 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Faster Neighborhood Attention: Reducing the O(n^2) Cost of Self Attention at the Threadblock Level
Mar 07, 2024
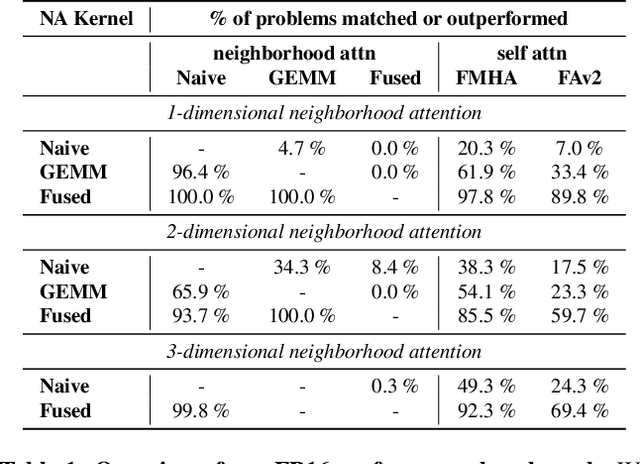
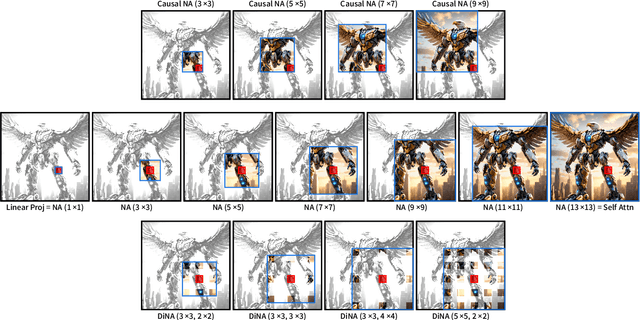
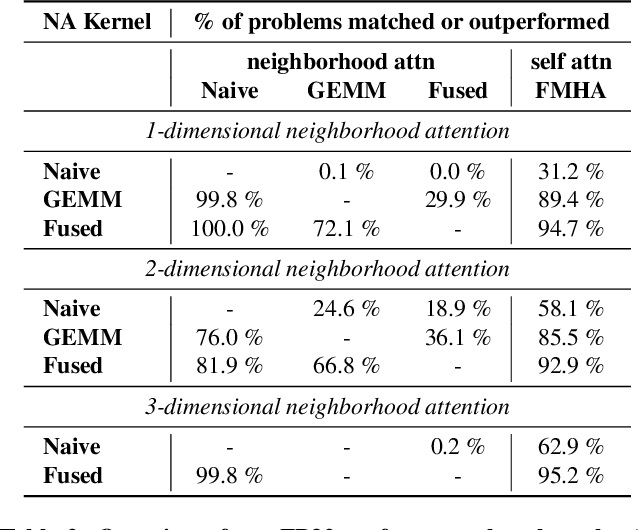
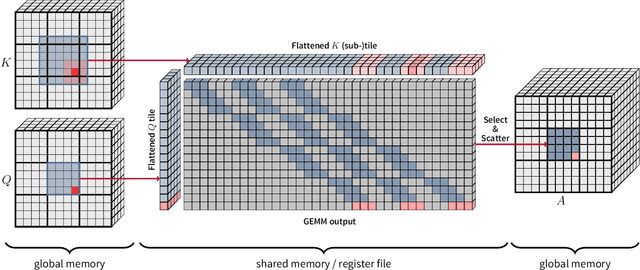
Neighborhood attention reduces the cost of self attention by restricting each token's attention span to its nearest neighbors. This restriction, parameterized by a window size and dilation factor, draws a spectrum of possible attention patterns between linear projection and self attention. Neighborhood attention, and more generally sliding window attention patterns, have long been bounded by infrastructure, particularly in higher-rank spaces (2-D and 3-D), calling for the development of custom kernels, which have been limited in either functionality, or performance, if not both. In this work, we first show that neighborhood attention can be represented as a batched GEMM problem, similar to standard attention, and implement it for 1-D and 2-D neighborhood attention. These kernels on average provide 895% and 272% improvement in full precision latency compared to existing naive kernels for 1-D and 2-D neighborhood attention respectively. We find certain inherent inefficiencies in all unfused neighborhood attention kernels that bound their performance and lower-precision scalability. We also developed fused neighborhood attention; an adaptation of fused dot-product attention kernels that allow fine-grained control over attention across different spatial axes. Known for reducing the quadratic time complexity of self attention to a linear complexity, neighborhood attention can now enjoy a reduced and constant memory footprint, and record-breaking half precision latency. We observe that our fused kernels successfully circumvent some of the unavoidable inefficiencies in unfused implementations. While our unfused GEMM-based kernels only improve half precision performance compared to naive kernels by an average of 496% and 113% in 1-D and 2-D problems respectively, our fused kernels improve naive kernels by an average of 1607% and 581% in 1-D and 2-D problems respectively.
