 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
STDAN: Deformable Attention Network for Space-Time Video Super-Resolution
Mar 14, 2022

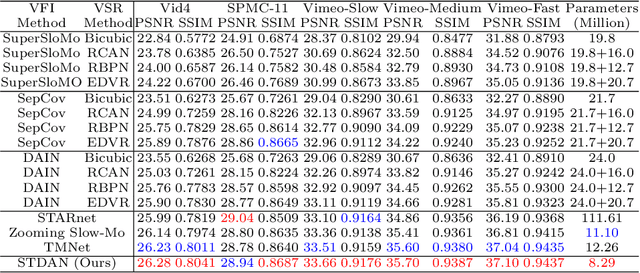
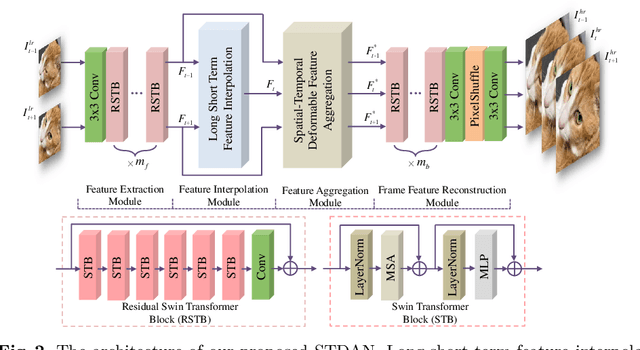
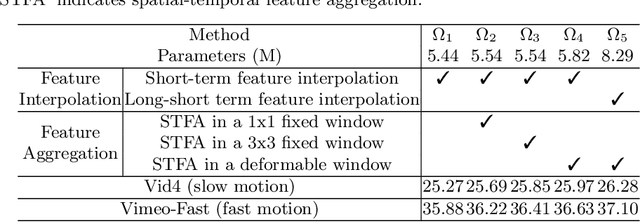
The target of space-time video super-resolution (STVSR) is to increase the spatial-temporal resolution of low-resolution (LR) and low frame rate (LFR) videos. Recent approaches based on deep learning have made significant improvements, but most of them only use two adjacent frames, that is, short-term features, to synthesize the missing frame embedding, which suffers from fully exploring the information flow of consecutive input LR frames. In addition, existing STVSR models hardly exploit the temporal contexts explicitly to assist high-resolution (HR) frame reconstruction. To address these issues, in this paper, we propose a deformable attention network called STDAN for STVSR. First, we devise a long-short term feature interpolation (LSTFI) module, which is capable of excavating abundant content from more neighboring input frames for the interpolation process through a bidirectional RNN structure. Second, we put forward a spatial-temporal deformable feature aggregation (STDFA) module, in which spatial and temporal contexts in dynamic video frames are adaptively captured and aggregated to enhance SR reconstruction. Experimental results on several datasets demonstrate that our approach outperforms state-of-the-art STVSR methods.
