 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
oViT: An Accurate Second-Order Pruning Framework for Vision Transformers
Oct 14, 2022
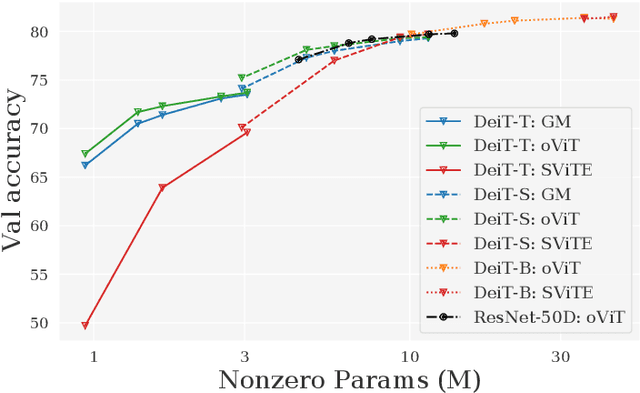
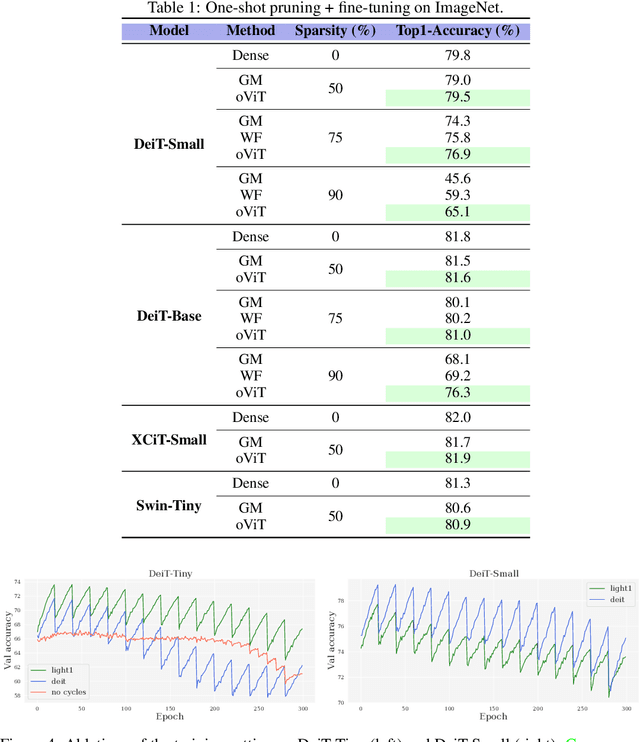
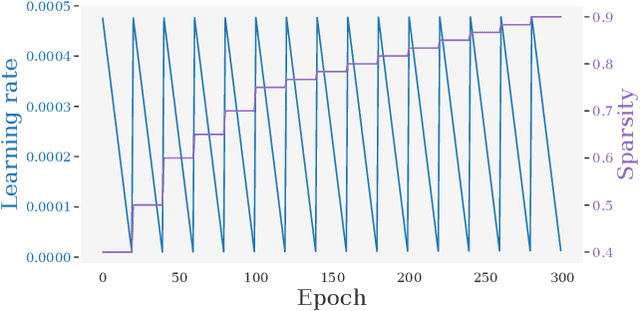
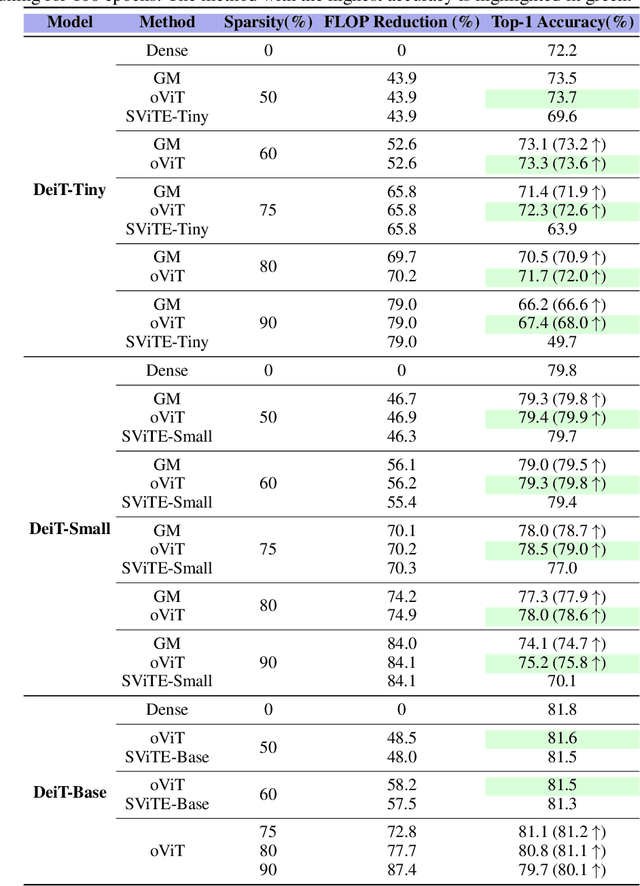
Models from the Vision Transformer (ViT) family have recently provided breakthrough results across image classification tasks such as ImageNet. Yet, they still face barriers to deployment, notably the fact that their accuracy can be severely impacted by compression techniques such as pruning. In this paper, we take a step towards addressing this issue by introducing Optimal ViT Surgeon (oViT), a new state-of-the-art method for the weight sparsification of Vision Transformers (ViT) models. At the technical level, oViT introduces a new weight pruning algorithm which leverages second-order information, specifically adapted to be both highly-accurate and efficient in the context of ViTs. We complement this accurate one-shot pruner with an in-depth investigation of gradual pruning, augmentation, and recovery schedules for ViTs, which we show to be critical for successful ViT compression. We validate our method via extensive experiments on classical ViT and DeiT models, as well as on newer variants, such as XCiT, EfficientFormer and Swin. Moreover, our results are even relevant to recently-proposed highly-accurate ResNets. Our results show for the first time that ViT-family models can in fact be pruned to high sparsity levels (e.g. $\geq 75\%$) with low impact on accuracy ($\leq 1\%$ relative drop), and that our approach outperforms prior methods by significant margins at high sparsities. In addition, we show that our method is compatible with structured pruning methods and quantization, and that it can lead to significant speedups on a sparsity-aware inference engine.
