3D point clouds. Inspired by metric learning, the key idea of CUE is to explore cross-point embeddings upon a conventional dense prediction pipeline. Specifically, CUE involves building a probabilistic embedding model and then enforcing metric alignments of massive points in the embedding space. We demonstrate that CUE is a generic and effective tool for dense uncertainty estimation of 3D point clouds in two different tasks: (1) in 3D geometric feature learning we for the first time obtain well-calibrated dense uncertainty, and (2) in semantic segmentation we reduce uncertainty`s Expected Calibration Error of the state-of-the-arts by 43.8%. All uncertainties are estimated without compromising predictive performance.
Towards Real-Time Visual Tracking with Graded Color-names Features
Jun 17, 2022

MeanShift algorithm has been widely used in tracking tasks because of its simplicity and efficiency. However, the traditional MeanShift algorithm needs to label the initial region of the target, which reduces the applicability of the algorithm. Furthermore, it is only applicable to the scene with a large overlap rate between the target area and the candidate area. Therefore, when the target speed is fast, the target scale change, shape deformation or the target occlusion occurs, the tracking performance will be deteriorated. In this paper, we address the challenges above-mentioned by developing a tracking method that combines the background models and the graded features of color-names under the MeanShift framework. This method significantly improve performance in the above scenarios. In addition, it facilitates the balance between detection accuracy and detection speed. Experimental results demonstrate the validation of the proposed method.
Reliability in Time: Evaluating the Web Sources of Information on COVID-19 in Wikipedia across Various Language Editions from the Beginning of the Pandemic
Apr 29, 2022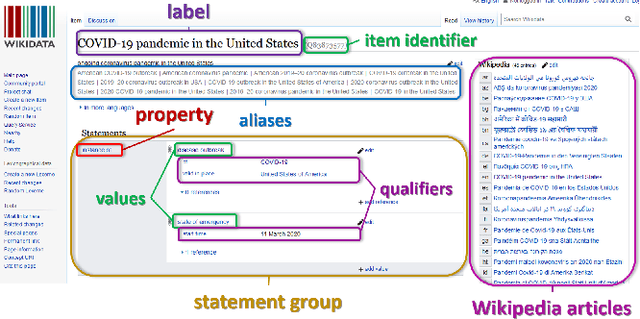
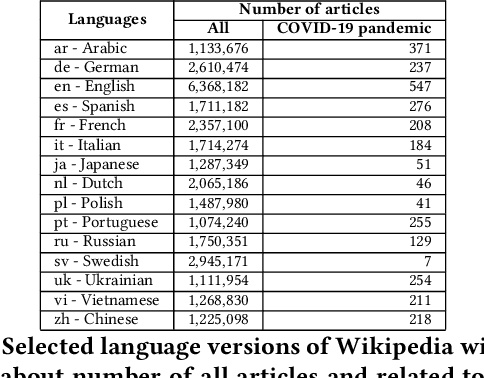
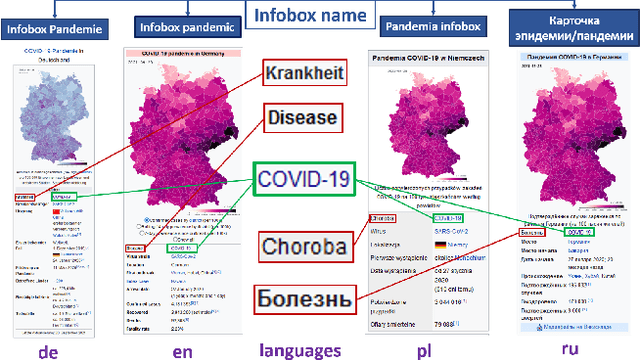
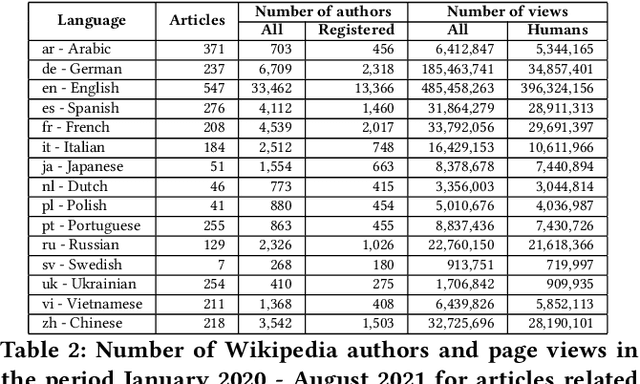
There are over a billion websites on the Internet that can potentially serve as sources of information on various topics. One of the most popular examples of such an online source is Wikipedia. This public knowledge base is co-edited by millions of users from all over the world. Information in each language version of Wikipedia can be created and edited independently. Therefore, we can observe certain inconsistencies in the statements and facts described therein - depending on