Exploring Low Rank Training of Deep Neural Networks
Sep 27, 2022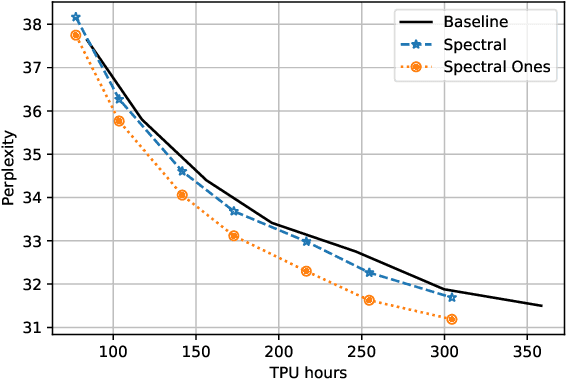

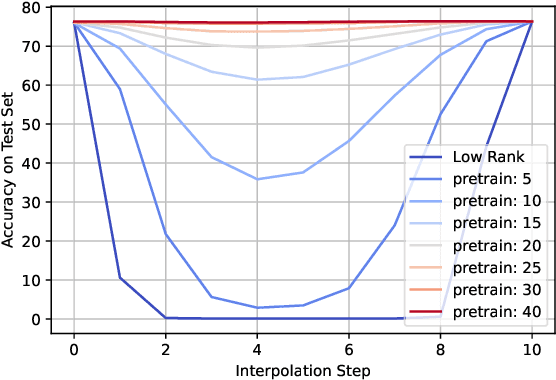
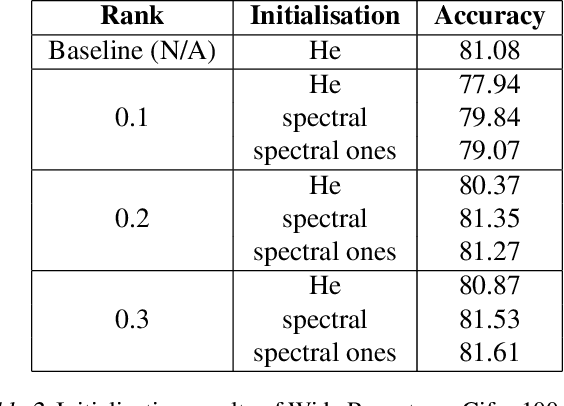
Training deep neural networks in low rank, i.e. with factorised layers, is of particular interest to the community: it offers efficiency over unfactorised training in terms of both memory consumption and training time. Prior work has focused on low rank approximations of pre-trained networks and training in low rank space with additional objectives, offering various ad hoc explanations for chosen practice. We analyse techniques that work well in practice, and through extensive ablations on models such as GPT2 we provide evidence falsifying common beliefs in the field, hinting in the process at exciting research opportunities that still need answering.
Semantic Clustering of a Sequence of Satellite Images
Aug 29, 2022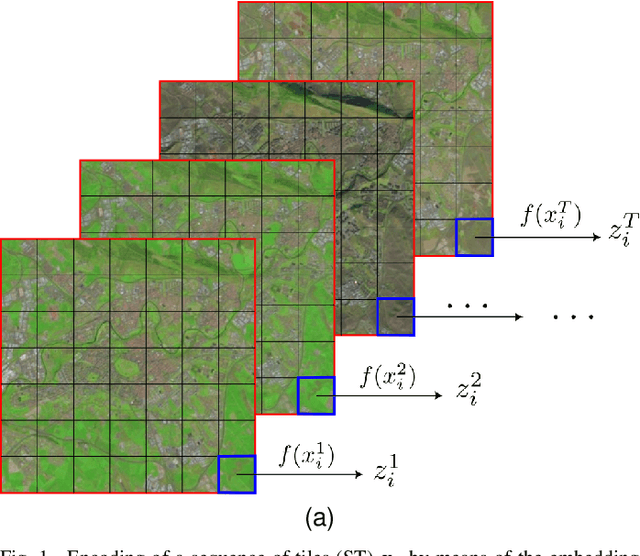
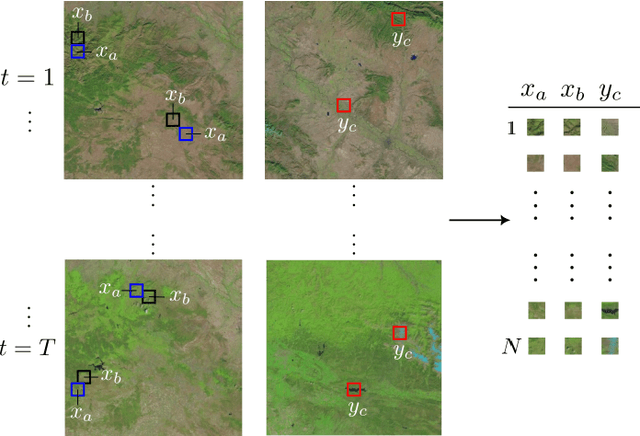
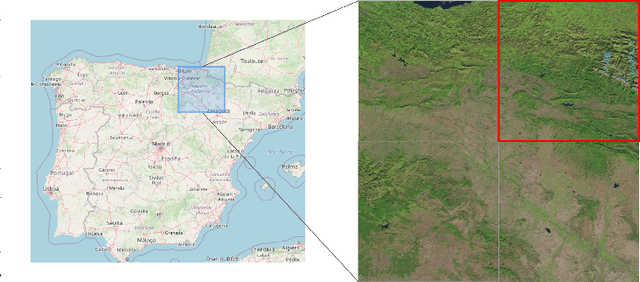
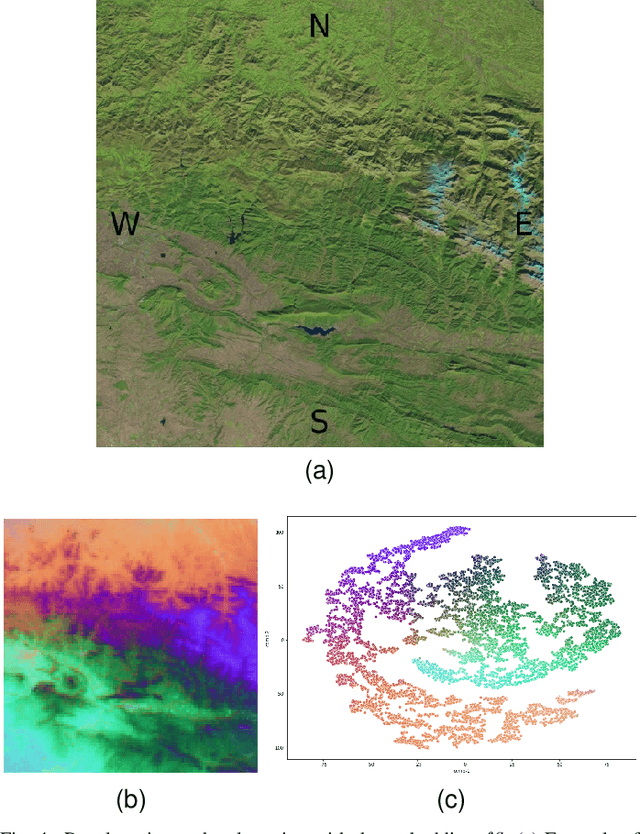
Satellite images constitute a highly valuable and abundant resource for many real world applications. However, the labeled data needed to train most machine learning models are scarce and difficult to obtain. In this context, the current work investigates a fully unsupervised methodology that, given a temporal sequence of satellite images, creates a partition of the ground according to its semantic properties and their evolution over time. The sequences of images are translated into a grid of multivariate time series of embedded tiles. The embedding and the partitional clustering of these sequences of tiles are constructed in two iterative steps: In the first step, the embedding is able to extract the information of the sequences of tiles based on a geographical neighborhood, and the tiles are grouped into clusters. In the second step, the embedding is refined by using the neighborhood defined by the clusters, and the final clustering of the sequences of tiles is obtained. We illustrate the methodology by conducting the semantic clustering of a sequence of 20 satellite images of the region of Navarra (Spain). The results show that the clustering of multivariate time series is robust and contains trustful spatio-temporal semantic information about the region under study. We unveil the close connection that exists between the geographic and embedded spaces, and find out that the semantic properties attributed to these kinds of embeddings are fully exploited and even enhanced by the proposed clustering of time series.