PL-$k$NN: A Parameterless Nearest Neighbors Classifier
Sep 26, 2022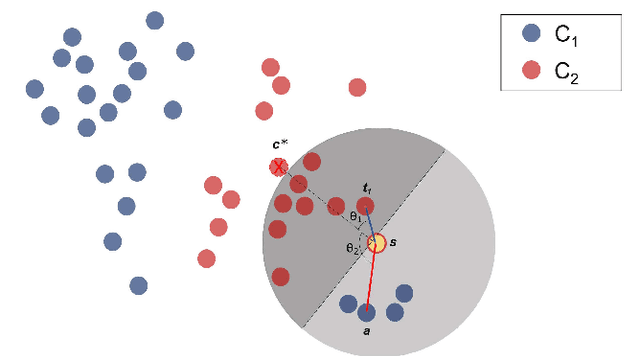
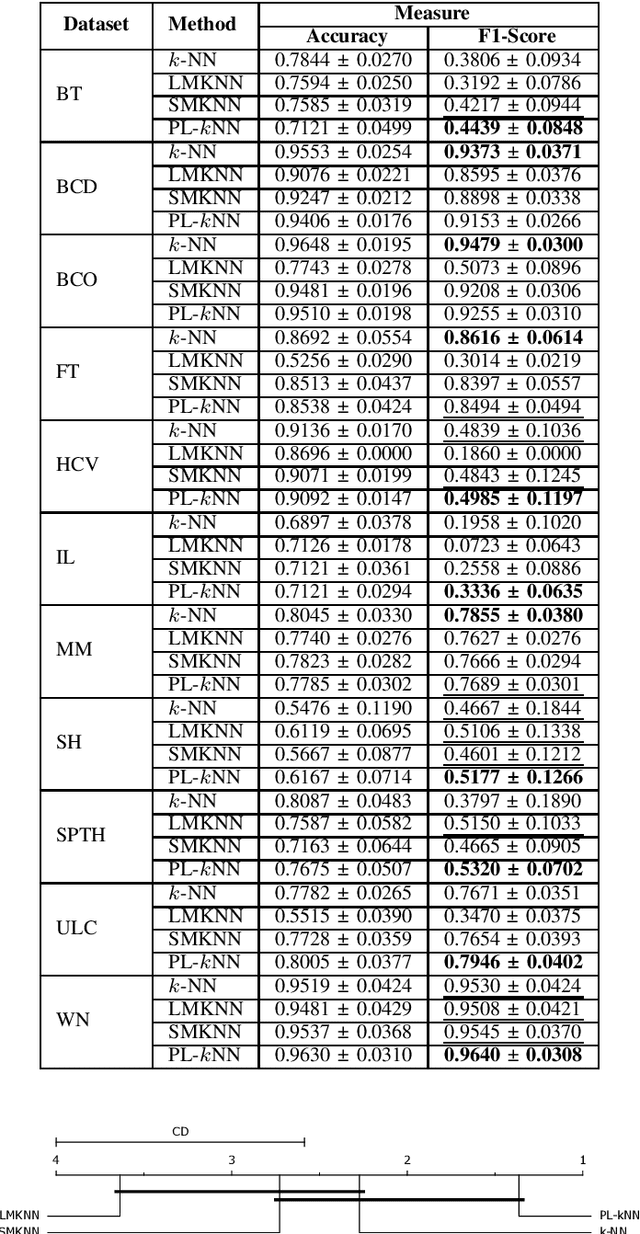
Demands for minimum parameter setup in machine learning models are desirable to avoid time-consuming optimization processes. The $k$-Nearest Neighbors is one of the most effective and straightforward models employed in numerous problems. Despite its well-known performance, it requires the value of $k$ for specific data distribution, thus demanding expensive computational efforts. This paper proposes a $k$-Nearest Neighbors classifier that bypasses the need to define the value of $k$. The model computes the $k$ value adaptively considering the data distribution of the training set. We compared the proposed model against the standard $k$-Nearest Neighbors classifier and two parameterless versions from the literature. Experiments over 11 public datasets confirm the robustness of the proposed approach, for the obtained results were similar or even better than its counterpart versions.