language and topic. In accordance with the Wikipedia content authoring guidelines, information in Wikipedia articles should be based on reliable, published sources. So, based on data from such a collaboratively edited encyclopedia, we should also be able to find important sources on specific topics. This effect can be potentially useful for people and organizations. The reliability of a source in Wikipedia articles depends on the context. So the same source (website) may have various degrees of reliability in Wikipedia depending on topic and language version. Moreover, reliability of the same source can change over the time. The purpose of this study is to identify reliable sources on a specific topic - the COVID-19 pandemic. Such an analysis was carried out on real data from Wikipedia within selected language versions and within a selected time period.
Self-supervised Video Representation Learning with Motion-Aware Masked Autoencoders
Oct 09, 2022
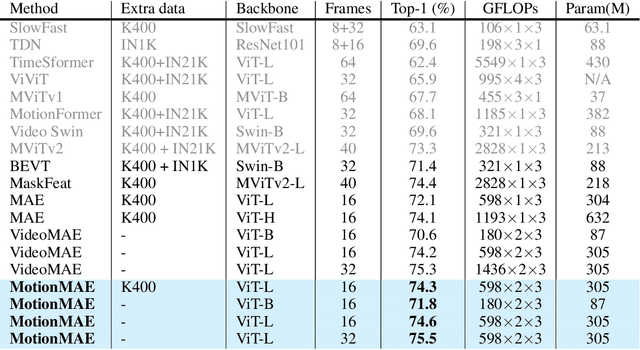
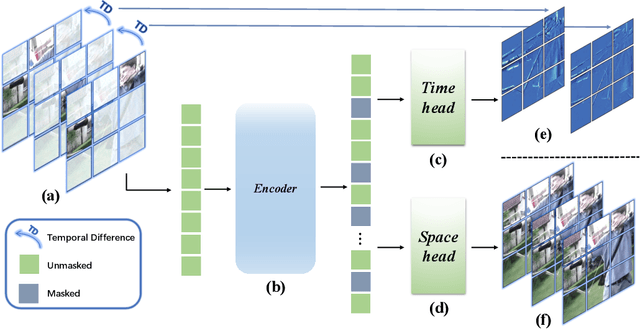
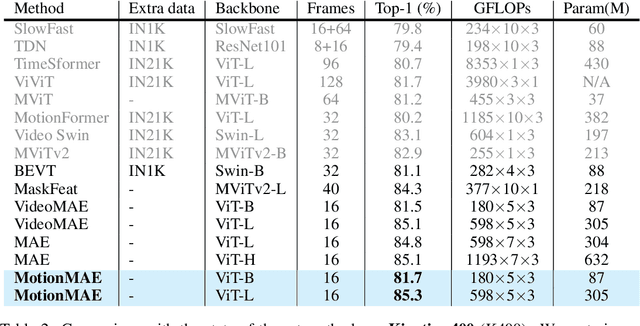
Masked autoencoders (MAEs) have emerged recently as art self-supervised spatiotemporal representation learners. Inheriting from the image counterparts, however, existing video MAEs still focus largely on static appearance learning whilst are limited in learning dynamic temporal information hence less effective for video downstream tasks. To resolve this drawback, in this work we present a motion-aware variant -- MotionMAE. Apart from learning to reconstruct individual masked patches of video frames, our model is designed to additionally predict the corresponding motion structure information over time. This motion information is available at the temporal difference of nearby frames. As a result, our model can extract effectively both static appearance and dynamic motion spontaneously, leading to superior spatiotemporal representation learning capability. Extensive experiments show that our MotionMAE outperforms significantly both supervised learning baseline and state-of-the-art MAE alternatives, under both domain-specific and domain-generic pretraining-then-finetuning settings. In particular, when using ViT-B as the backbone our MotionMAE surpasses the prior art model by a margin of 1.2% on Something-Something V2 and 3.2% on UCF101 in domain-specific pretraining setting. Encouragingly, it also surpasses the competing MAEs by a large margin of over 3% on the challenging video object segmentation task. The code is available at https://github.com/happy-hsy/MotionMAE.