Darwinian Model Upgrades: Model Evolving with Selective Compatibility
Oct 13, 2022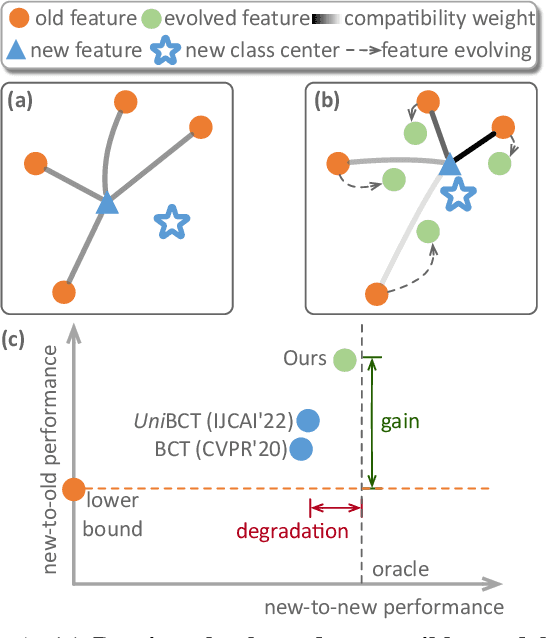
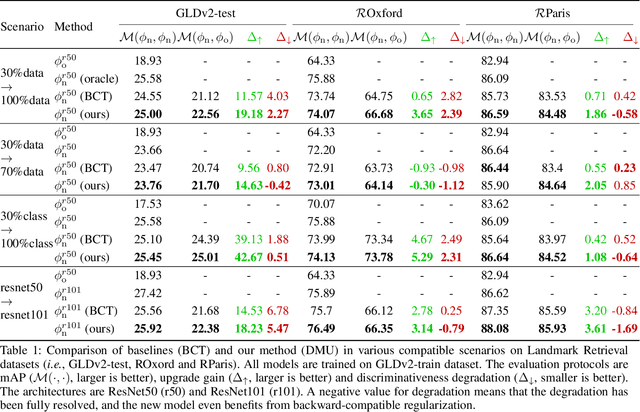
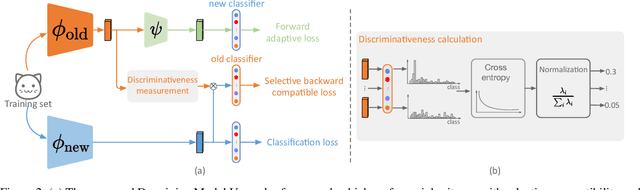
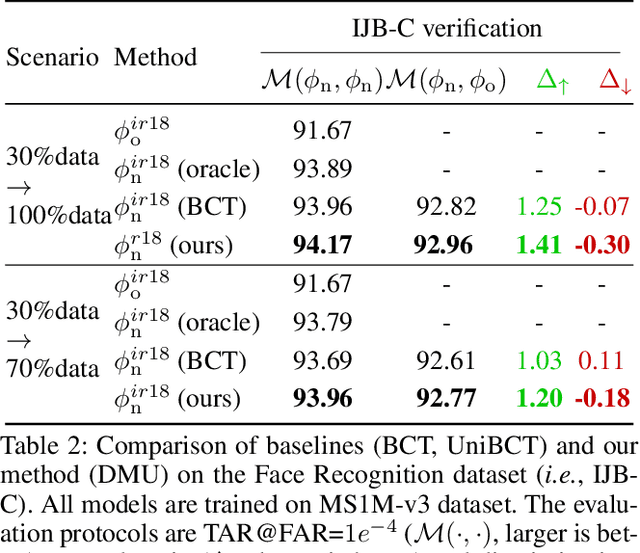
The traditional model upgrading paradigm for retrieval requires recomputing all gallery embeddings before deploying the new model (dubbed as "backfilling"), which is quite expensive and time-consuming considering billions of instances in industrial applications. BCT presents the first step towards backward-compatible model upgrades to get rid of backfilling. It is workable but leaves the new model in a dilemma between new feature discriminativeness and new-to-old compatibility due to the undifferentiated compatibility constraints. In this work, we propose Darwinian Model Upgrades (DMU), which disentangle the inheritance and variation in the model evolving with selective backward compatibility and forward adaptation, respectively. The old-to-new heritable knowledge is measured by old feature discriminativeness, and the gallery features, especially those of poor quality, are evolved in a lightweight manner to become more adaptive in the new latent space. We demonstrate the superiority of DMU through comprehensive experiments on large-scale landmark retrieval and face recognition benchmarks. DMU effectively alleviates the new-to-new degradation and improves new-to-old compatibility, rendering a more proper model upgrading paradigm in large-scale retrieval systems.