Are You Comfortable Now: Deep Learning the Temporal Variation in Thermal Comfort in Winters
Aug 20, 2022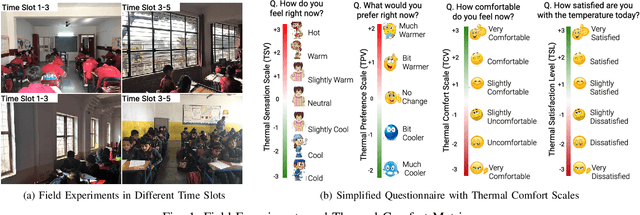

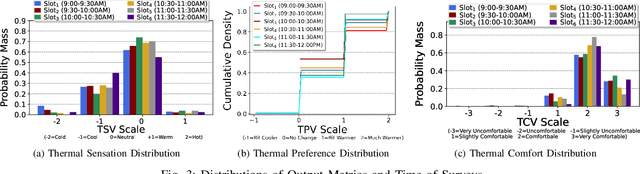
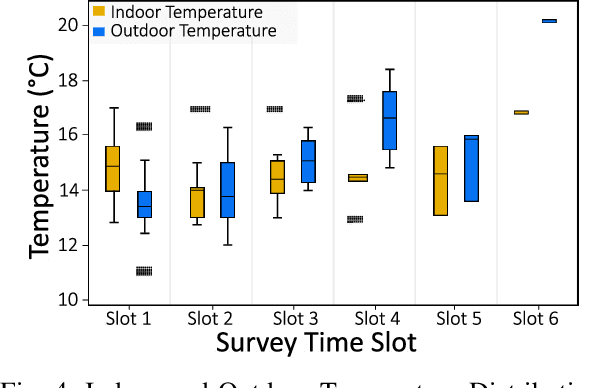
Indoor thermal comfort in smart buildings has a significant impact on the health and performance of occupants. Consequently, machine learning (ML) is increasingly used to solve challenges related to indoor thermal comfort. Temporal variability of thermal comfort perception is an important problem that regulates occupant well-being and energy consumption. However, in most ML-based thermal comfort studies, temporal aspects such as the time of day, circadian rhythm, and outdoor temperature are not considered. This work addresses these problems. It investigates the impact of circadian rhythm and outdoor temperature on the prediction accuracy and classification performance of ML models. The data is gathered through month-long field experiments carried out in 14 classrooms of 5 schools, involving 512 primary school students. Four thermal comfort metrics are considered as the outputs of Deep Neural Networks and Support Vector Machine models for the dataset. The effect of temporal variability on school children's comfort is shown through a "time of day" analysis. Temporal variability in prediction accuracy is demonstrated (up to 80%). Furthermore, we show that outdoor temperature (varying over time) positively impacts the prediction performance of thermal comfort models by up to 30%. The importance of spatio-temporal context is demonstrated by contrasting micro-level (location specific) and macro-level (6 locations across a city) performance. The most important finding of this work is that a definitive improvement in prediction accuracy is shown with an increase in the time of day and sky illuminance, for multiple thermal comfort metrics.
Augmentations in Hypergraph Contrastive Learning: Fabricated and Generative
Oct 07, 2022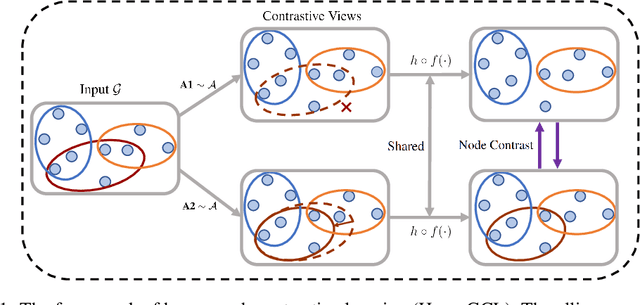

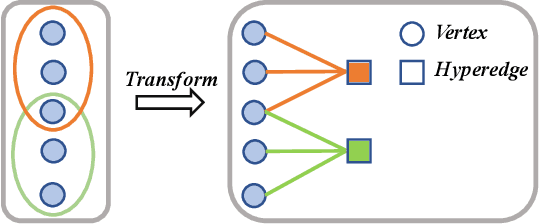

This paper targets at improving the generalizability of hypergraph neural networks in the low-label regime, through applying the contrastive learning approach from images/graphs (we refer to it as HyperGCL). We focus on the following question: How to construct contrastive views for hypergraphs via augmentations? We provide the solutions in two folds. First, guided by domain knowledge, we fabricate two schemes to augment hyperedges with higher-order relations encoded, and adopt three vertex augmentation strategies from graph-structured data. Second, in search of more effective views in a data-driven manner, we for the first time propose a hypergraph generative model to generate augmented views, and then an end-to-end differentiable pipeline to jointly learn hypergraph augmentations and model parameters. Our technical innovations are reflected in designing both fabricated and generative augmentations of hypergraphs. The experimental findings include: (i) Among fabricated augmentations in HyperGCL, augmenting hyperedges provides the most numerical gains, implying that higher-order information in structures is usually more downstream-relevant; (ii) Generative augmentations do better in preserving higher-order information to further benefit generalizability; (iii) HyperGCL also boosts robustness and fairness in hypergraph representation learning. Codes are released at https://github.com/weitianxin/HyperGCL.
