 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PACT: Perception-Action Causal Transformer for Autoregressive Robotics Pre-Training
Sep 23, 2022
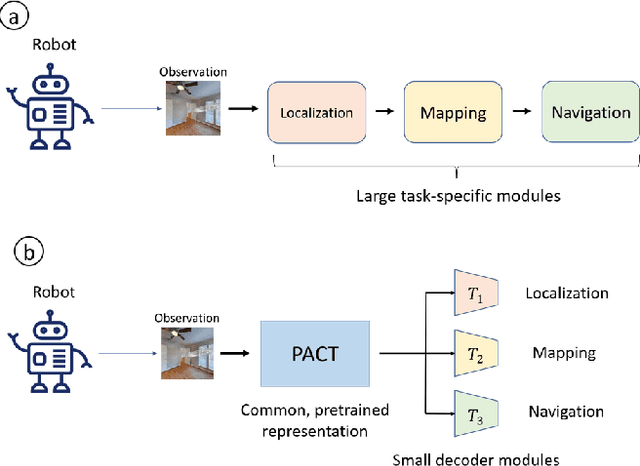
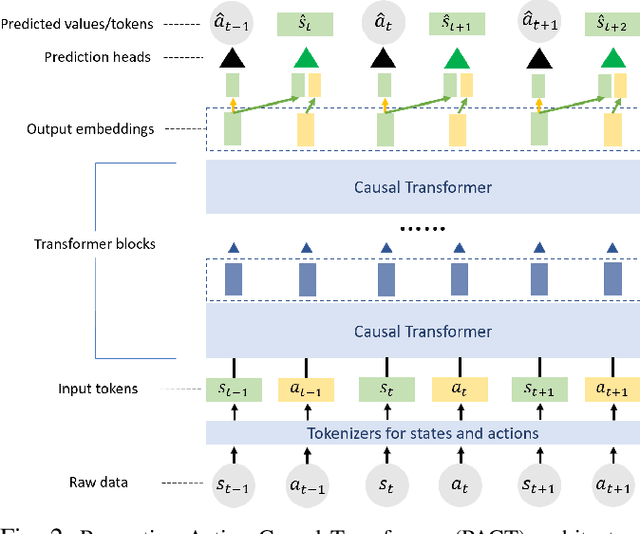
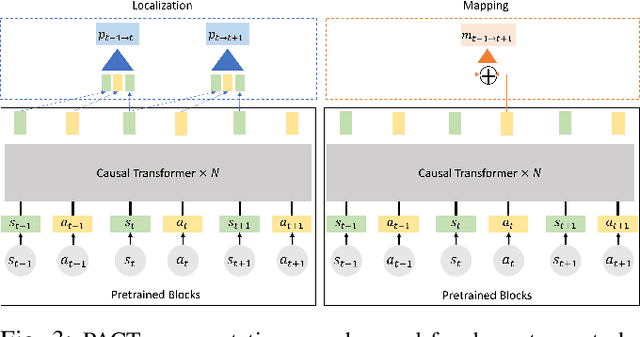

Robotics has long been a field riddled with complex systems architectures whose modules and connections, whether traditional or learning-based, require significant human expertise and prior knowledge. Inspired by large pre-trained language models, this work introduces a paradigm for pre-training a general purpose representation that can serve as a starting point for multiple tasks on a given robot. We present the Perception-Action Causal Transformer (PACT), a generative transformer-based architecture that aims to build representations directly from robot data in a self-supervised fashion. Through autoregressive prediction of states and actions over time, our model implicitly encodes dynamics and behaviors for a particular robot. Our experimental evaluation focuses on the domain of mobile agents, where we show that this robot-specific representation can function as a single starting point to achieve distinct tasks such as safe navigation, localization and mapping. We evaluate two form factors: a wheeled robot that uses a LiDAR sensor as perception input (MuSHR), and a simulated agent that uses first-person RGB images (Habitat). We show that finetuning small task-specific networks on top of the larger pretrained model results in significantly better performance compared to training a single model from scratch for all tasks simultaneously, and comparable performance to training a separate large model for each task independently. By sharing a common good-quality representation across tasks we can lower overall model capacity and speed up the real-time deployment of such systems.