Amortized Inference for Heterogeneous Reconstruction in Cryo-EM
Oct 13, 2022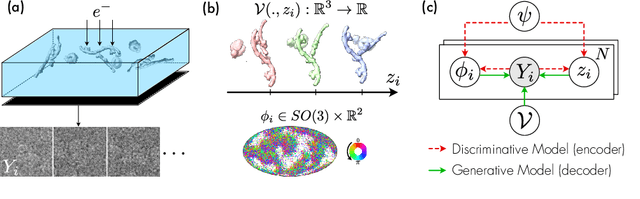
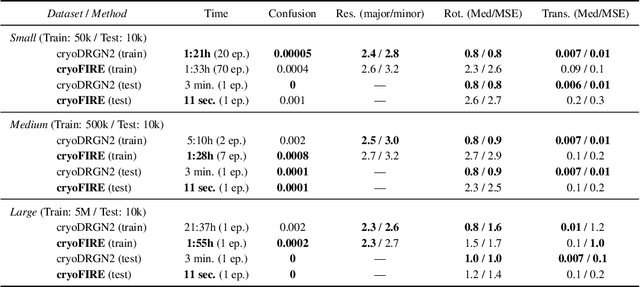
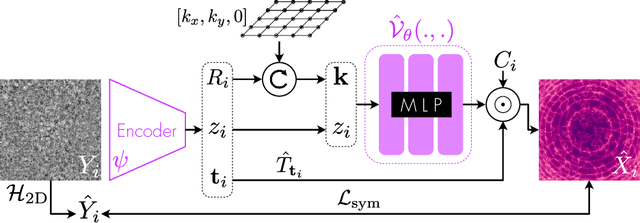
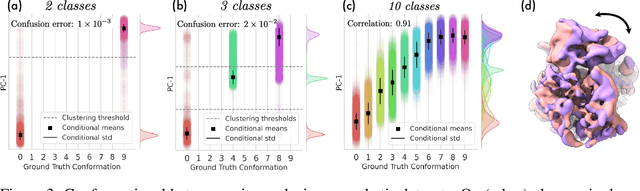
Cryo-electron microscopy (cryo-EM) is an imaging modality that provides unique insights into the dynamics of proteins and other building blocks of life. The algorithmic challenge of jointly estimating the poses, 3D structure, and conformational heterogeneity of a biomolecule from millions of noisy and randomly oriented 2D projections in a computationally efficient manner, however, remains unsolved. Our method, cryoFIRE, performs ab initio heterogeneous reconstruction with unknown poses in an amortized framework, thereby avoiding the computationally expensive step of pose search while enabling the analysis of conformational heterogeneity. Poses and conformation are jointly estimated by an encoder while a physics-based decoder aggregates the images into an implicit neural representation of the conformational space. We show that our method can provide one order of magnitude speedup on datasets containing millions of images without any loss of accuracy. We validate that the joint estimation of poses and conformations can be amortized over the size of the dataset. For the first time, we prove that an amortized method can extract interpretable dynamic information from experimental datasets.
Virtual-Reality based Vestibular Ocular Motor Screening for Concussion Detection using Machine-Learning
Oct 13, 2022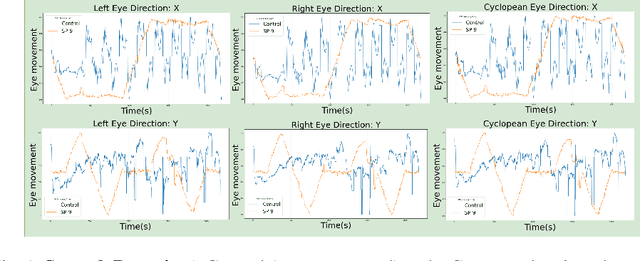

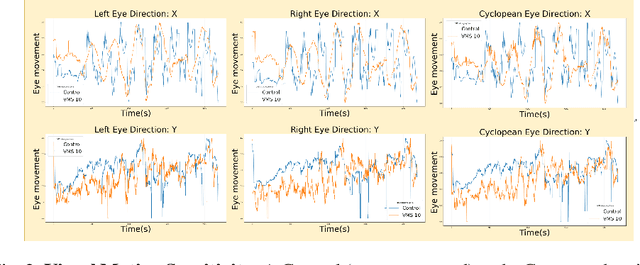
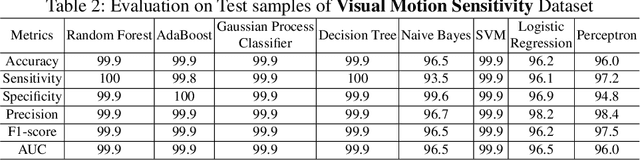
Sport-related concussion (SRC) depends on sensory information from visual, vestibular, and somatosensory systems. At the same time, the current clinical administration of Vestibular/Ocular Motor Screening (VOMS) is subjective and deviates among administrators. Therefore, for the assessment and management of concussion detection, standardization is required to