Integration of Riemannian Motion Policy and Whole-Body Control for Dynamic Legged Locomotion
Oct 07, 2022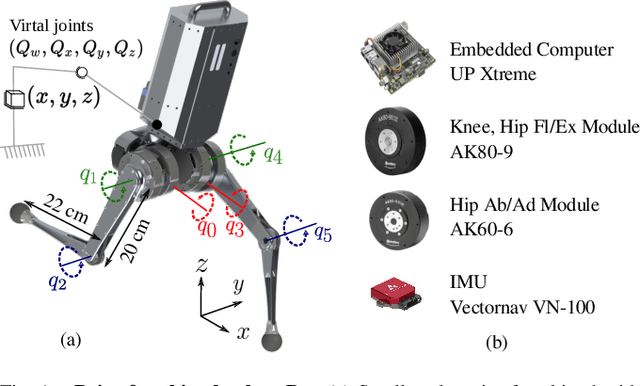
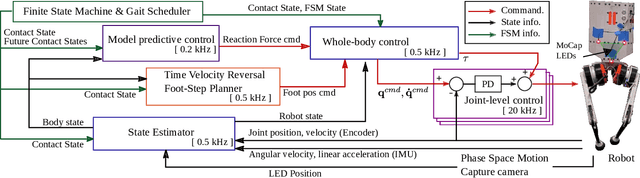
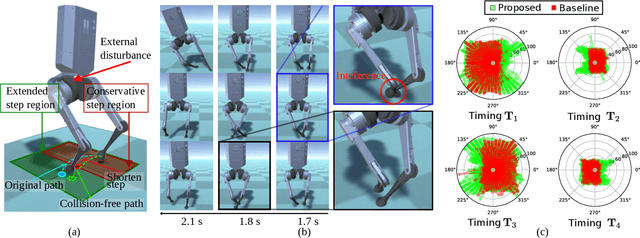
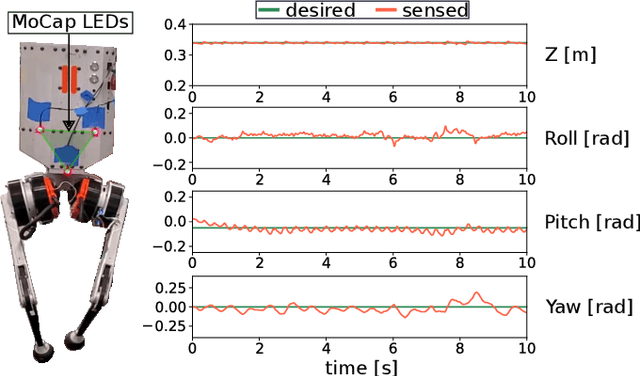
In this paper, we present a novel Riemannian Motion Policy (RMP)flow-based whole-body control framework for improved dynamic legged locomotion. RMPflow is a differential geometry-inspired algorithm for fusing multiple task-space policies (RMPs) into a configuration space policy in a geometrically consistent manner. RMP-based approaches are especially suited for designing simultaneous tracking and collision avoidance behaviors and have been successfully deployed on serial manipulators. However, one caveat of RMPflow is that it is designed with fully actuated systems in mind. In this work, we, for the first time, extend it to the domain of dynamic-legged systems, which have unforgiving under-actuation and limited control input. Thorough push recovery experiments are conducted in simulation to validate the overall framework. We show that expanding the valid stepping region with an RMP-based collision-avoidance swing leg controller improves balance robustness against external disturbances by up to $53\%$ compared to a baseline approach using a restricted stepping region. Furthermore, a point-foot biped robot is purpose-built for experimental studies of dynamic biped locomotion. A preliminary unassisted in-place stepping experiment is conducted to show the viability of the control framework and hardware.