Real-time Detection of Anomalies in Multivariate Time Series of Astronomical Data
Dec 15, 2021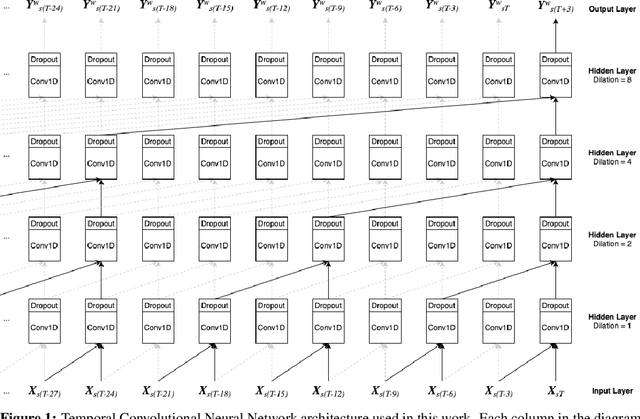
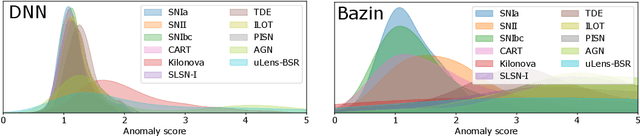
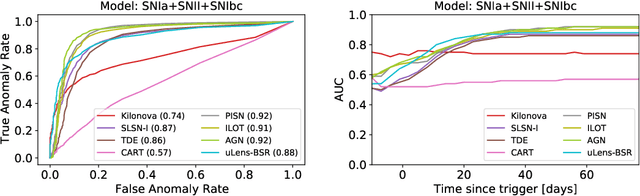
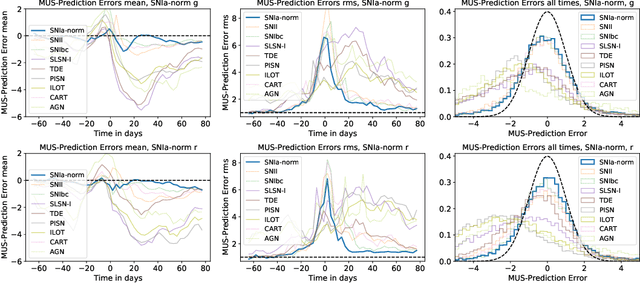
Astronomical transients are stellar objects that become temporarily brighter on various timescales and have led to some of the most significant discoveries in cosmology and astronomy. Some of these transients are the explosive deaths of stars known as supernovae while others are rare, exotic, or entirely new kinds of exciting stellar explosions. New astronomical sky surveys are observing unprecedented numbers of multi-wavelength transients, making standard approaches of visually identifying new and interesting transients infeasible. To meet this demand, we present two novel methods that aim to quickly and automatically detect anomalous transient light curves in real-time. Both methods are based on the simple idea that if the light curves from a known population of transients can be accurately modelled, any deviations from model predictions are likely anomalies. The first approach is a probabilistic neural network built using Temporal Convolutional Networks (TCNs) and the second is an interpretable Bayesian parametric model of a transient. We show that the flexibility of neural networks, the attribute that makes them such a powerful tool for many regression tasks, is what makes them less suitable for anomaly detection when compared with our parametric model.