lower the risk of injury and increase the validation among clinicians. With the advancement of technology, virtual reality (VR) can be utilized to advance the standardization of the VOMS, increasing the accuracy of testing administration and decreasing overall false positive rates. In this paper, we experimented with multiple machine learning methods to detect SRC on VR-generated data using VOMS. In our observation, the data generated from VR for smooth pursuit (SP) and the Visual Motion Sensitivity (VMS) tests are highly reliable for concussion detection. Furthermore, we train and evaluate these models, both qualitatively and quantitatively. Our findings show these models can reach high true-positive-rates of around 99.9 percent of symptom provocation on the VR stimuli-based VOMS vs. current clinical manual VOMS.
Condition-number-independent Convergence Rate of Riemannian Hamiltonian Monte Carlo with Numerical Integrators
Oct 13, 2022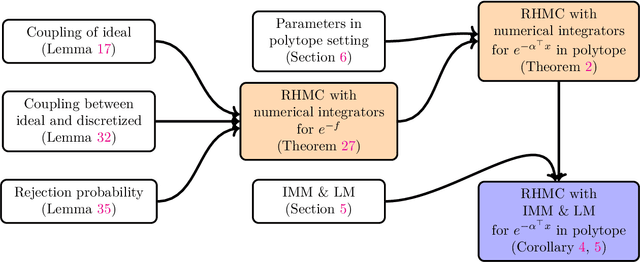
We study the convergence rate of discretized Riemannian Hamiltonian Monte Carlo on sampling from distributions in the form of $e^{-f(x)}$ on a convex set $\mathcal{M}\subset\mathbb{R}^{n}$. We show that for distributions in the form of $e^{-\alpha^{\top}x}$ on a polytope with $m$ constraints, the convergence rate of a family of commonly-used integrators is independent of $\left\Vert \alpha\right\Vert_2$ and the geometry of the polytope. In particular, the Implicit Midpoint Method (IMM) and the generalized Leapfrog integrator (LM) have a mixing time of $\widetilde{O}\left(mn^{3}\right)$ to achieve $\epsilon$ total variation distance to the target distribution. These guarantees are based on a general bound on the convergence rate for densities of the form $e^{-f(x)}$ in terms of parameters of the manifold and the integrator. Our theoretical guarantee complements the empirical results of [KLSV22], which shows that RHMC with IMM can sample ill-conditioned, non-smooth and constrained distributions in very high dimension efficiently in practice.