A Comparative Study of Rapidly-exploring Random Tree Algorithms Applied to Ship Trajectory Planning and Behavior Generation
Mar 02, 2024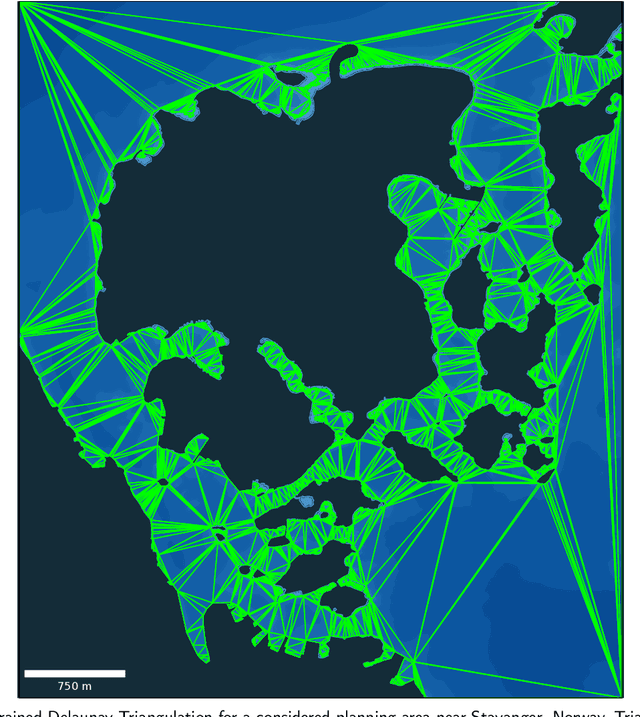
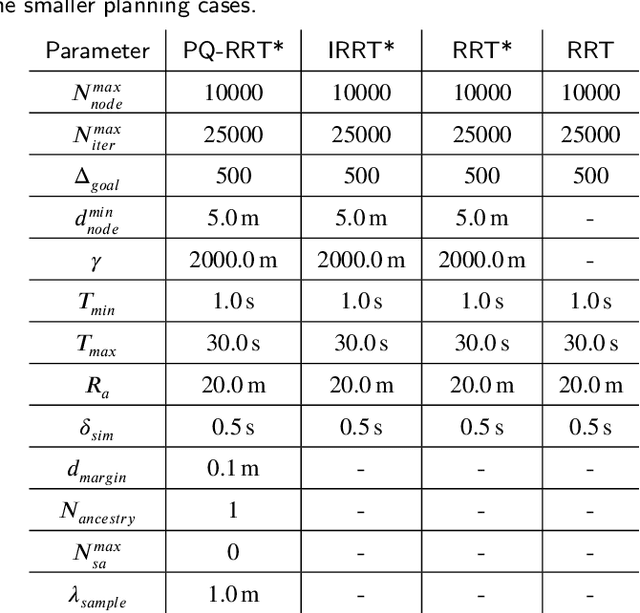
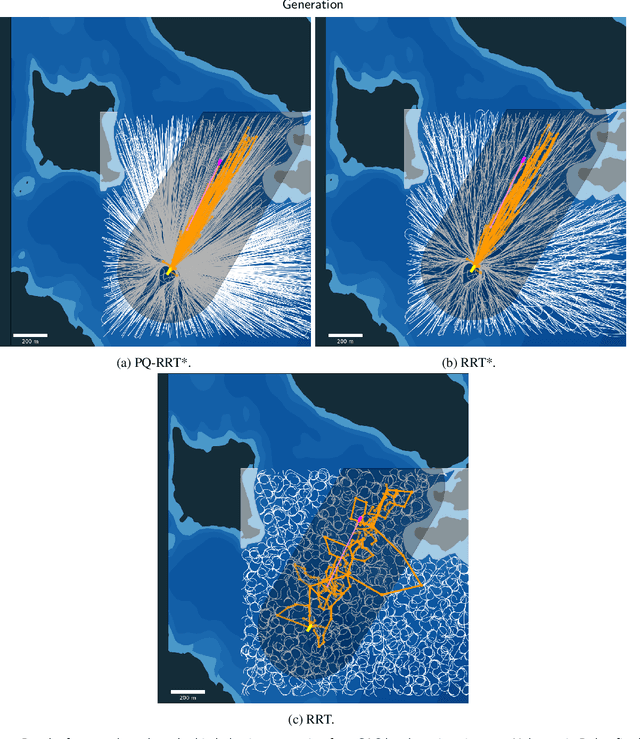
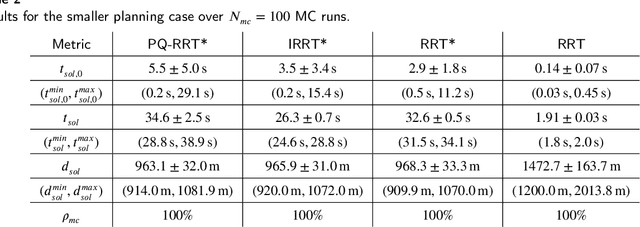
Rapidly Exploring Random Tree (RRT) algorithms are popular for sampling-based planning for nonholonomic vehicles in unstructured environments. However, we argue that previous work does not illuminate the challenges when employing such algorithms. Thus, in this article, we do a first comparison study of the performance of the following previously proposed RRT algorithm variants; Potential-Quick RRT* (PQ-RRT*), Informed RRT* (IRRT*), RRT* and RRT, for single-query nonholonomic motion planning over several cases in the unstructured maritime environment. The practicalities of employing such algorithms in the maritime domain are also discussed. On the side, we contend that these algorithms offer value not only for Collision Avoidance Systems (CAS) trajectory planning, but also for the verification of CAS through vessel behavior generation. Naturally, optimal RRT variants yield more distance-optimal paths at the cost of increased computational time due to the tree wiring process with nearest neighbor consideration. PQ-RRT* achieves marginally better results than IRRT* and RRT*, at the cost of higher tuning complexity and increased wiring time. Based on the results, we argue that for time-critical applications the considered RRT algorithms are, as stand-alone planners, more suitable for use in smaller problems or problems with low obstacle congestion ratio. This is attributed to the curse of dimensionality, and trade-off with available memory and computational resources.