InForecaster: Forecasting Influenza Hemagglutinin Mutations Through the Lens of Anomaly Detection
Oct 25, 2022
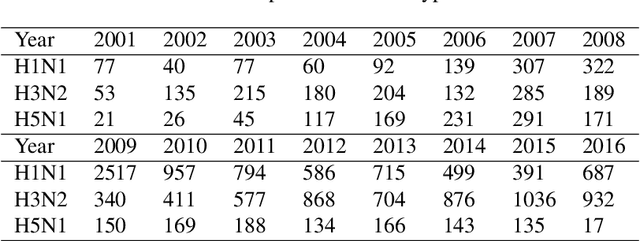

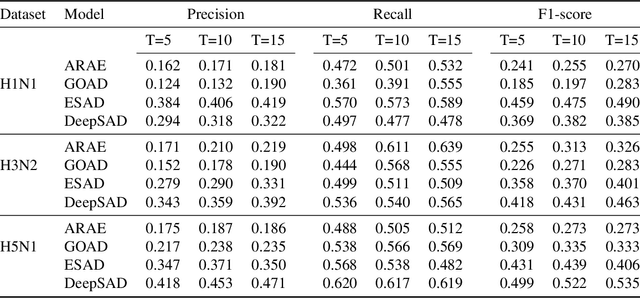
The influenza virus hemagglutinin is an important part of the virus attachment to the host cells. The hemagglutinin proteins are one of the genetic regions of the virus with a high potential for mutations. Due to the importance of predicting mutations in producing effective and low-cost vaccines, solutions that attempt to approach this problem have recently gained a significant attention. A historical record of mutations have been used to train predictive models in such solutions. However, the imbalance between mutations and the preserved proteins is a big challenge for the development of such models that needs to be addressed. Here, we propose to tackle this challenge through anomaly detection (AD). AD is a well-established field in Machine Learning (ML) that tries to distinguish unseen anomalies from the normal patterns using only normal training samples. By considering mutations as the anomalous behavior, we could benefit existing rich solutions in this field that have emerged recently. Such methods also fit the problem setup of extreme imbalance between the number of unmutated vs. mutated training samples. Motivated by this formulation, our method tries to find a compact representation for unmutated samples while forcing anomalies to be separated from the normal ones. This helps the model to learn a shared unique representation between normal training samples as much as possible, which improves the discernibility and detectability of mutated samples from the unmutated ones at the test time. We conduct a large number of experiments on four publicly available datasets, consisting of 3 different hemagglutinin protein datasets, and one SARS-CoV-2 dataset, and show the effectiveness of our method through different standard criteria.
MOFormer: Self-Supervised Transformer model for Metal-Organic Framework Property Prediction
Oct 25, 2022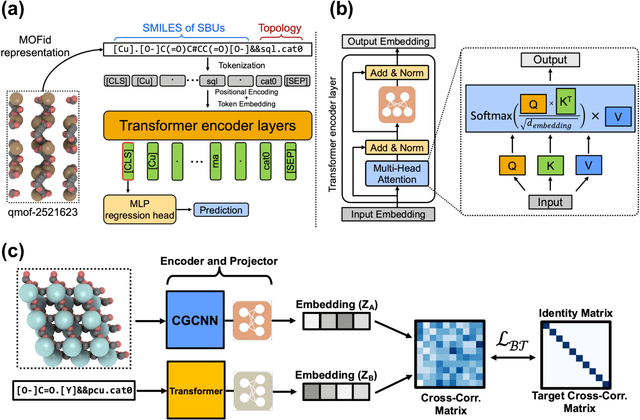

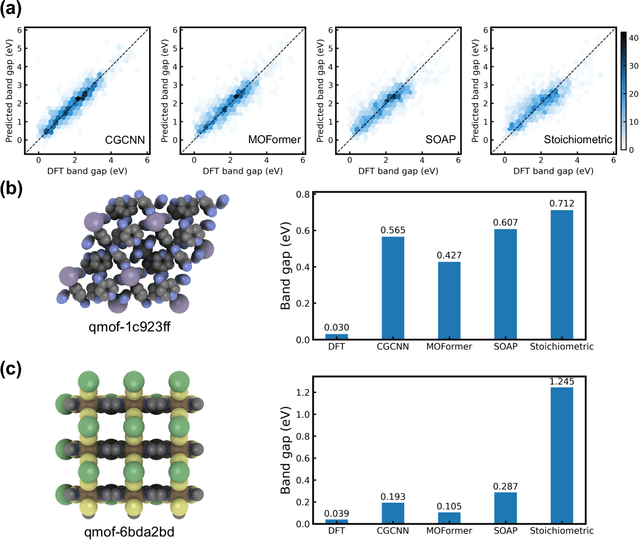