Geometric Active Learning for Segmentation of Large 3D Volumes
Oct 13, 2022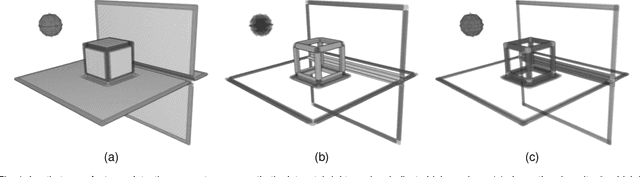
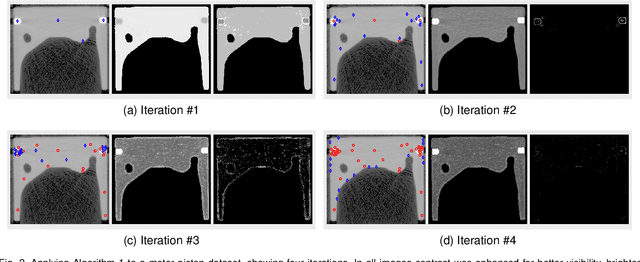
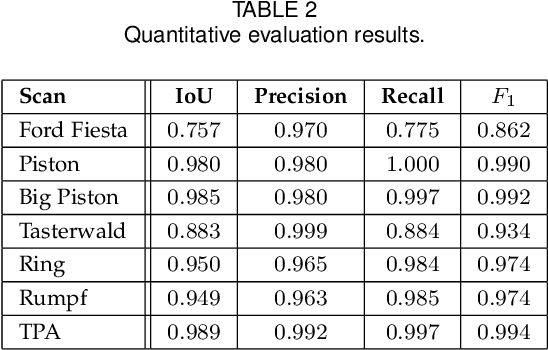
Segmentation, i.e., the partitioning of volumetric data into components, is a crucial task in many image processing applications ever since such data could be generated. Most existing applications nowadays, specifically CNNs, make use of voxelwise classification systems which need to be trained on a large number of annotated training volumes. However, in many practical applications such data sets are seldom available and the generation of annotations is time-consuming and cumbersome. In this paper, we introduce a novel voxelwise segmentation method based on active learning on geometric features. Our method uses interactively provided seed points to train a voxelwise classifier based entirely on local information. The combination of an ad hoc incorporation of domain knowledge and local processing results in a flexible yet efficient segmentation method that is applicable to three-dimensional volumes without size restrictions. We illustrate the potential and flexibility of our approach by applying it to selected computed tomography scans where we perform different segmentation tasks to scans from different domains and of different sizes.
Ensemble Creation via Anchored Regularization for Unsupervised Aspect Extraction
Oct 13, 2022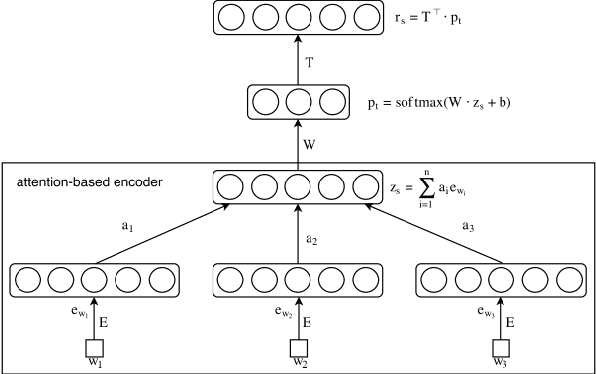
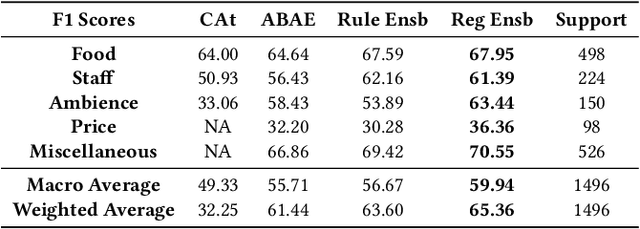
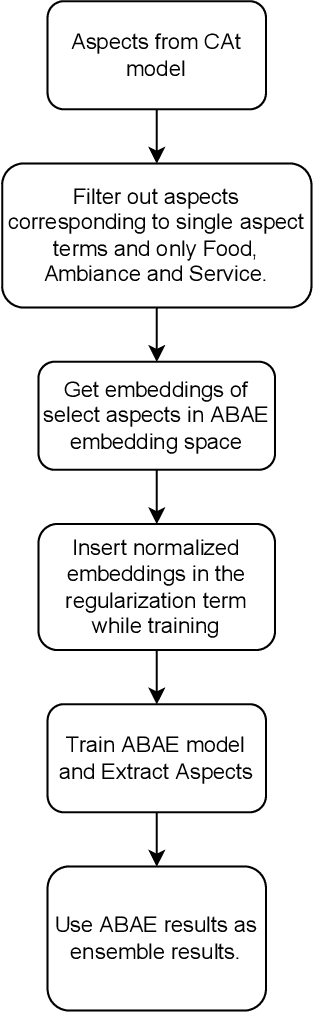
Aspect Based Sentiment Analysis is the most granular form of sentiment analysis that can be performed on the documents / sentences. Besides delivering the most insights at a finer grain, it also poses equally daunting challenges. One of them being the shortage of labelled data. To bring in value right out of the box for the text data being generated at a very fast pace in today's world, unsupervised aspect-based sentiment analysis allows us to generate insights without investing time or money in generating labels. From topic modelling approaches to recent deep learning-based aspect extraction models, this domain has seen a lot of development. One of the models that we improve upon is ABAE that reconstructs the sentences as a linear combination of aspect terms present in it, In this research we explore how we can use information from another unsupervised model to regularize ABAE, leading to better performance. We contrast it with baseline rule based ensemble and show that the ensemble methods work better than the individual models and the regularization based ensemble performs better than the rule-based one.