LiSTA: Geometric Object-Based Change Detection in Cluttered Environments
Mar 05, 2024
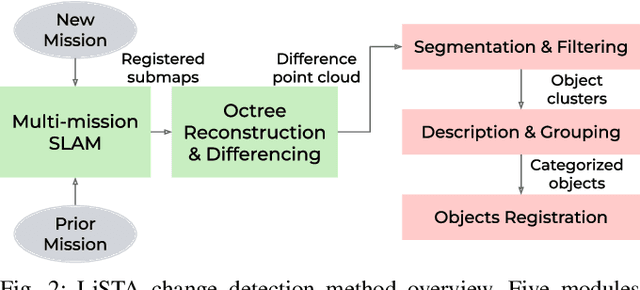
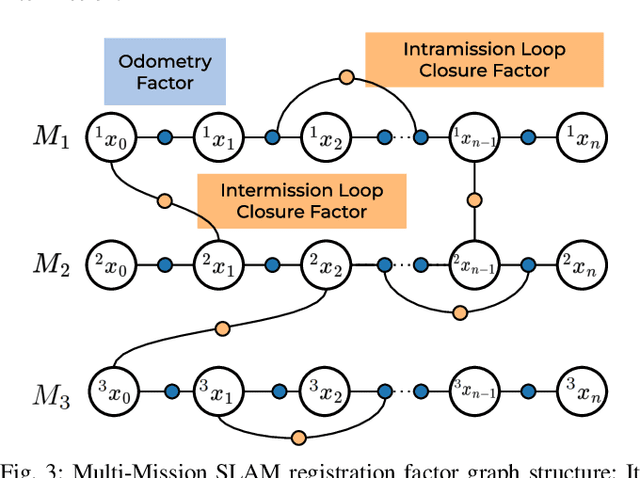

We present LiSTA (LiDAR Spatio-Temporal Analysis), a system to detect probabilistic object-level change over time using multi-mission SLAM. Many applications require such a system, including construction, robotic navigation, long-term autonomy, and environmental monitoring. We focus on the semi-static scenario where objects are added, subtracted, or changed in position over weeks or months. Our system combines multi-mission LiDAR SLAM, volumetric differencing, object instance description, and correspondence grouping using learned descriptors to keep track of an open set of objects. Object correspondences between missions are determined by clustering the object's learned descriptors. We demonstrate our approach using datasets collected in a simulated environment and a real-world dataset captured using a LiDAR system mounted on a quadruped robot monitoring an industrial facility containing static, semi-static, and dynamic objects. Our method demonstrates superior performance in detecting changes in semi-static environments compared to existing methods.
Learning Method for S4 with Diagonal State Space Layers using Balanced Truncation
Mar 05, 2024We introduce a novel learning method for Structured State Space Sequence (S4) models incorporating Diagonal State Space (DSS) layers, tailored for processing long-sequence data in edge intelligence applications, including sensor data analysis and real-time analytics. This method utilizes the balanced truncation, a prevalent model reduction technique in control theory, applied specifically to DSS layers to reduce computational costs during inference. By leveraging parameters from the reduced model, we refine the initialization