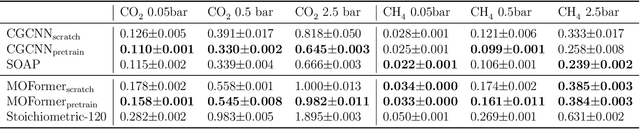
Metal-Organic Frameworks (MOFs) are materials with a high degree of porosity that can be used for applications in energy storage, water desalination, gas storage, and gas separation. However, the chemical space of MOFs is close to an infinite size due to the large variety of possible combinations of building blocks and topology. Discovering the optimal MOFs for specific applications requires an efficient and accurate search over an enormous number of potential candidates. Previous high-throughput screening methods using computational simulations like DFT can be time-consuming. Such methods also require optimizing 3D atomic structure of MOFs, which adds one extra step when evaluating hypothetical MOFs. In this work, we propose a structure-agnostic deep learning method based on the Transformer model, named as MOFormer, for property predictions of MOFs. The MOFormer takes a text string representation of MOF (MOFid) as input, thus circumventing the need of obtaining the 3D structure of hypothetical MOF and accelerating the screening process. Furthermore, we introduce a self-supervised learning framework that pretrains the MOFormer via maximizing the cross-correlation between its structure-agnostic representations and structure-based representations of crystal graph convolutional neural network (CGCNN) on >400k publicly available MOF data. Using self-supervised learning allows the MOFormer to intrinsically learn 3D structural information though it is not included in the input. Experiments show that pretraining improved the prediction accuracy of both models on various downstream prediction tasks. Furthermore, we revealed that MOFormer can be more data-efficient on quantum-chemical property prediction than structure-based CGCNN when training data is limited. Overall, MOFormer provides a novel perspective on efficient MOF design using deep learning.
Teal: Learning-Accelerated Optimization of Traffic Engineering
Oct 25, 2022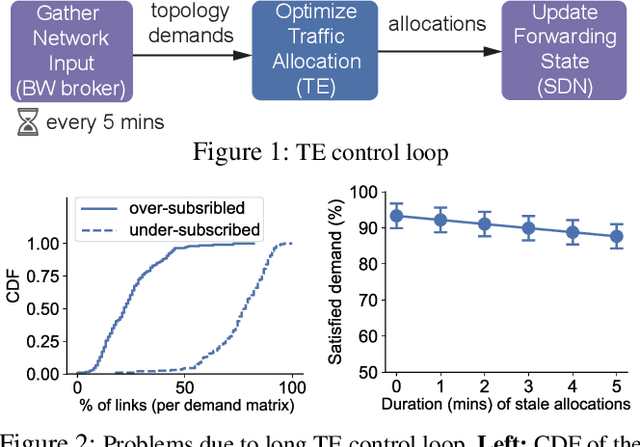
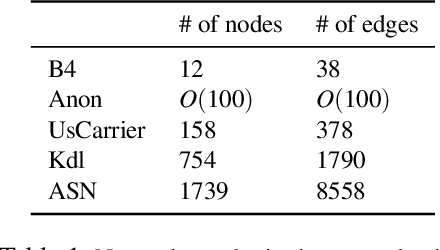

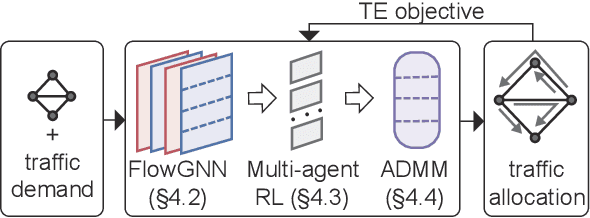