Simulating single-photon detector array sensors for depth imaging
Oct 07, 2022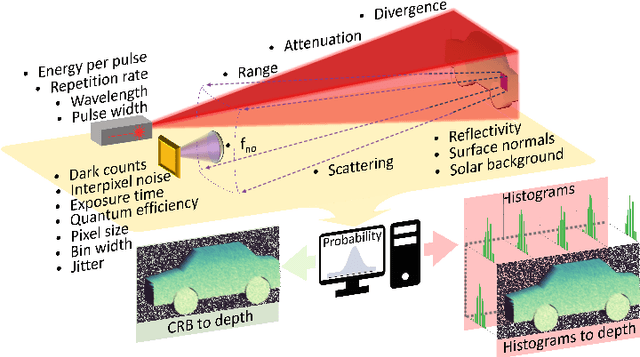
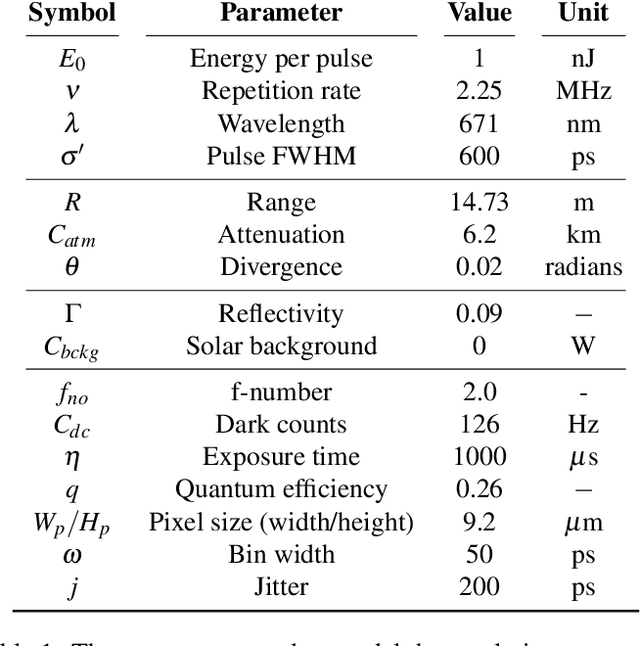
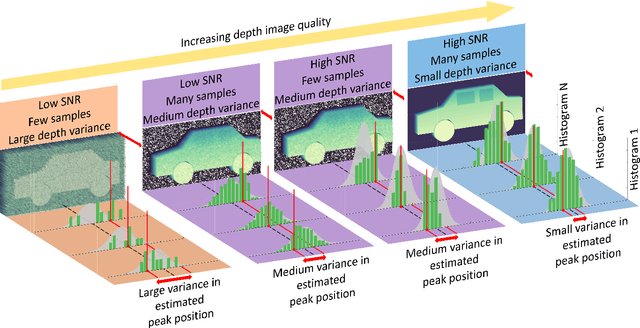
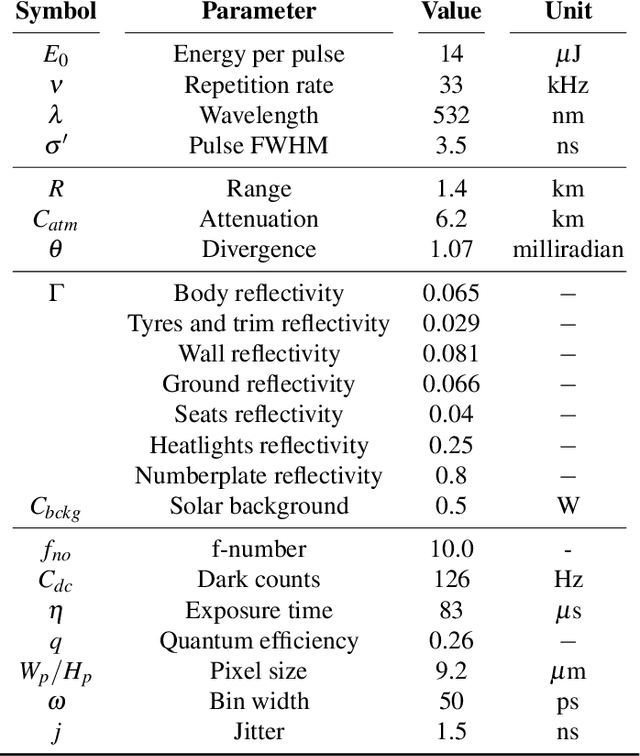
Single-Photon Avalanche Detector (SPAD) arrays are a rapidly emerging technology. These multi-pixel sensors have single-photon sensitivities and pico-second temporal resolutions thus they can rapidly generate depth images with millimeter precision. Such sensors are a key enabling technology for future autonomous systems as they provide guidance and situational awareness. However, to fully exploit the capabilities of SPAD array sensors, it is crucial to establish the quality of depth images they are able to generate in a wide range of scenarios. Given a particular optical system and a finite image acquisition time, what is the best-case depth resolution and what are realistic images generated by SPAD arrays? In this work, we establish a robust yet simple numerical procedure that rapidly establishes the fundamental limits to depth imaging with SPAD arrays under real world conditions. Our approach accurately generates realistic depth images in a wide range of scenarios, allowing the performance of an optical depth imaging system to be established without the need for costly and laborious field testing. This procedure has applications in object detection and tracking for autonomous systems and could be easily extended to systems for underwater imaging or for imaging around corners.