process of S4 models, outperforming the widely used Skew-HiPPO initialization in terms of performance. Numerical experiments demonstrate that our trained S4 models with DSS layers surpass conventionally trained models in accuracy and efficiency metrics. Furthermore, our observations reveal a positive correlation: higher accuracy in the original model consistently leads to increased accuracy in models trained using our method, suggesting that our approach effectively leverages the strengths of the original model.
VQSynery: Robust Drug Synergy Prediction With Vector Quantization Mechanism
Mar 05, 2024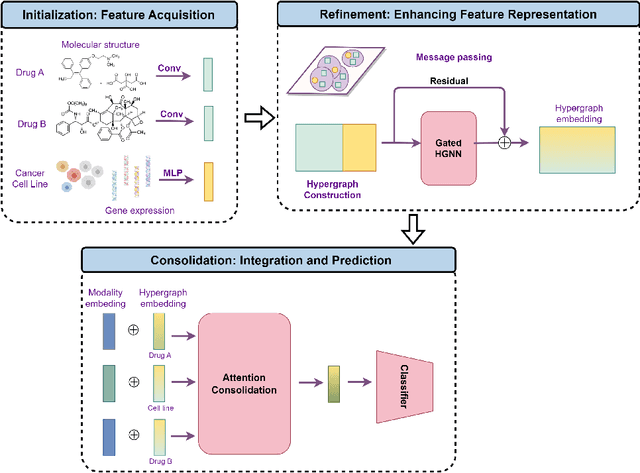

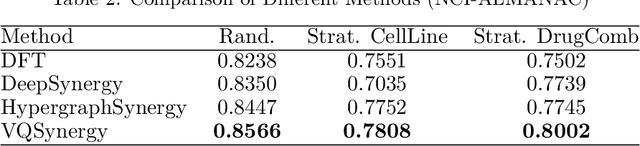
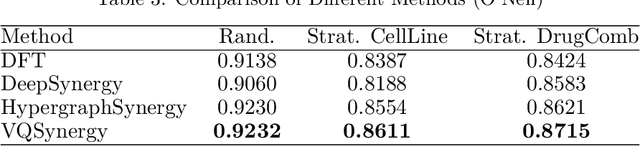
The pursuit of optimizing cancer therapies is significantly advanced by the accurate prediction of drug synergy. Traditional methods, such as clinical trials, are reliable yet encumbered by extensive time and financial demands. The emergence of high-throughput screening and computational innovations has heralded a shift towards more efficient methodologies for exploring drug interactions. In this study, we present VQSynergy, a novel framework that employs the Vector Quantization (VQ) mechanism, integrated with gated residuals and a tailored attention mechanism, to enhance the precision and generalizability of drug synergy predictions. Our findings demonstrate that VQSynergy surpasses existing models in terms of robustness, particularly under Gaussian noise conditions, highlighting its superior performance and utility in the complex and often noisy domain of drug synergy research. This study underscores the potential of VQSynergy in revolutionizing the field through its advanced predictive capabilities, thereby contributing to the optimization of cancer treatment strategies.