Fast Hierarchical Learning for Few-Shot Object Detection
Oct 10, 2022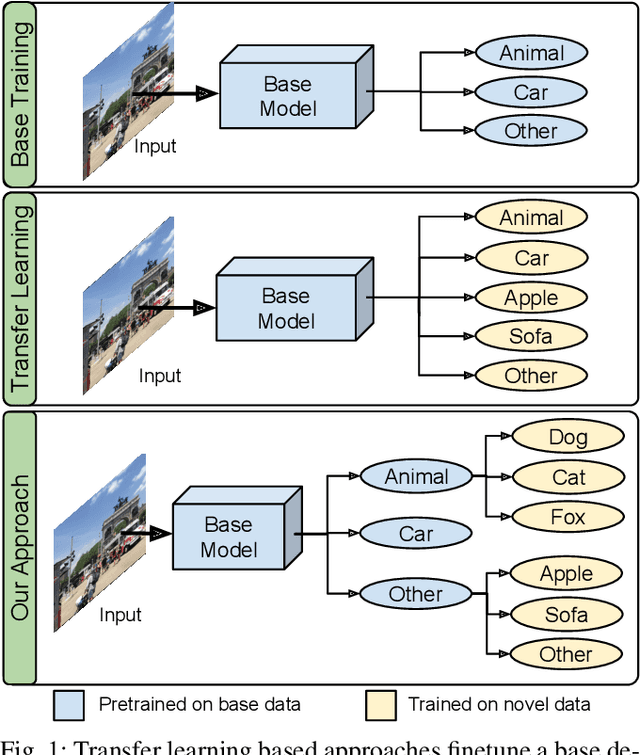
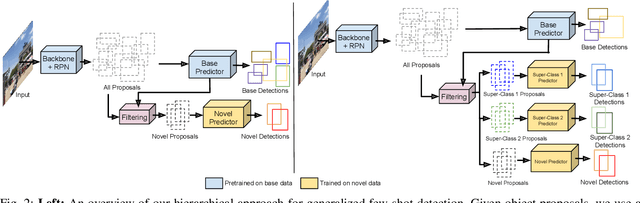
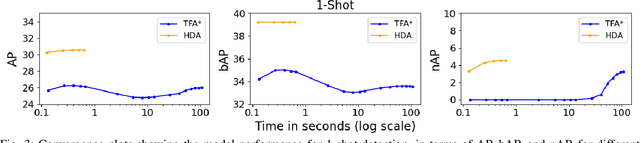

Transfer learning based approaches have recently achieved promising results on the few-shot detection task. These approaches however suffer from ``catastrophic forgetting'' issue due to finetuning of base detector, leading to sub-optimal performance on the base classes. Furthermore, the slow convergence rate of stochastic gradient descent (SGD) results in high latency and consequently restricts real-time applications. We tackle the aforementioned issues in this work. We pose few-shot detection as a hierarchical learning problem, where the novel classes are treated as the child classes of existing base classes and the background class. The detection heads for the novel classes are then trained using a specialized optimization strategy, leading to significantly lower training times compared to SGD. Our approach obtains competitive novel class performance on few-shot MS-COCO benchmark, while completely retaining the performance of the initial model on the base classes. We further demonstrate the application of our approach to a new class-refined few-shot detection task.