Research on Self-adaptive Online Vehicle Velocity Prediction Strategy Considering Traffic Information Fusion
Oct 07, 2022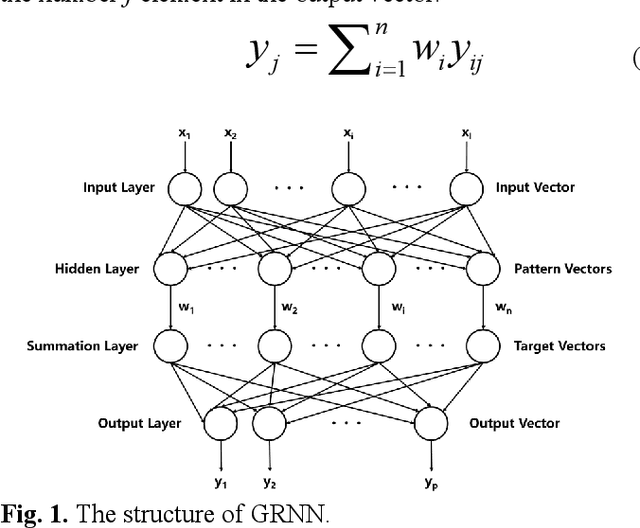
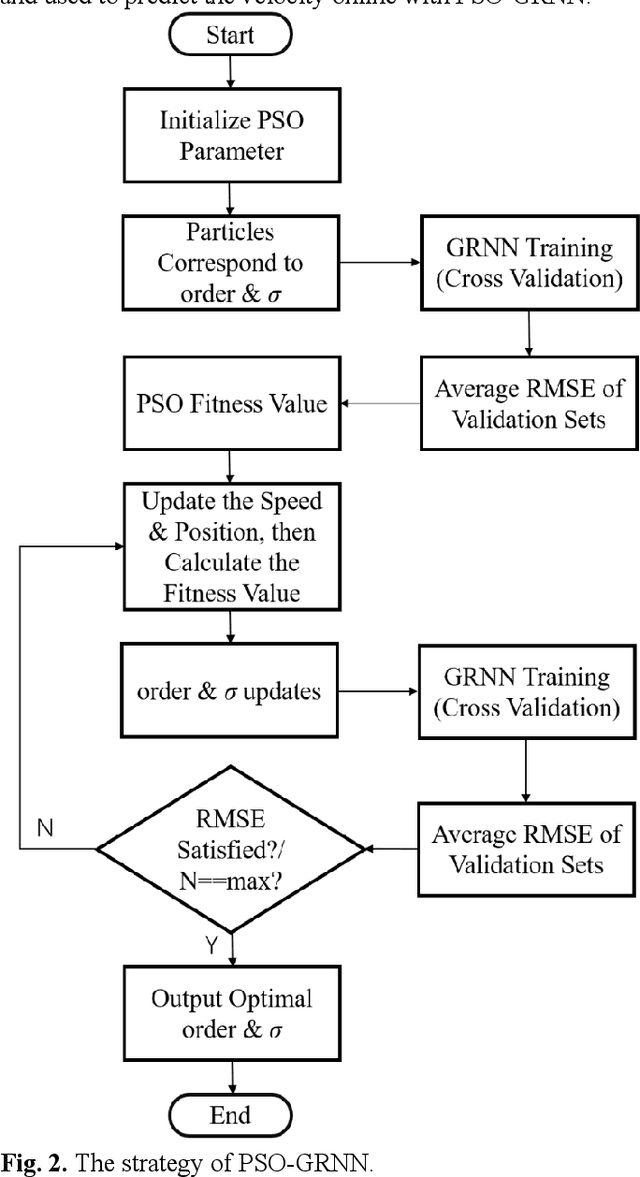
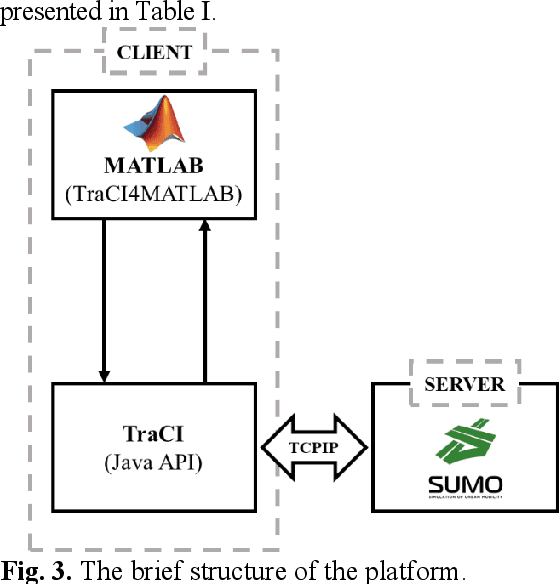
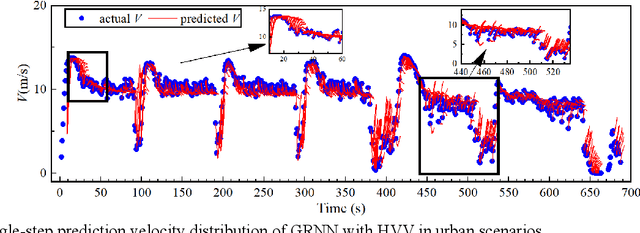
In order to increase the prediction accuracy of the online vehicle velocity prediction (VVP) strategy, a self-adaptive velocity prediction algorithm fused with traffic information was presented for the multiple scenarios. Initially, traffic scenarios were established inside the co-simulation environment. In addition, the algorithm of a general regressive neural network (GRNN) paired with datasets of the ego-vehicle, the front vehicle, and traffic lights was used in traffic scenarios, which increasingly improved the prediction accuracy. To ameliorate the robustness of the algorithm, then the strategy was optimized by particle swarm optimization (PSO) and k-fold cross-validation to find the optimal parameters of the neural network in real-time, which constructed a self-adaptive online PSO-GRNN VVP strategy with multi-information fusion to adapt with different operating situations. The self-adaptive online PSO-GRNN VVP strategy was then deployed to a variety of simulated scenarios to test its efficacy under various operating situations. Finally, the simulation results reveal that in urban and highway scenarios, the prediction accuracy is separately increased by 27.8% and 54.5% when compared to the traditional GRNN VVP strategy with fixed parameters utilizing only the historical ego-vehicle velocity dataset.