Solution Simplex Clustering for Heterogeneous Federated Learning
Mar 05, 2024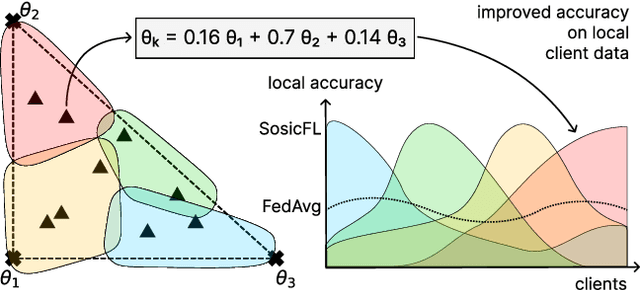

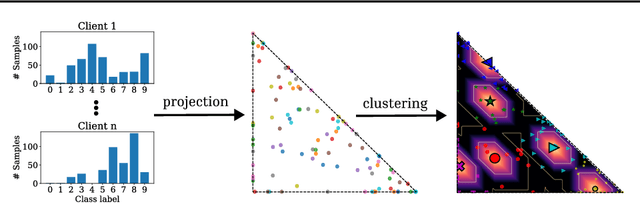
We tackle a major challenge in federated learning (FL) -- achieving good performance under highly heterogeneous client distributions. The difficulty partially arises from two seemingly contradictory goals: learning a common model by aggregating the information from clients, and learning local personalized models that should be adapted to each local distribution. In this work, we propose Solution Simplex Clustered Federated Learning (SosicFL) for dissolving such contradiction. Based on the recent ideas of learning solution simplices, SosicFL assigns a subregion in a simplex to each client, and performs FL to learn a common solution simplex. This allows the client models to possess their characteristics within the degrees of freedom in the solution simplex, and at the same time achieves the goal of learning a global common model. Our experiments show that SosicFL improves the performance and accelerates the training process for global and personalized FL with minimal computational overhead.
F$^3$Loc: Fusion and Filtering for Floorplan Localization
Mar 05, 2024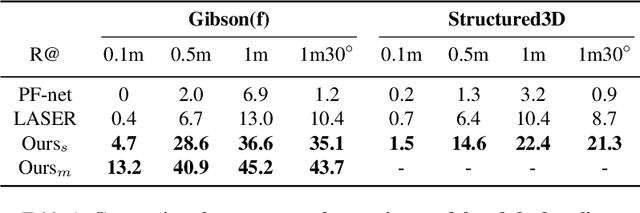
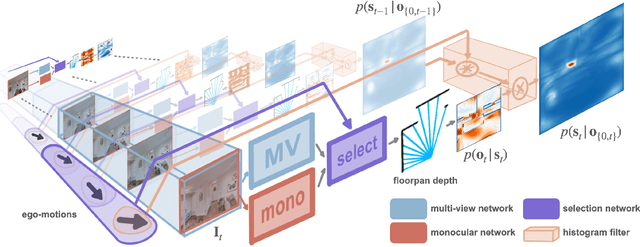
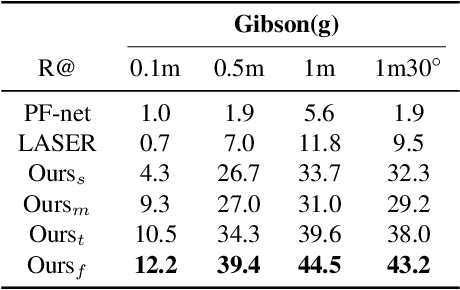
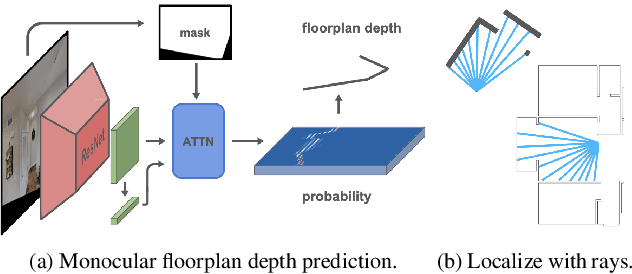
In this paper we propose an efficient data-driven solution to self-localization within a floorplan. Floorplan data is readily available, long-term persistent and inherently robust to changes in the visual appearance. Our method does not require retraining per map and location or demand a large database of images of the area of interest. We propose a novel probabilistic model consisting of an observation and a novel temporal filtering module. Operating internally with an efficient ray-based representation, the observation module consists of a single and a multiview module to predict horizontal depth from images and fuses their results to benefit from advantages offered by either methodology. Our method operates on conventional consumer hardware and overcomes a common limitation of competing methods that often demand upright images. Our full system meets real-time requirements, while outperforming the state-of-the-art by a significant margin.