In the last decade, global cloud wide-area networks (WANs) have grown 10$\times$ in size due to the deployment of new network sites and datacenters, making it challenging for commercial optimization engines to solve the network traffic engineering (TE) problem within the temporal budget of a few minutes. In this work, we show that carefully designed deep learning models are key to accelerating the running time of intra-WAN TE systems for large deployments since deep learning is both massively parallel and it benefits from the wealth of historical traffic allocation data from production WANs. However, off-the-shelf deep learning methods fail to perform well on the TE task since they ignore the effects of network connectivity on flow allocations. They are also faced with a tractability challenge posed by the large problem scale of TE optimization. Moreover, neural networks do not have mechanisms to readily enforce hard constraints on model outputs (e.g., link capacity constraints). We tackle these challenges by designing a deep learning-based TE system -- Teal. First, Teal leverages graph neural networks (GNN) to faithfully capture connectivity and model network flows. Second, Teal devises a multi-agent reinforcement learning (RL) algorithm to process individual demands independently in parallel to lower the problem scale. Finally, Teal reduces link capacity violations and improves solution quality using the alternating direction method of multipliers (ADMM). We evaluate Teal on traffic matrices of a global commercial cloud provider and find that Teal computes near-optimal traffic allocations with a 59$\times$ speedup over state-of-the-art TE systems on a WAN topology of over 1,500 nodes.
Decoupling Features in Hierarchical Propagation for Video Object Segmentation
Oct 19, 2022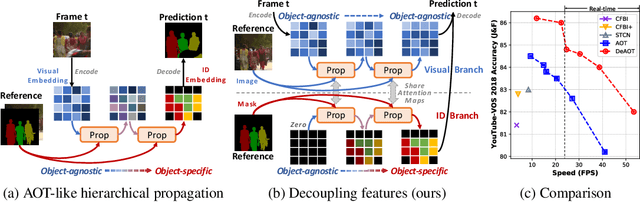
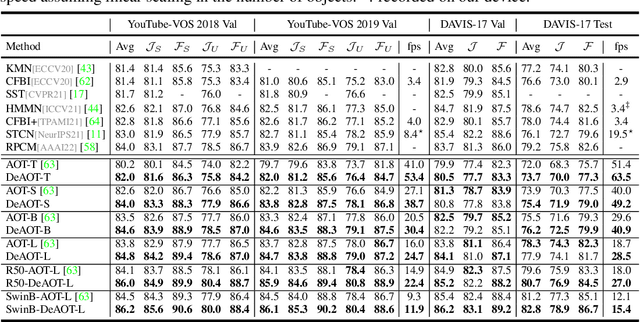
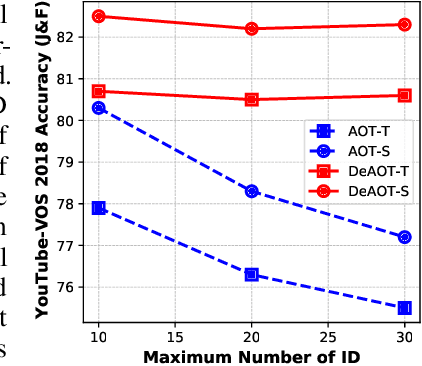
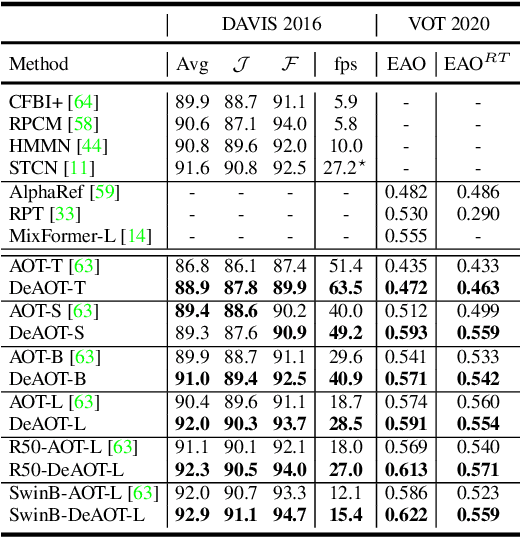