Model-based estimation of in-car-communication feedback applied to speech zone detection
Oct 07, 2022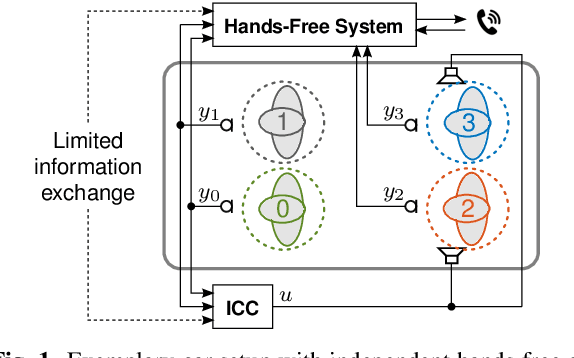
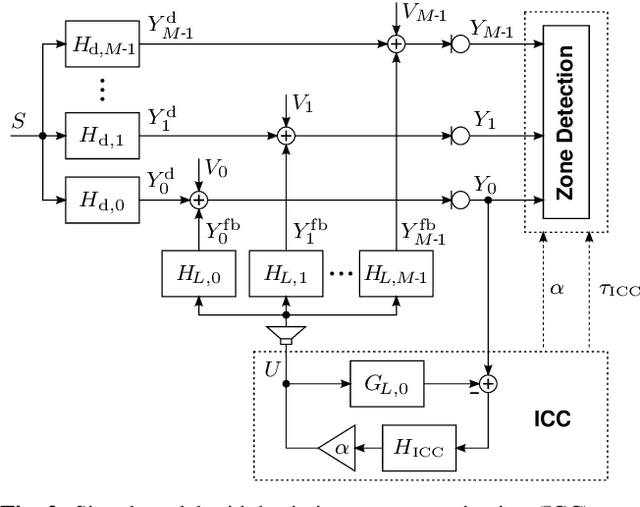

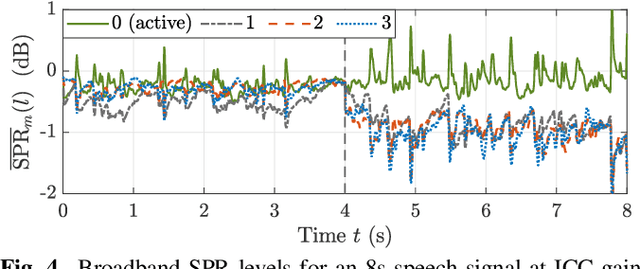
Modern cars provide versatile tools to enhance speech communication. While an in-car communication (ICC) system aims at enhancing communication between the passengers by playing back desired speech via loudspeakers in the car, these loudspeaker signals may disturb a speech enhancement system required for hands-free telephony and automatic speech recognition. In this paper, we focus on speech zone detection, i.e. detecting which passenger in the car is speaking, which is a crucial component of the speech enhancement system. We propose a model-based feedback estimation method to improve robustness of speech zone detection against ICC feedback. Specifically, since the zone detection system typically does not have access to the ICC loudspeaker signals, the proposed method estimates the feedback signal from the observed microphone signals based on a free-field propagation model between the loudspeakers and the microphones as well as the ICC gain. We propose an efficient recursive implementation in the short-time Fourier transform domain using convolutive transfer functions. A realistic simulation study indicates that the proposed method allows to increase the ICC gain by about 6dB while still achieving robust speech zone detection results.
Population-Based Reinforcement Learning for Combinatorial Optimization
Oct 07, 2022
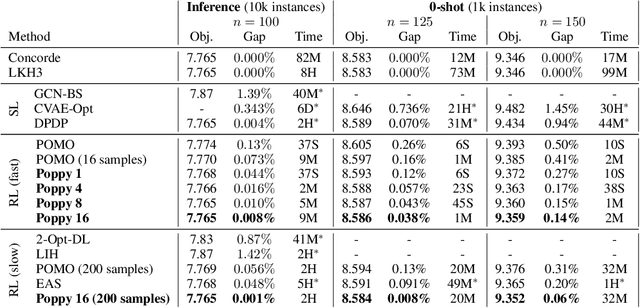
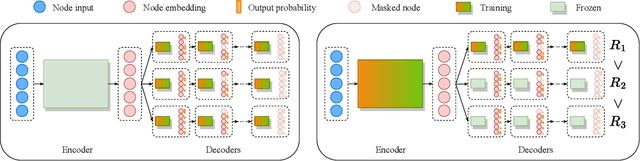
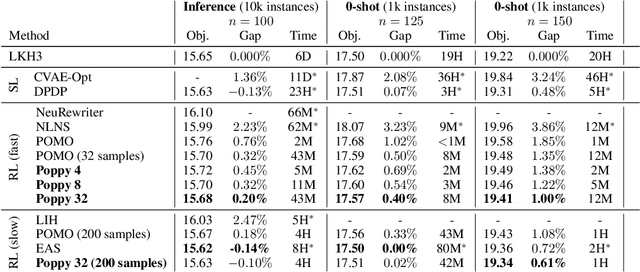
Applying reinforcement learning (RL) to combinatorial optimization problems is attractive as it removes the need for expert knowledge or pre-solved instances. However, it is unrealistic to expect an agent to solve these (often NP-)hard problems in a single shot at inference due to their inherent complexity. Thus, leading approaches often implement additional search strategies, from stochastic sampling and beam-search to explicit fine-tuning. In this paper, we argue for the benefits of learning a population of complementary policies, which can be simultaneously rolled out at inference. To this end, we introduce Poppy, a simple theoretically grounded training procedure for populations. Instead of relying on a predefined or hand-crafted notion of diversity, Poppy induces an unsupervised specialization targeted solely at maximizing the performance of the population. We show that Poppy produces a set of complementary policies, and obtains state-of-the-art RL results on three popular NP-hard problems: the traveling salesman (TSP), the capacitated vehicle routing (CVRP), and 0-1 knapsack (KP) problems. On TSP specifically, Poppy outperforms the previous state-of-the-art, dividing the optimality gap by 5 while reducing the inference time by more than an order of magnitude.