Multi-Curve Translator for Real-Time High-Resolution Image-to-Image Translation
Mar 15, 2022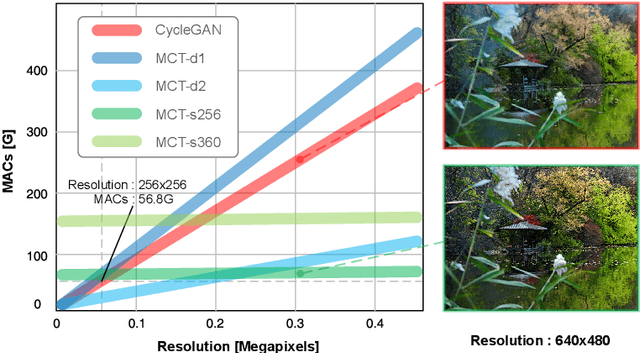
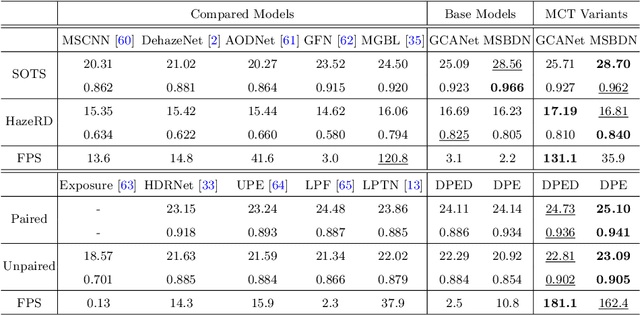
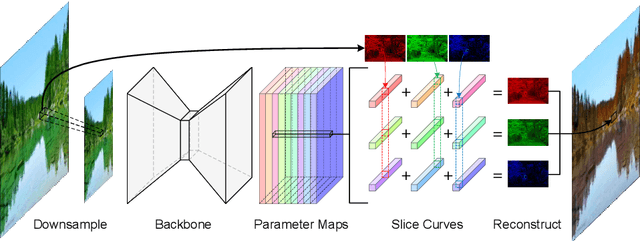
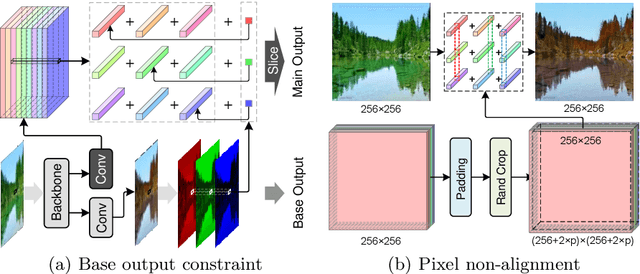
The dominant image-to-image translation methods are based on fully convolutional networks, which extract and translate an image's features and then reconstruct the image. However, they have unacceptable computational costs when working with high-resolution images. To this end, we present the Multi-Curve Translator (MCT), which not only predicts the translated pixels for the corresponding input pixels but also for their neighboring pixels. And if a high-resolution image is downsampled to its low-resolution version, the lost pixels are the remaining pixels' neighboring pixels. So MCT makes it possible to feed the network only the downsampled image to perform the mapping for the full-resolution image, which can dramatically lower the computational cost. Besides, MCT is a plug-in approach that utilizes existing base models and requires only replacing their output layers. Experiments demonstrate that the MCT variants can process 4K images in real-time and achieve comparable or even better performance than the base models on various image-to-image translation tasks.