This paper focuses on developing a more effective method of hierarchical propagation for semi-supervised Video Object Segmentation (VOS). Based on vision transformers, the recently-developed Associating Objects with Transformers (AOT) approach introduces hierarchical propagation into VOS and has shown promising results. The hierarchical propagation can gradually propagate information from past frames to the current frame and transfer the current frame feature from object-agnostic to object-specific. However, the increase of object-specific information will inevitably lead to the loss of object-agnostic visual information in deep propagation layers. To solve such a problem and further facilitate the learning of visual embeddings, this paper proposes a Decoupling Features in Hierarchical Propagation (DeAOT) approach. Firstly, DeAOT decouples the hierarchical propagation of object-agnostic and object-specific embeddings by handling them in two independent branches. Secondly, to compensate for the additional computation from dual-branch propagation, we propose an efficient module for constructing hierarchical propagation, i.e., Gated Propagation Module, which is carefully designed with single-head attention. Extensive experiments show that DeAOT significantly outperforms AOT in both accuracy and efficiency. On YouTube-VOS, DeAOT can achieve 86.0% at 22.4fps and 82.0% at 53.4fps. Without test-time augmentations, we achieve new state-of-the-art performance on four benchmarks, i.e., YouTube-VOS (86.2%), DAVIS 2017 (86.2%), DAVIS 2016 (92.9%), and VOT 2020 (0.622). Project page: https://github.com/z-x-yang/AOT.
Cluster and Aggregate: Face Recognition with Large Probe Set
Oct 19, 2022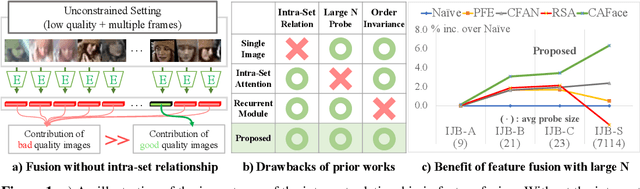
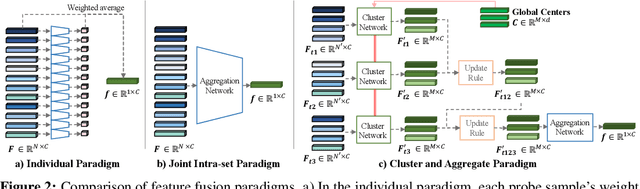
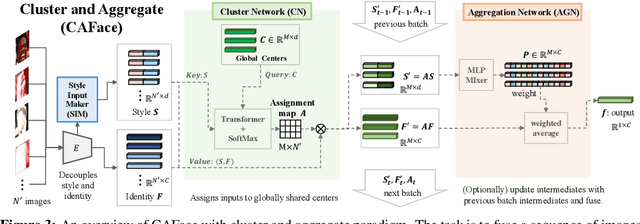

Feature fusion plays a crucial role in unconstrained face recognition where inputs (probes) comprise of a set of $N$ low quality images whose individual qualities vary. Advances in attention and recurrent modules have led to feature fusion that can model the relationship among the images in the input set. However, attention mechanisms cannot scale to large $N$ due to their quadratic complexity and recurrent modules suffer from input order sensitivity. We propose a two-stage feature fusion paradigm, Cluster and Aggregate, that