When Only Time Will Tell: Interpreting How Transformers Process Local Ambiguities Through the Lens of Restart-Incrementality
Feb 20, 2024Incremental models that process sentences one token at a time will sometimes encounter points where more than one interpretation is possible. Causal models are forced to output one interpretation and continue, whereas models that can revise may edit their previous output as the ambiguity is resolved. In this work, we look at how restart-incremental Transformers build and update internal states, in an effort to shed light on what processes cause revisions not viable in autoregressive models. We propose an interpretable way to analyse the incremental states, showing that their sequential structure encodes information on the garden path effect and its resolution. Our method brings insights on various bidirectional encoders for contextualised meaning representation and dependency parsing, contributing to show their advantage over causal models when it comes to revisions.
HyperPredict: Estimating Hyperparameter Effects for Instance-Specific Regularization in Deformable Image Registration
Mar 04, 2024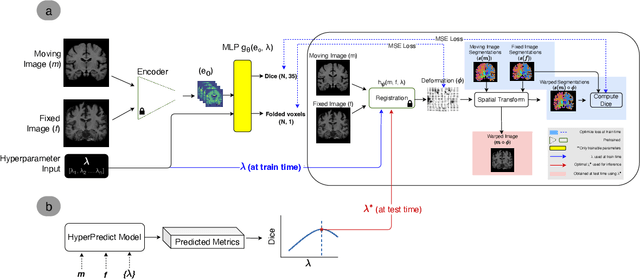

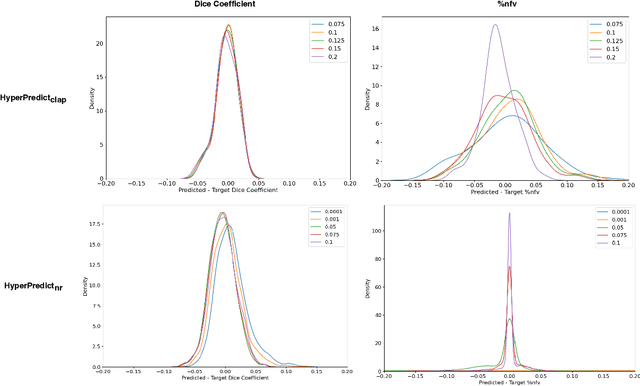
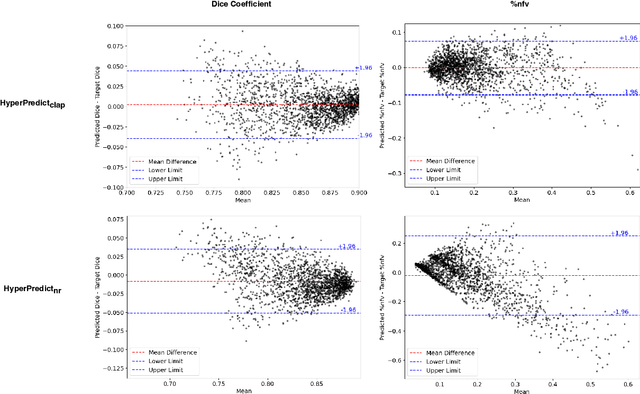
Methods for medical image registration infer geometric transformations that align pairs/groups of images by maximising an image similarity metric. This problem is ill-posed as several solutions may have equivalent likelihoods, also optimising purely for image similarity can yield implausible transformations. For these reasons regularization terms are essential to obtain meaningful registration results. However, this requires the introduction of at least one hyperparameter often termed {\lambda}, that serves as a tradeoff between loss terms. In some situations, the quality of the estimated transformation greatly depends on hyperparameter choice, and different choices may be required depending on the characteristics of the data. Analyzing the effect of these hyperparameters