High Resolution Spatio-Temporal Model for Room-Level Airborne Pandemic Spread
Oct 07, 2022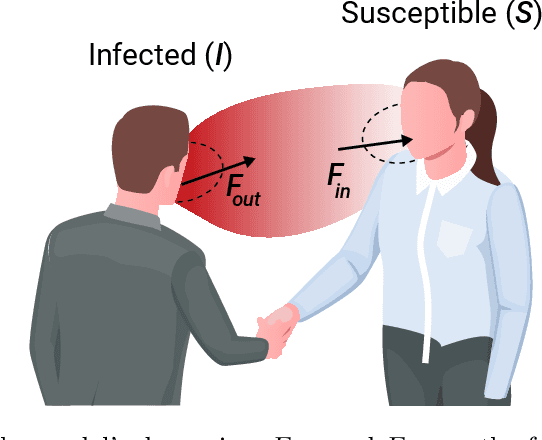
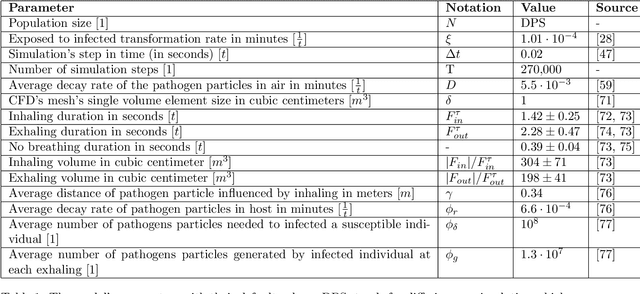
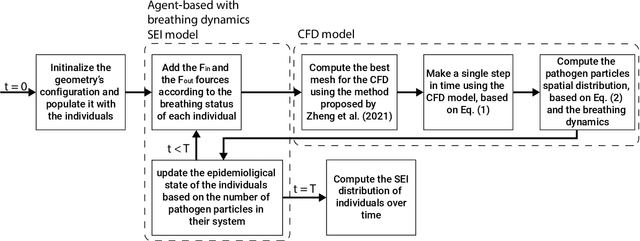
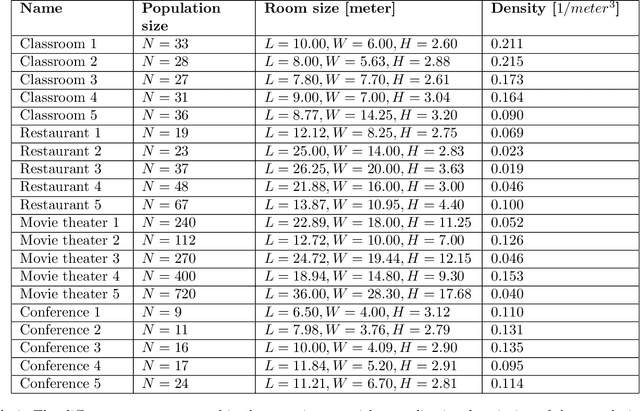
Airborne pandemics have caused millions of deaths worldwide, large-scale economic losses, and catastrophic sociological shifts in human history. Researchers have developed multiple mathematical models and computational frameworks to investigate and predict the pandemic spread on various levels and scales such as countries, cities, large social events, and even buildings. However, modeling attempts of airborne pandemic dynamics on the smallest scale, a single room, have been mostly neglected. As time indoors increases due to global urbanization processes, more infections occur in shared rooms. In this study, a high-resolution spatio-temporal epidemiological model with airflow dynamics to evaluate airborne pandemic spread is proposed. The model is implemented using high-resolution 3D data obtained using a light detection and ranging (LiDAR) device and computing the model based on the Computational Fluid Dynamics (CFD) model for the airflow and the Susceptible-Exposed-Infected (SEI) model for the epidemiological dynamics. The pandemic spread is evaluated in four types of rooms, showing significant differences even for a short exposure duration. We show that the room's topology and individual distribution in the room define the ability of air ventilation to reduce pandemic spread throughout breathing zone infection.