can both scale to large $N$ and maintain the ability to perform sequential inference with order invariance. Specifically, Cluster stage is a linear assignment of $N$ inputs to $M$ global cluster centers, and Aggregation stage is a fusion over $M$ clustered features. The clustered features play an integral role when the inputs are sequential as they can serve as a summarization of past features. By leveraging the order-invariance of incremental averaging operation, we design an update rule that achieves batch-order invariance, which guarantees that the contributions of early image in the sequence do not diminish as time steps increase. Experiments on IJB-B and IJB-S benchmark datasets show the superiority of the proposed two-stage paradigm in unconstrained face recognition. Code and pretrained models are available in https://github.com/mk-minchul/caface
Density Planner: Minimizing Collision Risk in Motion Planning with Dynamic Obstacles using Density-based Reachability
Oct 05, 2022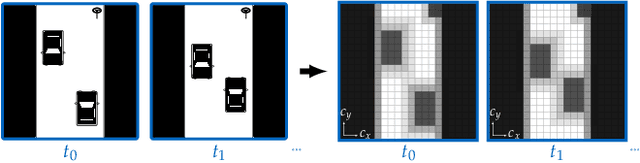
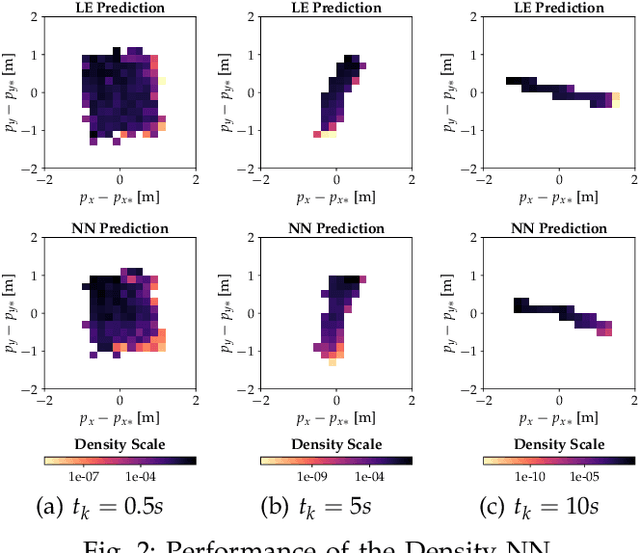
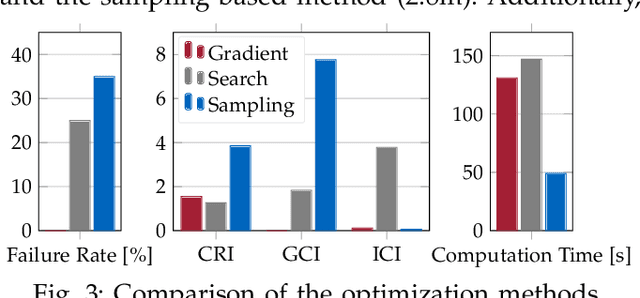
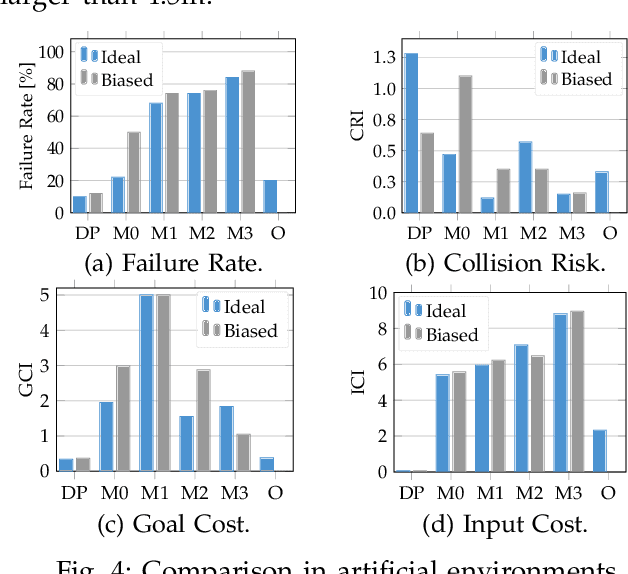
Autonomous systems with uncertainties are prevalent in robotics. However, ensuring the safety of those systems is challenging due to sophisticated dynamics and the hardness to predict future states. Usually, a classical motion planning method considering all possible states will not find a feasible path in crowded environments. To overcome this conservativeness, we propose a density-based method. The proposed method uses a neural network and the Liouville equation to learn the density evolution, and by applying a gradient-based optimization procedure, we can plan for feasible and probably safe trajectories to minimize the collision risk. We conduct experiments on simulated environments and environments generated from real-world data and outperform baseline methods such as model predictive control (MPC) and nonlinear programming (NLP). While our method requires planning time in advance, the online computational complexity is very low when compared to other methods.