requires labelled data, which is not commonly available at test-time. In this paper, we propose a method for evaluating the influence of hyperparameters and subsequently selecting an optimal value for given image pairs. Our approach which we call HyperPredict, implements a Multi-Layer Perceptron that learns the effect of selecting particular hyperparameters for registering an image pair by predicting the resulting segmentation overlap and measure of deformation smoothness. This approach enables us to select optimal hyperparameters at test time without requiring labelled data, removing the need for a one-size-fits-all cross-validation approach. Furthermore, the criteria used to define optimal hyperparameter is flexible post-training, allowing us to efficiently choose specific properties. We evaluate our proposed method on the OASIS brain MR dataset using a recent deep learning approach(cLapIRN) and an algorithmic method(Niftyreg). Our results demonstrate good performance in predicting the effects of regularization hyperparameters and highlight the benefits of our image-pair specific approach to hyperparameter selection.
Transformer for Times Series: an Application to the S&P500
Mar 04, 2024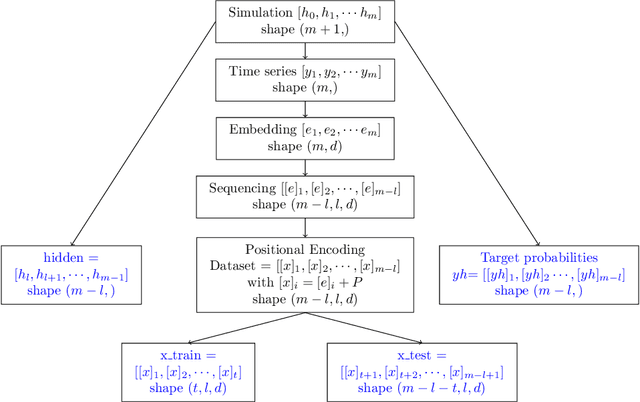

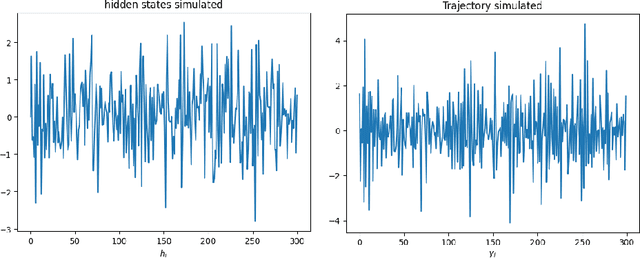
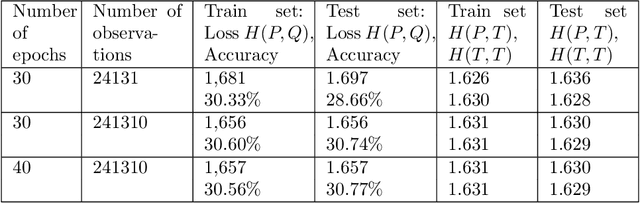
The transformer models have been extensively used with good results in a wide area of machine learning applications including Large Language Models and image generation. Here, we inquire on the applicability of this approach to financial time series. We first describe the dataset construction for two prototypical situations: a mean reverting synthetic Ornstein-Uhlenbeck process on one hand and real S&P500 data on the other hand. Then, we present in detail the proposed Transformer architecture and finally we discuss some encouraging results. For the synthetic data we predict rather accurately the next move, and for the S&P500 we get some interesting results related to quadratic variation and volatility prediction.