Linear-Time Verification of Data-Aware Dynamic Systems with Arithmetic
Mar 15, 2022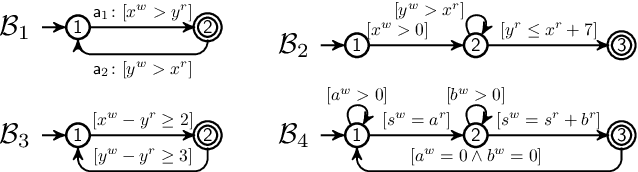
Combined modeling and verification of dynamic systems and the data they operate on has gained momentum in AI and in several application domains. We investigate the expressive yet concise framework of data-aware dynamic systems (DDS), extending it with linear arithmetic, and provide the following contributions. First, we introduce a new, semantic property of "finite summary", which guarantees the existence of a faithful finite-state abstraction. We rely on this to show that checking whether a witness exists for a linear-time, finite-trace property is decidable for DDSs with finite summary. Second, we demonstrate that several decidability conditions studied in formal methods and database theory can be seen as concrete, checkable instances of this property. This also gives rise to new decidability results. Third, we show how the abstract, uniform property of finite summary leads to modularity results: a system enjoys finite summary if it can be partitioned appropriately into smaller systems that possess the property. Our results allow us to analyze systems that were out of reach in earlier approaches. Finally, we demonstrate the feasibility of our approach in a prototype implementation.
AntidoteRT: Run-time Detection and Correction of Poison Attacks on Neural Networks
Jan 31, 2022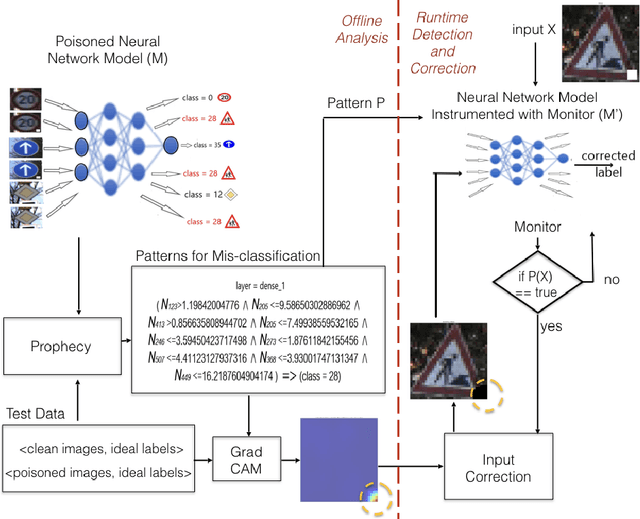


We study backdoor poisoning attacks against image classification networks, whereby an attacker inserts a trigger into a subset of the training data, in such a way that at test time, this trigger causes the classifier to predict some target class. %There are several techniques proposed in the literature that aim to detect the attack but only a few also propose to defend against it, and they typically involve retraining the network which is not always possible in practice. We propose lightweight automated detection and correction techniques against poisoning attacks, which are based on neuron patterns mined from the network using a small set of clean and poisoned test samples with known labels. The patterns built based on the mis-classified samples are used for run-time detection of new poisoned inputs. For correction, we propose an input correction technique that uses a differential analysis to identify the trigger in the detected poisoned images, which is then reset to a neutral color. Our detection and correction are performed at run-time and input level, which is in contrast to most existing work that is focused on offline model-level defenses. We demonstrate that our technique outperforms existing defenses such as NeuralCleanse and STRIP on popular benchmarks such as MNIST, CIFAR-10, and GTSRB against the popular BadNets attack and the more complex DFST attack.